개요
이 실습에서는 Cymbal Superstore라는 업체의 데이터 과학자가 되어 요청에 따라 마케팅팀을 도와 신규 고객을 식별, 분류, 개발해 봅니다. 경영진은 고객을 주문 행동에 따라 5개 그룹으로 나누고 그룹별로 설명 통계를 생성해 달라고 요청했습니다. 하지만 여러분은 이러한 각 그룹에 대해 몇 가지 실행 가능한 다음 단계도 제공하고자 합니다.
이러한 신규 고객을 식별하려면 Gemini, Vertex AI, BigQuery를 사용하여 전자상거래 데이터로 k-평균 클러스터링 모델을 생성, 시각화, 요약하여 마케팅 캠페인에 도움이 되는 다음 단계를 구축해야 합니다. 이 실습은 경험 수준과 상관없이 모든 데이터 과학자를 대상으로 합니다.
환경 구성이 이미 완료되었습니다. 여기에는 Gemini용 Cloud AI Companion을 사용 설정하고 Gemini를 사용하는 데 필요한 역할을 IAM에 부여하는 작업이 포함됩니다. 자세한 내용은 Google Cloud를 위한 Gemini 개요를 참조하세요.
참고: Duet AI의 이름이 Google의 차세대 모델인 Gemini로 변경되었습니다. 이 같은 변경사항을 반영하도록 실습을 업데이트했습니다. 실습 안내를 따르는 동안 사용자 인터페이스 또는 문서에 Duet AI가 언급되면 이를 Gemini와 동일하게 취급하세요.
참고: Gemini는 아직 초기 단계의 기술로, 그럴듯해 보이지만 실제로는 잘못된 출력을 생성할 수 있습니다. Gemini의 모든 출력을 사용 전에 미리 검사하는 것이 좋습니다. 자세한 내용은 Google Cloud를 위한 Gemini와 책임감 있는 AI를 참조하세요.
목표
이 실습에서는 다음 작업을 수행하는 방법을 알아봅니다.
- BigQuery Studio 내에서 Colab Enterprise Python 노트북 사용하기
- BigQuery Studio 내에서 BigQuery DataFrames 사용하기
- Gemini를 사용하여 자연어 프롬프트에서 코드 생성하기
- k-평균 클러스터링 모델 빌드하기
- 클러스터 시각화 생성하기
- Gemini Pro 모델을 사용하여 마케팅 캠페인의 다음 단계 개발하기
- 프로젝트 리소스 정리하기
설정 및 요건
실습 시작 버튼을 클릭하기 전에
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지를 표시합니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 직접 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
- 표준 인터넷 브라우저 액세스 권한(Chrome 브라우저 권장)
참고: 이 실습을 실행하려면 시크릿 모드 또는 시크릿 브라우저 창을 사용하세요. 개인 계정과 학습자 계정 간의 충돌로 개인 계정에 추가 요금이 발생하는 일을 방지해 줍니다.
- 실습을 완료하기에 충분한 시간. 실습을 시작하고 나면 일시중지할 수 없습니다.
참고: 계정에 추가 요금이 발생하지 않도록 하려면 개인용 Google Cloud 계정이나 프로젝트가 이미 있어도 이 실습에서는 사용하지 마세요.
실습을 시작하고 Google Cloud 콘솔에 로그인하는 방법
-
실습 시작 버튼을 클릭합니다. 실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 팝업이 열립니다.
왼쪽에는 다음과 같은 항목이 포함된 실습 세부정보 패널이 있습니다.
-
Google Cloud 콘솔 열기 버튼
- 남은 시간
- 이 실습에 사용해야 하는 임시 사용자 인증 정보
- 필요한 경우 실습 진행을 위한 기타 정보
-
Google Cloud 콘솔 열기를 클릭합니다(Chrome 브라우저를 실행 중인 경우 마우스 오른쪽 버튼으로 클릭하고 시크릿 창에서 링크 열기를 선택합니다).
실습에서 리소스가 가동되면 다른 탭이 열리고 로그인 페이지가 표시됩니다.
팁: 두 개의 탭을 각각 별도의 창으로 나란히 정렬하세요.
참고: 계정 선택 대화상자가 표시되면 다른 계정 사용을 클릭합니다.
-
필요한 경우 아래의 사용자 이름을 복사하여 로그인 대화상자에 붙여넣습니다.
{{{user_0.username | "Username"}}}
실습 세부정보 패널에서도 사용자 이름을 확인할 수 있습니다.
-
다음을 클릭합니다.
-
아래의 비밀번호를 복사하여 시작하기 대화상자에 붙여넣습니다.
{{{user_0.password | "Password"}}}
실습 세부정보 패널에서도 비밀번호를 확인할 수 있습니다.
-
다음을 클릭합니다.
중요: 실습에서 제공하는 사용자 인증 정보를 사용해야 합니다. Google Cloud 계정 사용자 인증 정보를 사용하지 마세요.
참고: 이 실습에 자신의 Google Cloud 계정을 사용하면 추가 요금이 발생할 수 있습니다.
-
이후에 표시되는 페이지를 클릭하여 넘깁니다.
- 이용약관에 동의하세요.
- 임시 계정이므로 복구 옵션이나 2단계 인증을 추가하지 마세요.
- 무료 체험판을 신청하지 마세요.
잠시 후 Google Cloud 콘솔이 이 탭에서 열립니다.
참고: Google Cloud 제품 및 서비스 목록이 있는 메뉴를 보려면 왼쪽 상단의 탐색 메뉴를 클릭합니다.

작업 1. 프로젝트를 위한 BigQuery 데이터 세트 생성
이 작업에서는 BigQuery에서 전자상거래 데이터 세트를 생성합니다. 데이터 세트는 이 실습에서 분류할 전자상거래 데이터를 저장하는 데 사용합니다.
-
Google Cloud 콘솔에서 탐색 메뉴( )를 선택한 다음 BigQuery를 선택합니다.
)를 선택한 다음 BigQuery를 선택합니다.
'Cloud 콘솔의 BigQuery에 오신 것을 환영합니다'라는 팝업이 표시됩니다.
-
완료를 클릭합니다.
-
탐색기 패널의 에서 작업 보기( )를 선택한 다음 데이터 세트 만들기를 선택합니다.
)를 선택한 다음 데이터 세트 만들기를 선택합니다.
테이블과 모델을 비롯한 데이터베이스 객체를 저장할 데이터 세트를 생성합니다.
-
데이터 세트 만들기 창에 다음 정보를 입력합니다.
| 필드 |
값 |
| 데이터 세트 ID |
전자상거래 |
| 위치 유형 |
멀티 리전 선택 |
| 멀티 리전 |
US(미국 내 여러 리전) 선택 |
다른 필드는 기본값을 유지합니다.
-
데이터 세트 만들기를 클릭합니다.
목표를 확인하려면 내 진행 상황 확인하기를 클릭합니다.
프로젝트를 위한 BigQuery 데이터 세트 생성
작업 2. 새 Python 노트북 만들기
이 작업에서는 BigQuery의 Gemini를 사용할 수 있도록 BigQuery에 새 Python 노트북을 만듭니다. Python 노트북이 BigQuery에 필요한 이유는 Python 머신러닝 라이브러리를 사용하여 전자상거래 데이터 세트의 쇼핑 데이터를 기반으로 고객을 식별하고 그룹으로 분류할 수 있기 때문입니다.
-
Google Cloud 콘솔에서 탐색 메뉴()를 선택한 다음 BigQuery를 선택합니다.
-
페이지 상단에서 더하기 기호 옆의 드롭다운 화살표를 클릭합니다.
-
노트북 > 빈 노트북을 선택합니다.
-
드롭다운에서 코드 애셋을 저장할 리전()을 선택하고 선택을 클릭합니다.
-
템플릿으로 시작 창에서 닫기를 클릭합니다.
작업 3. BigQuery의 Colab Enterprise 런타임에 연결
다음 단계는 BigQuery의 Colab Enterprise 런타임에 연결하는 것입니다. 이 런타임은 머신러닝 라이브러리에 액세스하여 고객을 식별하고 그룹으로 분류하는 데 도움이 되는 BigQuery의 관리형 환경이라고 볼 수 있습니다.
-
BigQuery Studio 콘솔 내에서 노트북의 오른쪽 상단에 있는 연결 옆의 드롭다운 화살표를 클릭합니다.
-
드롭다운에서 런타임에 연결을 선택합니다.
-
새 런타임 만들기를 선택합니다.
-
기본 런타임 만들기를 선택합니다.
-
Qwiklabs 수강생 ID를 클릭합니다.
참고: 런타임이 할당될 때까지 몇 분 정도 기다립니다. 그러면 브라우저 창 하단에 연결 상태가 '연결됨'으로 업데이트되는 것을 확인할 수 있습니다. 또한 탐색기의 프로젝트 아래 노트북 섹션에 Python 노트북이 추가된 것을 확인할 수 있습니다.
목표를 확인하려면 내 진행 상황 확인하기를 클릭합니다.
BigQuery의 Colab Enterprise 런타임에 연결
작업 4. Python 노트북 빌드
이 작업에서는 다음 단계를 수행하여 Python 노트북을 빌드합니다.
- Python 라이브러리 가져오기
- 변수 정의하기
- 공개 데이터 세트에서 기본 테이블을 BigQuery DataFrame으로 만들고 가져오기
- k-평균 클러스터링 모델 및 시각화 생성하기
Python 라이브러리 가져오기 및 변수 정의하기
Python 노트북을 빌드하는 첫 번째 단계는 Python 라이브러리를 가져와 변수를 정의하는 것입니다.
라이브러리를 노트북으로 가져오려면 아래 단계를 따릅니다.
-
노트북에 코드 셀을 추가하고 노트북 창 상단의 +코드 버튼을 클릭합니다.
-
셀에 다음 코드 스니펫을 붙여넣습니다.
from google.cloud import bigquery
from google.cloud import aiplatform
import bigframes.pandas as bpd
import pandas as pd
from vertexai.language_models._language_models import TextGenerationModel
from vertexai.generative_models import GenerativeModel
from bigframes.ml.cluster import KMeans
from bigframes.ml.model_selection import train_test_split
-
셀을 실행  합니다.
합니다.
런타임이 Python 라이브러리를 로드하는 데는 약 1분이 걸립니다. 브라우저 창 하단에서 런타임 상태를 확인하여 진행 상황을 살펴볼 수 있습니다.
완료되면 셀의 실행 버튼 옆에 녹색 체크표시  가 나타납니다.
가 나타납니다.
아래 표에는 방금 노트북으로 가져온 Python 라이브러리에 대한 자세한 정보와 각 라이브러리에 대한 간략한 설명이 나와 있습니다.
참고: 각 라이브러리에 대해 자세히 알아보려면 제공된 링크를 사용하세요.
변수를 정의하고 BigQuery 및 Vertex AI 연결 시작하기
다음으로 변수를 정의하고 BigQuery 및 Vertex AI 연결을 시작합니다.
-
노트북 끝에 코드 셀을 하나 더 추가합니다.
-
셀에 다음 코드 스니펫을 붙여넣습니다.
project_id = '<project_id>'
dataset_name = "ecommerce"
model_name = "customer_segmentation_model"
table_name = "customer_stats"
location = "<location>"
client = bigquery.Client(project=project_id)
aiplatform.init(project=project_id, location=location)
-
<project_id>를 (으)로 바꿉니다.
-
<location>을 (으)로 바꿉니다.
-
셀을 실행 합니다.
ecommerce.customer_stats 테이블 생성 및 가져오기
다음으로, thelook_ecommerce BigQuery 공개 데이터 세트의 데이터를 전자상거래 데이터 세트의 customer_status라는 제목의 새 테이블에 저장합니다.
-
노트북 끝에 코드 셀을 하나 더 추가합니다.
-
셀에 다음 코드 스니펫을 붙여넣습니다.
%%bigquery
CREATE OR REPLACE TABLE ecommerce.customer_stats AS
SELECT
user_id,
DATE_DIFF(CURRENT_DATE(), CAST(MAX(order_created_date) AS DATE), day) AS days_since_last_order, ---RECENCY
COUNT(order_id) AS count_orders, --FREQUENCY
AVG(sale_price) AS average_spend --MONETARY
FROM (
SELECT
user_id,
order_id,
sale_price,
created_at AS order_created_date
FROM `bigquery-public-data.thelook_ecommerce.order_items`
WHERE
created_at
BETWEEN '2022-01-01' AND '2023-01-01'
)
GROUP BY user_id;
-
셀을 실행 합니다.
BigQuery DataFrame을 만들고 Gemini 프롬프트를 사용하여 데이터 로드하기
이 단계에서는 Gemini 프롬프트를 사용하여 BigQuery DataFrame을 만든 후 여기에 고객 통계 데이터를 로드하여 나중에 k-평균 클러스터링 모델로 데이터를 처리할 수 있게 만듭니다.
참고: 실습을 시작할 때 언급했듯이 Gemini의 모든 출력을 사용 전에 검증해야 합니다. 제공된 코드 예시를 참고하되, 코드를 있는 그대로 복사하여 붙여넣지 마세요. 경우에 따라 작동하지 않을 수 있습니다. 출력을 개선하기 위해 Gemini가 제공한 코드를 재생성하는 것이 좋습니다.
-
노트북 끝에 코드 셀을 하나 더 추가합니다.
-
셀 내에서 생성을 클릭합니다. 이렇게 하면 Gemini로 코드를 생성할 수 있으며 텍스트를 입력할 수 있는 프롬프트가 표시됩니다.
-
프롬프트에 다음 텍스트를 붙여넣습니다.
Convert the table ecommerce.customer_stats to a bigframes dataframe and show the top 10 records
-
생성을 클릭합니다. Gemini가 아래 코드를 생성합니다.
bqdf = client.read_gbq(f"{project_id}.{dataset_name}.{table_name}")
df.head(10)
참고: 이전 단계에서 노트북의 셀 번호 2에 프로젝트 ID, 데이터 세트 이름, 테이블 이름을 변수로 저장한 코드를 추가했다는 것을 기억하세요. 이 단계를 완료하면 다음 단계에서 셀을 실행할 때 문제가 발생하지 않으며 처음 10개의 행이 표시된 DataFrame이 생성됩니다.
-
다음에 표시된 코드와 유사하게 출력되도록 코드를 재생성합니다.
bqdf = bpd.read_gbq(f"{project_id}.{dataset_name}.{table_name}")
bqdf.head(10)
-
셀을 실행 합니다.
데이터 세트에 대한 처음 10개의 행이 표시된 BigQuery DataFrame 출력이 나타납니다.
k-평균 클러스터링 모델 생성하기
이제 BigQuery DataFrame에 고객 데이터가 있으므로 k-평균 클러스터링 모델을 만들어 주문 후 경과 일수, 주문 수 및 지출액과 같은 필드를 기반으로 고객 데이터를 클러스터로 분할한 다음, 노트북 안에서 바로 차트 내의 그룹으로 시각화합니다.
-
노트북 끝에 코드 셀을 하나 더 추가합니다.
-
셀에서 생성을 클릭합니다. 이렇게 하면 프롬프트를 사용하여 Gemini로 코드를 생성할 수 있습니다.
-
셀에 다음 프롬프트를 추가합니다.
1. Split df (using random state and test size 0.2) into test and training data for a K-means clustering algorithm store these as df_test and df_train. 2. Create a K-means cluster model using bigframes.ml.cluster KMeans with 5 clusters. 3. Save the model using the to_gbq method where the model name is project_id.dataset_name.model_name.
-
생성을 클릭합니다. 다음과 비슷한 출력이 표시됩니다.
#prompt: 1. Split df (using random state and test size 0.2) into test and training data for a K-means clustering algorithm store these as df_test and df_train. 2. Create a K-means cluster model using bigframes.ml.cluster KMeans with 5 clusters. 3. Save the model using the to_gbq method where the model name is project_id.dataset_name.model_name.
df_train, df_test = train_test_split(bq_df, test_size=0.2, random_state = 42)
kmeans = KMeans(n_clusters=5)
kmeans.fit(df_train)
kmeans.to_gbq(f"{project_id}.{dataset_name}.{model_name}")
-
셀을 실행 합니다.
참고: 이 단계를 완료하는 데 약 2분이 소요됩니다.
이제 모델이 생성되었습니다.
-
프로젝트 이름 옆의 점 3개를 클릭하고 콘텐츠 새로고침을 선택하여 '탐색기' 패널의 콘텐츠를 새로고침합니다. 전자상거래 데이터 세트 아래에 팝업이 나타납니다.
다음으로, k-평균 모델이 생성한 세그먼트/클러스터를 원래 데이터에 다시 조인하는 새로운 BigQuery DataFrame을 정의합니다.
-
노트북 끝에 코드 셀을 하나 더 추가합니다.
-
셀에서 생성을 클릭합니다.
이렇게 하면 프롬프트를 사용하여 Gemini로 코드를 생성할 수 있습니다.
-
셀에 다음 프롬프트를 추가합니다.
1. Call the K-means prediction model on the df dataframe, and store the results as predictions_df and show the first 10 records.
-
생성을 클릭합니다. 다음과 비슷한 출력이 표시됩니다.
# prompt: 1. Call the K-means prediction model on the df dataframe, and store the results as predictions_df and show the first 10 records.
predictions_df = kmeans.predict(df_test)
predictions_df.head(10)
-
셀을 실행 합니다.
처음 10개의 레코드가 CENTROID_ID와 함께 표시됩니다. CENTROID_ID는 이 실습의 뒷부분에서 고객을 분류할 클러스터입니다. user_id, days_since_last_order, count_orders 및 average_spend 필드도 표시됩니다.
목표를 확인하려면 내 진행 상황 확인하기를 클릭합니다.
k-평균 클러스터링 모델 생성
k-평균 클러스터링 모델 결과에 대한 시각화 생성하기
다음 단계에서는 k-평균 클러스터링 모델 결과에 대한 시각화를 생성합니다. 구체적으로, predictions_df를 사용하여 분산형 차트를 생성하고, 마지막 주문 이후 경과 일수와 평균 지출액 간의 관계를 살펴봅니다. 이때 점의 색은 k-평균 모델을 통해 생성된 segment_id에 따라 구분됩니다.
-
노트북 끝에 코드 셀을 하나 더 추가합니다.
-
셀에서 생성을 클릭합니다.
이렇게 하면 프롬프트를 사용하여 Gemini로 코드를 생성할 수 있습니다.
-
셀에 다음 프롬프트를 추가합니다.
1. Using predictions_df, and matplotlib, generate a scatterplot. 2. On the x-axis of the scatterplot, display days_since_last_order and on the y-axis, display average_spend from predictions_df. 3. Color by cluster. 4. The chart should be titled "Attribute grouped by K-means cluster."
-
생성을 클릭합니다.
다음과 비슷한 출력이 표시됩니다.
#prompt: 1. Using predictions_df, and matplotlib, generate a scatterplot. 2. On the x-axis of the scatterplot, display days_since_last_order and on the y-axis, display average_spend from predictions_df. 3. Color by cluster. 4. The chart should be titled "Attribute grouped by K-means cluster."
import matplotlib.pyplot as plt
# Create the scatter plot
plt.figure(figsize=(10, 6)) # Adjust figure size as needed
plt.scatter(predictions_df['days_since_last_order'], predictions_df['average_spend'], c=predictions_df['cluster'], cmap='viridis')
# Customize the plot
plt.title('Attribute grouped by K-means cluster')
plt.xlabel('Days Since Last Order')
plt.ylabel('Average Spend')
plt.colorbar(label='Cluster ID')
# Display the plot
plt.show()
-
c=predictions_df 필드에서만 'cluster' 또는 'cluster_id'를 'CENTROID_ID'로 바꿉니다.
-
셀을 실행 합니다.
시각화가 표시됩니다.
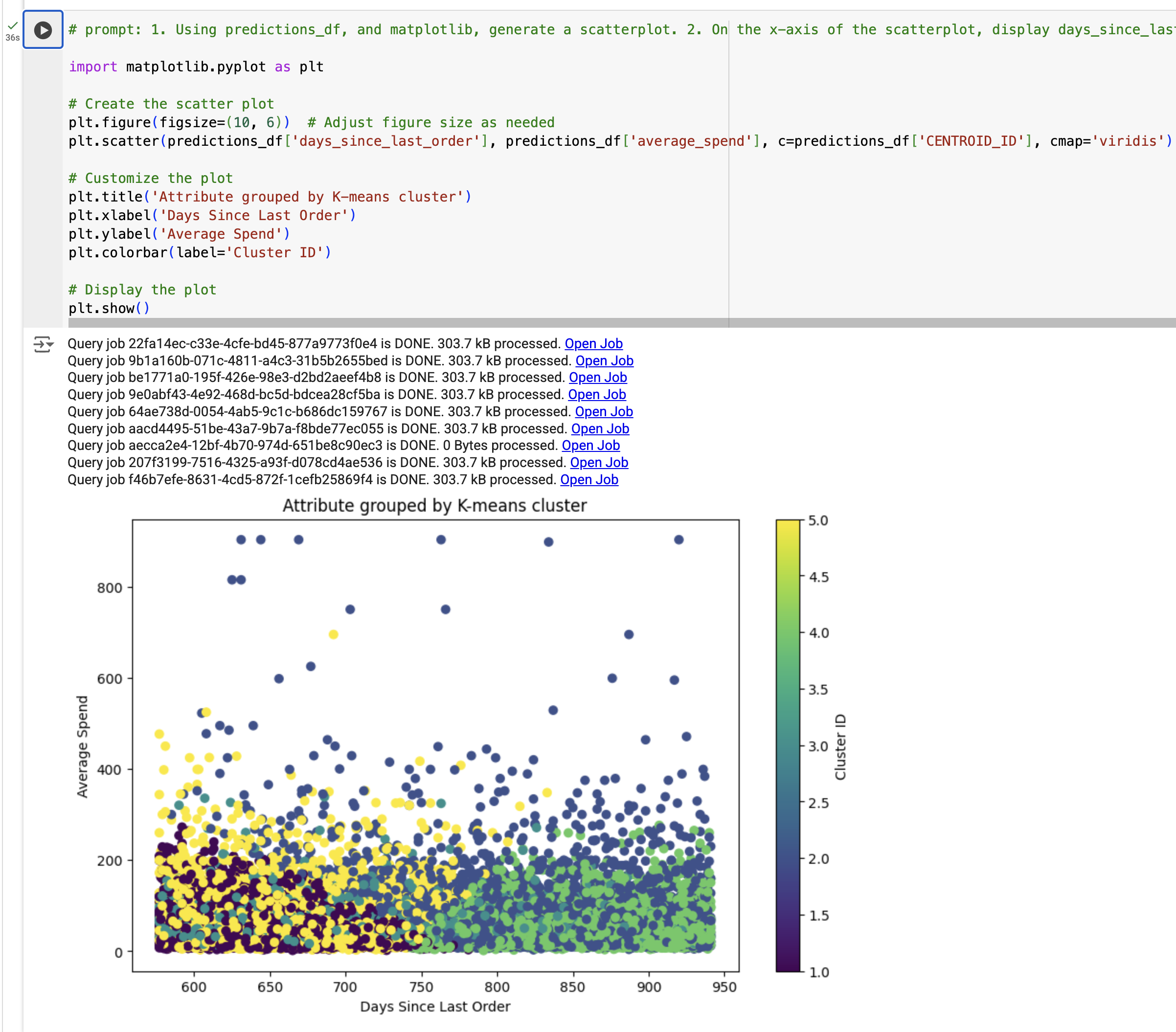
참고: TypeError가 발생하면 코드를 출력 예시로 바꾼 다음 셀을 실행하세요.
목표를 확인하려면 내 진행 상황 확인하기를 클릭합니다.
k-평균 클러스터링 모델 결과에서 시각화 생성
작업 5. 모델 결과에서 인사이트 생성
이 작업에서는 다음 단계를 수행하여 모델 결과에서 인사이트를 생성합니다.
- k-평균 모델에서 생성된 각 클러스터 요약하기
- 마케팅 캠페인용 프롬프트 정의하기
- Gemini를 사용하여 마케팅 캠페인 생성하기
k-평균 모델에서 생성된 각 클러스터 요약하기
이 단계에서는 k-평균 모델에서 생성된 각 클러스터를 요약합니다.
-
노트북 끝에 코드 셀을 하나 더 추가합니다.
-
셀에 다음 코드 스니펫을 붙여넣습니다.
query = """
SELECT
CONCAT('cluster ', CAST(centroid_id as STRING)) as centroid,
average_spend,
count_orders,
days_since_last_order
FROM (
SELECT centroid_id, feature, ROUND(numerical_value, 2) as value
FROM ML.CENTROIDS(MODEL `{0}.{1}`)
)
PIVOT (
SUM(value)
FOR feature IN ('average_spend', 'count_orders', 'days_since_last_order')
)
ORDER BY centroid_id
""".format(dataset_name, model_name)
df_centroid = client.query(query).to_dataframe()
df_centroid.head()
-
셀을 실행 합니다.
클러스터가 테이블로 요약된 것을 볼 수 있습니다. 이 테이블에서는 평균 지출액이 더 높은 클러스터와 주문 수가 더 많은 클러스터 등 몇 가지 인사이트를 얻을 수 있습니다.
다음으로 데이터 프레임을 문자열로 변환하여 대규모 언어 모델 호출에 전달합니다.
-
노트북 끝에 코드 셀을 하나 더 추가합니다.
-
셀에 다음 코드 스니펫을 붙여넣습니다.
df_query = client.query(query).to_dataframe()
df_query.to_string(header=False, index=False)
cluster_info = []
for i, row in df_query.iterrows():
cluster_info.append("{0}, average spend ${2}, count of orders per person {1}, days since last order {3}"
.format(row["centroid"], row["count_orders"], row["average_spend"], row["days_since_last_order"]) )
cluster_info = (str.join("\n", cluster_info))
print(cluster_info)
-
셀을 실행 합니다.
출력은 다음과 비슷합니다.
cluster 1, average spend $48.32, count of orders per person 1.36, days since last order 384.37
cluster 2, average spend $202.34, count of orders per person 1.3, days since last order 482.62
cluster 3, average spend $45.68, count of orders per person 1.36, days since last order 585.4
cluster 4, average spend $44.71, count of orders per person 1.36, days since last order 466.26
cluster 5, average spend $58.08, count of orders per person 3.92, days since last order 427.36
Gemini 모델을 사용하여 마케팅 캠페인 생성하기
k-평균 모델을 만들고, 모델에서 각 고객을 클러스터에 할당하고, 각 클러스터에 대한 요약 통계를 생성했습니다. 이 단계에서는 Gemini를 사용해 프롬프트에서 코드를 생성하여 고객 인사이트와 마케팅팀을 위한 다음 단계가 포함된 마케팅 캠페인을 생성합니다.
K-평균 모델이 정의한 각 클러스터/세그먼트에 대해 마케팅팀에서 사용할 수 있는 다음과 같은 세 가지 항목을 생성합니다.
-
노트북 끝에 코드 셀을 하나 더 추가합니다.
-
셀에 다음 코드 스니펫을 붙여넣습니다.
model = GenerativeModel("gemini-2.5-pro")
prompt = f"""
You're a creative brand strategist, given the following clusters, come up with \
creative brand persona, a catchy title, and next marketing action, \
explained step by step. Identify the cluster number, the title of the person, a persona for them and the next marketing step.
Clusters:
{cluster_info}
For each Cluster:
* Title:
* Persona:
* Next marketing step:
"""
responses = model.generate_content(
prompt,
generation_config={
"temperature": 0.1,
"max_output_tokens": 4000,
"top_p": 1.0,
"top_k": 40,
}
)
print(responses.text)
-
셀을 실행 합니다.
각 클러스터에 제목, 페르소나, 다음 단계가 표시됩니다.
**Cluster 1:**
* **Title:** The Lapsed Loyalists
* **Persona:** These customers have made a purchase in the past but haven't returned for an extended period. They likely had a positive experience but haven't been engaged recently.
* **Next Marketing Step:**
1. **Re-engagement campaign:** Send personalized emails or targeted ads reminding them of their previous purchase and highlighting new products or promotions that might interest them.
2. **Offer exclusive discounts or incentives:** Motivate them to return with special offers or loyalty rewards.
3. **Personalized product recommendations:** Leverage purchase history and browsing behavior to suggest relevant products they might be interested in.
**Cluster 2:**
* **Title:** The Occasional Treaters
* **Persona:** These customers make infrequent purchases but spend more when they do. They likely view the brand as a premium option for special occasions.
* **Next Marketing Step:**
1. **Highlight exclusivity and premium value:** Emphasize the unique features and benefits of your products to justify the higher price point.
2. **Offer limited-time promotions or bundles:** Encourage larger purchases with special deals on high-value items or curated product sets.
3. **Create a sense of urgency and scarcity:** Promote limited-edition products or flash sales to encourage immediate action.
**Cluster 3:**
* **Title:** The One-and-Done Buyers
* **Persona:** These customers have only made a single purchase and haven't returned. They might have had a neutral experience or haven't found a reason to come back.
* **Next Marketing Step:**
1. **Gather feedback:** Send post-purchase surveys to understand their experience and identify areas for improvement.
2. **Offer personalized recommendations:** Based on their initial purchase, suggest complementary products or accessories to encourage further engagement.
3. **Showcase customer testimonials and social proof:** Highlight positive reviews and user-generated content to build trust and encourage repeat purchases.
**Cluster 4:**
* **Title:** The Big Spenders
* **Persona:** These customers spend significantly more than others and are likely your most loyal and valuable segment. They appreciate high-quality products and personalized experiences.
* **Next Marketing Step:**
1. **Develop a VIP program:** Offer exclusive benefits, early access to new products, and personalized customer service to show appreciation and encourage continued loyalty.
2. **Personalized communication and offers:** Tailor your marketing messages and promotions to their specific interests and purchase history.
3. **Host exclusive events or experiences:** Create opportunities for them to connect with the brand and other high-value customers.
**Cluster 5:**
* **Title:** The Price-Conscious Shoppers
* **Persona:** These customers are primarily driven by price and make infrequent, low-value purchases. They are likely to compare prices and seek the best deals.
* **Next Marketing Step:**
1. **Promote competitive pricing and value-driven offers:** Highlight your competitive prices and bundle deals to attract price-sensitive customers.
2. **Offer free shipping or other incentives:** Reduce purchase barriers by offering free shipping or other attractive incentives.
3. **Focus on product benefits and value for money:** Emphasize the quality and functionality of your products to justify the price point.
목표를 확인하려면 내 진행 상황 확인하기를 클릭합니다.
Gemini를 사용하여 마케팅 캠페인 생성
작업 6. 프로젝트 리소스 정리(선택 사항)
이 실습에서는 Google Cloud 콘솔 내에서 리소스를 생성했습니다. 프로덕션 환경에서는 모델을 통해 인사이트를 수집하면 더 이상 리소스가 필요하지 않으므로 계정에서 이러한 리소스를 삭제해야 합니다. 계정에서 리소스를 삭제하고 추가 사용료가 부과되지 않도록 하는 방법에는 두 가지가 있습니다.
- 프로젝트 삭제(아래 주의사항 참조)
- 개별 리소스 삭제
프로젝트를 삭제하여 리소스 정리하기
이 튜토리얼에서 사용한 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 이 튜토리얼에서 만든 Google Cloud 프로젝트를 삭제하면 됩니다.
주의: 프로젝트를 삭제하면 다음과 같은 결과가 발생합니다.
- 프로젝트의 모든 항목이 삭제됩니다. 이 문서의 작업에 기존 프로젝트를 사용한 경우 프로젝트를 삭제하면 프로젝트에서 수행한 다른 작업도 삭제됩니다.
- 커스텀 프로젝트 ID가 손실됩니다. 이 프로젝트를 만들 때 앞으로 사용할 커스텀 프로젝트 ID를 만들었을 수 있습니다. appspot.com URL과 같이 프로젝트 ID를 사용하는 URL을 보존하려면 전체 프로젝트를 삭제하는 대신 프로젝트 내의 선택된 리소스만 삭제하세요.
여러 아키텍처, 튜토리얼 또는 빠른 시작을 살펴보려는 경우 프로젝트를 재사용하면 프로젝트 할당량 한도 초과를 방지할 수 있습니다.
-
Google Cloud 콘솔에서 IAM 및 관리자 > 리소스 관리 페이지로 이동합니다.
-
프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
-
대화상자에서 프로젝트 ID를 입력한 다음 무시하고 종료를 클릭하여 프로젝트를 삭제합니다.
개별 리소스를 삭제하여 리소스 정리하기
요금이 부과되지 않도록 하려면 노트북 내의 새 코드 셀에서 다음 코드를 실행하여 이 실습에 사용된 테이블과 모델을 삭제할 수 있습니다.
# Delete customer_stats table
client.delete_table(f"{project_id}.{dataset_name}.{table_name}", not_found_ok=True)
print(f"Deleted table: {project_id}.{dataset_name}.{table_name}")
# Delete K-means model
client.delete_model(f"{project_id}.{dataset_name}.{model_name}", not_found_ok=True)
print(f"Deleted model: {project_id}.{dataset_name}.{model_name}")
셀을 실행한 후 BigQuery Studio에서 프로젝트의 콘텐츠를 새로고침하면 테이블과 모델이 삭제되었음을 확인할 수 있습니다.
수고하셨습니다
이 실습에서는 다음을 수행하는 방법을 배웠습니다.
- BigQuery Studio 내에서 Colab Enterprise Python 노트북 사용하기
- BigQuery Studio 내에서 BigQuery DataFrames 사용하기
- Gemini를 사용하여 자연어 프롬프트에서 코드 생성하기
- k-평균 클러스터링 모델 빌드하기
- 클러스터의 시각화 생성하기
- Gemini를 사용하여 마케팅 캠페인의 다음 단계 개발하기
읽기 자료(선택 사항)
지금까지 Gemini, Vertex AI, BigQuery를 사용하여 Cymbal Superstore의 고객을 식별 및 분류하고 개발하는 데 도움을 주었습니다. Gemini에 대해 자세히 알아보고 싶다면 아래 링크를 참조하세요.
실습 종료
실습을 완료하면 실습 종료를 클릭합니다. Qwiklabs에서 사용된 리소스를 자동으로 삭제하고 계정을 지웁니다.
실습 경험을 평가할 수 있습니다. 해당하는 별표 수를 선택하고 의견을 입력한 후 제출을 클릭합니다.
별점의 의미는 다음과 같습니다.
- 별표 1개 = 매우 불만족
- 별표 2개 = 불만족
- 별표 3개 = 중간
- 별표 4개 = 만족
- 별표 5개 = 매우 만족
의견을 제공하고 싶지 않다면 대화상자를 닫으면 됩니다.
의견이나 제안 또는 수정할 사항이 있다면 지원 탭을 사용하세요.
설명서 최종 업데이트: 2025년 9월 3일
실습 최종 테스트: 2025년 9월 3일
Copyright 2024 Google LLC All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.





