Descripción general
En este lab, trabajarás como científico de datos para Cymbal Superstore y se te solicita que ayudes al equipo de marketing a identificar, categorizar y desarrollar clientes nuevos. El equipo de liderazgo te pide que separes los clientes en 5 grupos diferentes según su comportamiento en los pedidos y que generes estadísticas descriptivas respecto de cada grupo. Sin embargo, también deberás brindarles algunos pasos para poner en práctica en cada uno de estos grupos.
Con el objetivo de identificar estos clientes nuevos, usarás Gemini, Vertex AI y BigQuery para crear, visualizar y resumir un modelo de agrupamiento en clústeres de k-means con datos de comercio electrónico y, además, generar los próximos pasos útiles de una campaña de marketing. Este lab está dirigido a científicos de datos con diversos niveles de experiencia.
Ya se completó la configuración del entorno. Esto incluye habilitar Cloud AI Companion para Gemini y otorgarle a IAM los roles necesarios para usar Gemini. Para obtener más información, consulta la Descripción general de Gemini para Google Cloud.
Nota: Duet AI ahora se llama Gemini, nuestro modelo de nueva generación. Este lab se actualizó para reflejar este cambio. Cualquier referencia a Duet AI en la interfaz de usuario o la documentación debe considerarse equivalente a Gemini mientras sigues las instrucciones del lab.
Nota: Como tecnología en etapa inicial, Gemini puede generar resultados que parecen posibles, pero que no son correctos. Te recomendamos validar todos los resultados de Gemini antes de usarlos. Para obtener más información, consulta Gemini para Google Cloud y la IA responsable.
Objetivos
En este lab, aprenderás a realizar las siguientes tareas:
- Usar notebooks de Colab Enterprise de Python dentro de BigQuery Studio
- Usar BigQuery DataFrames dentro de BigQuery Studio
- Usar Gemini para generar código a partir de instrucciones en lenguaje natural
- Compilar un modelo de agrupamiento en clústeres de k-means
- Generar una visualización de los clústeres
- Usar el modelo de Gemini Pro para desarrollar los próximos pasos de una campaña de marketing
- Realizar una limpieza de los recursos del proyecto
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
En este lab práctico, se te proporcionarán credenciales temporales nuevas para acceder a Google Cloud y realizar las actividades en un entorno de nube real, no en uno de simulación o demostración.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
Nota: Usa una ventana de navegador privada o de incógnito para ejecutar el lab. Así evitarás cualquier conflicto entre tu cuenta personal y la cuenta de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
- Tiempo para completar el lab: Recuerda que, una vez que comienzas un lab, no puedes pausarlo.
Nota: Si ya tienes un proyecto o una cuenta personal de Google Cloud, no los uses en este lab para evitar cargos adicionales en tu cuenta.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá una ventana emergente para que selecciones tu forma de pago.
A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón Abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debes usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordena las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta.
-
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}}
También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}}
También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud.
Nota: Usar tu propia cuenta de Google Cloud para este lab podría generar cargos adicionales.
-
Haz clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.
Nota: Para ver un menú con una lista de productos y servicios de Google Cloud, haz clic en el menú de navegación que se encuentra en la parte superior izquierda.

Tarea 1. Crea un conjunto de datos de BigQuery para tu proyecto
En esta tarea, crearás el conjunto de datos de comercio electrónico en BigQuery. El conjunto de datos se usará para almacenar los datos de comercio electrónico que categorizarás en este lab.
-
En la consola de Google Cloud, selecciona el Menú de navegación ( )y, luego, BigQuery.
)y, luego, BigQuery.
Aparecerá la ventana emergente con el mensaje Te damos la bienvenida a BigQuery en la consola de Cloud.
-
Haz clic en Listo.
-
En el panel Explorador, en , selecciona Ver acciones ( ) y, luego, Crear conjunto de datos.
) y, luego, Crear conjunto de datos.
Crearás un conjunto de datos para almacenar objetos de base de datos, incluidos modelos y tablas.
-
En el panel Crear conjunto de datos, ingresa la información que se encuentra a continuación:
| Campo |
Valor |
| ID de conjunto de datos |
Comercio electrónico |
| Tipo de ubicación |
selecciona Multirregión
|
| Multirregión |
selecciona EE.UU. (varias regiones en Estados Unidos)
|
Deja los demás campos en la configuración predeterminada.
-
Haz clic en Crear conjunto de datos.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Crear un conjunto de datos de BigQuery para tu proyecto
Tarea 2. Crea un notebook nuevo de Python
En esta tarea, crearás un notebook de Python nuevo en BigQuery para poder usar Gemini en BigQuery. El notebook de Python es necesario en BigQuery para que puedas usar las bibliotecas de aprendizaje automático de Python. Estas bibliotecas te permitirán identificar clientes y categorizarlos en grupos según los datos de compras del conjunto de datos de comercio electrónico.
-
En la consola de Google Cloud, selecciona el menú de navegación () y, luego, BigQuery.
-
En la parte superior de la página, haz clic en la flecha hacia abajo que se encuentra junto al signo más.
-
Selecciona Notebook > Notebook vacío.
-
Selecciona la región para almacenar tus recursos de código en el menú desplegable y haz clic en Seleccionar.
-
En el panel Empezar con una plantilla, haz clic en Cerrar.
Tarea 3. Conéctate al entorno de ejecución de Colab Enterprise de BigQuery
El paso siguiente es conectarse al entorno de ejecución de Colab Enterprise en BigQuery. Considera este entorno de ejecución como un entorno administrado en BigQuery. Este te permite acceder a las bibliotecas de aprendizaje automático que pueden ayudarte a identificar tus clientes y categorizarlos en grupos.
-
Mientras estés en la consola de BigQuery Studio, en la esquina superior derecha del notebook, haz clic en la flecha hacia abajo junto a Conectar.
-
En el menú desplegable, selecciona Conectar a un entorno de ejecución.
-
Selecciona Crear un entorno de ejecución nuevo.
-
Selecciona Crear un entorno de ejecución predeterminado.
-
Haz clic en el ID de estudiante de Qwiklabs.
Nota: Espera unos minutos hasta que se asigne el entorno de ejecución. Luego, verás la actualización del estado de conexión como Conectado en la parte inferior de la ventana del navegador. También verás que se agregó el notebook de Python a la sección de notebooks del explorador en tu proyecto.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Conectarse al entorno de ejecución de Colab Enterprise de BigQuery
Tarea 4. Compila el notebook de Python
En esta tarea, comenzarás a compilar el notebook de Python y deberás seguir los pasos que se indican a continuación:
- Importar bibliotecas de Python
- Definir variables
- Crear e importar una tabla base como un BigQuery DataFrame a partir de un conjunto de datos públicos
- Generar el modelo de agrupamiento en clústeres de k-means y la visualización
Importa bibliotecas de Python y define variables
El primer paso para compilar el notebook de Python es importar bibliotecas de Python y definir variables.
Para importar las bibliotecas en tu notebook, sigue los pasos que se encuentran a continuación:
-
Agrega una celda de código al notebook, haz clic en el botón +Código que se encuentra en la parte superior de la ventana Notebook.
-
Pega el siguiente fragmento de código en la celda:
from google.cloud import bigquery
from google.cloud import aiplatform
import bigframes.pandas as bpd
import pandas as pd
from vertexai.language_models._language_models import TextGenerationModel
from vertexai.generative_models import GenerativeModel
from bigframes.ml.cluster import KMeans
from bigframes.ml.model_selection import train_test_split
-
Ejecuta  la celda.
la celda.
El entorno de ejecución cargará las bibliotecas de Python, lo que demorará aproximadamente 1 minuto. Comprueba el estado del entorno de ejecución en la parte inferior de la ventana del navegador para hacer un seguimiento del progreso.
Cuando haya finalizado, verás una marca de verificación verde  junto al botón Ejecutar en la celda.
junto al botón Ejecutar en la celda.
En la tabla que se encuentra a continuación, se proporciona más información sobre las bibliotecas de Python que acabas de importar a tu notebook, incluida una descripción breve de cada una.
| Biblioteca |
Descripción |
| BigQuery |
Es el cliente de Python para Google BigQuery. |
| AI Platform |
Es el SDK de Vertex AI para Python. |
| bigframes.pandas |
Permite trabajar con BigQuery DataFrames. |
| pandas |
Es una herramienta de análisis de datos de código abierto y manipulación, compilada sobre el lenguaje de programación de Python. |
| TextGenerationModel |
Crea un LanguageModel en Vertex AI. |
| Kmeans |
Se usa para crear modelos de agrupamiento en clústeres de k-means en BigQuery DataFrames. |
| train_test_split |
Se usa para dividir un conjunto de datos fuente en subconjuntos de entrenamiento y prueba, y para ajustar modelos en BigQuery DataFrames. |
Nota: Si quieres aprender más sobre cada biblioteca, usa el vínculo proporcionado.
Define variables e inicia la conexión de BigQuery y Vertex AI
A continuación, definirás variables e iniciarás la conexión de BigQuery y Vertex AI.
-
Agrega otra celda de código al final del notebook.
-
Pega el siguiente fragmento de código en la celda.
project_id = '<project_id>'
dataset_name = "ecommerce"
model_name = "customer_segmentation_model"
table_name = "customer_stats"
location = "<location>"
client = bigquery.Client(project=project_id)
aiplatform.init(project=project_id, location=location)
-
Reemplaza <project_id> por .
-
Reemplaza <location> por .
-
Ejecuta la celda.
Crea e importa la tabla ecommerce.customer_stats
A continuación, almacenarás datos del conjunto de datos públicos de BigQuery thelook_ecommerce en una tabla nueva con el nombre de customer_status en tu conjunto de datos de comercio electrónico.
-
Agrega otra celda de código al final del notebook.
-
Pega el siguiente fragmento de código en la celda.
%%bigquery
CREATE OR REPLACE TABLE ecommerce.customer_stats AS
SELECT
user_id,
DATE_DIFF(CURRENT_DATE(), CAST(MAX(order_created_date) AS DATE), day) AS days_since_last_order, ---RECENCY
COUNT(order_id) AS count_orders, --FREQUENCY
AVG(sale_price) AS average_spend --MONETARY
FROM (
SELECT
user_id,
order_id,
sale_price,
created_at AS order_created_date
FROM `bigquery-public-data.thelook_ecommerce.order_items`
WHERE
created_at
BETWEEN '2022-01-01' AND '2023-01-01'
)
GROUP BY user_id;
-
Ejecuta la celda.
Crea un BigQuery DataFrame y carga los datos con una instrucción de Gemini
En este paso, crearás un BigQuery DataFrame con una instrucción de Gemini y le cargarás los datos de estadísticas del cliente para que puedas procesar los datos más adelante con el modelo de agrupamiento en clústeres de k-means.
Nota: Como se mencionó al comienzo del lab, debes validar todos los resultados de Gemini antes de usarlos. Usa los ejemplos de código proporcionados para ayudarte. Sin embargo, no copies ni pegues el código tal como está, ya que es posible que no funcione en algunos casos. También te recomendamos que vuelvas a generar el código de Gemini para obtener un resultado más favorable.
-
Agrega otra celda de código al final del notebook.
-
Dentro de la celda, haz clic en generar. Esta acción te permite generar código con Gemini; además, verás una instrucción en la que puedes agregar texto.
-
Pega el siguiente texto en la instrucción.
Convert the table ecommerce.customer_stats to a bigframes dataframe and show the top 10 records
-
Haz clic en Generar. Gemini generará el código más abajo.
bqdf = client.read_gbq(f"{project_id}.{dataset_name}.{table_name}")
df.head(10)
Nota: Recuerda que, en un paso anterior, agregaste código a la celda número 2 del notebook que almacenó el ID del proyecto, el nombre del conjunto de datos y el nombre de la tabla como variables. Si completaste este paso, cuando ejecutes la celda en el paso siguiente, no tendrás problemas, y el DataFrame se creará con las 10 primeras filas que se muestran.
-
Vuelve a generar el código para que el resultado se vea similar al código que se muestra aquí:
bqdf = bpd.read_gbq(f"{project_id}.{dataset_name}.{table_name}")
bqdf.head(10)
-
Ejecuta la celda.
Verás el resultado de BigQuery DataFrame con las 10 primeras filas del conjunto de datos.
Genera el modelo de agrupamiento en clústeres de k-means
Ahora que tienes los datos del cliente en un BigQuery DataFrame, crearás un modelo de agrupamiento en clústeres de k-means para dividir los datos del cliente en clústeres con base en campos como compras recientes, número de pedidos y gastos. Luego, visualizarás estos grupos en un gráfico directamente en el notebook.
-
Agrega otra celda de código al final del notebook.
-
Haz clic en generar dentro de la celda. Esta acción te permitirá generar código con Gemini a partir de una instrucción.
-
Agrega la siguiente instrucción a la celda:
1. Split df (using random state and test size 0.2) into test and training data for a K-means clustering algorithm store these as df_test and df_train. 2. Create a K-means cluster model using bigframes.ml.cluster KMeans with 5 clusters. 3. Save the model using the to_gbq method where the model name is project_id.dataset_name.model_name.
-
Haz clic en Generar. Verás un resultado similar al siguiente:
#Instrucción: 1. Divide el DataFrame (usando random_state y test_size=0.2) en datos de prueba y entrenamiento para un algoritmo de clustering K-means; guarda estos como df_test y df_train. 2. Crea un modelo de clúster K-means usando bigframes.ml.cluster KMeans con 5 clústeres. 3. Guarda el modelo usando el método to_gbq, donde el nombre del modelo es project_id.dataset_name.model_name.
df_train, df_test = train_test_split(bq_df, test_size=0.2, random_state = 42)
kmeans = KMeans(n_clusters=5)
kmeans.fit(df_train)
kmeans.to_gbq(f"{project_id}.{dataset_name}.{model_name}")
-
Ejecuta la celda.
Nota: Este paso tardará aproximadamente 2 minutos en completarse.
¡Tu modelo ya está creado!
-
Actualiza el contenido de tu panel Explorador. Para eso, haz clic en los tres puntos que se encuentran junto al nombre de tu proyecto y selecciona Actualizar contenido. Debería aparecer como una ventana emergente en tu conjunto de datos de comercio electrónico.
A continuación, definirás un BigQuery DataFrame nuevo que una el clúster o segmento que produce el modelo de k-means con los datos originales.
-
Agrega otra celda de código al final del notebook.
-
Haz clic en generar dentro de la celda.
Esta acción te permitirá generar código con Gemini a partir de una instrucción.
-
Agrega la siguiente instrucción a la celda:
1. Call the K-means prediction model on the df dataframe, and store the results as predictions_df and show the first 10 records.
-
Haz clic en Generar. Verás un resultado similar al siguiente:
# Instrucción: 1. Llama al modelo de predicción K-means sobre el DataFrame df, guarda los resultados como predictions_df y muestra los primeros 10 registros.
predictions_df = kmeans.predict(df_test)
predictions_df.head(10)
-
Ejecuta la celda.
Verás que los primeros 10 registros se muestran con CENTROID_ID. CENTROID_ID es el clúster con el que se categorizará al cliente más adelante en el lab. También verás los campos user_id, days_since_last_order, count_orders y average_spend.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Generar el modelo de agrupamiento en clústeres de k-means.
Crea una visualización de los resultados del modelo de agrupamiento en clústeres de k-means
En este paso siguiente, crearás una visualización de los resultados del modelo de agrupamiento en clústeres de k-means. Específicamente, generarás un diagrama de dispersión con predictions_df para observar la relación que hay entre los días desde el último pedido con base en el gasto promedio, diferenciados por color según el segment_id (que se generó con nuestro modelo de k-means)
-
Agrega otra celda de código al final del notebook.
-
Haz clic en generar dentro de la celda.
Esta acción te permitirá generar código con Gemini a partir de una instrucción.
-
Agrega la siguiente instrucción a la celda:
1. Using predictions_df, and matplotlib, generate a scatterplot. 2. On the x-axis of the scatterplot, display days_since_last_order and on the y-axis, display average_spend from predictions_df. 3. Color by cluster. 4. The chart should be titled "Attribute grouped by K-means cluster."
-
Haz clic en Generar.
Verás un resultado similar al siguiente:
#Instrucción: 1. Usando predictions_df y matplotlib, genera un diagrama de dispersión. 2. En el eje x del diagrama, muestra days_since_last_order y en el eje y muestra average_spend de predictions_df. 3. Colorea por clúster. 4. 4. El gráfico debe titularse "Attribute grouped by K-means cluster".
import matplotlib.pyplot as plt
# Crea el diagrama de dispersión
plt.figure(figsize=(10, 6)) # Ajusta el tamaño de la figura si es necesario
plt.scatter(predictions_df['days_since_last_order'], predictions_df['average_spend'], c=predictions_df['cluster'], cmap='viridis')
# Personaliza el diagrama
plt.title('Attribute grouped by K-means cluster')
plt.xlabel('Days Since Last Order')
plt.ylabel('Average Spend')
plt.colorbar(label='Cluster ID')
# Muestra el diagrama
plt.show()
-
Reemplaza 'cluster' o 'cluster_id' por 'CENTROID_ID' solo en el campo c=predictions_df.
-
Ejecuta la celda.
Verás la visualización.
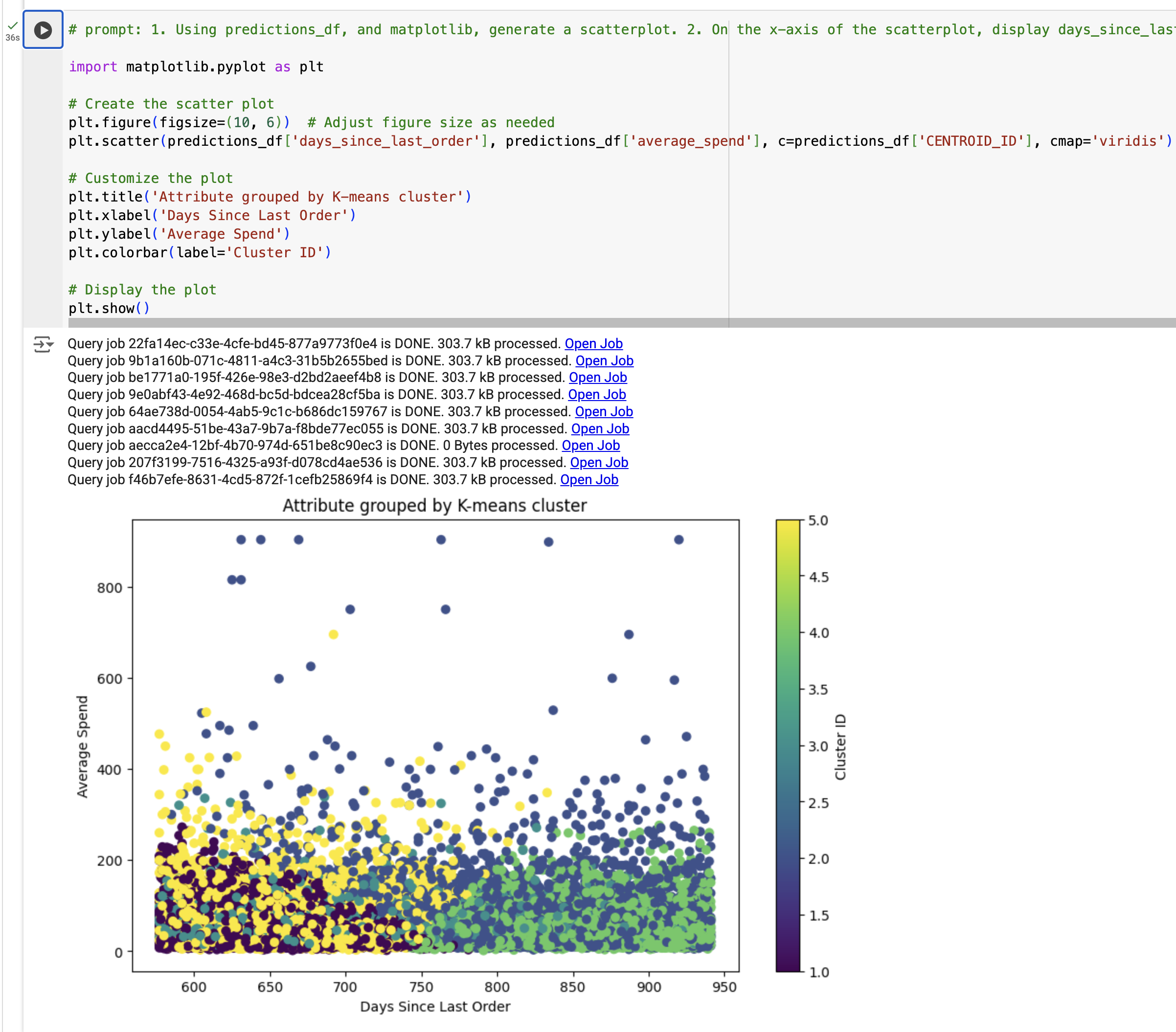
Nota: Si obtienes un TypeError, reemplaza el código por el resultado de ejemplo y, luego, ejecuta la celda.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Generar la visualización de los resultados del modelo de agrupamiento en clústeres de k-means
Tarea 5. Genera estadísticas a partir de los resultados del modelo
En esta tarea, generarás estadísticas a partir de los resultados del modelo con base en los pasos que se encuentran a continuación:
- Resumir cada clúster que se generó a partir del modelo de k-means
- Definir una instrucción para la campaña de marketing
- Generar la campaña de marketing con Gemini
Resumir cada clúster que se generó a partir del modelo de k-means
En este paso, resumirás cada clúster que se generó a partir del modelo de k-means.
-
Agrega otra celda de código al final del notebook.
-
Pega el siguiente fragmento de código en la celda:
query = """
SELECT
CONCAT('cluster ', CAST(centroid_id as STRING)) as centroid,
average_spend,
count_orders,
days_since_last_order
FROM (
SELECT centroid_id, feature, ROUND(numerical_value, 2) as value
FROM ML.CENTROIDS(MODEL `{0}.{1}`)
)
PIVOT (
SUM(value)
FOR feature IN ('average_spend', 'count_orders', 'days_since_last_order')
)
ORDER BY centroid_id
""".format(dataset_name, model_name)
df_centroid = client.query(query).to_dataframe()
df_centroid.head()
-
Ejecuta la celda.
Deberías ver los clústeres resumidos en una tabla. Algunas estadísticas que puedes obtener de esta tabla indican que algunos clústeres tienen un gasto promedio más alto, y otros tienen un número más alto de pedidos.
A continuación, convertirás el DataFrame en una cadena, para poder pasarlo a tu llamada de modelo de lenguaje grande.
-
Agrega otra celda de código al final del notebook.
-
Pega el siguiente fragmento de código en la celda:
df_query = client.query(query).to_dataframe()
df_query.to_string(header=False, index=False)
cluster_info = []
for i, row in df_query.iterrows():
cluster_info.append("{0}, average spend ${2}, count of orders per person {1}, days since last order {3}"
.format(row["centroid"], row["count_orders"], row["average_spend"], row["days_since_last_order"]) )
cluster_info = (str.join("\n", cluster_info))
print(cluster_info)
-
Ejecuta la celda.
El resultado debería ser similar al siguiente:
cluster 1, average spend $48.32, count of orders per person 1.36, days since last order 384.37
cluster 2, average spend $202.34, count of orders per person 1.3, days since last order 482.62
cluster 3, average spend $45.68, count of orders per person 1.36, days since last order 585.4
cluster 4, average spend $44.71, count of orders per person 1.36, days since last order 466.26
cluster 5, average spend $58.08, count of orders per person 3.92, days since last order 427.36
Genera la campaña de marketing con el modelo de Gemini
Creaste un modelo de k-means, asignaste cada cliente a un clúster del modelo y generaste estadísticas de resumen de cada clúster. En este paso, usarás Gemini para generar código a partir de una instrucción para crear una campaña de marketing, con estadísticas del cliente y los próximos pasos para nuestro equipo de marketing.
Por cada clúster o segmento que defina el modelo de k-means, generaremos tres elementos que nuestro equipo de marketing pueda usar:
- Título
- Arquetipo
- Próximo paso de marketing
-
Agrega otra celda de código al final del notebook.
-
Pega el siguiente fragmento de código en la celda:
model = GenerativeModel("gemini-2.5-pro")
prompt = f"""
You're a creative brand strategist, given the following clusters, come up with \
creative brand persona, a catchy title, and next marketing action, \
explained step by step. Identify the cluster number, the title of the person, a persona for them and the next marketing step.
Clusters:
{cluster_info}
For each Cluster:
* Title:
* Persona:
* Next marketing step:
"""
responses = model.generate_content(
prompt,
generation_config={
"temperature": 0.1,
"max_output_tokens": 4000,
"top_p": 1.0,
"top_k": 40,
}
)
print(responses.text)
-
Ejecuta la celda.
Deberías ver cada clúster con el título, el arquetipo y los próximos pasos.
**Cluster 1:**
* **Title:** The Lapsed Loyalists
* **Persona:** These customers have made a purchase in the past but haven't returned for an extended period. They likely had a positive experience but haven't been engaged recently.
* **Next Marketing Step:**
1. **Re-engagement campaign:** Send personalized emails or targeted ads reminding them of their previous purchase and highlighting new products or promotions that might interest them.
2. **Offer exclusive discounts or incentives:** Motivate them to return with special offers or loyalty rewards.
3. **Personalized product recommendations:** Leverage purchase history and browsing behavior to suggest relevant products they might be interested in.
**Cluster 2:**
* **Title:** The Occasional Treaters
* **Persona:** These customers make infrequent purchases but spend more when they do. They likely view the brand as a premium option for special occasions.
* **Next Marketing Step:**
1. **Highlight exclusivity and premium value:** Emphasize the unique features and benefits of your products to justify the higher price point.
2. **Offer limited-time promotions or bundles:** Encourage larger purchases with special deals on high-value items or curated product sets.
3. **Create a sense of urgency and scarcity:** Promote limited-edition products or flash sales to encourage immediate action.
**Cluster 3:**
* **Title:** The One-and-Done Buyers
* **Persona:** These customers have only made a single purchase and haven't returned. They might have had a neutral experience or haven't found a reason to come back.
* **Next Marketing Step:**
1. **Gather feedback:** Send post-purchase surveys to understand their experience and identify areas for improvement.
2. **Offer personalized recommendations:** Based on their initial purchase, suggest complementary products or accessories to encourage further engagement.
3. **Showcase customer testimonials and social proof:** Highlight positive reviews and user-generated content to build trust and encourage repeat purchases.
**Cluster 4:**
* **Title:** The Big Spenders
* **Persona:** These customers spend significantly more than others and are likely your most loyal and valuable segment. They appreciate high-quality products and personalized experiences.
* **Next Marketing Step:**
1. **Develop a VIP program:** Offer exclusive benefits, early access to new products, and personalized customer service to show appreciation and encourage continued loyalty.
2. **Personalized communication and offers:** Tailor your marketing messages and promotions to their specific interests and purchase history.
3. **Host exclusive events or experiences:** Create opportunities for them to connect with the brand and other high-value customers.
**Cluster 5:**
* **Title:** The Price-Conscious Shoppers
* **Persona:** These customers are primarily driven by price and make infrequent, low-value purchases. They are likely to compare prices and seek the best deals.
* **Next Marketing Step:**
1. **Promote competitive pricing and value-driven offers:** Highlight your competitive prices and bundle deals to attract price-sensitive customers.
2. **Offer free shipping or other incentives:** Reduce purchase barriers by offering free shipping or other attractive incentives.
3. **Focus on product benefits and value for money:** Emphasize the quality and functionality of your products to justify the price point.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Generar la campaña de marketing con Gemini
Tarea 6: Realiza una limpieza de los recursos del proyecto (opcional)
En este lab, creaste recursos en la consola de Google Cloud. En un entorno de producción, deberás quitar estos recursos de tu cuenta, debido a que ya no serán necesarios una vez que se recopilen las estadísticas del modelo. Para quitar los recursos de la cuenta y evitar otros cargos por su uso, tienes dos opciones:
- Quitar el proyecto (ver las precauciones a continuación)
- Quitar los recursos individuales
Quita el proyecto para realizar una limpieza de los recursos
Para evitar que se apliquen cargos a la cuenta de Google Cloud por los recursos que se usaron en el ejercicio, puedes borrar el proyecto de Google Cloud que creaste para este instructivo.
Precaución: Borrar un proyecto tiene las siguientes consecuencias:
- Se borra todo en el proyecto. Si usaste un proyecto existente para las tareas de este documento, cuando lo borres, también se borrará cualquier otro trabajo que hayas realizado en el proyecto.
- Se pierden los IDs personalizados del proyecto. Cuando creaste este proyecto, es posible que hayas creado un ID del proyecto personalizado que desees usar en el futuro. Para conservar las URLs que usan el ID del proyecto, como una URL de appspot.com, borra los recursos seleccionados dentro del proyecto en lugar de borrar todo el proyecto.
Si planeas explorar varios instructivos, arquitecturas o guías de inicio rápido, la reutilización de proyectos puede ayudarte a no exceder los límites de las cuotas de proyectos.
-
En la consola de Google Cloud, ve a la página IAM y administración > Administrar recursos.
-
En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
-
En el diálogo, escribe el ID del proyecto y, luego, haz clic en Apagar de todos modos para borrarlo.
Borra recursos individuales para realizar una limpieza de los recursos
Para evitar que se apliquen cargos, puedes borrar la tabla y el modelo que se usaron en este lab. Para eso, ejecuta el siguiente código en una celda de código nueva dentro del notebook:
# Elimina la tabla customer_stats
client.delete_table(f"{project_id}.{dataset_name}.{table_name}", not_found_ok=True)
print(f"Deleted table: {project_id}.{dataset_name}.{table_name}")
# Elimina el modelo K-means
client.delete_model(f"{project_id}.{dataset_name}.{model_name}", not_found_ok=True)
print(f"Deleted model: {project_id}.{dataset_name}.{model_name}")
Luego de ejecutar la celda, puedes actualizar el contenido de tu proyecto en BigQuery Studio para observar la eliminación de la tabla y el modelo.
¡Felicitaciones!
En este lab, aprendiste a realizar las siguientes tareas:
- Usar notebooks de Colab Enterprise de Python dentro de BigQuery Studio
- Usar BigQuery DataFrames dentro de BigQuery Studio
- Usar Gemini para generar código a partir de instrucciones en lenguaje natural
- Compilar un modelo de agrupamiento en clústeres de k-means
- Generar visualizaciones de los clústeres
- Usar Gemini para desarrollar los próximos pasos de una campaña de marketing
Lectura opcional
Ahora que definiste, categorizaste y ayudaste a desarrollar clientes para Cymbal Superstore con Gemini, Vertex AI y BigQuery, si quieres obtener más información acerca de Gemini, consulta los vínculos que se encuentran a continuación:
Finalice su lab
Cuando haya completado su lab, haga clic en Finalizar lab. Qwiklabs quitará los recursos que usó y limpiará la cuenta por usted.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
- 1 estrella = Muy insatisfecho
- 2 estrellas = Insatisfecho
- 3 estrellas = Neutral
- 4 estrellas = Satisfecho
- 5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Actualización más reciente del manual: 3 de septiembre de 2025
Prueba más reciente del lab: 3 de septiembre de 2025
Copyright 2024 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.





