Puntos de control
Combine the data and export Parquet files
/ 35
Query data in BigQuery
/ 30
Query data in Dataproc and Spark
/ 35
Compara los análisis de datos con BigQuery y Dataproc
 IMPORTANTE:
IMPORTANTE: Asegúrate de completar este lab práctico únicamente en una computadora de escritorio o laptop.
Asegúrate de completar este lab práctico únicamente en una computadora de escritorio o laptop. Se permiten solo 5 intentos por lab.
Se permiten solo 5 intentos por lab. A modo de recordatorio, es habitual no responder de forma correcta a todas las preguntas en el primer intento o incluso tener que volver a realizar una tarea; esto forma parte del proceso de aprendizaje.
A modo de recordatorio, es habitual no responder de forma correcta a todas las preguntas en el primer intento o incluso tener que volver a realizar una tarea; esto forma parte del proceso de aprendizaje. Una vez comenzado el lab, no se puede detener el cronómetro. Después de 1 hora y 30 minutos, el lab terminará y tendrás que volver a empezar.
Una vez comenzado el lab, no se puede detener el cronómetro. Después de 1 hora y 30 minutos, el lab terminará y tendrás que volver a empezar. Para obtener más información, consulta la lectura Sugerencias técnicas para el lab.
Para obtener más información, consulta la lectura Sugerencias técnicas para el lab.
Descripción general de la actividad
El análisis de datos en la nube es un campo de rápida evolución y los analistas deben aprender sobre nuevas plataformas y tecnologías para ser eficaces en su trabajo. Una buena forma de hacerlo es comparar distintas plataformas, como BigQuery y Dataproc.
BigQuery y Dataproc son dos plataformas de procesamiento de datos en la nube, pero se usan distintos motores, dialectos de SQL y entornos de desarrollo para analizar datos.
BigQuery es un almacén de datos útil para realizar consultas interactivas en conjuntos de datos grandes. Es fácil de usar y admite un amplio rango de tareas de análisis de datos.
Dataproc es un servicio administrado de Hadoop y Spark que es útil en trabajos de procesamiento por lotes en conjuntos de datos grandes. Es más flexible que BigQuery, pero puede ser más difícil de configurar y usar.
Tanto BigQuery como Dataproc están integrados a otros servicios de Google Cloud, lo que hace que mover datos entre ellos y descubrir fuentes de data lakes sea sencillo.
En este lab, unirás datos de dos archivos CSV en un archivo Parquet. Luego, usarás los datos combinados para comparar los análisis realizados por BigQuery con los realizados por Dataproc y Spark en los mismos datos.
Situación
El comercio electrónico TheLook está haciendo una prueba piloto de un programa que puede aceptar devoluciones de pedidos en línea en cualquiera de sus tiendas físicas. Este programa facilita el proceso de devolución de artículos para los clientes y se espera que esto derive en un aumento en las ventas y la satisfacción del cliente.
Para hacer un seguimiento de este programa, Marta, la jefa de productos, te pidió que prepares un informe en el que se combinen las direcciones y los datos de devoluciones de cada tienda. Este informe se usará para hacer un seguimiento de las devoluciones por ubicación y región; la información también será útil para determinar el éxito del programa piloto en distintos mercados.
Para empezar, revisas los datos recopilados de cada ubicación hasta entonces. Pero, de inmediato, te das cuenta de que la cantidad de datos es inmensa. Contactas a Arturo, el arquitecto de datos, para que te ayude a trabajar con el gran volumen de datos que se deben recopilar, procesar y analizar.
Arturo te sugiere que uses Dataproc para combinar los dos archivos CSV con los que estás trabajando en un solo archivo Parquet. Parquet es un formato de datos en columnas que está optimizado para realizar búsquedas analíticas rápidas. Arturo también dice que, como el comercio electrónico TheLook acaba de adquirir una empresa que hace estadísticas con Spark, esta es una gran oportunidad para aprender más sobre Dataproc y Spark.
La propuesta es que uses los datos combinados del informe de Marta para comparar dos formas de ejecutar estadísticas: una basada en BigQuery, un producto con el que estás familiarizado, y otra basada en Dataproc y Spark. Esta es una gran forma de obtener más información acerca de Dataproc y Spark, además de comparar ambas plataformas y descubrir cuál de las dos se ajusta mejor a las necesidades del programa piloto.
Agradeces a Arturo por su ayuda. Pero antes de poder empezar a comparar BigQuery con Dataproc y Spark, debes pensar en cómo recopilarás y procesarás los datos que usarás en la comparación.
Diseñas un diagrama para planear mejor cómo combinarás los dos archivos CSV; quieres unir ambos archivos con Dataproc Spark SQL y renderizar un archivo combinado de devoluciones en formato Parquet.
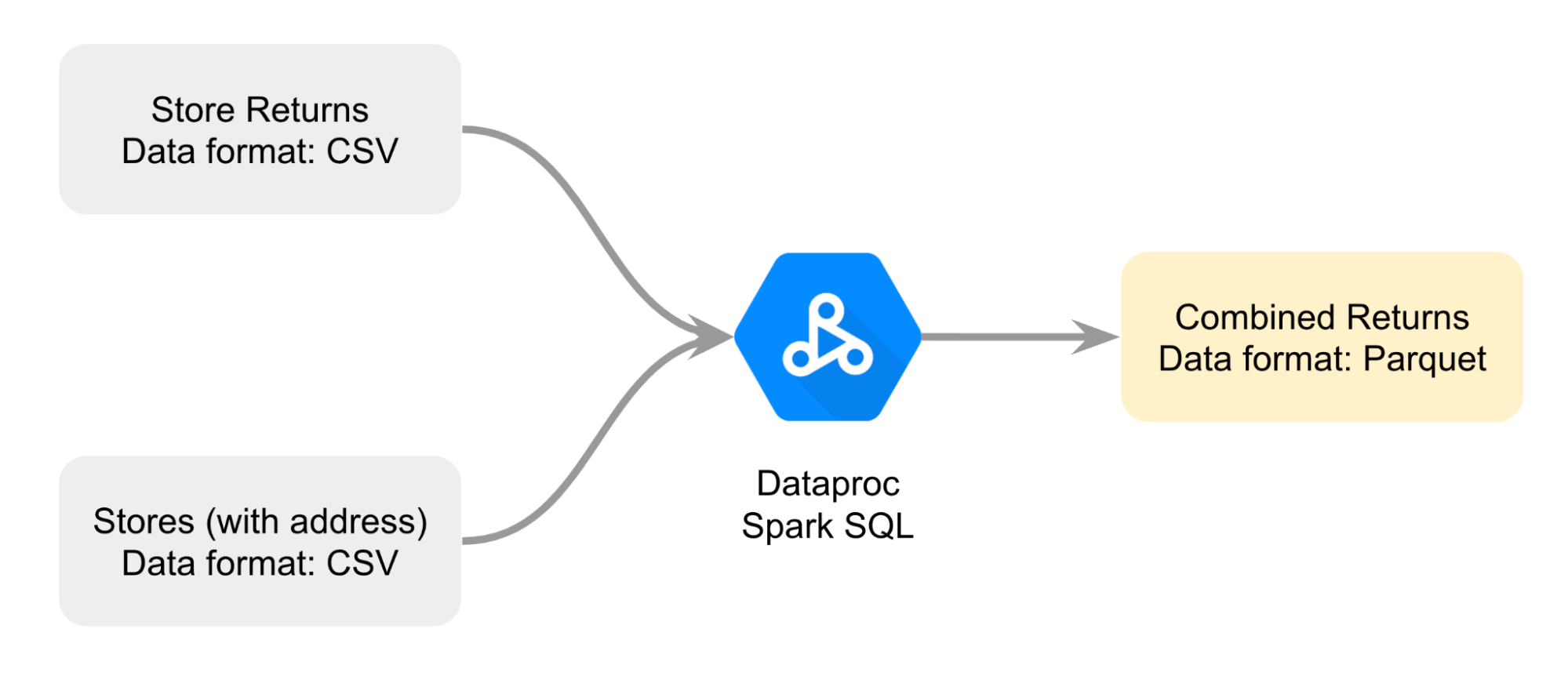
Estos son los datos que usarás como base para tu comparación.
Realizarás la tarea así: primero, abrirás un notebook de Jupyter en un clúster de Dataproc. Luego, seguirás las instrucciones en el notebook para unir los archivos CSV en un archivo Parquet. Después, cargarás los datos del archivo Parquet almacenados en un bucket de Cloud Storage a una tabla estándar de BigQuery para analizarlos. Por último, harás una referencia del archivo Parquet en un notebook de Jupyter en un clúster de Dataproc para comparar el análisis de datos de BigQuery con el realizado por Dataproc y Spark.
Configuración
Antes de hacer clic en Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
En este lab práctico, puedes realizar las actividades por tu cuenta en un entorno de nube real, en lugar de una simulación o un entorno de demostración. Para ello, se te proporcionan credenciales temporales nuevas que usarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab: Recuerda que, una vez que comienzas un lab, no puedes pausarlo.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haz clic en el botón Comenzar lab. A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- Tiempo restante
- El botón Abrir la consola de Google
- Las credenciales temporales que debes usar para el lab
- Otra información para completar el lab, si es necesaria
Nota: Si debes pagar por el lab, se abrirá una ventana emergente para que selecciones tu forma de pago. -
Haz clic en Abrir la consola de Google (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito) si ejecutas el navegador Chrome. La página Acceder se abre en una pestaña del navegador nueva.
Sugerencia: Puedes organizar las pestañas de manera independiente (una ventana al lado de la otra) para alternar fácilmente entre ellas.
Nota: Si aparece el diálogo Elige una cuenta, haz clic en Usar otra cuenta. -
Si es necesario, copia el nombre de usuario de Google Cloud a continuación, y pégalo en el diálogo Ingresar. Haz clic en Siguiente.
También puedes encontrar el nombre de usuario de Google Cloud en el panel Detalles del lab.
- Copia la contraseña de Google Cloud a continuación y pégala en el diálogo te damos la bienvenida. Haz clic en Siguiente.
También puedes encontrar la contraseña de Google Cloud en el panel Detalles del lab.
- Haz clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para las pruebas gratuitas.
Después de un momento, se abrirá la consola de Cloud en esta pestaña.

Tarea 1: Abre JupyterLab en un clúster de Dataproc
JupyterLab se puede usar para crear, abrir y editar notebooks de Jupyter en un clúster de Dataproc. Esto te permite aprovechar los recursos del clúster, como su alto rendimiento y escalabilidad, y te permite ejecutar tus notebooks más rápido y en conjuntos de datos más extensos. También puedes usar JupyterLab para colaborar con otros en tus proyectos.
En esta tarea, abrirás un clúster de Dataproc existente y navegarás a JupyterLab para ubicar los notebooks de Jupyter que usarás para completar el resto de las tareas de este lab.
- En la barra del título de la consola de Google Cloud, escribe “Dataproc” en el campo Búsqueda y presiona INTRO.
- En los resultados de la búsqueda, selecciona Dataproc.
- En la página Clústeres, haz clic en el nombre del clúster con el nombre mycluster.
- En la página con pestañas de detalles del Clúster, selecciona la pestaña Interfaces Web.
- En la sección Puerta de enlace del componente, haz clic en el vínculo JupyterLab.
El entorno de JupyterLab se abre en una pestaña nueva del navegador.
- Ubica el archivo
C2M4-1 Combine and Export.ipynben la lista de la barra lateral izquierda.
Tarea 2: Combina los datos y exporta los archivos Parquet
Marta necesita información sobre cada devolución y la dirección física donde esta se hizo para identificar las ubicaciones y los mercados. Pero esta información se encuentra en dos archivos CSV separados.
Los datos de devoluciones de la tienda se exportaron en un formato CSV y se copiaron en un bucket de Cloud Storage. Estos datos incluyen order_id, rma_id, return_status, status_date, product_ied, quantity_returned y store_id.
En las 10 primeras líneas del archivo de devoluciones de la tienda, se incluye lo siguiente:
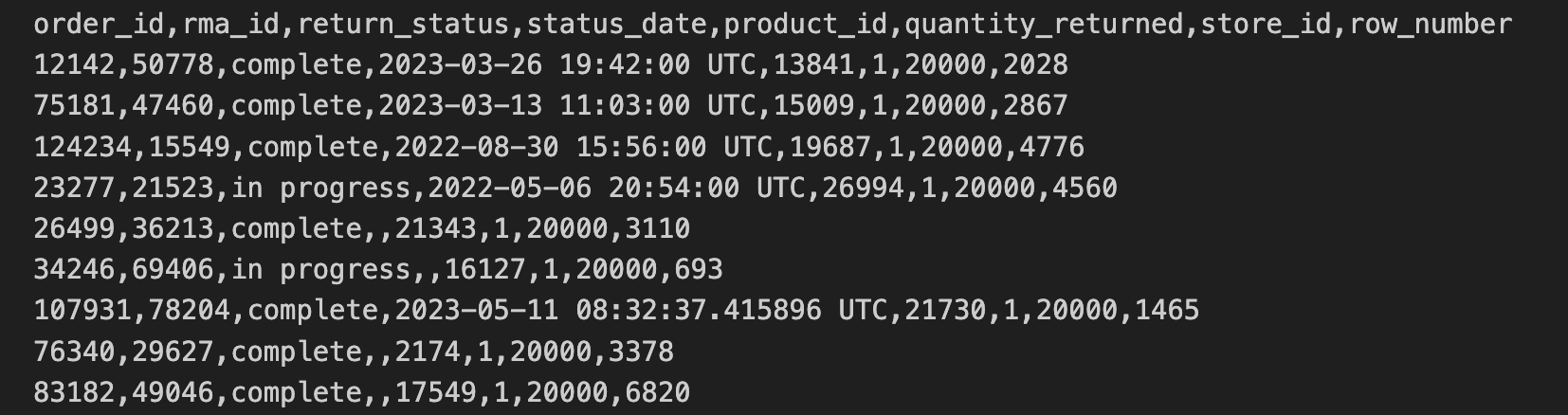
Los datos de la dirección de la tienda se incluyen en un archivo CSV separado. Estos datos incluyen el store_id y la street_address.
En las 10 primeras líneas del archivo de dirección de la tienda, se incluye:
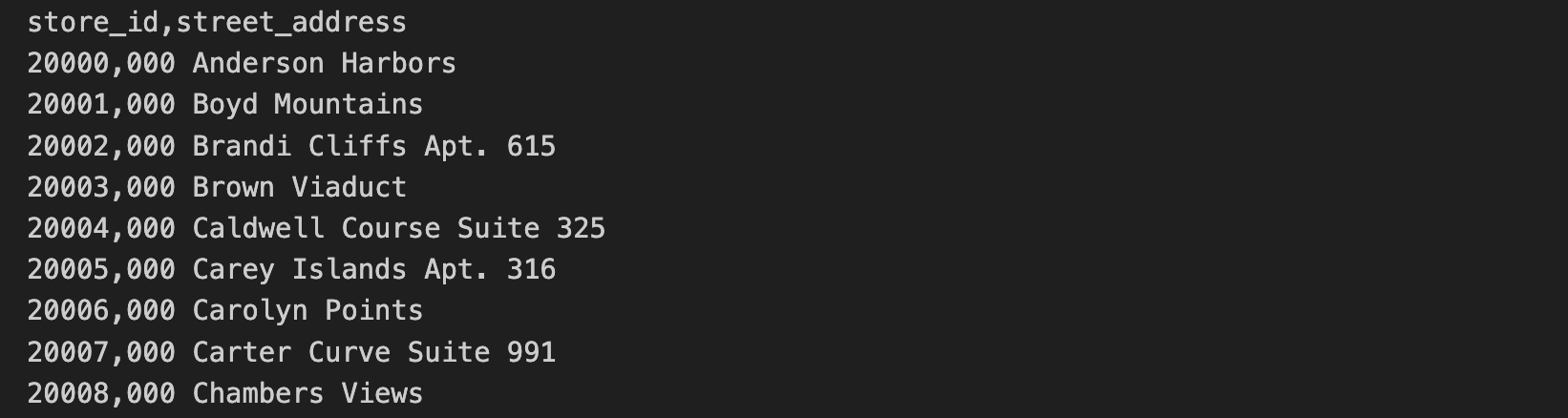
En esta tarea, ejecutarás las consultas en SQL y los comandos de Python contenidos en el archivo C2M4-1 Combine and Export.ipynb para unir los dos archivos CSV. Los archivos combinados se almacenarán como un archivo Parquet.
- En la barra lateral izquierda, haz doble clic en el archivo
C2M4-1 Combine and Export.ipynbpara abrirlo en el entorno de JupyterLab.
A continuación, sigue las instrucciones en el notebook y ejecuta el código en cada una de las celdas.
- Haz clic en cada celda del notebook y, luego, en el ícono Run the selected cells and advance (Ejecutar las celdas seleccionadas y continuar) (
) para ejecutar cada celda. También puedes presionar MAYÚSCULAS+INTRO para ejecutar el código. Las celdas que dependen del resultado de una celda anterior DEBEN ejecutarse en orden. Si cometes un error y ejecutas una celda en otro orden, haz clic en el botón de actualizar (
) en la barra de tareas del notebook para reiniciar el kernel.
- Explora los resultados de cada celda en el notebook. Los dos archivos CSV ahora están unidos y el archivo Parquet, que usarás en la próxima tarea, se creó automáticamente.
Una sesión de Spark en Dataproc es una forma de conectarse a un clúster de Dataproc y ejecutar aplicaciones de Spark. Es la manera principal de iniciar aplicaciones de Spark y crear DataFrames. Los DataFrames son tablas que Spark puede procesar y en las que puede ejecutar consultas. Con Spark, también puedes leer y escribir datos en diferentes sistemas de almacenamiento, como Google Cloud Storage o BigQuery.
En este notebook, creaste una sesión de Spark y cargaste los datos de devoluciones de la tienda desde un archivo CSV a un DataFrame, una tabla que se usa en Spark. Luego, cargaste las direcciones de las tiendas de un segundo archivo CSV y uniste ambos DataFrames para exportar una única tabla como un archivo Parquet. Por último, usaste una consulta para modificar el nombre de una de las columnas.
Sugerencia: Mantén el notebook con los resultados abierto mientras respondes las siguientes preguntas.
Haz clic en Revisar mi progreso para verificar que completaste esta tarea de manera correcta.
Tarea 3: Consulta datos en BigQuery
Ahora que el archivo Parquet combinado está creado y almacenado en un bucket de Cloud Storage, estás en buen camino para comparar las dos maneras de ejecutar análisis: una basada en BigQuery y otra basada en Dataproc y Spark.
Empieza por BigQuery, un almacén de datos que usa el motor de BigQuery para ejecutar consultas y analizar datos.
En la tarea anterior, creaste un archivo Parquet y lo almacenaste en un bucket de Cloud Storage. Tienes dos opciones para acceder a estos datos desde BigQuery: una tabla externa o una tabla estándar. Una tabla externa se refiere a los datos almacenados fuera de BigQuery, por ejemplo, en Google Cloud Storage. Una tabla estándar almacena una copia de los datos directamente en BigQuery.
Arturo te dijo que las tablas estándar suelen ser más eficientes cuando se trabaja con macrodatos, ya que estos se pueden consultar y procesar de manera rápida. Por esto, decides que una tabla estándar es la mejor opción para esta tarea.
En esta tarea, cargarás el archivo Parquet en una tabla estándar en BigQuery y ejecutarás una consulta mediante GoogleSQL, el dialecto SQL que se usa en el entorno de BigQuery. A continuación, responderás las preguntas para asegurarte de que tienes la información necesaria para comparar BigQuery con Dataproc y Spark en la próxima tarea.
-
Regresa a la pestaña del navegador de la consola de Google Cloud (donde todavía deberías tener la página de Dataproc abierta), sin cerrar la pestaña del navegador de JupyterLab.
-
En la consola de Google Cloud Menú de navegación (
), haz clic en BigQuery > BigQuery Studio. BigQuery Studio es la manera principal de escribir y ejecutar consultas en BigQuery.
-
En el Editor de consultas, haz clic en el ícono Redactar nueva consulta (+) para abrir una nueva pestaña Sin título.
-
Copia la siguiente búsqueda en la pestaña Sin título:
Esta consulta importa el archivo Parquet a BigQuery.
- Haz clic en Run.
Un URI (Identificador de Recursos Uniforme) es la ruta a un archivo en un bucket de Cloud Storage. Un conjunto de URI puede establecerse como entrada para el comando LOAD DATA si encierras los URI deseados entre corchetes []. Esto indica que el valor es un array de URI.
El URI siempre empieza con gs://, lo que indica que es un recurso en Cloud Storage. El URI del ejemplo anterior filtra los archivos con una extensión .parquet, ya que termina con *.parquet. El símbolo * es un comodín, es decir que puede ser cualquier cadena.
Esta consulta devuelve todos los archivos en la ruta gs://
- Copia la siguiente consulta en el Editor de consultas:
Esta consulta devuelve el número de filas en la tabla “thelook_gcda.product_returns_to_store”.
- Haz clic en Run.
De forma predeterminada, una consulta ejecutada en BigQuery Studio usa el dialecto GoogleSQL. GoogleSQL es un superconjunto del dialecto SQL estándar, es decir, incluye todas las consultas en SQL estándar y otras extensiones que facilitan el trabajo con grandes cantidades de datos y tipos de datos complejos en BigQuery.
- Copia la siguiente consulta en el Editor de consultas:
Esta consulta muestra la cantidad de devoluciones recibidas por mes y por estado.
- Haz clic en Run.
Haz clic en Revisar mi progreso para comprobar que completaste esta tarea de manera correcta.
Tarea 4. Consulta datos en Dataproc y Spark
Ahora que completaste tu análisis en BigQuery, tienes todo listo para explorar un análisis basado en Dataproc y Spark.
Spark es el principal motor de procesamiento de datos para analizar datos con Dataproc. Dataproc administra el clúster de Spark automáticamente y está preinstalado con Spark, lo que lo convierte en una opción conveniente y útil para el análisis de datos.
Además, Spark usa su propio dialecto de SQL, Spark SQL. Al igual que GoogleSQL, Spark SQL es un dialecto de SQL. Spark SQL es un dialecto de SQL distribuido, lo que significa que puede consultar y analizar datos distribuidos a través de distintas máquinas en un clúster de Spark.
Para ejecutar consultas en Spark SQL con Dataproc y Spark, deberás usar un notebook de Jupyter. Este entorno interactivo te permite escribir código y mostrar sus resultados de manera sencilla.
En esta tarea, ejecutarás consultas en Spark SQL en el archivo Parquet al que se hace referencia en el bucket de Cloud Storage. Luego, responderás preguntas que te ayudarán a completar la comparación de las dos formas de ejecutar análisis: una basada en BigQuery y una basada en Dataproc y Spark.
-
Regresa a la pestaña de JupyterLabSTRONG en tu navegador.
-
Haz doble clic en el archivo
C2M4-2 Query Store Data with Spark SQL.ipynbpara abrirlo en el entorno de JupyterLab.
Sigue las instrucciones en el notebook y ejecuta el código en cada una de las celdas.
-
Haz clic en cada celda del notebook y, luego, en Run o presiona MAYÚSCULAS+INTRO para ejecutar el código.
-
Explora los resultados de las consultas en Spark SQL en el notebook.
En este notebook, creaste una sesión de Spark. Luego, hiciste referencia a los datos en los archivos Parquet en Cloud Storage mediante el notebook The iPython y completaste un DataFrame. Después, creaste una vista para que el DataFrame pueda usarse con Spark SQL. Luego, ejecutaste una consulta en Spark SQL que devolvió las tres primeras filas del DataFrame. Por último, ejecutaste la misma consulta que ejecutaste en BigQuery en el paso anterior.
Haz clic en Revisar mi progreso para comprobar que completaste esta tarea de manera correcta.
Tarea 5. Detén el clúster
Como práctica recomendada, antes de salir de un entorno asegúrate de detener el clúster.
- Regresa a la pestaña BigQuery en tu navegador.
- En la barra del título de la consola de Google Cloud, escribe Dataproc en el campo Búsqueda.
- Selecciona Dataproc entre los resultados de la búsqueda. Se abre la página Clústeres.
- En la lista de clústeres, selecciona la casilla de verificación al lado de mycluster.
- En la barra Acción, haz clic en Detener.
Resumen
Revisa la siguiente tabla que resume las diferencias entre el análisis de datos con BigQuery y el análisis de datos con Dataproc y Spark que se abarcaron en este lab.
| Tarea 3 | Tarea 4 | |
|---|---|---|
| Producto central | BigQuery | Dataproc |
| Motor de procesamiento de datos | BigQuery | Spark |
| Ubicación de los datos | Tabla estándar de BigQuery | Archivo Parquet en GCS |
| Dialecto de SQL | GoogleSQL | Spark SQL |
| Entorno de desarrollo | BigQuery Studio | Notebooks de Jupyter |
Conclusión
Muy bien.
Recopilaste y procesaste con éxito los datos que Marta necesitaba en su informe y usaste los datos combinados para comparar dos formas de ejecutar análisis: una basada en BigQuery, un producto que ya conoces, y una basada en Dataproc y Spark.
Primero abriste un notebook de Jupyter en un clúster de Dataproc existente.
Luego, seguiste las instrucciones en el notebook para unir dos archivos CSV con los datos de devoluciones y direcciones para crear un archivo Parquet combinado y almacenarlo en un bucket de Cloud Storage.
Seguiste los consejos de Arturo y usaste el archivo Parquet combinado para comparar los análisis de datos de BigQuery y Dataproc y Spark para saber más sobre sus motores de procesamiento de datos, sus dialectos de SQL, la ubicación de sus datos y sus entornos de desarrollo.
Estás en un buen camino para comprender cómo usar Dataproc y Spark para trabajar con conjuntos de datos grandes.
Finaliza el lab
Antes de que finalices el lab, asegúrate de estar satisfecho de haber completado todas las tareas. Cuando estés conforme, haz clic en Finalizar Lab y, luego, haz clic en Enviar.
Finalizar el lab te quitará el acceso al entorno del lab y no podrás volver a acceder al trabajo que completaste.