In questo lab puoi usare Vertex AI per addestrare un modello ML ed eseguirne il deployment. Si presuppone che tu abbia familiarità con il machine learning, anche se ti verrà comunque fornito il codice di machine learning necessario per l'addestramento. Dovrai creare e gestire un set di dati, quindi utilizzare un modello personalizzato per l'addestramento di un modello Scikit Learn. Infine, dovrai eseguire il deployment del modello addestrato e generare le previsioni online. Per questa demo utilizzerai il set di dati Titanic.
Obiettivi
Creare un set di dati per i dati tabulari.
Creare un pacchetto di addestramento contenente codice personalizzato, utilizzando Notebooks.
Eseguire il deployment del modello addestrato e generare le previsioni online.
Configurazione
Per ciascun lab, riceverai un nuovo progetto Google Cloud e un insieme di risorse per un periodo di tempo limitato senza alcun costo aggiuntivo.
Accedi a Qwiklabs utilizzando una finestra di navigazione in incognito.
Tieni presente la durata dell'accesso al lab (ad esempio, 1:15:00) e assicurati di finire entro quell'intervallo di tempo.
Non è disponibile una funzionalità di pausa. Se necessario, puoi riavviare il lab ma dovrai ricominciare dall'inizio.
Quando è tutto pronto, fai clic su Inizia lab.
Annota le tue credenziali del lab (Nome utente e Password). Le userai per accedere a Google Cloud Console.
Fai clic su Apri console Google.
Fai clic su Utilizza un altro account e copia/incolla le credenziali per questo lab nei prompt.
Se utilizzi altre credenziali, compariranno errori oppure ti verranno addebitati dei costi.
Accetta i termini e salta la pagina di ripristino delle risorse.
Nota: se hai difficoltà a scaricare il set di dati nella modalità di navigazione in incognito, puoi scaricare Titanic dataset utilizzando la finestra normale.
Rinomina il set di dati scaricato, assegnandogli il nome titanic_toy.csv.
Quindi, dalla UI:
Apri il set di dati titanic che hai creato nel passaggio precedente. (Fai clic sull'icona Visualizza azioni () accanto al set di dati e seleziona Apri).
Fai clic su Crea tabella e specifica quanto segue:
Crea tabella da: Caricamento
Seleziona file: Usa il set di dati Titanic scaricato
Formato file: CSV
Nome tabella: survivors
Rilevamento automatico: Seleziona la casella di controllo Rilevamento automatico - Schema
Fai clic su Crea tabella.
Fai clic sull'icona Visualizza azioni accanto a survivors e seleziona Copia ID. Salva l'ID tabella appena copiato, che verrà utilizzato più avanti nel corso del lab.
Hai creato una tabella e l'hai compilata con il set di dati Titanic. Ora puoi esplorarne il contenuto, eseguire query e analizzare i dati.
Attività 2: crea un set di dati
Il comando Set di dati di Vertex AI consente di creare set di dati per i carichi di lavoro di machine learning. È possibile creare set di dati sia per i dati strutturati, come i file CSV o le tabelle di BigQuery, sia per i dati non strutturati, come il testo e le immagini. È importante notare che i set di dati Vertex AI si limitano a referenziare i dati originali, senza creare duplicati.
Creazione del set di dati ML
Nella console Google Cloud, seleziona Vertex AI > Set di dati dal menu di navigazione.
Seleziona e fai clic su Crea.
Assegna un nome al tuo set di dati, ad esempio titanic.
Puoi creare set di dati per immagini, testo o video, ma anche per i dati in formato tabulare.
Poiché il set di dati Titanic è in formato tabulare, fai clic sulla scheda Tabulare.
Per la selezione della regione, seleziona e fai clic su Crea.
In questa fase viene creato semplicemente un segnaposto. Non hai ancora stabilito la connessione all'origine dati. Lo farai nel passaggio successivo.
Selezione dell'origine dati
Dato che hai già caricato il set di dati Titanic in BigQuery, puoi connettere il tuo set di dati ML alla tua tabella BigQuery.
Scegli Seleziona una tabella o una visualizzazione da BigQuery.
Copia nel campo SFOGLIA l'ID tabella che hai copiato in precedenza.
Seleziona il set di dati e fai clic su Continua.
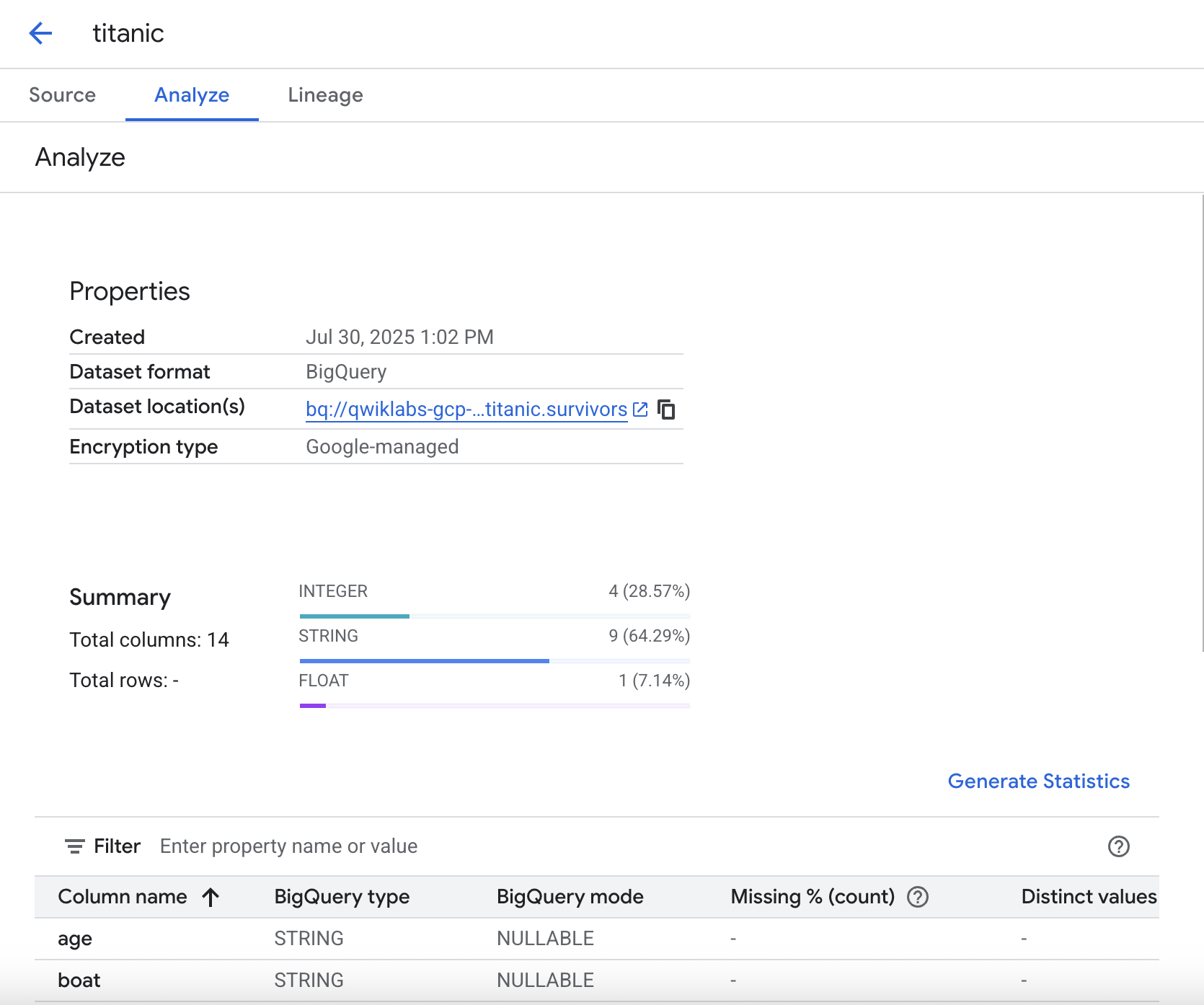
Generazione delle statistiche
La scheda Analisi consente di generare le statistiche relative ai dati, permettendoti di verificare rapidamente le distribuzioni, i valori mancanti e così via.
Per eseguire l'analisi statistica, fai clic su Genera statistiche. Poiché l'operazione può richiedere alcuni minuti, se lo desideri puoi continuare con il lab e tornare a questa scheda in seguito per vedere i risultati.
Attività 3: personalizza il pacchetto di addestramento con Workbench
È consigliabile pacchettizzare e parametrizzare il codice, in modo da trasformarlo in un asset portabile.
In questa sezione utilizzerai Vertex AI Workbench per creare un pacchetto di addestramento con il codice personalizzato. Per utilizzare questo servizio, è fondamentale essere in grado di creare una distribuzione di codice sorgente Python, che prende il nome di pacchetto di distribuzione. In pratica dovrai creare i file e le cartelle da inserire nel pacchetto di distribuzione. La struttura del pacchetto verrà illustrata nella sezione successiva.
Struttura dell'applicazione
La struttura di base di un pacchetto Python è illustrata nell'immagine che segue.
Vediamo a cosa servono i diversi file e cartelle:
titanic-package: è la directory di lavoro. Questa cartella dovrà contenere il tuo pacchetto, con il codice correlato al classificatore dei sopravvissuti del Titanic.
setup.py: è un file di configurazione che specifica come generare il pacchetto di distribuzione. Include informazioni come il nome e la versione del pacchetto, oltre a tutti gli altri pacchetti eventualmente necessari per il job di addestramento e che non sono inclusi per impostazione predefinita nei container di addestramento pronti all'uso della piattaforma Google Cloud.
trainer: questa cartella contiene il codice di addestramento. È anche un pacchetto Python, per via del file __init__.py vuoto contenuto nella cartella.
__init__.py: file vuoto di nome __init__.py. Indica che la cartella in cui si trova è un pacchetto.
task.py: il file task.py è un modulo del pacchetto, che contiene il punto di accesso del codice e accetta anche i parametri dell'interfaccia a riga di comando per l'addestramento del modello. Puoi includere il codice di addestramento direttamente in questo modulo oppure creare ulteriori moduli all'interno del pacchetto. Questa scelta, che determina la struttura del codice, spetta completamente a te.
Ora che hai compreso la struttura, ricorda che il pacchetto e i moduli possono avere qualsiasi nome, tranne "trainer" e "task.py". In questo lab abbiamo scelto questa convenzione di denominazione perché rispecchia quella della documentazione online, ma in realtà puoi utilizzare i nomi che preferisci.
Creazione di un'istanza del blocco note
Adesso possiamo creare un'istanza del blocco note e provare ad addestrare un modello personalizzato.
Nella console Google Cloud, nel menu di navigazione, fai clic su Vertex AI > Workbench.
Nella pagina Istanze notebook, fai clic su Crea nuova e avvia un'istanza con Python 3, che include Scikit-learn. Infatti, per il classificatore dovrai usare un modello Scikit-learn.
Comparirà un popup. Qui puoi modificare alcune impostazioni, come la regione in cui verrà creata l'istanza del blocco note e la potenza di calcolo necessaria.
Poiché i dati da gestire non sono molti e devi creare l'istanza solo a scopo di sviluppo, non devi modificare alcuna impostazione, ma semplicemente fare clic su Crea.
La creazione dell'istanza funzionante richiede al massimo due minuti.
Terminata la creazione dell'istanza puoi procedere con l'apertura di Jupyterlab.
Vedrai il messaggio popup "Build suggerita": fai clic su Crea. Se un messaggio ti informa che la creazione non è riuscita, ignoralo.
Creazione del pacchetto
Ora che disponi di un blocco note funzionante, puoi cominciare a creare gli asset di addestramento.
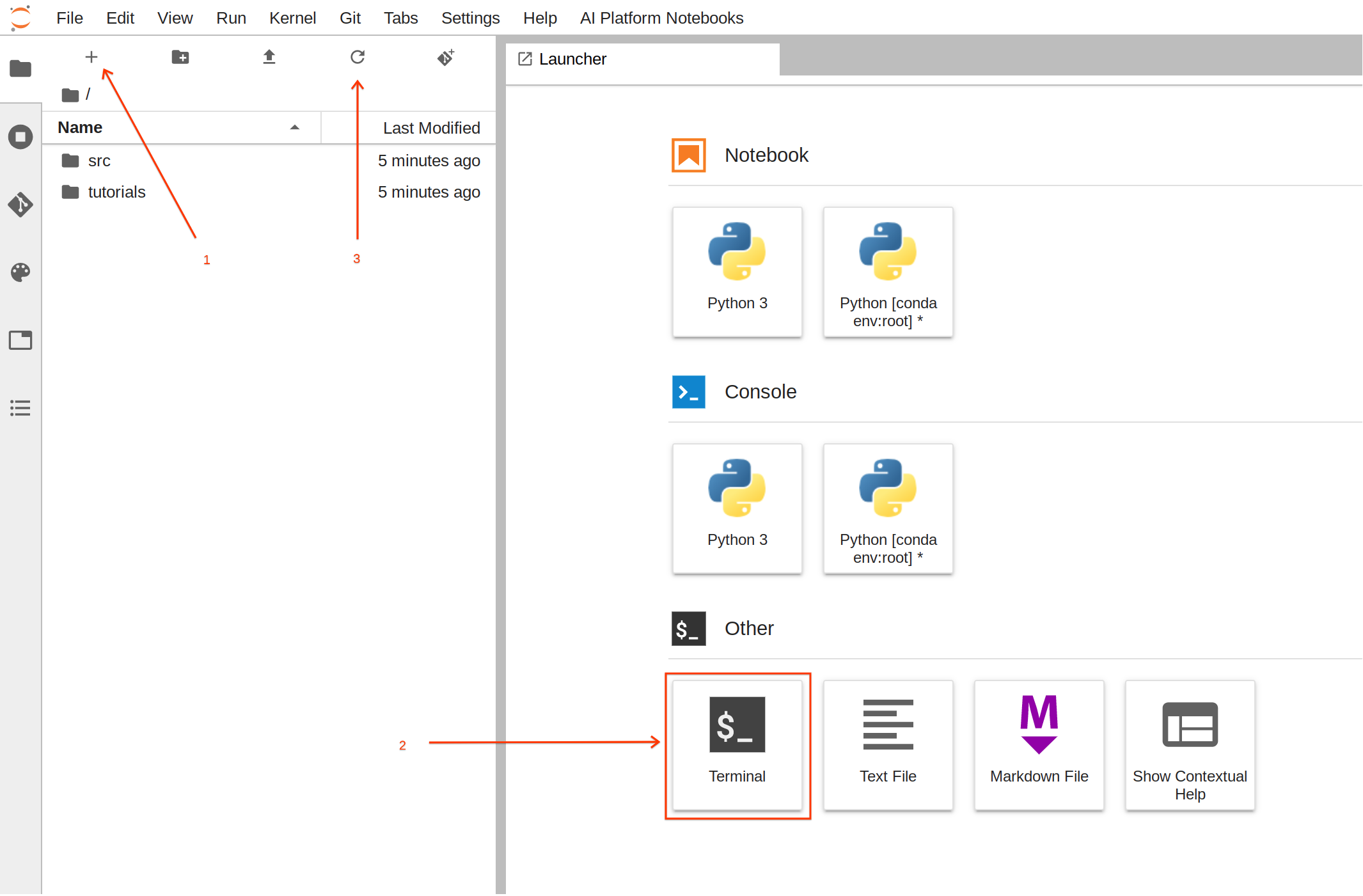
Per questa attività è consigliabile utilizzare il terminale, perché risulta più semplice.
Da Avvio app, fai clic su Terminale per creare una nuova sessione di terminale.
Nel terminale, esegui i comandi riportati di seguito per creare la struttura delle cartelle con i file necessari:
Dopo l'esecuzione dei comandi fai clic sul pulsante di aggiornamento per visualizzare i file e le cartelle appena creati.
Copia il codice riportato di seguito e incollalo nel file titanic/trainer/task.py. Il codice contiene alcuni commenti, pertanto è consigliabile esaminarlo attentamente per comprenderne meglio la logica:
from google.cloud import bigquery, bigquery_storage, storage
from sklearn.pipeline import make_pipeline, Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder, OrdinalEncoder
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
from sklearn.metrics import classification_report, f1_score
from typing import Union, List
import os, logging, json, pickle, argparse
import dask.dataframe as dd
import pandas as pd
import numpy as np
# feature selection. The FEATURE list defines what features are needed from the training data
# as well as the types of those features. We will perform different feature engineering depending on the type.
# List all column names for binary features: 0,1 or True,False or Male,Female etc
BINARY_FEATURES = [
'sex']
# List all column names for numeric features
NUMERIC_FEATURES = [
'age',
'fare']
# List all column names for categorical features
CATEGORICAL_FEATURES = [
'pclass',
'embarked',
'home_dest',
'parch',
'sibsp']
ALL_COLUMNS = BINARY_FEATURES+NUMERIC_FEATURES+CATEGORICAL_FEATURES
# define the column name for label
LABEL = 'survived'
# Define the index position of each feature. This is needed for processing a
# numpy array (instead of pandas) which has no column names.
BINARY_FEATURES_IDX = list(range(0,len(BINARY_FEATURES)))
NUMERIC_FEATURES_IDX = list(range(len(BINARY_FEATURES), len(BINARY_FEATURES)+len(NUMERIC_FEATURES)))
CATEGORICAL_FEATURES_IDX = list(range(len(BINARY_FEATURES+NUMERIC_FEATURES), len(ALL_COLUMNS)))
def load_data_from_gcs(data_gcs_path: str) -> pd.DataFrame:
'''
Loads data from Google Cloud Storage (GCS) to a dataframe
Parameters:
data_gcs_path (str): gs path for the location of the data. Wildcards are also supported. i.e gs://example_bucket/data/addestramento-*.csv
Returns:
pandas.DataFrame: a dataframe with the data from GCP loaded
'''
# using dask that supports wildcards to read multiple files. Then with dd.read_csv().compute we create a pandas dataframe
# Additionally I have noticed that some values for TotalCharges are missing and this creates confusion regarding TotalCharges as the data type.
# to overcome this we manually define TotalCharges as object.
# We will later fix this abnormality
logging.info("reading gs data: {}".format(data_gcs_path))
return dd.read_csv(data_gcs_path, dtype={'TotalCharges': 'object'}).compute()
def load_data_from_bq(bq_uri: str) -> pd.DataFrame:
'''
Loads data from BigQuery table (BQ) to a dataframe
Parameters:
bq_uri (str): bq table uri. i.e: example_project.example_dataset.example_table
Returns:
pandas.DataFrame: a dataframe with the data from GCP loaded
'''
if not bq_uri.startswith('bq://'):
raise Exception("uri is not a BQ uri. It should be bq://project_id.dataset.table")
logging.info("reading bq data: {}".format(bq_uri))
project,dataset,table = bq_uri.split(".")
bqclient = bigquery.Client(project=project[5:])
bqstorageclient = bigquery_storage.BigQueryReadClient()
query_string = """
SELECT * from {ds}.{tbl}
""".format(ds=dataset, tbl=table)
return (
bqclient.query(query_string)
.result()
.to_dataframe(bqstorage_client=bqstorageclient)
)
def clean_missing_numerics(df: pd.DataFrame, numeric_columns):
'''
removes invalid values in the numeric columns
Parameters:
df (pandas.DataFrame): The Pandas Dataframe to alter
numeric_columns (List[str]): List of column names that are numeric from the DataFrame
Returns:
pandas.DataFrame: a dataframe with the numeric columns fixed
'''
for n in numeric_columns:
df[n] = pd.to_numeric(df[n], errors='coerce')
df = df.fillna(df.mean())
return df
def data_selection(df: pd.DataFrame, selected_columns: List[str], label_column: str) -> (pd.DataFrame, pd.Series):
'''
From a dataframe it creates a new dataframe with only selected columns and returns it.
Additionally it splits the label column into a pandas Series.
Parameters:
df (pandas.DataFrame): The Pandas Dataframe to drop columns and extract label
selected_columns (List[str]): List of strings with the selected columns. i,e ['col_1', 'col_2', ..., 'col_n' ]
label_column (str): The name of the label column
Returns:
tuple(pandas.DataFrame, pandas.Series): Tuble with the new pandas DataFrame containing only selected columns and lablel pandas Series
'''
# We create a series with the prediciton label
labels = df[label_column].astype(int)
data = df.loc[:, selected_columns]
return data, labels
def pipeline_builder(params_svm: dict, bin_ftr_idx: List[int], num_ftr_idx: List[int], cat_ftr_idx: List[int]) -> Pipeline:
'''
Builds a sklearn pipeline with preprocessing and model configuration.
Preprocessing steps are:
* OrdinalEncoder - used for binary features
* StandardScaler - used for numerical features
* OneHotEncoder - used for categorical features
Model used is SVC
Parameters:
params_svm (dict): List of parameters for the sklearn.svm.SVC classifier
bin_ftr_idx (List[str]): List of ints that mark the column indexes with binary columns. i.e [0, 2, ... , X ]
num_ftr_idx (List[str]): List of ints that mark the column indexes with numerical columns. i.e [6, 3, ... , X ]
cat_ftr_idx (List[str]): List of ints that mark the column indexes with categorical columns. i.e [5, 10, ... , X ]
label_column (str): The name of the label column
Returns:
Pipeline: sklearn.pipelines.Pipeline with preprocessing and model training
'''
# Defining a preprocessing step for our pipeline.
# it specifies how the features are going to be transformed
preprocessor = ColumnTransformer(
transformers=[
('bin', OrdinalEncoder(), bin_ftr_idx),
('num', StandardScaler(), num_ftr_idx),
('cat', OneHotEncoder(handle_unknown='ignore'), cat_ftr_idx)], n_jobs=-1)
# We now create a full pipeline, for preprocessing and training.
# for training we selected a linear SVM classifier
clf = SVC()
clf.set_params(**params_svm)
return Pipeline(steps=[ ('preprocessor', preprocessor),
('classifier', clf)])
def train_pipeline(clf: Pipeline, X: Union[pd.DataFrame, np.ndarray], y: Union[pd.DataFrame, np.ndarray]) -> float:
'''
Trains a sklearn pipeline by fiting training data and labels and returns the accuracy f1 score
Parameters:
clf (sklearn.pipelines.Pipeline): the Pipeline object to fit the data
X: (pd.DataFrame OR np.ndarray): Training vectors of shape n_samples x n_features, where n_samples is the number of samples and n_features is the number of features.
y: (pd.DataFrame OR np.ndarray): Labels of shape n_samples. Order should mathc Training Vectors X
Returns:
score (float): Average F1 score from all cross validations
'''
# run cross validation to get training score. we can use this score to optimize training
score = cross_val_score(clf, X, y, cv=10, n_jobs=-1).mean()
# Now we fit all our data to the classifier.
clf.fit(X, y)
return score
def process_gcs_uri(uri: str) -> (str, str, str, str):
'''
Receives a Google Cloud Storage (GCS) uri and breaks it down to the scheme, bucket, path and file
Parameters:
uri (str): GCS uri
Returns:
scheme (str): uri scheme
bucket (str): uri bucket
path (str): uri path
file (str): uri file
'''
url_arr = uri.split("/")
if "." not in url_arr[-1]:
file = ""
else:
file = url_arr.pop()
scheme = url_arr[0]
bucket = url_arr[2]
path = "/".join(url_arr[3:])
path = path[:-1] if path.endswith("/") else path
return scheme, bucket, path, file
def pipeline_export_gcs(fitted_pipeline: Pipeline, model_dir: str) -> str:
'''
Exports trained pipeline to GCS
Parameters:
fitted_pipeline (sklearn.pipelines.Pipeline): the Pipeline object with data already fitted (trained pipeline object)
model_dir (str): GCS path to store the trained pipeline. i.e gs://example_bucket/training-job
Returns:
export_path (str): Model GCS location
'''
scheme, bucket, path, file = process_gcs_uri(model_dir)
if scheme != "gs:":
raise ValueError("URI scheme must be gs")
# Upload the model to GCS
b = storage.Client().bucket(bucket)
export_path = os.path.join(path, 'model.pkl')
blob = b.blob(export_path)
blob.upload_from_string(pickle.dumps(fitted_pipeline))
return scheme + "//" + os.path.join(bucket, export_path)
def prepare_report(cv_score: float, model_params: dict, classification_report: str, columns: List[str], example_data: np.ndarray) -> str:
'''
Prepares a training report in Text
Parameters:
cv_score (float): score of the training job during cross validation of training data
model_params (dict): dictonary containing the parameters the model was trained with
classification_report (str): Model classification report with test data
columns (List[str]): List of columns that where used in training.
example_data (np.array): Sample of data (2-3 rows are enough). This is used to include what the prediciton payload should look like for the model
Returns:
report (str): Full report in text
'''
buffer_example_data = '['
for r in example_data:
buffer_example_data+='['
for c in r:
if(isinstance(c,str)):
buffer_example_data+="'"+c+"', "
else:
buffer_example_data+=str(c)+", "
buffer_example_data= buffer_example_data[:-2]+"], \n"
buffer_example_data= buffer_example_data[:-3]+"]"
report = """
Training Job Report
Cross Validation Score: {cv_score}
Training Model Parameters: {model_params}
Test Data Classification Report:
{classification_report}
Example of data array for prediciton:
Order of columns:
{columns}
Example for clf.predict()
{predict_example}
Example of GCP API request body:
{{
"instances": {json_example}
}}
""".format(
cv_score=cv_score,
model_params=json.dumps(model_params),
classification_report=classification_report,
columns = columns,
predict_example = buffer_example_data,
json_example = json.dumps(example_data.tolist()))
return report
def report_export_gcs(report: str, report_dir: str) -> None:
'''
Exports training job report to GCS
Parameters:
report (str): Full report in text to sent to GCS
report_dir (str): GCS path to store the report model. i.e gs://example_bucket/training-job
Returns:
export_path (str): Report GCS location
'''
scheme, bucket, path, file = process_gcs_uri(report_dir)
if scheme != "gs:":
raise ValueError("URI scheme must be gs")
# Upload the model to GCS
b = storage.Client().bucket(bucket)
export_path = os.path.join(path, 'report.txt')
blob = b.blob(export_path)
blob.upload_from_string(report)
return scheme + "//" + os.path.join(bucket, export_path)
# Define all the command-line arguments your model can accept for training
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# Input Arguments
parser.add_argument(
'--model_param_kernel',
help = 'SVC model parameter- kernel',
choices=['linear', 'poly', 'rbf', 'sigmoid', 'precomputed'],
type = str,
default = 'linear'
)
parser.add_argument(
'--model_param_degree',
help = 'SVC model parameter- Degree. Only applies for poly kernel',
type = int,
default = 3
)
parser.add_argument(
'--model_param_C',
help = 'SVC model parameter- C (regularization)',
type = float,
default = 1.0
)
parser.add_argument(
'--model_param_probability',
help = 'Whether to enable probability estimates',
type = bool,
default = True
)
'''
Vertex AI automatically populates a set of environment variables in the container that executes
your training job. Those variables include:
* AIP_MODEL_DIR - Directory selected as model dir
* AIP_DATA_FORMAT - Type of dataset selected for training (can be csv or bigquery)
Vertex AI will automatically split selected dataset into training, validation and testing
and 3 more environment variables will reflect the location of the data:
* AIP_TRAINING_DATA_URI - URI of Training data
* AIP_VALIDATION_DATA_URI - URI of Validation data
* AIP_TEST_DATA_URI - URI of Test data
Notice that those environment variables are default. If the user provides a value using CLI argument,
the environment variable will be ignored. If the user does not provide anything as CLI argument
the program will try and use the environment variables if those exist. Otherwise will leave empty.
'''
parser.add_argument(
'--model_dir',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_MODEL_DIR'] if 'AIP_MODEL_DIR' in os.environ else ""
)
parser.add_argument(
'--data_format',
choices=['csv', 'bigquery'],
help = 'format of data uri csv for gs:// paths and bigquery for project.dataset.table formats',
type = str,
default = os.environ['AIP_DATA_FORMAT'] if 'AIP_DATA_FORMAT' in os.environ else "csv"
)
parser.add_argument(
'--training_data_uri',
help = 'location of training data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_TRAINING_DATA_URI'] if 'AIP_TRAINING_DATA_URI' in os.environ else ""
)
parser.add_argument(
'--validation_data_uri',
help = 'location of validation data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_VALIDATION_DATA_URI'] if 'AIP_VALIDATION_DATA_URI' in os.environ else ""
)
parser.add_argument(
'--test_data_uri',
help = 'location of test data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_TEST_DATA_URI'] if 'AIP_TEST_DATA_URI' in os.environ else ""
)
parser.add_argument("-v", "--verbose", help="increase output verbosity",
action="store_true")
args = parser.parse_args()
arguments = args.__dict__
if args.verbose:
logging.basicConfig(level=logging.INFO)
logging.info('Model artifacts will be exported here: {}'.format(arguments['model_dir']))
logging.info('Data format: {}'.format(arguments["data_format"]))
logging.info('Training data uri: {}'.format(arguments['training_data_uri']) )
logging.info('Validation data uri: {}'.format(arguments['validation_data_uri']))
logging.info('Test data uri: {}'.format(arguments['test_data_uri']))
'''
We have 2 different ways to load our data to pandas. One is from Cloud Storage by loading csv files and
the other is by connecting to BigQuery. Vertex AI supports both and
here we created a code that depending on the dataset provided. We will select the appropriate loading method.
'''
logging.info('Loading {} data'.format(arguments["data_format"]))
if(arguments['data_format']=='csv'):
df_train = load_data_from_gcs(arguments['training_data_uri'])
df_test = load_data_from_bq(arguments['test_data_uri'])
df_valid = load_data_from_gcs(arguments['validation_data_uri'])
elif(arguments['data_format']=='bigquery'):
print(arguments['training_data_uri'])
df_train = load_data_from_bq(arguments['training_data_uri'])
df_test = load_data_from_bq(arguments['test_data_uri'])
df_valid = load_data_from_bq(arguments['validation_data_uri'])
else:
raise ValueError("Invalid data type ")
#as we will be using cross validation, we will have just a training set and a single test set.
# we will merge the test and validation to achieve an 80%-20% split
df_test = pd.concat([df_test,df_valid])
logging.info('Defining model parameters')
model_params = dict()
model_params['kernel'] = arguments['model_param_kernel']
model_params['degree'] = arguments['model_param_degree']
model_params['C'] = arguments['model_param_C']
model_params['probability'] = arguments['model_param_probability']
df_train = clean_missing_numerics(df_train, NUMERIC_FEATURES)
df_test = clean_missing_numerics(df_test, NUMERIC_FEATURES)
logging.info('Running feature selection')
X_train, y_train = data_selection(df_train, ALL_COLUMNS, LABEL)
X_test, y_test = data_selection(df_test, ALL_COLUMNS, LABEL)
logging.info('Training pipelines in CV')
y_train = y_train.astype('int')
y_test = y_test.astype('int')
clf = pipeline_builder(model_params, BINARY_FEATURES_IDX, NUMERIC_FEATURES_IDX, CATEGORICAL_FEATURES_IDX)
cv_score = train_pipeline(clf, X_train, y_train)
logging.info('Export trained pipeline and report')
pipeline_export_gcs(clf, arguments['model_dir'])
y_pred = clf.predict(X_test)
test_score = f1_score(y_test, y_pred, average='weighted')
logging.info('f1score: '+ str(test_score))
report = prepare_report(cv_score,
model_params,
classification_report(y_test,y_pred),
ALL_COLUMNS,
X_test.to_numpy()[0:2])
report_export_gcs(report, arguments['model_dir'])
logging.info('Training job completed. Exiting...')
Premi Ctrl+S per salvare il file.
Generazione del pacchetto
Ora puoi generare il pacchetto, in modo da poterlo utilizzare per il servizio di addestramento.
Copia il codice riportato di seguito e incollalo nel file titanic/setup.py:
from setuptools import find_packages
from setuptools import setup
REQUIRED_PACKAGES = [
'gcsfs==0.7.1',
'dask[dataframe]==2021.2.0',
'google-cloud-bigquery-storage==1.0.0',
'six==1.15.0'
]
setup(
name='trainer',
version='0.1',
install_requires=REQUIRED_PACKAGES,
packages=find_packages(), # Automatically find packages within this directory or below.
include_package_data=True, # if packages include any data files, those will be packed together.
description='Classification training titanic survivors prediction model'
)
Premi Ctrl+S per salvare il file.
Torna al terminale e verifica la possibilità di addestrare un modello utilizzando il file task.py.
Dopo aver verificato che nella console sia selezionato il progetto GCP appropriato, crea le variabili di ambiente riportate di seguito:
PROJECT_ID: verrà impostata sull'ID progetto selezionato
BUCKET_NAME: conterrà il valore di PROJECT_ID seguito dalla dicitura "-bucket"
export REGION="{{{project_0.default_region|Region}}}"
export PROJECT_ID=$(gcloud config list --format 'value(core.project)')
export BUCKET_NAME=$PROJECT_ID"-bucket"
Crea il bucket in cui vuoi esportare il modello addestrato:
gsutil mb -l $REGION "gs://"$BUCKET_NAME
Ora esegui i comandi riportati di seguito. Per il test vengono utilizzati tutti i tuoi dati di addestramento. Lo stesso set di dati viene utilizzato per il test, la convalida e l'addestramento. In questo caso, devi assicurarti che il codice venga eseguito e che sia privo di bug. In una situazione reale è consigliabile utilizzare dati diversi per le attività di test e convalida. Questo è un aspetto che verrà gestito dal servizio di addestramento Vertex AI.
Installa innanzitutto le librerie necessarie.
cd /home/jupyter/titanic
pip install setuptools
python setup.py install
Nota: l'errore error: google-auth 2.3.3 is installed but google-auth<2.0dev,>=1.25.0 is required by {'google-api-core'} può essere ignorato, perché non interferisce con le funzionalità del lab.
Ora esegui il codice di addestramento, per verificare che non ci siano problemi:
Se il codice viene eseguito correttamente, vengono visualizzati i log INFO, due righe con il punteggio f1, che deve essere circa 0,85, seguite da una riga che conferma il completamento corretto del job di addestramento:
In questa sezione addestrerai un modello in Vertex AI. A questo scopo, dovrai utilizzare la GUI. Questa operazione può essere eseguita anche in modo programmatico, utilizzando l'SDK Python, ma utilizzando la GUI potrai capire il processo più chiaramente.
Nella console Google Cloud, vai a Vertex AI > Addestramento.
Seleziona la regione .
Fai clic su Addestra nuovo modello.
Metodo di addestramento
In questo passaggio, devi selezionare il set di dati e definire lo scopo del job di addestramento.
Set di dati: è il set di dati che hai creato in precedenza, con il nome titanic.
Scopo: il modello prevede la probabilità di sopravvivere alla tragedia del Titanic. Si tratta di un problema di Classificazione.
Addestramento personalizzato: utilizzerai il tuo pacchetto di addestramento personalizzato.
Fai clic su Continua.
Dettagli modello
Ora devi specificare il nome del modello.
Il nome predefinito è costituito dal nome del set di dati seguito da un timestamp. Puoi lasciarlo invariato.
Facendo clic su Opzioni avanzate, hai la possibilità di suddividere i dati nei set di addestramento, test e convalida. L'opzione Assegnazione casuale suddividerà i dati casualmente, nei set di addestramento, test e convalida, pertanto sembra essere quella ottimale.
Fai clic su Continua.
Container di addestramento
Definisci il tuo ambiente di addestramento.
Container predefinito: Google Cloud offre una serie di container pronti all'uso, che semplificano l'addestramento dei modelli. Questi container supportano framework come Scikit-learn, TensorFlow e XGBoost. Se il tuo job di addestramento presenta caratteristiche particolari, dovrai preparare un container di addestramento personalizzato ed eseguirne il provisioning. Il tuo modello è basato su Scikit-learn ed è già disponibile un container predefinito.
Framework modello: Scikit-learn. È la libreria che hai utilizzato per l'addestramento del modello.
Versione framework modello: il tuo codice è compatibile con la versione 0.23.
Località pacchetto: puoi cercare e selezionare la località del tuo pacchetto di addestramento, che è quella in cui hai caricato il file training-0.1.tar.gz. Se hai eseguito correttamente i passaggi precedenti, la località è gs://YOUR-BUCKET-NAME/titanic/dist/trainer-0.1.tar.gz, dove YOUR-BUCKET-NAME indica il nome del bucket che hai utilizzato nella sezione Generazione del pacchetto.
Modulo Python: nome del modulo Python che hai creato in Notebooks. Corrisponde al nome della cartella che contiene il tuo codice/modulo di addestramento e a quello del file del punto di accesso, pertanto deve essere trainer.task.
Progetto BigQuery per l'esportazione di dati: nel Passaggio 1 hai selezionato il set di dati e definito una suddivisione automatica. All'interno del progetto selezionato verranno creati i nuovi set di dati e le nuove tabelle per le fasi di addestramento, test e convalida.
Inserisci lo stesso ID progetto utilizzato per il lab.
Inoltre, poiché gli URI dei set di dati per le fasi di addestramento, test e convalida verranno impostati come variabili di ambiente nel container di addestramento, puoi utilizzare automaticamente le variabili corrispondenti per caricare i dati. I nomi delle variabili di ambiente per il set di dati sono: AIP_addestramento_DATA_URI, AIP_TEST_DATA_URI e AIP_convalida_DATA_URI. Viene creata anche la variabile aggiuntiva AIP_DATA_FORMAT, che può essere di tipo csv o bigquery, a seconda del tipo di set di dati selezionato nel Passaggio 1.
Questa logica è già stata creata nel file task.py. Osserva questo esempio di codice (tratto dal file task.py):
...
parser.add_argument( '--training_data_uri ',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_TRAINING_DATA_URI'] if 'AIP_TRAINING_DATA_URI' in os.environ else "" )
...
Directory di output del modello: posizione in cui verrà esportato il modello. Questa informazione verrà inserita nella variabile di ambiente AIP_MODEL_DIR del container di addestramento. Nel file task.py è disponibile un parametro di input per registrare questo valore:
...
parser.add_argument( '--model_dir',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_MODEL_DIR'] if 'AIP_MODEL_DIR' in os.environ else "" )
...
Puoi usare la variabile di ambiente per determinare dove esportare gli artefatti del job di addestramento. Seleziona: gs://YOUR-BUCKET-NAME/titanic/
Fai clic su Continua.
Ottimizzazione degli iperparametri
La sezione Ottimizzazione degli iperparametri consente di definire un set di parametri del modello da utilizzare per l'ottimizzazione del modello. Vengono esaminati diversi valori, allo scopo di generare il modello con i parametri ottimali. Nel tuo codice non hai implementato la funzionalità di ottimizzazione degli iperparametri. Bastano poche righe di codice (circa cinque), ma al momento non è necessario aumentare ulteriormente la complessità.
Seleziona Continua per ignorare questo passaggio.
Calcolo e prezzi
Dove vuoi eseguire il tuo job di addestramento e quale tipo di server desideri utilizzare? Il tuo processo di addestramento del modello non richiede molte risorse. Hai eseguito il job di addestramento all'interno di un'istanza del blocco note relativamente piccola e l'esecuzione è stata piuttosto rapida.
Di conseguenza, puoi selezionare:
Regione:
Tipo di macchina: n1-standard-4
Fai clic su Continua.
Container di previsione
In questo passaggio puoi decidere se vuoi limitarti ad addestrare il modello o aggiungere anche le impostazioni necessarie per il servizio di previsione, che viene utilizzato quando si desidera introdurre il modello nell'ambiente di produzione.
In questo lab utilizzerai un container predefinito. Ricorda tuttavia che in Vertex AI è possibile scegliere fra diverse opzioni per l'erogazione del modello:
Container senza previsione: il modello viene semplicemente addestrato e il passaggio in produzione verrà gestito in un secondo momento.
Container predefinito: viene eseguito l'addestramento del modello e viene specificato il container predefinito da utilizzare per il deployment.
Container personalizzato: viene eseguito l'addestramento del modello e viene specificato un container personalizzato da utilizzare per il deployment.
Poiché Google Cloud offre già un container Scikit-Learn, puoi selezionare Container predefinito. Eseguirai il deployment del modello al termine del job di addestramento.
Framework modello: scikit-learn
Versione framework modello: 0.23
Directory modello: gs://YOUR-BUCKET-NAME/titanic/. Deve coincidere con la directory di output del modello definita nel Passaggio 3.
Fai clic su Inizia addestramento.
Il nuovo job di addestramento verrà visualizzato nella scheda Pipeline di addestramento. L'addestramento richiede circa 15 minuti in tutto.
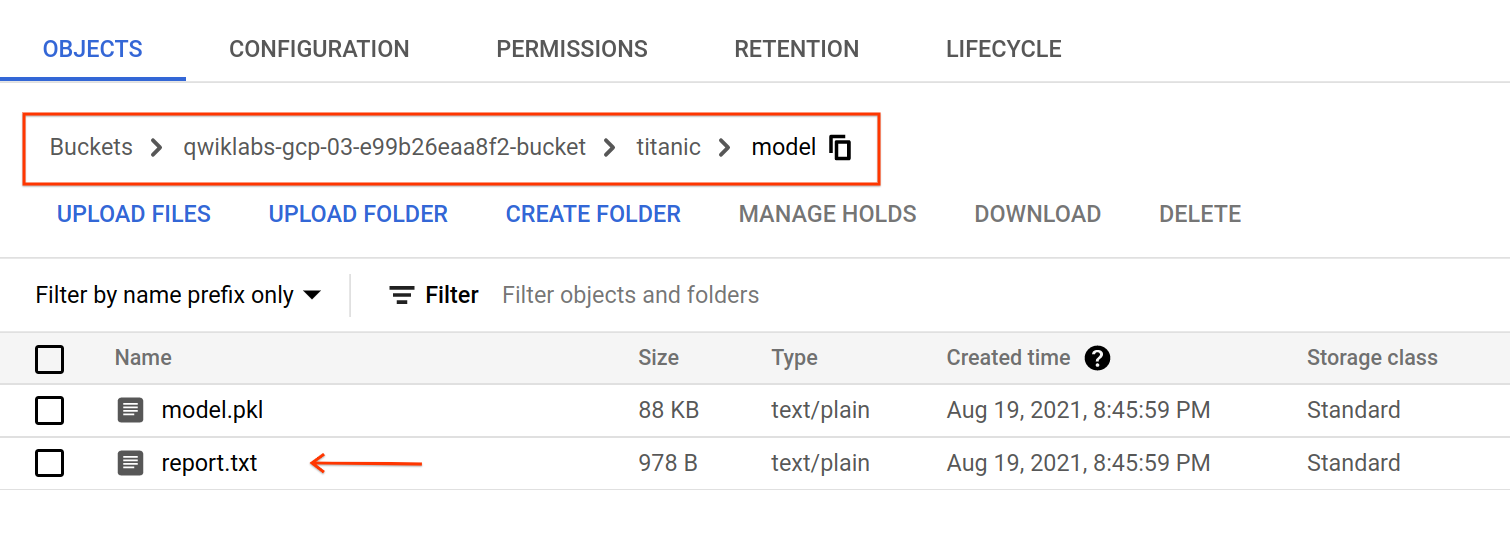
Attività 5: valuta il modello
Al termine del job di addestramento, gli artefatti vengono esportati in gs://YOUR-BUCKET-NAME/titanic/model/. Puoi ispezionare il file report.txt, che contiene le metriche di valutazione e il report di classificazione del modello.
Attività 6: esegui il deployment del modello
Nel menu di navigazione della console Cloud fai clic su Vertex AI > Addestramento.
Al termine del job di addestramento del modello, seleziona il modello addestrato ed eseguine il deployment in un endpoint.
Passa alla scheda DEPLOYMENT E TEST, quindi fai clic su DEPLOYMENT SU ENDPOINT.
Nel popup puoi definire le risorse necessarie per il deployment del modello:
Nome endpoint: URL dell'endpoint il cui viene pubblicato il modello. Nel nostro caso, puoi usare ad esempio titanic-endpoint. Fai clic su Continua.
Suddivisione traffico: indica la percentuale del traffico che desideri indirizzare a questo modello. In un endpoint possono essere presenti più modelli e tu puoi decidere come suddividere il traffico tra di loro. Poiché in questo caso esegui il deployment di un solo modello, la percentuale di traffico deve essere del 100 percento.
Numero minimo di nodi di computing: numero minimo di nodi necessario per generare le previsioni del modello. Inizia con 1. Inoltre, in caso di traffico il servizio di previsione utilizza la scalabilità automatica.
Numero massimo di nodi di computing: se viene utilizzata la scalabilità automatica, questa variabile definisce il numero massimo di nodi, per proteggerti dai costi indesiderati che possono essere generati da questa funzione. Imposta questa variabile su 2.
Tipo di macchina: Google Cloud consente di eseguire il deployment del modello su vari tipi di macchine, ciascuna delle quali dispone di specifiche proprie per memoria e vCPU. Poiché il tuo modello è semplice, è sufficiente gestirlo in un'istanza n1-standard-4.
Fai clic su Fine, quindi su Esegui il deployment.
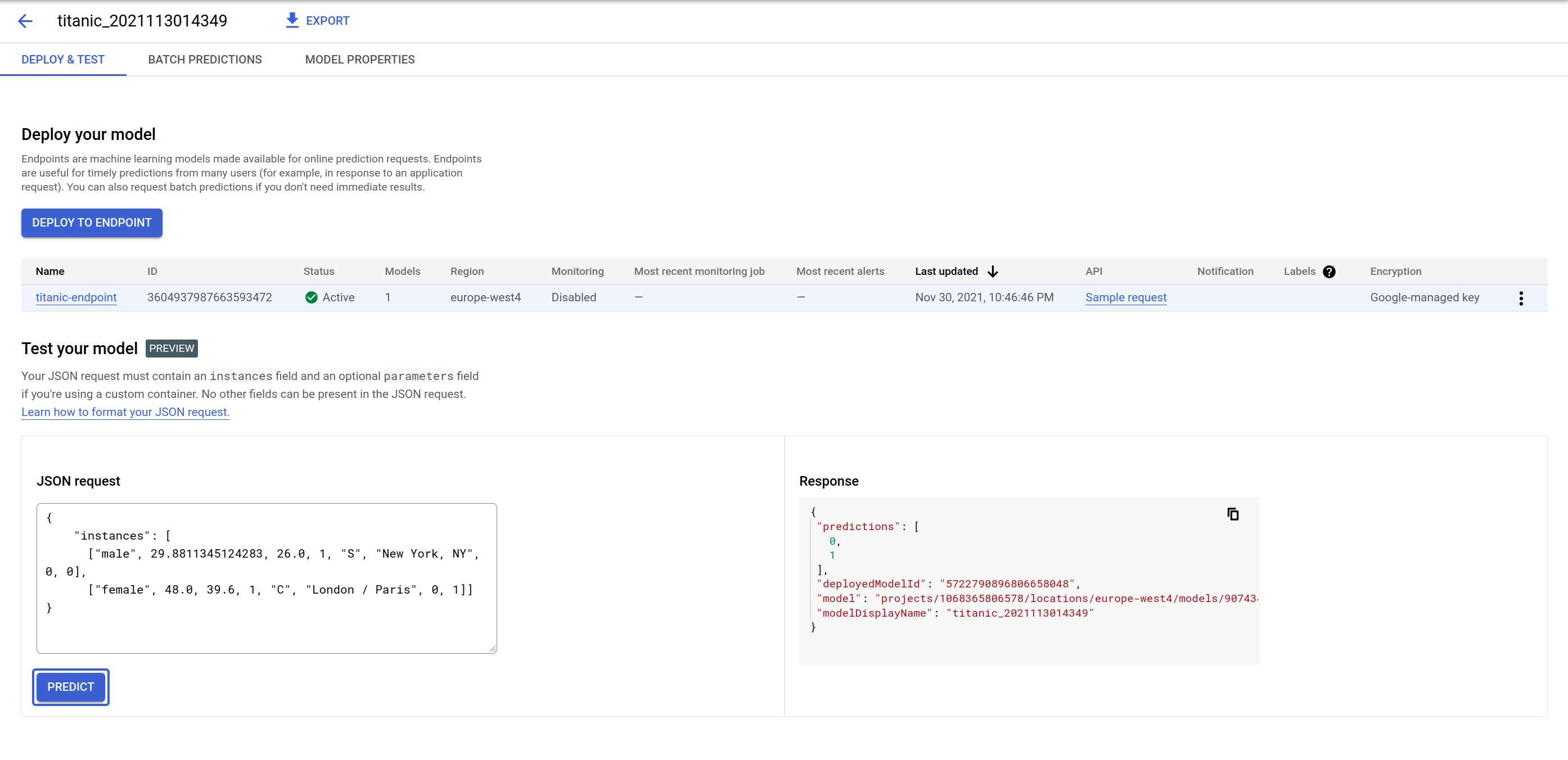
Attività 7: genera la previsione del modello
In Deployment del modello puoi provare l'endpoint di previsione del modello. La GUI fornisce un modulo che consente di inviare un payload di richiesta JSON e restituisce le previsioni, oltre all'ID del modello utilizzato per la previsione, perché è possibile eseguire il deployment di più modelli in uno stesso endpoint e suddividere il traffico.
Prova il payload riportato di seguito, e magari cambia alcuni valori per vedere come cambiano le previsioni. La sequenza delle caratteristiche di input è [‘sex', ‘age', ‘fare', ‘pclass', ‘embarked', ‘home_dest', ‘parch', ‘sibsp'].
L'endpoint restituisce una serie di zeri o uno, nello stesso ordine dell'input. Il valore 0 indica che il soggetto ha scarse probabilità di sopravvivere alla tragedia del Titanic, mentre 1 indica che le probabilità di sopravvivenza sono buone.
Attività 8: esegui la pulizia
Complimenti! Hai creato un set di dati, pacchettizzato il codice di addestramento ed eseguito un job di addestramento personalizzato utilizzando Vertex AI. Inoltre, hai eseguito il deployment del modello addestrato e inviato alcuni dati per le previsioni.
Dato che le risorse create non ti servono, ti suggeriamo di eliminarle per evitare addebiti indesiderati.
Accedi alla pagina del set di dati nella console, fai clic sui tre puntini sulla riga del set di dati che desideri eliminare, quindi fai clic su Elimina set di dati. Fai clic su Elimina per confermare l'eliminazione.
Accedi alla pagina Workbench nella console, seleziona esclusivamente il blocco note da eliminare, quindi fai clic su Elimina sulla barra dei menu superiore. Fai clic su Elimina per confermare l'eliminazione.
Per eliminare l'endpoint implementato in precedenza, fai clic su questo endpoint nella sezione Endpoint della console di Vertex AI, quindi fai clic sul menu extra (), seleziona Annulla il deployment del modello nell'endpoint e infine fai clic su Annulla deployment.
Per rimuovere l'endpoint, fai clic sull'icona del menu extra () e seleziona Elimina endpoint. Quindi, fai clic su Conferma.
Passa alla pagina Modelli nella console, fai clic sui tre puntini () sulla riga del modello da eliminare e fai clic su Elimina modello. Quindi, fai clic su Elimina.
Per eliminare il bucket Cloud Storage, seleziona il bucket nella pagina Cloud Storage e fai clic su Elimina. Digita DELETE per confermare l'eliminazione, quindi fai clic su Elimina.
Per eliminare il set di dati di BigQuery, procedi come segue:
Accedi alla console BigQuery.
Nel riquadro di esplorazione, fai clic sull'icona Visualizza azioni accanto al tuo set di dati. Fai clic su Elimina.
Nella finestra di dialogo Elimina set di dati, digita delete per confermare l'eliminazione, quindi fai clic su Elimina.
Terminare il lab
Una volta completato il lab, fai clic su Termina lab. Qwiklabs rimuove le risorse che hai utilizzato ed esegue la pulizia dell'account.
Avrai la possibilità di inserire una valutazione in merito alla tua esperienza. Seleziona il numero di stelle applicabile, inserisci un commento, quindi fai clic su Invia.
Il numero di stelle corrisponde alle seguenti valutazioni:
1 stella = molto insoddisfatto
2 stelle = insoddisfatto
3 stelle = esperienza neutra
4 stelle = soddisfatto
5 stelle = molto soddisfatto
Se non vuoi lasciare un feedback, chiudi la finestra di dialogo.
Per feedback, suggerimenti o correzioni, utilizza la scheda Assistenza.
Copyright 2020 Google LLC Tutti i diritti riservati. Google e il logo Google sono marchi di Google LLC. Tutti gli altri nomi di società e prodotti sono marchi delle rispettive società a cui sono associati.
I lab creano un progetto e risorse Google Cloud per un periodo di tempo prestabilito
I lab hanno un limite di tempo e non possono essere messi in pausa. Se termini il lab, dovrai ricominciare dall'inizio.
In alto a sinistra dello schermo, fai clic su Inizia il lab per iniziare
Utilizza la navigazione privata
Copia il nome utente e la password forniti per il lab
Fai clic su Apri console in modalità privata
Accedi alla console
Accedi utilizzando le tue credenziali del lab. L'utilizzo di altre credenziali potrebbe causare errori oppure l'addebito di costi.
Accetta i termini e salta la pagina di ripristino delle risorse
Non fare clic su Termina lab a meno che tu non abbia terminato il lab o non voglia riavviarlo, perché il tuo lavoro verrà eliminato e il progetto verrà rimosso
Questi contenuti non sono al momento disponibili
Ti invieremo una notifica via email quando sarà disponibile
Bene.
Ti contatteremo via email non appena sarà disponibile
Un lab alla volta
Conferma per terminare tutti i lab esistenti e iniziare questo
Utilizza la navigazione privata per eseguire il lab
Utilizza una finestra del browser in incognito o privata per eseguire questo lab. In questo modo eviterai eventuali conflitti tra il tuo account personale e l'account Studente, che potrebbero causare addebiti aggiuntivi sul tuo account personale.
In questo lab puoi usare Vertex AI per addestrare un modello ML ed eseguirne il deployment.
Durata:
Configurazione in 0 m
·
Accesso da 120 m
·
Completamento in 120 m
 ) accanto a tuo ID progetto, quindi seleziona Crea set di dati.
) accanto a tuo ID progetto, quindi seleziona Crea set di dati.