Dans cet atelier, vous pouvez utiliser Vertex AI pour entraîner et déployer un modèle de ML. Nous partons du principe que vous connaissez bien le machine learning, même si le code de machine learning de cet entraînement vous est fourni. Vous utiliserez des ensembles de données quand vous aurez à en créer et à en gérer, ainsi qu'un modèle personnalisé dont vous vous servirez pour entraîner un modèle scikit-learn. Enfin, vous déploierez le modèle entraîné et vous obtiendrez des prédictions en ligne. L'ensemble de données que vous utiliserez pour cette démo est l'ensemble de données Titanic.
Objectifs
Créer un ensemble de données pour des données tabulaires
Créer un package d'entraînement avec du code personnalisé à l'aide de Notebooks
Déployer le modèle entraîné et obtenir des prédictions en ligne
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Qwiklabs dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à Google Cloud Console.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Veillez à sélectionner le bon projet en haut de la page de la console.
Dans le panneau Explorateur, cliquez sur Afficher les actions () à côté de l'ID de votre projet et sélectionnez Créer un ensemble de données.
Un pop-up s'affiche.
Saisissez titanic pour l'ID de l'ensemble de données et utilisez pour la région dans l'emplacement des données, puis cliquez sur Créer un ensemble de données.
Vous avez maintenant créé l'ensemble de données.
Créer une table
Vous avez besoin d'une table pour charger vos données.
Remarque : Si vous rencontrez des problèmes lorsque vous téléchargez l'ensemble de données en mode navigation privée, téléchargez-le depuis une fenêtre normale.
Renommez l'ensemble de données téléchargé titanic_toy.csv.
Puis, dans l'UI :
Ouvrez l'ensemble de données titanic que vous avez créé à l'étape précédente. (Cliquez sur Afficher les actions [] à côté de l'ensemble de données et sélectionnez Ouvrir.)
Cliquez sur Créer une table et spécifiez les éléments suivants :
Créer une table à partir de : Importer
Sélectionner un fichier : utilisez l'ensemble de données Titanic téléchargé
Format de fichier : CSV
Nom de la table : survivors
Détection automatique : sélectionnez la détection automatique en cochant la case Schéma
Cliquez sur Créer une table.
Cliquez sur l'icône Afficher les actions à côté de la table survivors et sélectionnez Copier l'identifiant. Enregistrez l'ID de table que vous avez copié. Vous en aurez besoin plus tard dans l'atelier.
Vous avez maintenant créé la table et vous avez inséré les données de l'ensemble Titanic. Vous pouvez explorer son contenu, exécuter des requêtes et analyser vos données.
Tâche 2. Créer un ensemble de données
Les ensembles de données de Vertex AI vous permettent de créer des ensembles de données pour vos charges de travail de machine learning. Vous pouvez créer des ensembles de données pour des données structurées (des fichiers CSV ou des tables BigQuery) ou non structurées (telles que des images et du texte). Il est important de noter que les ensembles de données Vertex AI ne font que référencer vos données d'origine et qu'il n'y a pas de duplication.
Créer un ensemble de données de ML
Dans le Menu de navigation de la console Google Cloud, sélectionnez Vertex AI > Ensembles de données.
Sélectionnez , puis cliquez sur Créer.
Spécifiez un nom pour votre ensemble de données. Vous pouvez par exemple l'appeler titanic.
Vous pouvez créer des ensembles de données pour des images, du texte ou des vidéos, ainsi que pour des données tabulaires.
L'ensemble de données Titanic étant tabulaire, vous devez cliquer sur l'onglet Tabulaire.
Pour sélectionner une région, sélectionnez , puis cliquez sur Créer.
À ce stade, vous venez de créer un espace réservé. Vous ne vous êtes pas encore connecté à la source de données. Vous le ferez à l'étape suivante.
Sélectionner une source de données
Étant donné que vous avez déjà chargé l'ensemble de données Titanic dans BigQuery, vous pouvez connecter votre ensemble de données de ML à votre table BigQuery.
Choisissez Sélectionner une table ou une vue à partir de BigQuery.
Dans le champ PARCOURIR, collez l'ID de table que vous avez copié.
Sélectionnez l'ensemble de données, puis cliquez sur Continuer.
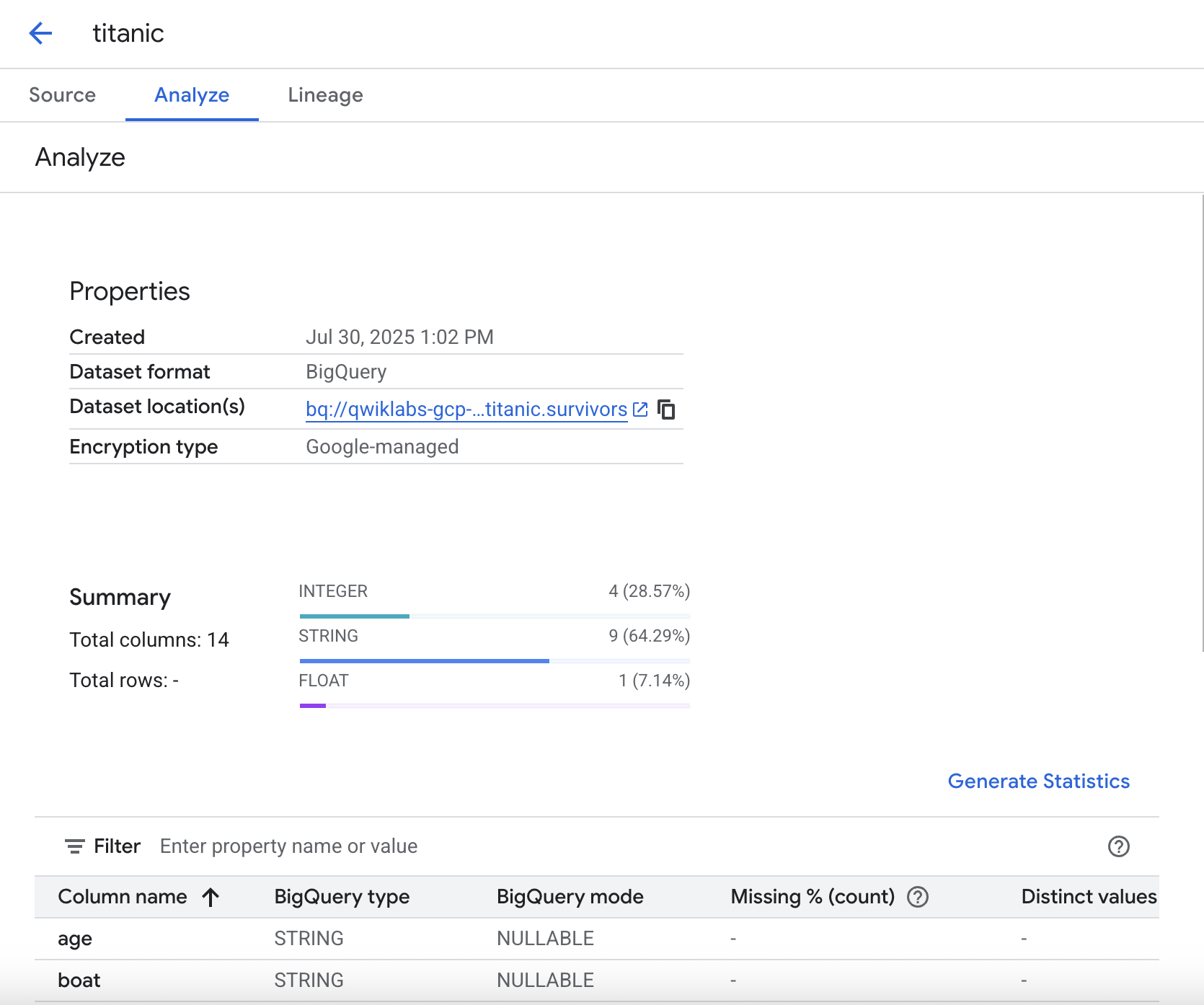
Générer des statistiques
Vous pouvez générer des statistiques sur vos données dans l'onglet Analyser. Cela vous permet d'obtenir rapidement un aperçu des données et de contrôler les répartitions, les valeurs manquantes, etc.
Cliquez sur Générer des statistiques pour exécuter l'analyse statistique. L'exécution peut prendre quelques minutes. Si vous le souhaitez, vous pouvez donc continuer l'atelier et revenir consulter les résultats ultérieurement.
Tâche 3 : Créer un package d'entraînement personnalisé à l'aide de Workbench
Nous vous recommandons de placer votre code dans un package et d'en définir les paramètres pour en faire une ressource portable.
Dans cette section, vous allez créer un package d'entraînement avec du code personnalisé à l'aide de Vertex AI Workbench. Pour pouvoir utiliser le service, il est fondamental que vous sachiez créer une distribution source Python. On parle aussi de package de distribution. Cela revient en fait à créer des dossiers et des fichiers dans le package de distribution. La section suivante s'attache à expliquer comment un package est structuré.
Structure de l'application
La structure de base d'un package Python se présente comme illustré ci-dessous.
Voyons à quoi servent ces dossiers et ces fichiers :
titanic-package : c'est votre répertoire de travail. Ce dossier contiendra votre package et le code relatif au classificateur "survivor" de Titanic.
setup.py : le fichier de configuration indique comment votre package de distribution doit être créé. lI contient des informations telles que le nom du package, sa version ainsi que les autres packages dont vous pourriez avoir besoin pour votre job d'entraînement et qui ne sont pas inclus par défaut dans les conteneurs d'entraînement prédéfinis de GCP.
trainer : c'est le dossier qui contient le code d'entraînement. Il s'agit aussi d'un package Python. C'est le fichier vide __init__.py que l'on trouve dans ce dossier qui fait de celui-ci un package.
__init__.py : fichier vide nommé __init__.py. Sa présence dans un dossier fait de celui-ci un package.
task.py : task.py est un module de package. Il s'agit du point d'entrée de votre code. Il accepte aussi les paramètres de CLI pour l'entraînement de modèle. Vous pouvez placer votre code d'entraînement dans ce module ou créer des modules supplémentaires dans votre package. Le choix vous appartient et dépend de la façon dont vous voulez structurer votre code.
Maintenant que vous savez à quoi correspond la structure, il est temps de préciser que les noms du package et du module ne doivent pas nécessairement être "trainer" et "task.py". Dans cet atelier, nous nous servons de ces noms qui sont ceux utilisés dans notre documentation en ligne, mais vous pouvez choisir ceux qui vous conviennent le mieux.
Créer votre instance de notebook
Nous allons maintenant créer une instance de notebook et essayer d'entraîner un modèle personnalisé.
Dans le menu de navigation de la console Google Cloud, cliquez sur Vertex AI > Workbench.
Sur la page "Instances de notebook", cliquez sur Créer et démarrez une instance avec Python 3, qui inclut scikit-learn. Vous allez utiliser un modèle scikit-learn pour votre classificateur.
Un pop-up s'affiche. Vous pouvez ici modifier des paramètres tels que la région dans laquelle votre instance de notebook sera créée et la puissance de calcul dont vous avez besoin.
Étant donné que vous ne devez pas traiter de grandes quantités de données et que vous n'avez besoin de l'instance qu'à des fins de développement, ne modifiez aucun des paramètres. Il vous suffit de cliquer sur Créer.
Il ne faudra que quelques minutes pour que l'instance soit opérationnelle.
Quand elle sera prête, vous pourrez ouvrir Jupyterlab.
Lorsque le pop-up "Compilation recommandée" s'affiche, cliquez sur "Compiler". Si le message "Échec de la compilation" apparaît, ignorez-le.
Créer votre package
Maintenant que le notebook est opérationnel, vous pouvez commencer à créer vos ressources d'entraînement.
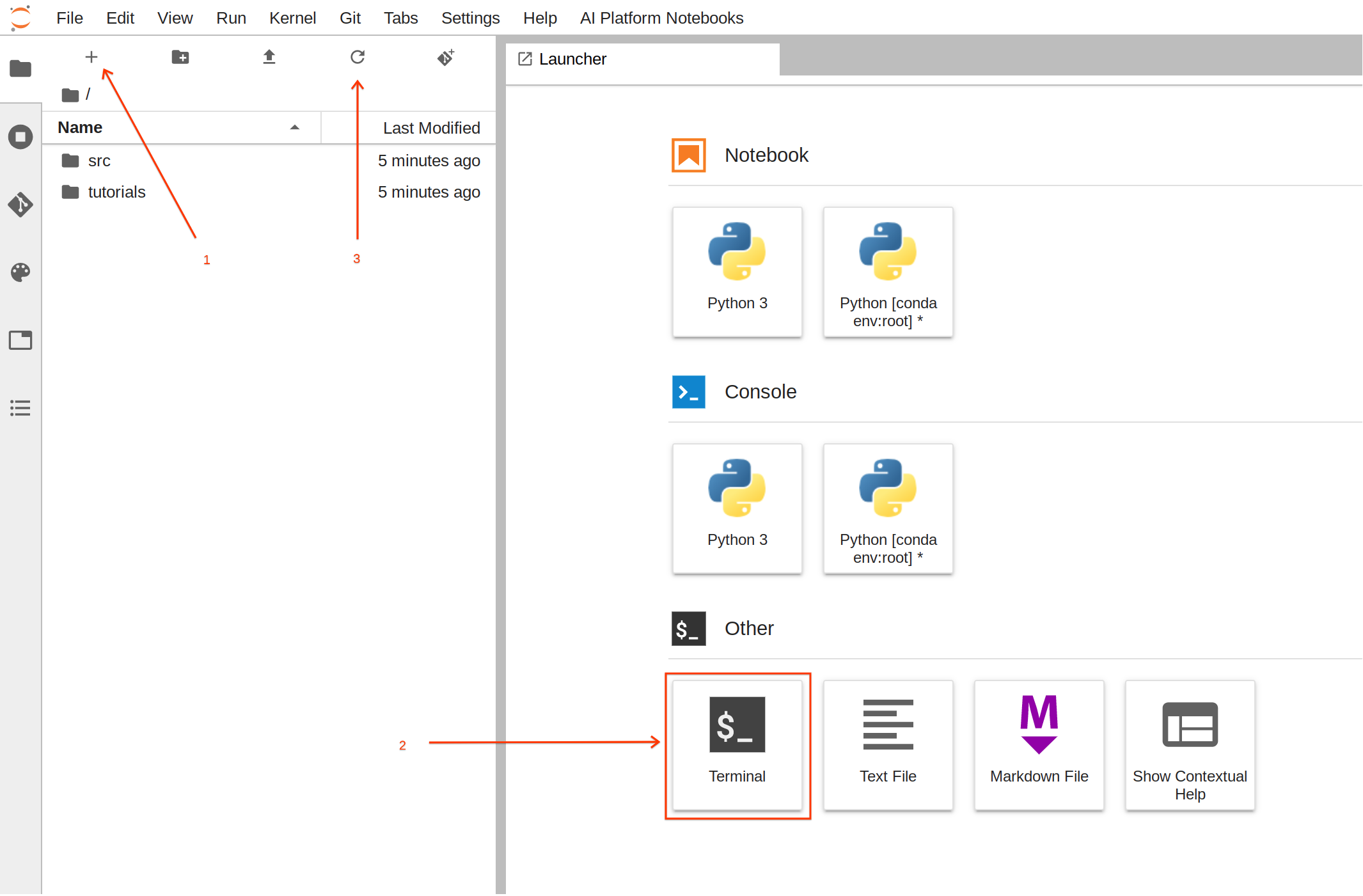
Pour cette tâche, il est plus simple d'utiliser le terminal.
À partir du lanceur, cliquez sur Terminal pour créer une session de terminal.
Une fois que vous êtes dans le terminal, exécutez les commandes suivantes pour créer la structure de dossiers avec les fichiers requis :
Quand vous aurez exécuté les commandes, cliquez sur le bouton d'actualisation pour voir le dossier et les fichiers nouvellement créés.
Copiez et collez le code suivant dans titanic/trainer/task.py. Le code contenant des commentaires, vous pouvez passer quelques minutes à parcourir le fichier pour mieux le comprendre :
from google.cloud import bigquery, bigquery_storage, storage
from sklearn.pipeline import make_pipeline, Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder, OrdinalEncoder
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
from sklearn.metrics import classification_report, f1_score
from typing import Union, List
import os, logging, json, pickle, argparse
import dask.dataframe as dd
import pandas as pd
import numpy as np
# feature selection. The FEATURE list defines what features are needed from the training data
# as well as the types of those features. We will perform different feature engineering depending on the type.
# List all column names for binary features: 0,1 or True,False or Male,Female etc
BINARY_FEATURES = [
'sex']
# List all column names for numeric features
NUMERIC_FEATURES = [
'age',
'fare']
# List all column names for categorical features
CATEGORICAL_FEATURES = [
'pclass',
'embarked',
'home_dest',
'parch',
'sibsp']
ALL_COLUMNS = BINARY_FEATURES+NUMERIC_FEATURES+CATEGORICAL_FEATURES
# define the column name for label
LABEL = 'survived'
# Define the index position of each feature. This is needed for processing a
# numpy array (instead of pandas) which has no column names.
BINARY_FEATURES_IDX = list(range(0,len(BINARY_FEATURES)))
NUMERIC_FEATURES_IDX = list(range(len(BINARY_FEATURES), len(BINARY_FEATURES)+len(NUMERIC_FEATURES)))
CATEGORICAL_FEATURES_IDX = list(range(len(BINARY_FEATURES+NUMERIC_FEATURES), len(ALL_COLUMNS)))
def load_data_from_gcs(data_gcs_path: str) -> pd.DataFrame:
'''
Loads data from Google Cloud Storage (GCS) to a dataframe
Parameters:
data_gcs_path (str): gs path for the location of the data. Wildcards are also supported. i.e gs://example_bucket/data/training-*.csv
Returns:
pandas.DataFrame: a dataframe with the data from GCP loaded
'''
# using dask that supports wildcards to read multiple files. Then with dd.read_csv().compute we create a pandas dataframe
# Additionally I have noticed that some values for TotalCharges are missing and this creates confusion regarding TotalCharges as the data type.
# to overcome this we manually define TotalCharges as object.
# We will later fix this abnormality
logging.info("reading gs data: {}".format(data_gcs_path))
return dd.read_csv(data_gcs_path, dtype={'TotalCharges': 'object'}).compute()
def load_data_from_bq(bq_uri: str) -> pd.DataFrame:
'''
Loads data from BigQuery table (BQ) to a dataframe
Parameters:
bq_uri (str): bq table uri. i.e: example_project.example_dataset.example_table
Returns:
pandas.DataFrame: a dataframe with the data from GCP loaded
'''
if not bq_uri.startswith('bq://'):
raise Exception("uri is not a BQ uri. It should be bq://project_id.dataset.table")
logging.info("reading bq data: {}".format(bq_uri))
project,dataset,table = bq_uri.split(".")
bqclient = bigquery.Client(project=project[5:])
bqstorageclient = bigquery_storage.BigQueryReadClient()
query_string = """
SELECT * from {ds}.{tbl}
""".format(ds=dataset, tbl=table)
return (
bqclient.query(query_string)
.result()
.to_dataframe(bqstorage_client=bqstorageclient)
)
def clean_missing_numerics(df: pd.DataFrame, numeric_columns):
'''
removes invalid values in the numeric columns
Parameters:
df (pandas.DataFrame): The Pandas Dataframe to alter
numeric_columns (List[str]): List of column names that are numeric from the DataFrame
Returns:
pandas.DataFrame: a dataframe with the numeric columns fixed
'''
for n in numeric_columns:
df[n] = pd.to_numeric(df[n], errors='coerce')
df = df.fillna(df.mean())
return df
def data_selection(df: pd.DataFrame, selected_columns: List[str], label_column: str) -> (pd.DataFrame, pd.Series):
'''
From a dataframe it creates a new dataframe with only selected columns and returns it.
Additionally it splits the label column into a pandas Series.
Parameters:
df (pandas.DataFrame): The Pandas Dataframe to drop columns and extract label
selected_columns (List[str]): List of strings with the selected columns. i,e ['col_1', 'col_2', ..., 'col_n' ]
label_column (str): The name of the label column
Returns:
tuple(pandas.DataFrame, pandas.Series): Tuble with the new pandas DataFrame containing only selected columns and lablel pandas Series
'''
# We create a series with the prediciton label
labels = df[label_column].astype(int)
data = df.loc[:, selected_columns]
return data, labels
def pipeline_builder(params_svm: dict, bin_ftr_idx: List[int], num_ftr_idx: List[int], cat_ftr_idx: List[int]) -> Pipeline:
'''
Builds a sklearn pipeline with preprocessing and model configuration.
Preprocessing steps are:
* OrdinalEncoder - used for binary features
* StandardScaler - used for numerical features
* OneHotEncoder - used for categorical features
Model used is SVC
Parameters:
params_svm (dict): List of parameters for the sklearn.svm.SVC classifier
bin_ftr_idx (List[str]): List of ints that mark the column indexes with binary columns. i.e [0, 2, ... , X ]
num_ftr_idx (List[str]): List of ints that mark the column indexes with numerical columns. i.e [6, 3, ... , X ]
cat_ftr_idx (List[str]): List of ints that mark the column indexes with categorical columns. i.e [5, 10, ... , X ]
label_column (str): The name of the label column
Returns:
Pipeline: sklearn.pipelines.Pipeline with preprocessing and model training
'''
# Defining a preprocessing step for our pipeline.
# it specifies how the features are going to be transformed
preprocessor = ColumnTransformer(
transformers=[
('bin', OrdinalEncoder(), bin_ftr_idx),
('num', StandardScaler(), num_ftr_idx),
('cat', OneHotEncoder(handle_unknown='ignore'), cat_ftr_idx)], n_jobs=-1)
# We now create a full pipeline, for preprocessing and training.
# for training we selected a linear SVM classifier
clf = SVC()
clf.set_params(**params_svm)
return Pipeline(steps=[ ('preprocessor', preprocessor),
('classifier', clf)])
def train_pipeline(clf: Pipeline, X: Union[pd.DataFrame, np.ndarray], y: Union[pd.DataFrame, np.ndarray]) -> float:
'''
Trains a sklearn pipeline by fiting training data and labels and returns the accuracy f1 score
Parameters:
clf (sklearn.pipelines.Pipeline): the Pipeline object to fit the data
X: (pd.DataFrame OR np.ndarray): Training vectors of shape n_samples x n_features, where n_samples is the number of samples and n_features is the number of features.
y: (pd.DataFrame OR np.ndarray): Labels of shape n_samples. Order should mathc Training Vectors X
Returns:
score (float): Average F1 score from all cross validations
'''
# run cross validation to get training score. we can use this score to optimize training
score = cross_val_score(clf, X, y, cv=10, n_jobs=-1).mean()
# Now we fit all our data to the classifier.
clf.fit(X, y)
return score
def process_gcs_uri(uri: str) -> (str, str, str, str):
'''
Receives a Google Cloud Storage (GCS) uri and breaks it down to the scheme, bucket, path and file
Parameters:
uri (str): GCS uri
Returns:
scheme (str): uri scheme
bucket (str): uri bucket
path (str): uri path
file (str): uri file
'''
url_arr = uri.split("/")
if "." not in url_arr[-1]:
file = ""
else:
file = url_arr.pop()
scheme = url_arr[0]
bucket = url_arr[2]
path = "/".join(url_arr[3:])
path = path[:-1] if path.endswith("/") else path
return scheme, bucket, path, file
def pipeline_export_gcs(fitted_pipeline: Pipeline, model_dir: str) -> str:
'''
Exports trained pipeline to GCS
Parameters:
fitted_pipeline (sklearn.pipelines.Pipeline): the Pipeline object with data already fitted (trained pipeline object)
model_dir (str): GCS path to store the trained pipeline. i.e gs://example_bucket/training-job
Returns:
export_path (str): Model GCS location
'''
scheme, bucket, path, file = process_gcs_uri(model_dir)
if scheme != "gs:":
raise ValueError("URI scheme must be gs")
# Upload the model to GCS
b = storage.Client().bucket(bucket)
export_path = os.path.join(path, 'model.pkl')
blob = b.blob(export_path)
blob.upload_from_string(pickle.dumps(fitted_pipeline))
return scheme + "//" + os.path.join(bucket, export_path)
def prepare_report(cv_score: float, model_params: dict, classification_report: str, columns: List[str], example_data: np.ndarray) -> str:
'''
Prepares a training report in Text
Parameters:
cv_score (float): score of the training job during cross validation of training data
model_params (dict): dictonary containing the parameters the model was trained with
classification_report (str): Model classification report with test data
columns (List[str]): List of columns that where used in training.
example_data (np.array): Sample of data (2-3 rows are enough). This is used to include what the prediciton payload should look like for the model
Returns:
report (str): Full report in text
'''
buffer_example_data = '['
for r in example_data:
buffer_example_data+='['
for c in r:
if(isinstance(c,str)):
buffer_example_data+="'"+c+"', "
else:
buffer_example_data+=str(c)+", "
buffer_example_data= buffer_example_data[:-2]+"], \n"
buffer_example_data= buffer_example_data[:-3]+"]"
report = """
Training Job Report
Cross Validation Score: {cv_score}
Training Model Parameters: {model_params}
Test Data Classification Report:
{classification_report}
Example of data array for prediciton:
Order of columns:
{columns}
Example for clf.predict()
{predict_example}
Example of GCP API request body:
{{
"instances": {json_example}
}}
""".format(
cv_score=cv_score,
model_params=json.dumps(model_params),
classification_report=classification_report,
columns = columns,
predict_example = buffer_example_data,
json_example = json.dumps(example_data.tolist()))
return report
def report_export_gcs(report: str, report_dir: str) -> None:
'''
Exports training job report to GCS
Parameters:
report (str): Full report in text to sent to GCS
report_dir (str): GCS path to store the report model. i.e gs://example_bucket/training-job
Returns:
export_path (str): Report GCS location
'''
scheme, bucket, path, file = process_gcs_uri(report_dir)
if scheme != "gs:":
raise ValueError("URI scheme must be gs")
# Upload the model to GCS
b = storage.Client().bucket(bucket)
export_path = os.path.join(path, 'report.txt')
blob = b.blob(export_path)
blob.upload_from_string(report)
return scheme + "//" + os.path.join(bucket, export_path)
# Define all the command-line arguments your model can accept for training
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# Input Arguments
parser.add_argument(
'--model_param_kernel',
help = 'SVC model parameter- kernel',
choices=['linear', 'poly', 'rbf', 'sigmoid', 'precomputed'],
type = str,
default = 'linear'
)
parser.add_argument(
'--model_param_degree',
help = 'SVC model parameter- Degree. Only applies for poly kernel',
type = int,
default = 3
)
parser.add_argument(
'--model_param_C',
help = 'SVC model parameter- C (regularization)',
type = float,
default = 1.0
)
parser.add_argument(
'--model_param_probability',
help = 'Whether to enable probability estimates',
type = bool,
default = True
)
'''
Vertex AI automatically populates a set of environment variables in the container that executes
your training job. Those variables include:
* AIP_MODEL_DIR - Directory selected as model dir
* AIP_DATA_FORMAT - Type of dataset selected for training (can be csv or bigquery)
Vertex AI will automatically split selected dataset into training, validation and testing
and 3 more environment variables will reflect the location of the data:
* AIP_TRAINING_DATA_URI - URI of Training data
* AIP_VALIDATION_DATA_URI - URI of Validation data
* AIP_TEST_DATA_URI - URI of Test data
Notice that those environment variables are default. If the user provides a value using CLI argument,
the environment variable will be ignored. If the user does not provide anything as CLI argument
the program will try and use the environment variables if those exist. Otherwise will leave empty.
'''
parser.add_argument(
'--model_dir',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_MODEL_DIR'] if 'AIP_MODEL_DIR' in os.environ else ""
)
parser.add_argument(
'--data_format',
choices=['csv', 'bigquery'],
help = 'format of data uri csv for gs:// paths and bigquery for project.dataset.table formats',
type = str,
default = os.environ['AIP_DATA_FORMAT'] if 'AIP_DATA_FORMAT' in os.environ else "csv"
)
parser.add_argument(
'--training_data_uri',
help = 'location of training data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_TRAINING_DATA_URI'] if 'AIP_TRAINING_DATA_URI' in os.environ else ""
)
parser.add_argument(
'--validation_data_uri',
help = 'location of validation data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_VALIDATION_DATA_URI'] if 'AIP_VALIDATION_DATA_URI' in os.environ else ""
)
parser.add_argument(
'--test_data_uri',
help = 'location of test data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_TEST_DATA_URI'] if 'AIP_TEST_DATA_URI' in os.environ else ""
)
parser.add_argument("-v", "--verbose", help="increase output verbosity",
action="store_true")
args = parser.parse_args()
arguments = args.__dict__
if args.verbose:
logging.basicConfig(level=logging.INFO)
logging.info('Model artifacts will be exported here: {}'.format(arguments['model_dir']))
logging.info('Data format: {}'.format(arguments["data_format"]))
logging.info('Training data uri: {}'.format(arguments['training_data_uri']) )
logging.info('Validation data uri: {}'.format(arguments['validation_data_uri']))
logging.info('Test data uri: {}'.format(arguments['test_data_uri']))
'''
We have 2 different ways to load our data to pandas. One is from Cloud Storage by loading csv files and
the other is by connecting to BigQuery. Vertex AI supports both and
here we created a code that depending on the dataset provided. We will select the appropriate loading method.
'''
logging.info('Loading {} data'.format(arguments["data_format"]))
if(arguments['data_format']=='csv'):
df_train = load_data_from_gcs(arguments['training_data_uri'])
df_test = load_data_from_bq(arguments['test_data_uri'])
df_valid = load_data_from_gcs(arguments['validation_data_uri'])
elif(arguments['data_format']=='bigquery'):
print(arguments['training_data_uri'])
df_train = load_data_from_bq(arguments['training_data_uri'])
df_test = load_data_from_bq(arguments['test_data_uri'])
df_valid = load_data_from_bq(arguments['validation_data_uri'])
else:
raise ValueError("Invalid data type ")
#as we will be using cross validation, we will have just a training set and a single test set.
# we will merge the test and validation to achieve an 80%-20% split
df_test = pd.concat([df_test,df_valid])
logging.info('Defining model parameters')
model_params = dict()
model_params['kernel'] = arguments['model_param_kernel']
model_params['degree'] = arguments['model_param_degree']
model_params['C'] = arguments['model_param_C']
model_params['probability'] = arguments['model_param_probability']
df_train = clean_missing_numerics(df_train, NUMERIC_FEATURES)
df_test = clean_missing_numerics(df_test, NUMERIC_FEATURES)
logging.info('Running feature selection')
X_train, y_train = data_selection(df_train, ALL_COLUMNS, LABEL)
X_test, y_test = data_selection(df_test, ALL_COLUMNS, LABEL)
logging.info('Training pipelines in CV')
y_train = y_train.astype('int')
y_test = y_test.astype('int')
clf = pipeline_builder(model_params, BINARY_FEATURES_IDX, NUMERIC_FEATURES_IDX, CATEGORICAL_FEATURES_IDX)
cv_score = train_pipeline(clf, X_train, y_train)
logging.info('Export trained pipeline and report')
pipeline_export_gcs(clf, arguments['model_dir'])
y_pred = clf.predict(X_test)
test_score = f1_score(y_test, y_pred, average='weighted')
logging.info('f1score: '+ str(test_score))
report = prepare_report(cv_score,
model_params,
classification_report(y_test,y_pred),
ALL_COLUMNS,
X_test.to_numpy()[0:2])
report_export_gcs(report, arguments['model_dir'])
logging.info('Training job completed. Exiting...')
Appuyez sur Ctrl+S pour enregistrer le fichier.
Créer votre package
Il est maintenant temps de créer votre package afin de l'utiliser avec le service d'entraînement.
Copiez et collez le code suivant dans titanic/setup.py :
from setuptools import find_packages
from setuptools import setup
REQUIRED_PACKAGES = [
'gcsfs==0.7.1',
'dask[dataframe]==2021.2.0',
'google-cloud-bigquery-storage==1.0.0',
'six==1.15.0'
]
setup(
name='trainer',
version='0.1',
install_requires=REQUIRED_PACKAGES,
packages=find_packages(), # Automatically find packages within this directory or below.
include_package_data=True, # if packages include any data files, those will be packed together.
description='Classification training titanic survivors prediction model'
)
Appuyez sur Ctrl+S pour enregistrer le fichier.
Retournez dans votre terminal et vérifiez si vous pouvez entraîner un modèle à l'aide de task.py.
Commencez par créer les variables d'environnement suivantes, mais n'oubliez pas de vous assurer que vous avez sélectionné le bon projet GCP dans la console :
La variable d'environnement PROJECT_ID sera définie sur l'ID du projet sélectionné.
La variable d'environnement BUCKET_NAME sera définie sur la valeur de PROJECT_ID suivie de "-bucket".
export REGION="{{{project_0.default_region|Region}}}"
export PROJECT_ID=$(gcloud config list --format 'value(core.project)')
export BUCKET_NAME=$PROJECT_ID"-bucket"
Créez le bucket dans lequel vous voulez exporter votre modèle entraîné :
gsutil mb -l $REGION "gs://"$BUCKET_NAME
Exécutez maintenant les commandes suivantes. Vous utilisez l'intégralité de vos données d'entraînement pour le test. Le même ensemble de données est utilisé pour le test, la validation et l'entraînement. Vous voulez ici vous assurer que le code s'exécute et qu'il est exempt de bugs. Vous voudrez en réalité utiliser des données différentes pour le test et la validation. Vous laisserez le service d'entraînement Vertex AI se charger de cela.
Commencez par installer les bibliothèques requises.
cd /home/jupyter/titanic
pip install setuptools
python setup.py install
Remarque : Vous pouvez ignorer le message d'erreur error: google-auth 2.3.3 is installed but google-auth<2.0dev,>=1.25.0 is required by {'google-api-core'}, car il n'a pas d'incidence sur les fonctionnalités de l'atelier.
Vérifiez maintenant que votre code d'entraînement s'exécute sans problème :
Si le code s'exécute correctement, vous pourrez voir des messages de journalisation de niveau INFO. Les deux lignes ont trait au score F1, qui doit être environ de 0,85, et la dernière indique que le job d'entraînement s'est correctement terminé :
C'est exactement ce que fait la commande suivante :
cd /home/jupyter/titanic
python setup.py sdist
Une fois la commande exécutée, vous verrez un nouveau dossier appelé dist contenant un fichier tar.gz. C'est votre package Python.
Vous devez copier le package dans GCS afin que le service d'entraînement puisse l'utiliser pour entraîner un nouveau modèle quand vous en aurez besoin :
Dans cette section, vous allez entraîner un modèle sur Vertex AI. Vous allez pour cela vous servir de l'interface utilisateur. Vous pouvez également parvenir à ce résultat en ayant recours à la programmation avec un SDK Python. Toutefois, le fait de vous servir de l'interface utilisateur vous aidera à mieux comprendre la procédure.
Dans la console Google Cloud, accédez à Vertex AI > Entraînement.
Sélectionnez la région .
Cliquez sur Entraîner un nouveau modèle.
Méthode d'entraînement
À cette étape, vous allez sélectionner l'ensemble de données et définir l'objectif du job d'entraînement.
Ensemble de données : l'ensemble de données que vous avez créé lors d'une étape précédente. Il doit s'appeler titanic.
Objectif : le modèle prédit si une personne était susceptible de survivre à la tragédie du Titanic. C'est un problème de classification.
Le nom par défaut doit être le nom de l'ensemble de données assorti d'un code temporel. Vous pouvez le laisser tel quel.
Si vous cliquez sur Options avancées, vous verrez l'option permettant de définir la répartition des données entre les ensembles d'entraînement, de test et de validation. L'attribution aléatoire répartit aléatoirement les données entre ces trois ensembles. Cela semble être une bonne façon de procéder.
Cliquez sur Continuer.
Conteneur d'entraînement
Définissez votre environnement d'entraînement.
Conteneur prédéfini : Google Cloud propose un ensemble de conteneurs prédéfinis qui facilitent l'entraînement de vos modèles. Ces conteneurs sont compatibles avec des frameworks tels que scikit-learn, TensorFlow et XGBoost. Si votre job d'entraînement utilise un élément atypique, vous devrez préparer et fournir un conteneur (personnalisé) pour l'entraînement. Votre modèle est basé sur scikit-learn et il existe déjà un conteneur prédéfini.
Framework de modèle : scikit-learn. Il s'agit de la bibliothèque que vous avez utilisée pour l'entraînement du modèle.
Version du framework de modèle : votre code est compatible avec la version 0.23.
Emplacement du package : vous pouvez rechercher l'emplacement de votre package d'entraînement. Il s'agit de celui où vous avez importé training-0.1.tar.gz. Si vous avez correctement suivi les étapes précédentes, l'emplacement doit être gs://YOUR-BUCKET-NAME/titanic/dist/trainer-0.1.tar.gz, YOUR-BUCKET-NAME correspondant au nom du bucket que vous avez utilisé dans la section Créer votre package.
Module Python : le module Python que vous avez créé dans Notebooks. Son nom correspondra à celui du dossier dans lequel se trouve votre code/module d'entraînement suivi du nom du fichier d'entrée. Il doit donc s'appeler trainer.task.
Projet BigQuery pour l'exportation des données : à l'étape 1, vous avez sélectionné l'ensemble de données et défini une répartition automatique. Un nouvel ensemble de données et des tables pour les ensembles d'entraînement, de test et de validation seront créés sous le projet sélectionné.
Saisissez le même ID de projet que vous utilisez pour l'atelier.
Des URI d'ensembles de données d'entraînement, de test et de validation seront en outre définis en tant que variables d'environnement dans le conteneur d'entraînement afin que vous puissiez automatiquement utiliser ces variables pour charger vos données. Les noms des variables d'environnement correspondant aux ensembles de données seront AIP_TRAINING_DATA_URI, AIP_TEST_DATA_URI et AIP_VALIDATION_DATA_URI. S'ajoutera à cela une autre variable (AIP_DATA_FORMAT) qui pourra être au format csv ou bigquery en fonction du type de l'ensemble de données sélectionné à l'étape 1.
Vous avez déjà créé cette logique dans task.py. Observez cet exemple de code (issu de task.py) :
...
parser.add_argument( '--training_data_uri ',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_TRAINING_DATA_URI'] if 'AIP_TRAINING_DATA_URI' in os.environ else "" )
...
Répertoire de sortie du modèle : l'emplacement vers lequel le modèle sera exporté. Il s'agira d'une variable d'environnement du conteneur d'entraînement dont le nom sera AIP_MODEL_DIR. Notre fichier task.py contient un paramètre d'entrée destiné à capturer cela :
...
parser.add_argument( '--model_dir',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_MODEL_DIR'] if 'AIP_MODEL_DIR' in os.environ else "" )
...
Vous pouvez utiliser la variable d'environnement pour savoir où exporter les artefacts du job d'entraînement. Nous allons sélectionner gs://YOUR-BUCKET-NAME/titanic/.
Cliquez sur Continuer.
Réglages d'hyperparamètres
La section réservée aux réglages d'hyperparamètres vous permet de définir un ensemble de paramètres que vous voudriez utiliser pour régler votre modèle. Différentes valeurs seront explorées de façon que nous puissions produire le modèle présentant les meilleurs paramètres. Dans votre code, vous n'avez pas implémenté la fonctionnalité de réglage des hyperparamètres. Cela ne représente que quelques lignes de code (environ cinq lignes), mais vous ne vouliez pas ajouter cette complexité pour le moment.
Nous allons donc ignorer cette étape en cliquant sur Continuer.
Options de calcul et tarifs
Où voulez-vous que votre job d'entraînement s'exécute et quel type de serveur voulez-vous utiliser ? Votre processus d'entraînement de modèle n'est pas un gros consommateur de ressources. Vous avez pu exécuter le job d'entraînement dans une instance de notebook relativement petite et l'exécution se termine assez rapidement.
Sachant cela, vous sélectionnez les paramètres suivants :
Région :
Type de machine :n1-standard-4
Cliquez sur Continuer.
Conteneur de prédiction
À cette étape, vous pouvez décider de simplement entraîner le modèle ou d'ajouter également des paramètres pour le service de prédiction utilisé afin de faire passer votre modèle en production.
Dans cet atelier, vous allez utiliser un conteneur prédéfini. Cependant, gardez à l'esprit que Vertex AI vous offre plusieurs possibilités pour servir le modèle :
Pas de conteneur de prédiction : vous vous contentez d'entraîner le modèle et vous le ferez passer en production ultérieurement.
Conteneur prédéfini : vous entraînez le modèle et vous spécifiez le conteneur prédéfini à utiliser pour le déploiement.
Conteneur personnalisé : vous entraînez le modèle et vous définissez un conteneur personnalisé à utiliser pour le déploiement.
Vous devez choisir un conteneur prédéfini puisque Google Cloud propose déjà un conteneur scikit-learn. Vous déploierez le modèle quand le job d'entraînement sera terminé.
Framework de modèle : scikit-learn
Version du framework de modèle : 0.23
Répertoire du modèle : gs://YOUR-BUCKET-NAME/titanic/. Ce doit être le même répertoire que le répertoire de sortie du modèle que vous avez défini à l'étape 3.
Cliquez sur Démarrer l'entraînement.
Le nouveau job d'entraînement va s'afficher dans l'onglet Pipeline d'entraînement. L'entraînement va prendre environ 15 minutes.
Tâche 5 : Évaluer le modèle
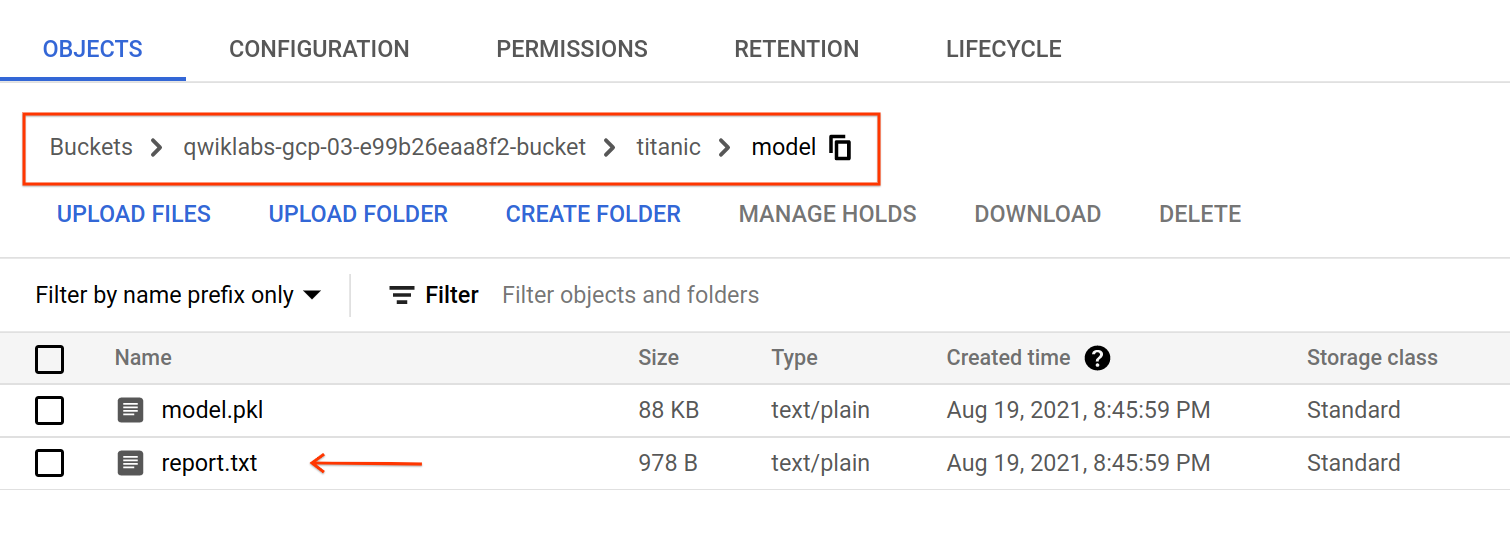
Lorsque le job d'entraînement sera terminé, des artefacts seront exportés sous gs://YOUR-BUCKET-NAME/titanic/model/. Vous pouvez consulter le fichier report.txt qui contient des métriques d'évaluation et un rapport de classification du modèle.
Tâche 6 : Déployer le modèle
Dans le Menu de navigation de la console Cloud, cliquez sur Vertex AI > Entraînement.
Une fois le job d'entraînement du modèle terminé, sélectionnez le modèle entraîné et déployez-le sur un point de terminaison.
Accédez à l'onglet DÉPLOYER ET TESTER, puis cliquez sur DÉPLOYER SUR UN POINT DE TERMINAISON.
Dans le pop-up, vous pouvez définir les ressources requises pour le déploiement du modèle :
Nom du point de terminaison : URL du point de terminaison où le modèle est diffusé. Nous pourrions utiliser le nom titanic-endpoint. Cliquez sur Continuer.
Répartition du trafic : définit le pourcentage du trafic que vous voulez diriger vers ce modèle. Un point de terminaison peut avoir plusieurs modèles et vous pouvez décider de la façon dont le trafic doit être réparti entre eux. Dans ce cas, vous déployez un seul modèle. Il doit donc être destinataire de 100 % du trafic.
Nombre minimal de nœuds de calcul : le nombre minimal de nœuds requis pour la diffusion des prédictions du modèle. Commencez avec 1. Nous pouvons en outre compter sur le fait que le service de prédiction effectuera un autoscaling si le trafic le nécessite.
Nombre maximal de nœuds de calcul : cette variable définit pour le nombre de nœuds une limite supérieure qui doit être respectée si un autoscaling est effectué. Cela constitue une protection contre les coûts indésirables qui pourraient être occasionnés par l'autoscaling. Définissez cette variable sur 2.
Type de machine : Google Cloud propose un ensemble de types de machines utilisables pour le déploiement de votre modèle. Chaque machine dispose de sa propre mémoire et d'un certain nombre de processeurs virtuels. Votre modèle étant simple, l'utilisation pour sa diffusion d'une instance n1-standard-4 sera suffisante.
Cliquez sur OK, puis sur Déployer.
Tâche 7 : Prédiction du modèle
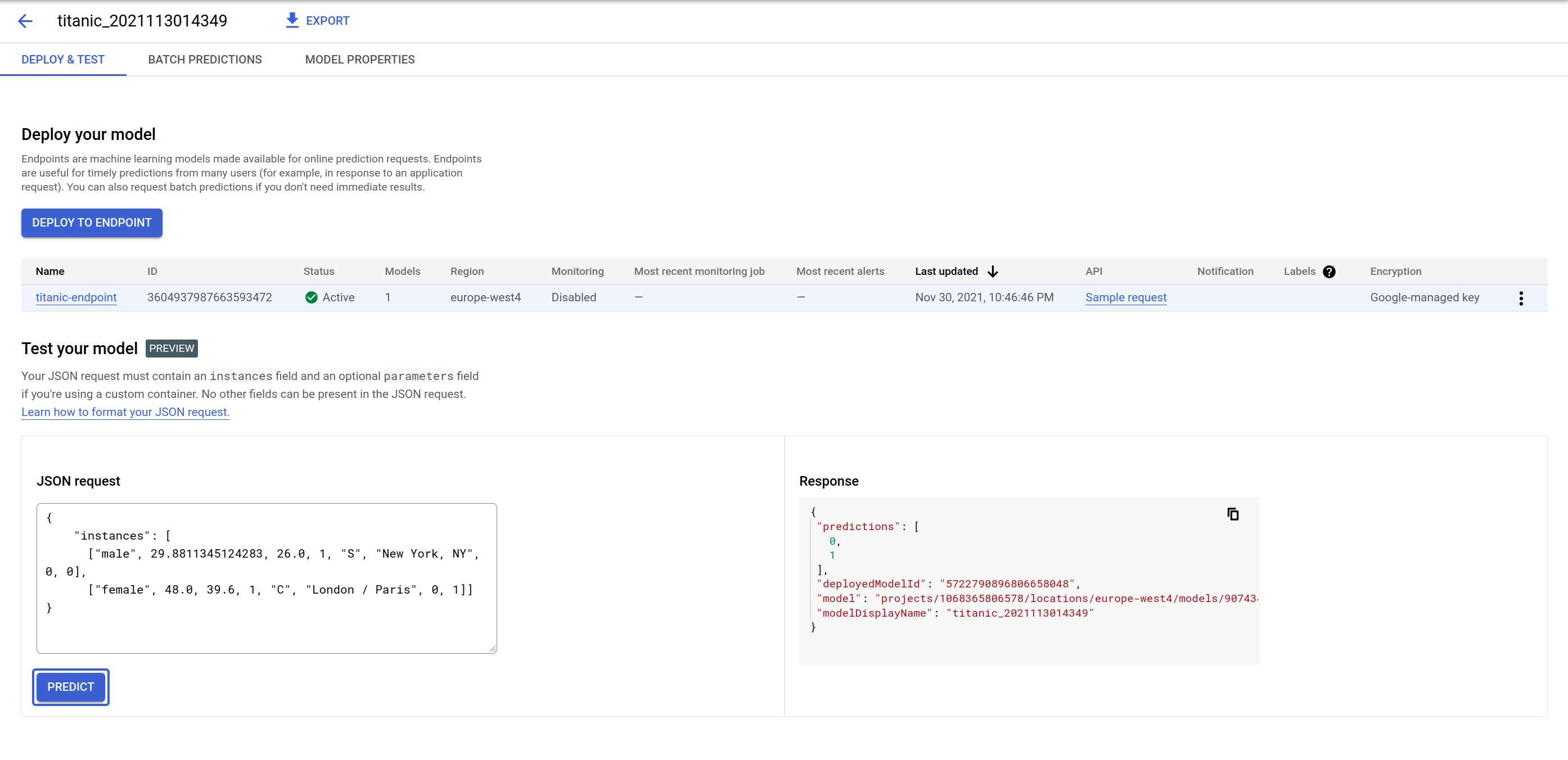
Sous Déployer le modèle, testez le point de terminaison de prédiction du modèle. L'interface utilisateur comporte un formulaire permettant d'envoyer une charge utile de requête JSON. La réponse qui s'affiche contient les prédictions ainsi que l'ID du modèle utilisé pour les générer. Cela est dû au fait que vous pouvez déployer plusieurs modèles sur un point de terminaison et répartir le trafic.
Faites un test avec la charge utile suivante. Vous pouvez éventuellement modifier certaines des valeurs pour voir comment les prédictions évoluent : l'ordre des caractéristiques d'entrée est [‘sex', ‘age', ‘fare', ‘pclass', ‘embarked', ‘home_dest', ‘parch', ‘sibsp'].
Le point de terminaison répond par une liste de zéros ou de uns dans un ordre identique à celui de votre entrée. "0" signifie qu'il est plus probable que la personne ne survivra pas à l'accident du Titanic tandis que "1" veut dire qu'elle est susceptible d'y survivre.
Tâche 8 : Nettoyer
Félicitations ! Vous avez créé un ensemble de données, empaqueté votre code d'entraînement et exécuté un job d'entraînement personnalisé à l'aide de Vertex AI. Vous avez ensuite déployé le modèle entraîné et envoyé des données pour obtenir des prédictions.
Étant donné que vous n'avez pas besoin des ressources créées, nous vous recommandons de les supprimer afin d'éviter que des frais inutiles ne vous soient facturés.
Accédez à la page "Ensembles de données" de la console, cliquez sur les trois points situés à côté de l'ensemble de données que vous voulez supprimer, puis cliquez sur Supprimer l'ensemble de données. Cliquez sur Supprimer pour confirmer la suppression.
Accédez à la page Workbench de la console, sélectionnez uniquement le notebook que vous voulez supprimer, puis cliquez sur Supprimer dans le menu supérieur. Cliquez sur Supprimer pour confirmer la suppression.
Pour supprimer le point de terminaison que vous avez déployé, accédez à la section Points de terminaison de votre console Vertex AI. Cliquez sur le point de terminaison, sur le menu à développer (), sur Annuler le déploiement du modèle sur le point de terminaison, puis sur Annuler le déploiement.
Pour supprimer le point de terminaison, cliquez sur le menu à développer (), puis sur Supprimer un point de terminaison. Cliquez ensuite sur Confirmer.
Accédez à la page Modèles de la console, cliquez sur les trois points () situés à côté du modèle que vous voulez supprimer, puis cliquez sur Supprimer le modèle. Cliquez ensuite sur Supprimer.
Pour supprimer le bucket Cloud Storage, sélectionnez votre bucket sur la page Cloud Storage, puis cliquez sur Supprimer. Pour confirmer la suppression, saisissez DELETE, puis cliquez sur Supprimer.
Pour supprimer l'ensemble de données BigQuery, procédez comme suit :
Accédez à la console BigQuery.
Dans le panneau Explorateur, cliquez sur l'icône Afficher les actions située à côté de votre ensemble de données. Cliquez sur Supprimer.
Dans la boîte de dialogue "Supprimer l'ensemble de données", confirmez la commande de suppression en saisissant delete, puis cliquez sur Supprimer.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur End Lab (Terminer l'atelier). Qwiklabs supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez le nombre d'étoiles correspondant à votre note, saisissez un commentaire, puis cliquez sur Submit (Envoyer).
Le nombre d'étoiles que vous pouvez attribuer à un atelier correspond à votre degré de satisfaction :
1 étoile = très mécontent(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez utiliser l'onglet Support (Assistance).
Copyright 2020 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Ouvrez une fenêtre de navigateur en mode navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous pouvez utiliser Vertex AI pour entraîner et déployer un modèle de ML.
Durée :
0 min de configuration
·
Accessible pendant 120 min
·
Terminé après 120 min
 ) à côté de l'ID de votre projet et sélectionnez Créer un ensemble de données.
) à côté de l'ID de votre projet et sélectionnez Créer un ensemble de données.