Visão geral
Neste laboratório, você vai trabalhar como um cientista de dados da Cymbal Superstore que recebeu uma solicitação para ajudar a equipe de marketing a identificar, categorizar e desenvolver novos clientes. A equipe de liderança pediu para você dividir os clientes em cinco grupos diferentes com base nos comportamentos de pedidos deles e gerar estatísticas descritivas sobre cada grupo. No entanto, você também quer oferecer a eles algumas etapas úteis para cada um dos grupos.
Para identificar esses novos clientes, você vai usar o Gemini, a Vertex AI e o BigQuery a fim de criar, exibir e resumir um modelo de clustering K-means com dados de e-commerce para gerar próximas etapas úteis para uma campanha de marketing. O laboratório é destinado a cientistas de dados com qualquer nível de experiência.
A configuração do ambiente já foi concluída. Isso inclui ativar o Cloud AI Companion para o Gemini e conceder ao IAM os papéis necessários para usar o Gemini. Para mais informações, consulte Visão geral do Gemini para o Google Cloud.
Observação: a Duet AI agora é o Gemini, nosso modelo de última geração. Este laboratório foi atualizado para refletir essa mudança. Ao seguir as instruções dele, as referências à Duet AI na interface do usuário ou na documentação devem ser tratadas como referentes ao Gemini.
Observação: como uma tecnologia em estágio inicial, o Gemini pode gerar uma saída plausível, mas que é factualmente incorreta. Recomendamos que você valide todas as saídas antes de usá-las. Para mais informações, consulte Gemini para o Google Cloud e IA responsável.
Objetivos
Neste laboratório, você vai aprender a fazer o seguinte:
- Usar notebooks Python do Colab Enterprise no BigQuery Studio.
- Usar o BigQuery DataFrames no BigQuery Studio.
- Usar o Gemini para gerar códigos com base em comandos de linguagem natural.
- Criar um modelo de clustering K-means.
- Gerar uma visualização dos clusters.
- Usar o modelo Gemini Pro para desenvolver as próximas etapas de uma campanha de marketing.
- Limpar os recursos do projeto.
Configuração e requisitos
Antes de clicar no botão "Começar o laboratório"
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório – não se esqueça: depois de começar, não será possível pausar o laboratório.
Observação: não use seu projeto nem sua conta pessoal do Google Cloud neste laboratório para evitar cobranças extras.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento.
No painel Detalhes do laboratório à esquerda, você vai encontrar o seguinte:
- O botão Abrir console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Nome de usuário"}}}
Você também encontra o Nome de usuário no painel Detalhes do laboratório.
-
Clique em Avançar.
-
Copie a Senha abaixo e cole na caixa de diálogo de boas-vindas.
{{{user_0.password | "Senha"}}}
Você também encontra a Senha no painel Detalhes do laboratório.
-
Clique em Avançar.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes sem custo financeiro.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: clique no menu de navegação no canto superior esquerdo para acessar uma lista de produtos e serviços do Google Cloud.

Tarefa 1: criar um conjunto de dados do BigQuery para o projeto
Nesta tarefa, você vai criar o conjunto de dados de e-commerce no BigQuery. Esse conjunto de dados é usado para armazenar os dados de e-commerce que você vai categorizar neste laboratório.
-
No console do Google Cloud, selecione o menu de navegação ( ) e clique em BigQuery.
) e clique em BigQuery.
O pop-up Olá! Este é o BigQuery no console do Cloud.
-
Clique em Concluído.
-
No painel Explorador, para , selecione Ver ações ( ) e selecione Criar conjunto de dados.
) e selecione Criar conjunto de dados.
Ao criar um conjunto de dados, você armazena objetos do banco de dados, incluindo tabelas e modelos.
-
No painel Criar conjunto de dados, digite as seguintes informações:
| Campo |
Valor |
| ID do conjunto de dados |
E-commerce |
| Tipo de local |
Selecione Multirregional. |
| Multirregional |
Selecione EUA (várias regiões nos Estados Unidos). |
Deixe os demais campos com os valores padrão.
-
Clique em Criar conjunto de dados.
Para verificar o objetivo, clique em Verificar meu progresso.
Criar um conjunto de dados do BigQuery para o projeto.
Tarefa 2: criar um notebook Python
Nesta tarefa, você vai criar um notebook Python no BigQuery para poder usar o Gemini no BigQuery. O notebook Python é necessário no BigQuery a fim de usar as bibliotecas de machine learning Python para identificar clientes e categorizá-los em grupos, com base nos dados de compras no conjunto de dados de e-commerce.
-
No console do Google Cloud, selecione o menu de navegação () e clique em BigQuery.
-
Na parte superior da página, clique na seta para baixo ao lado do sinal de mais.
-
Selecione Notebook > Notebook vazio.
-
Selecione a região para armazenar os ativos de código do menu suspenso e clique em Selecionar.
-
No painel Começar com um modelo, clique em Fechar.
Tarefa 3: conectar-se ao ambiente de execução do Colab Enterprise no BigQuery
A próxima etapa é conectar-se ao ambiente de execução do Colab Enterprise no BigQuery. Pense nesse ambiente de execução como um ambiente gerenciado no BigQuery que permite que você acesse bibliotecas de machine learning que podem ajudar a identificar os clientes e categorizá-los em grupos.
-
Ainda no console do BigQuery Studio, no canto superior direito do notebook, clique na seta para baixo ao lado de Conectar-se.
-
No menu suspenso, selecione Conectar-se a um ambiente de execução.
-
Selecione Criar novo ambiente de execução.
-
Selecione Criar ambiente de execução padrão.
-
Clique no ID do estudante do Qwiklabs.
Observação: aguarde alguns minutos enquanto o ambiente de execução é alocado. Em seguida, o status da conexão será atualizado para Conectado na parte inferior da janela do navegador. O notebook Python também é adicionado à seção de notebooks do explorador no projeto.
Para verificar o objetivo, clique em Verificar meu progresso.
Conectar-se ao ambiente de execução do Colab Enterprise no BigQuery.
Tarefa 4: criar o notebook Python
Nesta tarefa, você vai seguir estas etapas para começar a criar o notebook Python:
- Importar bibliotecas Python
- Definir variáveis
- Criar e importar uma tabela base como um pacote BigQuery DataFrames de um conjunto de dados público
- Gerar o modelo de clustering K-means e a visualização
Importar bibliotecas Python e definir variáveis
A primeira etapa para criar o notebook Python é importar bibliotecas Python e definir variáveis.
Para importar as bibliotecas para o notebook, siga estas etapas:
-
Adicione uma célula de código ao notebook e clique no botão + Código na parte superior da janela do notebook.
-
Cole o seguinte snippet de código na célula:
from google.cloud import bigquery
from google.cloud import aiplatform
import bigframes.pandas as bpd
import pandas as pd
from vertexai.language_models._language_models import TextGenerationModel
from vertexai.generative_models import GenerativeModel
from bigframes.ml.cluster import KMeans
from bigframes.ml.model_selection import train_test_split
-
Execute  a célula.
a célula.
O ambiente de execução vai carregar as bibliotecas Python, o que pode levar até um minuto. Você pode acompanhar o progresso verificando o status do ambiente de execução na parte inferior da janela do navegador.
Ao final, uma marca de seleção verde  será exibida na célula ao lado do botão Executar.
será exibida na célula ao lado do botão Executar.
A tabela abaixo fornece mais informações sobre as bibliotecas Python que você acabou de importar para o notebook, incluindo uma breve descrição sobre cada uma.
| Biblioteca |
Descrição |
| BigQuery |
Cliente Python para o Google BigQuery |
| AI Platform |
SDK da Vertex AI para Python |
| bigframes.pandas |
BigQuery DataFrames |
| Pandas |
Ferramenta de análise e manipulação de dados de código aberto, criada com base na linguagem de programação Python. |
| TextGenerationModel |
Cria um LanguageModel na Vertex AI. |
| K-means |
Usado para criar modelos de clustering K-means no BigQuery DataFrames. |
| train_test_split |
Usado para dividir o conjunto de dados de origem em subconjuntos de teste e treinamento, além de ser usado com o ajuste de modelo no BigQuery DataFrames. |
Observação: para saber mais sobre cada biblioteca, acesse o link fornecido.
Definir as variáveis e iniciar a conexão do BigQuery com a Vertex AI
Agora você vai definir as variáveis e iniciar a conexão do BigQuery com a Vertex AI.
-
Adicione outra célula de código no final do notebook.
-
Cole o snippet de código a seguir na célula.
project_id = '<project_id>'
dataset_name = "ecommerce"
model_name = "customer_segmentation_model"
table_name = "customer_stats"
location = "<location>"
client = bigquery.Client(project=project_id)
aiplatform.init(project=project_id, location=location)
-
Substitua <project_id> por .
-
Substitua <location> por .
-
Execute a célula.
Criar e importar a tabela ecommerce.customer_stats
Em seguida, você vai armazenar dados do conjunto de dados público look_ecommerce do BigQuery em uma nova tabela chamada customer_status no conjunto de dados de e-commerce.
-
Adicione outra célula de código no final do notebook.
-
Cole o snippet de código a seguir na célula.
%%bigquery
CREATE OR REPLACE TABLE ecommerce.customer_stats AS
SELECT
user_id,
DATE_DIFF(CURRENT_DATE(), CAST(MAX(order_created_date) AS DATE), day) AS days_since_last_order, ---RECENCY
COUNT(order_id) AS count_orders, --FREQUENCY
AVG(sale_price) AS average_spend --MONETARY
FROM (
SELECT
user_id,
order_id,
sale_price,
created_at AS order_created_date
FROM `bigquery-public-data.thelook_ecommerce.order_items`
WHERE
created_at
BETWEEN '2022-01-01' AND '2023-01-01'
)
GROUP BY user_id;
-
Execute a célula.
Criar um pacote BigQuery Dataframes e carregar os dados usando um comando do Gemini
Nesta etapa, você vai criar um pacote BigQuery DataFrames usando um comando do Gemini e carregar os dados de estatísticas do cliente nele, para processá-los mais tarde com o modelo de clustering K-means.
Observação: como mencionado no início do laboratório, é necessário validar todas as respostas do Gemini antes de usar. Use os exemplos de código fornecidos para ajudar, mas não copie e cole o código exatamente como está, porque pode ser que não funcione em alguns casos. Também é possível gerar novamente o código do Gemini para gerar um resultado melhor.
-
Adicione outra célula de código no final do notebook.
-
Dentro dela, clique em Gerar. Com isso, é possível gerar o código com o Gemini, e um comando é exibido para que você possa adicionar textos.
-
Cole o texto a seguir no comando.
Converta a tabela ecommerce.customer_stats em um DataFrame Bigframes e exiba os 10 primeiros registros
-
Clique em Gerar. O Gemini vai gerar o código abaixo.
bqdf = client.read_gbq(f"{project_id}.{dataset_name}.{table_name}")
df.head(10)
Observação: lembre-se de que em uma etapa anterior, você adicionou um código à célula número 2 do notebook que salvou o ID do projeto, o nome do conjunto de dados e o nome da tabela como variáveis. Se essa etapa foi realizada corretamente, você não terá problemas em executar a célula na etapa a seguir, e o DataFrame será criado exibindo as primeiras 10 linhas.
-
Gere o código novamente para que o resultado seja semelhante ao código mostrado aqui:
bqdf = bpd.read_gbq(f"{project_id}.{dataset_name}.{table_name}")
bqdf.head(10)
-
Execute a célula.
A resposta do BigQuery DataFrames será exibida com as primeiras 10 linhas do conjunto de dados.
Gerar o modelo de clustering K-means
Agora que você tem os dados dos clientes em um BigQuery DataFrames, vai criar um modelo de clustering K-means para dividir esses dados em clusters com base em campos como recência, contagem de pedidos e gastos, e poderá visualizá-los como grupos em um gráfico diretamente no notebook.
-
Adicione outra célula de código no final do notebook.
-
Clique em Gerar na célula. Com isso, é possível gerar códigos com o Gemini usando um comando.
-
Adicione este comando à célula:
1. Dividir df (usando um estado aleatório e a proporção de 0,2) entre dados de teste e de treinamento para um algoritmo de clustering K-means e guardá-los como df_test e df_train. 2. Criar um modelo de cluster K-means usando bigframes.ml.cluster KMeans com 5 clusters. 3. Salvar o modelo usando o método to_gbq em que o nome do modelo seja project_id.dataset_name.model_name.
-
Clique em Gerar. Você verá um resultado semelhante a este:
#comando: 1. Dividir df (usando um estado aleatório e a proporção de 0,2) entre dados de teste e de treinamento para um algoritmo de clustering K-means e guardá-los como df_test e df_train. 2. Criar um modelo de cluster K-means usando bigframes.ml.cluster KMeans com 5 clusters. 3. Salvar o modelo usando o método to_gbq em que o nome do modelo seja project_id.dataset_name.model_name.
df_train, df_test = train_test_split(bq_df, test_size=0.2, random_state = 42)
kmeans = KMeans(n_clusters=5)
kmeans.fit(df_train)
kmeans.to_gbq(f"{project_id}.{dataset_name}.{model_name}")
-
Execute a célula.
Observação: essa etapa demora cerca de dois minutos para ser concluída.
O modelo foi criado.
-
Atualize o conteúdo do painel Explorador clicando nos três pontos ao lado do nome do projeto e selecionando Atualizar conteúdo. Isso deve ser exibido no conjunto de dados de e-commerce.
Em seguida, você vai definir um novo BigQuery DataFrames que mescle o segmento/cluster produzido pelo modelo K-means novamente com os dados originais.
-
Adicione outra célula de código no final do notebook.
-
Clique em Gerar na célula.
Com isso, é possível gerar códigos com o Gemini usando um comando.
-
Adicione este comando à célula:
1. Chamar o modelo de previsão K-means no DataFrame df, armazenar os resultados como predictions_df e exibir os 10 primeiros registros.
-
Clique em Gerar. Você verá um resultado semelhante a este:
#comando: 1. Chamar o modelo de previsão K-means no DataFrame df, armazenar os resultados como predictions_df e exibir os 10 primeiros registros.
predictions_df = kmeans.predict(df_test)
predictions_df.head(10)
-
Execute a célula.
Observe que os primeiros 10 registros são mostrados com o CENTROID_ID. CENTROID_ID é o cluster em que os clientes serão categorizados mais tarde no laboratório. Também é possível observar os campos user_id, days_since_last_order, count_orders e average_spend.
Para verificar o objetivo, clique em Verificar meu progresso.
Gerar o modelo de clustering K-means.
Criar uma visualização dos resultados do modelo de clustering K-means
Nesta etapa, você vai criar uma visualização dos resultados do modelo de clustering K-means. Em específico, você vai gerar um gráfico de dispersão usando predictions_df para observar a relação entre os dias desde o último pedido por gasto médio, em que a cor está de acordo com o segment_id (que foi gerado usando o modelo K-means).
-
Adicione outra célula de código no final do notebook.
-
Clique em Gerar na célula.
Com isso, é possível gerar códigos com o Gemini usando um comando.
-
Adicione este comando à célula:
1. Usando predictions_df e matplotlib, gere um gráfico de dispersão. 2. No eixo-x desse gráfico, exibir days_since_last_order e no eixo-y, exibir average_spend from predictions_df. 3. Usar uma cor por cluster. 4. O gráfico deve ter o título "Atributo agrupado por cluster K-means."
-
Clique em Gerar.
Você verá um resultado semelhante a este:
#comando: 1. Usando predictions_df e matplotlib, gere um gráfico de dispersão. 2. No eixo-x desse gráfico, exibir days_since_last_order e no eixo-y, exibir average_spend from predictions_df. 3. Usar uma cor por cluster. 4. O gráfico deve ter o título "Atributo agrupado por cluster K-means."
import matplotlib.pyplot as plt
# Criar o gráfico de dispersão
plt.figure(figsize=(10, 6)) # Ajuste o tamanho da figura conforme necessário
plt.scatter(predictions_df['days_since_last_order'], predictions_df['average_spend'], c=predictions_df['cluster'], cmap='viridis')
# Personalizar o gráfico
plt.title('Atributo agrupado por cluster K-means')
plt.xlabel('Dias desde o último pedido')
plt.ylabel('Gasto médio')
plt.colorbar(label='ID do cluster')
# Exibir o gráfico
plt.show()
-
Substitua "cluster" ou "cluster_id" por "CENTROID_ID" apenas no campo c=predictions_df.
-
Execute a célula.
A visualização será exibida.
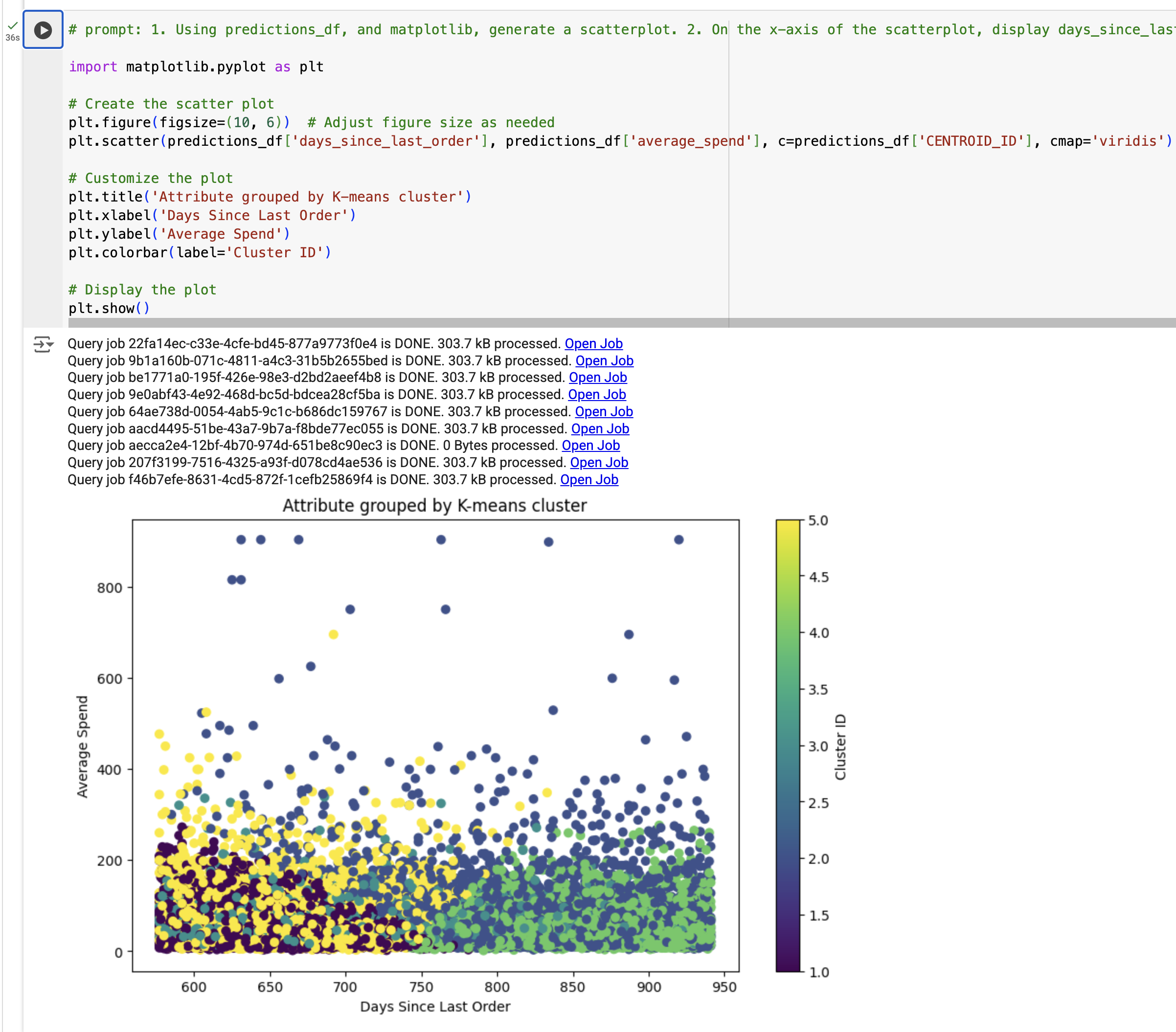
Observação: se você receber um TypeError, substitua o código pela saída de exemplo e execute a célula.
Para verificar o objetivo, clique em Verificar meu progresso.
Gerar a visualização com base nos resultados do modelo de clustering K-means.
Tarefa 5: gerar insights com base nos resultados do modelo
Nesta tarefa, você vai seguir estas etapas para gerar insights com base nos resultados do modelo:
- Resumir cada cluster gerado com base no modelo K-means
- Definir um comando para a campanha de marketing
- Gerar a campanha de marketing usando o Gemini
Resumir cada cluster gerado com base no modelo K-means
Nesta etapa, você vai resumir cada cluster gerado com base no modelo K-means.
-
Adicione outra célula de código no final do notebook.
-
Cole o seguinte snippet de código na célula:
query = """
SELECT
CONCAT('cluster ', CAST(centroid_id as STRING)) as centroid,
average_spend,
count_orders,
days_since_last_order
FROM (
SELECT centroid_id, feature, ROUND(numerical_value, 2) as value
FROM ML.CENTROIDS(MODEL `{0}.{1}`)
)
PIVOT (
SUM(value)
FOR feature IN ('average_spend', 'count_orders', 'days_since_last_order')
)
ORDER BY centroid_id
""".format(dataset_name, model_name)
df_centroid = client.query(query).to_dataframe()
df_centroid.head()
-
Execute a célula.
Os clusters serão resumidos em uma tabela. Nessa tabela, é possível acessar alguns insights que descrevem que alguns clusters têm um gasto médio maior e outros têm uma contagem maior de pedidos.
Em seguida, você vai converter o DataFrame em uma string, para transmiti-lo à chamada do modelo de linguagem grande.
-
Adicione outra célula de código no final do notebook.
-
Cole o seguinte snippet de código na célula:
df_query = client.query(query).to_dataframe()
df_query.to_string(header=False, index=False)
cluster_info = []
for i, row in df_query.iterrows():
cluster_info.append("{0}, average spend ${2}, count of orders per person {1}, days since last order {3}"
.format(row["centroid"], row["count_orders"], row["average_spend"], row["days_since_last_order"]) )
cluster_info = (str.join("\n", cluster_info))
print(cluster_info)
-
Execute a célula.
O resultado será semelhante a este:
cluster 1, gasto médio US$ 48,32, número de pedidos por pessoa 1,36, dias desde o último pedido 384,37
cluster 2, gasto médio US$ 202,34, número de pedidos por pessoa 1,3, dias desde o último pedido 482,62
cluster 3, gasto médio US$ 45,68, número de pedidos por pessoa 1,36, dias desde o último pedido 585,4
cluster 4, gasto médio US$ 44,71, número de pedidos por pessoa 1,36, dias desde o último pedido 466,26
cluster 5, gasto médio US$ 58,08, número de pedidos por pessoa 3,92, dias desde o último pedido 427,36
Gerar a campanha de marketing usando o modelo Gemini
Você criou um modelo K-means, atribuiu cada cliente a um cluster do modelo e gerou estatísticas de resumo para cada cluster. Nesta etapa, você vai usar o Gemini para gerar código a partir de um comando para criar uma campanha de marketing, com insights do cliente e próximas etapas para nossa equipe de marketing.
Para cada cluster/segmento definido pelo modelo K-means, você vai gerar três itens que podem ser usados pela equipe de marketing:
- Título
- Persona
- Próxima etapa de marketing
-
Adicione outra célula de código no final do notebook.
-
Cole o seguinte snippet de código na célula:
model = GenerativeModel("gemini-2.5-pro")
prompt = f"""
Você é um estrategista de marca com abordagem criativa. Com base nos clusters a seguir, crie \
uma persona de marca criativa, um título chamativo e a próxima ação de marketing. \
Explique tudo de maneira detalhada. Identifique o número do cluster, o cargo da pessoa, uma persona para ela e a próxima etapa de marketing.
Clusters:
{cluster_info}
Para cada cluster:
* Título:
* Persona:
* Próxima etapa de marketing:
"""
responses = model.generate_content(
prompt,
generation_config={
"temperature": 0.1,
"max_output_tokens": 4000,
"top_p": 1.0,
"top_k": 40,
}
)
print(responses.text)
-
Execute a célula.
Você vai ver cada cluster com o título, a persona e as próximas etapas.
**Cluster 1:**
* **Título:** Os fiéis inativos
* **Persona:** Esses clientes já fizeram uma compra no passado, mas não retornaram por um longo período. Eles provavelmente tiveram uma experiência positiva, mas não interagiram recentemente.
* **Próxima etapa de marketing:**
1. **Campanha de reengajamento**: envie e-mails personalizados ou anúncios segmentados lembrando os clientes da compra anterior e destacando novos produtos ou promoções que possam interessar a eles.
2. **Ofereça descontos ou incentivos exclusivos**: motive os usuários a voltar com ofertas especiais ou recompensas de fidelidade.
3. **Recomendações personalizadas de produtos**: use o histórico de compras e o comportamento de navegação para sugerir produtos relevantes que possam interessar aos clientes.
**Cluster 2:**
* **Título:** Os compradores ocasionais
* **Persona:** esses clientes fazem compras com pouca frequência, mas gastam mais quando compram. Eles provavelmente consideram a marca uma opção premium para ocasiões especiais.
* **Próxima etapa de marketing:**
1. **Destaque a exclusividade e o valor premium**: enfatize os recursos e benefícios exclusivos dos seus produtos para justificar o preço mais alto.
2. **Ofereça promoções ou pacotes por tempo limitado**: incentive compras maiores com ofertas especiais em itens de alto valor ou conjuntos de produtos selecionados.
3. **Crie um senso de urgência e escassez**: faça a promoção de produtos de edição limitada ou ofertas relâmpago para incentivar a ação imediata.
**Cluster 3:**
* **Título:** Compradores únicos
* **Persona:** esses clientes fizeram apenas uma compra e não voltaram. Talvez a experiência tenha sido neutra ou eles não tenham encontrado um motivo para voltar.
* **Próxima etapa de marketing:**
1. **Colete feedback**: envie pesquisas pós-compra para entender a experiência dos clientes e identificar áreas de melhoria.
2. **Ofereça recomendações personalizadas**: com base na compra inicial deles, sugira produtos ou acessórios complementares para incentivar mais engajamento.
3. **Mostre depoimentos de clientes e provas sociais**: destaque avaliações positivas e conteúdo gerado pelo usuário para criar confiança e incentivar compras repetidas.
**Cluster 4:**
* **Título**: Os grandes gastadores
* **Persona**: esses clientes gastam muito mais do que os outros e provavelmente são seu segmento mais fiel e valioso. Eles apreciam produtos de alta qualidade e experiências personalizadas.
* **Próxima etapa de marketing:**
1. **Desenvolva um programa VIP**: ofereça benefícios exclusivos, acesso antecipado a novos produtos e atendimento personalizado para mostrar seu apreço e incentivar a fidelidade contínua.
2. **Comunicação e ofertas personalizadas**: adapte suas mensagens de marketing e promoções aos interesses e ao histórico de compras específicos deles.
3. **Promova eventos ou experiências exclusivas**: crie oportunidades para que eles se conectem com a marca e outros clientes de alto valor.
**Cluster 5:**
* **Título:** Os consumidores conscientes de preço
* **Persona:** esses clientes são movidos principalmente pelo preço e fazem compras pouco frequentes e de baixo valor. É provável que eles comparem preços e busquem as melhores ofertas.
* **Próxima etapa de marketing:**
1. **Promova preços competitivos e ofertas baseadas em valor**: destaque seus preços competitivos e ofertas de pacotes para atrair clientes sensíveis a preços.
2. **Ofereça frete grátis ou outros incentivos**: reduza as barreiras à compra oferecendo frete grátis ou outros incentivos atraentes.
3. **Foque nos benefícios do produto e no custo-benefício**: destaque a qualidade e a funcionalidade dos seus produtos para justificar o preço.
Para verificar o objetivo, clique em Verificar meu progresso.
Gerar a campanha de marketing usando o Gemini.
Tarefa 6: limpar os recursos do projeto (opcional)
Neste laboratório, você criou recursos usando o console do Google Cloud. Em um ambiente de produção, você vai precisar remover esses recursos da conta, porque eles não serão mais necessários quando os insights do modelo forem coletados. Você tem duas opções para remover os recursos da conta e evitar cobranças adicionais pelo uso deles:
- Remover o projeto (confira os avisos abaixo)
- Remover os recursos individuais
Limpar os recursos removendo o projeto
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste tutorial, exclua o projeto do Google Cloud criado relacionado a este tutorial.
Cuidado! Excluir um projeto tem os seguintes efeitos:
- Tudo no projeto é excluído. Se você tiver usado um projeto atual para as tarefas neste documento, a exclusão dele incluirá a exclusão de quaisquer outros trabalhos feitos nele.
- Os IDs do projeto personalizados são perdidos. Ao criar o projeto, você pode ter criado um ID do projeto personalizado para ser usado no futuro. Para preservar os URLs que usam o ID do projeto, como um URL appspot.com, exclua recursos específicos do projeto, em vez de excluir o projeto inteiro.
Se você planeja explorar várias arquiteturas, tutoriais e guias de início rápido, a reutilização de projetos pode evitar que você exceda limites da cota.
-
No console do Google Cloud, acesse a página IAM e administrador > Gerenciar recursos.
-
Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
-
Na caixa de diálogo, digite o ID do projeto e clique em Encerrar mesmo assim para excluí-lo.
Limpar os recursos excluindo-os de modo individual
Para não incorrer em cobranças, você pode excluir a tabela e o modelo usados neste laboratório executando o seguinte código em uma nova célula de código no notebook:
# Excluir a tabela customer_stats
client.delete_table(f"{project_id}.{dataset_name}.{table_name}", not_found_ok=True)
print(f"Tabela excluída: {project_id}.{dataset_name}.{table_name}")
# Excluir o modelo K-means
client.delete_model(f"{project_id}.{dataset_name}.{model_name}", not_found_ok=True)
print(f"Modelo excluído: {project_id}.{dataset_name}.{model_name}")
Depois de executar a célula, é possível atualizar o conteúdo do projeto no BigQuery Studio para conferir se a tabela e o modelo foram excluídos.
Parabéns!
Neste laboratório, você aprendeu a executar as seguintes tarefas:
- Usar notebooks Python do Colab Enterprise no BigQuery Studio.
- Usar o BigQuery DataFrames no BigQuery Studio.
- Usar o Gemini para gerar códigos com base em comandos de linguagem natural.
- Criar um modelo de clustering K-means.
- Gerar visualizações dos clusters.
- Usar o Gemini para desenvolver as próximas etapas de uma campanha de marketing.
Leitura opcional
Agora que você identificou, categorizou e ajudou a desenvolver clientes para a Cymbal Superstore usando o Gemini, a Vertex AI e o BigQuery, confira os links abaixo para saber mais sobre o Gemini:
Finalize o laboratório
Após terminar seu laboratório, clique em End Lab. O Qwiklabs removerá os recursos usados e limpará a conta para você.
Você poderá avaliar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Submit.
O número de estrelas indica o seguinte:
- 1 estrela = muito insatisfeito
- 2 estrelas = insatisfeito
- 3 estrelas = neutro
- 4 estrelas = satisfeito
- 5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Support.
Manual atualizado em 3 de setembro de 2025
Laboratório testado em 03 de setembro de 2025
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.





