GSP1052

Visão geral
No ambiente competitivo de hoje, as organizações precisam tomar decisões de forma fácil e rápida com base em dados coletados em tempo real. O Datastream para BigQuery oferece replicação otimizada de origens de bancos de dados operacionais como AlloyDB, MySQL, PostgreSQL e Oracle diretamente para o BigQuery, o data warehouse sem servidor do Google Cloud. Com arquitetura sem servidor e com escalonamento automático, o Datastream permite configurar facilmente um pipeline ELT (extrair, carregar e transformar) para a replicação de dados de baixa latência, gerando insights em tempo real.
Neste laboratório prático, você vai implantar um banco de dados do Cloud SQL para PostgreSQL e importar um conjunto de dados de amostra usando a linha de comando gcloud. Na interface, você vai criar e iniciar um fluxo do Datastream e replicar os dados para o BigQuery.
Embora seja possível copiar e colar os comandos do laboratório no local adequado, os estudantes precisam digitá-los para reforçar o aprendizado dos conceitos principais.
Atividades deste laboratório
- Preparar uma instância do Cloud SQL para PostgreSQL usando o console do Google Cloud
- Importar dados para a instância do Cloud SQL
- Criar um perfil de conexão do Datastream para o banco de dados do PostgreSQL
- Criar um perfil de conexão do Datastream para o destino do BigQuery
- Criar um fluxo do Datastream e começar a replicação
- Validar se os dados existentes e as alterações foram replicados corretamente para o BigQuery
Pré-requisitos
- Familiaridade com ambientes Linux padrão
- Familiaridade com conceitos de captura de dados alterados (CDC)
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é ativado quando você clica em Iniciar laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, e não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima (recomendado) ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça que, depois de começar, não será possível pausar o laboratório.
Observação: use apenas a conta de estudante neste laboratório. Se usar outra conta do Google Cloud, você poderá receber cobranças nela.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar por ele, uma caixa de diálogo vai aparecer para você selecionar a forma de pagamento.
No painel Detalhes do Laboratório, à esquerda, você vai encontrar o seguinte:
- O botão Abrir Console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer Login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Username"}}}
Você também encontra o nome de usuário no painel Detalhes do Laboratório.
-
Clique em Próxima.
-
Copie a Senha abaixo e cole na caixa de diálogo de Olá.
{{{user_0.password | "Password"}}}
Você também encontra a senha no painel Detalhes do Laboratório.
-
Clique em Próxima.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar os produtos e serviços do Google Cloud, clique no Menu de navegação ou digite o nome do serviço ou produto no campo Pesquisar.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
-
Clique em Ativar o Cloud Shell  na parte de cima do console do Google Cloud.
na parte de cima do console do Google Cloud.
-
Clique nas seguintes janelas:
- Continue na janela de informações do Cloud Shell.
- Autorize o Cloud Shell a usar suas credenciais para fazer chamadas de APIs do Google Cloud.
Depois de se conectar, você verá que sua conta já está autenticada e que o projeto está configurado com seu Project_ID, . A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
gcloud auth list
- Clique em Autorizar.
Saída:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (Opcional) É possível listar o ID do projeto usando este comando:
gcloud config list project
Saída:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Observação: consulte a documentação completa da gcloud no Google Cloud no guia de visão geral da gcloud CLI.
Tarefa 1: criar um banco de dados para replicação
Nesta seção, você vai preparar um banco de dados do Cloud SQL para PostgreSQL para replicação pelo Datastream.
Criar o banco de dados do Cloud SQL
- Execute o seguinte comando para ativar a API Cloud SQL:
gcloud services enable sqladmin.googleapis.com
- Execute o seguinte comando para criar uma instância de banco de dados do Cloud SQL para PostgreSQL:
POSTGRES_INSTANCE=postgres-db
DATASTREAM_IPS={{{project_0.startup_script.ip_Address | IP_ADDRESS}}}
gcloud sql instances create ${POSTGRES_INSTANCE} \
--database-version=POSTGRES_14 \
--cpu=2 --memory=10GB \
--authorized-networks=${DATASTREAM_IPS} \
--region={{{project_0.default_region|REGION}}} \
--root-password pwd \
--database-flags=cloudsql.logical_decoding=on
Observação: esse comando cria o banco de dados em . Para outras regiões, substitua DATASTREAM_IPS pelos IPs públicos do Datastream certos para sua região.
Observação: após a criação da instância, anote o IP público dela. Você vai precisar dele mais tarde ao criar o perfil de conexão do Datastream.
Clique em Verificar meu progresso para conferir o objetivo.
Criar um banco de dados para replicação
Preencher o banco de dados com os dados de amostra
Conecte-se ao banco de dados do PostgreSQL executando o seguinte comando no Cloud Shell.
gcloud sql connect postgres-db --user=postgres
Quando a senha for solicitada, digite pwd.
Após se conectar ao banco de dados, execute o seguinte comando SQL para criar um esquema de amostra e uma tabela:
CREATE SCHEMA IF NOT EXISTS test;
CREATE TABLE IF NOT EXISTS test.example_table (
id SERIAL PRIMARY KEY,
text_col VARCHAR(50),
int_col INT,
date_col TIMESTAMP
);
ALTER TABLE test.example_table REPLICA IDENTITY DEFAULT;
INSERT INTO test.example_table (text_col, int_col, date_col) VALUES
('hello', 0, '2020-01-01 00:00:00'),
('goodbye', 1, NULL),
('name', -987, NOW()),
('other', 2786, '2021-01-01 00:00:00');
Configurar o banco de dados para replicação
- Execute o seguinte comando SQL para criar uma publicação e um slot de replicação:
CREATE PUBLICATION test_publication FOR ALL TABLES;
ALTER USER POSTGRES WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('test_replication', 'pgoutput');
Tarefa 2: criar os recursos do Datastream e começar a replicação
Agora que o banco de dados está pronto, crie os perfis de conexão e o fluxo do Datastream para começar a replicação.
-
No menu de navegação, clique em Mostrar todos os produtos. Em Análise, selecione Datastream
-
Clique em Ativar para ativar a API Datastream.
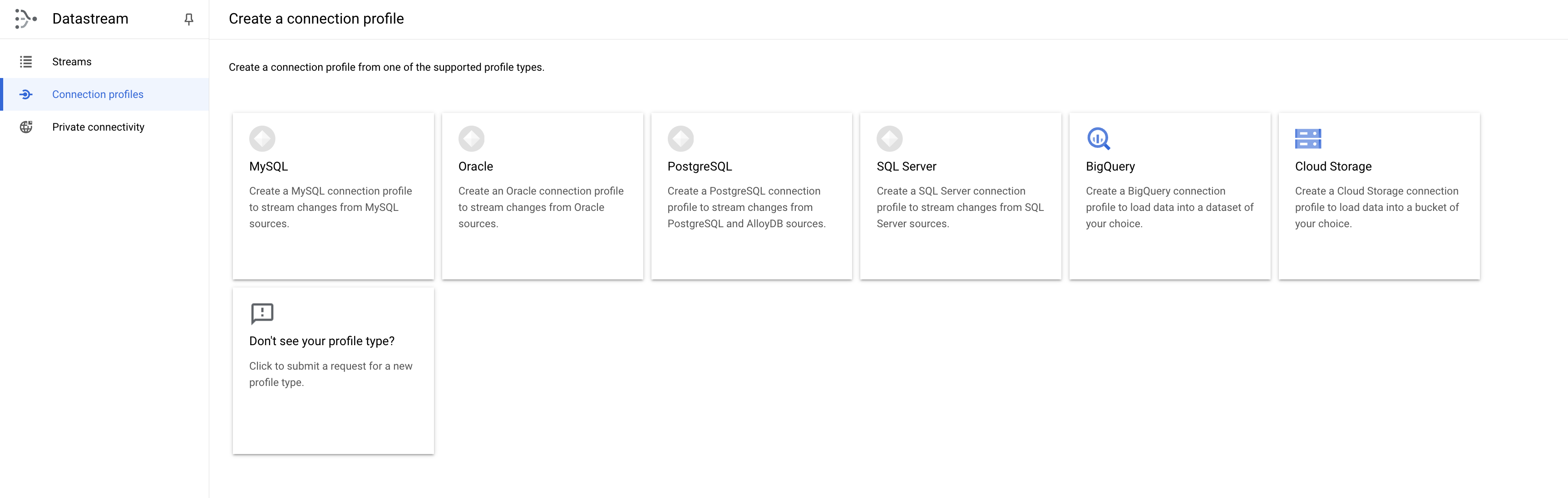
Criar perfis de conexão
Crie dois perfis de conexão, um para a origem do PostgreSQL e outro para o destino do BigQuery.
Perfil de conexão do PostgreSQL
- No console do Cloud, navegue até a guia Perfis de conexão e clique em Criar perfil.

- Selecione o tipo de perfil PostgreSQL.
-
Use postgres-cp como nome e ID do perfil de conexão.
-
Digite os detalhes de conexão do banco de dados:
- Região:
- O IP e a porta da instância do Cloud SQL criada anteriormente(Tarefa 1)
- Para encontrar o endereço IP da sua instância do Cloud SQL:
- No menu de navegação, clique em SQL:
- Na página SQL, localize sua instância do PostgreSQL (normalmente chamada de postgres-db).
- Copie o endereço IP público da instância.
- Nome de usuário:
postgres
- Senha:
pwd
- Banco de dados:
postgres
-
Clique em Continuar.
-
Selecione o método de conectividade Lista de permissões de IP e clique em Continuar.
-
Clique em EXECUTAR TESTE para garantir que o Datastream pode alcançar o banco de dados.
-
Clique em Criar.
Perfil de conexão do BigQuery
- No console do Cloud, navegue até a guia Perfis de conexão e clique em Criar perfil.
- Selecione o tipo de perfil de conexão BigQuery.
-
Use bigquery-cp como nome e ID do perfil de conexão.
-
Região
-
Clique em Criar.
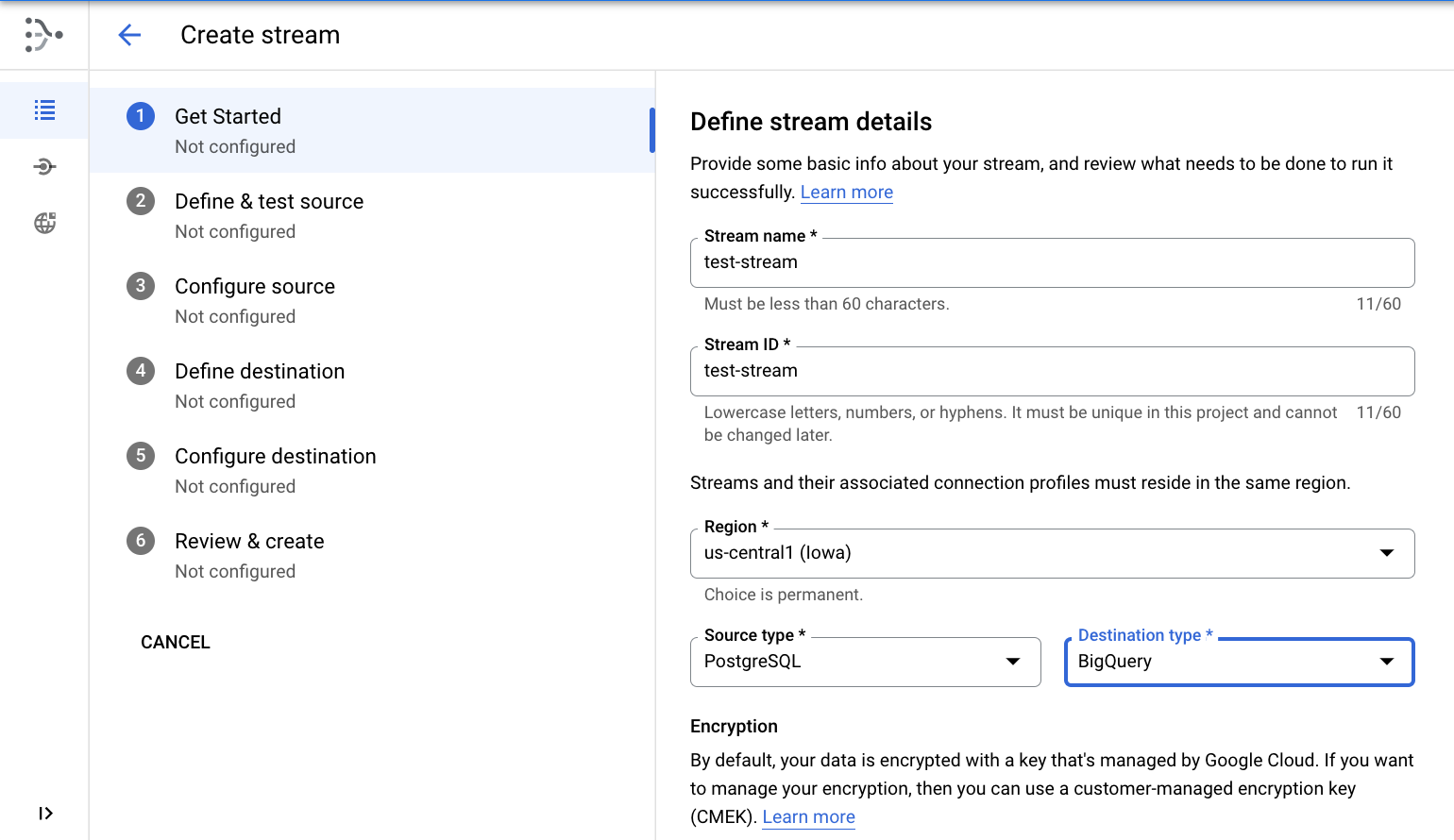
Criar fluxo
Crie o fluxo que conecta os perfis de conexão criados acima e define a configuração do fluxo de dados da origem até o destino.
- No console do Cloud, navegue até a guia Fluxos e clique em Criar fluxo.

Definir os detalhes do fluxo
- Use
test-stream como nome e ID do fluxo.
- Região
- Selecione PostgreSQL como tipo de origem
- Selecione BigQuery como tipo de destino
- Clique em CONTINUAR.
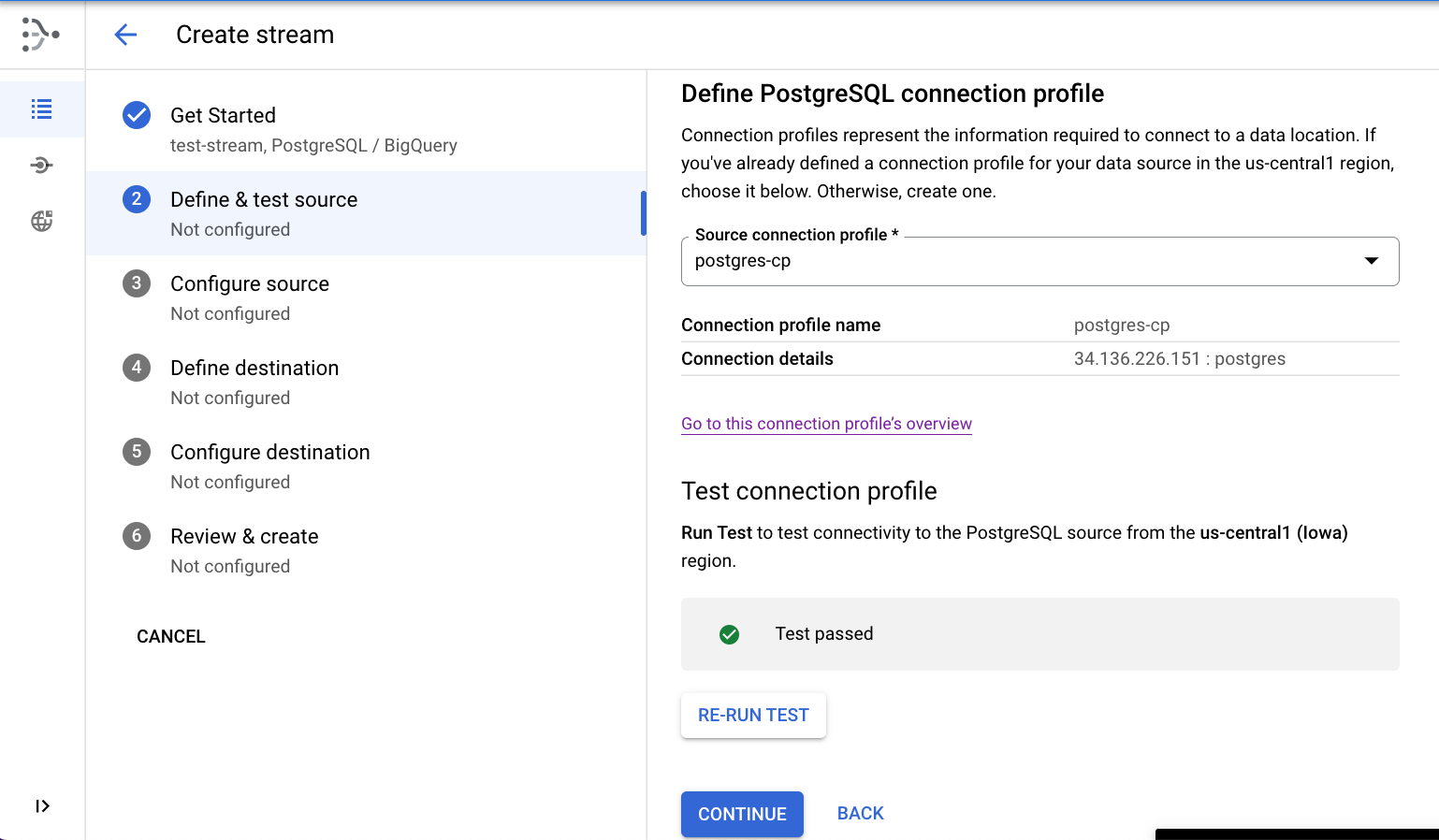
Definir a origem
- Selecione o perfil de conexão postgres-cp criado na etapa anterior.
- [Opcional] Teste a conectividade clicando em EXECUTAR TESTE.
- Clique em CONTINUAR.
Configurar a origem
- Especifique o nome do slot de replicação como
test_replication.
- Especifique o nome de publicação como
test_publication.
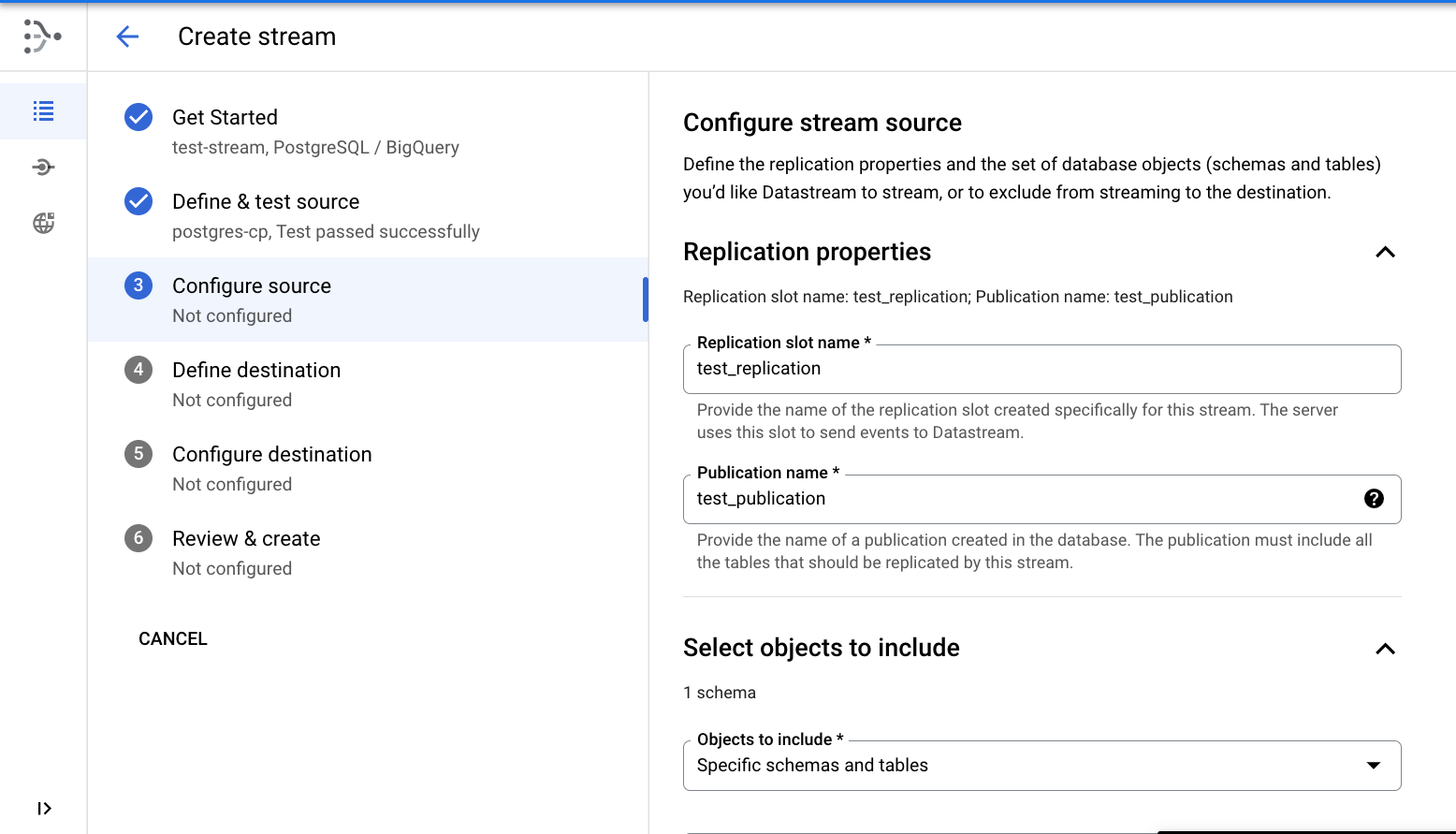
- Selecione o esquema test para replicação.
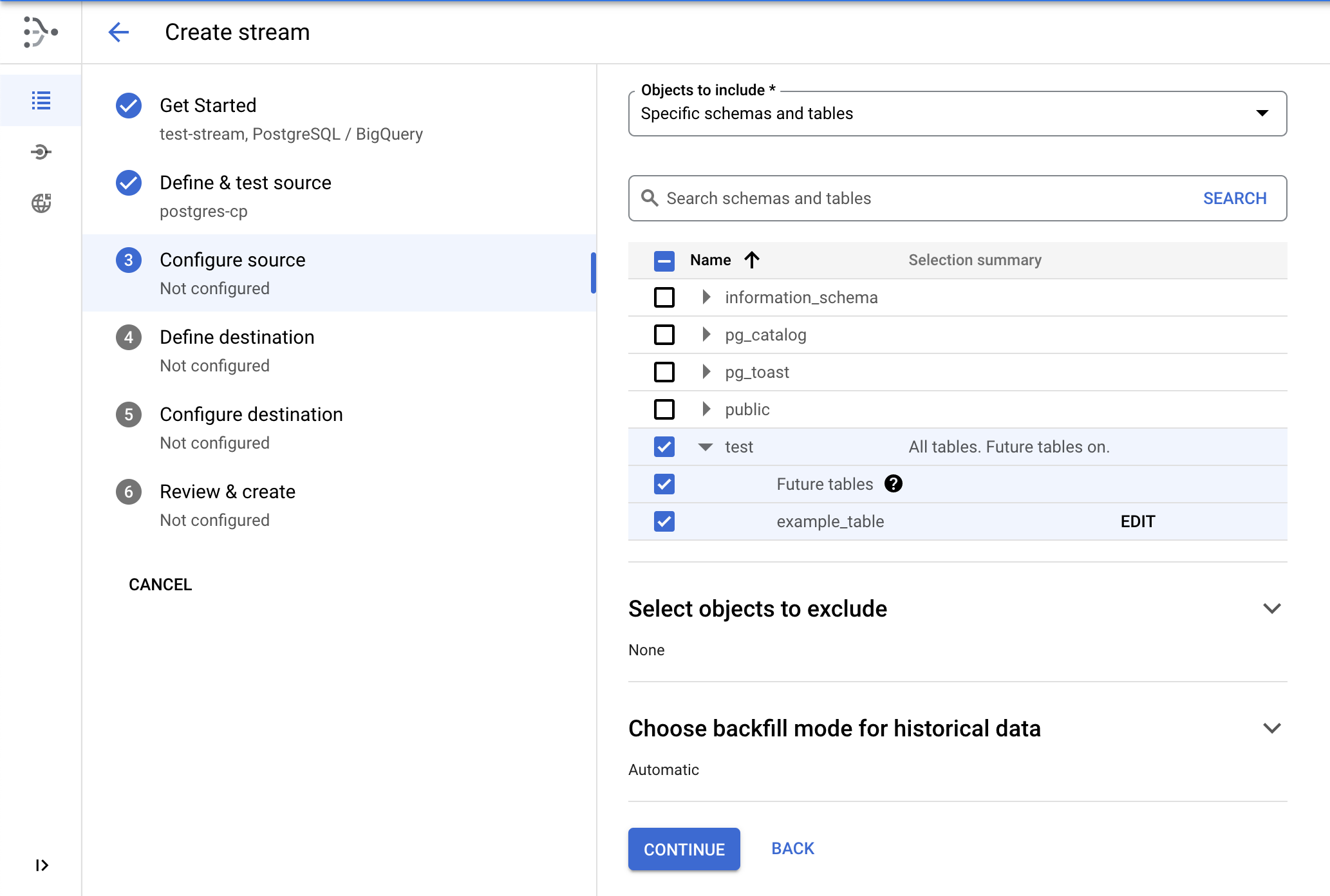
- Clique em Continuar.
Definir o destino
- Selecione o perfil de conexão bigquery-cp criado na etapa anterior e clique em Continuar.
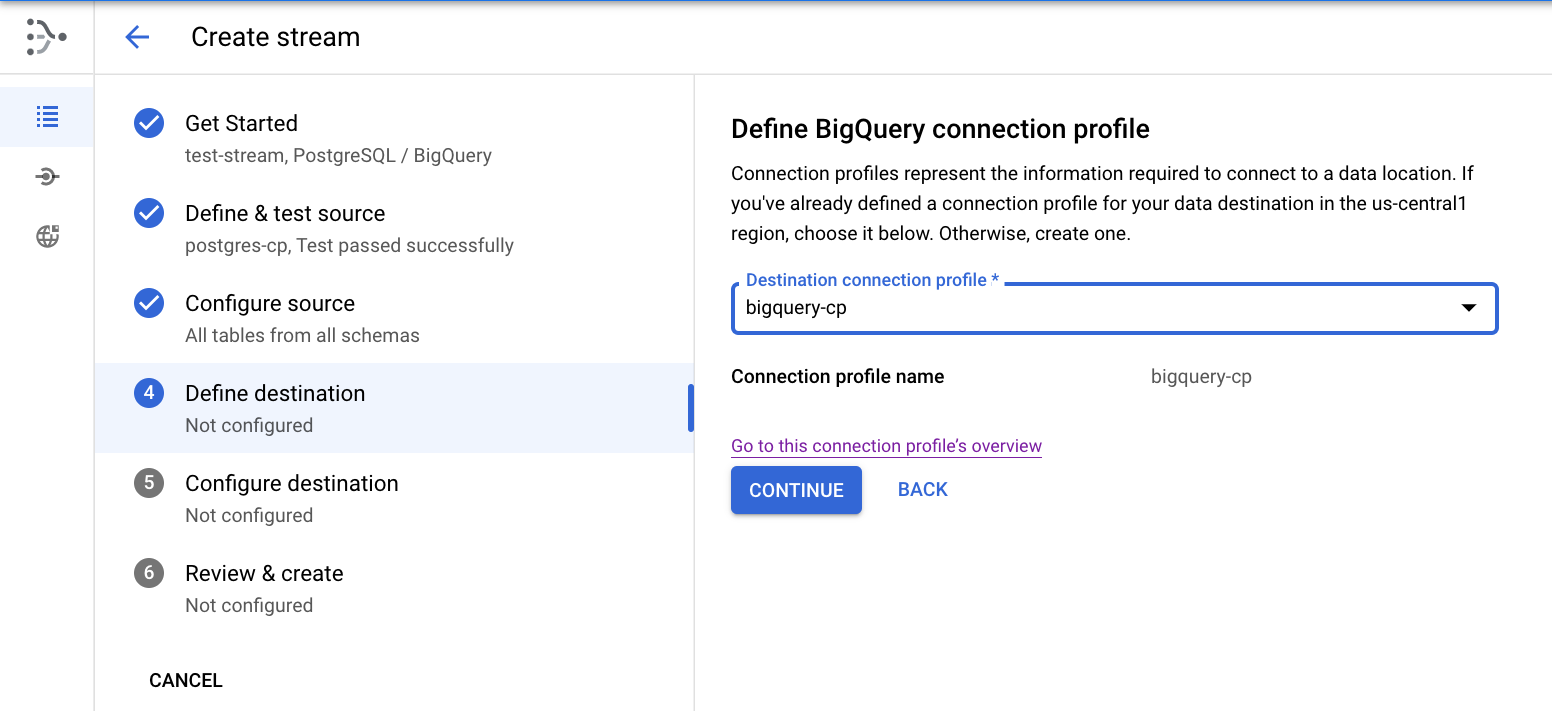
Configurar o destino
- Escolha "Região" e selecione como local do conjunto de dados do BigQuery.
- Defina o limite de inatividade como 0 segundo.
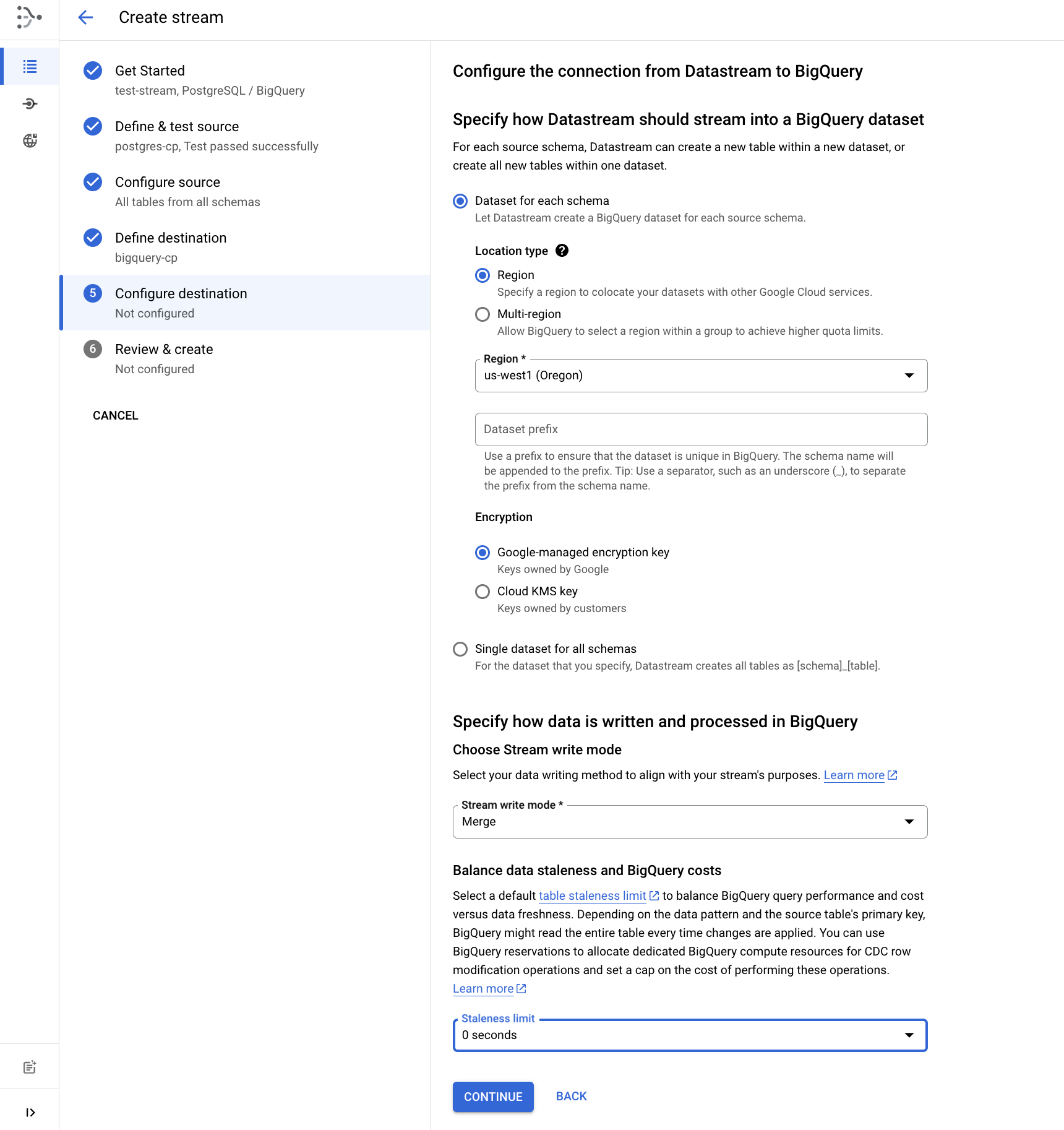
- Clique em Continuar.
Revisar e criar o fluxo
- Por fim, valide os detalhes do fluxo clicando em Executar validação. Quando a validação for concluída, clique em Criar e iniciar e confirme Criar e iniciar.
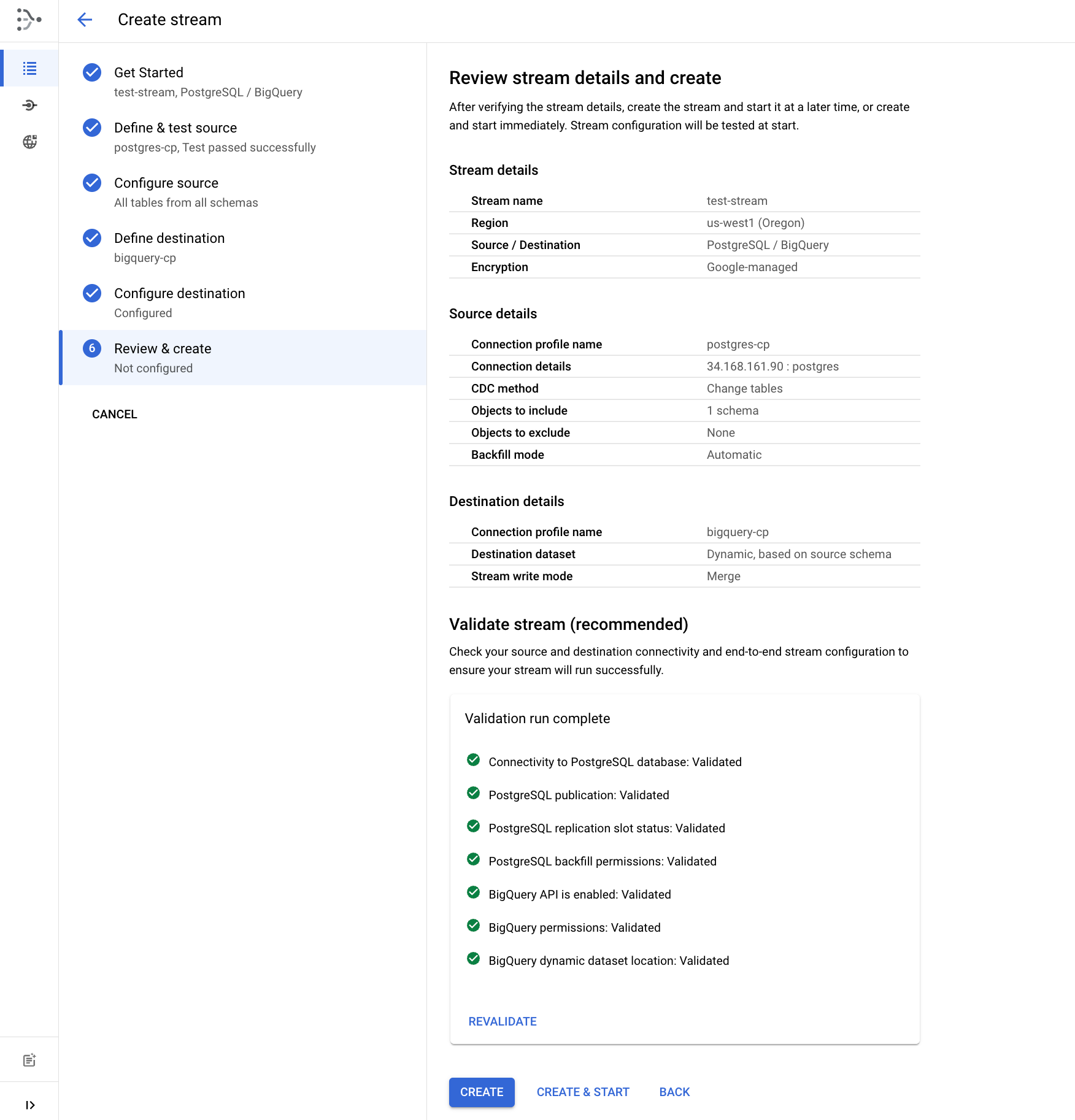
Aguarde aproximadamente 1 a 2 minutos até que o status do fluxo seja mostrado como "Em execução".
Clique em Verificar meu progresso para conferir o objetivo.
Criar os recursos do Datastream
Tarefa 3: visualizar os dados no BigQuery
Agora que o fluxo está em execução, confira a replicação dos dados para o conjunto de dados do BigQuery.
- No menu de navegação do console do Google Cloud, acesse o BigQuery.
No pop-up, clique em Concluído.
- No explorador do BigQuery Studio, abra o nó do projeto para ver a lista de bancos de dados.
- Abra o nó de banco de dados test.
- Clique na tabela example_table.
- Clique na guia VISUALIZAR para ver os dados no BigQuery.
Observação: pode levar alguns minutos para os dados aparecerem na seção Visualizar.
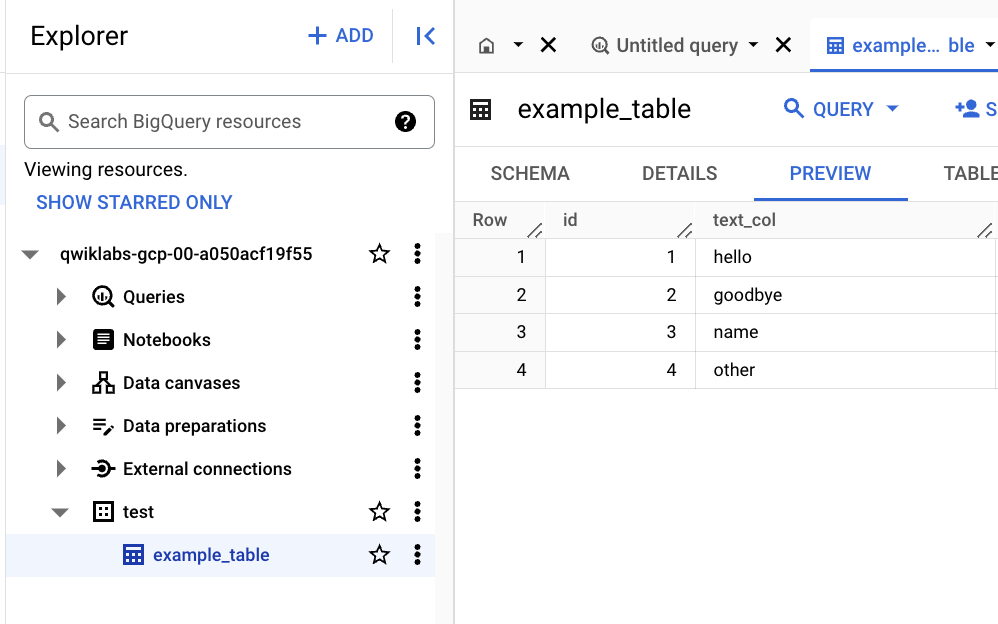
- Se a mensagem "Não há dados para mostrar" aparecer na guia de prévia, verifique os dados usando o seguinte comando.
SELECT * FROM test.example_table ORDER BY id;
Tarefa 4: verificar se as mudanças na origem são replicadas para o BigQuery
- Execute o seguinte comando no Cloud Shell para se conectar ao banco de dados do Cloud SQL (a senha é
pwd):
gcloud sql connect postgres-db --user=postgres
- Execute os seguintes comandos SQL para fazer algumas alterações nos dados:
INSERT INTO test.example_table (text_col, int_col, date_col) VALUES
('abc', 0, '2022-10-01 00:00:00'),
('def', 1, NULL),
('ghi', -987, NOW());
UPDATE test.example_table SET int_col=int_col*2;
DELETE FROM test.example_table WHERE text_col = 'abc';
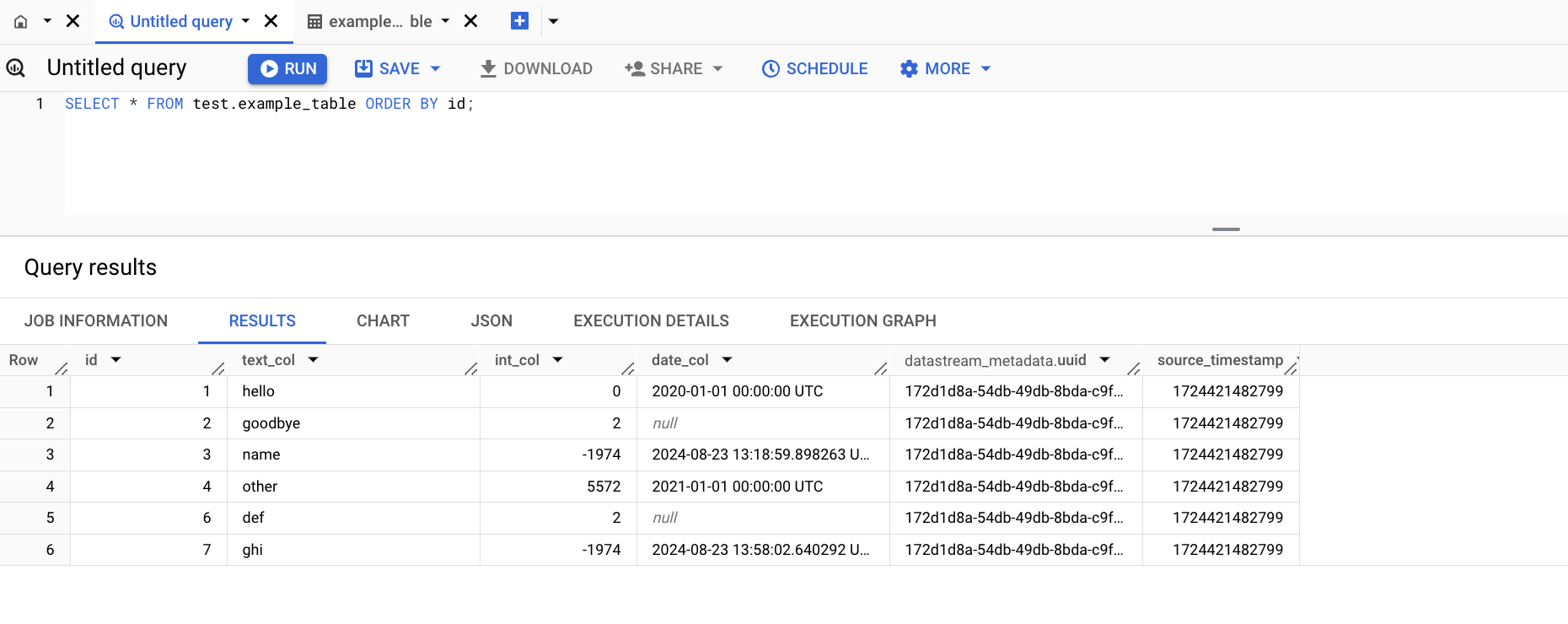
- Abra o espaço de trabalho do BigQuery SQL e execute a seguinte consulta para ver as mudanças no BigQuery:
SELECT * FROM test.example_table ORDER BY id;
Parabéns!
O Datastream é um recurso importante de integração e análise de dados. Você aprendeu os conceitos básicos de replicação do PostgreSQL para o BigQuery com o Datastream.
Manual atualizado em 24 de fevereiro de 2025
Laboratório testado em 24 de fevereiro de 2025
Copyright 2025 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.





