GSP642


Descripción general
Hace doce años, Lily fundó la cadena de clínicas veterinarias Pet Theory, la cual se expandió rápidamente durante el último tiempo. Sin embargo, su viejo sistema de programación de citas no puede manejar el aumento de la carga. Por eso, Lily te pide que diseñes un sistema basado en la nube que se pueda escalar mejor que la solución heredada.
En el equipo de operaciones de Pet Theory trabaja una sola persona, Patrick, por lo que se necesita una solución que no requiera mucho mantenimiento continuo. El equipo decidió optar por la tecnología sin servidores.
Se contrató a Ruby como asesora para que ayude a Pet Theory a hacer la transición hacia un modelo sin servidores. Después de comparar opciones de bases de datos sin servidores, el equipo elige Cloud Firestore. Puesto que Firestore es una tecnología sin servidores, no es necesario aprovisionar capacidad por adelantado. Esto significa que no existe el riesgo de alcanzar límites de operaciones o almacenamiento. Firestore mantiene tus datos sincronizados en todas las aplicaciones de cliente a través de objetos de escucha en tiempo real. Además, ofrece soporte sin conexión destinado a aplicaciones web y para dispositivos móviles, de modo que se puede compilar una aplicación dinámica que funcione independientemente de la latencia de la red o de la conectividad a Internet.
En este lab, ayudarás a Patrick a subir los datos existentes de Pet Theory a una base de datos de Cloud Firestore. Patrick trabaja estrechamente con Ruby para lograrlo.
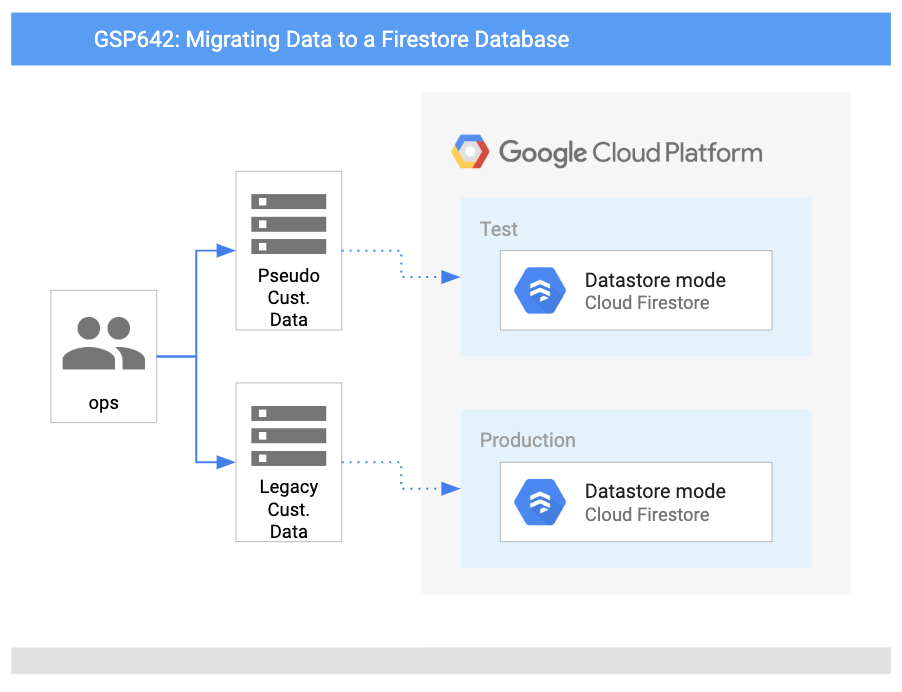
Arquitectura
En este diagrama, se muestra una descripción general de los servicios que usarás y la manera en que se conectan entre sí:
Objetivos
En este lab, aprenderás a realizar las siguientes tareas:
- Configurar Firestore en Google Cloud
- Escribir código para importar bases de datos
- Generar una colección de datos de clientes para hacer pruebas
- Importar los datos de clientes de prueba a Firestore
Requisitos previos
Este es un lab de nivel introductorio. Lo que supone que el usuario tiene conocimientos previos sobre los entornos de shell y la consola de Cloud. Será útil tener experiencia en Firebase, pero no es obligatorio.
Además, debes sentirte cómodo editando archivos. Puedes usar tu editor de texto favorito (como nano, vi, etc.) o puedes iniciar el editor de código de Cloud Shell, que se encuentra en la cinta superior:

Cuando esté todo listo, desplázate hacia abajo y sigue los pasos que se muestran a continuación para configurar el entorno de tu lab.
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs cuentan con un temporizador que no se puede pausar. El temporizador, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar. Se recomienda el navegador Chrome.
Nota: Usa una ventana del navegador privada o de incógnito (opción recomendada) para ejecutar el lab. Así evitarás conflictos entre tu cuenta personal y la cuenta de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
- Tiempo para completar el lab (recuerda que, una vez que comienzas un lab, no puedes pausarlo).
Nota: Usa solo la cuenta de estudiante para este lab. Si usas otra cuenta de Google Cloud, es posible que se apliquen cargos a esa cuenta.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá un diálogo para que selecciones la forma de pago.
A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón para abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debes usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordena las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta.
-
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}}
También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}}
También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud.
Nota: Usar tu propia cuenta de Google Cloud para este lab podría generar cargos adicionales.
-
Haz clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.
Nota: Para acceder a los productos y servicios de Google Cloud, haz clic en el menú de navegación o escribe el nombre del servicio o producto en el campo Buscar.

Activa Cloud Shell
Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
-
Haz clic en Activar Cloud Shell  en la parte superior de la consola de Google Cloud.
en la parte superior de la consola de Google Cloud.
-
Haz clic para avanzar por las siguientes ventanas:
- Continúa en la ventana de información de Cloud Shell.
- Autoriza a Cloud Shell para que use tus credenciales para realizar llamadas a la API de Google Cloud.
Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu Project_ID, . El resultado contiene una línea que declara el Project_ID para esta sesión:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
- Puedes solicitar el nombre de la cuenta activa con este comando (opcional):
gcloud auth list
- Haz clic en Autorizar.
Resultado:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Puedes solicitar el ID del proyecto con este comando (opcional):
gcloud config list project
Resultado:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Nota: Para obtener toda la documentación de gcloud, en Google Cloud, consulta la guía con la descripción general de gcloud CLI.
Tarea 1: Configura Firestore en Google Cloud
La tarea de Patrick es subir los datos existentes de Pet Theory a una base de datos de Cloud Firestore. Patrick trabajará estrechamente con Ruby para lograr este objetivo. Ruby recibe un mensaje de Patrick, de TI…
|

Patrick, administrador de TI
|
Hola Ruby:
El primer paso que debemos dar para adoptar la tecnología sin servidores es crear una base de datos de Firestore con Google Cloud. ¿Puedes ayudarme con esta tarea? No sé muy bien cómo hacerlo.
Patrick
|
|

Ruby, asesora de software
|
Hola, Patrick
Por supuesto. Será un placer ayudarte. Te enviaré algunos recursos para comenzar. Avísame cuando termines de crear la base de datos.
Ruby
|
Ayuda a Patrick a configurar una base de datos de Firestore a través de la consola de Cloud.
-
En la consola de Cloud, en el menú de navegación ( ), haz clic en Ver todos los productos y, en Bases de datos, selecciona Firestore.
), haz clic en Ver todos los productos y, en Bases de datos, selecciona Firestore.
-
Haz clic en Crear una base de datos de Firestore.
-
Selecciona Edición Standard.
-
En Opciones de configuración, selecciona Firestore nativo.
-
En Reglas de seguridad, elige Abrir.
-
En Tipo de ubicación, haz clic en Región y, luego, selecciona la región que se estableció al inicio del lab en la lista.
Nota: Si la lista de regiones no se completa, actualiza el navegador o vuelve a cargar el asistente desde el menú de la consola de Cloud.
Nota: Ambos modos son de alto rendimiento y ofrecen coherencia sólida, pero lucen diferentes y están optimizados para casos de uso distintos.
- Deja el resto de los parámetros de configuración con sus valores predeterminados y haz clic en Crear base de datos.
Cuando termina la tarea, Ruby le envía un correo electrónico a Patrick…
|
Ruby, asesora de software
|
Hola, Patrick
Configuraste muy bien la base de datos de Firestore. Para administrar el acceso a esta, usaremos una cuenta de servicio que se creó automáticamente con los privilegios necesarios.
Ya estamos listos para hacer la migración de la base de datos vieja a Firestore.
Ruby
|
|

Patrick, administrador de TI
|
Hola, Ruby
Gracias por ayudarme. Configurar la base de datos de Firestore fue sencillo.
Espero que el proceso de importar la base de datos sea más fácil que el de la base de datos heredada, que es bastante complejo y requiere muchos pasos.
Patrick
|
Tarea 2: Escribe código para importar la base de datos
La nueva base de datos de Cloud Firestore está lista pero vacía. Los datos de clientes de Pet Theory todavía existen solo en la base de datos vieja.
Patrick le envía un mensaje a Ruby…
|

Patrick, administrador de TI
|
Hola, Ruby
Mi gerente desea comenzar a migrar datos de clientes a la nueva base de datos de Firestore.
Exporté un archivo CSV de nuestra base de datos heredada, pero no sé bien cómo importar estos datos a Firestore.
¿Hay alguna posibilidad de que me ayudes?
Patrick
|
|
Ruby, asesora de software
|
Hola, Patrick
Por supuesto. Programemos una reunión para analizar los pasos que debemos dar.
Ruby
|
Tal como mencionó Patrick, los datos de clientes estarán disponibles en un archivo CSV. Ayuda a Patrick a crear una aplicación que lea los registros de clientes de un archivo CSV y los escriba en Firestore. Puesto que Patrick está familiarizado con JavaScript, compila esta aplicación con Node.js, el entorno de ejecución de JavaScript.
- En la terminal de Cloud Shell, ejecuta el siguiente comando para clonar el repositorio de Pet Theory:
git clone https://github.com/rosera/pet-theory
- Usa el editor de código de Cloud Shell (o tu editor preferido) para editar tus archivos. En la cinta superior de la sesión de Cloud Shell, haz clic en Abrir editor, el cual se abrirá en una pestaña nueva. Si se te solicita, haz clic en Abrir en una ventana nueva para iniciar el editor de código.
- Luego, cambia tu directorio de trabajo actual a
lab01:
cd pet-theory/lab01
En el directorio, puedes ver el archivo package.json de Patrick. Este archivo muestra los paquetes de los que depende tu proyecto de Node.js y hace que tu compilación se pueda reproducir, por lo que será más fácil compartirla con otros.
A continuación, se muestra un archivo package.json de ejemplo:
{
"name": "lab01",
"version": "1.0.0",
"description": "This is lab01 of the Pet Theory labs",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "Patrick - IT",
"license": "MIT",
"dependencies": {
"csv-parse": "^5.5.3"
}
}
Ahora que Patrick ya importó su código fuente, se contacta con Ruby para saber qué paquetes necesita para que la migración funcione.
|
Patrick, administrador de TI
|
Hola, Ruby
El código que usaste para la base de datos heredada es bastante básico: solo crea un archivo CSV listo para el proceso de importación. ¿Necesito descargar algo antes de comenzar?
Patrick
|
|
Ruby, asesora de software
|
Hola, Patrick
Te sugiero que uses uno de los muchos paquetes de Node de @google-cloud para interactuar con Firestore.
En ese caso, solo tendríamos que modificar un poco el código existente, puesto que ya se hizo el trabajo pesado.
Ruby
|
Para permitir que el código de Patrick escriba en la base de datos de Firestore, debes instalar algunas dependencias de par adicionales.
- Para ello, ejecuta el comando siguiente:
npm install @google-cloud/firestore
- Para permitir que la aplicación escriba registros en Cloud Logging, instala un módulo adicional:
npm install @google-cloud/logging
Cuando el comando se complete correctamente, el archivo package.json se actualizará automáticamente para incluir las nuevas dependencias de par y se verá de esta forma.
...
"dependencies": {
"@google-cloud/firestore": "^7.3.0",
"@google-cloud/logging": "^11.0.0",
"csv-parse": "^5.5.3"
}
Ahora, es el momento de observar la secuencia de comandos que lee el archivo CSV de los clientes y escribe un registro en Firestore por cada línea del archivo. A continuación, se muestra la aplicación original de Patrick:
const csv = require('csv-parse');
const fs = require('fs');
function writeToDatabase(records) {
records.forEach((record, i) => {
console.log(`ID: ${record.id} Email: ${record.email} Name: ${record.name} Phone: ${record.phone}`);
});
return ;
}
async function importCsv(csvFilename) {
const parser = csv.parse({ columns: true, delimiter: ',' }, async function (err, records) {
if (e) {
console.error('Error parsing CSV:', e);
return;
}
try {
console.log(`Call write to Firestore`);
await writeToDatabase(records);
console.log(`Wrote ${records.length} records`);
} catch (e) {
console.error(e);
process.exit(1);
}
});
await fs.createReadStream(csvFilename).pipe(parser);
}
if (process.argv.length < 3) {
console.error('Please include a path to a csv file');
process.exit(1);
}
importCsv(process.argv[2]).catch(e => console.error(e));
La aplicación toma la salida del archivo CSV de entrada y la importa a la base de datos heredada. A continuación, actualiza este código para escribir en Firestore.
- Abre el archivo
pet-theory/lab01/importTestData.js.
Para hacer referencia a la API de Firestore a través de la aplicación, debes agregar la dependencia de par a la base de código existente.
- Agrega la siguiente dependencia de Firestore en la línea 3 del archivo:
const { Firestore } = require("@google-cloud/firestore");
Asegúrate de que la parte superior del archivo sea así:
const csv = require('csv-parse');
const fs = require('fs');
const { Firestore } = require("@google-cloud/firestore"); // Add this
La integración con la base de datos de Firestore se puede realizar con algunas líneas de código. Ruby compartió contigo y con Patrick algunos códigos de plantilla justamente con ese fin.
- Agrega el siguiente código debajo de la línea 34 o después del condicional
if (process.argv.length < 3):
async function writeToFirestore(records) {
const db = new Firestore({
// projectId: projectId
});
const batch = db.batch()
records.forEach((record)=>{
console.log(`Write: ${record}`)
const docRef = db.collection("customers").doc(record.email);
batch.set(docRef, record, { merge: true })
})
batch.commit()
.then(() => {
console.log('Batch executed')
})
.catch(err => {
console.log(`Batch error: ${err}`)
})
return
}
El fragmento de código anterior declara un nuevo objeto de base de datos, que hace referencia a la base de datos que creaste antes en este lab.
La función usa un procesamiento por lotes en el que cada registro se procesa de a uno y recibe una referencia de documento según el identificador agregado.
Al final de la función, el contenido del lote se confirma (escribe) en la base de datos.
- Actualiza la función
importCsv para agregar la llamada a función a writeToFirestore y quitar la llamada a writeToDatabase. Se verá de la siguiente manera:
async function importCsv(csvFilename) {
const parser = csv.parse({ columns: true, delimiter: ',' }, async function (err, records) {
if (err) {
console.error('Error parsing CSV:', err);
return;
}
try {
console.log(`Call write to Firestore`);
await writeToFirestore(records);
// await writeToDatabase(records);
console.log(`Wrote ${records.length} records`);
} catch (e) {
console.error(e);
process.exit(1);
}
});
await fs.createReadStream(csvFilename).pipe(parser);
}
- Agrega el registro para la aplicación. Para hacer referencia a la API de Logging a través de la aplicación, agrega la dependencia de par a la base de código existente. Agrega la siguiente línea justo debajo de las otras sentencias en la parte superior del archivo:
const { Logging } = require('@google-cloud/logging');
Asegúrate de que la parte superior del archivo sea así:
const csv = require('csv-parse');
const fs = require('fs');
const { Firestore } = require("@google-cloud/firestore");
const { Logging } = require('@google-cloud/logging');
- Agrega algunas variables constantes y, luego, inicializa el cliente de Logging. Agrégalas justo debajo de las líneas anteriores en el archivo (línea 5 aprox.), de la siguiente manera:
const logName = "pet-theory-logs-importTestData";
// Creates a Logging client
const logging = new Logging();
const log = logging.log(logName);
const resource = {
type: "global",
};
- Agrega código para escribir los registros en la función
importCsv justo debajo de la línea "console.log(Wrote ${records.length} records);", que debería verse de la siguiente manera:
// A text log entry
success_message = `Success: importTestData - Wrote ${records.length} records`;
const entry = log.entry(
{ resource: resource },
{ message: `${success_message}` }
);
log.write([entry]);
Después de estas actualizaciones, tu bloque de código de la función importCsv debería verse de la siguiente manera:
async function importCsv(csvFilename) {
const parser = csv.parse({ columns: true, delimiter: ',' }, async function (err, records) {
if (err) {
console.error('Error parsing CSV:', err);
return;
}
try {
console.log(`Call write to Firestore`);
await writeToFirestore(records);
// await writeToDatabase(records);
console.log(`Wrote ${records.length} records`);
// A text log entry
success_message = `Success: importTestData - Wrote ${records.length} records`;
const entry = log.entry(
{ resource: resource },
{ message: `${success_message}` }
);
log.write([entry]);
} catch (e) {
console.error(e);
process.exit(1);
}
});
await fs.createReadStream(csvFilename).pipe(parser);
}
Ahora, cuando se ejecute el código de la aplicación, la base de datos de Firestore se actualizará con el contenido del archivo CSV. La función importCsv toma un nombre de archivo y analiza el contenido línea por línea. Cada línea procesada se envía ahora a la función de Firestore writeToFirestore, donde cada nuevo registro se escribe en la base de datos de "clientes".
Nota: En un entorno de producción, escribirás tu propia versión de la secuencia de comandos de importación.
Ayuda a que el nuevo miembro del equipo de Patrick se ponga al día
Hasta hace poco, el equipo de operaciones de Pet Theory estaba compuesto por una sola persona, Patrick. Si bien la solución de base de datos sin servidores de Cloud Firestore requiere poco mantenimiento, la jefa de Patrick, Lily, reclutó a otra persona para que lo ayude en el equipo. Lily quiere que ayudes a poner al día al nuevo miembro del equipo.
Gracias a las funciones potenciadas por IA de Gemini Code Assist, puedes aumentar la productividad y, al mismo tiempo, minimizar el cambio de contexto, ya que Gemini Code Assist proporciona acciones inteligentes potenciadas por IA directamente en tu editor de código.
Habilita Gemini Code Assist en el IDE de Cloud Shell
Puedes usar Gemini Code Assist en un entorno de desarrollo integrado (IDE) como Cloud Shell para recibir orientación sobre el código o resolver problemas con tu código. Antes de comenzar a usar Gemini Code Assist, debes habilitarlo.
- En Cloud Shell, habilita la API de Gemini for Google Cloud con el siguiente comando:
gcloud services enable cloudaicompanion.googleapis.com
- En la barra de herramientas de Cloud Shell, haz clic en Abrir editor.
Nota: Para abrir el editor de Cloud Shell, haz clic en Abrir editor en la barra de herramientas de Cloud Shell. Para cambiar entre Cloud Shell y el editor de código, haz clic en Abrir editor o Abrir terminal, según sea necesario.
-
En el panel izquierdo, haz clic en el ícono de Configuración y, luego, en la vista Configuración, busca Gemini Code Assist.
-
Busca la opción Geminicodeassist: Habilitar y asegúrate de que esté seleccionada. Luego, cierra la Configuración.
-
Haz clic en Cloud Code - Sin proyecto en la barra de estado, en la parte inferior de la pantalla.
-
Autoriza el complemento según las instrucciones. Si no se selecciona un proyecto automáticamente, haz clic en Seleccionar un proyecto de Google Cloud y elige .
-
Verifica que tu proyecto de Google Cloud () se muestre en el mensaje de la barra de estado de Cloud Code.
Decides dejar que Gemini Code Assist ayude a explicar la secuencia de comandos de Node.js importTestData.js al nuevo miembro del equipo de operaciones.
-
Con la secuencia de comandos de Node.js importTestData.js abierta en el directorio de archivos del editor de código de Cloud Shell pet-theory/lab01 y Gemini Code Assist habilitado en el IDE, observa la presencia del ícono  en la esquina superior derecha del editor.
en la esquina superior derecha del editor.
-
Haz clic en el ícono Gemini Code Assist: Smart Actions y selecciona Explicar esto.
-
Gemini Code Assist abre un panel de chat con la instrucción Explicar esto completada previamente. En el cuadro de texto intercalado del chat de Code Assist, reemplaza la instrucción completada previamente por lo siguiente y haz clic en Enviar:
Eres ingeniero de software sénior en el equipo de operaciones de la cadena de clínicas veterinarias Pet Theory. Analiza la secuencia de comandos de Node.js importTestData.js y proporciona una explicación detallada para un miembro nuevo del equipo.
1. Describe el propósito principal de la secuencia de comandos.
2. Desglosa la funcionalidad de cada una de las funciones clave: importCsv y writeToFirestore.
3. Explica cómo la secuencia de comandos maneja el archivo CSV y qué bibliotecas se usan para este proceso.
4. Detalla cómo se escriben los datos en Firestore y cómo se usa una operación por lotes.
5. Explica el propósito de la integración de Google Cloud Logging
For the suggested improvements, don't update this file.
La explicación del código en la secuencia de comandos de Node.js importTestData.js aparece en el chat de Gemini Code Assist.
Tarea 3: Crea datos de prueba
Es hora de importar algunos datos. Patrick contacta a Ruby porque tiene una duda sobre cómo ejecutar una prueba con datos de clientes reales…
|

Patrick, administrador de TI
|
Hola, Ruby
Creo que lo mejor sería no usar datos de clientes para hacer las pruebas. Debemos proteger la privacidad de los clientes, pero también debemos tener certeza de que la secuencia de comandos de importación de datos funciona correctamente.
¿Se te ocurre otra forma de hacer las pruebas?
Patrick
|
|
Ruby, asesora de software
|
Hola, Patrick
Es un buen punto. Es una situación delicada, ya que los datos de clientes pueden incluir información de identificación personal, o PII.
Compartiré algunos códigos de inicio contigo para crear datos de clientes ficticios. Luego, podemos usar esos datos para probar la secuencia de comandos de importación.
Ruby
|
Ayuda a Patrick a poner en marcha este generador de datos pseudoaleatorio.
- Primero, instala la biblioteca "faker". La secuencia de comandos que genera los datos de clientes falsos usará esa biblioteca. Ejecuta el siguiente comando para actualizar la dependencia en
package.json:
npm install faker@5.5.3
- Ahora, abre el archivo llamado createTestData.js con el editor de código y analiza el código. Asegúrate de que se vea de la siguiente manera:
const fs = require('fs');
const faker = require('faker');
function getRandomCustomerEmail(firstName, lastName) {
const provider = faker.internet.domainName();
const email = faker.internet.email(firstName, lastName, provider);
return email.toLowerCase();
}
async function createTestData(recordCount) {
const fileName = `customers_${recordCount}.csv`;
var f = fs.createWriteStream(fileName);
f.write('id,name,email,phone\n')
for (let i=0; i<recordCount; i++) {
const id = faker.datatype.number();
const firstName = faker.name.firstName();
const lastName = faker.name.lastName();
const name = `${firstName} ${lastName}`;
const email = getRandomCustomerEmail(firstName, lastName);
const phone = faker.phone.phoneNumber();
f.write(`${id},${name},${email},${phone}\n`);
}
console.log(`Created file ${fileName} containing ${recordCount} records.`);
}
recordCount = parseInt(process.argv[2]);
if (process.argv.length != 3 || recordCount < 1 || isNaN(recordCount)) {
console.error('Include the number of test data records to create. Example:');
console.error(' node createTestData.js 100');
process.exit(1);
}
createTestData(recordCount);
- Agrega Logging para la base de código. En la línea 3, agrega la siguiente referencia para el módulo de la API de Logging desde el código de la aplicación:
const { Logging } = require("@google-cloud/logging");
La parte superior del archivo debería verse de este modo:
const fs = require("fs");
const faker = require("faker");
const { Logging } = require("@google-cloud/logging"); //add this
- Ahora, agrega algunas variables constantes y, luego, inicializa el cliente de Logging. Agrégalas justo debajo de las sentencias
const:
const logName = "pet-theory-logs-createTestData";
// Creates a Logging client
const logging = new Logging();
const log = logging.log(logName);
const resource = {
// This example targets the "global" resource for simplicity
type: "global",
};
- Agrega código para escribir los registros en la función createTestData justo debajo de la línea "console.log(
Created file ${fileName} containing ${recordCount} records.);", que se verá de la siguiente manera:
// A text log entry
const success_message = `Success: createTestData - Created file ${fileName} containing ${recordCount} records.`;
const entry = log.entry(
{ resource: resource },
{
name: `${fileName}`,
recordCount: `${recordCount}`,
message: `${success_message}`,
}
);
log.write([entry]);
- Después de actualizar, el bloque de código de la función
createTestData debería verse así:
async function createTestData(recordCount) {
const fileName = `customers_${recordCount}.csv`;
var f = fs.createWriteStream(fileName);
f.write('id,name,email,phone\n')
for (let i=0; i<recordCount; i++) {
const id = faker.datatype.number();
const firstName = faker.name.firstName();
const lastName = faker.name.lastName();
const name = `${firstName} ${lastName}`;
const email = getRandomCustomerEmail(firstName, lastName);
const phone = faker.phone.phoneNumber();
f.write(`${id},${name},${email},${phone}\n`);
}
console.log(`Created file ${fileName} containing ${recordCount} records.`);
// A text log entry
const success_message = `Success: createTestData - Created file ${fileName} containing ${recordCount} records.`;
const entry = log.entry(
{ resource: resource },
{
name: `${fileName}`,
recordCount: `${recordCount}`,
message: `${success_message}`,
}
);
log.write([entry]);
}
Continuar con la capacitación del nuevo miembro del equipo
Gemini Code Assist está a tu disposición y listo para ofrecer asistencia de programación potenciada por IA cuando la necesites.
En esta sección, le pedirás a Gemini Code Assist que te ayude a explicar otra secuencia de comandos de Node.js para continuar con la capacitación de tu nuevo miembro del equipo de operaciones.
-
Con la secuencia de comandos de Node.js createTestData.js abierta en el directorio de archivos pet-theory/lab01 del editor de código de Cloud Shell, haz clic en el ícono Gemini Code Assist: Smart Actions y selecciona Explicar esto.
-
Gemini Code Assist abre un panel de chat con la instrucción Explicar esto completada previamente. En el cuadro de texto intercalado del chat de Code Assist, reemplaza la instrucción completada previamente por lo siguiente y haz clic en Enviar:
Eres ingeniero de software sénior en el equipo de operaciones de la cadena de clínicas veterinarias Pet Theory. Analiza la secuencia de comandos de Node.js createTestData.js y proporciona una explicación detallada para un nuevo miembro del equipo.
1. Describe el propósito general de la secuencia de comandos.
2. Explica el rol de la función "createTestData" y detalla cómo usa la biblioteca "faker" para generar datos.
3. Describe cómo la secuencia de comandos escribe datos en un archivo CSV
4. Explica el propósito de la integración de Google Cloud Logging y qué información se registra
5. Explica el manejo de argumentos de línea de comandos al final de la secuencia de comandos
For the suggested improvements, don't update this file.
La explicación del código en la secuencia de comandos de Node.js createTestData.js aparece en el chat de Gemini Code Assist.
- Ejecuta el siguiente comando en Cloud Shell para crear el archivo
customers_1000.csv, que incluirá 1,000 registros de datos de prueba:
node createTestData 1000
Deberías obtener un resultado similar al siguiente:
Created file customers_1000.csv containing 1000 records.
- Abre el archivo
customers_1000.csv y verifica que se hayan creado los datos de prueba.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si creaste correctamente datos de prueba de muestra para la base de datos de Firestore, verás una puntuación de evaluación.
Crear datos de prueba para la base de datos de Firestore
Tarea 4: Importa datos de clientes de prueba
- Para probar la capacidad de importación, usa la secuencia de comandos de importación y los datos de prueba que creaste antes:
node importTestData customers_1000.csv
Deberías obtener un resultado similar al siguiente:
Writing record 500
Writing record 1000
Wrote 1000 records
- Observa si obtienes un error similar al siguiente:
Error: Cannot find module 'csv-parse'
De ser así, ejecuta el siguiente comando para agregar el paquete csv-parse a tu entorno:
npm install csv-parse
- Luego, vuelve a ejecutar el comando. Deberías recibir el siguiente resultado.
Resultado:
Writing record 500
Writing record 1000
Wrote 1000 records
En las secciones anteriores, viste cómo Patrick y Ruby crearon datos de prueba y una secuencia de comandos para importar datos a Firestore.
Ahora, Patrick se siente más confiado en cuanto a la carga de datos de clientes en la base de datos de Firestore.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada.
Si importaste correctamente datos de prueba de muestra a la base de datos de Firestore, verás una puntuación de evaluación.
Importar datos de prueba a la base de datos de Firestore
Tarea 5: Inspecciona los datos en Firestore
Con un poco de ayuda de ti y de Ruby, Patrick migró correctamente los datos de prueba a la base de datos de Firestore. Abre Firestore y observa los resultados.
-
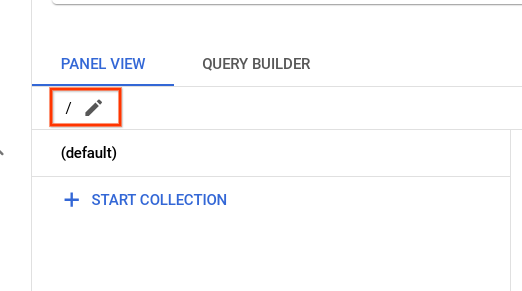
Vuelve a la pestaña de la consola de Cloud. En el menú de navegación (), haz clic en Ver todos los productos y, en Bases de datos, selecciona Firestore. Luego, haz clic en la base de datos predeterminada. Una vez allí, haz clic en el ícono de lápiz.
-
Escribe /customers y presiona Intro.
-
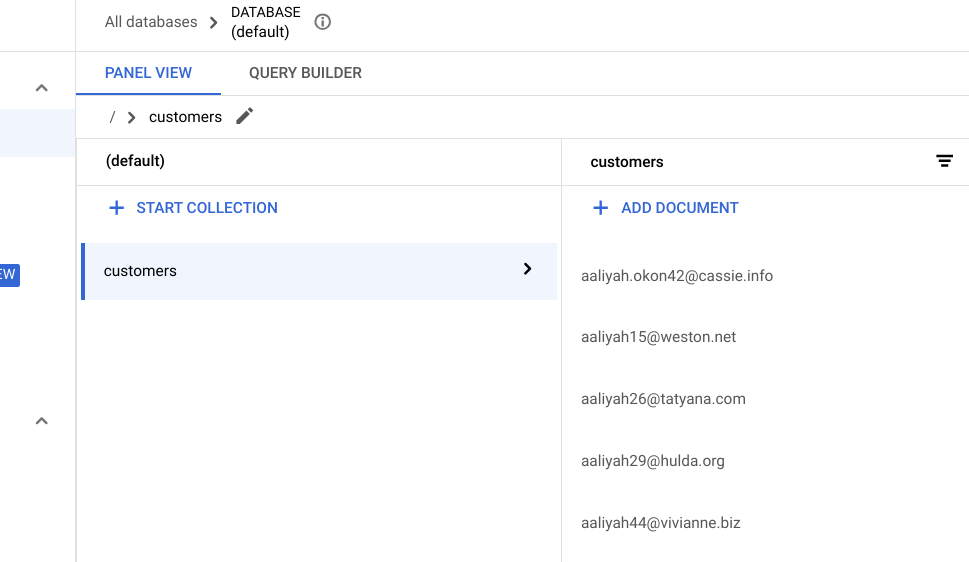
Actualiza la pestaña de tu navegador. Deberías ver que la siguiente lista de clientes se migró correctamente:
¡Felicitaciones!
En este lab, adquiriste experiencia práctica en Firestore y exploraste cómo usar Smart Actions de Gemini Code Assist directamente en el IDE. Después de generar una colección de datos de clientes para hacer pruebas, ejecutaste una secuencia de comandos que importó los datos a Firestore. Luego, aprendiste a manipular datos en Firestore desde la consola de Cloud.
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 27 de agosto de 2025
Prueba más reciente del lab: 27 de agosto de 2025
Copyright 2025 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.





