Neste laboratório, é possível usar a Vertex AI para treinar e implantar um modelo de ML. É pressuposto que você está familiarizado com machine learning, mesmo que o código de machine learning para este treinamento seja oferecido a você. Você vai usar conjuntos de dados, para a criação e o gerenciamento de conjuntos de dados, e um modelo personalizado, para treinar um modelo de Scikit Learn. Por fim, você vai implantar o modelo treinado e receber previsões on-line. O conjunto de dados que você vai usar para essa demonstração é o Conjunto de dados Titanic.
Objetivos
Criar um conjunto de dados para dados tabulares.
Criar um pacote de treinamento com código personalizado usando Notebooks.
Implantar o modelo treinado e receber previsões on-line.
Configuração
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Observação: se você tiver dificuldade para fazer o download do conjunto de dados no modo de navegação anônima, use a janela normal para fazer download do conjunto de dados Titanic.
Renomeie o conjunto de dados baixado como titanic_toy.csv.
Depois, faça o seguinte na interface:
Abra o conjunto de dados titanic que você criou na etapa anterior. (Clique em Mostrar ações () ao lado do conjunto de dados e selecione Abrir).
Clique em Criar tabela e especifique o seguinte:
Criar tabela de: Upload
Selecionar arquivo: use o conjunto de dados Titanic baixado
Formato do arquivo: CSV
Nome da tabela: sobreviventes
Detecção automática: selecione a caixa de seleção de detecção automática em Esquema
Selecione Criar tabela.
Clique no ícone Mostrar ações ao lado de survivors e selecione Copiar ID. Salve o ID da tabela copiado para usar posteriormente no laboratório.
Você criou e preencheu a tabela com o conjunto de dados Titanic. Você pode explorar o conteúdo dela, realizar consultas e analisar seus dados.
Tarefa 2: criar um conjunto de dados
Os conjuntos de dados na Vertex AI permitem a criação de conjuntos de dados para suas cargas de trabalho de machine learning. Você pode criar conjuntos de dados estruturados (arquivos CSV ou tabelas do BigQuery) ou dados não estruturados, como imagens e texto. É importante observar que os conjuntos de dados na Vertex AI apenas fazem referência aos seus dados originais, não havendo duplicação.
Criar um conjunto de dados de ML
No console do Google Cloud, no Menu de navegação, selecione Vertex AI > Conjuntos de dados.
Selecione e clique em Criar.
Dê um nome ao seu conjunto de dados, como titanic.
Você pode criar conjuntos de dados para imagens, texto ou vídeos, bem como para dados tabulares.
O conjunto de dados Titanic é tabular, portanto, clique na guia Tabular.
Para escolher a região, selecione e clique em Criar.
Nesta fase, você acabou de criar um marcador de posição. Você ainda não se conectou à fonte de dados. Vamos fazer isso na etapa seguinte.
Selecionar a fonte de dados
Como você já carregou o conjunto de dados Titanic no BigQuery, você pode conectar seu conjunto de dados de ML à sua tabela do BigQuery.
Clique em Selecionar uma tabela ou visualização do BigQuery
Cole o ID da tabela já copiado no campo "PROCURAR".
Depois de escolher o conjunto de dados, clique em Continuar.
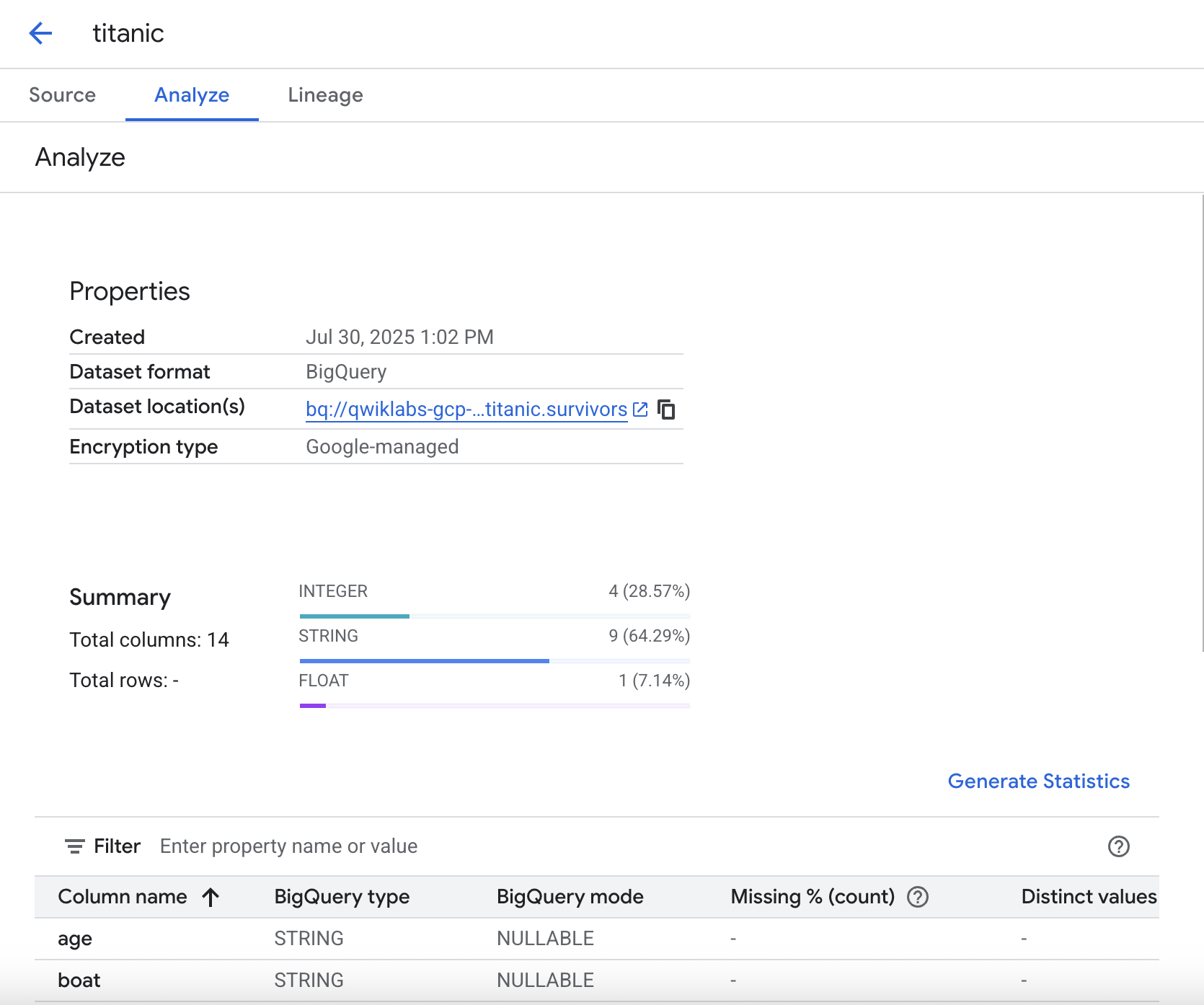
Gerar estatísticas
Na guia Analisar, é possível gerar estatísticas relacionadas aos seus dados. Isso dá a você a capacidade de rapidamente consultar os dados e verificar distribuições, valores ausentes etc.
Para executar a análise estatística, clique em Gerar estatísticas. A execução pode demorar alguns minutos. Portanto, se quiser, você pode prosseguir com o laboratório e voltar mais tarde para conferir os resultados.
Tarefa 3: criar pacote de treinamento personalizado usando o Workbench
É uma boa prática empacotar e parametrizar seu código para que ele se torne um ativo portátil.
Nesta seção, você criará um pacote de treinamento com código personalizado usando o Vertex AI Workbench. Uma etapa fundamental no uso do serviço é poder criar uma distribuição de origem Python, também conhecida como pacote de distribuição. Isso não é muito diferente de criar pastas e arquivos dentro do pacote de distribuição. A próxima seção vai explicar como um pacote é estruturado.
Estrutura do aplicativo
A estrutura básica de um pacote Python pode ser vista na imagem abaixo.
Vamos conferir para que serve aquelas pastas e arquivos:
titanic-package: este é seu diretório de trabalho. Dentro desta pasta vão estar seu pacote e código relacionados ao classificador "sobreviventes" do Titanic.
setup.py: o arquivo de configuração especifica como criar seu pacote de distribuição. Ele inclui informações como o nome e a versão do pacote e quaisquer outros pacotes que você possa precisar para seu trabalho de treinamento e que não estejam incluídos por padrão nos contêineres de treinamento pré-criados do GCP.
trainer: a pasta que contém o código de treinamento. Isso também é um pacote Python. O que o torna um pacote é o arquivo vazio __init__.py dentro da pasta.
__init__.py: arquivo vazio chamado __init__.py. Significa que a pasta à qual ele pertence é um pacote.
task.py: task.py é um módulo de pacote. Aqui está o ponto de entrada do seu código; ele também aceita parâmetros CLI para treinamento de modelo. Também é possível incluir o código de treinamento neste módulo ou criar outros módulos dentro do seu pacote. Isso depende inteiramente de você e de como quer estruturar seu código.
Agora que você entendeu a estrutura, podemos esclarecer que os nomes usados para o pacote e o módulo não precisam ser "trainer" e "task.py". Estamos usando essa convenção de nomenclatura neste laboratório para que ela se alinhe à nossa documentação on-line, mas você pode escolher os nomes que preferir.
Criar sua instância de notebook
Agora vamos criar uma instância de notebook e tentar treinar um modelo personalizado.
No Menu de navegação do console do Google Cloud, clique em Vertex AI > Workbench.
Na página de instâncias do notebook, clique em Criar novo e inicie uma instância com Python 3, que inclui Scikit-learn. Você vai usar um modelo Scikit-learn para seu classificador.
Será exibido um pop-up. Aqui você pode alterar configurações como a região em que sua instância de notebook vai ser criada e a capacidade de processamento necessária.
Como você não está lidando com muitos dados e só precisa da instância para fins de desenvolvimento, não altere nenhuma das configurações, apenas clique em Criar.
A instância vai entrar em funcionamento em alguns minutos.
Assim que a instância estiver pronta, você pode Abrir o Jupyterlab.
Quando o pop-up de “Build recomendado” aparecer, clique em Criar. Se houver uma falha nesse processo, ela pode ser ignorada.
Criar seu pacote
Agora que o notebook está funcionando, você pode começar a criar seus ativos de treinamento.
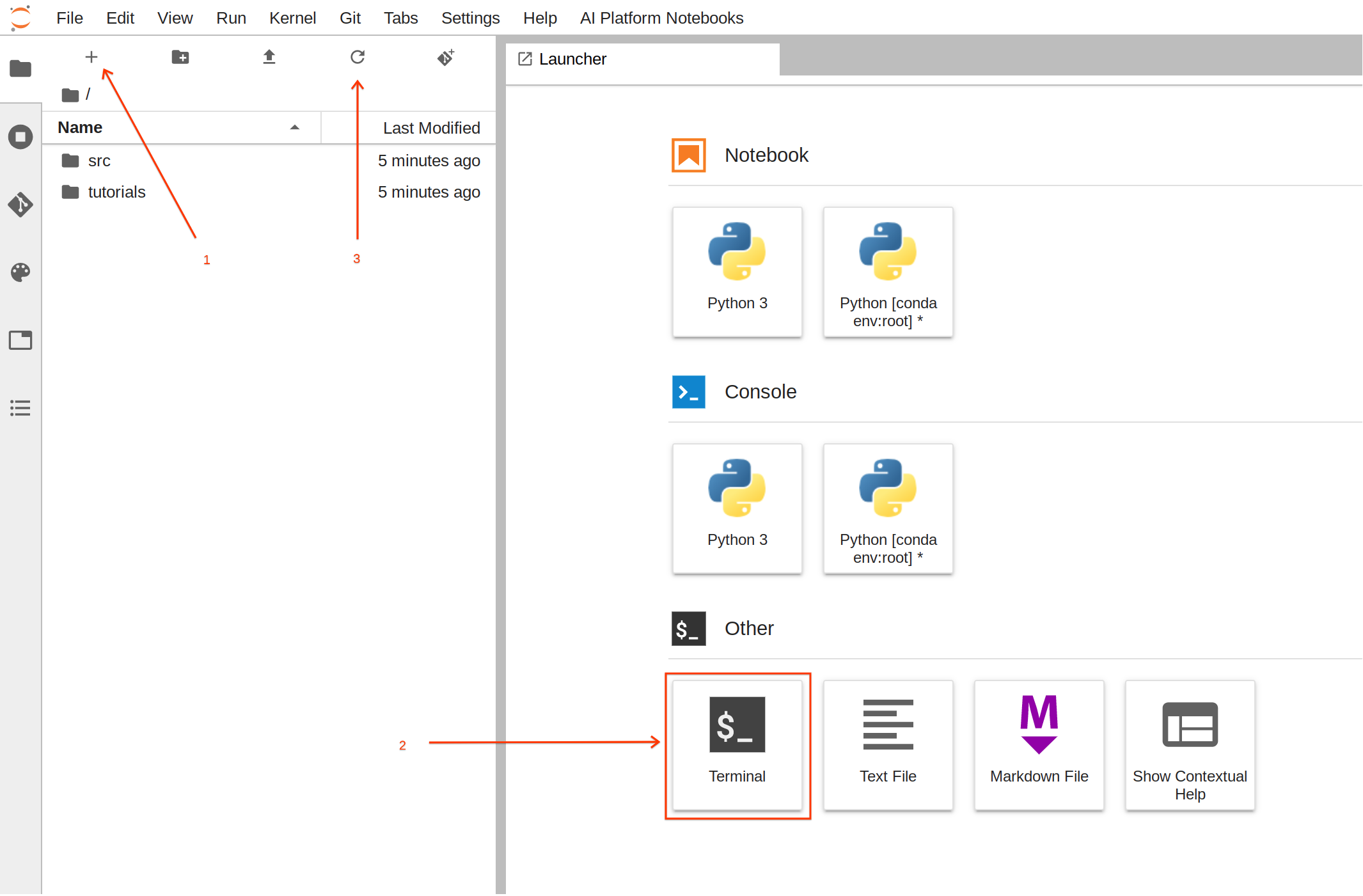
Para essa tarefa, é mais fácil usar o terminal.
Na Tela de início, clique em Terminal para criar uma nova sessão de terminal.
Agora, no terminal, execute os seguintes comandos para criar a estrutura de pasta com os arquivos necessários:
Depois de executar os comandos, clique no botão atualizar para conferir a pasta e os arquivos recém-criados.
Copie e cole o código a seguir em titanic/trainer/task.py. O código contém comentários que ajudarão a entender o arquivo:
from google.cloud import bigquery, bigquery_storage, storage
from sklearn.pipeline import make_pipeline, Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder, OrdinalEncoder
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
from sklearn.metrics import classification_report, f1_score
from typing import Union, List
import os, logging, json, pickle, argparse
import dask.dataframe as dd
import pandas as pd
import numpy as np
# seleção de atributos. A lista FEATURE define quais atributos os dados de treinamento devem ter
# e os tipos desses atributos. De acordo com o tipo, realizaremos uma engenharia de atributos diferente.
# Enumera todos os nomes das colunas para os atributos binários: 0,1 ou True,False ou Male,Female etc
BINARY_FEATURES = [
'sex']
# Enumera todos os nomes das colunas para os atributos numéricos
NUMERIC_FEATURES = [
'age',
'fare']
# Enumera todos os nomes das colunas para os atributos categóricos
CATEGORICAL_FEATURES = [
'pclass',
'embarked',
'home_dest',
'parch',
'sibsp']
ALL_COLUMNS = BINARY_FEATURES+NUMERIC_FEATURES+CATEGORICAL_FEATURES
# Define o nome da coluna para o rótulo
LABEL = 'survived'
# Define a posição do índice de cada atributo. Isso é necessário para processar uma matriz
# numpy (e não pandas), que não tem nomes de colunas.
BINARY_FEATURES_IDX = list(range(0,len(BINARY_FEATURES)))
NUMERIC_FEATURES_IDX = list(range(len(BINARY_FEATURES), len(BINARY_FEATURES)+len(NUMERIC_FEATURES)))
CATEGORICAL_FEATURES_IDX = list(range(len(BINARY_FEATURES+NUMERIC_FEATURES), len(ALL_COLUMNS)))
def load_data_from_gcs(data_gcs_path: str) -> pd.DataFrame:
'''
Loads data from Google Cloud Storage (GCS) to a dataframe
Parameters:
data_gcs_path (str): gs path for the location of the data. Wildcards are also supported. i.e gs://example_bucket/data/training-*.csv
Returns:
pandas.DataFrame: a dataframe with the data from GCP loaded
'''
# usando dask compatível com caracteres curinga para ler diversos arquivos. E com dd.read_csv().compute podemos criar um dataframe pandas
# Também vi que alguns valores para TotalCharges estão ausentes e isso gera confusão com relação a TotalCharges como o tipo de dados.
# para resolver esse problema, TotalCharges foi definido de maneira manual como objeto.
# Vamos corrigir depois essa anormalidade
logging.info("reading gs data: {}".format(data_gcs_path))
return dd.read_csv(data_gcs_path, dtype={'TotalCharges': 'object'}).compute()
def load_data_from_bq(bq_uri: str) -> pd.DataFrame:
'''
Loads data from BigQuery table (BQ) to a dataframe
Parameters:
bq_uri (str): bq table uri. i.e: example_project.example_dataset.example_table
Returns:
pandas.DataFrame: a dataframe with the data from GCP loaded
'''
if not bq_uri.startswith('bq://'):
raise Exception("uri is not a BQ uri. It should be bq://project_id.dataset.table")
logging.info("reading bq data: {}".format(bq_uri))
project,dataset,table = bq_uri.split(".")
bqclient = bigquery.Client(project=project[5:])
bqstorageclient = bigquery_storage.BigQueryReadClient()
query_string = """
SELECT * from {ds}.{tbl}
""".format(ds=dataset, tbl=table)
return (
bqclient.query(query_string)
.result()
.to_dataframe(bqstorage_client=bqstorageclient)
)
def clean_missing_numerics(df: pd.DataFrame, numeric_columns):
'''
removes invalid values in the numeric columns
Parameters:
df (pandas.DataFrame): The Pandas Dataframe to alter
numeric_columns (List[str]): List of column names that are numeric from the DataFrame
Returns:
pandas.DataFrame: a dataframe with the numeric columns fixed
'''
for n in numeric_columns:
df[n] = pd.to_numeric(df[n], errors='coerce')
df = df.fillna(df.mean())
return df
def data_selection(df: pd.DataFrame, selected_columns: List[str], label_column: str) -> (pd.DataFrame, pd.Series):
'''
From a dataframe it creates a new dataframe with only selected columns and returns it.
Additionally it splits the label column into a pandas Series.
Parameters:
df (pandas.DataFrame): The Pandas Dataframe to drop columns and extract label
selected_columns (List[str]): List of strings with the selected columns. i,e ['col_1', 'col_2', ..., 'col_n' ]
label_column (str): The name of the label column
Returns:
tuple(pandas.DataFrame, pandas.Series): Tuble with the new pandas DataFrame containing only selected columns and lablel pandas Series
'''
# Criamos uma série com o rótulo de previsão
labels = df[label_column].astype(int)
data = df.loc[:, selected_columns]
return data, labels
def pipeline_builder(params_svm: dict, bin_ftr_idx: List[int], num_ftr_idx: List[int], cat_ftr_idx: List[int]) -> Pipeline:
'''
Builds a sklearn pipeline with preprocessing and model configuration.
Preprocessing steps are:
* OrdinalEncoder - used for binary features
* StandardScaler - used for numerical features
* OneHotEncoder - used for categorical features
Model used is SVC
Parameters:
params_svm (dict): List of parameters for the sklearn.svm.SVC classifier
bin_ftr_idx (List[str]): List of ints that mark the column indexes with binary columns. i.e [0, 2, ... , X ]
num_ftr_idx (List[str]): List of ints that mark the column indexes with numerical columns. i.e [6, 3, ... , X ]
cat_ftr_idx (List[str]): List of ints that mark the column indexes with categorical columns. i.e [5, 10, ... , X ]
label_column (str): The name of the label column
Returns:
Pipeline: sklearn.pipelines.Pipeline with preprocessing and model training
'''
# Definição de uma etapa de pré-processamento para nosso pipeline.
# Especifica como os atributos serão transformados
preprocessor = ColumnTransformer(
transformers=[
('bin', OrdinalEncoder(), bin_ftr_idx),
('num', StandardScaler(), num_ftr_idx),
('cat', OneHotEncoder(handle_unknown='ignore'), cat_ftr_idx)], n_jobs=-1)
# Agora criamos um pipeline completo, para pré-processamento e treinamento.
# para treinamento, selecionamos um classificador SVM linear
clf = SVC()
clf.set_params(**params_svm)
return Pipeline(steps=[ ('preprocessor', preprocessor),
('classifier', clf)])
def train_pipeline(clf: Pipeline, X: Union[pd.DataFrame, np.ndarray], y: Union[pd.DataFrame, np.ndarray]) -> float:
'''
Trains a sklearn pipeline by fiting training data and labels and returns the accuracy f1 score
Parameters:
clf (sklearn.pipelines.Pipeline): the Pipeline object to fit the data
X: (pd.DataFrame OR np.ndarray): Training vectors of shape n_samples x n_features, where n_samples is the number of samples and n_features is the number of features.
y: (pd.DataFrame OR np.ndarray): Labels of shape n_samples. Order should mathc Training Vectors X
Returns:
score (float): Average F1 score from all cross validations
'''
# Execute durante a validação para conseguir pontuação de treinamento. Podemos usar essa pontuação para otimizar o treinamento
score = cross_val_score(clf, X, y, cv=10, n_jobs=-1).mean()
# Agora adaptamos todos os dados ao classificador.
clf.fit(X, y)
return score
def process_gcs_uri(uri: str) -> (str, str, str, str):
'''
Receives a Google Cloud Storage (GCS) uri and breaks it down to the scheme, bucket, path and file
Parameters:
uri (str): GCS uri
Returns:
scheme (str): uri scheme
bucket (str): uri bucket
path (str): uri path
file (str): uri file
'''
url_arr = uri.split("/")
if "." not in url_arr[-1]:
file = ""
else:
file = url_arr.pop()
scheme = url_arr[0]
bucket = url_arr[2]
path = "/".join(url_arr[3:])
path = path[:-1] if path.endswith("/") else path
return scheme, bucket, path, file
def pipeline_export_gcs(fitted_pipeline: Pipeline, model_dir: str) -> str:
'''
Exports trained pipeline to GCS
Parameters:
fitted_pipeline (sklearn.pipelines.Pipeline): the Pipeline object with data already fitted (trained pipeline object)
model_dir (str): GCS path to store the trained pipeline. i.e gs://example_bucket/training-job
Returns:
export_path (str): Model GCS location
'''
scheme, bucket, path, file = process_gcs_uri(model_dir)
if scheme != "gs:":
raise ValueError("URI scheme must be gs")
# Faça o upload do modelo para o GCS
b = storage.Client().bucket(bucket)
export_path = os.path.join(path, 'model.pkl')
blob = b.blob(export_path)
blob.upload_from_string(pickle.dumps(fitted_pipeline))
return scheme + "//" + os.path.join(bucket, export_path)
def prepare_report(cv_score: float, model_params: dict, classification_report: str, columns: List[str], example_data: np.ndarray) -> str:
'''
Prepares a training report in Text
Parameters:
cv_score (float): score of the training job during cross validation of training data
model_params (dict): dictonary containing the parameters the model was trained with
classification_report (str): Model classification report with test data
columns (List[str]): List of columns that where used in training.
example_data (np.array): Sample of data (2-3 rows are enough). This is used to include what the prediciton payload should look like for the model
Returns:
report (str): Full report in text
'''
buffer_example_data = '['
for r in example_data:
buffer_example_data+='['
for c in r:
if(isinstance(c,str)):
buffer_example_data+="'"+c+"', "
else:
buffer_example_data+=str(c)+", "
buffer_example_data= buffer_example_data[:-2]+"], \n"
buffer_example_data= buffer_example_data[:-3]+"]"
report = """
Training Job Report
Cross Validation Score: {cv_score}
Training Model Parameters: {model_params}
Test Data Classification Report:
{classification_report}
Example of data array for prediciton:
Order of columns:
{columns}
Example for clf.predict()
{predict_example}
Example of GCP API request body:
{{
"instances": {json_example}
}}
""".format(
cv_score=cv_score,
model_params=json.dumps(model_params),
classification_report=classification_report,
columns = columns,
predict_example = buffer_example_data,
json_example = json.dumps(example_data.tolist()))
return report
def report_export_gcs(report: str, report_dir: str) -> None:
'''
Exports training job report to GCS
Parameters:
report (str): Full report in text to sent to GCS
report_dir (str): GCS path to store the report model. i.e gs://example_bucket/training-job
Returns:
export_path (str): Report GCS location
'''
scheme, bucket, path, file = process_gcs_uri(report_dir)
if scheme != "gs:":
raise ValueError("URI scheme must be gs")
# Faça o upload do modelo para o GCS
b = storage.Client().bucket(bucket)
export_path = os.path.join(path, 'report.txt')
blob = b.blob(export_path)
blob.upload_from_string(report)
return scheme + "//" + os.path.join(bucket, export_path)
# Defina todos os argumentos de linha de comando aceitos por seu modelo para fins de treinamento
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# Input Arguments
parser.add_argument(
'--model_param_kernel',
help = 'SVC model parameter- kernel',
choices=['linear', 'poly', 'rbf', 'sigmoid', 'precomputed'],
type = str,
default = 'linear'
)
parser.add_argument(
'--model_param_degree',
help = 'SVC model parameter- Degree. Only applies for poly kernel',
type = int,
default = 3
)
parser.add_argument(
'--model_param_C',
help = 'SVC model parameter- C (regularization)',
type = float,
default = 1.0
)
parser.add_argument(
'--model_param_probability',
help = 'Whether to enable probability estimates',
type = bool,
default = True
)
'''
Vertex AI automatically populates a set of environment variables in the container that executes
your training job. Those variables include:
* AIP_MODEL_DIR - Directory selected as model dir
* AIP_DATA_FORMAT - Type of dataset selected for training (can be csv or bigquery)
Vertex AI will automatically split selected dataset into training, validation and testing
and 3 more environment variables will reflect the location of the data:
* AIP_TRAINING_DATA_URI - URI of Training data
* AIP_VALIDATION_DATA_URI - URI of Validation data
* AIP_TEST_DATA_URI - URI of Test data
Notice that those environment variables are default. If the user provides a value using CLI argument,
the environment variable will be ignored. If the user does not provide anything as CLI argument
the program will try and use the environment variables if those exist. Otherwise will leave empty.
'''
parser.add_argument(
'--model_dir',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_MODEL_DIR'] if 'AIP_MODEL_DIR' in os.environ else ""
)
parser.add_argument(
'--data_format',
choices=['csv', 'bigquery'],
help = 'format of data uri csv for gs:// paths and bigquery for project.dataset.table formats',
type = str,
default = os.environ['AIP_DATA_FORMAT'] if 'AIP_DATA_FORMAT' in os.environ else "csv"
)
parser.add_argument(
'--training_data_uri',
help = 'location of training data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_TRAINING_DATA_URI'] if 'AIP_TRAINING_DATA_URI' in os.environ else ""
)
parser.add_argument(
'--validation_data_uri',
help = 'location of validation data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_VALIDATION_DATA_URI'] if 'AIP_VALIDATION_DATA_URI' in os.environ else ""
)
parser.add_argument(
'--test_data_uri',
help = 'location of test data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_TEST_DATA_URI'] if 'AIP_TEST_DATA_URI' in os.environ else ""
)
parser.add_argument("-v", "--verbose", help="increase output verbosity",
action="store_true")
args = parser.parse_args()
arguments = args.__dict__
if args.verbose:
logging.basicConfig(level=logging.INFO)
logging.info('Model artifacts will be exported here: {}'.format(arguments['model_dir']))
logging.info('Data format: {}'.format(arguments["data_format"]))
logging.info('Training data uri: {}'.format(arguments['training_data_uri']) )
logging.info('Validation data uri: {}'.format(arguments['validation_data_uri']))
logging.info('Test data uri: {}'.format(arguments['test_data_uri']))
'''
We have 2 different ways to load our data to pandas. One is from Cloud Storage by loading csv files and
the other is by connecting to BigQuery. Vertex AI supports both and
here we created a code that depending on the dataset provided. We will select the appropriate loading method.
'''
logging.info('Loading {} data'.format(arguments["data_format"]))
if(arguments['data_format']=='csv'):
df_train = load_data_from_gcs(arguments['training_data_uri'])
df_test = load_data_from_bq(arguments['test_data_uri'])
df_valid = load_data_from_gcs(arguments['validation_data_uri'])
elif(arguments['data_format']=='bigquery'):
print(arguments['training_data_uri'])
df_train = load_data_from_bq(arguments['training_data_uri'])
df_test = load_data_from_bq(arguments['test_data_uri'])
df_valid = load_data_from_bq(arguments['validation_data_uri'])
else:
raise ValueError("Invalid data type ")
#Como vamos usar validação cruzada, teremos apenas um conjunto de treinamento e um único conjunto de teste.
# Vamos mesclar o teste com a validação para ter uma divisão de 80%-20%
df_test = pd.concat([df_test,df_valid])
logging.info('Defining model parameters')
model_params = dict()
model_params['kernel'] = arguments['model_param_kernel']
model_params['degree'] = arguments['model_param_degree']
model_params['C'] = arguments['model_param_C']
model_params['probability'] = arguments['model_param_probability']
df_train = clean_missing_numerics(df_train, NUMERIC_FEATURES)
df_test = clean_missing_numerics(df_test, NUMERIC_FEATURES)
logging.info('Running feature selection')
X_train, y_train = data_selection(df_train, ALL_COLUMNS, LABEL)
X_test, y_test = data_selection(df_test, ALL_COLUMNS, LABEL)
logging.info('Training pipelines in CV')
y_train = y_train.astype('int')
y_test = y_test.astype('int')
clf = pipeline_builder(model_params, BINARY_FEATURES_IDX, NUMERIC_FEATURES_IDX, CATEGORICAL_FEATURES_IDX)
cv_score = train_pipeline(clf, X_train, y_train)
logging.info('Export trained pipeline and report')
pipeline_export_gcs(clf, arguments['model_dir'])
y_pred = clf.predict(X_test)
test_score = f1_score(y_test, y_pred, average='weighted')
logging.info('f1score: '+ str(test_score))
report = prepare_report(cv_score,
model_params,
classification_report(y_test,y_pred),
ALL_COLUMNS,
X_test.to_numpy()[0:2])
report_export_gcs(report, arguments['model_dir'])
logging.info('Training job completed. Exiting...')
Pressione Ctrl+S para salvar o arquivo.
Crie seu pacote
Agora vamos criar seu pacote para que você possa usá-lo com o serviço de treinamento.
Copie e cole o código abaixo em titanic/setup.py
from setuptools import find_packages
from setuptools import setup
REQUIRED_PACKAGES = [
'gcsfs==0.7.1',
'dask[dataframe]==2021.2.0',
'google-cloud-bigquery-storage==1.0.0',
'six==1.15.0'
]
setup(
name='trainer',
version='0.1',
install_requires=REQUIRED_PACKAGES,
packages=find_packages(), # Automatically find packages within this directory or below.
include_package_data=True, # if packages include any data files, those will be packed together.
description='Classification training titanic survivors prediction model'
)
Pressione Ctrl+S para salvar o arquivo.
Volte ao terminal e verifique se é possível treinar um modelo usando task.py.
Primeiro crie as seguintes variáveis de ambiente, mas lembre-se de garantir que você selecionou o projeto do GCP correto no console:
PROJECT_ID vai ser definido como o ID do projeto selecionado
BUCKET_NAME será o PROJECT_ID e "-bucket" anexado a ele
export REGION="{{{project_0.default_region|Region}}}"
export PROJECT_ID=$(gcloud config list --format 'value(core.project)')
export BUCKET_NAME=$PROJECT_ID"-bucket"
Crie um bucket a fim de exportar para ele o modelo treinado:
gsutil mb -l $REGION "gs://"$BUCKET_NAME
Agora execute os comandos a seguir. Você está usando todos os seus dados de treinamento para fazer testes. O mesmo conjunto de dados é usado para teste, validação e treinamento. Aqui é importante garantir que o código seja executado e que esteja livre de bugs. Na realidade, é melhor que você use diferentes dados de teste e validação. Deixe que o serviço de treinamento na Vertex AI lide com isso.
Primeiro instale as bibliotecas necessárias.
cd /home/jupyter/titanic
pip install setuptools
python setup.py install
Observação: é possível ignorar a mensagem error: google-auth 2.3.3 is installed but google-auth<2.0dev,>=1.25.0 is required by {'google-api-core'} porque ela não afeta a funcionalidade do laboratório.
Agora execute o código de treinamento para verificar se a execução ocorre sem problemas:
Se o código for executado com sucesso, serão exibidos os logs INFO impressos. As duas linhas indicam a pontuação f1, que deve estar em torno de 0,85, e a última linha indica que o trabalho de treinamento foi concluído com sucesso:
Nesta seção, você vai treinar um modelo na Vertex AI. Para isso, vamos usar a GUI. Há também uma forma programática de fazer isso usando um SDK do Python. No entanto, usar a GUI vai ajudar você a entender melhor o processo.
No console do Google Cloud, acesse Vertex AI > Treinamento.
Selecione a região como .
Clique em Treinar novo modelo.
Método de treinamento
Nesta etapa, selecione o conjunto de dados e defina o objetivo para o trabalho de treinamento.
Conjunto de dados: o conjunto de dados que você criou há algumas etapas. O nome deve ser titanic.
Objetivo: o modelo prevê a probabilidade de um indivíduo sobreviver à tragédia do Titanic. Isso é um problema de Classificação.
Treinamento personalizado: use seu pacote de treinamento personalizado.
Clique em Continuar.
Detalhes do modelo
Agora defina o nome do modelo.
O nome padrão deve ser o nome do conjunto de dados e um carimbo de data/hora. Não modifique esse nome.
Ao clicar em Opções avançadas, você vê a opção para definir a divisão dos dados em conjuntos de treinamento, teste e validação. A atribuição aleatória vai dividir os dados aleatoriamente entre treinamento, teste e validação. Isso parece uma boa opção.
Clique em Continuar.
Contêiner de treinamento
Defina seu ambiente de treinamento.
Contêiner pré-criado: o Google Cloud oferece um conjunto de contêineres pré-criados que facilitam o treinamento dos seus modelos. Esses contêineres dão suporte para estruturas como Scikit-learn, TensorFlow e XGBoost. Caso seu trabalho de treinamento esteja usando algo exótico, você vai precisar preparar e fornecer um contêiner para treinamento (contêiner personalizado). Seu modelo é baseado no Scikit-learn, e já existe um contêiner pré-criado.
Framework do modelo: Scikit-learn. Essa é a biblioteca que você usou para o treinamento do modelo.
Versão do framework do modelo: seu código é compatível com 0.23.
Localização do pacote: você pode navegar até o local do seu pacote de treinamento. Esse é o local em que você fez o upload do training-0.1.tar.gz. Se você tiver seguido as etapas anteriores corretamente, o local deverá ser gs://YOUR-BUCKET-NAME/titanic/dist/trainer-0.1.tar.gz e YOUR-BUCKET-NAME é o nome do bucket que você usou na seção Criar seu pacote.
Módulo do Python: o módulo do Python que você criou nos Notebooks, que corresponderá à pasta que contém seu código/módulo de treinamento e o nome do arquivo de entrada. Ele deve ser trainer.task
Projeto do BigQuery para exportar dados: na Etapa 1, você escolheu o conjunto de dados e definiu uma divisão automática. Um novo conjunto de dados e tabelas para conjuntos de treinamento/teste/validação vai ser criado no projeto selecionado.
Insira o mesmo ID do projeto que você está executando para o laboratório.
Além disso, os URIs dos conjuntos de dados de treinamento/teste/validação vão ser definidos como variáveis de ambiente no contêiner de treinamento, para que você possa usar essas variáveis automaticamente para carregar seus dados. Os nomes das variáveis de ambiente para os conjuntos de dados vão ser AIP_TRAINING_DATA_URI, AIP_TEST_DATA_URI e AIP_VALIDATION_DATA_URI. Uma variável adicional é AIP_DATA_FORMAT que vai ser csv ou bigquery, dependendo do tipo do conjunto de dados selecionado na Etapa 1.
Você já criou essa lógica em task.py. Observe este código de exemplo (tirado do task.py):
...
parser.add_argument( '--training_data_uri ',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_TRAINING_DATA_URI'] if 'AIP_TRAINING_DATA_URI' in os.environ else "" )
...
Diretório de saída do modelo: local para qual o modelo vai ser exportado. Esta vai ser uma variável de ambiente no contêiner de treinamento chamada AIP_MODEL_DIR. No task.py, há parâmetros de entrada para capturar isso:
...
parser.add_argument( '--model_dir',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_MODEL_DIR'] if 'AIP_MODEL_DIR' in os.environ else "" )
...
Você pode usar a variável de ambiente para saber para onde exportar os artefatos do trabalho de treinamento. Vamos selecionar: gs://YOUR-BUCKET-NAME/titanic/
Clique em Continuar.
Ajuste de hiperparâmetros
A seção de ajuste de hiperparâmetros permite definir um conjunto de parâmetros de modelo com os quais você gostaria de ajustar seu modelo. Vamos explorar valores diferentes para produzir o modelo com os melhores parâmetros. Você não implementou no seu código a funcionalidade do ajustador de hiperparâmetros. São apenas algumas linhas de código (cerca de cinco linhas), mas você não quer acrescentar essa complexidade agora.
Vamos pular essa etapa. Clique em Continuar.
Computação e preços
Onde você quer que seu trabalho de treinamento seja executado e que tipo de servidor quer usar? Seu processo de treinamento de modelo não está à procura de recursos. Você conseguiu executar o trabalho de treinamento dentro de uma instância de notebook relativamente pequena, e a execução termina bem rápido.
Com isso em mente, escolha:
Região:
Tipo de máquina: n1-standard-4
Clique em Continuar.
Contêiner de previsão
Nesta etapa, você pode decidir se quer apenas treinar o modelo ou também adicionar configurações para o serviço de previsão usado para produzir seu modelo.
Você vai usar um contêiner pré-criado neste laboratório. No entanto, tenha em mente que a Vertex AI oferece algumas opções para disponibilização de modelos:
Contêiner sem previsão: apenas treine o modelo e depois verifique como colocá-lo em produção.
Contêiner pré-criado: treine o modelo e defina o contêiner pré-criado que vai ser usado para implantação.
Contêiner personalizado: treine o modelo e defina um contêiner personalizado que vai ser usado para implantação.
Recomendamos que escolha um contêiner pré-criado, porque o Google Cloud já oferece um contêiner Scikit-Learn. Você vai implantar o modelo depois de concluir o trabalho de treinamento.
Framework do modelo: scikit-learn
Versão do framework do modelo: 0.23
Diretório do modelo: gs://YOUR-BUCKET-NAME/titanic/. Ele deve ser igual ao diretório de saída do modelo definido na etapa 3.
Clique em Iniciar treinamento.
O novo trabalho de treinamento vai ser mostrado na guia Pipeline de treinamento. O treinamento levará em torno de 15 minutos.
Tarefa 5: avaliação de modelo
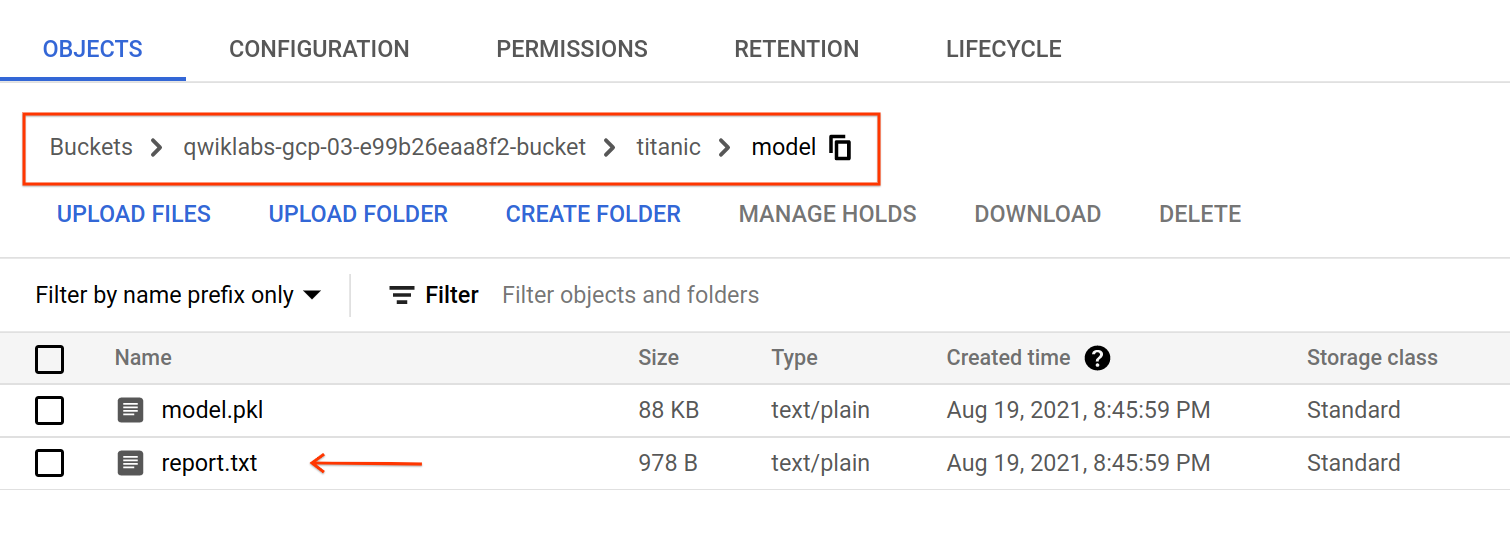
Depois da conclusão do trabalho de treinamento, artefatos vão ser exportados em gs://YOUR-BUCKET-NAME/titanic/model. Você pode inspecionar o arquivo report.txt que contém métricas de avaliação e relatório de classificação do modelo.
Tarefa 6: Implantação do modelo
No console do Google Cloud, no menu de navegação, clique em Vertex AI > Treinamento.
Depois da conclusão do trabalho de treinamento do modelo, selecione o modelo de treinamento e implante-o em um endpoint.
Acesse a guia IMPLANTAR E TESTAR e clique em IMPLANTAR NO ENDPOINT.
No pop-up, é possível definir os recursos necessários para a implantação do modelo:
Nome do endpoint: URL do endpoint onde o modelo é exibido. Um nome razoável para ele é titanic-endpoint. Clique em Continuar.
Divisão de tráfego: define a porcentagem de tráfego que você quer direcionar para este modelo. Um endpoint pode ter múltiplos modelos e você pode decidir como dividir o tráfego entre eles. Neste caso você está implantando um único modelo. Logo, o tráfego precisa ser de 100 por cento.
Número mínimo de nós de computação: o número mínimo de nós necessário para exibir previsões de modelos. Comece com 1. Além disso, o serviço de previsão vai ser automaticamente escalonado se houver tráfego
Número máximo de nós de computação: no caso de escalonamento automático, esta variável define o limite superior de nós. Isso ajuda na proteção contra gastos indesejados que o escalonamento automático pode acarretar. Defina esta variável como 2.
Tipo de máquina: o Google Cloud oferece um conjunto de tipos de máquina nas quais você pode implantar seu modelo. Cada máquina tem uma especificação própria de memória e vCPU. Seu modelo é simples, e exibir em uma instância n1-standard-4 é suficiente.
Clique em Concluído e, em seguida, em Implantar.
Tarefa 7: Previsão do modelo
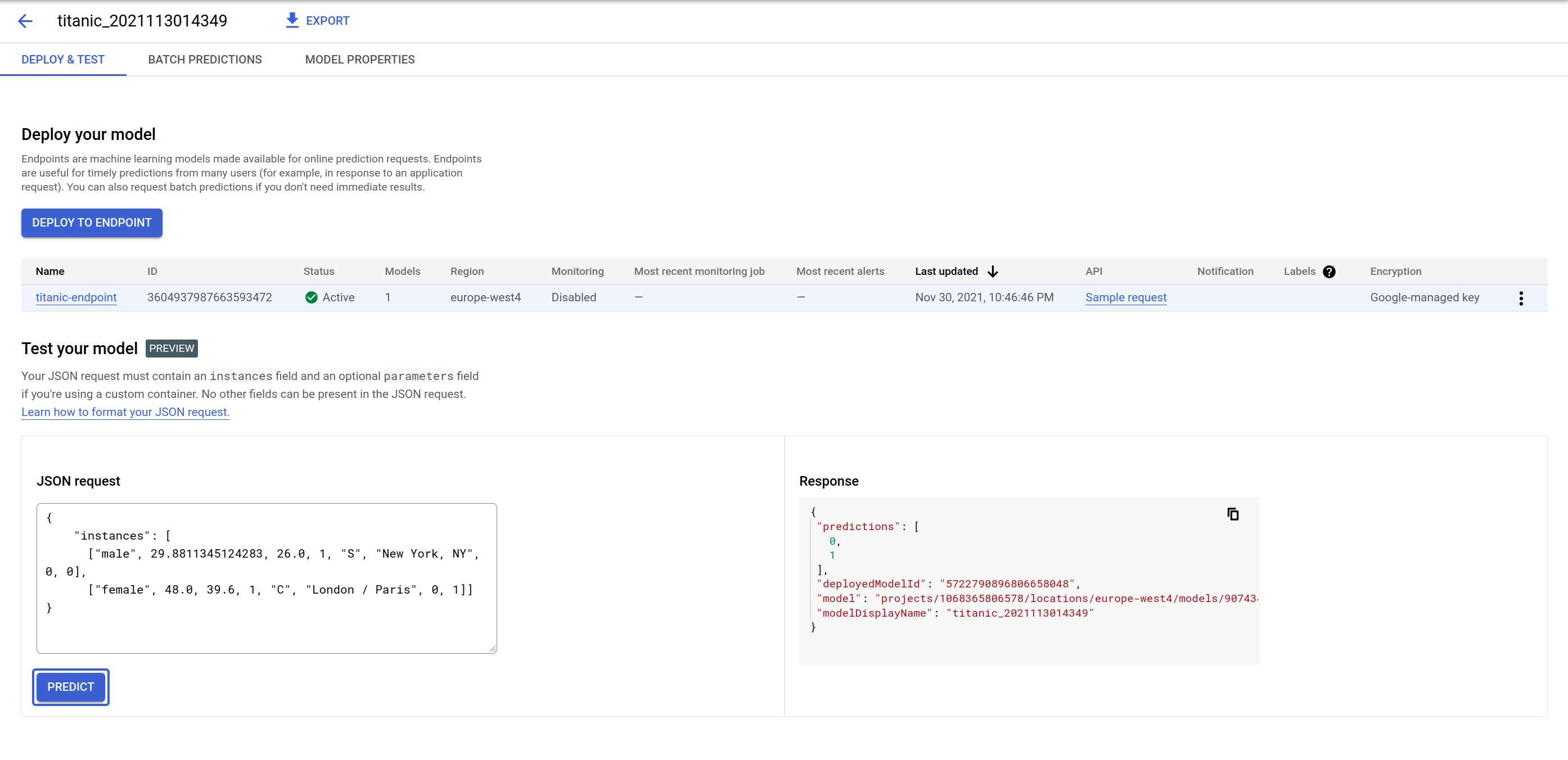
Em Implantar o modelo, teste o endpoint de previsão de modelo. A GUI fornece um formulário para enviar uma payload de solicitação JSON e responde com as previsões, bem como o ID do modelo usado para a previsão. Isso porque você pode implantar mais de um modelo em um endpoint e dividir o tráfego.
Experimente o payload abaixo e modifique alguns dos valores para conferir como as previsões mudam: a sequência dos recursos de entrada é ['sex', 'age', 'fare', 'pclass', 'embarked', 'home_dest', 'parch', 'sibsp'].
O endpoint responde com uma lista de zero ou um com a mesma ordem que sua entrada. 0 significa que é mais provável que o indivíduo não sobreviva ao acidente do Titanic e 1 significa que o indivíduo provavelmente vai sobreviver.
Tarefa 8: limpeza
Parabéns! Você criou um conjunto de dados, empacotou seu código de treinamento e executou um trabalho de treinamento personalizado usando a Vertex AI. Além disso, você implantou o modelo treinado e enviou alguns dados para previsões.
Como você não precisa dos recursos criados, é uma boa ideia excluí-los para evitar cobranças indesejadas.
Navegue até a página de Conjuntos de dados no console, clique nos três pontos do conjunto de dados que você quer excluir e clique em Excluir conjunto de dados. Em seguida, clique em Excluir para confirmar a ação.
Acesse a página Workbench no console, selecione apenas o notebook que você quer excluir e clique em Excluir no menu superior. Em seguida, clique em Excluir para confirmar a ação.
Para excluir o endpoint que implantou, na seção Endpoints do console da Vertex AI, clique no endpoint e depois clique no menu flutuante () e selecione Cancelar a implantação do modelo do endpoint. Feito isso, clique em Cancelar a implantação.
Para remover o endpoint, clique no menu flutuante () e, em seguida, em Excluir endpoint. Depois clique em Confirmar.
Navegue até a página Modelos no console, clique nos três pontos () no modelo que quer excluir e depois clique em Excluir modelo. Em seguida, clique em Excluir.
Para excluir o bucket do Cloud Storage, na página do Cloud Storage, selecione seu bucket e depois clique em Excluir. Confirme a exclusão digitando DELETE e depois clique em Excluir.
Para excluir o conjunto de dados do BigQuery, siga as etapas abaixo:
Navegue até o console do BigQuery.
No painel Explorador, clique no ícone de Conferir ações próximo ao seu conjunto de dados. Clique em Excluir.
Na caixa de diálogo "Excluir conjunto de dados", confirme o comando de exclusão digitando excluir e depois clique em Excluir.
Finalize o laboratório
Após terminar seu laboratório, clique em End Lab. O Qwiklabs removerá os recursos usados e limpará a conta para você.
Você poderá avaliar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Submit.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Support.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Neste laboratório, é possível usar Vertex AI para treinar e implantar um modelo de ML.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 120 minutos
·
Tempo para conclusão: 120 minutos
 ) ao lado do ID do projeto e selecione Criar conjunto de dados.
) ao lado do ID do projeto e selecione Criar conjunto de dados.