개요
BigQuery ML(BigQuery 머신러닝)은 데이터 분석가가 최소한의 코딩으로 머신러닝 모델을 만들고, 학습시키고, 평가하며, 이를 통해 예측을 수행할 수 있는 BigQuery의 기능입니다.
Google Merchandise Store의 Google 애널리틱스 레코드 수백만 개가 포함된 Google 애널리틱스 샘플 전자상거래 데이터 세트가 BigQuery로 로드되었습니다. 이 실습에서는 이 데이터를 사용하여 기업에서 고객의 구매 습관 관련 사항을 파악할 때 사용하는 몇 가지 일반적인 쿼리를 실행합니다.
목표
이 실습에서는 다음 작업을 수행하는 방법에 대해 알아봅니다.
- BigQuery를 사용하여 공개 데이터 세트 찾기
- 전자상거래 데이터 세트 쿼리 및 살펴보기
- 일괄 예측에 사용할 학습 및 평가 데이터 세트 만들기
- BigQuery ML에서 분류(로지스틱 회귀) 모델 만들기
- 머신러닝 모델의 성능 평가하기
- 방문자가 구매할 가능성 예측 및 순위 지정하기
환경 설정
실습 설정
각 실습에서는 정해진 기간 동안 새 Google Cloud 프로젝트와 리소스 집합이 무료로 제공됩니다.
-
시크릿 창을 사용하여 Qwiklabs에 로그인합니다.
-
실습 사용 가능 시간(예: 1:15:00)을 참고하여 해당 시간 내에 완료합니다.
일시중지 기능은 없습니다. 필요한 경우 다시 시작할 수 있지만 처음부터 시작해야 합니다.
-
준비가 되면 실습 시작을 클릭합니다.
-
실습 사용자 인증 정보(사용자 이름 및 비밀번호)를 기록해 두세요. Google Cloud Console에 로그인합니다.
-
Google Console 열기를 클릭합니다.
-
다른 계정 사용을 클릭한 다음, 안내 메시지에 이 실습에 대한 사용자 인증 정보를 복사하여 붙여넣습니다.
다른 사용자 인증 정보를 사용하는 경우 오류가 발생하거나 요금이 부과됩니다.
-
약관에 동의하고 리소스 복구 페이지를 건너뜁니다.
BigQuery 콘솔 열기
- Google Cloud Console에서 탐색 메뉴 > BigQuery를 선택합니다.
Cloud Console의 BigQuery에 오신 것을 환영합니다라는 메시지 상자가 열립니다. 이 메시지 상자에서는 빠른 시작 가이드 링크 및 UI 업데이트 목록을 확인할 수 있습니다.
-
완료를 클릭합니다.
과정 데이터 세트 액세스
BigQuery가 열리면 새 브라우저 탭에서 data-to-insights 프로젝트를 열어 이 프로젝트를 BigQuery 프로젝트 패널로 가져옵니다.
data-to-insights 전자상거래 데이터 세트에 대한 필드 정의는 [UA] BigQuery Export 스키마 페이지에 있습니다. 참고용으로 새 탭에서 링크를 열어둡니다.
작업 1. 전자상거래 데이터 탐색
시나리오: 데이터 분석가 팀이 전자상거래 웹사이트에 대한 Google 애널리틱스 로그를 BigQuery로 내보내고 모든 전자상거래 방문자 세션 원시 데이터를 사용하여 탐색 가능한 새 테이블을 만들었습니다. 이 데이터를 사용하여 몇 가지 질문에 답변해 보세요.
질문: 웹사이트를 방문한 전체 방문자 중 제품을 구매한 방문자는 몇 퍼센트(%)인가요?
- 쿼리 편집기를 클릭합니다.
- 새로운 쿼리 필드에 다음을 추가합니다.
#standardSQL
WITH visitors AS(
SELECT
COUNT(DISTINCT fullVisitorId) AS total_visitors
FROM `data-to-insights.ecommerce.web_analytics`
),
purchasers AS(
SELECT
COUNT(DISTINCT fullVisitorId) AS total_purchasers
FROM `data-to-insights.ecommerce.web_analytics`
WHERE totals.transactions IS NOT NULL
)
SELECT
total_visitors,
total_purchasers,
total_purchasers / total_visitors AS conversion_rate
FROM visitors, purchasers
-
실행을 클릭합니다.
결과는 2.69%입니다.
질문: 판매율 상위 5개 제품은 무엇인가요?
- 쿼리 편집기에 다음 쿼리를 추가한 후 실행을 클릭합니다.
SELECT
p.v2ProductName,
p.v2ProductCategory,
SUM(p.productQuantity) AS units_sold,
ROUND(SUM(p.localProductRevenue/1000000),2) AS revenue
FROM `data-to-insights.ecommerce.web_analytics`,
UNNEST(hits) AS h,
UNNEST(h.product) AS p
GROUP BY 1, 2
ORDER BY revenue DESC
LIMIT 5;
결과:
| 행 |
v2ProductName |
v2ProductCategory |
units_sold |
revenue |
| 1 |
Nest® Learning Thermostat 3rd Gen-USA - Stainless Steel |
Nest-USA |
17651 |
870976.95 |
| 2 |
Nest® Cam Outdoor Security Camera - USA |
Nest-USA |
16930 |
684034.55 |
| 3 |
Nest® Cam Indoor Security Camera - USA |
Nest-USA |
14155 |
548104.47 |
| 4 |
Nest® Protect Smoke + CO White Wired Alarm-USA |
Nest-USA |
6394 |
178937.6 |
| 5 |
Nest® Protect Smoke + CO White Battery Alarm-USA |
Nest-USA |
6340 |
178572.4 |
질문: 웹사이트를 재방문하여 구매한 방문자는 몇 명입니까?
- 다음 쿼리를 실행하여 확인합니다.
# visitors who bought on a return visit (could have bought on first as well
WITH all_visitor_stats AS (
SELECT
fullvisitorid, # 741,721 unique visitors
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
SELECT
COUNT(DISTINCT fullvisitorid) AS total_visitors,
will_buy_on_return_visit
FROM all_visitor_stats
GROUP BY will_buy_on_return_visit
결과:
| 행 |
total_visitors |
will_buy_on_return_visit |
| 1 |
729848 |
0 |
| 2 |
11873 |
1 |
결과를 분석해보면 전체 방문자의 1.6%(11873 / 729848)가 웹사이트를 재방문하여 구매하는 것을 알 수 있습니다. 여기에는 첫 번째 세션에서 구매한 후 다시 방문하여 재구매한 방문자의 하위 집합이 포함됩니다.
이러한 행동은 구매를 결정하기 전에 고객이 시간을 들여 사전 조사와 비교를 수행하는 고가의 제품(예: 자동차 구매) 구입 시 흔히 발생하지만, 이 사이트의 상품(티셔츠, 액세서리 등)을 구입할 때에도 어느 정도는 발생합니다.
온라인 마케팅에서는 첫 방문 시 특성을 기반으로 미래 고객을 식별하고 이들에게 마케팅하면 전환율을 높이고 경쟁 사이트로의 유출을 줄일 수 있습니다.
작업 2. 특성 선택 및 학습 데이터 세트 만들기
이제 BigQuery에서 머신러닝 모델을 만들어 향후 신규 사용자의 구매 가능성을 예측해 보겠습니다. 이러한 고가치 사용자를 식별하면 마케팅팀이 특별 프로모션 및 광고 캠페인을 통해 이들을 타겟팅하는 데 도움이 될 수 있습니다.
Google 애널리틱스는 이 전자상거래 웹사이트에서 사용자의 방문에 대한 다양한 측정기준과 측정값을 수집합니다. [UA] BigQuery Export 스키마 가이드에서 전체 필드 목록을 둘러본 다음 데모 데이터 세트 미리보기를 통해 머신러닝 모델이 방문자의 웹사이트 첫 방문 관련 데이터와 재방문 시 구매할지 여부 사이의 관계를 이해하는 데 도움이 되는 유용한 특성을 찾습니다.
팀에서 다음 두 필드가 분류 모델에 적합한 입력인지 여부를 테스트하기로 결정합니다.
-
totals.bounces(방문자가 웹사이트를 즉시 떠났는지 여부)
-
totals.timeOnSite(방문자가 웹사이트에 머문 시간)
머신러닝의 성능은 입력되는 학습 데이터의 품질에 좌우됩니다. 모델이 입력 특성과 라벨(이 경우 방문자가 나중에 구매했는지 여부) 사이의 관계를 판단하고 둘의 관계를 학습할 수 있는 정보가 충분하지 않으면 모델의 정확성이 낮아집니다. 처음에는 이 두 필드로만 모델을 학습시키지만, 두 필드의 값이 정확한 모델을 생성하기에 충분한지 곧 확인할 수 있습니다.
- 쿼리 편집기에서 다음 쿼리를 추가한 후 실행을 클릭합니다.
SELECT
* EXCEPT(fullVisitorId)
FROM
# features
(SELECT
fullVisitorId,
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
totals.newVisits = 1)
JOIN
(SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM
`data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid)
USING (fullVisitorId)
ORDER BY time_on_site DESC
LIMIT 10;
결과:
| 행 |
bounces |
time_on_site |
will_buy_on_return_visit |
| 1 |
0 |
15047 |
0 |
| 2 |
0 |
12136 |
0 |
| 3 |
0 |
11201 |
0 |
| 4 |
0 |
10046 |
0 |
| 5 |
0 |
9974 |
0 |
| 6 |
0 |
9564 |
0 |
| 7 |
0 |
9520 |
0 |
| 8 |
0 |
9275 |
1 |
| 9 |
0 |
9138 |
0 |
| 10 |
0 |
8872 |
0 |
설명: 첫 번째 방문이 이뤄진 직후에는 will_buy_on_return_visit를 알 수 없습니다. 이 실습에서는 웹사이트를 재방문하여 구매한 사용자의 하위 집합을 예측하고자 합니다. 예측 시점에는 미래를 알 수 없기 때문에 신규 방문자가 재방문하여 구매할 것인지 단정할 수 없습니다. ML 모델을 구축하면 첫 번째 세션에 대해 얻은 데이터를 기반으로 향후 구매 확률을 구할 수 있습니다.
질문: 초기 데이터 결과를 봤을 때 time_on_site 및 bounces가 사용자의 재방문 구매 여부를 가늠할 수 있는 좋은 지표가 될 것 같나요?
답변: 모델을 학습시키고 평가하기 전에 판단하기는 어렵지만, 빠르게 훑어봤을 때 상위 10개 time_on_site 중 단 1명의 고객만 구매하기 위해 재방문했으므로 그다지 좋은 지표라고 할 수 없습니다. 모델이 얼마나 잘 작동하는지 살펴보겠습니다.
작업 3. 모델을 저장할 BigQuery 데이터 세트 만들기
다음으로 ML 모델을 저장할 새 BigQuery 데이터 세트를 만듭니다.
- 왼쪽 창에서 프로젝트 이름을 클릭한 다음
작업 보기 아이콘(점 3개)을 클릭하고 데이터 세트 만들기를 선택합니다.
-
데이터 세트 만들기 대화상자에서 다음을 실행합니다.
-
데이터 세트 ID에 전자상거래를 입력합니다.
- 다른 값은 기본값을 유지합니다.
-
데이터 세트 만들기를 클릭합니다.
작업 4. BigQuery ML 모델 유형 선택 및 옵션 지정
초기 특성을 선택했으므로 이제 BigQuery에서 첫 번째 ML 모델을 만들어 보도록 하겠습니다.
선택할 수 있는 두 가지 모델 유형이 있습니다.
| 모델 |
모델 유형 |
라벨 데이터 유형 |
예 |
| 예측 |
linear_reg |
숫자 값(보통 정수 또는 부동 소수점) |
과거 매출 데이터를 바탕으로 내년 매출 수치를 예측합니다. |
| 분류 |
logistic_reg |
0 또는 1(이진 분류) |
컨텍스트를 바탕으로 이메일을 일반 또는 스팸으로 분류합니다. |
참고: 그 밖에도 머신러닝에 사용할 수 있는 다양한 유형의 모델(예: 신경망, 결정 트리)이 있으며, TensorFlow와 같은 라이브러리를 통해 사용할 수 있습니다. 이 실습의 작성 시점을 기준으로, BigQuery ML은 위에 나열된 두 가지 유형의 모델을 지원합니다.
- 다음 쿼리를 입력하여 모델을 만들고 모델 옵션을 지정합니다.
CREATE OR REPLACE MODEL `ecommerce.classification_model`
OPTIONS
(
model_type='logistic_reg',
labels = ['will_buy_on_return_visit']
)
AS
#standardSQL
SELECT
* EXCEPT(fullVisitorId)
FROM
# features
(SELECT
fullVisitorId,
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
totals.newVisits = 1
AND date BETWEEN '20160801' AND '20170430') # train on first 9 months
JOIN
(SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM
`data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid)
USING (fullVisitorId)
;
- 그런 다음 실행을 클릭하여 모델을 학습시킵니다.
모델이 학습을 마칠 때까지 기다립니다(5~10분).
참고: 모델 평가 및 테스트를 위해 일부 데이터 포인트를 입력에 사용하지 않고 남겨 두어야 하므로 모델 학습에 사용 가능한 모든 데이터를 피딩하면 안 됩니다. 이를 수행하려면, 12개월 데이터 세트에서 첫 9개월간의 세션 데이터를 필터링하여 학습에 사용하도록 WHERE 절 조건을 추가합니다.
모델 학습이 끝나면 '이 문으로 이름이 qwiklabs-gcp-xxxxxxxxx:ecommerce.classification_model인 새 모델이 생성되었습니다'라는 메시지가 표시됩니다.
-
모델로 이동을 클릭합니다.
전자상거래 데이터 세트를 살펴보고 이제 classification_model이 표시되는지 확인합니다.
다음 단계에서는 입력되지 않은 새 평가 데이터를 기반으로 모델 성능을 평가하겠습니다.
작업 5. 분류 모델 성능 평가
성능 기준 선택
ML의 분류 문제의 경우, 거짓양성률(사용자가 재방문하여 구매할 것으로 예상하지만 실제로는 구매하지 않음)을 최소화하고 참양성률(사용자가 재방문하여 구매할 것으로 예상하고 실제로 구매함)을 최대화하는 것이 바람직합니다.
이 관계는 아래에서처럼 ROC(수신자 조작 특성) 곡선으로 시각화할 수 있으며, 곡선 아래 영역(AUC)을 최대화하고자 합니다.
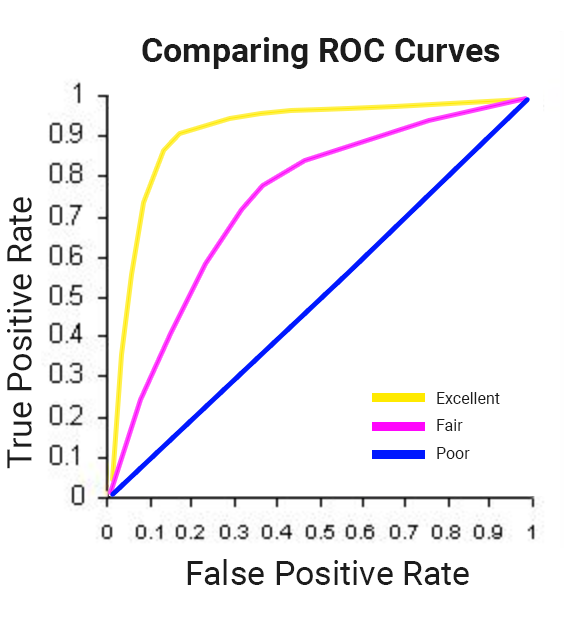
BigQuery ML에서 roc_auc는 학습된 ML 모델을 평가할 때 쿼리 가능한 필드입니다.
- 이제 학습이 완료되었으므로,
ML.EVALUATE를 사용하여 이 쿼리를 실행함으로써 모델 성능이 어떤지 평가할 수 있습니다.
SELECT
roc_auc,
CASE
WHEN roc_auc > .9 THEN 'good'
WHEN roc_auc > .8 THEN 'fair'
WHEN roc_auc > .7 THEN 'not great'
ELSE 'poor' END AS model_quality
FROM
ML.EVALUATE(MODEL ecommerce.classification_model, (
SELECT
* EXCEPT(fullVisitorId)
FROM
# features
(SELECT
fullVisitorId,
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
totals.newVisits = 1
AND date BETWEEN '20170501' AND '20170630') # eval on 2 months
JOIN
(SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM
`data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid)
USING (fullVisitorId)
));
결과:
| 행 |
roc_auc |
model_quality |
| 1 |
0.724588 |
not great |
모델 평가를 완료하면 roc_auc가 0.72로 나타나며, 이는 모델의 예측 성능이 좋지 않음을 나타냅니다. 목표는 곡선 아래 영역을 가능한 한 1.0에 가깝게 만드는 것이므로 개선의 여지가 있습니다.
작업 6. 특성 추출로 모델 성능 향상
앞서 잠깐 언급했듯이 데이터 세트에는 방문자의 첫 번째 세션과 후속 방문에서 구매할 가능성 사이의 관계를 모델이 더 잘 파악하는 데 도움이 되는 더 많은 특성이 있습니다.
몇 가지 새로운 특성을 추가하고 classification_model_2라는 두 번째 머신러닝 모델을 만듭니다.
- 첫 방문 시 방문자가 결제 프로세스를 진행한 정도
- 방문자의 유입 경로(트래픽 소스: 자연 검색, 추천 사이트 등)
- 기기 카테고리(모바일, 태블릿, 데스크톱)
- 지리 정보(국가)
- 아래 쿼리를 실행하여 두 번째 모델을 만듭니다.
CREATE OR REPLACE MODEL `ecommerce.classification_model_2`
OPTIONS
(model_type='logistic_reg', labels = ['will_buy_on_return_visit']) AS
WITH all_visitor_stats AS (
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
# add in new features
SELECT * EXCEPT(unique_session_id) FROM (
SELECT
CONCAT(fullvisitorid, CAST(visitId AS STRING)) AS unique_session_id,
# labels
will_buy_on_return_visit,
MAX(CAST(h.eCommerceAction.action_type AS INT64)) AS latest_ecommerce_progress,
# behavior on the site
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site,
totals.pageviews,
# where the visitor came from
trafficSource.source,
trafficSource.medium,
channelGrouping,
# mobile or desktop
device.deviceCategory,
# geographic
IFNULL(geoNetwork.country, "") AS country
FROM `data-to-insights.ecommerce.web_analytics`,
UNNEST(hits) AS h
JOIN all_visitor_stats USING(fullvisitorid)
WHERE 1=1
# only predict for new visits
AND totals.newVisits = 1
AND date BETWEEN '20160801' AND '20170430' # train 9 months
GROUP BY
unique_session_id,
will_buy_on_return_visit,
bounces,
time_on_site,
totals.pageviews,
trafficSource.source,
trafficSource.medium,
channelGrouping,
device.deviceCategory,
country
);
참고: 이 새로운 모델도 이전과 동일하게 첫 9개월간의 데이터로 학습시킵니다. 모델 출력의 품질이 새로운 학습 데이터나 다른 학습 데이터가 아니라 더 나은 입력 특성에 따라 향상됨을 확인하기 위해 동일한 학습 데이터 세트를 사용하는 것이 중요합니다.
학습 데이터 세트 쿼리에 추가된 중요한 새 특성은 각 방문자가 세션에서 도달한 최대 결제 진행률이며 hits.eCommerceAction.action_type 필드에 기록되어 있습니다. 필드 정의에서 해당 필드를 검색하면 6 = Completed Purchase의 필드 매핑이 표시됩니다.
별도로 웹로그 분석 데이터 세트에는 ARRAYS와 같이 데이터 세트에서 별도의 행으로 분리해야 하는 중첩되고 반복되는 필드가 있습니다. 위의 쿼리에서 볼 수 있듯 UNNEST() 함수를 사용하여 행을 분리할 수 있습니다.
새 모델이 학습을 마칠 때까지 기다립니다(5~10분).
- 이 새로운 모델의 예측 성능이 더 나은지 확인하기 위해 아래 쿼리를 실행합니다.
#standardSQL
SELECT
roc_auc,
CASE
WHEN roc_auc > .9 THEN 'good'
WHEN roc_auc > .8 THEN 'fair'
WHEN roc_auc > .7 THEN 'not great'
ELSE 'poor' END AS model_quality
FROM
ML.EVALUATE(MODEL ecommerce.classification_model_2, (
WITH all_visitor_stats AS (
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
# add in new features
SELECT * EXCEPT(unique_session_id) FROM (
SELECT
CONCAT(fullvisitorid, CAST(visitId AS STRING)) AS unique_session_id,
# labels
will_buy_on_return_visit,
MAX(CAST(h.eCommerceAction.action_type AS INT64)) AS latest_ecommerce_progress,
# behavior on the site
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site,
totals.pageviews,
# where the visitor came from
trafficSource.source,
trafficSource.medium,
channelGrouping,
# mobile or desktop
device.deviceCategory,
# geographic
IFNULL(geoNetwork.country, "") AS country
FROM `data-to-insights.ecommerce.web_analytics`,
UNNEST(hits) AS h
JOIN all_visitor_stats USING(fullvisitorid)
WHERE 1=1
# only predict for new visits
AND totals.newVisits = 1
AND date BETWEEN '20170501' AND '20170630' # eval 2 months
GROUP BY
unique_session_id,
will_buy_on_return_visit,
bounces,
time_on_site,
totals.pageviews,
trafficSource.source,
trafficSource.medium,
channelGrouping,
device.deviceCategory,
country
)
));
(출력)
| 행 |
roc_auc |
model_quality |
| 1 |
0.910382 |
good |
새 모델의 roc_auc는 0.91로 첫 번째 모델보다 훨씬 결과가 개선되었습니다.
이제 학습된 모델이 있으므로 몇 가지 예측을 수행해 보겠습니다.
작업 7. 어떤 신규 방문자가 재방문하여 구매할 것인지 예측
다음으로 어떤 신규 방문자가 재방문하여 구매할 것인지 예측하는 쿼리를 작성해 보겠습니다.
- 개선된 분류 모델을 사용하는 아래의 예측 쿼리를 실행하여 Google Merchandise Store의 신규 방문자가 재방문 시 구매할 확률을 예측합니다.
SELECT
*
FROM
ml.PREDICT(MODEL `ecommerce.classification_model_2`,
(
WITH all_visitor_stats AS (
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
SELECT
CONCAT(fullvisitorid, '-',CAST(visitId AS STRING)) AS unique_session_id,
# labels
will_buy_on_return_visit,
MAX(CAST(h.eCommerceAction.action_type AS INT64)) AS latest_ecommerce_progress,
# behavior on the site
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site,
totals.pageviews,
# where the visitor came from
trafficSource.source,
trafficSource.medium,
channelGrouping,
# mobile or desktop
device.deviceCategory,
# geographic
IFNULL(geoNetwork.country, "") AS country
FROM `data-to-insights.ecommerce.web_analytics`,
UNNEST(hits) AS h
JOIN all_visitor_stats USING(fullvisitorid)
WHERE
# only predict for new visits
totals.newVisits = 1
AND date BETWEEN '20170701' AND '20170801' # test 1 month
GROUP BY
unique_session_id,
will_buy_on_return_visit,
bounces,
time_on_site,
totals.pageviews,
trafficSource.source,
trafficSource.medium,
channelGrouping,
device.deviceCategory,
country
)
)
ORDER BY
predicted_will_buy_on_return_visit DESC;
데이터 세트의 지난 1개월(12개월 중)에 대해 예측이 이루어집니다.
이제 모델은 2017년 7월 전자상거래 세션에 대한 예측을 출력합니다. 다음과 같은 새로 추가된 필드 3개를 볼 수 있습니다.
- predicted_will_buy_on_return_visit: 모델이 방문자가 나중에 구매할 것이라고 생각하는지 여부(1 = 예)
- predicted_will_buy_on_return_visit_probs.label: 예/아니요에 관한 바이너리 분류기
- predicted_will_buy_on_return_visit_probs.prob: 모델의 예측에 대한 신뢰도(1 = 100%)
결과
- 신규 방문자의 상위 6%(예측 확률이 내림차순으로 정렬됨) 중 6% 이상은 재방문 시 구매합니다.
- 이러한 사용자는 재방문 시 구매하는 모든 신규 방문자의 거의 50%를 차지합니다.
- 전반적으로 신규 방문자의 0.7%만이 재방문 시 구매를 진행합니다.
- 신규 방문자의 상위 6%를 타겟팅하면 모든 방문자를 타겟팅할 때보다 마케팅 ROI가 9배 증가합니다.
추가 정보
roc_auc는 모델 평가 중에 사용할 수 있는 성능 측정항목 중 하나일 뿐입니다. 또한 정확성, 정밀도, 재현율을 사용할 수 있습니다. 전반적인 목표가 무엇인지에 따라 적절한 성능 측정항목을 선택합니다.
축하합니다
SQL만 사용하여 머신러닝 모델을 만들었습니다.
도전과제
요약
앞선 두 작업을 통해 모델 성능 개선에 있어 특성 추출의 영향력을 확인했습니다. 하지만 여전히 다른 모델 유형을 시험하여 성능 향상을 도모할 수 있습니다. 분류 문제의 경우 BigQuery ML은 다음 모델 유형도 지원합니다.
작업
특성 추출 이후 선형 분류(로지스틱 회귀) 모델이 쓸만한 성능을 내기는 했지만, 이 모델은 특성과 라벨 간의 관계를 완전히 포착하기에는 지나치게 단순한 편입니다. 이번 도전과제에서는 작업 6에서 ecommerce.classification_model_2 모델을 생성하기 위해 사용한 것과 동일한 데이터 세트 및 라벨을 사용하여 XGBoost 분류기를 생성해 보세요.
참고:
힌트: Boosted_Tree_Classifier에 대해 다음 옵션을 사용하세요.
1. L2_reg = 0.1
2. num_parallel_tree = 8
3. max_tree_depth = 10
정확한 문법을 보려면 위에 링크된 문서를 참조해야 할 수도 있습니다. 모델을 학습시키는 데 7분 정도 걸립니다. 쿼리 작성에 도움이 필요한 경우 아래 솔루션 섹션에서 솔루션을 참고하세요.
솔루션:
다음은 XGBoost 분류기를 생성하는 데 필요한 솔루션입니다.
CREATE OR REPLACE MODEL `ecommerce.classification_model_3`
OPTIONS
(model_type='BOOSTED_TREE_CLASSIFIER' , l2_reg = 0.1, num_parallel_tree = 8, max_tree_depth = 10,
labels = ['will_buy_on_return_visit']) AS
WITH all_visitor_stats AS (
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
# add in new features
SELECT * EXCEPT(unique_session_id) FROM (
SELECT
CONCAT(fullvisitorid, CAST(visitId AS STRING)) AS unique_session_id,
# labels
will_buy_on_return_visit,
MAX(CAST(h.eCommerceAction.action_type AS INT64)) AS latest_ecommerce_progress,
# behavior on the site
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site,
totals.pageviews,
# where the visitor came from
trafficSource.source,
trafficSource.medium,
channelGrouping,
# mobile or desktop
device.deviceCategory,
# geographic
IFNULL(geoNetwork.country, "") AS country
FROM `data-to-insights.ecommerce.web_analytics`,
UNNEST(hits) AS h
JOIN all_visitor_stats USING(fullvisitorid)
WHERE 1=1
# only predict for new visits
AND totals.newVisits = 1
AND date BETWEEN '20160801' AND '20170430' # train 9 months
GROUP BY
unique_session_id,
will_buy_on_return_visit,
bounces,
time_on_site,
totals.pageviews,
trafficSource.source,
trafficSource.medium,
channelGrouping,
device.deviceCategory,
country
);
이제 모델을 평가하고 결과를 살펴보겠습니다.
#standardSQL
SELECT
roc_auc,
CASE
WHEN roc_auc > .9 THEN 'good'
WHEN roc_auc > .8 THEN 'fair'
WHEN roc_auc > .7 THEN 'not great'
ELSE 'poor' END AS model_quality
FROM
ML.EVALUATE(MODEL ecommerce.classification_model_3, (
WITH all_visitor_stats AS (
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
# add in new features
SELECT * EXCEPT(unique_session_id) FROM (
SELECT
CONCAT(fullvisitorid, CAST(visitId AS STRING)) AS unique_session_id,
# labels
will_buy_on_return_visit,
MAX(CAST(h.eCommerceAction.action_type AS INT64)) AS latest_ecommerce_progress,
# behavior on the site
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site,
totals.pageviews,
# where the visitor came from
trafficSource.source,
trafficSource.medium,
channelGrouping,
# mobile or desktop
device.deviceCategory,
# geographic
IFNULL(geoNetwork.country, "") AS country
FROM `data-to-insights.ecommerce.web_analytics`,
UNNEST(hits) AS h
JOIN all_visitor_stats USING(fullvisitorid)
WHERE 1=1
# only predict for new visits
AND totals.newVisits = 1
AND date BETWEEN '20170501' AND '20170630' # eval 2 months
GROUP BY
unique_session_id,
will_buy_on_return_visit,
bounces,
time_on_site,
totals.pageviews,
trafficSource.source,
trafficSource.medium,
channelGrouping,
device.deviceCategory,
country
)
));
roc_auc가 0.02 정도 늘어나 약 0.94로 증가했습니다.
참고: 정확한 값은 학습 과정에 포함된 임의성으로 인해 차이가 있을 수 있습니다.
roc_auc는 근소하게 변하지만 1은 완전한 roc_auc이므로 1에 가까울수록 측정항목을 개선하기가 더 어렵습니다.
이는 BigQuery ML에서 다양한 옵션으로 다양한 모델 유형을 시도하여 성능을 확인하기가 얼마나 쉬운지 보여주는 좋은 예입니다. SQL을 한 줄만 변경하여 훨씬 더 복잡한 모델 유형을 사용할 수 있었습니다.
ML 모델 학습에 사용할 적절한 옵션을 선택하는 방법은 실험을 거듭하는 것입니다. 해결하고자 하는 문제에 가장 적합한 모델 유형을 찾으려면 초매개변수 조정이라는 프로세스에서 다양한 옵션 조합을 실험해야 합니다.
개선된 모델로 예측을 생성하고 이전 모델로 생성한 예측과 어떤 차이가 있는지 살펴보면서 마무리하도록 하겠습니다. 부스팅된 트리 분류기 모델을 사용하면 ROC AUC가 이전 모델보다 0.2 정도 다소 개선된 것을 관찰할 수 있습니다. 아래 쿼리는 어떤 신규 방문자가 재방문하여 구매할 것인지를 예측합니다.
SELECT
*
FROM
ml.PREDICT(MODEL `ecommerce.classification_model_3`,
(
WITH all_visitor_stats AS (
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
SELECT
CONCAT(fullvisitorid, '-',CAST(visitId AS STRING)) AS unique_session_id,
# labels
will_buy_on_return_visit,
MAX(CAST(h.eCommerceAction.action_type AS INT64)) AS latest_ecommerce_progress,
# behavior on the site
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site,
totals.pageviews,
# where the visitor came from
trafficSource.source,
trafficSource.medium,
channelGrouping,
# mobile or desktop
device.deviceCategory,
# geographic
IFNULL(geoNetwork.country, "") AS country
FROM `data-to-insights.ecommerce.web_analytics`,
UNNEST(hits) AS h
JOIN all_visitor_stats USING(fullvisitorid)
WHERE
# only predict for new visits
totals.newVisits = 1
AND date BETWEEN '20170701' AND '20170801' # test 1 month
GROUP BY
unique_session_id,
will_buy_on_return_visit,
bounces,
time_on_site,
totals.pageviews,
trafficSource.source,
trafficSource.medium,
channelGrouping,
device.deviceCategory,
country
)
)
ORDER BY
predicted_will_buy_on_return_visit DESC;
출력을 살펴보면 이 분류 모델은 이제 Google Merchandise Store의 신규 방문자가 재방문 시 구매할 확률을 더 잘 예측합니다.
위의 결과를 작업 7의 이전 모델과 비교하면 logistic_regression 모델 유형보다 해당 모델의 예측 신뢰도가 더 정확하다는 것을 알 수 있습니다.
실습 종료하기
실습을 완료하면 실습 종료를 클릭합니다. Google Cloud Skills Boost에서 사용된 리소스를 자동으로 삭제하고 계정을 지웁니다.
실습 경험을 평가할 수 있습니다. 해당하는 별표 수를 선택하고 의견을 입력한 후 제출을 클릭합니다.
별점의 의미는 다음과 같습니다.
- 별표 1개 = 매우 불만족
- 별표 2개 = 불만족
- 별표 3개 = 중간
- 별표 4개 = 만족
- 별표 5개 = 매우 만족
의견을 제공하고 싶지 않다면 대화상자를 닫으면 됩니다.
의견이나 제안 또는 수정할 사항이 있다면 지원 탭을 사용하세요.
Copyright 2020 Google LLC All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.





