

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create BigQuery Python notebook and connect to runtime
/ 10
Create the cloud resource connection and grant IAM role
/ 10
Review images, dataset, and grant IAM role to service account
/ 10
Create the dataset and customer reviews table in BigQuery
/ 30
Create the Gemini Pro model in BigQuery
/ 10
Prompt Gemini to analyze customer reviews for keywords and sentiment
/ 20
Respond to customer reviews
/ 10
このラボでは、BigQuery Machine Learning(ML)とリモートモデル(Gemini Pro)を使用してキーワードを抽出し、購入者レビューで顧客の感情を評価する方法について学習します。
BigQuery は、データから最大限の価値を引き出すのに役立つフルマネージドの AI 対応データ分析プラットフォームで、マルチエンジン、マルチフォーマット、マルチクラウドに対応しています。BigQuery の主な機能の一つである BigQuery Machine Learning(ML)では、SQL クエリまたは Colab Enterprise ノートブックを使用して ML モデルを作成および実行できます。
Gemini は、Google DeepMind が開発した、生成 AI モデルのファミリーであり、マルチモーダル ユースケース用に設計されています。Gemini API を使用すると、Gemini Pro、Gemini Pro Vision、Gemini Flash のモデルにアクセスできます。
このラボの最後では、BigQuery 内の Colab Enterprise ノートブックで Python ベースのカスタマー サービス アプリケーションをビルドし、Gemini Flash モデルを使用して音声ベースの購入者レビューに返信します。
このラボでは、次の方法について学びます。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

このタスクでは、BigQuery Python ノートブックを作成してランタイムに接続します。
Google Cloud コンソールのナビゲーション メニューで、[BigQuery] をクリックします。
表示されるポップアップ画面で [完了] をクリックします。
[ノートブック] をクリックします。
[リージョン] で [
[選択] をクリックします。
プロジェクトの下にあるエクスプローラの [ノートブック] セクションに、Python ノートブックが追加されたことを確認できます。
各セルにカーソルを合わせると表示されるゴミ箱アイコンをクリックして、ノートブック内のすべてのセルを削除します。
完了するとノートブックが空になり、次のステップに進めるようになります。
[接続] をクリックします。
Qwiklabs の受講者 ID をクリックします。
しばらくお待ちください。ランタイムに接続するには、最長で 3 分かかる場合があります。
完了すると、ブラウザ ウィンドウの下部に表示される接続ステータスが [接続済み] に更新されます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、BigQuery で Cloud リソース接続を作成し、Gemini Pro および Gemini Flash で作業できるようにします。また、ロールを通じて Cloud リソース接続のサービス アカウントに IAM の権限を付与し、Vertex AI サービスにアクセスできるようにします。
リソース接続は Python SDK と Google Cloud CLI を使用して作成しますが、まずは Python ライブラリをインポートし、project_id 変数と region 変数を設定する必要があります。
以下のコードを使用して新しいコードセルを作成します。
このコードによって Python ライブラリがインポートされます。
このセルを実行します。ライブラリが読み込まれ、使用できるようになります。
以下のコードを使用して新しいコードセルを作成します。
このセルを実行します。project_id と region の変数が設定されます。
以下のコードを使用して新しいコードセルを作成します。
このコードは、Google Cloud CLI コマンド bq mk --connection を使用してリソース接続を作成します。
このセルを実行します。これでリソース接続が作成されました。
[エクスプローラ] でプロジェクト ID の横にある [アクションを表示] ボタンをクリックします。
[コンテンツを更新] を選択します。
[外部接続] を開きます。外部接続として us.gemini_conn がリストされていることがわかります。
[us.gemini_conn] をクリックします。
[接続情報] ペインで、サービス アカウント ID をテキスト ファイルにコピーして、次のタスクで使用できるようにします。
コンソールのナビゲーション メニューで、[IAM と管理] をクリックします。
[アクセスを許可] をクリックします。
[新しいプリンシパル] フィールドに前の手順でコピーしたサービス アカウント ID を入力します。
[ロールを選択] フィールドに [Vertex AI] と入力し、[Vertex AI ユーザー] ロールを選択します。
[保存] をクリックします。
これにより、サービス アカウントに Vertex AI ユーザーロールが含まれるようになります。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、データセットと音声ファイルを確認し、Cloud リソース接続のサービス アカウントに IAM の権限を付与します。
このタスクでは、リソース接続のサービス アカウントに権限を付与しますが、その前にデータセットと画像ファイルを確認します。
Google Cloud コンソールのナビゲーション メニュー(
バケットに含まれている gsp1249 フォルダを開きます。次の 4 つの項目が表示されます。
audio フォルダには、分析するすべての音声ファイルが含まれています。このフォルダに自由にアクセスして、音声ファイルを確認できます。customer_reviews.csv ファイルは、テキストベースの購入者レビューが含まれるデータセットです。images フォルダには、このラボの後半で使用する画像ファイルが含まれています。このフォルダに自由にアクセスして、フォルダに含まれる画像ファイルを表示できます。notebook.ipynb は、このラボで作成するノートブックのコピーです。必要に応じて確認してください。BigQuery で作業を開始する前に、リソース接続のサービス アカウントに IAM の権限を付与すると、クエリの実行時にアクセス拒否エラーが発生しなくなります。
バケットのルートに戻ります。
[権限] をクリックします。
[アクセスを許可] をクリックします。
[新しいプリンシパル] フィールドに、前の手順でコピーしたサービス アカウント ID を入力します。
[ロールを選択] フィールドに「Storage オブジェクト」と入力し、[Storage オブジェクト管理者] ロールを選択します。
[保存] をクリックします。
これにより、サービス アカウントに Storage オブジェクト管理者ロールが含まれるようになります。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、プロジェクトのデータセットである購入者レビューのテーブルを作成します。
データセットでは次のプロパティを使用します。
| フィールド | 値 |
|---|---|
| データセット ID | gemini_demo |
| ロケーション タイプ | [マルチリージョン] を選択 |
| マルチリージョン | [米国] を選択 |
BigQuery の Python ノートブックに戻ります。
以下のコードを使用して新しいコードセルを作成します。
コードが %%bigquery で始まっていることに注目してください。これは、このステートメントの直後のコードが SQL コードになることを Python に指示するものです。
このセルを実行します。
SQL コードによって、BigQuery の [エクスプローラ] のプロジェクトの下に表示される [米国] リージョンにあるプロジェクトに gemini_demo データセットが作成されます。
SQL クエリを使用して、購入者レビューのテーブルを作成します。
以下のコードを使用して新しいコードセルを作成します。
このセルを実行します。
これにより、データセット内の各レビューの customer_review_id、customer_id、location_id、review_datetime、review_text、social_media_source、social_media_handle などの購入者レビューのサンプルデータを含む customer_reviews テーブルが作成されます。
[エクスプローラ] で customer_reviews テーブルをクリックし、スキーマと詳細を確認します。
以下のコードを使用して新しいコードセルを作成し、テーブルをクエリしてレコードを確認します。
このセルを実行します。
これにより、すべての列が含まれるテーブルでレコードが表示されるようになります。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
テーブルが作成されたので、テーブルの操作を開始できます。このタスクでは、BigQuery で Gemini Pro モデルを作成します。
Python ノートブックに戻ります。
以下のコードを使用して新しいコードセルを作成します。
このセルを実行します。
これにより、gemini_pro モデルが作成され、[モデル] セクションの gemini_demo データセットに追加されます。
[エクスプローラ] で gemini_pro モデルをクリックし、スキーマと詳細を確認します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、Gemini Pro モデルを使用して、各購入者レビューの感情(肯定的または否定的)を分析します。
以下のコードを使用して新しいコードセルを作成します。
このセルを実行します。
このクエリは、customer_reviews テーブルから購入者レビューを取得し、プロンプトを構築します。その後、gemini_pro モデルでそれらを使用して各レビューの感情を分類します。後でさらに詳しい分析に使用できるよう、新しいテーブル customer_reviews_analysis に結果が保存されます。
しばらくお待ちください。モデルによって購入者レビューのレコードが処理されるまでに約 30 秒かかります。
完了すると、customer_reviews_analysis テーブルが作成されます。
[エクスプローラ] で customer_reviews_analysis テーブルをクリックし、スキーマと詳細を確認します。
以下のコードを使用して新しいコードセルを作成します。
このセルを実行します。
これにより、ml_generate_text_llm_result 列(感情分析を含む)、購入者レビュー テキスト、お客様 ID、ロケーション ID が行に含まれるようになります。
レコードを見てみましょう。結果(肯定的および否定的)の一部が正しくフォーマットされず、ピリオドや余分なスペースなどの不要な文字が含まれる場合があります。これについては、以下のビューを使用してレコードをサニタイズできます。
以下のコードを使用して新しいコードセルを作成します。
このセルを実行します。
このコードによって、感情の結果、レビュー テキスト、お客様 ID、ロケーション ID が含まれる cleaned_data_view ビューが作成されます。次に、感情の結果(肯定的または否定的)を取得します。その際、すべての文字が小文字に変換され、余分なスペースやピリオドなどの不要な文字が削除されます。このビューにより、このラボの後のステップでさらに分析を行うことが容易になります。
以下のコードを使用して新しいコードセルを作成します。
このセルを実行します。
sentiment 列に肯定的なレビューと否定的なレビューのクリーンな値が含まれていることを確認できます。このビューは、後のステップでレポートの作成に使用できます。
Python と Matplotlib ライブラリを使用して、肯定的なレビューと否定的なレビューの件数についての棒グラフレポートを作成できます。
新しいコードセルを作成し、BigQuery クライアントを使用して cleaned_data_view でクエリを実行することで肯定的レビューと否定的レビューを取得し、感情別にグループ化して結果を DataFrame に保存します。
このセルを実行します。
肯定的なレビューと否定的なレビューの合計件数を含むテーブルが出力されます。
新しいセルを作成して、レポートの変数を定義します。
このセルを実行します。出力はありません。
新しいセルを作成してレポートを作成します。
このセルを実行します。
これにより、肯定的なレビューと否定的なレビューの件数についての棒グラフが作成されます。
または、以下のコードを使用して、否定的な感情と肯定的な感情の件数についてのシンプルな色分けされたレポートを作成することもできます。
| Negative | Positive |
|---|---|
| {count[0]} | {count[1]} |
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Data Beans は、画像と音声録音が使用される購入者レビューをテストしたいと考えています。ノートブックのこのセクションでは、Cloud Storage、BigQuery、Gemini Flash、Python を使用して、画像や音声ファイルとして Data Beans に提供された購入者レビューの感情分析を実行します。また、顧客にレビューへの感謝を伝えたり、レビューに基づくコーヒーハウスの対応を説明したりするなど、分析結果に応じたカスタマー サービスの返信を生成します。
これを大規模に実行した後、1 つの画像ファイルや音声ファイルを使用して実行することで、カスタマー サービス担当者向けの概念実証アプリケーションを作成する方法を習得します。これにより顧客のフィードバック プロセスを対象とした「人間参加型」戦略が実現し、カスタマー サービス担当者が顧客とコーヒーハウスの各店舗の両方に対してアクションを取れるようになります。
音声ファイルの感情分析を実行し、顧客に返信するための新しいセルを作成します。
このセルに関しては、いくつか重要なポイントがあります。
このセルを実行します。
これにより、5 つの音声ファイルすべてが分析され、分析の出力が JSON レスポンスとして提供されます。JSON レスポンスは適宜解析されて適切なアプリケーションに転送され、改善のためのアクションとともに顧客と店舗に送信されます。
このセクションでは、否定的なレビューの分析に基づいてカスタマー サービス アプリケーションを作成する方法について学習します。次のことを行います。
新しいセルを作成して次のコードを入力すると、否定的なレビューの音声ファイルから文字起こしを生成し、JSON オブジェクトおよび関連する変数を作成できます。
このセルに関しては、いくつか重要なポイントがあります。
セルを実行します。
出力は最小限で、処理された音声ファイルの URI と処理メッセージのみです。
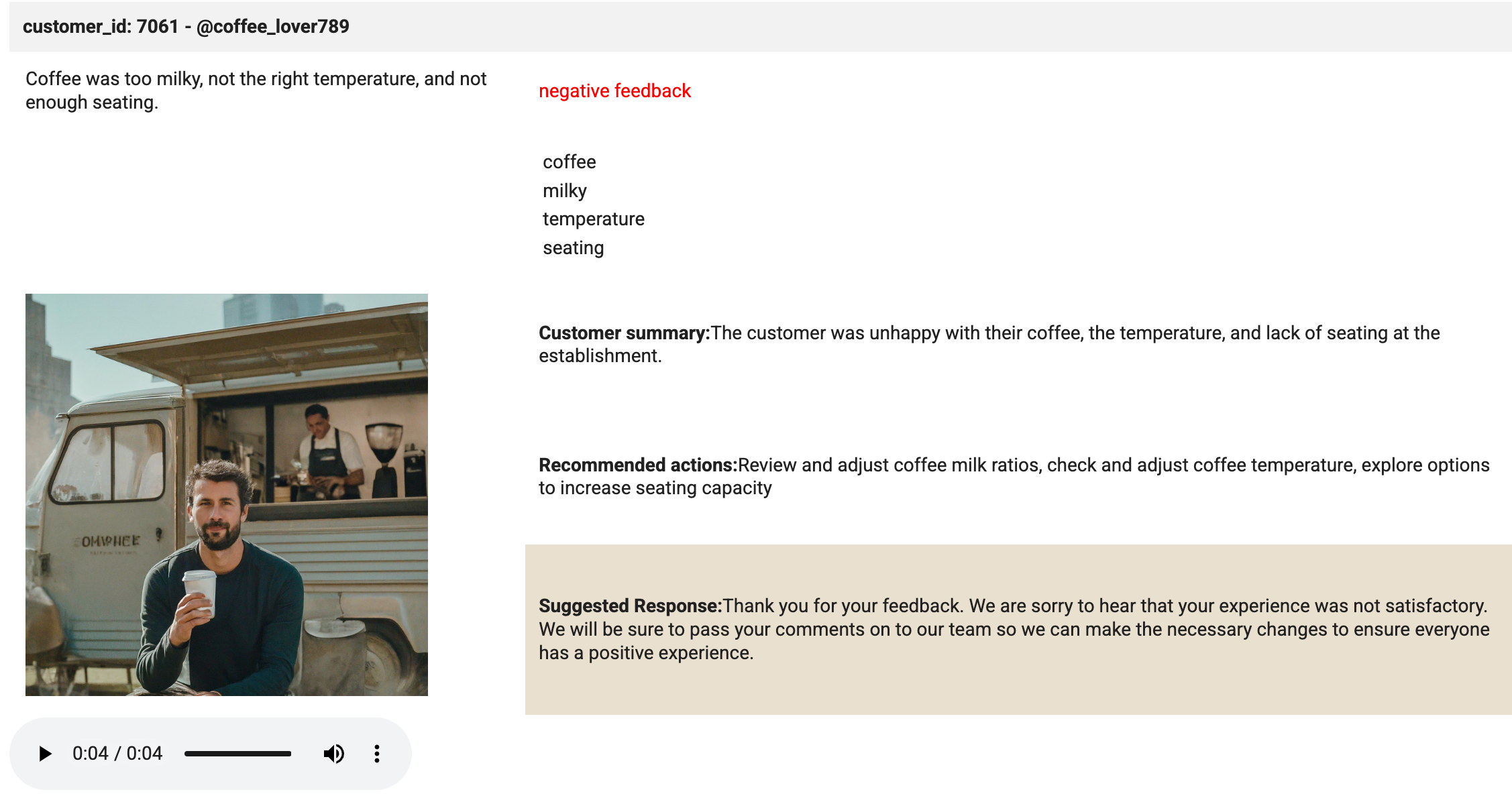
選択した値から HTML ベースのテーブルを作成し、否定的なレビューを含む音声ファイルをプレーヤーに読み込みます。
| customer_id: 7061 - @coffee_lover789 |
|---|
| {transcript} | {sentiment} feedback | ||||
|
|||||
| Customer summary:{summary} | |||||
| Recommended actions:{actions} | |||||
| Suggested Response:{response} |
このセルに関しては、いくつか重要なポイントがあります。
{summary} 出力が含まれる <td style="padding:10px;"> タグを見つけ、その前に新しいコード行を追加します。
この新しいコード行に <td rowspan="3" style="padding: 10px;"><img src="<authenticated url here>" alt="Customer Image" style="max-width: 300px;"></td> を貼り付けます。
image_7061.png ファイルの認証済み URL を見つけます。Cloud Storage に移動し、そこにある唯一のバケットである画像フォルダを選択して、画像をクリックします。
表示されたページで、画像の認証済み URL をコピーします。
BigQuery の Python ノートブックに戻ります。<authenticated url here> を、貼り付けたコード内の実際の認証済み URL に置き換えます。
セルを実行します。
ここでも出力は最小限で、各ステップが完了したことを示す処理メッセージのみです。
以下のコードを使用し、音声ファイルをダウンロードしてプレーヤーに読み込むための新しいセルを作成します。
このセルに関しては、いくつか重要なポイントがあります。
セルを実行します。
新しいセルを作成し、以下のコードを入力します。
セルを実行します。
このセルで魔法が起こります。display メソッドは、プレーヤーに読み込まれた音声ファイルと HTML を表示するために使用されます。セルの出力を確認します(下の画像のようになるはずです)。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
BigQuery で Cloud リソース接続を正常に作成できました。また、データセット、テーブル、モデルを作成し、購入者レビューの感情とキーワードを分析するよう、Gemini にプロンプトで指示しました。最後に、Gemini を使用して音声ベースの購入者レビューを分析し、カスタマー サービス アプリケーション内で購入者レビューに返信するための要約とキーワードを生成しました。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2025 年 4 月 10 日
ラボの最終テスト日: 2025 年 4 月 10 日
Copyright 2025 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください