Gemini umfasst eine Reihe generativer KI-Modelle von Google, die auf multimodale Anwendungsfälle ausgelegt sind. Die Gemini API bietet verschiedene Modelle für unterschiedliche Anwendungsfälle. Gemini Pro ist ein leistungsstarkes Modell, das Antworten mit höchstmöglicher Accuracy liefert. Gemini Flash ist ein multimodales Modell mit niedriger Latenz und hoher Leistung. Das Modell Gemini Flash-Lite ist äußerst kosteneffizient und bietet eine niedrige Latenz. Weitere Informationen zu diesen Modellvarianten finden Sie in der Dokumentation.
In Google Cloud bietet die Vertex AI Gemini API eine einheitliche Benutzeroberfläche für die Interaktion mit Gemini-Modellen. Die API unterstützt multimodale Prompts (Audio, Bilder, Videos, Texte) als Eingabe und generiert Texte, Bilder und Audio als Ausgabe. Mit dem Imagen-Modell lassen sich Bilder aus Text erzeugen.
Vertex AI ist eine Plattform für maschinelles Lernen (ML), mit der Sie ML-Modelle und KI-Anwendungen trainieren und bereitstellen können. Außerdem können Sie Large Language Models (LLMs) für Ihre KI-basierten Anwendungen anpassen. Vertex AI ermöglicht die Anpassung von Gemini bei vollständiger Datenkontrolle und bietet Google Cloud-Funktionen für Sicherheit, Datenschutz, Data Governance und Compliance in Unternehmen. Mehr über Vertex AI finden Sie im Abschnitt Weitere Informationen am Ende des Labs.
In diesem Lab rufen Sie die Vertex AI Gemini API mit dem Vertex AI SDK for Python auf.
Lernziele
Aufgaben in diesem Lab:
Python-Anwendung mit dem Streamlit-Framework entwickeln
Vertex AI SDK for Python installieren
Code entwickeln, um über die Vertex AI Gemini API mit dem Gemini-Modell (gemini-2.0-flash) zu interagieren
Anwendung containerisieren, in Cloud Run bereitstellen und testen
Einrichtung
Für jedes Lab werden Ihnen ein neues Google Cloud-Projekt und die entsprechenden Ressourcen für eine bestimmte Zeit kostenlos zur Verfügung gestellt.
Melden Sie sich über ein Inkognitofenster in Qwiklabs an.
Beachten Sie die Zugriffszeit (z. B. 1:15:00). Das Lab muss in dieser Zeit abgeschlossen werden.
Es gibt keine Pausenfunktion. Sie können bei Bedarf neu starten, müssen dann aber von vorn beginnen.
Wenn Sie bereit sind, klicken Sie auf Lab starten.
Notieren Sie sich Ihre Anmeldedaten (Nutzername und Passwort). Mit diesen Daten melden Sie sich in der Google Cloud Console an.
Klicken Sie auf Google Console öffnen.
Klicken Sie auf Anderes Konto verwenden. Kopieren Sie den Nutzernamen und das Passwort für dieses Lab und fügen Sie beides in die entsprechenden Felder ein.
Wenn Sie andere Anmeldedaten verwenden, tritt ein Fehler auf oder es fallen Kosten an.
Akzeptieren Sie die Nutzungsbedingungen und überspringen Sie die Seite zur Wiederherstellung der Ressourcen.
Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Cloud Shell bietet Ihnen Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen. gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
Klicken Sie in der Google Cloud Console im Navigationsbereich auf Cloud Shell aktivieren ().
Klicken Sie auf Weiter.
Die Bereitstellung und Verbindung mit der Umgebung dauert einen kleinen Moment. Wenn Sie verbunden sind, sind Sie auch authentifiziert und das Projekt ist auf Ihre PROJECT_ID eingestellt. Beispiel:
Klicken Sie auf Fortschritt prüfen.
Relevante APIs aktivieren.
Aufgabe 2: Anwendungsumgebung einrichten
In dieser Aufgabe richten Sie eine virtuelle Python-Umgebung ein und installieren die Anwendungsabhängigkeiten.
Prüfen, ob Cloud Shell autorisiert ist
Führen Sie in Cloud Shell den folgenden Befehl aus, um zu prüfen, ob Cloud Shell autorisiert ist:
gcloud auth list
Wenn Sie aufgefordert werden, Cloud Shell zu autorisieren, klicken Sie auf Autorisieren.
Anwendungsverzeichnis erstellen
Führen Sie den folgenden Befehl aus, um das Anwendungsverzeichnis zu erstellen:
mkdir ~/gemini-app
Wechseln Sie zum Verzeichnis ~/gemini-app:
cd ~/gemini-app
Die Anwendungsdateien werden im Verzeichnis ~/gemini-app erstellt. Dieses Verzeichnis enthält die Quelldateien der Python-Anwendung, die Abhängigkeiten und eine Docker-Datei, die wir später in diesem Lab verwenden werden.
Virtuelle Python-Umgebung einrichten
Sie erstellen eine virtuelle Umgebung in der vorhandenen Python-Installation, damit alle in dieser Umgebung installierten Pakete von den Paketen in der Basisumgebung getrennt sind. Wenn Installationstools wie pip in einer virtuellen Umgebung verwendet werden, werden Python-Pakete dort installiert.
Führen Sie zum Erstellen der virtuellen Python-Umgebung im Ordner gemini-app den folgenden Befehl aus:
python3 -m venv gemini-streamlit
Mit dem Modul venv wird eine einfache virtuelle Umgebung mit einem eigenen unabhängigen Satz von Python-Paketen erstellt.
Aktivieren Sie die virtuelle Python-Umgebung:
source gemini-streamlit/bin/activate
Anwendungsabhängigkeiten installieren
Eine Datei mit Python-Anforderungen ist eine einfache Textdatei, in der die für Ihr Projekt erforderlichen Abhängigkeiten aufgeführt sind. Wir brauchen für den Anfang drei Module in unserer Anforderungsdatei.
Unsere Anwendung wird mit Streamlit geschrieben, einer Open-Source-Python-Bibliothek, mit der Webanwendungen für maschinelles Lernen und Data Science entwickelt werden. Die Anwendung verwendet die Vertex AI SDK for Python-Bibliothek, um mit der Gemini API und den Modellen zu interagieren. Mit Cloud Logging werden Informationen aus unserer Anwendung erfasst.
Führen Sie den folgenden Befehl aus, um die Datei requirements zu erstellen:
pip ist das Paketinstallationsprogramm für Python.
Warten Sie, bis alle Pakete installiert sind, bevor Sie mit der nächsten Aufgabe fortfahren.
Aufgabe 3: Anwendung entwickeln
Der Quellcode der Anwendung wird in mehreren .py-Quelldateien geschrieben. Beginnen wir mit dem Haupteinstiegspunkt in app.py.
Haupteinstiegspunkt der Anwendung schreiben
Führen Sie den folgenden Befehl aus, um den Code für den Einstiegspunkt app.py zu erstellen:
cat > ~/gemini-app/app.py <<EOF
import os
import streamlit as st
from app_tab1 import render_story_tab
from vertexai.preview.generative_models import GenerativeModel
import vertexai
import logging
from google.cloud import logging as cloud_logging
# configure logging
logging.basicConfig(level=logging.INFO)
# attach a Cloud Logging handler to the root logger
log_client = cloud_logging.Client()
log_client.setup_logging()
PROJECT_ID = os.environ.get('PROJECT_ID') # Your Qwiklabs Google Cloud Project ID
LOCATION = os.environ.get('REGION') # Your Qwiklabs Google Cloud Project Region
vertexai.init(project=PROJECT_ID, location=LOCATION)
@st.cache_resource
def load_models():
text_model = GenerativeModel("gemini-2.0-flash")
multimodal_model = GenerativeModel("gemini-2.0-flash")
return text_model, multimodal_model
st.header("Vertex AI Gemini API", divider="rainbow")
text_model, multimodal_model = load_models()
tab1, tab2, tab3, tab4 = st.tabs(["Story", "Marketing Campaign", "Video Playground", "Image Playground"])
with tab1:
render_story_tab(text_model)
EOF
Sehen Sie sich den Inhalt der Datei app.py an:
cat ~/gemini-app/app.py
In der Anwendung werden mit streamlit mehrere Tabs in der Benutzeroberfläche erstellt. In dieser ersten Version der Anwendung erstellen wir den Tab Story mit Funktionen zum Erstellen einer Geschichte. In den nachfolgenden Aufgaben im Lab erstellen wir dann nach und nach die anderen Tabs.
Die Anwendung initialisiert zuerst das Vertex AI SDK und übergibt die Werte der Umgebungsvariablen PROJECT_ID und REGION.
Anschließend wird das Modell gemini-2.0-flash mit der Klasse GenerativeModel geladen, die ein Gemini-Modell darstellt. Diese Klasse bietet Methoden zum Generieren von Inhalten aus Texten, Bildern und Videos.
In der Benutzeroberfläche der Anwendung werden vier Tabs mit den Bezeichnungen Story, Marketing Campaign, Image Playground und Video Playground erstellt.
Der Code ruft dann die Funktion render_tab1() auf, um die Benutzeroberfläche für den Tab Story in der Anwendung zu erstellen.
Tab 1 „Story“ entwickeln
Führen Sie den folgenden Befehl aus, um Code zu schreiben, der den Tab Story in der Benutzeroberfläche der Anwendung rendert:
cat > ~/gemini-app/app_tab1.py <<EOF
import streamlit as st
from vertexai.preview.generative_models import GenerativeModel
from response_utils import *
import logging
# create the model prompt based on user input.
def generate_prompt():
# Story character input
character_name = st.text_input("Enter character name: \n\n",key="character_name",value="Mittens")
character_type = st.text_input("What type of character is it? \n\n",key="character_type",value="Cat")
character_persona = st.text_input("What personality does the character have? \n\n",
key="character_persona",value="Mitten is a very friendly cat.")
character_location = st.text_input("Where does the character live? \n\n",key="character_location",value="Andromeda Galaxy")
# Story length and premise
length_of_story = st.radio("Select the length of the story: \n\n",["Short","Long"],key="length_of_story",horizontal=True)
story_premise = st.multiselect("What is the story premise? (can select multiple) \n\n",["Love","Adventure","Mystery","Horror","Comedy","Sci-Fi","Fantasy","Thriller"],key="story_premise",default=["Love","Adventure"])
creative_control = st.radio("Select the creativity level: \n\n",["Low","High"],key="creative_control",horizontal=True)
if creative_control == "Low":
temperature = 0.30
else:
temperature = 0.95
prompt = f"""Write a {length_of_story} story based on the following premise: \n
character_name: {character_name} \n
character_type: {character_type} \n
character_persona: {character_persona} \n
character_location: {character_location} \n
story_premise: {",".join(story_premise)} \n
If the story is "short", then make sure to have 5 chapters or else if it is "long" then 10 chapters.
Important point is that each chapter should be generated based on the premise given above.
First start by giving the book introduction, chapter introductions and then each chapter. It should also have a proper ending.
The book should have a prologue and an epilogue.
"""
return temperature, prompt
# function to render the story tab, and call the model, and display the model prompt and response.
def render_story_tab (text_model: GenerativeModel):
st.subheader("Generate a story")
temperature, prompt = generate_prompt()
config = {
"temperature": temperature,
"max_output_tokens": 2048,
}
generate_t2t = st.button("Generate my story", key="generate_t2t")
if generate_t2t and prompt:
# st.write(prompt)
with st.spinner("Generating your story using Gemini..."):
first_tab1, first_tab2 = st.tabs(["Story response", "Prompt"])
with first_tab1:
response = get_gemini_text_response(text_model, prompt, generation_config=config)
if response:
st.write("Your story:")
st.write(response)
logging.info(response)
with first_tab2:
st.text(prompt)
EOF
Sehen Sie sich den Inhalt der Datei app_tab1.py an:
cat ~/gemini-app/app_tab1.py
Die Funktion render_story_tab generiert die UI-Steuerelemente auf dem Tab, indem Funktionen zum Rendern der Texteingabefelder und anderer Optionen aufgerufen werden.
Die Funktion generate_prompt generiert den Text-Prompt, der an die Gemini API übergeben wird. Der Prompt-String wird erstellt, indem von Nutzern eingegebene Werte auf dem Tab für eine Figur in der Geschichte mit Optionen wie der Länge der Geschichte (kurz, lang), dem Kreativitätsgrad (niedrig, hoch) und der Prämisse der Geschichte verknüpft werden.
Die Funktion gibt außerdem basierend auf dem ausgewählten Kreativitätsgrad einen temperature-Wert zurück. Dieser Wert wird dem Modell als Konfigurationsparameter temperature übergeben, der die Zufälligkeit der Vorhersagen des Modells steuert. Der Konfigurationsparameter max_output_tokens gibt die maximale Anzahl von Ausgabetokens an, die pro Nachricht generiert werden sollen.
Zum Generieren der Modellantwort wird auf der Tab-Benutzeroberfläche eine Schaltfläche erstellt. Wenn darauf geklickt wird, wird die Funktion get_gemini_text_response aufgerufen, die wir im nächsten Schritt des Labs programmieren.
response_utils entwickeln
Die Datei response_utils.py enthält Funktionen zum Generieren der Antworten des Modells.
Führen Sie den folgenden Befehl aus, um Code zum Generieren der Textantworten des Modells zu schreiben:
Sehen Sie sich den Inhalt der Datei response_utils.py an:
cat ~/gemini-app/response_utils.py
Die Funktion get_gemini_text_response verwendet die Klasse GenerativeModel sowie einige andere aus dem Paket vertexai.preview.generative_models im Vertex AI SDK for Python. Über die Methode generate_content der Klasse wird eine Antwort auf den Text-Prompt generiert, der an die Methode übergeben wird.
Außerdem wird dieser Methode ein safety_settings-Objekt übergeben, um unsichere Inhalte in der Modellantwort zu blockieren. Im Beispielcode in diesem Lab werden Sicherheitseinstellungen verwendet, die das Modell anweisen, immer Inhalte zurückzugeben, unabhängig von der Wahrscheinlichkeit, dass diese unsicher sind. Sie können die generierten Inhalte analysieren und diese Einstellungen anpassen, wenn Ihre Anwendung eine restriktivere Konfiguration erfordert. Weitere Informationen finden Sie in der Dokumentation zu den Sicherheitseinstellungen.
Aufgabe 4: Anwendung lokal ausführen und testen
In dieser Aufgabe führen Sie die Anwendung lokal mit streamlit aus und testen ihre Funktionen.
Anwendung ausführen
Führen Sie in Cloud Shell den folgenden Befehl aus, um die Anwendung lokal auszuführen:
Die Anwendung wird gestartet und Sie erhalten eine URL für den Zugriff darauf.
Klicken Sie in der Cloud Shell-Menüleiste auf Webvorschau und dann auf Vorschau auf Port 8080, um die Startseite der Anwendung im Browser zu öffnen.
Sie können die URL auch kopieren und in einen separaten Browsertab einfügen, um auf die Anwendung zuzugreifen.
Anwendung testen – Tab „Story“
Sie generieren mithilfe einer Eingabe eine Geschichte und sehen sich den Prompt sowie die vom Gemini-Modell generierte Antwort an.
Lassen Sie auf dem Tab Story die Standardeinstellungen unverändert und klicken Sie auf Generate my story.
Warten Sie, bis die Antwort generiert wurde, und klicken Sie dann auf den Tab Story response.
Wenn Sie den Prompt sehen möchten, der zum Generieren der Antwort verwendet wurde, klicken Sie auf den Tab Prompt.
Klicken Sie auf Fortschritt prüfen.
Tab „Story“ wird in der Anwendung entwickelt.
Aufgabe 5: Marketingkampagne erstellen
In dieser Aufgabe verwenden Sie das Gemini 2.0 Flash-Modell, um eine Marketingkampagne für ein Unternehmen zu erstellen. Sie entwickeln den Code, durch den ein zweiter Tab in Ihrer Anwendung generiert wird.
Tab 2 „Marketing Campaign“ entwickeln
Öffnen Sie ein zweites Terminalfenster in Cloud Shell. Klicken Sie dazu in der Cloud Shell-Menüleiste auf +.
Führen Sie den folgenden Befehl aus, um Code zu schreiben, der den Tab Marketing Campaign in der Benutzeroberfläche der Anwendung rendert:
cat > ~/gemini-app/app_tab2.py <<EOF
import streamlit as st
from vertexai.preview.generative_models import GenerativeModel
from response_utils import *
import logging
# create the model prompt based on user input.
def generate_prompt():
product_name = st.text_input("What is the name of the product? \n\n",key="product_name",value="ZomZoo")
product_category = st.radio("Select your product category: \n\n",["Clothing","Electronics","Food","Health & Beauty","Home & Garden"],key="product_category",horizontal=True)
st.write("Select your target audience: ")
target_audience_age = st.radio("Target age: \n\n",["18-24","25-34","35-44","45-54","55-64","65+"],key="target_audience_age",horizontal=True)
# target_audience_gender = st.radio("Target gender: \n\n",["male","female","trans","non-binary","others"],key="target_audience_gender",horizontal=True)
target_audience_location = st.radio("Target location: \n\n",["Urban", "Suburban","Rural"],key="target_audience_location",horizontal=True)
st.write("Select your marketing campaign goal: ")
campaign_goal = st.multiselect("Select your marketing campaign goal: \n\n",["Increase brand awareness","Generate leads","Drive sales","Improve brand sentiment"],key="campaign_goal",default=["Increase brand awareness","Generate leads"])
if campaign_goal is None:
campaign_goal = ["Increase brand awareness","Generate leads"]
brand_voice = st.radio("Select your brand voice: \n\n",["Formal","Informal","Serious","Humorous"],key="brand_voice",horizontal=True)
estimated_budget = st.radio("Select your estimated budget ($): \n\n",["1,000-5,000","5,000-10,000","10,000-20,000","20,000+"],key="estimated_budget",horizontal=True)
prompt = f"""Generate a marketing campaign for {product_name}, a {product_category} designed for the age group: {target_audience_age}.
The target location is this: {target_audience_location}.
Aim to primarily achieve {campaign_goal}.
Emphasize the product's unique selling proposition while using a {brand_voice} tone of voice.
Allocate the total budget of {estimated_budget}.
With these inputs, make sure to follow following guidelines and generate the marketing campaign with proper headlines: \n
- Briefly describe the company, its values, mission, and target audience.
- Highlight any relevant brand guidelines or messaging frameworks.
- Provide a concise overview of the campaign's objectives and goals.
- Briefly explain the product or service being promoted.
- Define your ideal customer with clear demographics, psychographics, and behavioral insights.
- Understand their needs, wants, motivations, and pain points.
- Clearly articulate the desired outcomes for the campaign.
- Use SMART goals (Specific, Measurable, Achievable, Relevant, and Time-bound) for clarity.
- Define key performance indicators (KPIs) to track progress and success.
- Specify the primary and secondary goals of the campaign.
- Examples include brand awareness, lead generation, sales growth, or website traffic.
- Clearly define what differentiates your product or service from competitors.
- Emphasize the value proposition and unique benefits offered to the target audience.
- Define the desired tone and personality of the campaign messaging.
- Identify the specific channels you will use to reach your target audience.
- Clearly state the desired action you want the audience to take.
- Make it specific, compelling, and easy to understand.
- Identify and analyze your key competitors in the market.
- Understand their strengths and weaknesses, target audience, and marketing strategies.
- Develop a differentiation strategy to stand out from the competition.
- Define how you will track the success of the campaign.
- Use relevant KPIs to measure performance and return on investment (ROI).
Provide bullet points and headlines for the marketing campaign. Do not produce any empty lines. Be very succinct and to the point.
"""
return prompt
# function to render the story tab, and call the model, and display the model prompt and response.
def render_mktg_campaign_tab (text_model: GenerativeModel):
st.subheader("Generate a marketing campaign")
prompt = generate_prompt()
config = {
"temperature": 0.8,
"max_output_tokens": 2048,
}
generate_t2m = st.button("Generate campaign", key="generate_t2m")
if generate_t2m and prompt:
# st.write(prompt)
with st.spinner("Generating a marketing campaign using Gemini..."):
first_tab1, first_tab2 = st.tabs(["Campaign response", "Prompt"])
with first_tab1:
response = get_gemini_text_response(text_model, prompt, generation_config=config)
if response:
st.write("Marketing campaign:")
st.write(response)
logging.info(response)
with first_tab2:
st.text(prompt)
EOF
Haupteinstiegspunkt der Anwendung ändern
Führen Sie den folgenden Befehl aus, um der Anwendung UI-Inhalte für Tab 2 (Marketing Campaign) hinzuzufügen:
cat >> ~/gemini-app/app.py <<EOF
from app_tab2 import render_mktg_campaign_tab
with tab2:
render_mktg_campaign_tab(text_model)
EOF
Anwendung testen – Tab „Marketing Campaign“
Sie erstellen eine Marketingkampagne, indem Sie eine Eingabe senden, und sehen sich den Prompt sowie die vom Gemini-Modell generierte Antwort an.
Aktualisieren Sie den Browsertab oder das Browserfenster, in dem die Anwendung angezeigt wird, um die aktualisierte Benutzeroberfläche der Anwendung neu zu laden und zu öffnen.
Lassen Sie zum Generieren einer Marketingkampagne auf dem Tab Marketing Campaign die Standardeinstellungen unverändert und klicken Sie auf Generate campaign.
Warten Sie, bis die Antwort generiert wurde, und klicken Sie dann auf den Tab Campaign response.
Wenn Sie den Prompt sehen möchten, der zum Generieren der Antwort verwendet wurde, klicken Sie auf den Tab Prompt.
Wiederholen Sie die obigen Schritte, um Marketingkampagnen mit unterschiedlichen Werten für die Parameter wie Produktkategorie, Zielgruppe, Standort und Kampagnenziele zu erstellen.
Klicken Sie auf Fortschritt prüfen.
Tab „Marketing Campaign“ wird in der Anwendung entwickelt.
Aufgabe 6: Video-Playground generieren
In dieser Aufgabe verwenden Sie das Gemini 2.0 Flash-Modell, um Videos zu verarbeiten und Tags und Informationen aus den Videos zu generieren, die an das Modell übergeben werden.
Tab 3 „Video Playground“ entwickeln
Das Modell Gemini 2.0 Flash kann auch eine Beschreibung dessen liefern, was in einem Video passiert. In dieser Teilaufgabe implementieren Sie den Code für den Tab Video Playground und den Code für die Interaktion mit dem Modell, um die Beschreibung eines Videos zu generieren.
Führen Sie den folgenden Befehl aus, um Code zu schreiben, der den Tab Video Playground in der Benutzeroberfläche der Anwendung rendert:
cat > ~/gemini-app/app_tab3.py <<EOF
import streamlit as st
from vertexai.preview.generative_models import GenerativeModel, Part
from response_utils import *
import logging
# render the Video Playground tab with multiple child tabs
def render_video_playground_tab(multimodal_model: GenerativeModel):
video_desc, video_tags, video_highlights, video_geoloc = st.tabs(["Video description", "Video tags", "Video highlights", "Video geolocation"])
with video_desc:
video_desc_uri = "gs://cloud-training/OCBL447/gemini-app/videos/mediterraneansea.mp4"
video_desc_url = "https://storage.googleapis.com/"+video_desc_uri.split("gs://")[1]
video_desc_vid = Part.from_uri(video_desc_uri, mime_type="video/mp4")
st.video(video_desc_url)
st.write("Generate a description of the video.")
prompt = """Describe what is happening in the video and answer the following questions: \n
- What am I looking at?
- Where should I go to see it?
- What are other top 5 places in the world that look like this?
"""
tab1, tab2 = st.tabs(["Response", "Prompt"])
video_desc_description = st.button("Generate video description", key="video_desc_description")
with tab1:
if video_desc_description and prompt:
with st.spinner("Generating video description"):
response = get_gemini_vision_response(multimodal_model, [prompt, video_desc_vid])
st.markdown(response)
logging.info(response)
with tab2:
st.write("Prompt used:")
st.write(prompt,"\n","{video_data}")
EOF
Sehen Sie sich den Inhalt der Datei app_tab3.py an:
cat ~/gemini-app/app_tab3.py
Mit der Funktion render_video_playground_tab wird die Benutzeroberfläche erstellt, über die Nutzer mit dem Gemini-Modell interagieren können. Es werden die Tabs „Video description“, „Video tags“, „Video highlights“ und „Video geolocation“ erstellt. Den Code für die übrigen Tabs schreiben Sie in den nachfolgenden Aufgaben in diesem Lab.
Auf dem Tab Video description wird anhand eines Prompts und des Videos eine Beschreibung des Videos erstellt und es werden andere Orte identifiziert, die dem im Video gezeigten Ort ähneln.
response_utils aktualisieren
Die Datei response_utils.py enthält Funktionen zum Generieren der Antworten des Modells.
Aktualisieren Sie die Datei und fügen Sie Code hinzu, der die multimodale Antwort des Modells generiert:
Führen Sie den folgenden Befehl aus, um der Anwendung UI-Inhalte für Tab 3 (Video Playground) hinzuzufügen:
cat >> ~/gemini-app/app.py <<EOF
from app_tab3 import render_video_playground_tab
with tab3:
render_video_playground_tab(multimodal_model)
EOF
Anwendung testen – Tab „Video Playground“
Aktualisieren Sie den Browsertab oder das Browserfenster, in dem die Anwendung angezeigt wird, um die aktualisierte Benutzeroberfläche der Anwendung neu zu laden und zu öffnen.
Klicken Sie auf Video Playground und dann auf Video description.
Auf dem Tab wird das Video eines Ortes angezeigt. Klicken Sie darauf, um das Video abzuspielen.
Warten Sie, bis das Video zu Ende ist, bevor Sie mit dem nächsten Schritt fortfahren.
Klicken Sie auf Generate video description.
Wenn Ihnen die Fehlermeldung google.api_core.exceptions.FailedPrecondition: 400 Service agents are being provisioned (https://cloud.google.com/vertex-ai/docs/general/access-control#service-agents). Service agents are needed to read the Cloud Storage file provided. So please try again in a few minutes. angezeigt wird, warten Sie einige Minuten und klicken Sie dann noch einmal auf Generate video description.
Sehen Sie sich die Antwort des Modells an.
Diese enthält eine Beschreibung des Ortes sowie fünf weitere Orte, die ähnlich aussehen.
Klicken Sie auf Fortschritt prüfen.
Tab „Video description“ wird im Tab „Video Playground“ der Anwendung entwickelt.
Aufgabe 7: Video-Tags generieren
In dieser Aufgabe verwenden Sie das Gemini 2.0 Flash-Modell, um Tags aus einem Video zu generieren.
Tab „Video Playground – Video tags“ aktualisieren
Führen Sie den folgenden Befehl aus, um Code für den Tab Video tags auf dem Tab Video Playground in der Benutzeroberfläche der Anwendung zu implementieren:
cat >> ~/gemini-app/app_tab3.py <<EOF
with video_tags:
video_tags_uri = "gs://cloud-training/OCBL447/gemini-app/videos/photography.mp4"
video_tags_url = "https://storage.googleapis.com/"+video_tags_uri.split("gs://")[1]
video_tags_vid = Part.from_uri(video_tags_uri, mime_type="video/mp4")
st.video(video_tags_url)
st.write("Generate tags for the video.")
prompt = """Answer the following questions using the video only:
1. What is in the video?
2. What objects are in the video?
3. What is the action in the video?
4. Provide 5 best tags for this video?
Write the answer in table format with the questions and answers in columns.
"""
tab1, tab2 = st.tabs(["Response", "Prompt"])
video_tags_desc = st.button("Generate video tags", key="video_tags_desc")
with tab1:
if video_tags_desc and prompt:
with st.spinner("Generating video tags"):
response = get_gemini_vision_response(multimodal_model, [prompt, video_tags_vid])
st.markdown(response)
logging.info(response)
with tab2:
st.write("Prompt used:")
st.write(prompt,"\n","{video_data}")
EOF
Mit dem Code oben wird die Benutzeroberfläche des Tabs Video tags erstellt. Ein Video wird zusammen mit Text in einem Prompt an das Modell gesendet, damit es daraus Tags generiert und Fragen zu Szenen im Video beantwortet.
Anwendung testen – Tab „Video Playground – Video tags“
Aktualisieren Sie den Browsertab oder das Browserfenster, in dem die Anwendung angezeigt wird, um die aktualisierte Benutzeroberfläche der Anwendung neu zu laden und zu öffnen.
Klicken Sie auf Video Playground und dann auf Video tags.
Auf dem Tab wird das Video angezeigt, das als Prompt für das Modell verwendet wird. Klicken Sie darauf, um das Video abzuspielen.
Klicken Sie auf Generate video tags.
Sehen Sie sich die Antwort des Modells an.
Die Modellantwort enthält die Antworten auf die Fragen, die dem Modell im Prompt gestellt wurden. Die Fragen und Antworten werden in Tabellenform ausgegeben und enthalten wie angefordert fünf Tags.
Klicken Sie auf Fortschritt prüfen.
Tab „Video tags“ wird im Tab „Video Playground“ entwickelt.
Aufgabe 8: Video-Highlights erstellen
In dieser Aufgabe verwenden Sie das Gemini 2.0 Flash-Modell, um Highlights aus einem Video zu generieren, die Informationen zu den darin gezeigten Objekten, Personen und dem Kontext enthalten.
Führen Sie den folgenden Befehl aus, um Code für den Tab Video highlights auf dem Tab Video Playground in der Benutzeroberfläche der Anwendung zu implementieren:
cat >> ~/gemini-app/app_tab3.py <<EOF
with video_highlights:
video_highlights_uri = "gs://cloud-training/OCBL447/gemini-app/videos/pixel8.mp4"
video_highlights_url = "https://storage.googleapis.com/"+video_highlights_uri.split("gs://")[1]
video_highlights_vid = Part.from_uri(video_highlights_uri, mime_type="video/mp4")
st.video(video_highlights_url)
st.write("Generate highlights for the video.")
prompt = """Answer the following questions using the video only:
What is the profession of the girl in this video?
Which features of the phone are highlighted here?
Summarize the video in one paragraph.
"""
tab1, tab2 = st.tabs(["Response", "Prompt"])
video_highlights_description = st.button("Generate video highlights", key="video_highlights_description")
with tab1:
if video_highlights_description and prompt:
with st.spinner("Generating video highlights"):
response = get_gemini_vision_response(multimodal_model, [prompt, video_highlights_vid])
st.markdown(response)
logging.info(response)
with tab2:
st.write("Prompt used:")
st.write(prompt,"\n","{video_data}")
EOF
Mit dem Code oben wird die Benutzeroberfläche des Tabs Video highlights erstellt. Ein Video wird zusammen mit Text als Prompt an das Modell gesendet, damit es Highlights aus dem Video generiert.
Anwendung testen – Tab „Video Playground – Video highlights“
Aktualisieren Sie den Browsertab oder das Browserfenster, in dem die Anwendung angezeigt wird, um die aktualisierte Benutzeroberfläche der Anwendung neu zu laden und zu öffnen.
Klicken Sie auf Video Playground und dann auf Video highlights.
Auf dem Tab wird das Video angezeigt, das als Prompt für das Modell verwendet wird. Klicken Sie darauf, um das Video abzuspielen.
Klicken Sie auf Generate video highlights.
Sehen Sie sich die Antwort des Modells an.
Die Modellantwort enthält die Antworten auf die Fragen, die dem Modell im Prompt gestellt wurden. Die Antworten enthalten Fakten aus dem Video, zum Beispiel den Beruf des Mädchens und die verwendeten Funktionen des Smartphones. Die Modellantwort umfasst außerdem eine Zusammenfassung der Szenen im Video.
Klicken Sie auf Fortschritt prüfen.
Tab „Video highlights“ wird im Tab „Video Playground“ entwickelt.
Aufgabe 9: Drehort des Videos erkennen
In dieser Aufgabe verwenden Sie das Gemini 2.0 Flash-Modell, um herauszufinden, an welchem Ort die Szene im Video spielt.
Tab „Image Playground – Video geolocation“ aktualisieren
Führen Sie den folgenden Befehl aus, um Code für den Tab Video geolocation auf dem Tab Video Playground in der Benutzeroberfläche der Anwendung zu implementieren:
cat >> ~/gemini-app/app_tab3.py <<EOF
with video_geoloc:
video_geolocation_uri = "gs://cloud-training/OCBL447/gemini-app/videos/bus.mp4"
video_geolocation_url = "https://storage.googleapis.com/"+video_geolocation_uri.split("gs://")[1]
video_geolocation_vid = Part.from_uri(video_geolocation_uri, mime_type="video/mp4")
st.video(video_geolocation_url)
st.markdown("""Answer the following questions from the video:
- What is this video about?
- How do you know which city it is?
- What street is this?
- What is the nearest intersection?
""")
prompt = """Answer the following questions using the video only:
What is this video about?
How do you know which city it is?
What street is this?
What is the nearest intersection?
"""
tab1, tab2 = st.tabs(["Response", "Prompt"])
video_geolocation_description = st.button("Generate", key="video_geolocation_description")
with tab1:
if video_geolocation_description and prompt:
with st.spinner("Generating location information"):
response = get_gemini_vision_response(multimodal_model, [prompt, video_geolocation_vid])
st.markdown(response)
logging.info(response)
with tab2:
st.write("Prompt used:")
st.write(prompt,"\n","{video_data}")
EOF
Mit dem Code oben wird die Benutzeroberfläche des Tabs Video geolocation erstellt. Ein Video wird zusammen mit Text als Prompt an das Modell gesendet, damit dieses Fragen zum Video beantwortet. Die Antworten sollen Standortinformationen zu Dingen im Video enthalten.
Anwendung testen – Tab „Video Playground – Video geolocation“
Aktualisieren Sie den Browsertab oder das Browserfenster, in dem die Anwendung angezeigt wird, um die aktualisierte Benutzeroberfläche der Anwendung neu zu laden und zu öffnen.
Klicken Sie auf Video Playground und dann auf Video geolocation.
Auf dem Tab wird das Video angezeigt, das als Prompt für das Modell verwendet wird. Klicken Sie darauf, um das Video abzuspielen.
Klicken Sie auf Erstellen.
Sehen Sie sich die Antwort des Modells an.
Die Modellantwort enthält die Antworten auf die Fragen, die dem Modell im Prompt gestellt wurden. Die Antworten enthalten die angeforderten Standortinformationen.
Klicken Sie auf Fortschritt prüfen.
Tab „Video geolocation“ wird im Tab „Video Playground“ entwickelt.
Aufgabe 10: Bilder-Playground generieren
In dieser Aufgabe verwenden Sie das Gemini 2.0 Flash-Modell, um Bilder zu verarbeiten und Empfehlungen und Informationen aus den Bildern zu erhalten, die an das Modell gesendet werden.
Tab 4 „Image Playground“ entwickeln
In dieser Teilaufgabe implementieren Sie den Code für den Tab Image Playground und den Code für die Interaktion mit dem Modell, um Empfehlungen aus einem Bild zu generieren.
Führen Sie den folgenden Befehl aus, um Code zu schreiben, der den Tab Image Playground in der Benutzeroberfläche der Anwendung rendert:
cat > ~/gemini-app/app_tab4.py <<EOF
import streamlit as st
from vertexai.preview.generative_models import GenerativeModel, Part
from response_utils import *
import logging
# render the Image Playground tab with multiple child tabs
def render_image_playground_tab(multimodal_model: GenerativeModel):
recommendations, screens, diagrams, equations = st.tabs(["Furniture recommendation", "Oven instructions", "ER diagrams", "Math reasoning"])
with recommendations:
room_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/living_room.jpeg"
chair_1_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair1.jpeg"
chair_2_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair2.jpeg"
chair_3_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair3.jpeg"
chair_4_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair4.jpeg"
room_image_url = "https://storage.googleapis.com/"+room_image_uri.split("gs://")[1]
chair_1_image_url = "https://storage.googleapis.com/"+chair_1_image_uri.split("gs://")[1]
chair_2_image_url = "https://storage.googleapis.com/"+chair_2_image_uri.split("gs://")[1]
chair_3_image_url = "https://storage.googleapis.com/"+chair_3_image_uri.split("gs://")[1]
chair_4_image_url = "https://storage.googleapis.com/"+chair_4_image_uri.split("gs://")[1]
room_image = Part.from_uri(room_image_uri, mime_type="image/jpeg")
chair_1_image = Part.from_uri(chair_1_image_uri,mime_type="image/jpeg")
chair_2_image = Part.from_uri(chair_2_image_uri,mime_type="image/jpeg")
chair_3_image = Part.from_uri(chair_3_image_uri,mime_type="image/jpeg")
chair_4_image = Part.from_uri(chair_4_image_uri,mime_type="image/jpeg")
st.image(room_image_url,width=350, caption="Image of a living room")
st.image([chair_1_image_url,chair_2_image_url,chair_3_image_url,chair_4_image_url],width=200, caption=["Chair 1","Chair 2","Chair 3","Chair 4"])
st.write("Our expectation: Recommend a chair that would complement the given image of a living room.")
prompt_list = ["Consider the following chairs:",
"chair 1:", chair_1_image,
"chair 2:", chair_2_image,
"chair 3:", chair_3_image, "and",
"chair 4:", chair_4_image, "\n"
"For each chair, explain why it would be suitable or not suitable for the following room:",
room_image,
"Only recommend for the room provided and not other rooms. Provide your recommendation in a table format with chair name and reason as columns.",
]
tab1, tab2 = st.tabs(["Response", "Prompt"])
generate_image_description = st.button("Generate recommendation", key="generate_image_description")
with tab1:
if generate_image_description and prompt_list:
with st.spinner("Generating recommendation using Gemini..."):
response = get_gemini_vision_response(multimodal_model, prompt_list)
st.markdown(response)
logging.info(response)
with tab2:
st.write("Prompt used:")
st.text(prompt_list)
EOF
Sehen Sie sich den Inhalt der Datei app_tab4.py an:
cat ~/gemini-app/app_tab4.py
Mit der Funktion render_image_playground_tab wird die Benutzeroberfläche erstellt, über die Nutzer mit dem Gemini-Modell interagieren können. Es werden die Tabs „Furniture recommendation“, „Oven instructions“, „ER diagrams“ und „Math reasoning“ erstellt. Den Code für die übrigen Tabs schreiben Sie in den nachfolgenden Aufgaben in diesem Lab.
Auf dem Tab Furniture recommendation wird das Bild eines Wohnzimmers für visuelles Verstehen verwendet. Im Code wird das Modell zusammen mit einer Reihe weiterer Bilder von Stühlen verwendet, um einen Stuhl zu empfehlen, der in dieses Wohnzimmer passt.
Der Code enthält mehrere Text-Prompts und die Bilder des Wohnzimmers sowie der Stühle und stellt sie dem Modell in einer Liste zur Verfügung. Mit der Klasse Part wird das Bild aus dem mehrteiligen Inhalts-URI abgerufen, der in einem Cloud Storage-Bucket gehostet wird. Im Prompt ist außerdem ein Tabellenformat für die Modellausgabe vorgegeben und das Modell wird aufgefordert, die Begründung für die Empfehlung anzugeben.
Haupteinstiegspunkt der Anwendung ändern
Führen Sie den folgenden Befehl aus, um der Anwendung UI-Inhalte für Tab 4 (Image Playground) hinzuzufügen:
cat >> ~/gemini-app/app.py <<EOF
from app_tab4 import render_image_playground_tab
with tab4:
render_image_playground_tab(multimodal_model)
EOF
Anwendung testen – Tab „Image Playground“
Aktualisieren Sie den Browsertab oder das Browserfenster, in dem die Anwendung angezeigt wird, um die aktualisierte Benutzeroberfläche der Anwendung neu zu laden und zu öffnen.
Klicken Sie auf Image Playground und dann auf Furniture recommendation.
Auf dem Tab werden die Bilder des Wohnzimmers und der Stühle angezeigt.
Klicken Sie auf Generate recommendation.
Wenn Ihnen die Fehlermeldung google.api_core.exceptions.FailedPrecondition: 400 Service agents are being provisioned (https://cloud.google.com/vertex-ai/docs/general/access-control#service-agents). Service agents are needed to read the Cloud Storage file provided. So please try again in a few minutes. angezeigt wird, warten Sie einige Minuten und klicken Sie dann noch einmal auf Generate recommendation.
Sehen Sie sich die Antwort des Modells an.
Die Antwort ist im Tabellenformat, wie im Prompt angegeben. Das Modell empfiehlt zwei der vier Stühle und gibt eine Begründung für die Empfehlung.
Klicken Sie auf Fortschritt prüfen.
Tab „Furniture recommendation“ wird im Tab „Image Playground“ entwickelt.
Aufgabe 11: Bildlayout analysieren
In dieser Aufgabe verwenden Sie das Gemini 2.0 Flash-Modell, um Informationen aus einem Bild zu extrahieren, nachdem das Layout der Symbole und des Textes analysiert wurde.
Gemini kann Informationen aus visuellen Elementen extrahieren und Screenshots, Symbole und Layouts analysieren, um die Darstellung zu verstehen. In dieser Aufgabe stellen Sie dem Modell ein Bild des Bedienfelds eines Backofens zur Verfügung und fordern es dann auf, eine Anleitung für eine bestimmte Funktion zu generieren.
Führen Sie den folgenden Befehl aus, um Code für den Tab Oven instructions auf dem Tab Image Playground in der Benutzeroberfläche der Anwendung zu implementieren:
cat >> ~/gemini-app/app_tab4.py <<EOF
with screens:
oven_screen_uri = "gs://cloud-training/OCBL447/gemini-app/images/oven.jpg"
oven_screen_url = "https://storage.googleapis.com/"+oven_screen_uri.split("gs://")[1]
oven_screen_img = Part.from_uri(oven_screen_uri, mime_type="image/jpeg")
st.image(oven_screen_url, width=350, caption="Image of an oven control panel")
st.write("Provide instructions for resetting the clock on this appliance in English")
prompt = """How can I reset the clock on this appliance? Provide the instructions in English.
If instructions include buttons, also explain where those buttons are physically located.
"""
tab1, tab2 = st.tabs(["Response", "Prompt"])
generate_instructions_description = st.button("Generate instructions", key="generate_instructions_description")
with tab1:
if generate_instructions_description and prompt:
with st.spinner("Generating instructions using Gemini..."):
response = get_gemini_vision_response(multimodal_model, [oven_screen_img, prompt])
st.markdown(response)
logging.info(response)
with tab2:
st.write("Prompt used:")
st.text(prompt+"\n"+"input_image")
EOF
Mit dem Code oben wird die Benutzeroberfläche des Tabs Oven instructions erstellt. Ein Bild des Bedienfelds eines Backofens wird zusammen mit Text als Prompt an das Modell gesendet, damit dieses eine Anleitung für eine bestimmte Funktion generiert, die auf dem Bedienfeld verfügbar ist, in diesem Fall das Zurücksetzen der Uhr.
Aktualisieren Sie den Browsertab oder das Browserfenster, in dem die Anwendung angezeigt wird, um die aktualisierte Benutzeroberfläche der Anwendung neu zu laden und zu öffnen.
Klicken Sie auf Image Playground und dann auf Oven instructions.
Auf dem Tab wird ein Bild des Bedienfelds des Backofens angezeigt.
Klicken Sie auf Generate instructions.
Sehen Sie sich die Antwort des Modells an.
Die Antwort enthält die Schritte, mit denen die Uhr auf dem Bedienfeld des Backofens zurückgesetzt werden kann. Außerdem enthält sie einen Hinweis, wo sich der Knopf auf dem Bedienfeld befindet, was die Fähigkeit des Modells veranschaulicht, das Layout des Bedienfelds im Bild zu analysieren.
Klicken Sie auf Fortschritt prüfen.
Tab „Oven instructions“ wird im Tab „Image Playground“ entwickelt.
Aufgabe 12: ER-Diagramme analysieren
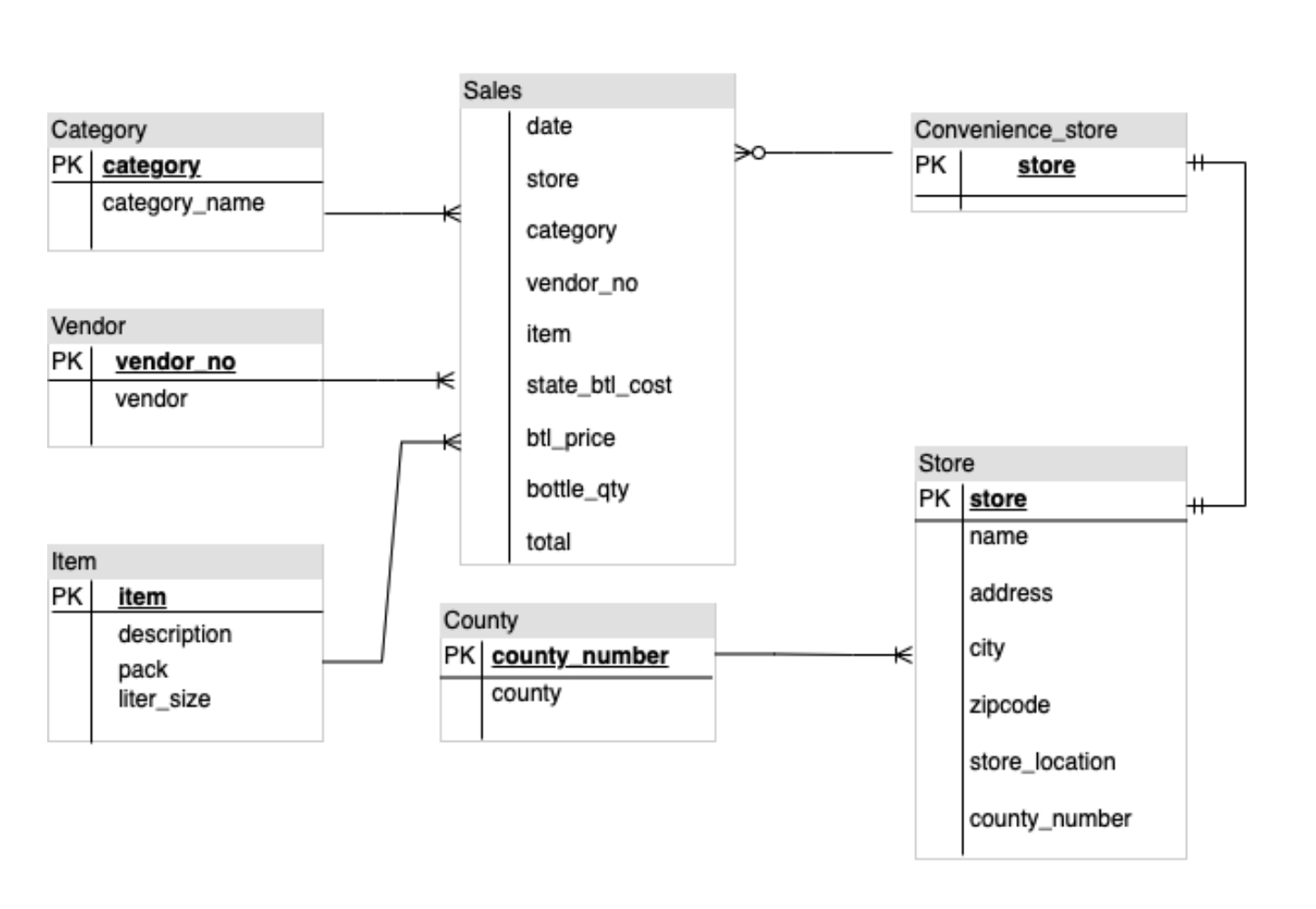
Dank der multimodalen Funktionen kann Gemini Diagramme analysieren und Maßnahmen ergreifen, wie Dokumente oder Code generieren. In dieser Aufgabe analysieren Sie mit dem Gemini 2.0 Flash-Modell ein Entity-Relationship-Diagramm (ER-Diagramm) und generieren eine Dokumentation zu den Entitäten und Beziehungen im Diagramm.
In dieser Aufgabe stellen Sie dem Modell ein Bild eines ER-Diagramms zur Verfügung und fordern es dann auf, eine Dokumentation dazu zu generieren.
Führen Sie den folgenden Befehl aus, um Code für den Tab ER diagrams auf dem Tab Image Playground in der Benutzeroberfläche der Anwendung zu implementieren:
cat >> ~/gemini-app/app_tab4.py <<EOF
with diagrams:
er_diag_uri = "gs://cloud-training/OCBL447/gemini-app/images/er.png"
er_diag_url = "https://storage.googleapis.com/"+er_diag_uri.split("gs://")[1]
er_diag_img = Part.from_uri(er_diag_uri,mime_type="image/png")
st.image(er_diag_url, width=350, caption="Image of an ER diagram")
st.write("Document the entities and relationships in this ER diagram.")
prompt = """Document the entities and relationships in this ER diagram."""
tab1, tab2 = st.tabs(["Response", "Prompt"])
er_diag_img_description = st.button("Generate documentation", key="er_diag_img_description")
with tab1:
if er_diag_img_description and prompt:
with st.spinner("Generating..."):
response = get_gemini_vision_response(multimodal_model,[er_diag_img,prompt])
st.markdown(response)
logging.info(response)
with tab2:
st.write("Prompt used:")
st.text(prompt+"\n"+"input_image")
EOF
Mit dem Code oben wird die Benutzeroberfläche des Tabs ER diagrams erstellt. Ein Bild eines ER-Diagramms wird zusammen mit Text als Prompt an das Modell gesendet, damit es eine Dokumentation zu den Entitäten und Beziehungen im Diagramm generiert.
Anwendung testen – Tab „Image Playground – ER diagrams“
Aktualisieren Sie den Browsertab oder das Browserfenster, in dem die Anwendung angezeigt wird, um die aktualisierte Benutzeroberfläche der Anwendung neu zu laden und zu öffnen.
Klicken Sie auf Image Playground und dann auf ER diagrams.
Auf dem Tab wird das Bild des ER-Diagramms angezeigt.
Klicken Sie auf Generate documentation.
Sehen Sie sich die Antwort des Modells an.
Die Antwort enthält eine Liste der Entitäten und ihrer Beziehungen im Diagramm.
Klicken Sie auf Fortschritt prüfen.
Tab „ER diagrams“ wird im Tab „Image Playground“ entwickelt.
Aufgabe 13: Mathematische Schlussfolgerungen
Gemini 2.0 Flash kann auch mathematische Formeln und Gleichungen erkennen und bestimmte Informationen daraus extrahieren. Diese Funktion ist besonders nützlich, um Erklärungen für mathematische Probleme zu generieren.
Tab „Image Playground – Math reasoning“ aktualisieren
In dieser Aufgabe verwenden Sie das Gemini 2.0 Flash-Modell, um eine mathematische Formel aus einem Bild zu extrahieren und zu interpretieren.
Führen Sie den folgenden Befehl aus, um Code für den Tab Math reasoning auf dem Tab Image Playground in der Benutzeroberfläche der Anwendung zu implementieren:
cat >> ~/gemini-app/app_tab4.py <<EOF
with equations:
math_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/math_eqn.jpg"
math_image_url = "https://storage.googleapis.com/"+math_image_uri.split("gs://")[1]
math_image_img = Part.from_uri(math_image_uri,mime_type="image/jpeg")
st.image(math_image_url,width=350, caption="Image of a math equation")
st.markdown(f"""
Ask questions about the math equation as follows:
- Extract the formula.
- What is the symbol right before Pi? What does it mean?
- Is this a famous formula? Does it have a name?
""")
prompt = """Follow the instructions. Surround math expressions with $. Use a table with a row for each instruction and its result.
INSTRUCTIONS:
- Extract the formula.
- What is the symbol right before Pi? What does it mean?
- Is this a famous formula? Does it have a name?
"""
tab1, tab2 = st.tabs(["Response", "Prompt"])
math_image_description = st.button("Generate answers", key="math_image_description")
with tab1:
if math_image_description and prompt:
with st.spinner("Generating answers for formula using Gemini..."):
response = get_gemini_vision_response(multimodal_model, [math_image_img, prompt])
st.markdown(response)
logging.info(response)
with tab2:
st.write("Prompt used:")
st.text(prompt)
EOF
Mit dem Code oben wird die Benutzeroberfläche des Tabs Math reasoning erstellt. Ein Bild einer mathematischen Gleichung wird zusammen mit Text als Prompt an das Modell gesendet, damit es Antworten und Informationen zu Eigenschaften der Gleichung generiert.
Anwendung testen – Tab „Image Playground – Math reasoning“
Aktualisieren Sie den Browsertab oder das Browserfenster, in dem die Anwendung angezeigt wird, um die aktualisierte Benutzeroberfläche der Anwendung neu zu laden und zu öffnen.
Klicken Sie auf Image Playground und dann auf Math reasoning.
Auf dem Tab wird das Bild mit der mathematischen Gleichung angezeigt.
Klicken Sie auf Generate answers.
Sehen Sie sich die Antwort des Modells an.
Die Ausgabe enthält die Antworten auf die Fragen, die dem Modell im Prompt gestellt wurden.
Beenden Sie im ursprünglichen Cloud Shell-Fenster die Anwendung und kehren Sie mit Strg + C zur Eingabeaufforderung zurück.
Klicken Sie auf Fortschritt prüfen.
Tab „Math reasoning“ wird im Tab „Image Playground“ entwickelt.
Aufgabe 14: Anwendung in Cloud Run bereitstellen
Nachdem Sie die Anwendung lokal getestet haben, können Sie sie für andere verfügbar machen, indem Sie sie in Cloud Run in Google Cloud bereitstellen. Cloud Run ist eine verwaltete Computing-Plattform, mit der Sie Anwendungscontainer auf der skalierbaren Infrastruktur von Google ausführen können.
Umgebung einrichten
Sie müssen sich im Verzeichnis app befinden:
cd ~/gemini-app
Prüfen Sie, ob die Umgebungsvariablen PROJECT_ID und REGION festgelegt sind:
Legen Sie Umgebungsvariablen für Ihren Dienst und Ihr Artefakt-Repository fest:
SERVICE_NAME='gemini-app-playground' # Name of your Cloud Run service.
AR_REPO='gemini-app-repo' # Name of your repository in Artifact Registry that stores your application container image.
echo "SERVICE_NAME=${SERVICE_NAME}"
echo "AR_REPO=${AR_REPO}"
Docker-Repository erstellen
Führen Sie den folgenden Befehl aus, um das Repository in Artifact Registry zu erstellen:
gcloud artifacts repositories create "$AR_REPO" --location="$REGION" --repository-format=Docker
Artifact Registry ist ein Google Cloud-Dienst, der einen zentralen Ort für das Speichern und Verwalten Ihrer Softwarepakete und Docker-Container-Images bietet.
Richten Sie die Authentifizierung für das Repository ein:
Wir nutzen ein Dockerfile, um das Container-Image für unsere Anwendung zu erstellen. Ein Dockerfile ist ein Textdokument, das alle Befehle enthält, die Nutzer in der Befehlszeile aufrufen können, um ein Container-Image zusammenzustellen. Es wird mit Docker verwendet, einer Containerplattform, mit der Container-Images erstellt und ausgeführt werden.
Führen Sie den folgenden Befehl aus, um ein Dockerfile zu erstellen:
Führen Sie den folgenden Befehl aus, um das Container-Image für Ihre Anwendung zu erstellen:
gcloud builds submit --tag "$REGION-docker.pkg.dev/$PROJECT_ID/$AR_REPO/$SERVICE_NAME"
Mit dem Befehl gcloud builds submit wird ein Build mit Cloud Build gesendet. Wenn Sie das Flag tag verwenden, erstellt Cloud Build mithilfe eines Dockerfiles ein Container-Image aus den Anwendungsdateien im Quellverzeichnis.
Cloud Build ist ein Dienst, der Builds gemäß Ihren Spezifikationen in Google Cloud ausführt und Artefakte wie Docker-Container oder Java-Archive erstellt.
Warten Sie, bis der Befehl abgeschlossen ist, bevor Sie mit dem nächsten Schritt fortfahren.
Anwendung in Cloud Run bereitstellen und testen
Als Letztes stellen Sie den Dienst in Cloud Run mit dem Image bereit, das erstellt und per Push in das Repository in Artifact Registry übertragen wurde.
Führen Sie den folgenden Befehl aus, um Ihre Anwendung in Cloud Run bereitzustellen:
Nachdem der Dienst bereitgestellt wurde, wird in der Ausgabe des vorherigen Befehls eine URL zum Dienst generiert. Wenn Sie Ihre Anwendung in Cloud Run testen möchten, rufen Sie diese URL in einem separaten Browsertab oder ‑fenster auf.
Wählen Sie die Anwendungsfunktion aus, die Sie testen möchten. Die Anwendung ruft die Vertex AI Gemini API auf, um die Antworten zu generieren und anzuzeigen.
Klicken Sie auf Fortschritt prüfen.
Anwendung wird in Cloud Run bereitgestellt.
Lab beenden
Wenn Sie das Lab abgeschlossen haben, klicken Sie auf Lab beenden. Qwiklabs entfernt daraufhin die von Ihnen genutzten Ressourcen und bereinigt das Konto.
Anschließend erhalten Sie die Möglichkeit, das Lab zu bewerten. Wählen Sie die entsprechende Anzahl von Sternen aus, schreiben Sie einen Kommentar und klicken Sie anschließend auf Senden.
Die Anzahl der Sterne hat folgende Bedeutung:
1 Stern = Sehr unzufrieden
2 Sterne = Unzufrieden
3 Sterne = Neutral
4 Sterne = Zufrieden
5 Sterne = Sehr zufrieden
Wenn Sie kein Feedback geben möchten, können Sie das Dialogfeld einfach schließen.
Verwenden Sie für Feedback, Vorschläge oder Korrekturen den Tab Support.
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
Folgende Aufgaben haben Sie ausgeführt:
Python-Anwendung mit dem Streamlit-Framework entwickelt
Vertex AI SDK for Python installiert
Code entwickelt, um über die Vertex AI Gemini API mit dem Modell Gemini 2.0 Flash zu interagieren
Text-Prompts an das Modell gesendet, um eine Geschichte und eine Marketingkampagne zu generieren
Text, Bilder und Videos an das Modell gesendet, um Informationen aus Bildern und Videos zu verarbeiten und zu extrahieren
Anwendung in Cloud Run bereitgestellt und getestet
Labs erstellen ein Google Cloud-Projekt und Ressourcen für einen bestimmten Zeitraum
Labs haben ein Zeitlimit und keine Pausenfunktion. Wenn Sie das Lab beenden, müssen Sie von vorne beginnen.
Klicken Sie links oben auf dem Bildschirm auf Lab starten, um zu beginnen
Privates Surfen verwenden
Kopieren Sie den bereitgestellten Nutzernamen und das Passwort für das Lab
Klicken Sie im privaten Modus auf Konsole öffnen
In der Konsole anmelden
Melden Sie sich mit Ihren Lab-Anmeldedaten an. Wenn Sie andere Anmeldedaten verwenden, kann dies zu Fehlern führen oder es fallen Kosten an.
Akzeptieren Sie die Nutzungsbedingungen und überspringen Sie die Seite zur Wiederherstellung der Ressourcen
Klicken Sie erst auf Lab beenden, wenn Sie das Lab abgeschlossen haben oder es neu starten möchten. Andernfalls werden Ihre bisherige Arbeit und das Projekt gelöscht.
Diese Inhalte sind derzeit nicht verfügbar
Bei Verfügbarkeit des Labs benachrichtigen wir Sie per E-Mail
Sehr gut!
Bei Verfügbarkeit kontaktieren wir Sie per E-Mail
Es ist immer nur ein Lab möglich
Bestätigen Sie, dass Sie alle vorhandenen Labs beenden und dieses Lab starten möchten
Privates Surfen für das Lab verwenden
Nutzen Sie den privaten oder Inkognitomodus, um dieses Lab durchzuführen. So wird verhindert, dass es zu Konflikten zwischen Ihrem persönlichen Konto und dem Teilnehmerkonto kommt und zusätzliche Gebühren für Ihr persönliches Konto erhoben werden.
In diesem Lab entwickeln Sie eine Anwendung mit dem Streamlit-Framework und der Gemini API von Vertex AI und stellen sie in Cloud Run bereit.
 ).
).