Présentation
Dans cet atelier, vous travaillez en tant que data scientist pour Cymbal Superstore. Vous êtes chargé d'aider l'équipe marketing à identifier, classer et développer de nouveaux clients. L'équipe de direction vous a demandé de répartir les clients dans cinq groupes différents en fonction de leur comportement d'achat, ainsi que de générer des statistiques descriptives concernant chaque groupe. Vous souhaitez également proposer à l'équipe des étapes ultérieures qu'elle pourra exploiter pour chacun de ces groupes.
Pour identifier ces nouveaux clients, vous allez utiliser Gemini, Vertex AI et BigQuery afin de créer, visualiser et résumer un modèle de clustering en k-moyennes avec des données d'e-commerce, et de générer des étapes ultérieures utiles pour une campagne marketing. Cet atelier s'adresse aux data scientists de tous niveaux.
L'environnement a déjà été configuré pour vous. Cela inclut l'activation de Cloud AI Companion pour Gemini et l'attribution des rôles IAM nécessaires pour utiliser Gemini. Pour en savoir plus, consultez la présentation de Gemini pour Google Cloud.
Remarque : Duet AI a été renommé "Gemini", notre modèle nouvelle génération. Cet atelier a été modifié en conséquence. Lorsque vous effectuerez l'atelier, toute référence à Duet AI dans l'interface utilisateur ou la documentation doit être traitée comme l'équivalent de Gemini.
Remarque : Comme il s'agit d'une technologie encore à un stade précoce, il se peut que Gemini génère des résultats qui semblent plausibles, mais qui sont en fait incorrects. Nous vous recommandons de valider tous les résultats de Gemini avant de les utiliser. Pour en savoir plus, consultez Gemini pour Google Cloud et l'IA responsable.
Objectifs
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Utiliser des notebooks Python Colab Enterprise dans BigQuery Studio
- Utiliser BigQuery DataFrames dans BigQuery Studio
- Utiliser Gemini pour générer du code à l'aide de prompts en langage naturel
- Créer un modèle de clustering en k-moyennes
- Générer une visualisation des clusters
- Utiliser le modèle Gemini Pro pour développer les prochaines étapes d'une campagne marketing
- Nettoyer les ressources du projet
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- Vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome).
Remarque : Ouvrez une fenêtre de navigateur en mode navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- Vous disposez d'un temps limité. N'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Si vous possédez déjà votre propre compte ou projet Google Cloud, veillez à ne pas l'utiliser pour réaliser cet atelier afin d'éviter que des frais supplémentaires ne vous soient facturés.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google Cloud
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau Détails concernant l'atelier.
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau Détails concernant l'atelier.
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
-
Procédez tel qu'indiqué ci-dessous sur les pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour afficher un menu contenant la liste des produits et services Google Cloud, cliquez sur le menu de navigation en haut à gauche.

Tâche 1 : Créer un ensemble de données BigQuery pour votre projet
Dans cette tâche, vous allez créer l'ensemble de données "ecommerce" dans BigQuery. Cet ensemble de données servira à stocker les données d'e-commerce que vous allez classer dans cet atelier.
-
Dans la console Google Cloud, ouvrez le menu de navigation ( ) et sélectionnez BigQuery.
) et sélectionnez BigQuery.
Le pop-up "Bienvenue sur BigQuery dans la console Cloud" s'affiche.
-
Cliquez sur OK.
-
Dans le panneau Explorateur, pour , sélectionnez Afficher les actions ( ), puis Créer un ensemble de données.
), puis Créer un ensemble de données.
Vous créez un ensemble de données pour stocker des objets de bases de données, dont des tables et des modèles.
-
Dans le volet Créer un ensemble de données, saisissez les informations suivantes :
| Champ |
Valeur |
| ID de l'ensemble de données |
ecommerce |
| Type d'emplacement |
Sélectionnez Multirégional
|
| Multirégional |
Sélectionnez US (plusieurs régions aux États-Unis)
|
Conservez les valeurs par défaut dans les autres champs.
-
Cliquez sur Créer un ensemble de données.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer un ensemble de données BigQuery pour votre projet
Tâche 2 : Créer un notebook Python
Dans cette tâche, vous allez créer un notebook Python dans BigQuery pour pouvoir utiliser Gemini dans BigQuery. Vous avez besoin d'un notebook Python dans BigQuery pour pouvoir utiliser les bibliothèques de machine learning Python afin d'identifier les clients et de les classer dans différents groupes en fonction des données sur les achats présentes dans l'ensemble de données d'e-commerce.
-
Dans la console Google Cloud, ouvrez le menu de navigation () et sélectionnez BigQuery.
-
En haut de la page, cliquez sur la flèche vers le bas à côté du signe plus.
-
Sélectionnez Notebook > Notebook vide.
-
Choisissez la région dans le menu déroulant pour stocker vos éléments de code et cliquez sur Sélectionner.
-
Dans le volet Commencer avec un modèle, cliquez sur Fermer.
Tâche 3 : Se connecter à l'environnement d'exécution Colab Enterprise dans BigQuery
Dans la prochaine étape, vous allez vous connecter à l'environnement d'exécution Colab Enterprise dans BigQuery. Voyez cet environnement d'exécution comme un environnement géré dans BigQuery qui vous permet d'accéder à des bibliothèques de machine learning utiles pour identifier vos clients et les classer dans différents groupes.
-
Toujours dans la console BigQuery Studio, cliquez sur la flèche vers le bas à côté de "Se connecter" en haut à droite du notebook.
-
Dans le menu déroulant, sélectionnez Connexion à un environnement d'exécution.
-
Sélectionnez Créer un environnement d'exécution.
-
Sélectionnez Créer un environnement d'exécution par défaut.
-
Cliquez sur l'ID de participant Qwiklabs.
Remarque : Patientez quelques minutes le temps que l'environnement d'exécution soit alloué. Vous pouvez constater que l'état de connexion passe à "Connecté" en bas de la fenêtre du navigateur. Vous pouvez également remarquer que le notebook Python est ajouté à la section des notebooks de l'explorateur sous votre projet.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Se connecter à l'environnement d'exécution Colab Enterprise dans BigQuery
Tâche 4 : Créer le notebook Python
Dans cette tâche, vous allez commencer à créer le notebook Python en suivant ces étapes :
- Importer les bibliothèques Python
- Définir les variables
- Créer et importer une table de base en tant que DataFrame BigQuery à partir d'un ensemble de données public
- Générer le modèle de clustering en k-moyennes et la visualisation
Importer les bibliothèques Python et définir les variables
La première étape de la création du notebook Python consiste à importer les bibliothèques Python et à définir les variables.
Pour importer les bibliothèques dans votre notebook, suivez ces étapes :
-
Ajoutez une cellule de code au notebook : cliquez sur le bouton + Code en haut de la fenêtre du notebook.
-
Collez l'extrait de code suivant dans la cellule :
from google.cloud import bigquery
from google.cloud import aiplatform
import bigframes.pandas as bpd
import pandas as pd
from vertexai.language_models._language_models import TextGenerationModel
from vertexai.generative_models import GenerativeModel
from bigframes.ml.cluster import KMeans
from bigframes.ml.model_selection import train_test_split
-
Exécutez  le code de la cellule.
le code de la cellule.
L'environnement d'exécution va charger les bibliothèques Python, ce qui doit prendre environ une minute. Pour suivre la progression de l'opération, contrôlez l'état de l'environnement d'exécution en bas de la fenêtre du navigateur.
Lorsque l'opération est terminée, vous pouvez voir une coche verte ( ) à côté du bouton "Exécuter" dans la cellule.
) à côté du bouton "Exécuter" dans la cellule.
Le tableau ci-dessous fournit des informations complémentaires sur les bibliothèques Python que vous venez d'importer dans votre notebook, y compris une brève description de chacune d'entre elles.
| Bibliothèque |
Description |
| BigQuery |
Client Python pour Google BigQuery |
| AI Platform |
SDK Vertex AI pour Python |
| bigframes.pandas |
BigQuery DataFrames |
| pandas |
Outil d'analyse et de manipulation de données Open Source reposant sur le langage de programmation Python |
| TextGenerationModel |
Permet de créer un modèle de langage dans Vertex AI |
| KMeans |
Permet de créer des modèles de clustering en k-moyennes dans BigQuery DataFrames |
| train_test_split |
Utilisé pour scinder un ensemble de données source en sous-ensembles d'entraînement et de test, ainsi que pour les opérations de réglage de modèles dans BigQuery DataFrames |
Remarque : Si vous souhaitez en savoir plus sur une bibliothèque, utilisez le lien correspondant.
Définir les variables et établir la connexion entre BigQuery et Vertex AI
Ensuite, vous devez définir les variables et établir la connexion entre BigQuery et Vertex AI.
-
Ajoutez une cellule de code à la fin du notebook.
-
Collez l'extrait de code suivant dans la cellule :
project_id = '<project_id>'
dataset_name = "ecommerce"
model_name = "customer_segmentation_model"
table_name = "customer_stats"
location = "<location>"
client = bigquery.Client(project=project_id)
aiplatform.init(project=project_id, location=location)
-
Remplacez <project_id> par .
-
Remplacez <location> par .
-
Exécutez le code de la cellule.
Créer et importer la table ecommerce.customer_stats
Vous allez ensuite stocker les données de l'ensemble de données public BigQuery "thelook_ecommerce" dans une nouvelle table (nommée "customer_status") de votre ensemble de données "ecommerce".
-
Ajoutez une cellule de code à la fin du notebook.
-
Collez l'extrait de code suivant dans la cellule :
%%bigquery
CREATE OR REPLACE TABLE ecommerce.customer_stats AS
SELECT
user_id,
DATE_DIFF(CURRENT_DATE(), CAST(MAX(order_created_date) AS DATE), day) AS days_since_last_order, ---RECENCY
COUNT(order_id) AS count_orders, --FREQUENCY
AVG(sale_price) AS average_spend --MONETARY
FROM (
SELECT
user_id,
order_id,
sale_price,
created_at AS order_created_date
FROM `bigquery-public-data.thelook_ecommerce.order_items`
WHERE
created_at
BETWEEN '2022-01-01' AND '2023-01-01'
)
GROUP BY user_id;
-
Exécutez le code de la cellule.
Créer un DataFrame BigQuery et charger les données à l'aide d'un prompt Gemini
Lors de cette étape, vous allez créer un DataFrame BigQuery à l'aide d'un prompt Gemini et y charger les données de statistiques clients. Vous pourrez ainsi traiter les données à l'aide du modèle de clustering en k-moyennes par la suite.
Remarque : Comme indiqué au début de l'atelier, vous devez vérifier tous les résultats de Gemini avant de vous en servir. Utilisez les extraits de code fournis pour vous aider, mais ne copiez pas le code tel quel, car il est possible qu'il ne fonctionne pas dans certains cas. Vous pouvez également demander à Gemini de le générer à nouveau pour obtenir un résultat qui correspond davantage à vos attentes.
-
Ajoutez une cellule de code à la fin du notebook.
-
Cliquez sur generate dans la cellule. Cela vous permet de générer du code avec Gemini (vous verrez une invite à l'endroit où vous pouvez afficher du texte).
-
Collez le texte suivant dans le champ de prompt :
Convert the table ecommerce.customer_stats to a bigframes dataframe and show the top 10 records
-
Cliquez sur Générer. Gemini génère le code ci-dessous :
bqdf = client.read_gbq(f"{project_id}.{dataset_name}.{table_name}")
df.head(10)
Remarque : Rappelez-vous que lors d'une étape précédente, vous avez ajouté du code à la cellule numéro 2 du notebook afin de consigner l'ID du projet et les noms de l'ensemble de données et de la table en tant que variables. Si vous avez correctement effectué cette étape, vous n'aurez aucun problème lorsque vous exécuterez la cellule à l'étape suivante : le DataFrame sera créé et les 10 premières lignes seront affichées.
-
Regénérez le code pour que le résultat ressemble à ce qui suit :
bqdf = bpd.read_gbq(f"{project_id}.{dataset_name}.{table_name}")
bqdf.head(10)
-
Exécutez la cellule.
Le résultat renvoyé doit correspondre au DataFrame BigQuery : les 10 premières lignes de l'ensemble de données doivent s'afficher.
Générer le modèle de clustering en k-moyennes
Maintenant que vos données client sont disponibles dans un DataFrame BigQuery, vous pouvez créer un modèle de clustering en k-moyennes pour les répartir en fonction de champs tels que "order recency" (ancienneté des commandes), "order count" (nombre de commandes) ou "spend" (montant dépensé). Vous pourrez ainsi les visualiser sous forme de groupes dans un graphique directement au sein du notebook.
-
Ajoutez une cellule de code à la fin du notebook.
-
Cliquez sur generate dans la cellule. Cela vous permet de générer du code avec Gemini à l'aide d'un prompt.
-
Ajoutez le prompt suivant à la cellule :
1. Split df (using random state and test size 0.2) into test and training data for a K-means clustering algorithm store these as df_test and df_train. 2. Create a K-means cluster model using bigframes.ml.cluster KMeans with 5 clusters. 3. Save the model using the to_gbq method where the model name is project_id.dataset_name.model_name.
-
Cliquez sur Générer. Vous devez obtenir un résultat semblable à ce qui suit :
#prompt: 1. Split df (using random state and test size 0.2) into test and training data for a K-means clustering algorithm store these as df_test and df_train. 2. Create a K-means cluster model using bigframes.ml.cluster KMeans with 5 clusters. 3. Save the model using the to_gbq method where the model name is project_id.dataset_name.model_name.
df_train, df_test = train_test_split(bq_df, test_size=0.2, random_state = 42)
kmeans = KMeans(n_clusters=5)
kmeans.fit(df_train)
kmeans.to_gbq(f"{project_id}.{dataset_name}.{model_name}")
-
Exécutez le code de la cellule.
Remarque : Cette étape prend environ deux minutes.
Votre modèle est désormais créé.
-
Pour actualiser le contenu du panneau "Explorateur", cliquez sur les trois points à côté du nom du projet et sélectionnez Actualiser le contenu. Le résultat doit apparaître sous votre ensemble de données "ecommerce".
Ensuite, vous devez définir un DataFrame BigQuery qui associe le segment/cluster produit par le modèle en k-moyennes aux données d'origine.
-
Ajoutez une cellule de code à la fin du notebook.
-
Cliquez sur generate dans la cellule.
Cela vous permet de générer du code avec Gemini à l'aide d'un prompt.
-
Ajoutez le prompt suivant à la cellule :
1. Call the K-means prediction model on the df dataframe, and store the results as predictions_df and show the first 10 records.
-
Cliquez sur Générer. Vous devez obtenir un résultat semblable à ce qui suit :
# prompt: 1. Call the K-means prediction model on the df dataframe, and store the results as predictions_df and show the first 10 records.
predictions_df = kmeans.predict(df_test)
predictions_df.head(10)
-
Exécutez le code de la cellule.
Vous pouvez voir que les 10 premiers enregistrements sont présentés avec CENTROID_ID. CENTROID_ID est le cluster qui servira à classer le client plus tard dans cet atelier. Vous pouvez aussi noter la présence des champs "user_id" (ID utilisateur), "days_since_last_order" (Nombre de jours depuis la dernière commande), "count_orders" (Nombre de commandes) et "average_spend" (Dépense moyenne).
Cliquez sur Vérifier ma progression pour valider l'objectif.
Générer le modèle de clustering en k-moyennes
Créer une visualisation des résultats du modèle de clustering en k-moyennes
Dans cette étape, vous allez créer une visualisation des résultats du modèle de clustering en k-moyennes. Plus précisément, vous allez générer un graphique à nuage de points à l'aide de predictions_df pour examiner la relation entre le nombre de jours écoulés depuis la dernière commande et les dépenses moyennes, les résultats étant colorés en fonction de segment_id (cette présentation a été générée par notre modèle en k-moyennes).
-
Ajoutez une cellule de code à la fin du notebook.
-
Cliquez sur generate dans la cellule.
Cela vous permet de générer du code avec Gemini à l'aide d'un prompt.
-
Ajoutez le prompt suivant à la cellule :
1. Using predictions_df, and matplotlib, generate a scatterplot. 2. On the x-axis of the scatterplot, display days_since_last_order and on the y-axis, display average_spend from predictions_df. 3. Color by cluster. 4. The chart should be titled "Attribute grouped by K-means cluster."
-
Cliquez sur Générer.
Vous devez obtenir un résultat semblable à ce qui suit :
#prompt: 1. Using predictions_df, and matplotlib, generate a scatterplot. 2. On the x-axis of the scatterplot, display days_since_last_order and on the y-axis, display average_spend from predictions_df. 3. Color by cluster. 4. The chart should be titled "Attribute grouped by K-means cluster."
import matplotlib.pyplot as plt
# Create the scatter plot
plt.figure(figsize=(10, 6)) # Adjust figure size as needed
plt.scatter(predictions_df['days_since_last_order'], predictions_df['average_spend'], c=predictions_df['cluster'], cmap='viridis')
# Customize the plot
plt.title('Attribute grouped by K-means cluster')
plt.xlabel('Days Since Last Order')
plt.ylabel('Average Spend')
plt.colorbar(label='Cluster ID')
# Display the plot
plt.show()
-
Remplacez cluster ou cluster_id par CENTROID_ID dans le champ c=predictions_df uniquement.
-
Exécutez le code de la cellule.
La visualisation doit s'afficher.
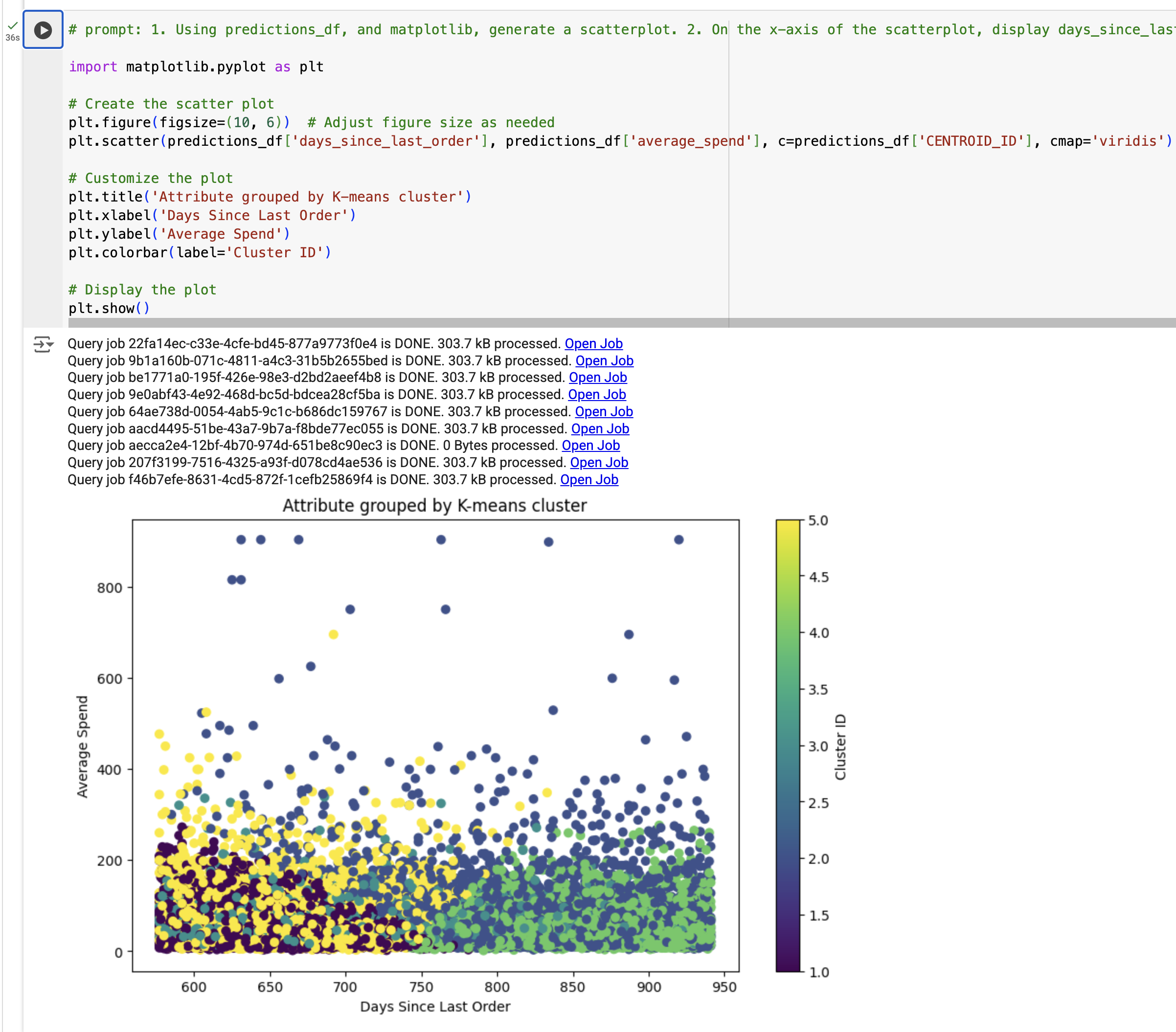
Remarque : Si un message d'erreur TypeError vous est renvoyé, remplacez le code par l'exemple de résultat, puis exécutez la cellule une nouvelle fois.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Générer la visualisation à partir des résultats du modèle de clustering en k-moyennes
Tâche 5 : Générer des insights à partir des résultats du modèle
Dans cette tâche, vous allez générer des insights à partir des résultats du modèle en suivant ces étapes :
- Résumer chaque cluster généré à partir du modèle en k-moyennes
- Définir un prompt pour la campagne marketing
- Générer la campagne marketing à l'aide de Gemini
Résumer chaque cluster généré à partir du modèle en k-moyennes
Au cours de cette étape, vous allez résumer chaque cluster généré à partir du modèle en k-moyennes.
-
Ajoutez une cellule de code à la fin du notebook.
-
Collez l'extrait de code suivant dans la cellule :
query = """
SELECT
CONCAT('cluster ', CAST(centroid_id as STRING)) as centroid,
average_spend,
count_orders,
days_since_last_order
FROM (
SELECT centroid_id, feature, ROUND(numerical_value, 2) as value
FROM ML.CENTROIDS(MODEL `{0}.{1}`)
)
PIVOT (
SUM(value)
FOR feature IN ('average_spend', 'count_orders', 'days_since_last_order')
)
ORDER BY centroid_id
""".format(dataset_name, model_name)
df_centroid = client.query(query).to_dataframe()
df_centroid.head()
-
Exécutez le code de la cellule.
Vous devez voir les clusters résumés dans une table. Cette table vous permet de dégager les insights suivants : certains clusters présentent un niveau moyen de dépenses plus élevé, tandis que d'autres ont un nombre de commandes supérieur.
Vous devez maintenant convertir le DataFrame en chaîne afin de pouvoir le transmettre lors de l'appel au grand modèle de langage.
-
Ajoutez une cellule de code à la fin du notebook.
-
Collez l'extrait de code suivant dans la cellule :
df_query = client.query(query).to_dataframe()
df_query.to_string(header=False, index=False)
cluster_info = []
for i, row in df_query.iterrows():
cluster_info.append("{0}, average spend ${2}, count of orders per person {1}, days since last order {3}"
.format(row["centroid"], row["count_orders"], row["average_spend"], row["days_since_last_order"]) )
cluster_info = (str.join("\n", cluster_info))
print(cluster_info)
-
Exécutez le code de la cellule.
Le résultat doit être semblable à ceci :
cluster 1, average spend $48.32, count of orders per person 1.36, days since last order 384.37
cluster 2, average spend $202.34, count of orders per person 1.3, days since last order 482.62
cluster 3, average spend $45.68, count of orders per person 1.36, days since last order 585.4
cluster 4, average spend $44.71, count of orders per person 1.36, days since last order 466.26
cluster 5, average spend $58.08, count of orders per person 3.92, days since last order 427.36
Générer la campagne marketing à l'aide du modèle Gemini
Vous avez créé un modèle en k-moyennes, associé chaque client à un cluster du modèle et généré des statistiques récapitulatives pour chaque cluster. Dans cette étape, vous allez utiliser Gemini pour générer du code à partir d'un prompt afin de créer une campagne marketing, avec des insights sur les clients et les prochaines étapes que votre équipe marketing devra suivre.
Pour chaque cluster/segment défini par le modèle en k-moyennes, nous allons générer trois éléments que l'équipe marketing pourra utiliser :
- Titre
- Persona
- Étape marketing suivante
-
Ajoutez une cellule de code à la fin du notebook.
-
Collez l'extrait de code suivant dans la cellule :
model = GenerativeModel("gemini-2.5-pro")
prompt = f"""
You're a creative brand strategist, given the following clusters, come up with \
creative brand persona, a catchy title, and next marketing action, \
explained step by step. Identify the cluster number, the title of the person, a persona for them and the next marketing step.
Clusters:
{cluster_info}
For each Cluster:
* Title:
* Persona:
* Next marketing step:
"""
responses = model.generate_content(
prompt,
generation_config={
"temperature": 0.1,
"max_output_tokens": 4000,
"top_p": 1.0,
"top_k": 40,
}
)
print(responses.text)
-
Exécutez le code de la cellule.
Chaque cluster doit s'afficher avec le titre, le persona et les prochaines étapes.
**Cluster 1:**
* **Title:** The Lapsed Loyalists
* **Persona:** These customers have made a purchase in the past but haven't returned for an extended period. They likely had a positive experience but haven't been engaged recently.
* **Next Marketing Step:**
1. **Re-engagement campaign:** Send personalized emails or targeted ads reminding them of their previous purchase and highlighting new products or promotions that might interest them.
2. **Offer exclusive discounts or incentives:** Motivate them to return with special offers or loyalty rewards.
3. **Personalized product recommendations:** Leverage purchase history and browsing behavior to suggest relevant products they might be interested in.
**Cluster 2:**
* **Title:** The Occasional Treaters
* **Persona:** These customers make infrequent purchases but spend more when they do. They likely view the brand as a premium option for special occasions.
* **Next Marketing Step:**
1. **Highlight exclusivity and premium value:** Emphasize the unique features and benefits of your products to justify the higher price point.
2. **Offer limited-time promotions or bundles:** Encourage larger purchases with special deals on high-value items or curated product sets.
3. **Create a sense of urgency and scarcity:** Promote limited-edition products or flash sales to encourage immediate action.
**Cluster 3:**
* **Title:** The One-and-Done Buyers
* **Persona:** These customers have only made a single purchase and haven't returned. They might have had a neutral experience or haven't found a reason to come back.
* **Next Marketing Step:**
1. **Gather feedback:** Send post-purchase surveys to understand their experience and identify areas for improvement.
2. **Offer personalized recommendations:** Based on their initial purchase, suggest complementary products or accessories to encourage further engagement.
3. **Showcase customer testimonials and social proof:** Highlight positive reviews and user-generated content to build trust and encourage repeat purchases.
**Cluster 4:**
* **Title:** The Big Spenders
* **Persona:** These customers spend significantly more than others and are likely your most loyal and valuable segment. They appreciate high-quality products and personalized experiences.
* **Next Marketing Step:**
1. **Develop a VIP program:** Offer exclusive benefits, early access to new products, and personalized customer service to show appreciation and encourage continued loyalty.
2. **Personalized communication and offers:** Tailor your marketing messages and promotions to their specific interests and purchase history.
3. **Host exclusive events or experiences:** Create opportunities for them to connect with the brand and other high-value customers.
**Cluster 5:**
* **Title:** The Price-Conscious Shoppers
* **Persona:** These customers are primarily driven by price and make infrequent, low-value purchases. They are likely to compare prices and seek the best deals.
* **Next Marketing Step:**
1. **Promote competitive pricing and value-driven offers:** Highlight your competitive prices and bundle deals to attract price-sensitive customers.
2. **Offer free shipping or other incentives:** Reduce purchase barriers by offering free shipping or other attractive incentives.
3. **Focus on product benefits and value for money:** Emphasize the quality and functionality of your products to justify the price point.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Générer la campagne marketing à l'aide de Gemini
Tâche 6 : Nettoyer les ressources du projet (facultatif)
Lors de cet atelier, vous avez créé des ressources dans la console Google Cloud. Dans un environnement de production, vous devez supprimer ces ressources de votre compte, étant donné que vous n'en avez plus besoin une fois que les insights du modèle ont été collectés. Pour supprimer ces ressources de votre compte et éviter d'encourir des frais d'utilisation par la suite, vous avez deux possibilités :
- Supprimer le projet (voir les mises en garde ci-dessous)
- Supprimer chaque ressource
Nettoyer les ressources en supprimant le projet
Pour éviter que les ressources utilisées dans ce tutoriel soient facturées sur votre compte Google Cloud, vous pouvez supprimer le projet Google Cloud que vous avez créé pour l'occasion.
Attention : La suppression d'un projet entraîne les effets suivants :
- Tout le contenu du projet est supprimé. Si vous avez utilisé un projet existant pour les tâches décrites dans ce document et que vous le supprimez, vous supprimerez également tout autre travail effectué dans le projet.
- Les ID de projets personnalisés sont perdus. Lorsque vous avez créé ce projet, vous avez peut-être créé un ID de projet personnalisé dont vous souhaitez vous servir par la suite. Pour conserver les URL qui utilisent l'ID de projet, par exemple une URL appspot.com, supprimez les ressources sélectionnées dans le projet au lieu de supprimer l'ensemble du projet.
Si vous envisagez d'explorer plusieurs architectures, tutoriels et guides de démarrage rapide, réutiliser des projets peut vous aider à ne pas dépasser les limites de quotas des projets.
-
Dans la console Google Cloud, accédez à la page IAM et administration > Gérer les ressources.
-
Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
-
Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter quand même pour supprimer le projet.
Nettoyer les ressources en supprimant chacune d'elles
Afin d'éviter que des frais ne vous soient facturés, vous pouvez supprimer la table et le modèle utilisés dans ce projet en exécutant le code suivant dans une nouvelle cellule de code du notebook :
# Delete customer_stats table
client.delete_table(f"{project_id}.{dataset_name}.{table_name}", not_found_ok=True)
print(f"Deleted table: {project_id}.{dataset_name}.{table_name}")
# Delete K-means model
client.delete_model(f"{project_id}.{dataset_name}.{model_name}", not_found_ok=True)
print(f"Deleted model: {project_id}.{dataset_name}.{model_name}")
Une fois que vous avez exécuté la cellule, vous pouvez actualiser le contenu de votre projet dans BigQuery Studio afin de confirmer que la table et le modèle ont bien été supprimés.
Félicitations !
Dans cet atelier, vous avez appris à effectuer les tâches suivantes :
- Utiliser des notebooks Python Colab Enterprise dans BigQuery Studio
- Utiliser BigQuery DataFrames dans BigQuery Studio
- Utiliser Gemini pour générer du code à l'aide de prompts en langage naturel
- Créer un modèle de clustering en k-moyennes
- Générer une visualisation des clusters
- Utiliser Gemini pour développer les prochaines étapes d'une campagne marketing
Ressources complémentaires
Maintenant que vous avez identifié, classé et contribué à développer les clients pour Cymbal Superstore à l'aide de Gemini, Vertex AI et BigQuery, consultez les liens ci-dessous si vous souhaitez en savoir plus sur Gemini :
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur End Lab (Terminer l'atelier). Qwiklabs supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez le nombre d'étoiles correspondant à votre note, saisissez un commentaire, puis cliquez sur Submit (Envoyer).
Le nombre d'étoiles que vous pouvez attribuer à un atelier correspond à votre degré de satisfaction :
- 1 étoile = très mécontent(e)
- 2 étoiles = insatisfait(e)
- 3 étoiles = ni insatisfait(e), ni satisfait(e)
- 4 étoiles = satisfait(e)
- 5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez utiliser l'onglet Support (Assistance).
Dernière mise à jour du manuel : 3 septembre 2025
Dernier test de l'atelier : 3 septembre 2025
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.





