En este lab, usarás Vertex AI para entrenar y, luego, implementar un modelo de AA. Se da por sentado que estás familiarizado con el aprendizaje automático, a pesar de que se te proporciona el código correspondiente para el entrenamiento. Crearás y administrarás conjuntos de datos y usarás un modelo personalizado para entrenar un modelo de scikit-learn. Por último, implementarás el modelo entrenado para obtener predicciones en línea. El conjunto de datos que usarás para esta demostración es el del Titanic.
Objetivos
Crear un conjunto de datos para datos tabulares
Crear un paquete de entrenamiento con código personalizado usando notebooks
Implementar el modelo entrenado para obtener predicciones en línea
Configuración
En cada lab, recibirá un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Qwiklabs desde una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesita, puede reiniciar el lab, pero deberá hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usa otras credenciales, se generarán errores o incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Nota: Si tienes problemas para descargar el conjunto de datos en modo Incógnito, usa la ventana normal para descargar el conjunto de datos del Titanic.
Cambia el nombre del conjunto de datos que descargaste a titanic_toy.csv.
Luego, haz lo siguiente en la IU:
Abre el conjunto de datos titanic que creaste en el paso anterior haciendo clic en el ícono de Ver acciones () que se encuentra a un lado del conjunto de datos y seleccionando Abrir.
Haz clic en Crear tabla y especifica lo siguiente:
Crear tabla desde: Subir
Seleccionar archivo: Usa el conjunto de datos del Titanic descargado
Formato de archivo: CSV
Nombre de la tabla: survivors
Detección automática: Selecciona la casilla de verificación Esquema
Haz clic en Crear tabla.
Haz clic en el ícono de Ver acciones junto a survivors y selecciona Copiar ID. Guarda el ID de la tabla que copiaste para usarlo más adelante en el lab.
Acabas de crear la tabla y la completaste con el conjunto de datos del Titanic. Ahora puedes explorar su contenido, realizar consultas y analizar sus datos.
Tarea 2. Crea un conjunto de datos
Los conjuntos de datos en Vertex AI te permiten crear conjuntos de datos para tus cargas de trabajo de aprendizaje automático. Puedes crear conjuntos de datos para datos estructurados (archivos CSV o tablas de BigQuery) sin estructurar, como imágenes y texto. Es importante señalar que los conjuntos de datos de Vertex AI solo hacen referencia a los datos originales y no los duplican.
Crea un conjunto de datos de AA
En el menú de navegación de la consola de Google Cloud, selecciona Vertex AI > Conjuntos de datos.
Selecciona y haz clic en Crear.
Asígnale un nombre al conjunto de datos, como titanic.
Puedes crear conjuntos de datos para imágenes, texto, video o datos tabulares.
El conjunto de datos del Titanic es tabular, así que debes hacer clic en la pestaña Tabular.
Para seleccionar la región, elige y haz clic en Crear.
En esta etapa, acabas de crear un marcador de posición. Aún no te has conectado a la fuente de datos; lo harás en el siguiente paso.
Selecciona la fuente de datos
Como ya cargaste el conjunto de datos del Titanic en BigQuery, puedes conectar el conjunto de datos de AA a tu tabla de BigQuery.
Elige Selecciona una tabla o una vista de BigQuery.
Pega el ID de tabla que copiaste en el campo EXPLORAR.
Una vez que selecciones el conjunto de datos, haz clic en Continuar.
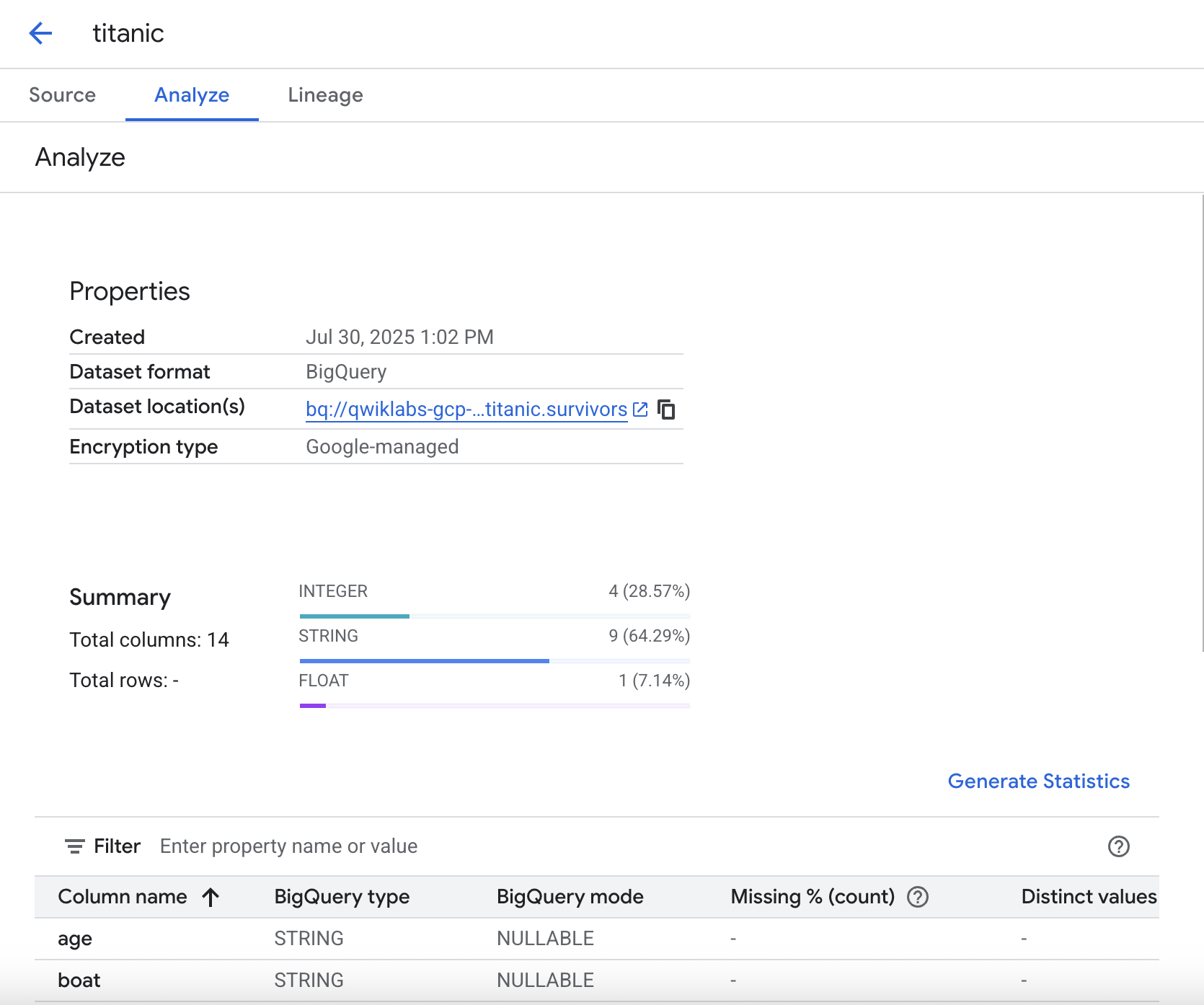
Genera estadísticas
En la pestaña Analizar, puedes generar estadísticas sobre tus datos. Esto te permite consultar datos rápidamente y revisar las distribuciones, los valores faltantes, etcétera.
Para ejecutar el análisis estadístico, haz clic en Generar estadísticas. Esto puede tardar unos minutos en ejecutarse, así que puedes continuar con el lab y regresar más tarde para ver los resultados.
Tarea 3. Paquete de entrenamiento personalizado usando Workbench
Una práctica recomendada es empaquetar y parametrizar el código para que sea un recurso portátil.
En esta sección, crearás un paquete de entrenamiento con código personalizado usando Vertex AI Workbench. Un paso fundamental para usar el servicio es poder crear una distribución de código fuente de Python, lo que también se conoce como paquete de distribución. Esto no implica mucho más que crear carpetas y archivos en el paquete de distribución. En la próxima sección, se explicará la estructura del paquete.
Estructura de la aplicación
La estructura básica de un paquete de Python puede verse en la imagen que se muestra a continuación.
Veamos qué función desempeñan las carpetas y los archivos:
titanic-package: Este es el directorio de trabajo. En esta carpeta, tendrás el paquete y el código relacionados con el clasificador de sobrevivientes del Titanic.
setup.py: Es el archivo de configuración que especifica cómo compilar el paquete de distribución. Incluye información, como el nombre y la versión del paquete, y los demás paquetes que podrías necesitar para el trabajo de entrenamiento y que no se incluyen de forma predeterminada en los contenedores de entrenamiento de Google Cloud creados previamente.
trainer: Es la carpeta que contiene el código de entrenamiento. También es un paquete de Python debido al archivo vacío __init__.py que se encuentra dentro de la carpeta.
__init__.py: Es un archivo vacío llamado __init__.py. Indica que la carpeta a la que pertenece es un paquete.
task.py: Es un módulo del paquete. Aquí se encuentra el punto de entrada de tu código y solo acepta parámetros de CLI para entrenar modelos. Puedes incluir tu código de entrenamiento en este módulo o crear módulos adicionales en el paquete. Esto depende exclusivamente de ti y de cómo quieras estructurar el código.
Ahora que ya comprendes la estructura, es necesario aclarar que los nombres usados para el paquete y el módulo no tienen que ser “trainer” ni “task.py” forzosamente. Usamos esta convención en el lab para alinear los nombres con nuestra documentación en línea, pero puedes elegir los nombres que te parezcan más adecuados.
Crea la instancia de notebook
Ahora, crearemos una instancia de notebook y entrenaremos un modelo personalizado.
En el menú de navegación de la consola de Google Cloud, haz clic en Vertex AI > Workbench.
En la página de instancias de Notebook, haz clic en Crear nuevo y, luego, inicia una instancia con Python 3, que incluye scikit-learn. Usarás un modelo de scikit‑learn para el clasificador.
Aparecerá una ventana emergente. Aquí puedes cambiar la configuración, como la región en la que se creará la instancia de notebook y la capacidad de procesamiento que necesitarás.
Como no trabajarás con muchos datos y solo necesitas la instancia para objetivos de desarrollo, no cambies ninguno de los parámetros de configuración; solo debes hacer clic en Crear.
Esta instancia estará lista para usarse en unos pocos minutos.
Cuando esté lista, abre Jupyterlab.
Verás una ventana emergente que indicará “Build recommended”, haz clic en Build. Si ves que la compilación falló, ignórala.
Crea el paquete
Ahora que el notebook está listo, puedes comenzar a crear los elementos de entrenamiento.
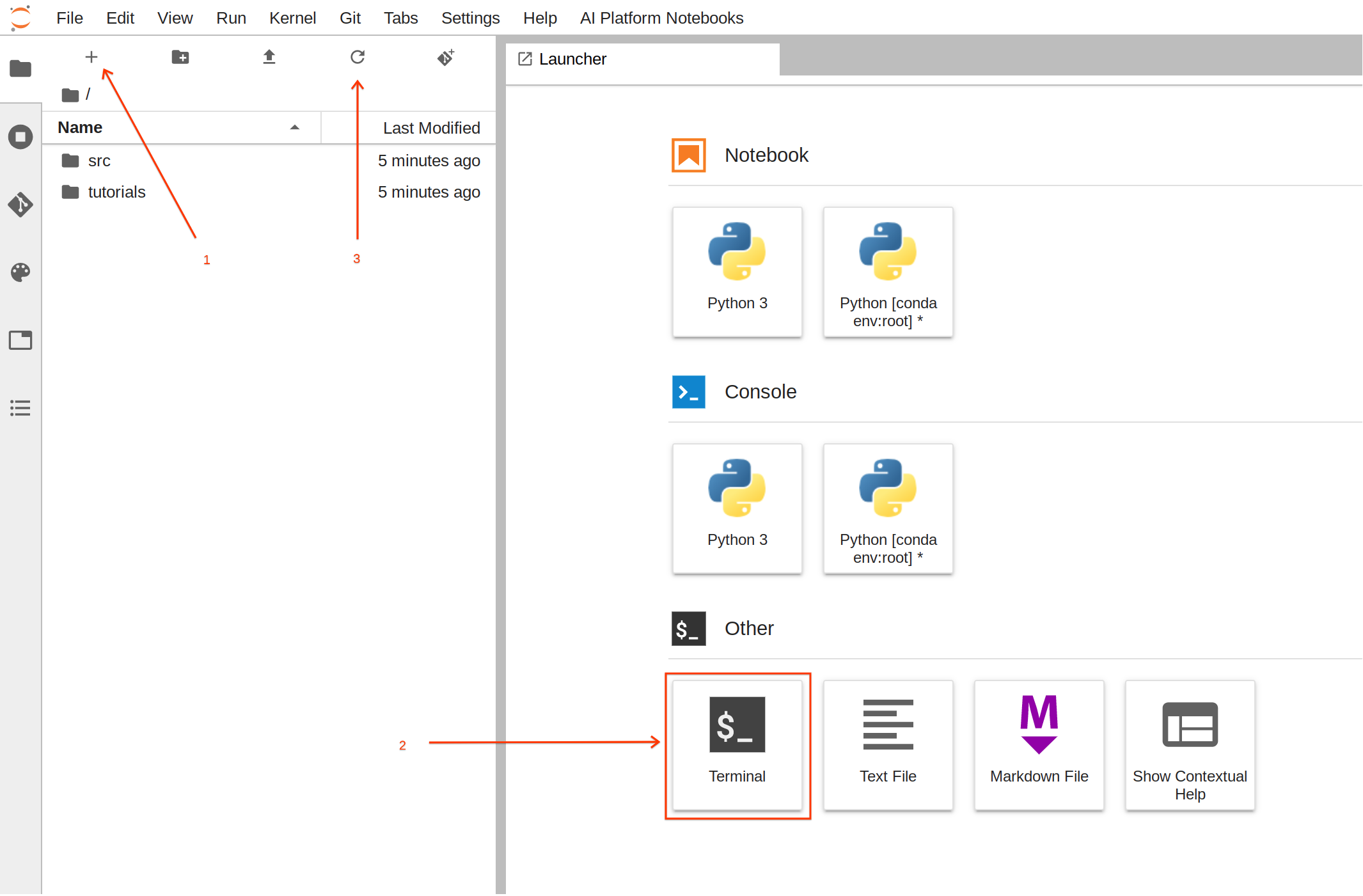
Para esta tarea, es más sencillo usar la terminal.
En el selector, haz clic en Terminal para crear una nueva sesión.
Ahora, ejecuta los siguientes comandos en la terminal para crear la estructura de carpetas con los archivos requeridos:
Cuando ejecutes los comandos, haz clic en el botón Actualizar para ver las carpetas y los archivos recién creados.
Copia y pega el siguiente código en titanic/trainer/task.py. El código contiene comentarios, así que es útil examinarlo durante algunos minutos para comprenderlo mejor:
from google.cloud import bigquery, bigquery_storage, storage
from sklearn.pipeline import make_pipeline, Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder, OrdinalEncoder
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
from sklearn.metrics import classification_report, f1_score
from typing import Union, List
import os, logging, json, pickle, argparse
import dask.dataframe as dd
import pandas as pd
import numpy as np
# selección de atributos. La lista FEATURE define cuáles atributos se necesitan de los datos de entrenamiento
# así como los tipos de esos atributos. Realizaremos una ingeniería de atributos diferente dependiendo del tipo.
# Enumera todos los nombres de columna para atributos binarios: 0,1 o True,False o Male,Female etc
BINARY_FEATURES = [
'sex']
# Enumera todos los nombres de columna para atributos numéricos
NUMERIC_FEATURES = [
'age',
'fare']
# Enumera todos los nombres de columna para atributos categóricos
CATEGORICAL_FEATURES = [
'pclass',
'embarked',
'home_dest',
'parch',
'sibsp']
ALL_COLUMNS = BINARY_FEATURES+NUMERIC_FEATURES+CATEGORICAL_FEATURES
# define el nombre de columna para la etiqueta
LABEL = 'survived'
# Define la posición de índice de cada atributo. Esto se necesita para procesar un
array # numpy (en lugar de pandas) que no tiene nombres de columna.
BINARY_FEATURES_IDX = list(range(0,len(BINARY_FEATURES)))
NUMERIC_FEATURES_IDX = list(range(len(BINARY_FEATURES), len(BINARY_FEATURES)+len(NUMERIC_FEATURES)))
CATEGORICAL_FEATURES_IDX = list(range(len(BINARY_FEATURES+NUMERIC_FEATURES), len(ALL_COLUMNS)))
def load_data_from_gcs(data_gcs_path: str) -> pd.DataFrame:
'''
Loads data from Google Cloud Storage (GCS) to a dataframe
Parameters:
data_gcs_path (str): gs path for the location of the data. Wildcards are also supported. i.e gs://example_bucket/data/training-*.csv
Returns:
pandas.DataFrame: a dataframe with the data from GCP loaded
'''
# usar dask que admite comodines para leer varios archivos. Luego, con dd.read_csv().compute creamos un DataFrame de pandas
# Además he observado que faltan algunos valores de TotalCharges y esto crea confusión sobre TotalCharges como el tipo de datos.
# para superar esto definimos manualmente TotalCharges como objeto.
# Corregiremos esta anomalía más adelante
logging.info("reading gs data: {}".format(data_gcs_path))
return dd.read_csv(data_gcs_path, dtype={'TotalCharges': 'object'}).compute()
def load_data_from_bq(bq_uri: str) -> pd.DataFrame:
'''
Loads data from BigQuery table (BQ) to a dataframe
Parameters:
bq_uri (str): bq table uri. i.e: example_project.example_dataset.example_table
Returns:
pandas.DataFrame: a dataframe with the data from GCP loaded
'''
if not bq_uri.startswith('bq://'):
raise Exception("uri is not a BQ uri. It should be bq://project_id.dataset.table")
logging.info("reading bq data: {}".format(bq_uri))
project,dataset,table = bq_uri.split(".")
bqclient = bigquery.Client(project=project[5:])
bqstorageclient = bigquery_storage.BigQueryReadClient()
query_string = """
SELECT * from {ds}.{tbl}
""".format(ds=dataset, tbl=table)
return (
bqclient.query(query_string)
.result()
.to_dataframe(bqstorage_client=bqstorageclient)
)
def clean_missing_numerics(df: pd.DataFrame, numeric_columns):
'''
removes invalid values in the numeric columns
Parameters:
df (pandas.DataFrame): The Pandas Dataframe to alter
numeric_columns (List[str]): List of column names that are numeric from the DataFrame
Returns:
pandas.DataFrame: a dataframe with the numeric columns fixed
'''
for n in numeric_columns:
df[n] = pd.to_numeric(df[n], errors='coerce')
df = df.fillna(df.mean())
return df
def data_selection(df: pd.DataFrame, selected_columns: List[str], label_column: str) -> (pd.DataFrame, pd.Series):
'''
From a dataframe it creates a new dataframe with only selected columns and returns it.
Additionally it splits the label column into a pandas Series.
Parameters:
df (pandas.DataFrame): The Pandas Dataframe to drop columns and extract label
selected_columns (List[str]): List of strings with the selected columns. i,e ['col_1', 'col_2', ..., 'col_n' ]
label_column (str): The name of the label column
Returns:
tuple(pandas.DataFrame, pandas.Series): Tuble with the new pandas DataFrame containing only selected columns and lablel pandas Series
'''
# Crearemos una serie con la etiqueta de predicción
labels = df[label_column].astype(int)
data = df.loc[:, selected_columns]
return data, labels
def pipeline_builder(params_svm: dict, bin_ftr_idx: List[int], num_ftr_idx: List[int], cat_ftr_idx: List[int]) -> Pipeline:
'''
Builds a sklearn pipeline with preprocessing and model configuration.
Preprocessing steps are:
* OrdinalEncoder - used for binary features
* StandardScaler - used for numerical features
* OneHotEncoder - used for categorical features
Model used is SVC
Parameters:
params_svm (dict): List of parameters for the sklearn.svm.SVC classifier
bin_ftr_idx (List[str]): List of ints that mark the column indexes with binary columns. i.e [0, 2, ... , X ]
num_ftr_idx (List[str]): List of ints that mark the column indexes with numerical columns. i.e [6, 3, ... , X ]
cat_ftr_idx (List[str]): List of ints that mark the column indexes with categorical columns. i.e [5, 10, ... , X ]
label_column (str): The name of the label column
Returns:
Pipeline: sklearn.pipelines.Pipeline with preprocessing and model training
'''
# Definir un paso de procesamiento previo para nuestra canalización.
# especifica cómo los atributos se van a transformar
preprocessor = ColumnTransformer(
transformers=[
('bin', OrdinalEncoder(), bin_ftr_idx),
('num', StandardScaler(), num_ftr_idx),
('cat', OneHotEncoder(handle_unknown='ignore'), cat_ftr_idx)], n_jobs=-1)
# Ahora crearemos una canalización completa, para procesamiento previo y entrenamiento.
# para el entrenamiento, seleccionamos un clasificador SVM lineal
clf = SVC()
clf.set_params(**params_svm)
return Pipeline(steps=[ ('preprocessor', preprocessor),
('classifier', clf)])
def train_pipeline(clf: Pipeline, X: Union[pd.DataFrame, np.ndarray], y: Union[pd.DataFrame, np.ndarray]) -> float:
'''
Trains a sklearn pipeline by fiting training data and labels and returns the accuracy f1 score
Parameters:
clf (sklearn.pipelines.Pipeline): the Pipeline object to fit the data
X: (pd.DataFrame OR np.ndarray): Training vectors of shape n_samples x n_features, where n_samples is the number of samples and n_features is the number of features.
y: (pd.DataFrame OR np.ndarray): Labels of shape n_samples. Order should mathc Training Vectors X
Returns:
score (float): Average F1 score from all cross validations
'''
# ejecuta una validación cruzada para obtener la puntuación de entrenamiento. Podemos usar esta puntuación para optimizar el entrenamiento
score = cross_val_score(clf, X, y, cv=10, n_jobs=-1).mean()
# Ahora ponemos todos nuestros datos en el clasificador.
clf.fit(X, y)
return score
def process_gcs_uri(uri: str) -> (str, str, str, str):
'''
Receives a Google Cloud Storage (GCS) uri and breaks it down to the scheme, bucket, path and file
Parameters:
uri (str): GCS uri
Returns:
scheme (str): uri scheme
bucket (str): uri bucket
path (str): uri path
file (str): uri file
'''
url_arr = uri.split("/")
if "." not in url_arr[-1]:
file = ""
else:
file = url_arr.pop()
scheme = url_arr[0]
bucket = url_arr[2]
path = "/".join(url_arr[3:])
path = path[:-1] if path.endswith("/") else path
return scheme, bucket, path, file
def pipeline_export_gcs(fitted_pipeline: Pipeline, model_dir: str) -> str:
'''
Exports trained pipeline to GCS
Parameters:
fitted_pipeline (sklearn.pipelines.Pipeline): the Pipeline object with data already fitted (trained pipeline object)
model_dir (str): GCS path to store the trained pipeline. i.e gs://example_bucket/training-job
Returns:
export_path (str): Model GCS location
'''
scheme, bucket, path, file = process_gcs_uri(model_dir)
if scheme != "gs:":
raise ValueError("URI scheme must be gs")
# Sube el modelo a GCS
b = storage.Client().bucket(bucket)
export_path = os.path.join(path, 'model.pkl')
blob = b.blob(export_path)
blob.upload_from_string(pickle.dumps(fitted_pipeline))
return scheme + "//" + os.path.join(bucket, export_path)
def prepare_report(cv_score: float, model_params: dict, classification_report: str, columns: List[str], example_data: np.ndarray) -> str:
'''
Prepares a training report in Text
Parameters:
cv_score (float): score of the training job during cross validation of training data
model_params (dict): dictonary containing the parameters the model was trained with
classification_report (str): Model classification report with test data
columns (List[str]): List of columns that where used in training.
example_data (np.array): Sample of data (2-3 rows are enough). This is used to include what the prediciton payload should look like for the model
Returns:
report (str): Full report in text
'''
buffer_example_data = '['
for r in example_data:
buffer_example_data+='['
for c in r:
if(isinstance(c,str)):
buffer_example_data+="'"+c+"', "
else:
buffer_example_data+=str(c)+", "
buffer_example_data= buffer_example_data[:-2]+"], \n"
buffer_example_data= buffer_example_data[:-3]+"]"
report = """
Training Job Report
Cross Validation Score: {cv_score}
Training Model Parameters: {model_params}
Test Data Classification Report:
{classification_report}
Example of data array for prediciton:
Order of columns:
{columns}
Example for clf.predict()
{predict_example}
Example of GCP API request body:
{{
"instances": {json_example}
}}
""".format(
cv_score=cv_score,
model_params=json.dumps(model_params),
classification_report=classification_report,
columns = columns,
predict_example = buffer_example_data,
json_example = json.dumps(example_data.tolist()))
return report
def report_export_gcs(report: str, report_dir: str) -> None:
'''
Exports training job report to GCS
Parameters:
report (str): Full report in text to sent to GCS
report_dir (str): GCS path to store the report model. i.e gs://example_bucket/training-job
Returns:
export_path (str): Report GCS location
'''
scheme, bucket, path, file = process_gcs_uri(report_dir)
if scheme != "gs:":
raise ValueError("URI scheme must be gs")
# Sube el modelo a GCS
b = storage.Client().bucket(bucket)
export_path = os.path.join(path, 'report.txt')
blob = b.blob(export_path)
blob.upload_from_string(report)
return scheme + "//" + os.path.join(bucket, export_path)
# Define todos los argumentos de línea de comandos que tu modelo puede aceptar para entrenamiento
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# Ingresa los argumentos
parser.add_argument(
'--model_param_kernel',
help = 'SVC model parameter- kernel',
choices=['linear', 'poly', 'rbf', 'sigmoid', 'precomputed'],
type = str,
default = 'linear'
)
parser.add_argument(
'--model_param_degree',
help = 'SVC model parameter- Degree. Only applies for poly kernel',
type = int,
default = 3
)
parser.add_argument(
'--model_param_C',
help = 'SVC model parameter- C (regularization)',
type = float,
default = 1.0
)
parser.add_argument(
'--model_param_probability',
help = 'Whether to enable probability estimates',
type = bool,
default = True
)
'''
Vertex AI automatically populates a set of environment variables in the container that executes
your training job. Those variables include:
* AIP_MODEL_DIR - Directory selected as model dir
* AIP_DATA_FORMAT - Type of dataset selected for training (can be csv or bigquery)
Vertex AI will automatically split selected dataset into training, validation and testing
and 3 more environment variables will reflect the location of the data:
* AIP_TRAINING_DATA_URI - URI of Training data
* AIP_VALIDATION_DATA_URI - URI of Validation data
* AIP_TEST_DATA_URI - URI of Test data
Notice that those environment variables are default. If the user provides a value using CLI argument,
the environment variable will be ignored. If the user does not provide anything as CLI argument
the program will try and use the environment variables if those exist. Otherwise will leave empty.
'''
parser.add_argument(
'--model_dir',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_MODEL_DIR'] if 'AIP_MODEL_DIR' in os.environ else ""
)
parser.add_argument(
'--data_format',
choices=['csv', 'bigquery'],
help = 'format of data uri csv for gs:// paths and bigquery for project.dataset.table formats',
type = str,
default = os.environ['AIP_DATA_FORMAT'] if 'AIP_DATA_FORMAT' in os.environ else "csv"
)
parser.add_argument(
'--training_data_uri',
help = 'location of training data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_TRAINING_DATA_URI'] if 'AIP_TRAINING_DATA_URI' in os.environ else ""
)
parser.add_argument(
'--validation_data_uri',
help = 'location of validation data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_VALIDATION_DATA_URI'] if 'AIP_VALIDATION_DATA_URI' in os.environ else ""
)
parser.add_argument(
'--test_data_uri',
help = 'location of test data in either gs:// uri or bigquery uri',
type = str,
default = os.environ['AIP_TEST_DATA_URI'] if 'AIP_TEST_DATA_URI' in os.environ else ""
)
parser.add_argument("-v", "--verbose", help="increase output verbosity",
action="store_true")
args = parser.parse_args()
arguments = args.__dict__
if args.verbose:
logging.basicConfig(level=logging.INFO)
logging.info('Model artifacts will be exported here: {}'.format(arguments['model_dir']))
logging.info('Data format: {}'.format(arguments["data_format"]))
logging.info('Training data uri: {}'.format(arguments['training_data_uri']) )
logging.info('Validation data uri: {}'.format(arguments['validation_data_uri']))
logging.info('Test data uri: {}'.format(arguments['test_data_uri']))
'''
We have 2 different ways to load our data to pandas. One is from Cloud Storage by loading csv files and
the other is by connecting to BigQuery. Vertex AI supports both and
here we created a code that depending on the dataset provided. We will select the appropriate loading method.
'''
logging.info('Loading {} data'.format(arguments["data_format"]))
if(arguments['data_format']=='csv'):
df_train = load_data_from_gcs(arguments['training_data_uri'])
df_test = load_data_from_bq(arguments['test_data_uri'])
df_valid = load_data_from_gcs(arguments['validation_data_uri'])
elif(arguments['data_format']=='bigquery'):
print(arguments['training_data_uri'])
df_train = load_data_from_bq(arguments['training_data_uri'])
df_test = load_data_from_bq(arguments['test_data_uri'])
df_valid = load_data_from_bq(arguments['validation_data_uri'])
else:
raise ValueError("Invalid data type ")
#ya que utilizaremos la validación cruzada, tendremos solo un conjunto de entrenamiento y un único conjunto de prueba.
# we will merge the test and validation to achieve an 80%-20% split
df_test = pd.concat([df_test,df_valid])
logging.info('Defining model parameters')
model_params = dict()
model_params['kernel'] = arguments['model_param_kernel']
model_params['degree'] = arguments['model_param_degree']
model_params['C'] = arguments['model_param_C']
model_params['probability'] = arguments['model_param_probability']
df_train = clean_missing_numerics(df_train, NUMERIC_FEATURES)
df_test = clean_missing_numerics(df_test, NUMERIC_FEATURES)
logging.info('Running feature selection')
X_train, y_train = data_selection(df_train, ALL_COLUMNS, LABEL)
X_test, y_test = data_selection(df_test, ALL_COLUMNS, LABEL)
logging.info('Training pipelines in CV')
y_train = y_train.astype('int')
y_test = y_test.astype('int')
clf = pipeline_builder(model_params, BINARY_FEATURES_IDX, NUMERIC_FEATURES_IDX, CATEGORICAL_FEATURES_IDX)
cv_score = train_pipeline(clf, X_train, y_train)
logging.info('Export trained pipeline and report')
pipeline_export_gcs(clf, arguments['model_dir'])
y_pred = clf.predict(X_test)
test_score = f1_score(y_test, y_pred, average='weighted')
logging.info('f1score: '+ str(test_score))
report = prepare_report(cv_score,
model_params,
classification_report(y_test,y_pred),
ALL_COLUMNS,
X_test.to_numpy()[0:2])
report_export_gcs(report, arguments['model_dir'])
logging.info('Training job completed. Exiting...')
Presiona Ctrl + S para guardar el archivo.
Crea tu paquete
Ahora, es momento de crear el paquete para usarlo con el servicio de entrenamiento.
Copia y pega el siguiente código en titanic/setup.py:
from setuptools import find_packages
from setuptools import setup
REQUIRED_PACKAGES = [
'gcsfs==0.7.1',
'dask[dataframe]==2021.2.0',
'google-cloud-bigquery-storage==1.0.0',
'six==1.15.0'
]
setup(
name='trainer',
version='0.1',
install_requires=REQUIRED_PACKAGES,
packages=find_packages(), # Encontrar automáticamente paquetes en este directorio o a continuación.
include_package_data=True, # si los paquetes incluyen archivos de datos, estos se empaquetarán juntos.
description='Classification training titanic survivors prediction model'
)
Presiona Ctrl + S para guardar el archivo.
Regresa a la terminal y comprueba si puedes entrenar un modelo con task.py.
En primer lugar, crea las siguientes variables de entorno, pero recuerda seleccionar el proyecto de Google Cloud correcto en la consola:
PROJECT_ID se establecerá como el ID del proyecto seleccionado.
BUCKET_NAME será el PROJECT_ID y el “-bucket” adjunto.
export REGION="{{{project_0.default_region|Region}}}"
export PROJECT_ID=$(gcloud config list --format 'value(core.project)')
export BUCKET_NAME=$PROJECT_ID"-bucket"
Crea un bucket para exportar ahí el modelo entrenado:
gsutil mb -l $REGION "gs://"$BUCKET_NAME
Ahora, ejecuta los siguientes comandos. Debes usar todos los datos de entrenamiento para realizar la prueba. Se usará el mismo conjunto de datos para realizar pruebas, validaciones y entrenamientos. Aquí, debes asegurarte de que el código se ejecute y que no contenga errores. En realidad, es recomendable usar distintos datos de prueba y de validación. Debes permitir que el servicio de entrenamiento de Vertex AI se encargue de esto.
En primer lugar, instala las bibliotecas requeridas.
cd /home/jupyter/titanic
pip install setuptools
python setup.py install
Nota: Puedes ignorar el error: google-auth 2.3.3 is installed but google-auth<2.0dev,>=1.25.0 is required by {'google-api-core'}, ya que no afecta a la funcionalidad del lab.
Ahora ejecuta el código de entrenamiento para comprobar que se ejecuta sin problemas:
Si el código se ejecutó correctamente, se imprimirán los registros de INFO y podrás verlos. Son dos líneas. En la primera, se muestra la puntuación F1, que debe ser de aproximadamente 0.85, y, en la segunda, se indica que el trabajo de entrenamiento se completó correctamente:
En esta sección, entrenarás un modelo de Vertex AI. Para ello, usarás la GUI. También existe un modo programático de hacerlo con un SDK de Python. Sin embargo, si usas la GUI, comprenderás mejor el proceso.
En la consola de Google Cloud, navega a Vertex AI > Entrenamiento.
Selecciona la región como .
Haz clic en Entrenar un modelo nuevo.
Método de entrenamiento
En este paso, selecciona el conjunto de datos y define el objetivo del trabajo de entrenamiento.
Conjunto de datos: Es el conjunto de datos que creaste en un paso anterior. El nombre debe ser titanic.
Objetivo: El modelo predice las probabilidades de que un individuo sobreviva en la tragedia del Titanic. Este es un problema de Clasificación.
Entrenamiento personalizado: Debes usar tu paquete de entrenamiento personalizado.
Haz clic en Continuar.
Detalles del modelo
Ahora define el nombre del modelo.
El nombre predeterminado debe ser el del conjunto de datos y de la marca de tiempo. Puedes dejarlo como está.
Si haces clic en Opciones avanzadas, verás la opción para definir la división de los datos entre conjuntos de entrenamiento, prueba y validación. Las asignaciones aleatorias repartirán al azar los datos entre conjuntos de entrenamiento, prueba y validación. Esta parece ser una buena opción.
Haz clic en Continuar.
Contenedor de entrenamiento
Define el entorno de entrenamiento.
Contenedor creado previamente: Google Cloud ofrece un conjunto de contenedores creados previamente que facilitan el entrenamiento de los modelos. Admiten frameworks como scikit‑learn, TensorFlow y XGBoost. Si tu trabajo de entrenamiento usa un elemento exótico, deberás preparar y proporcionar un contenedor (personalizado) para el entrenamiento. Tu modelo se basa en scikit‑learn y ya existe un contenedor creado previamente.
Framework de modelo: scikit‑learn. Esta es la biblioteca que usaste para el entrenamiento de modelos.
Versión del framework de modelo: Tu código es compatible con la versión 0.23.
Ubicación del paquete: Puedes navegar hasta la ubicación de tu paquete de entrenamiento. Esta es la ubicación a la que subiste training-0.1.tar.gz. Si seguiste correctamente los pasos anteriores, la ubicación debería ser gs://YOUR-BUCKET-NAME/titanic/dist/trainer-0.1.tar.gz, y YOUR-BUCKET-NAME es el nombre del bucket que usaste en la sección Crea tu paquete.
Módulo de Python: Es el módulo de Python que creaste en Notebooks. Corresponderá a la carpeta que contiene el código/módulo de entrenamiento y el nombre del archivo de entrada. Debería ser trainer.task
Proyecto de BigQuery para exportar datos: En el paso 1, seleccionaste el conjunto de datos y definiste una división automática. Se crearán en el proyecto seleccionado un conjunto de datos y tablas nuevos para conjuntos de entrenamiento, prueba o validación.
Ingresa el mismo ID del proyecto que ejecutas para el lab.
Además, los URI de los conjuntos de datos de entrenamiento, prueba o validación se configurarán como variables de entorno en el contenedor de entrenamiento, así que puedes usarlas automáticamente para cargar tus datos. Los nombres de las variables de entorno para los conjuntos de datos serán AIP_TRAINING_DATA_URI, AIP_TEST_DATA_URI y AIP_VALIDATION_DATA_URI. También habrá una variable adicional llamada AIP_DATA_FORMAT, que será de tipo csv o bigquery según el tipo del conjunto de datos seleccionado en el paso 1.
Ya creaste esta lógica en task.py. Observa este código de ejemplo (tomado de task.py):
...
parser.add_argument( '--training_data_uri ',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_TRAINING_DATA_URI'] if 'AIP_TRAINING_DATA_URI' in os.environ else "" )
...
Directorio de salida del modelo: Es la ubicación a la que se exportará el modelo. Será una variable de entorno llamada AIP_MODEL_DIR en el contenedor de entrenamiento. En task.py, se incluye un parámetro de entrada para capturar esto:
...
parser.add_argument( '--model_dir',
help = 'Directory to output model and artifacts',
type = str,
default = os.environ['AIP_MODEL_DIR'] if 'AIP_MODEL_DIR' in os.environ else "" )
...
Puedes usar la variable de entorno para saber dónde exportar los artefactos del trabajo de entrenamiento. Seleccionemos lo siguiente: gs://YOUR-BUCKET-NAME/titanic/
Haz clic en Continuar.
Ajuste de hiperparámetros
En la sección de ajuste de hiperparámetros, puedes definir un conjunto de parámetros para ajustar el modelo. Se explorarán diversos valores para crear el modelo con los mejores parámetros. En tu código, no implementaste la funcionalidad del ajustador de hiperparámetros. Son unas pocas líneas de código (alrededor de cinco), pero es mejor no agregar esta complejidad ahora.
Hagamos clic en Continuar para saltar este paso.
Procesamiento y precios
¿Dónde quieres ejecutar el trabajo de entrenamiento y qué tipo de servidor deseas usar? El proceso de entrenamiento de tu modelo no requiere muchos recursos. Pudiste ejecutar el trabajo de entrenamiento en una instancia de notebook relativamente pequeña y la ejecución se completa bastante rápido.
Teniendo esto en cuenta, elige lo siguiente:
Región:
Tipo de máquina: n1-standard-4
Haz clic en Continuar.
Contenedor de predicción
En este paso, puedes decidir si solo quieres entrenar el modelo o si también deseas agregar parámetros de configuración para el servicio de predicción que usas para llevar el modelo a producción.
En este lab, usarás un contenedor creado previamente. Sin embargo, ten en cuenta que Vertex AI ofrece algunas opciones para entregar el modelo:
Sin contenedor de predicción: Solo entrena el modelo y preocúpate después de llevarlo a producción.
Contenedor creado previamente: Entrena el modelo y define qué contenedor creado previamente se usará para la implementación.
Contenedor personalizado: Entrena el modelo y define qué contenedor personalizado se usará para la implementación.
Debes elegir un contenedor creado previamente, dado que Google Cloud ya ofrece un contenedor de scikit-learn. Implementarás el modelo cuando se complete el trabajo de entrenamiento.
Framework de modelo: scikit‑learn
Versión del framework de modelo: 0.23
Directorio del modelo: gs://YOUR-BUCKET-NAME/titanic/. La ruta debe ser la misma que la del directorio de salida del modelo que definiste en el paso 3.
Haz clic en Comenzar el entrenamiento.
El nuevo trabajo de entrenamiento se mostrará en la pestaña Canalización de entrenamiento. El entrenamiento tardará alrededor de 15 minutos en completarse.
Tarea 5. Evaluación del modelo
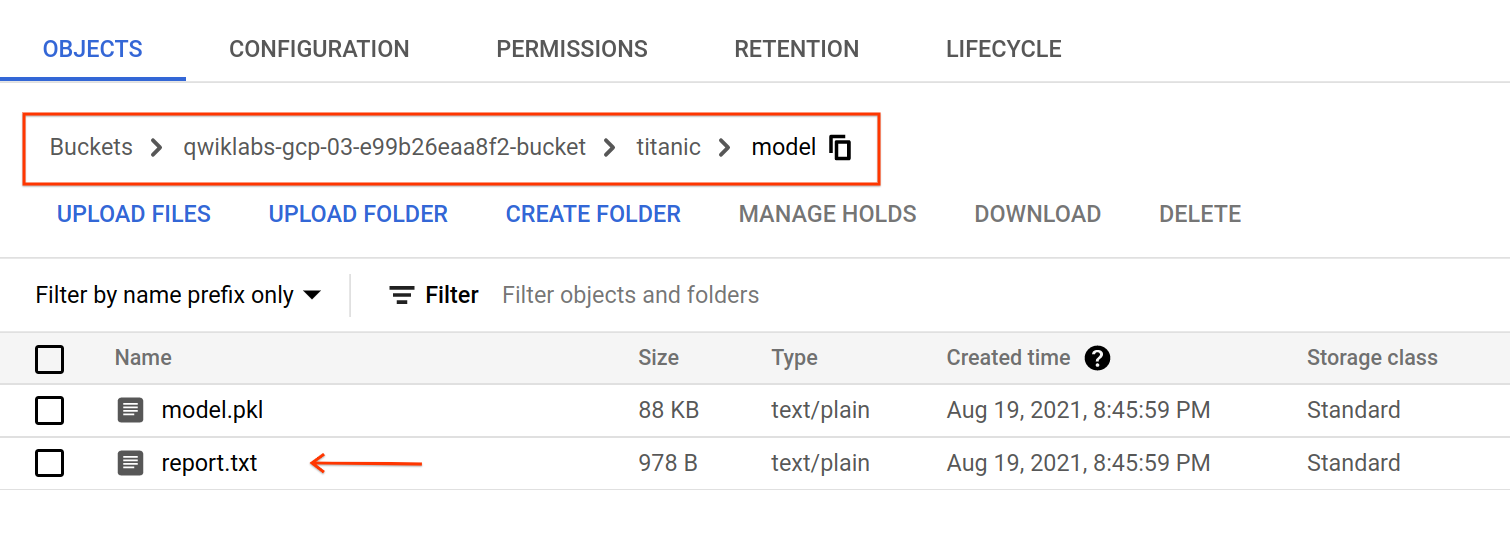
Cuando se complete el trabajo de entrenamiento, se exportarán los artefactos a gs://YOUR-BUCKET-NAME/titanic/model/. Puedes revisar el archivo report.txt que contiene las métricas de evaluación y el informe de clasificación del modelo.
Tarea 6: Implementación del modelo
En el menú de navegación de la consola de Cloud, haz clic en Vertex AI > Entrenamiento.
Cuando se complete el trabajo de entrenamiento de modelos, selecciona el modelo entrenado y, luego, impleméntalo en un extremo.
Navega a la pestaña IMPLEMENTA Y PRUEBA y, luego, haz clic en IMPLEMENTAR EN EL EXTREMO.
En la ventana emergente, puedes definir los recursos necesarios para implementar el modelo:
Nombre del extremo: Es la URL del extremo en el que se entrega el modelo. titanic-endpoint es un nombre adecuado. Haz clic en Continuar.
División del tráfico: Define el porcentaje del tráfico que deseas destinar a este modelo. Un extremo puede tener varios modelos, y tú decides cómo dividir el tráfico entre ellos. En este caso, implementarás solo un modelo, así que el tráfico debe ser del 100%.
Cantidad mínima de nodos de procesamiento: Es la cantidad mínima de nodos que se necesita para entregar las predicciones del modelo. Comienza con 1. Además, el servicio de predicción ajustará la escala automáticamente si hay tráfico.
Cantidad máxima de nodos de procesamiento: Si se aplica el ajuste de escala automático, esta variable define la cantidad máxima de nodos, con lo que se evitan los costos no deseados que pudieran generarse por el ajuste de escala automático. Establece esta variable en 2.
Tipo de máquina: Google Cloud ofrece un conjunto de tipos de máquina en los que puedes implementar tu modelo. Cada tipo tiene especificaciones únicas de memoria y CPU virtual. Tu modelo es sencillo, así que bastará con entregar el modelo en una instancia n1-standard-4.
Haz clic en Done y, luego, en Implementar.
Tarea 7. Predicción del modelo
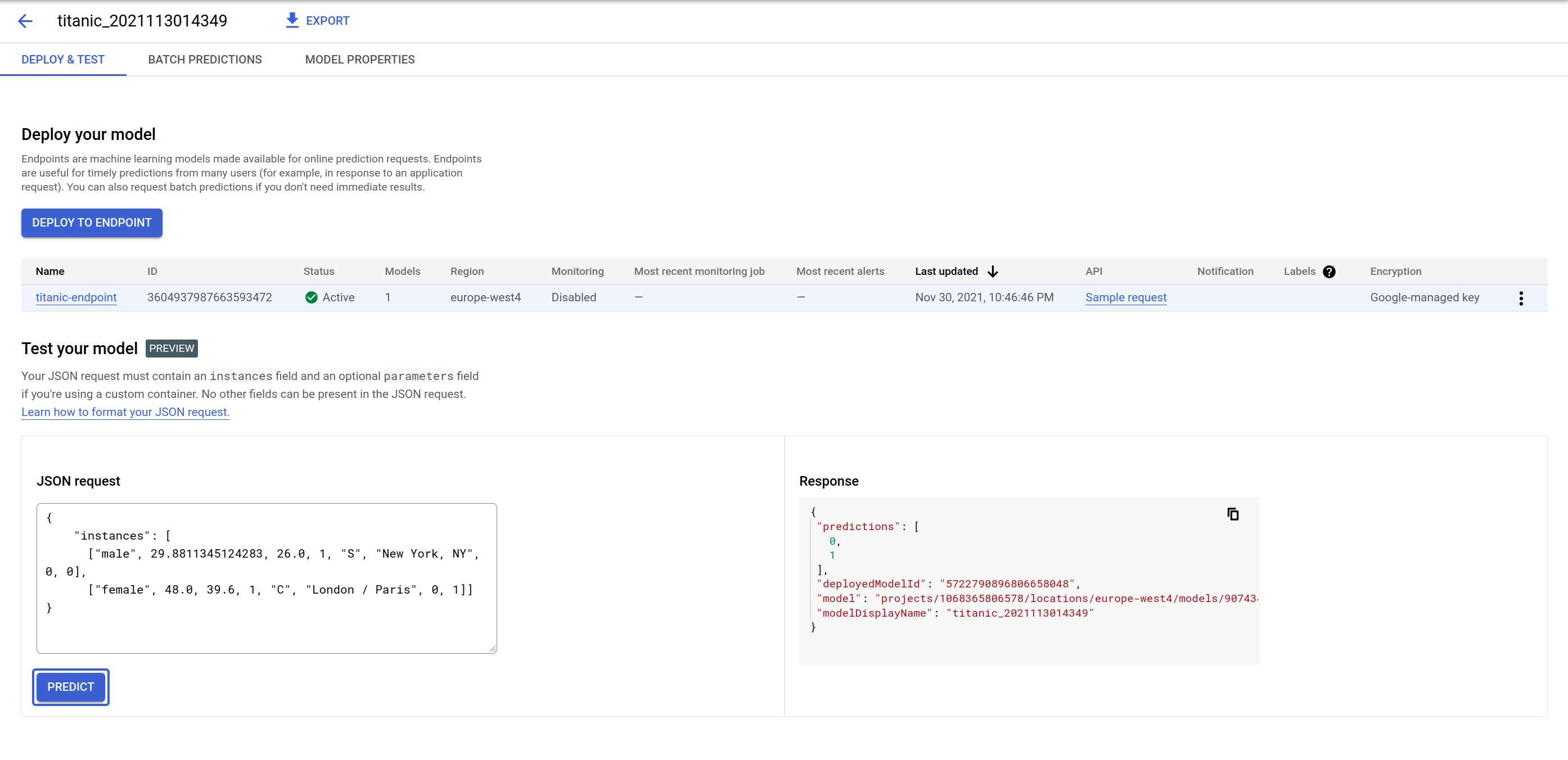
En Implementa tu modelo, prueba el extremo de predicción del modelo. En la GUI, encontrarás un formulario para enviar una carga útil de solicitud en formato JSON; su respuesta serán las predicciones y el ID de modelo que se usó para realizarlas. Esto se debe a que puedes implementar más de un modelo en un extremo y dividir el tráfico.
Prueba la siguiente carga útil; puedes modificar algunos valores para ver cómo cambian las predicciones. Esta es la secuencia de los atributos de entrada: [‘sex', ‘age', ‘fare', ‘pclass', ‘embarked', ‘home_dest', ‘parch', ‘sibsp'].
El extremo genera una lista de ceros y unos en el mismo orden que la entrada. 0 significa que es más probable que el individuo no sobreviva al accidente del Titanic, y 1 indica que es probable que sí lo haga.
Tarea 8. Realiza una limpieza
¡Felicitaciones! Creaste un conjunto de datos, empaquetaste el código de entrenamiento y ejecutaste un trabajo de entrenamiento personalizado con Vertex AI. Además, implementaste el modelo entrenado y enviaste algunos datos para realizar predicciones.
Como no necesitas los recursos creados, es buena idea borrarlos para evitar costos no deseados.
Navega a la página Conjuntos de datos en la consola, haz clic en el menú de tres puntos del conjunto que deseas borrar y, luego, selecciona Borrar conjuntos de datos. Por último, haz clic en Borrar para confirmar esta acción.
Navega a la página Workbench en la consola, selecciona solo el notebook que deseas borrar y haz clic en Borrar en el menú de la parte superior. Por último, haz clic en Borrar para confirmar esta acción.
Para borrar el extremo que implementaste, ve a la sección Extremos de la consola de Vertex AI, haz clic en el que quieras borrar. En el menú ampliado (), selecciona Anular la implementación del modelo en el extremo y haz clic en Anular la implementación.
Para quitar el extremo, haz clic en el menú ampliado () y, luego, en Borrar extremo. Luego, haz clic en Confirmar.
Navega a la página Modelos en la consola, haz clic en los tres puntos () del modelo que deseas borrar y, luego, selecciona Borrar modelo. Luego, haz clic en Borrar.
Para borrar el bucket de Cloud Storage, ve a la página Cloud Storage, selecciona tu bucket y, luego, haz clic en Borrar. Escribe DELETE para confirmar la acción y, luego, haz clic en Borrar.
Sigue estos pasos para borrar el conjunto de datos de BigQuery:
Navega a la consola de BigQuery.
En el panel Explorador, haz clic en el ícono de ver acciones que se encuentra junto a tu conjunto de datos. Haz clic en Borrar.
En el cuadro de diálogo Borrar conjunto de datos, confirma el comando para borrar escribiendo delete y, luego, haciendo clic en Borrar.
Finalice su lab
Cuando haya completado su lab, haga clic en Finalizar lab. Qwiklabs quitará los recursos que usó y limpiará la cuenta por usted.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Neutral
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2020 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usa una ventana de navegación privada o de Incógnito para ejecutar el lab. Así
evitarás cualquier conflicto entre tu cuenta personal y la cuenta
de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
En este lab, usarás Vertex AI para entrenar y, luego, implementar un modelo de AA.
Duración:
0 min de configuración
·
Acceso por 120 min
·
120 min para completar
 ) junto a tu ID del proyecto y selecciona Crear conjunto de datos.
) junto a tu ID del proyecto y selecciona Crear conjunto de datos.