
Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Create an API Key
/ 40
Make an Sentiment Analysis Request
/ 30
Check the Sentiment Analysis response
/ 30
The Cloud Natural Language API lets you extract entities from text, perform sentiment and syntactic analysis, and classify text into categories.
In this lab, you learn how to perform the following tasks:
Create a Natural Language API request and call the API
Run sentiment analysis on sample phrases using the Natural Language API
Perform linguistic analysis on text to create dependency parse trees
For each lab, you get a new Google Cloud project and set of resources for a fixed time at no cost.
Sign in to Qwiklabs using an incognito window.
Note the lab's access time (for example, 1:15:00), and make sure you can finish within that time.
There is no pause feature. You can restart if needed, but you have to start at the beginning.
When ready, click Start lab.
Note your lab credentials (Username and Password). You will use them to sign in to the Google Cloud Console.
Click Open Google Console.
Click Use another account and copy/paste credentials for this lab into the prompts.
If you use other credentials, you'll receive errors or incur charges.
Accept the terms and skip the recovery resource page.
In this task, you generate an API key that will allow you to send, get, or pull requests when using the Natural Language API.
In the Cloud Console, on the Navigation menu (
Click Create credentials, and then click API key.
Copy the generated API key, and then click Close.
Click Check my progress to verify the objective.
In the next steps, you connect to the instance provisioned for you via SSH.
), click Compute Engine.
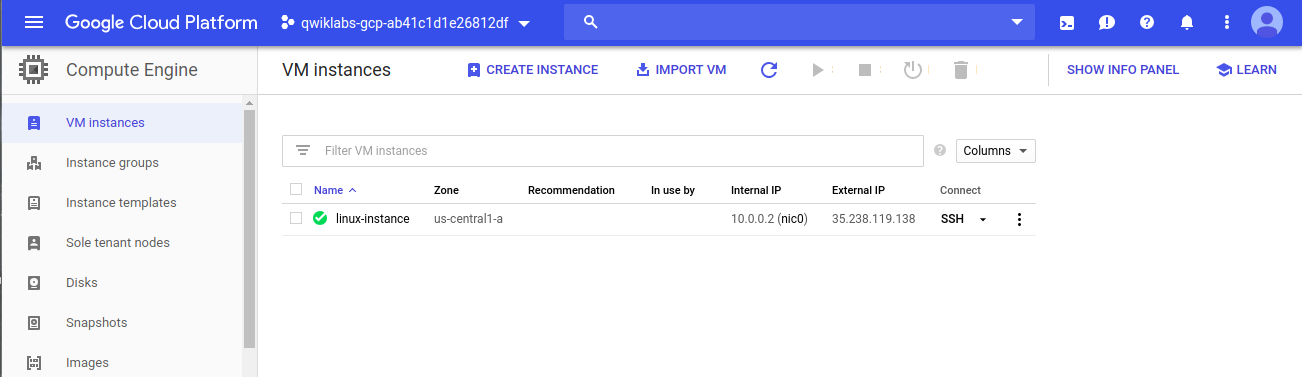
You should see a provisioned linux instance:Click on the SSH button. You will be brought to an interactive shell.
In the command line, execute the following command, replacing <YOUR_API_KEY> with the key you just copied:
In this task, you submit a request written in JSON—a specific programming language. The Natural Language API lets you perform sentiment analysis on a block of text.
Open the request.json file by executing the following command:
Replace the code in request.json with the following sentiment:
Click Check my progress to verify the objective.
Send the request to the API's analyzeSentiment endpoint by executing the following command:
Check the response type by executing the following command:
Your response should look like this:
Notice that you get two types of sentiment values: sentiment for the document as a whole, and sentiment broken down by sentence. The sentiment method returns two values:
score - is a number from -1.0 to 1.0 indicating how positive or negative the statement is.magnitude - is a number ranging from 0 to infinity that represents the weight of sentiment expressed in the statement, regardless of being positive or negative.Longer blocks of text with heavily weighted statements have higher magnitude values. The score for the first sentence is positive (0.9), whereas the score for the second sentence is also (0.9).
Click Check my progress to verify the objective.
In this task, you use the Natural Language API to obtain sentiment for each entity in the text. The Natural Language API can not only provide details on the entire text document, but can also break down sentiment by the entities in the text, for example:
I liked the yoga instructor but the room was really dusty.
In this case, getting a sentiment score for the entire sentence as you did above might not be so useful. If this was a yoga class review and there were hundreds of reviews for the same class, you'd want to know exactly which things people liked and didn't like in their reviews.
Fortunately, the Natural Language API has a method that lets you get the sentiment for each entity in the text, called analyzeEntitySentiment. Let's see how it works!
Open the request.json file by typing the following command:
Replace the code in request.json with the following sentiment:
Press CTRL+O, ENTER to save the file, and press CTRL+X to exit nano.
Call the analyzeEntitySentiment endpoint by typing the following command:
In the response, you receive two entity objects: one for "yoga instructor" and one for "room". See below for the full JSON response:
You can see that the score returned for "instructor" was 0.1, whereas "room" got a score of 0. Cool! You also may notice that there are two sentiment objects returned for each entity. If either of these terms were mentioned more than once, the API would return a different sentiment score and magnitude for each mention, along with an aggregate sentiment for the entity.
In this task, you use syntactic analysis, another of the Natural Language API's method, to dive deeper into the linguistic details of the text. analyzeSyntax extracts linguistic information, breaking up the given text into a series of sentences and tokens (generally, word boundaries), to provide further analysis on those tokens. For each word in the text, the API tells you the word's part of speech (noun, verb, adjective, etc.) and how it relates to other words in the sentence (Is it the root verb? A modifier?).
You can try this out with a simple sentence. This JSON request will be similar to the ones above, with the addition of a features key. This tells the API to perform syntax annotation.
Open the request.json file by typing the following command:
Replace the code in request.json with the following sentiment:
Press CTRL+O, ENTER to save the file, and press CTRL+X to exit nano.
Call the API's analyzeSyntax method by typing the following command:
The response should return an object like the one below for each token in the sentence:
This is how the response breaks down:
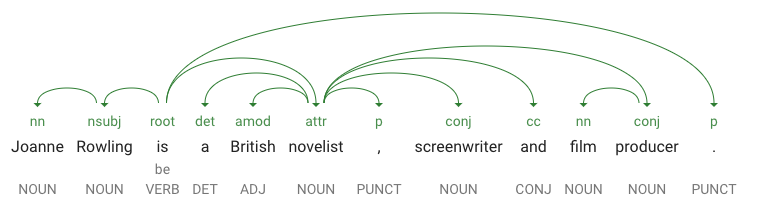
partOfSpeech tells you that "Joanne" is a noun.dependencyEdge includes data that you can use to create a dependency parse tree of the text. Essentially, this is a diagram showing how words in a sentence relate to each other. A dependency parse tree for the sentence above would look like this:headTokenIndex is the index of the token that has an arc pointing at "Joanne". Think of each token in the sentence as a word in an array.
headTokenIndex of 1 for "Joanne" refers to the word "Rowling", which it is connected to in the tree. The label NN (short for noun compound modifier) describes the word's role in the sentence. "Joanne" modifies "Rowling", the subject of the sentence.
lemma is the canonical form of the word. For example, the words run, runs, ran, and running all have a lemma of run. The lemma value is useful for tracking occurrences of a word in a large piece of text over time.
In this lab you performed text analysis using the Cloud Natural Language API to analyze sentiment, and perform syntax annotation. You created a Natural Language API request and called the API. You also ran sentiment analysis on sample phrases using the Natural Language API, before finally performing linguistic analysis on text to create dependency parse trees.
When you have completed your lab, click End Lab. Qwiklabs removes the resources you’ve used and cleans the account for you.
You will be given an opportunity to rate the lab experience. Select the applicable number of stars, type a comment, and then click Submit.
The number of stars indicates the following:
You can close the dialog box if you don't want to provide feedback.
For feedback, suggestions, or corrections, please use the Support tab.
Copyright 2022 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.



This content is not currently available
We will notify you via email when it becomes available

Great!
We will contact you via email if it becomes available

One lab at a time
Confirm to end all existing labs and start this one