概要
このラボでは、Vertex AI を使用して ML モデルのトレーニングとデプロイを行うことができます。ML を十分に理解している方を対象としていますが、このトレーニング用の ML のコードは用意されています。作成および管理を行うデータセットと、Scikit-learn モデルをトレーニングするためのカスタムモデルを使用します。最後に、トレーニングしたモデルをデプロイし、オンライン予測を取得します。このデモで使用するデータセットは、タイタニック データセット(タイタニック号の乗客者の生存状況に関するデータセット)です。
目標
- 表形式データ用のデータセットを作成する。
- Notebooks を使用して、カスタムコードを含むトレーニング パッケージを作成する。
- トレーニングしたモデルをデプロイし、オンライン予測を取得する。
設定
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
-
Qwiklabs にシークレット ウィンドウでログインします。
-
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
-
準備ができたら、[ラボを開始] をクリックします。
-
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
-
[Google Console を開く] をクリックします。
-
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
-
利用規約に同意し、再設定用のリソースページをスキップします。
タスク 1. 環境の設定
Vertex AI API を有効にする
データセットを作成する
-
BigQuery データセットを作成するには、Google Cloud コンソールの BigQuery に移動します。
-
コンソール ページの上部で、正しいプロジェクトが選択されていることを確認します。
-
エクスプローラ パネルで、プロジェクト ID の横に表示される [アクションを表示](![[アクションを表示] アイコン](https://cdn.qwiklabs.com/2ufrDePg5inKfodUoT2Kib4oE7II7emYn%2BypCC85FjQ%3D) )をクリックし、[データセットを作成] を選択します。
)をクリックし、[データセットを作成] を選択します。
ポップアップが表示されます。
- [データセット ID] に「titanic」、[データのロケーション] > [リージョン] に「」と入力し、[データセットを作成] をクリックします。
これでデータセットの作成が完了しました。
テーブルを作成する
データを読み込むにはテーブルが必要です。
- まず、タイタニック データセットをローカルにダウンロードします。
注: シークレット モードでダウンロードできない場合は、通常のウィンドウを使って Titanic dataset(タイタニック データセット)をダウンロードしてください。
- ダウンロードしたデータセットの名前を titanic_toy.csv に変更します。
その後、UI で次の操作を行います。
-
前のステップで作成した titanic データセットを開きます(データセットの横のアクションを表示()をクリックし、[開く] を選択します)。
-
[テーブルを作成] をクリックし、以下を指定します。
- テーブルの作成元: アップロード
- ファイルを選択: ダウンロードしたタイタニック データセットを使用する
- ファイル形式: CSV
- テーブル名: survivors
- 自動検出: [スキーマ] の [自動検出] チェックボックスをオンにする
-
[テーブルを作成] をクリックします。
-
survivors(生存者)の横にある「アクションを表示」アイコンをクリックし、[ID をコピー] を選択します。ラボで後から使用できるように、コピーしたテーブル ID を保存しておきます。
これで、テーブルの作成と、そのテーブルへのタイタニック データセットの入力が完了し、テーブルの内容の参照、クエリの実行、データの分析を行えるようになりました。
タスク 2. データセットの作成
Vertex AI のデータセットを使用して、ML ワークロード用のデータセットを作成できます。構造化データ(CSV ファイルまたは BigQuery テーブル)用または非構造化データ(画像やテキストなど)用のデータセットを作成できます。Vertex AI のデータセットは元のデータを参照しているだけであり、データの複製が行われるわけではありませんので注意してください。
ML データセットを作成する
- Google Cloud コンソールのナビゲーション メニューで、[Vertex AI] > [データセット] を選択します。
-
[] を選択して [作成] をクリックします。
-
データセットに名前を付けます(titanic など)。
画像、テキスト、動画、表形式データのデータセットを作成できます。
-
タイタニック データセットは表形式なので、[表形式] タブをクリックします。
-
リージョンの選択で [] を選択し、[作成] をクリックします。
この段階ではプレースホルダが作成されただけです。データソースにはまだ接続されておらず、次のステップで接続を行います。
データソースを選択する
タイタニック データセットはすでに BigQuery に読み込まれているため、ML データセットを BigQuery テーブルに接続できます。
- [テーブルまたはビューを BigQuery から選択] をクリックします。
- 前の手順でコピーしたテーブル ID を [参照] フィールドに貼り付けます。
- データセットを選択したら、[続行] をクリックします。
統計情報を生成する
[分析] タブで、データに関する統計情報を生成できます。これにより、データの概要の把握、分布や欠損値などの確認をすばやく行えます。
- 統計分析を実行するには、[統計情報を生成] をクリックします。実行には数分かかるため、ラボを続行して、しばらくしてから結果を確認しても結構です。
![[分析] タブページに表示された統計情報](https://cdn.qwiklabs.com/E7T%2B5cZ%2Bvt2BmsVYbFbG%2BHoMfZwc8M2VlL1R6qjVXxY%3D)
タスク 3. Workbench を使用したカスタム トレーニング パッケージ
移植可能なアセットになるように、コードはパッケージ化およびパラメータ化することをおすすめします。
このセクションでは、Vertex AI Workbench を使用して、カスタムコードでトレーニング パッケージを作成します。このサービスを使用する場合の基本的なステップは、Python ソース配布(配布パッケージ)を作成できるようにすることです。これは、配布パッケージ内にフォルダやファイルを作成する程度の処理です。次のセクションでは、パッケージの構造を説明します。
アプリケーションの構造
Python パッケージの基本的な構造は、次の図のようになります。

これらのフォルダやファイルの役割を見ていきましょう。
-
titanic-package: 作業ディレクトリ。このフォルダ内に、タイタニック号生存者の分類器に関連するパッケージやコードを配置します。
-
setup.py: 配布パッケージのビルド方法を指定する設定ファイル。パッケージ名やバージョンに加え、トレーニング ジョブに必要ではあるもののデフォルトでは GCP のビルド済みトレーニング コンテナに含まれていないその他のパッケージなどの情報が含まれます。
-
trainer: トレーニング コードが含まれるフォルダ。これは Python パッケージでもあります。フォルダ内に空の
__init__.py ファイルが存在することでパッケージとなります。
-
__init__.py: __init__.py という名前の空のファイル。このファイルが存在するフォルダはパッケージとなります。
-
task.py: パッケージ モジュール。ここがコードのエントリ ポイントとなります。また、モデル トレーニング用の CLI のパラメータもここで受け取ります。このモジュールにトレーニング コードを含めたり、パッケージ内に追加のモジュールを作成したりできます。これを実際に行うかどうかは、コードをどのような構造にするか次第で、自由に決めることができます。
これで、構造について説明しました。なお、パッケージやモジュールの名前を「trainer」や「task.py」にする必要はありません。本ラボでこのような命名規則に従っているのは、オンライン ドキュメントとの整合性を考慮してのことであり、実際には適切な名前を自由に設定できます。
ノートブック インスタンスを作成する
ここで、ノートブック インスタンスを作成し、カスタムモデルのトレーニングを行ってみましょう。
-
Google Cloud コンソールのナビゲーション メニューで、[Vertex AI] > [Workbench] をクリックします。
-
ノートブック インスタンスのページで [新規作成] をクリックし、[Python 3](Scikit-learn を含む)を使用してインスタンスを開始します。分類器には Scikit-learn モデルを使用します。
ポップアップが表示されます。ここでは、ノートブック インスタンスが作成されるリージョンや必要な演算能力などの設定を変更できます。
- 今回は、大量のデータを処理するわけではなく、開発用にインスタンスが必要であるだけなので、どの設定も変更せずにそのまま [作成] をクリックします。
このインスタンスはわずか数分で稼働します。
-
インスタンスの準備ができたら、[Jupyterlab を開く] を選択します。
-
「Build Recommended」というポップアップが表示されたら、[Build] をクリックします。ビルドがエラーになった場合は無視してかまいません。
パッケージを作成する
ノートブックが稼働したので、トレーニング アセットの構築を開始できます。
このタスクはターミナルを使ったほうが簡単です。
-
ランチャーで [Terminal] をクリックして、新しいターミナル セッションを作成します。
-
ターミナルで、以下のコマンドを実行して、必要なファイルを含むフォルダ構造を作成します。
mkdir -p /home/jupyter/titanic/trainer
touch /home/jupyter/titanic/setup.py /home/jupyter/titanic/trainer/__init__.py /home/jupyter/titanic/trainer/task.py
-
コマンドを実行したら、更新ボタンをクリックして、新たに作成されたフォルダとファイルを確認します。
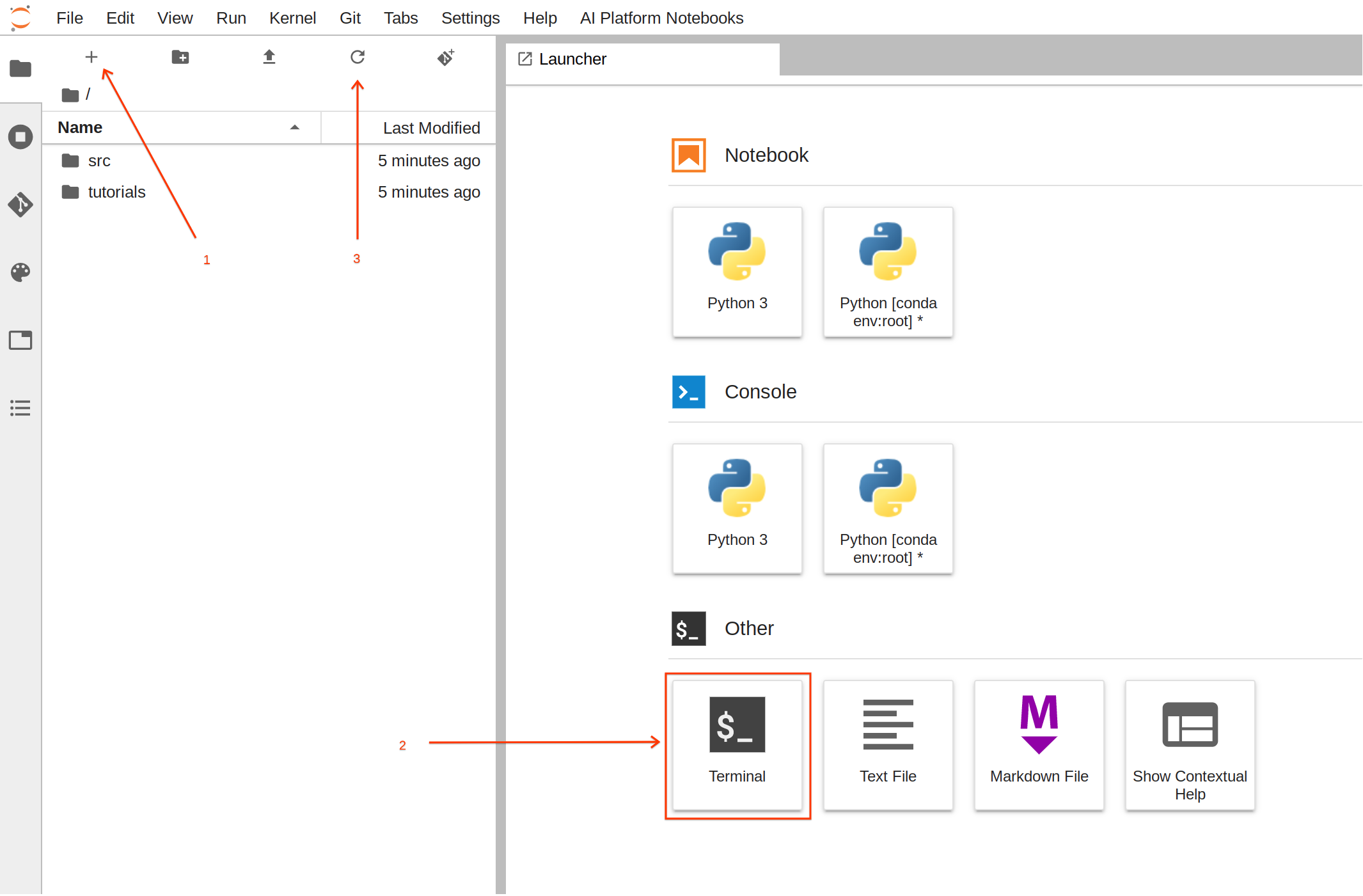
- 以下のコードをコピーして titanic/trainer/task.py に貼り付けます。このコードにはコメントが含まれているので、少し時間をかけてファイルの内容に目を通すと理解が深まります。
from google.cloud import bigquery, bigquery_storage, storage
from sklearn.pipeline import make_pipeline, Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder, OrdinalEncoder
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
from sklearn.metrics import classification_report, f1_score
from typing import Union, List
import os, logging, json, pickle, argparse
import dask.dataframe as dd
import pandas as pd
import numpy as np
# 特徴の選択。特徴のリストは、トレーニング データのうちどの特徴量が必要であるか、また
# これらの特徴の種類も定義している。その種類に応じて、異なる特徴量エンジニアリングを実施する。
# バイナリ特徴(0 / 1、True / False、Male / Female など)の列名すべてのリスト
BINARY_FEATURES = [
'sex']
# 数値特徴の列名すべてのリスト
NUMERIC_FEATURES = [
'age',
'fare']
# カテゴリ特徴の列名すべてのリスト
CATEGORICAL_FEATURES = [
'pclass',
'embarked',
'home_dest',
'parch',
'sibsp']
ALL_COLUMNS = BINARY_FEATURES+NUMERIC_FEATURES+CATEGORICAL_FEATURES
# ラベルの列名を定義
LABEL = 'survived'
# 各特徴のインデックス位置を定義。これは、列の名前を持たない
# (pandas ではなく)numpy 配列を処理するために必要。
BINARY_FEATURES_IDX = list(range(0,len(BINARY_FEATURES)))
NUMERIC_FEATURES_IDX = list(range(len(BINARY_FEATURES), len(BINARY_FEATURES)+len(NUMERIC_FEATURES)))
CATEGORICAL_FEATURES_IDX = list(range(len(BINARY_FEATURES+NUMERIC_FEATURES), len(ALL_COLUMNS)))
def load_data_from_gcs(data_gcs_path: str) -> pd.DataFrame:
'''
Google Cloud Storage(GCS)から DataFrame にデータを読み込む
パラメータ:
data_gcs_path (str): データの場所を示す gs パス。ワイルドカードもサポートしている(gs://example_bucket/data/training-*.csv など)
戻り値:
pandas.DataFrame: GCP から読み込まれたデータを持つデータフレーム
'''
# ワイルドカードをサポートしている Dask を使用して複数のファイルを読み取る。その後、dd.read_csv().compute によって pandas データフレームを作成する
# また TotalCharges のいくつかの値が欠損していることが判明、これによってデータ型としての TotalCharges に関して混乱が生じる。
# この問題を解決するために TotalCharges をオブジェクトとして手動で定義する。
# この異常は後で修正
logging.info("reading gs data: {}".format(data_gcs_path))
return dd.read_csv(data_gcs_path, dtype={'TotalCharges': 'object'}).compute()
def load_data_from_bq(bq_uri: str) -> pd.DataFrame:
'''
BigQuery テーブル(BQ)からデータをデータフレームに読み込む
パラメータ:
bq_uri (str): bq テーブルの URI(example_project.example_dataset.example_table など)
戻り値:
pandas.DataFrame: GCP から読み込まれたデータを持つデータフレーム
'''
if not bq_uri.startswith('bq://'):
raise Exception("uri is not a BQ uri. It should be bq://project_id.dataset.table")
logging.info("reading bq data: {}".format(bq_uri))
project,dataset,table = bq_uri.split(".")
bqclient = bigquery.Client(project=project[5:])
bqstorageclient = bigquery_storage.BigQueryReadClient()
query_string = """
SELECT * from {ds}.{tbl}
""".format(ds=dataset, tbl=table)
return (
bqclient.query(query_string)
.result()
.to_dataframe(bqstorage_client=bqstorageclient)
)
def clean_missing_numerics(df: pd.DataFrame, numeric_columns):
'''
数値列内にある無効な値を削除する
パラメータ:
df (pandas.DataFrame): 変更する Pandas データフレーム
numeric_columns (List[str]): データフレームに含まれている数値である列の名前のリスト
戻り値:
pandas.DataFrame: 数値の列が修正されたデータフレーム
'''
for n in numeric_columns:
df[n] = pd.to_numeric(df[n], errors='coerce')
df = df.fillna(df.mean())
return df
def data_selection(df: pd.DataFrame, selected_columns: List[str], label_column: str) -> (pd.DataFrame, pd.Series):
'''
データフレームから選択した列だけで別の新しいデータフレームを作成して返す。
さらに、ラベル列を分割して pandas Series に変換する。
パラメータ:
df (pandas.DataFrame): 列を削除してラベルを抽出するための Pandas データフレーム
selected_columns (List[str]): 選択した列を表す文字列のリスト(['col_1', 'col_2', ..., 'col_n'] など)
label_column (str): ラベル列の名前
戻り値:
tuple(pandas.DataFrame, pandas.Series): 選択した列だけを含む新しい pandas データフレームと pandas Series のラベルを持つタプル
'''
# 予測ラベルを持つ系列を作成
labels = df[label_column].astype(int)
data = df.loc[:, selected_columns]
return data, labels
def pipeline_builder(params_svm: dict, bin_ftr_idx: List[int], num_ftr_idx: List[int], cat_ftr_idx: List[int]) -> Pipeline:
'''
前処理とモデルの構成を含む sklearn パイプラインをビルドする。
前処理の手順は次のとおり:
* OrdinalEncoder - バイナリ特徴用
* StandardScaler - 数値特徴用
* OneHotEncoder - カテゴリ特徴用
使用するモデルは SVC
パラメータ:
params_svm (dict): sklearn.svm.SVC 分類器のパラメータのリスト
bin_ftr_idx (List[str]): バイナリ列に対する列インデックスを示す整数のリスト([0, 2, ... , X ] など)
num_ftr_idx (List[str]): 数値列に対する列インデックスを示す整数のリスト([6, 3, ... , X ] など)
cat_ftr_idx (List[str]): カテゴリ列に対する列インデックスを示す整数のリスト([5, 10, ... , X ] など)
label_column (str): ラベル列の名前
戻り値:
Pipeline: 前処理およびモデル トレーニングを含む sklearn.pipelines.Pipeline
'''
# パイプラインでの前処理の手順を定義 # 特徴がどのように変換されるのかを指定
preprocessor = ColumnTransformer(
transformers=[
('bin', OrdinalEncoder(), bin_ftr_idx),
('num', StandardScaler(), num_ftr_idx),
('cat', OneHotEncoder(handle_unknown='ignore'), cat_ftr_idx)], n_jobs=-1)
# 完全なパイプラインを作成(前処理およびトレーニング用)
# トレーニングには線形 SVM 分類器を選択
clf = SVC()
clf.set_params(**params_svm)
return Pipeline(steps=[ ('preprocessor', preprocessor),
('classifier', clf)])
def train_pipeline(clf: Pipeline, X: Union[pd.DataFrame, np.ndarray], y: Union[pd.DataFrame, np.ndarray]) -> float:
'''
トレーニング データとラベルを当てはめて sklearn パイプをトレーニングし、精度の f1 スコアを返す
パラメータ:
clf (sklearn.pipelines.Pipeline): データに当てはめる Pipeline オブジェクト
X: (pd.DataFrame OR np.ndarray): シェイプが n_samples x n_features のトレーニング ベクトル(n_samples はサンプルの数、n_features は特徴の数)
y: (pd.DataFrame OR np.ndarray): シェイプが n_samples のラベル。順序はトレーニング ベクトル X と一致している必要がある
戻り値:
score (float): すべての交差検証の平均 F1 スコア
'''
# 交差検証を実行してトレーニング スコアを取得する。このスコアはトレーニングの最適化に使用可能
score = cross_val_score(clf, X, y, cv=10, n_jobs=-1).mean()
# すべてのデータを分類器に当てはめる
clf.fit(X, y)
return score
def process_gcs_uri(uri: str) -> (str, str, str, str):
'''
Google Cloud Storage(GCS)の URI を受け取り、スキーム、バケット、パス、ファイルに分割する
パラメータ:
uri (str): GCS の URI
戻り値:
scheme (str): URI のスキーム
bucket (str): URI のバケット
path (str): URI のパス
file (str): URI のファイル
'''
url_arr = uri.split("/")
if "." not in url_arr[-1]:
file = ""
else:
file = url_arr.pop()
scheme = url_arr[0]
bucket = url_arr[2]
path = "/".join(url_arr[3:])
path = path[:-1] if path.endswith("/") else path
return scheme, bucket, path, file
def pipeline_export_gcs(fitted_pipeline: Pipeline, model_dir: str) -> str:
'''
トレーニングされたパイプラインを GCS にエクスポートする
パラメータ:
fitted_pipeline (sklearn.pipelines.Pipeline): すでにデータが当てはめられた Pipeline オブジェクト(トレーニング済みのパイプライン オブジェクト)
model_dir (str): トレーニング済みパイプラインを保存する GCS パス(gs://example_bucket/training-job など)
戻り値:
export_path (str): モデルの GCS ロケーション
'''
scheme, bucket, path, file = process_gcs_uri(model_dir)
if scheme != "gs:":
raise ValueError("URI scheme must be gs")
# モデルを GCS にアップロード
b = storage.Client().bucket(bucket)
export_path = os.path.join(path, 'model.pkl')
blob = b.blob(export_path)
blob.upload_from_string(pickle.dumps(fitted_pipeline))
return scheme + "//" + os.path.join(bucket, export_path)
def prepare_report(cv_score: float, model_params: dict, classification_report: str, columns: List[str], example_data: np.ndarray) -> str:
'''
トレーニング レポートをテキストで用意する
パラメータ:
cv_score (float): トレーニング データの交差検証中のトレーニング ジョブのスコア
model_params (dict): モデルのトレーニングに使用したパラメータが含まれている辞書
classification_report (str): モデルによるテストデータの分類レポート
columns (List[str]): トレーニングで使用された列のリスト
example_data (np.array): データのサンプル(2~3 行で十分)。モデルにとって予測ペイロードがどのように見えるかを記すために使用される
戻り値:
report (str): テキスト形式の完全なレポート
'''
buffer_example_data = '['
for r in example_data:
buffer_example_data+='['
for c in r:
if(isinstance(c,str)):
buffer_example_data+="'"+c+"', "
else:
buffer_example_data+=str(c)+", "
buffer_example_data= buffer_example_data[:-2]+"], \n"
buffer_example_data= buffer_example_data[:-3]+"]"
report = """
トレーニング ジョブ レポート
交差検証スコア: {cv_score}
トレーニング モデル パラメータ: {model_params}
テストデータ分類レポート:
{classification_report}
予測用データ配列の例:
列の順序:
{columns}
clf.predict() の例:
{predict_example}
GCP API リクエスト本文の例:
{{
"instances": {json_example}
}}
""".format(
cv_score=cv_score,
model_params=json.dumps(model_params),
classification_report=classification_report,
columns = columns,
predict_example = buffer_example_data,
json_example = json.dumps(example_data.tolist()))
return report
def report_export_gcs(report: str, report_dir: str) -> None:
'''
トレーニング ジョブ レポートを GCS にエクスポートする
パラメータ:
report (str): GCS に送信するテキスト形式の完全なレポート
report_dir (str): レポート モデルを保存する GCS パス(gs://example_bucket/training-job など)
戻り値:
export_path (str): レポートの GCS ロケーション
'''
scheme, bucket, path, file = process_gcs_uri(report_dir)
if scheme != "gs:":
raise ValueError("URI scheme must be gs")
# モデルを GCS にアップロード
b = storage.Client().bucket(bucket)
export_path = os.path.join(path, 'report.txt')
blob = b.blob(export_path)
blob.upload_from_string(report)
return scheme + "//" + os.path.join(bucket, export_path)
# トレーニングでモデルが受け取れるすべてのコマンドライン引数を定義
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# 入力引数
parser.add_argument(
'--model_param_kernel',
help = 'SVC model parameter- kernel',
choices=['linear', 'poly', 'rbf', 'sigmoid', 'precomputed'],
type = str,
default = 'linear'
)
parser.add_argument(
'--model_param_degree',
help = 'SVC model parameter- Degree. Only applies for poly kernel',
type = int,
default = 3
)
parser.add_argument(
'--model_param_C',
help = 'SVC model parameter- C (regularization)',
type = float,
default = 1.0
)
parser.add_argument(
'--model_param_probability',
help = 'Whether to enable probability estimates',
type = bool,
default = True
)
'''
Vertex AI は一連の環境変数を、トレーニング ジョブを実行するコンテナ内に
自動的に設定するそのような変数は次のとおり:
* AIP_MODEL_DIR - モデル ディレクトリとして選択されたディレクトリ
* AIP_DATA_FORMAT - トレーニング用に選択されたデータセットの種類(csv または bigquery)
Vertex AI は選択されたデータセットをトレーニング用、検証用、テスト用に自動的に分割する
その他 3 つの環境変数がこれらのデータの場所を示している:
* AIP_TRAINING_DATA_URI - トレーニング データの URI
* AIP_VALIDATION_DATA_URI - 検証データの URI
* AIP_TEST_DATA_URI - テストデータの URI
これらの環境変数はデフォルト値である。ユーザーが CLI 引数を使用して値を指定した場合、
該当する環境変数は無視される。ユーザーが CLI 引数として何も指定しなかった場合、
プログラムは環境変数(存在する場合)の使用を試みる。
存在しなかった場合は空のままになる。
'''
parser.add_argument(
'--model_dir',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_MODEL_DIR'] if 'AIP_MODEL_DIR' in os.environ else ""
)
parser.add_argument(
'--data_format',
choices=['csv', 'bigquery'],
help = 'format of data uri csv for gs:// paths and bigquery for project.dataset.table formats',
type = str,
default = os.environ['AIP_DATA_FORMAT'] if 'AIP_DATA_FORMAT' in os.environ else "csv"
)
parser.add_argument(
'--training_data_uri',
help = 'location of training data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_TRAINING_DATA_URI'] if 'AIP_TRAINING_DATA_URI' in os.environ else ""
)
parser.add_argument(
'--validation_data_uri',
help = 'location of validation data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_VALIDATION_DATA_URI'] if 'AIP_VALIDATION_DATA_URI' in os.environ else ""
)
parser.add_argument(
'--test_data_uri',
help = 'location of test data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_TEST_DATA_URI'] if 'AIP_TEST_DATA_URI' in os.environ else ""
)
parser.add_argument("-v", "--verbose", help="increase output verbosity",
action="store_true")
args = parser.parse_args()
arguments = args.__dict__
if args.verbose:
logging.basicConfig(level=logging.INFO)
logging.info('Model artifacts will be exported here: {}'.format(arguments['model_dir']))
logging.info('Data format: {}'.format(arguments["data_format"]))
logging.info('Training data uri: {}'.format(arguments['training_data_uri']) )
logging.info('Validation data uri: {}'.format(arguments['validation_data_uri']))
logging.info('Test data uri: {}'.format(arguments['test_data_uri']))
'''
データを pandas に読み込むには 2 種類の方法がある。1 つは Cloud Storage から csv ファイルを読み込む方法で
もう 1 つは BigQuery に接続する方法。Vertex AI はどちらの方法もサポートしているが、
ここでは提供されているデータセットに依存したコードを作成した。適切な読み込み方法を選択すること
'''
logging.info('Loading {} data'.format(arguments["data_format"]))
if(arguments['data_format']=='csv'):
df_train = load_data_from_gcs(arguments['training_data_uri'])
df_test = load_data_from_bq(arguments['test_data_uri'])
df_valid = load_data_from_gcs(arguments['validation_data_uri'])
elif(arguments['data_format']=='bigquery'):
print(arguments['training_data_uri'])
df_train = load_data_from_bq(arguments['training_data_uri'])
df_test = load_data_from_bq(arguments['test_data_uri'])
df_valid = load_data_from_bq(arguments['validation_data_uri'])
else:
raise ValueError("Invalid data type ")
# ここでは交差検証を使用するので、トレーニング セットとテストセットを 1 つずつ用意
# 80% と 20% の比率になるようにテスト用と検証用を結合
df_test = pd.concat([df_test,df_valid])
logging.info('Defining model parameters')
model_params = dict()
model_params['kernel'] = arguments['model_param_kernel']
model_params['degree'] = arguments['model_param_degree']
model_params['C'] = arguments['model_param_C']
model_params['probability'] = arguments['model_param_probability']
df_train = clean_missing_numerics(df_train, NUMERIC_FEATURES)
df_test = clean_missing_numerics(df_test, NUMERIC_FEATURES)
logging.info('Running feature selection')
X_train, y_train = data_selection(df_train, ALL_COLUMNS, LABEL)
X_test, y_test = data_selection(df_test, ALL_COLUMNS, LABEL)
logging.info('Training pipelines in CV')
y_train = y_train.astype('int')
y_test = y_test.astype('int')
clf = pipeline_builder(model_params, BINARY_FEATURES_IDX, NUMERIC_FEATURES_IDX, CATEGORICAL_FEATURES_IDX)
cv_score = train_pipeline(clf, X_train, y_train)
logging.info('Export trained pipeline and report')
pipeline_export_gcs(clf, arguments['model_dir'])
y_pred = clf.predict(X_test)
test_score = f1_score(y_test, y_pred, average='weighted')
logging.info('f1score: '+ str(test_score))
report = prepare_report(cv_score,
model_params,
classification_report(y_test,y_pred),
ALL_COLUMNS,
X_test.to_numpy()[0:2])
report_export_gcs(report, arguments['model_dir'])
logging.info('Training job completed. Exiting...')
-
Ctrl+S キーを押してファイルを保存します。
パッケージをビルドする
ここで、トレーニング サービスで使用できるようにパッケージをビルドします。
- 以下のコードをコピーして titanic/setup.py に貼り付けます。
from setuptools import find_packages
from setuptools import setup
REQUIRED_PACKAGES = [
'gcsfs==0.7.1',
'dask[dataframe]==2021.2.0',
'google-cloud-bigquery-storage==1.0.0',
'six==1.15.0'
]
setup(
name='trainer',
version='0.1',
install_requires=REQUIRED_PACKAGES,
packages=find_packages(), # このディレクトリまたは下位の階層でパッケージを自動的に探す
include_package_data=True, # パッケージにデータファイルが含まれている場合、すべて一緒にパッケージ化される
description='Classification training titanic survivors prediction model'
)
-
Ctrl+S キーを押してファイルを保存します。
-
ターミナルに戻り、task.py を使用してモデルをトレーニングできるかどうかテストします。
-
まず、以下の環境変数を作成します。この際必ず、コンソールで正しい GCP プロジェクトが選択されていることを確認してください。
-
PROJECT_ID: 選択されているプロジェクトの ID を設定
-
BUCKET_NAME: PROJECT_ID の後に「-bucket」を付けたもの
export REGION="{{{project_0.default_region|Region}}}"
export PROJECT_ID=$(gcloud config list --format 'value(core.project)')
export BUCKET_NAME=$PROJECT_ID"-bucket"
-
トレーニング済みのモデルをエクスポートするバケットを作成します。
gsutil mb -l $REGION "gs://"$BUCKET_NAME
以下のコマンドを実行します。すべてのトレーニング データをテストに使用します。テスト、検証、トレーニングに同じデータセットを使用します。ここで、コードが実行されること、バグがないことを確認する必要があります。実際には、使用するテストデータと検証データを別々のものにする必要があります。そのような処理は Vertex AI トレーニング サービスに任せることになります。
-
まず、必要なライブラリをインストールします。
cd /home/jupyter/titanic
pip install setuptools
python setup.py install
注: error: google-auth 2.3.3 is installed but google-auth<2.0dev,>=1.25.0 is required by {'google-api-core'} はラボの機能に影響を与えないため無視できます。
-
ここで、トレーニング コードを実行して、問題なく実行されることを確認します。
python -m trainer.task -v \
--model_param_kernel=linear \
--model_dir="gs://"$BUCKET_NAME"/titanic/trial" \
--data_format=bigquery \
--training_data_uri="bq://"$PROJECT_ID".titanic.survivors" \
--test_data_uri="bq://"$PROJECT_ID".titanic.survivors" \
--validation_data_uri="bq://"$PROJECT_ID".titanic.survivors"
コードが正しく実行された場合、出力された INFO ログを確認できます。F1 スコア(0.85 程度)を示す行と、トレーニング ジョブが正しく完了したことを示す行の 2 行が表示されます。
INFO:root:f1score: 0.85
INFO:root:Training job completed. Exiting...
これで完了です。トレーニング用の Python パッケージを作成する準備が整いました。
-
これを実行するには、次のコマンドを実行します。
cd /home/jupyter/titanic
python setup.py sdist
このコマンドを実行すると、tar.gz ファイルが 1 つ含まれている dist という新しいフォルダが表示されます。これが Python パッケージです。
-
このパッケージを GCS にコピーします。それにより、必要なときにトレーニング サービスでこれを使って新しいモデルをトレーニングできます。
gsutil cp dist/trainer-0.1.tar.gz "gs://"$BUCKET_NAME"/titanic/dist/trainer-0.1.tar.gz"
タスク 4. モデルのトレーニング
このセクションでは、Vertex AI でモデルのトレーニングを行います。GUI を使用して実施します。Python SDK を使ってこの処理をプログラムによって行うこともできますが、GUI を使ったほうが理解は深まります。
-
Google Cloud コンソール で、[Vertex AI] > [トレーニング] を選択します。
-
リージョンとして [] を選択します。
-
[新しいモデルのトレーニング] をクリックします。
トレーニング方法
このステップでは、データセットを選択し、トレーニング ジョブの目標を定義します。
-
データセット: 少し前のステップで作成したデータセット。名前は titanic です。
-
目標: モデルにより、タイタニック号の悲劇に遭遇した個人が生存できたかどうかを予測します。これは分類問題です。
-
カスタム トレーニング: カスタム トレーニング パッケージを使用することになります。
- [続行] をクリックします。
モデルの詳細
モデルの名前を定義します。
デフォルトの名前は、データセット名とタイムスタンプを組み合わせたものになります。これはそのままにします。
- [詳細オプション] をクリックすると、トレーニング用、テスト用、検証用の各セットへのデータの分割を定義するオプションが表示されます。ランダム割り当てでは、データがトレーニング用、テスト用、検証用にランダムに分割されます。ここではこのオプションを使用します。
- [続行] をクリックします。
トレーニング コンテナ
トレーニング環境を定義します。
-
ビルド済みコンテナ: Google Cloud には、モデルを簡単にトレーニングできるように複数のビルド済みコンテナが用意されています。このようなコンテナでは、Scikit-learn、TensorFlow、XGBoost などのフレームワークがサポートされています。トレーニング ジョブで特殊なものを使用する場合は、トレーニング用のコンテナ(カスタム コンテナ)を準備し、提供する必要があります。使用するモデルは Scikit-learn に基づいたものであり、ビルド済みコンテナがすでに存在します。
-
モデル フレームワーク:
Scikit-learn。モデルのトレーニングに使用したライブラリです。
-
モデル フレームワークのバージョン: コードはバージョン
0.23 に準拠しています。
-
パッケージの場所: トレーニング パッケージの場所をブラウジングできます。training-0.1.tar.gz をアップロードした場所になります。これまでの手順に正しく従っていた場合、この場所は
gs://YOUR-BUCKET-NAME/titanic/dist/trainer-0.1.tar.gz になります。YOUR-BUCKET-NAME の部分には「パッケージをビルドする」セクションで使用したバケットの名前が入ります。
-
Python モジュール: Notebooks で作成した Python モジュールです。トレーニング コード / モジュールがあるフォルダとエントリ ファイルの名前に対応しています。
trainer.task になります。
-
データをエクスポートするための BigQuery プロジェクト: ステップ 1 でデータセットを選択して自動分割を定義しました。選択したプロジェクトに、トレーニング / テスト / 検証セット用の新しいデータセットとテーブルが作成されます。
-
ラボで実行しているのと同じプロジェクト ID を入力します。また、トレーニング / テスト / 検証用の各データセットの URI がトレーニング コンテナ内の環境変数として設定されます。そのため、データの読み込みでは、これらの変数を自動的に使用できます。各データセットの環境変数名は、
AIP_TRAINING_DATA_URI、AIP_TEST_DATA_URI、AIP_VALIDATION_DATA_URI となります。追加の変数である AIP_DATA_FORMAT は、ステップ 1 で選択したデータセットの種類に応じて csv または bigquery となります。
このロジックはすでに task.py に組み込まれています。この部分のサンプルコードを確認しておきましょう(task.py から抜粋)。
...
parser.add_argument( '--training_data_uri ',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_TRAINING_DATA_URI'] if 'AIP_TRAINING_DATA_URI' in os.environ else "" )
...
-
モデル出力ディレクトリ: モデルがエクスポートされる場所です。トレーニング コンテナ内の
AIP_MODEL_DIR という環境変数の値になります。task.py には、この変数を取得するための入力パラメータがあります。
...
parser.add_argument( '--model_dir',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_MODEL_DIR'] if 'AIP_MODEL_DIR' in os.environ else "" )
...
-
この環境変数を使用すると、トレーニング ジョブのアーティファクトのエクスポート先がわかります。gs://YOUR-BUCKET-NAME/titanic/ を選択します。
-
[続行] をクリックします。
ハイパーパラメータ調整
ハイパーパラメータ調整のセクションでは、モデルの調整に使用する複数のモデル パラメータを定義できます。最適なパラメータでモデルを作成するために、さまざまな値を試すことになります。今回のコードでは、ハイパーパラメータ チューナーの機能は実装しませんでした。数行(5 行ほど)のコードだけとはいえ、これ以上複雑にならないようにするためです。
- [続行] を選択して、このステップはスキップします。
コンピューティングと料金
どこでトレーニング ジョブを実行し、どのようなタイプのサーバーを使用しますか。モデル トレーニングの処理はリソースをあまり必要としません。トレーニング ジョブは比較的小さなノートブック インスタンスの内部で実行できました。その実行は短時間で終了します。
- これを踏まえて、以下のように選択します。
-
リージョン:
-
マシンタイプ:
n1-standard-4
- [続行] をクリックします。
予測コンテナ
このステップでは、モデルのトレーニングだけを行うか、モデルを製品化するために使用する予測サービスの設定も追加するかを決定できます。
このラボでは、ビルド済みコンテナを使用します。ただし、Vertex AI ではモデル提供についていくつかのオプションがあります。
-
予測コンテナなし: モデルのトレーニングだけを行い、モデルの製品化については後で検討します。
-
ビルド済みコンテナ: モデルをトレーニングし、デプロイに使用されるビルド済みコンテナを定義します。
-
カスタム コンテナ: モデルをトレーニングし、デプロイに使用されるカスタム コンテナを定義します。
- Google Cloud には Scikit-learn コンテナがすでに用意されているので、ビルド済みコンテナを選択してください。トレーニング ジョブの完了後にモデルをデプロイします。
-
モデル フレームワーク:
Scikit-learn
-
モデル フレームワークのバージョン:
0.23
-
モデル ディレクトリ:
gs://YOUR-BUCKET-NAME/titanic/. これはステップ 3 で定義したモデル出力ディレクトリと同じものです。
- [トレーニングを開始] をクリックします。
[トレーニング パイプライン] タブに新しいトレーニング ジョブが表示されます。トレーニングが完了するまでに約 15 分かかります。
タスク 5. モデルの評価
トレーニング ジョブの完了後、gs://YOUR-BUCKET-NAME/titanic/model/ にアーティファクトがエクスポートされます。モデルの評価指標と分類レポートが含まれる report.txt ファイルを調べることができます。
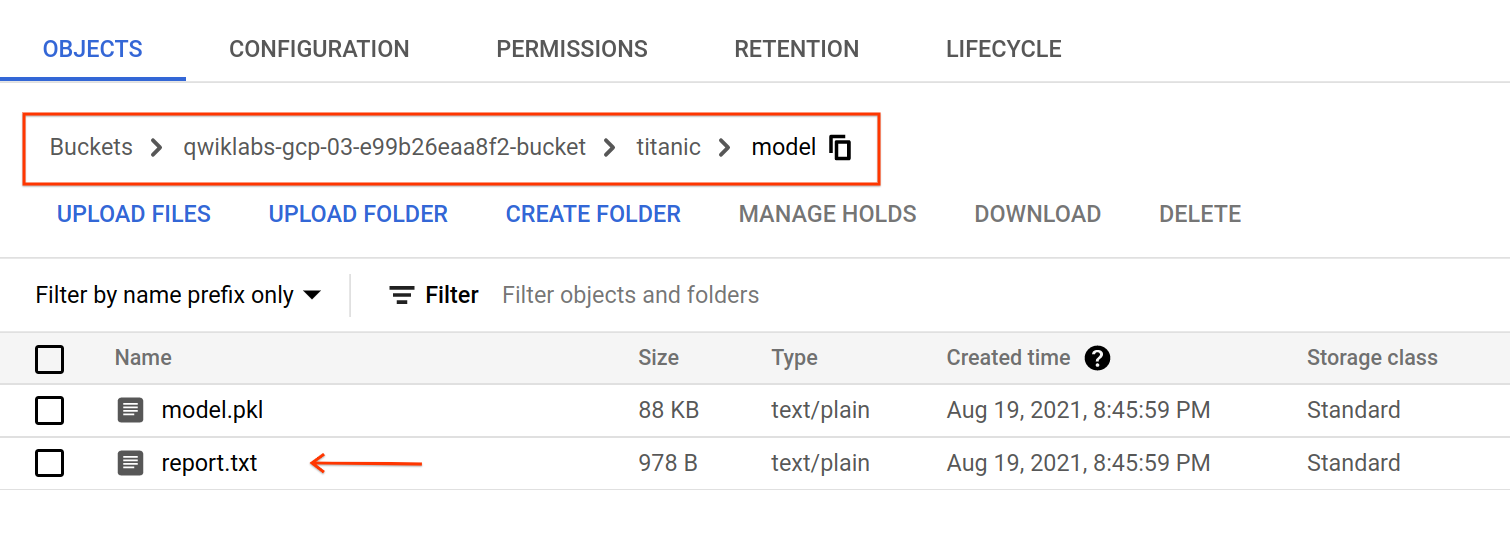
タスク 6. モデルのデプロイ
-
Cloud コンソールのナビゲーション メニューで、[Vertex AI] > [トレーニング] をクリックします。
-
モデルのトレーニング ジョブが完了したら、トレーニング済みのモデルを選択してエンドポイントにデプロイします。
-
[デプロイとテスト] タブに移動し、[エンドポイントにデプロイ] をクリックします。
ポップアップで、モデルのデプロイに必要なリソースを定義できます。
-
エンドポイント名: モデルが提供されるエンドポイント URL。ここでは、
titanic-endpoint のような名前が妥当です。[続行] をクリックします。
-
トラフィック分割: このモデルに送信するトラフィックの割合を定義します。エンドポイントには複数のモデルを配置でき、各モデル間でトラフィックをどのように分割するかを決定できます。ここでは、デプロイするモデルが 1 つだけなので、トラフィックは
100% にする必要があります。
-
コンピューティング ノードの最小数: モデルの予測を提供するのに必要な最小ノード数です。最初は
1 にします。トラフィックが発生すると、予測サービスによって自動スケーリングが行われます。
-
コンピューティング ノードの最大数: 自動スケーリングが行われる場合、この変数でノード数の上限を定義します。自動スケーリングで不要な費用が発生するのを防止できます。この変数は
2 に設定します。
-
マシンタイプ: Google Cloud には、モデルのデプロイ先となるマシンのタイプが複数用意されています。マシンごとにメモリおよび vCPU の仕様が異なります。ここで使用するモデルはシンプルなので、
n1-standard-4 インスタンスで十分です。
- [完了] をクリックし、[デプロイ] をクリックします。
タスク 7. モデルの予測
- [モデルをデプロイする] で、モデル予測用エンドポイントをテストします。GUI では、JSON リクエスト ペイロードを送信するフォームを利用できます。また、予測結果と、予測に使用されたモデル ID を含む応答が返されます。これは、1 つのエンドポイントに複数のモデルをデプロイしてトラフィックを分割できるためです。
![[デプロイとテスト] タブページの表示](https://cdn.qwiklabs.com/UQmgNuxTMUdvGDNe6c2nD3jU2QVpfquiqpZE5tpAukw%3D)
- 次のペイロードを試し、値をいくつか変更して予測がどのように変化するか確認してみましょう。入力する特徴量の順序は [‘sex', ‘age', ‘fare', ‘pclass', ‘embarked', ‘home_dest', ‘parch', ‘sibsp'] です。
{
"instances": [
["male", 29.8811345124283, 26.0, 1, "S", "New York, NY", 0, 0],
["female", 48.0, 39.6, 1, "C", "London / Paris", 0, 1]]
}
- [予測] をクリックします。
エンドポイントは、入力と同じ順序で 0 または 1 の値のリストを返します。0 はタイタニック号の事故に遭ったときに生存できる可能性が低いことを意味し、1 は生存の可能性が高いことを意味します。
タスク 8. クリーンアップ
お疲れさまでした。Vertex AI を使用して、データセットを作成し、トレーニング コードをパッケージ化し、カスタム トレーニング ジョブを実行しました。また、トレーニングしたモデルをデプロイし、予測用に一部のデータを送信しました。
作成されたリソースが不要な場合は、意図しない費用が発生するのを避けるために、それらのリソースを削除することをおすすめします。
-
コンソールの [データセット] ページに移動し、削除するデータセットのその他アイコンをクリックして [データセットの削除] をクリックします。[削除] をクリックして削除を確定します。
-
コンソールの [Workbench] ページに移動し、削除するノートブックのみを選択して、トップメニューにある [削除] をクリックします。[削除] をクリックして削除を確定します。
-
デプロイしたエンドポイントを削除するには、Vertex AI コンソールの [エンドポイント] セクションで対象のエンドポイントをクリックし、オーバーフロー メニュー()をクリックします。次に、[エンドポイントからモデルのデプロイを解除] を選択し、[デプロイ解除] をクリックします。
-
エンドポイントを削除するには、オーバーフロー メニュー()、[エンドポイントを削除] の順にクリックし、[確定] をクリックします。
-
モデルのコンソール ページに移動して、削除するモデルに対してその他アイコン()、[モデルを削除] の順にクリックし、[削除] をクリックします。
-
Cloud Storage バケットを削除するには、[Cloud Storage] ページで対象のバケットを選択して [削除] をクリックします。「DELETE」と入力して [削除] をクリックし、削除を確定します。
-
BigQuery データセットを削除するには、以下の手順を実行します。
- BigQuery コンソールに移動します。
- [エクスプローラ] パネルで、データセットの横にあるアクションを表示アイコンをクリックします。[削除] をクリックします。
- データセットの削除を確認するダイアログ ボックスで、「
delete」と入力し、[削除] をクリックして削除コマンドを確定します。
ラボを終了する
ラボでの学習が完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Qwiklabs から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
- 星 1 つ = 非常に不満
- 星 2 つ = 不満
- 星 3 つ = どちらともいえない
- 星 4 つ = 満足
- 星 5 つ = 非常に満足
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバック、ご提案、修正が必要な箇所については、[サポート] タブからお知らせください。
Copyright 2020 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。





