Übersicht
In diesem Lab arbeiten Sie als Data Scientist für Cymbal Superstore und werden gebeten, das Marketingteam beim Identifizieren, Kategorisieren und Gewinnen von Neukunden zu unterstützen. Das Führungsteam möchte, dass Sie die Kunden anhand ihres Bestellverhaltens in fünf verschiedene Gruppen einteilen und aussagekräftige Statistiken zu jeder Gruppe erstellen. Sie haben außerdem vor, weitere Maßnahmen für die verschiedenen Kundengruppen zu empfehlen.
Anhand von Gemini, Vertex AI und BigQuery erstellen, visualisieren und fassen Sie in dieser Aufgabe ein K-Means-Clusteringmodell mit E-Commerce-Daten zusammen, um Neukunden zu identifizieren und verschiedene Schritte einer Marketingkampagne zu definieren. Dieses Lab richtet sich an Data Scientists aller Erfahrungsstufen.
Die Umgebung wurde bereits für Sie konfiguriert. Dazu gehören auch das Aktivieren von Cloud AI Companion für Gemini und das Gewähren der erforderlichen IAM-Rollen für die Verwendung von Gemini. Weitere Informationen finden Sie unter Gemini for Google Cloud – Übersicht.
Hinweis: Duet AI wurde umbenannt in Gemini, unser Modell der nächsten Generation. Dieses Lab wurde dementsprechend angepasst. Referenzen zu Duet AI in der Benutzeroberfläche oder Dokumentation sollten als Referenzen zu Gemini behandelt werden. Die Lab-Anweisungen bleiben ansonsten unverändert.
Hinweis: Da es sich bei Gemini um eine Technologie im Frühstadium handelt, kann es zu Ergebnissen kommen, die zwar plausibel erscheinen, aber faktisch falsch sind. Ausgaben von Gemini sollten daher vor der Verwendung geprüft werden. Weitere Informationen finden Sie unter Gemini für Google Cloud und verantwortungsbewusste Anwendung von KI.
Lernziele
Aufgaben in diesem Lab:
- Colab Enterprise-Python-Notebooks in BigQuery Studio verwenden
- BigQuery DataFrames in BigQuery Studio verwenden
- Mit Gemini und Prompts in natürlicher Sprache Code generieren
- K‑Means-Clusteringmodell erstellen
- Cluster visualisieren
- Mithilfe des Gemini Pro-Modells die nächsten Schritte einer Marketingkampagne entwickeln
- Projektressourcen bereinigen
Einrichtung und Anforderungen
Vor dem Klick auf „Lab starten“
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange die Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung selbst durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
Hinweis: Nutzen Sie den privaten oder Inkognitomodus, um dieses Lab durchzuführen. So wird verhindert, dass es zu Konflikten zwischen Ihrem persönlichen Konto und dem Teilnehmerkonto kommt und zusätzliche Gebühren für Ihr persönliches Konto erhoben werden.
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Hinweis: Wenn Sie über ein persönliches Google Cloud-Konto oder -Projekt verfügen, verwenden Sie es nicht für dieses Lab. So werden zusätzliche Kosten für Ihr Konto vermieden.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Pop-up-Fenster geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
Auf der linken Seite befindet sich der Bereich Details zum Lab mit diesen Informationen:
- Schaltfläche Google Cloud Console öffnen
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite Anmelden geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden.
-
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}}
Sie finden den Nutzernamen auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}}
Sie finden das Passwort auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos.
Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen.
-
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.
Hinweis: Wenn Sie eine Liste der Google Cloud-Produkte und ‑Dienste aufrufen möchten, klicken Sie oben links auf das Navigationsmenü.

Aufgabe 1: BigQuery-Dataset für Ihr Projekt erstellen
In dieser Aufgabe erstellen Sie das E‑Commerce-Dataset in BigQuery. Es dient dazu, die E‑Commerce-Daten zu speichern, die Sie in diesem Lab kategorisieren.
-
Klicken Sie in der Google Cloud Console auf das Navigationsmenü ( ) und dann auf BigQuery.
) und dann auf BigQuery.
Das Pop-up-Fenster „Willkommen bei BigQuery in der Cloud Console“ wird angezeigt.
-
Klicken Sie auf Fertig.
-
Wählen Sie im Bereich Explorer unter die Option Aktionen ansehen ( ) und dann Dataset erstellen.
) und dann Dataset erstellen.
Sie erstellen ein Dataset, um Datenbankobjekte zu speichern, einschließlich Tabellen und Modelle.
-
Geben Sie im Bereich Dataset erstellen die folgenden Informationen ein:
| Feld |
Wert |
| Dataset-ID |
ecommerce |
| Standorttyp |
Multiregional auswählen |
| Mehrere Regionen |
USA (mehrere Regionen in den USA) auswählen |
Übernehmen Sie für alle anderen Felder die Standardeinstellung.
-
Klicken Sie auf Dataset erstellen.
Klicken Sie auf Fortschritt prüfen.
BigQuery-Dataset für Ihr Projekt erstellen
Aufgabe 2: Neues Python-Notebook erstellen
In dieser Aufgabe erstellen Sie ein neues Python-Notebook in BigQuery, damit Sie Gemini in BigQuery verwenden können. Mit dem Python-Notebook in BigQuery können Sie Python-ML-Bibliotheken nutzen. So können Sie basierend auf E‑Commerce-Daten zum Kaufverhalten Kunden identifizieren und kategorisieren.
-
Klicken Sie in der Google Cloud Console auf das Navigationsmenü () und dann auf BigQuery.
-
Klicken Sie oben auf der Seite neben dem Pluszeichen auf den Abwärtspfeil.
-
Wählen Sie Notebook > Leeres Notebook aus.
-
Wählen Sie im Drop-down-Menü die Region zum Speichern der Code-Assets aus und klicken Sie auf Auswählen.
-
Klicken Sie im Bereich Mit einer Vorlage beginnen auf Schließen.
Aufgabe 3: Verbindung zur Colab Enterprise-Laufzeit in BigQuery herstellen
Im nächsten Schritt stellen Sie eine Verbindung zur Colab Enterprise-Laufzeit in BigQuery her. Diese Laufzeitumgebung funktioniert hier wie eine verwaltete Umgebung in BigQuery für den Zugriff auf ML-Bibliotheken, mit denen sich Kunden identifizieren und kategorisieren lassen.
-
Klicken Sie in der BigQuery Studio Console in der oberen rechten Ecke des Notebooks auf den Abwärtspfeil neben „Verbinden“.
-
Wählen Sie im Drop-down-Menü Mit einer Laufzeit verbinden aus.
-
Wählen Sie Neue Laufzeit erstellen aus.
-
Wählen Sie Standardlaufzeit erstellen aus.
-
Klicken Sie auf die Qwiklabs-Teilnehmer-ID.
Hinweis: Es dauert ein paar Minuten, bis die Laufzeit zugewiesen ist. Unten im Browserfenster wird nun als Verbindungsstatus „Verbunden“ angezeigt. Außerdem wurde das Python-Notebook im Abschnitt „Notebooks“ des Explorers unter Ihrem Projekt hinzugefügt.
Klicken Sie auf Fortschritt prüfen.
Verbindung zur Colab Enterprise-Laufzeit in BigQuery herstellen
Aufgabe 4: Python-Notebook erstellen
In dieser Aufgabe beginnen Sie mit dem Erstellen des Python-Notebooks und führen dazu die folgenden Schritte aus:
- Python-Bibliotheken importieren
- Variablen definieren
- Basistabelle erstellen und als BigQuery DataFrame aus einem öffentlichen Dataset importieren
- K‑Means-Clusteringmodell und Visualisierung erstellen
Python-Bibliotheken importieren und Variablen definieren
Der erste Schritt zum Erstellen des Python-Notebooks ist der Import von Python-Bibliotheken und das Definieren von Variablen.
So importieren Sie die Bibliotheken in Ihr Notebook:
-
Fügen Sie eine Codezelle zum Notebook hinzu, indem Sie oben im Notebookfenster auf +Code klicken.
-
Fügen Sie das folgende Code-Snippet in die Zelle ein:
from google.cloud import bigquery
from google.cloud import aiplatform
import bigframes.pandas as bpd
import pandas as pd
from vertexai.language_models._language_models import TextGenerationModel
from vertexai.generative_models import GenerativeModel
from bigframes.ml.cluster import KMeans
from bigframes.ml.model_selection import train_test_split
-
Führen Sie die Zelle aus ( ).
).
Die Laufzeit lädt die Python-Bibliotheken. Dieser Vorgang dauert etwa eine Minute. Sie können den Fortschritt verfolgen, indem Sie den Status der Laufzeit unten im Browserfenster prüfen.
Nach Abschluss des Ladevorgangs wird neben der Schaltfläche „Ausführen“ für die Zelle ein grünes Häkchen ( ) angezeigt.
) angezeigt.
Die folgende Tabelle enthält weitere Informationen zu den Python-Bibliotheken, die Sie gerade in Ihr Notebook importiert haben, einschließlich einer kurzen Beschreibung.
| Bibliothek |
Beschreibung |
| BigQuery |
Python-Client für Google BigQuery |
| AI Platform |
Vertex AI SDK for Python |
| bigframes.pandas |
BigQuery DataFrames |
| pandas |
Open-Source-Tool für Datenanalyse und ‑bearbeitung, das für die Programmiersprache Python ausgelegt ist |
| TextGenerationModel |
Erstellt ein Language Model in Vertex AI |
| Kmeans |
Dient dem Erstellen von K‑Means-Clusteringmodellen in BigQuery DataFrames |
| train_test_split |
Dient dem Aufteilen des Quell-Datasets in Test‑ und Trainingsdaten; wird zur Modellabstimmung in BigQuery DataFrames verwendet |
Hinweis: Über die Links finden Sie weitere Informationen zu den jeweiligen Bibliotheken.
Variablen definieren und Verbindung zwischen BigQuery und Vertex AI herstellen
Als Nächstes definieren Sie Variablen und stellen die Verbindung zwischen BigQuery und Vertex AI her.
-
Fügen Sie am Ende des Notebooks eine weitere Codezelle hinzu.
-
Fügen Sie das folgende Code-Snippet in die Zelle ein:
project_id = '<project_id>'
dataset_name = "ecommerce"
model_name = "customer_segmentation_model"
table_name = "customer_stats"
location = "<location>"
client = bigquery.Client(project=project_id)
aiplatform.init(project=project_id, location=location)
-
Ersetzen Sie <project_id> durch .
-
Ersetzen Sie <location> durch .
-
Führen Sie die Zelle aus ().
Tabelle „ecommerce.customer_stats“ erstellen und importieren
Als Nächstes speichern Sie Daten aus dem öffentlichen BigQuery-Dataset „thelook_ecommerce“ in einer neuen Tabelle namens „customer_status“ in Ihrem E‑Commerce-Dataset.
-
Fügen Sie am Ende des Notebooks eine weitere Codezelle hinzu.
-
Fügen Sie das folgende Code-Snippet in die Zelle ein:
%%bigquery
CREATE OR REPLACE TABLE ecommerce.customer_stats AS
SELECT
user_id,
DATE_DIFF(CURRENT_DATE(), CAST(MAX(order_created_date) AS DATE), day) AS days_since_last_order, ---RECENCY
COUNT(order_id) AS count_orders, --FREQUENCY
AVG(sale_price) AS average_spend --MONETARY
FROM (
SELECT
user_id,
order_id,
sale_price,
created_at AS order_created_date
FROM `bigquery-public-data.thelook_ecommerce.order_items`
WHERE
created_at
BETWEEN '2022-01-01' AND '2023-01-01'
)
GROUP BY user_id;
-
Führen Sie die Zelle aus ().
BigQuery DataFrame erstellen und Daten mithilfe eines Gemini-Prompts laden
In diesem Schritt erstellen Sie mithilfe eines Gemini-Prompts ein BigQuery DataFrame und laden Daten zu Kundenstatistiken, damit Sie diese später mit dem K‑Means-Clusteringmodell verarbeiten können.
Hinweis: Wie bereits zu Beginn des Labs erwähnt, müssen Sie alle Ausgaben von Gemini prüfen, bevor Sie sie verwenden. Sie können die bereitgestellten Codebeispiele als Orientierungshilfe verwenden. Kopieren Sie den Code jedoch nicht einfach, da dieser in einigen Fällen möglicherweise nicht funktioniert. Sie können den Code von Gemini auch neu generieren lassen, um eine bessere Ausgabe zu erhalten.
-
Fügen Sie am Ende des Notebooks eine weitere Codezelle hinzu.
-
Klicken Sie in der Zelle auf Generieren. So können Sie Code mit Gemini erstellen und Ihnen wird ein Prompt angezeigt, in dem Sie Text hinzufügen können.
-
Fügen Sie den folgenden Text in den Prompt ein:
Convert the table ecommerce.customer_stats to a bigframes dataframe and show the top 10 records
-
Klicken Sie auf Generieren. Gemini erstellt den folgenden Code:
bqdf = client.read_gbq(f"{project_id}.{dataset_name}.{table_name}")
df.head(10)
Hinweis: In einem vorherigen Schritt haben Sie in Notebook-Zelle 2 Code eingefügt und somit die Projekt-ID sowie den Dataset- und Tabellennamen als Variablen gespeichert. Wenn Sie diesen Schritt erledigt haben und die Zelle im nächsten Schritt ausführen, wird das DataFrame anhand der ersten zehn angezeigten Zeilen erstellt.
-
Generieren Sie den Code neu. Die Ausgabe soll in etwa so aussehen:
bqdf = bpd.read_gbq(f"{project_id}.{dataset_name}.{table_name}")
bqdf.head(10)
-
Führen Sie die Zelle aus ().
Ihnen wird die BigQuery DataFrame-Ausgabe mit den ersten zehn Zeilen des Datasets angezeigt.
K‑Means-Clusteringmodell erstellen
Die Kundendaten sind nun in ein BigQuery DataFrame übertragen. Als Nächstes erstellen Sie ein K‑Means-Clusteringmodell, um die Kundendaten in Cluster zu strukturieren. Diese Aufteilung soll auf Feldern basieren, wie etwa Aktualität und Anzahl der Bestellungen oder Ausgaben. Anschließend visualisieren Sie Kundengruppen in einem Notebook-Diagramm.
-
Fügen Sie am Ende des Notebooks eine weitere Codezelle hinzu.
-
Klicken Sie in der Zelle auf Generieren. So können Sie mithilfe eines Prompts Code mit Gemini erstellen.
-
Fügen Sie den folgenden Prompt in die Zelle ein:
1. Split df (using random state and test size 0.2) into test and training data for a K-means clustering algorithm store these as df_test and df_train. 2. Create a K-means cluster model using bigframes.ml.cluster KMeans with 5 clusters. 3. Save the model using the to_gbq method where the model name is project_id.dataset_name.model_name.
-
Klicken Sie auf Generieren. Es wird eine Ausgabe angezeigt, die in etwa so aussieht:
#prompt: 1. Split df (using random state and test size 0.2) into test and training data for a K-means clustering algorithm store these as df_test and df_train. 2. Create a K-means cluster model using bigframes.ml.cluster KMeans with 5 clusters. 3. Save the model using the to_gbq method where the model name is project_id.dataset_name.model_name.
df_train, df_test = train_test_split(bq_df, test_size=0.2, random_state = 42)
kmeans = KMeans(n_clusters=5)
kmeans.fit(df_train)
kmeans.to_gbq(f"{project_id}.{dataset_name}.{model_name}")
-
Führen Sie die Zelle aus ().
Hinweis: Dieser Vorgang dauert etwa zwei Minuten.
Ihr Modell wurde erstellt.
-
Aktualisieren Sie die Anzeige im Explorer, indem Sie auf das Dreipunkt-Menü neben dem Projektnamen klicken und Inhalte aktualisieren auswählen. Der aktualisierte Inhalt wird unter dem E‑Commerce-Dataset angezeigt.
Als Nächstes definieren Sie ein neues BigQuery DataFrame, das das vom K‑Means-Modell erstellte Segment bzw. den Cluster mit den ursprünglichen Daten verbindet.
-
Fügen Sie am Ende des Notebooks eine weitere Codezelle hinzu.
-
Klicken Sie in der Zelle auf Generieren.
So können Sie mithilfe eines Prompts Code mit Gemini erstellen.
-
Fügen Sie den folgenden Prompt in die Zelle ein:
1. Call the K-means prediction model on the df dataframe, and store the results as predictions_df and show the first 10 records.
-
Klicken Sie auf Generieren. Es wird eine Ausgabe angezeigt, die in etwa so aussieht:
# prompt: 1. Call the K-means prediction model on the df dataframe, and store the results as predictions_df and show the first 10 records.
predictions_df = kmeans.predict(df_test)
predictions_df.head(10)
-
Führen Sie die Zelle aus ().
Die ersten zehn Einträge werden mit der CENTROID_ID angezeigt. CENTROID_ID ist der Cluster, der im weiteren Verlauf dieses Labs zur Kategorisierung von Kunden verwendet wird. Außerdem sehen Sie die Felder „user_id“, „days_since_last_order“, „count_orders“ und „average_spend“.
Klicken Sie auf Fortschritt prüfen.
K‑Means-Clusteringmodell erstellen
Visualisierung der Ergebnisse des K‑Means-Clusteringmodells erstellen
Im nächsten Schritt visualisieren Sie die Ergebnisse des K‑Means-Clusteringmodells. Dazu generieren Sie anhand von predictions_df ein Streudiagramm, um die Beziehung zwischen „Tagen seit letzter Bestellung“ und „Durchschnittsausgaben“ in verschiedenen Farben je nach segment_id darzustellen. Die jeweilige segment_id haben Sie zuvor mit dem K‑Means-Modell erstellt.
-
Fügen Sie am Ende des Notebooks eine weitere Codezelle hinzu.
-
Klicken Sie in der Zelle auf Generieren.
So können Sie mithilfe eines Prompts Code mit Gemini erstellen.
-
Fügen Sie den folgenden Prompt in die Zelle ein:
1. Using predictions_df, and matplotlib, generate a scatterplot. 2. On the x-axis of the scatterplot, display days_since_last_order and on the y-axis, display average_spend from predictions_df. 3. Color by cluster. 4. The chart should be titled "Attribute grouped by K-means cluster."
-
Klicken Sie auf Generieren.
Es wird eine Ausgabe angezeigt, die in etwa so aussieht:
#prompt: 1. Using predictions_df, and matplotlib, generate a scatterplot. 2. On the x-axis of the scatterplot, display days_since_last_order and on the y-axis, display average_spend from predictions_df. 3. Color by cluster. 4. The chart should be titled "Attribute grouped by K-means cluster."
import matplotlib.pyplot as plt
# Create the scatter plot
plt.figure(figsize=(10, 6)) # Adjust figure size as needed
plt.scatter(predictions_df['days_since_last_order'], predictions_df['average_spend'], c=predictions_df['cluster'], cmap='viridis')
# Customize the plot
plt.title('Attribute grouped by K-means cluster')
plt.xlabel('Days Since Last Order')
plt.ylabel('Average Spend')
plt.colorbar(label='Cluster ID')
# Display the plot
plt.show()
-
Ersetzen Sie nur im Feld c=predictions_df den Wert 'cluster' oder 'cluster_id' durch 'CENTROID_ID'.
-
Führen Sie die Zelle aus ().
Sehen Sie sich die Visualisierung an.
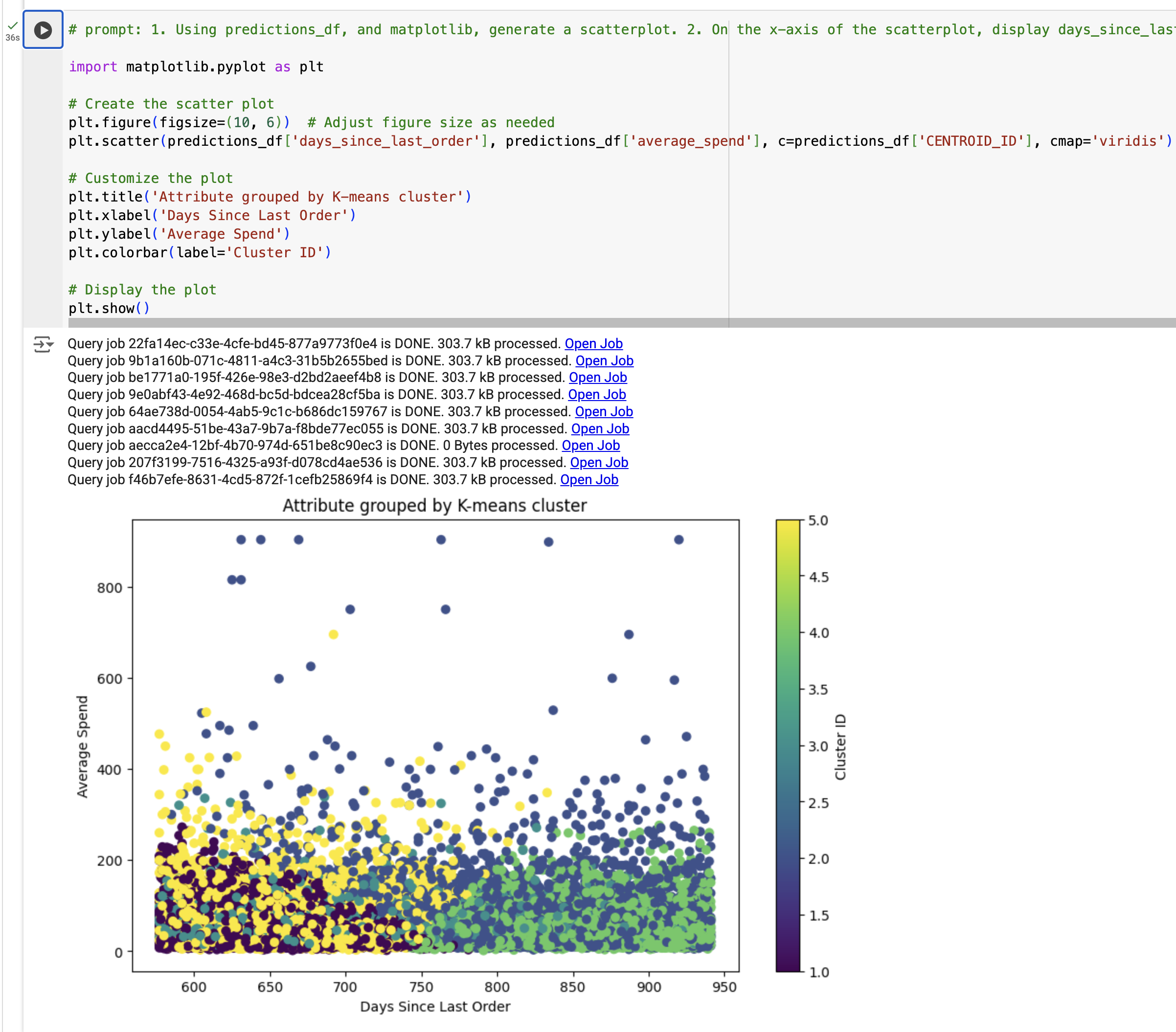
Hinweis: Wenn Ihnen TypeError angezeigt wird, ersetzen Sie den Code durch die Beispielausgabe und führen Sie die Zelle aus.
Klicken Sie auf Fortschritt prüfen.
Visualisierung aus den Ergebnissen des K‑Means-Clusteringmodells erstellen
Aufgabe 5: Aus den Ergebnissen des Modells Insights generieren
In dieser Aufgabe generieren Sie aus den Ergebnissen des Modells Insights, indem Sie die folgenden Schritte ausführen:
- Alle aus dem K‑Means-Modell erstellten Cluster zusammenfassen
- Prompt für die Marketingkampagne definieren
- Marketingkampagne mit Gemini erstellen
Alle aus dem K‑Means-Modell erstellten Cluster zusammenfassen
In diesem Schritt fassen Sie die Cluster zusammen, die anhand des K‑Means-Modells erstellt wurden.
-
Fügen Sie am Ende des Notebooks eine weitere Codezelle hinzu.
-
Fügen Sie das folgende Code-Snippet in die Zelle ein:
query = """
SELECT
CONCAT('cluster ', CAST(centroid_id as STRING)) as centroid,
average_spend,
count_orders,
days_since_last_order
FROM (
SELECT centroid_id, feature, ROUND(numerical_value, 2) as value
FROM ML.CENTROIDS(MODEL `{0}.{1}`)
)
PIVOT (
SUM(value)
FOR feature IN ('average_spend', 'count_orders', 'days_since_last_order')
)
ORDER BY centroid_id
""".format(dataset_name, model_name)
df_centroid = client.query(query).to_dataframe()
df_centroid.head()
-
Führen Sie die Zelle aus ().
Die Cluster sollten jetzt in einer Tabelle zusammengefasst sein. Daraus können Sie unter anderem ablesen, dass manche Cluster höhere durchschnittliche Ausgaben aufweisen, andere dagegen eine höhere Anzahl an Bestellungen.
Als Nächstes wandeln Sie den Datenframe in einen String um, um ihn an den Large-Language-Model-Aufruf übergeben zu können.
-
Fügen Sie am Ende des Notebooks eine weitere Codezelle hinzu.
-
Fügen Sie das folgende Code-Snippet in die Zelle ein:
df_query = client.query(query).to_dataframe()
df_query.to_string(header=False, index=False)
cluster_info = []
for i, row in df_query.iterrows():
cluster_info.append("{0}, average spend ${2}, count of orders per person {1}, days since last order {3}"
.format(row["centroid"], row["count_orders"], row["average_spend"], row["days_since_last_order"]) )
cluster_info = (str.join("\n", cluster_info))
print(cluster_info)
-
Führen Sie die Zelle aus ().
Die Ausgabe sollte in etwa so aussehen:
cluster 1, average spend $48.32, count of orders per person 1.36, days since last order 384.37
cluster 2, average spend $202.34, count of orders per person 1.3, days since last order 482.62
cluster 3, average spend $45.68, count of orders per person 1.36, days since last order 585.4
cluster 4, average spend $44.71, count of orders per person 1.36, days since last order 466.26
cluster 5, average spend $58.08, count of orders per person 3.92, days since last order 427.36
Mit dem Gemini-Modell eine Marketingkampagne erstellen
Sie haben ein K‑Means-Modell angelegt, jeden Kunden einem Cluster des Modells zugewiesen und eine zusammenfassende Statistik für jeden Cluster erstellt. In diesem Schritt verwenden Sie Gemini, um aus einem Prompt Code zu generieren, mit dem Sie eine Marketingkampagne erstellen können – inklusive Insights zu den Kunden und Handlungsempfehlungen für das Marketingteam.
Sie erstellen für jeden durch das K‑Means-Modell definierten Cluster bzw. jedes Segment drei Elemente, die vom Marketingteam verwendet werden können:
- Titel
- Rolle
- Nächster Marketingschritt
-
Fügen Sie am Ende des Notebooks eine weitere Codezelle hinzu.
-
Fügen Sie das folgende Code-Snippet in die Zelle ein:
model = GenerativeModel("gemini-2.5-pro")
prompt = f"""
You're a creative brand strategist, given the following clusters, come up with \
creative brand persona, a catchy title, and next marketing action, \
explained step by step. Identify the cluster number, the title of the person, a persona for them and the next marketing step.
Clusters:
{cluster_info}
For each Cluster:
* Title:
* Persona:
* Next marketing step:
"""
responses = model.generate_content(
prompt,
generation_config={
"temperature": 0.1,
"max_output_tokens": 4000,
"top_p": 1.0,
"top_k": 40,
}
)
print(responses.text)
-
Führen Sie die Zelle aus ().
Sie sollten jeden Cluster mit Titel, Persona und nächsten Schritten sehen.
**Cluster 1:**
* **Title:** The Lapsed Loyalists
* **Persona:** These customers have made a purchase in the past but haven't returned for an extended period. They likely had a positive experience but haven't been engaged recently.
* **Next Marketing Step:**
1. **Re-engagement campaign:** Send personalized emails or targeted ads reminding them of their previous purchase and highlighting new products or promotions that might interest them.
2. **Offer exclusive discounts or incentives:** Motivate them to return with special offers or loyalty rewards.
3. **Personalized product recommendations:** Leverage purchase history and browsing behavior to suggest relevant products they might be interested in.
**Cluster 2:**
* **Title:** The Occasional Treaters
* **Persona:** These customers make infrequent purchases but spend more when they do. They likely view the brand as a premium option for special occasions.
* **Next Marketing Step:**
1. **Highlight exclusivity and premium value:** Emphasize the unique features and benefits of your products to justify the higher price point.
2. **Offer limited-time promotions or bundles:** Encourage larger purchases with special deals on high-value items or curated product sets.
3. **Create a sense of urgency and scarcity:** Promote limited-edition products or flash sales to encourage immediate action.
**Cluster 3:**
* **Title:** The One-and-Done Buyers
* **Persona:** These customers have only made a single purchase and haven't returned. They might have had a neutral experience or haven't found a reason to come back.
* **Next Marketing Step:**
1. **Gather feedback:** Send post-purchase surveys to understand their experience and identify areas for improvement.
2. **Offer personalized recommendations:** Based on their initial purchase, suggest complementary products or accessories to encourage further engagement.
3. **Showcase customer testimonials and social proof:** Highlight positive reviews and user-generated content to build trust and encourage repeat purchases.
**Cluster 4:**
* **Title:** The Big Spenders
* **Persona:** These customers spend significantly more than others and are likely your most loyal and valuable segment. They appreciate high-quality products and personalized experiences.
* **Next Marketing Step:**
1. **Develop a VIP program:** Offer exclusive benefits, early access to new products, and personalized customer service to show appreciation and encourage continued loyalty.
2. **Personalized communication and offers:** Tailor your marketing messages and promotions to their specific interests and purchase history.
3. **Host exclusive events or experiences:** Create opportunities for them to connect with the brand and other high-value customers.
**Cluster 5:**
* **Title:** The Price-Conscious Shoppers
* **Persona:** These customers are primarily driven by price and make infrequent, low-value purchases. They are likely to compare prices and seek the best deals.
* **Next Marketing Step:**
1. **Promote competitive pricing and value-driven offers:** Highlight your competitive prices and bundle deals to attract price-sensitive customers.
2. **Offer free shipping or other incentives:** Reduce purchase barriers by offering free shipping or other attractive incentives.
3. **Focus on product benefits and value for money:** Emphasize the quality and functionality of your products to justify the price point.
Klicken Sie auf Fortschritt prüfen.
Marketingkampagne mit Gemini erstellen
Aufgabe 6: Projektressourcen bereinigen (optional)
In diesem Lab haben Sie Ressourcen in der Google Cloud Console erstellt. In einer Produktionsumgebung werden diese Ressourcen aus dem Konto entfernt, da sie nach Erstellen der Insights nicht mehr benötigt werden. Sie haben zwei Möglichkeiten, die Ressourcen aus Ihrem Konto zu löschen und so weitere Kosten für deren Verwendung zu vermeiden:
- Projekt entfernen (siehe Hinweise unten)
- Einzelne Ressourcen entfernen
Ressourcen durch Entfernen des Projekts bereinigen
Wenn Sie vermeiden möchten, dass Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen in Rechnung gestellt werden, können Sie das dafür erstellte Google Cloud-Projekt löschen.
Achtung: Das Löschen von Projekten hat folgende Auswirkungen:
- Alle Inhalte des Projekts werden gelöscht. Wenn Sie für die Aufgaben in diesem Dokument ein bereits bestehendes Projekt verwendet haben und dieses löschen, werden auch alle anderen im Rahmen des Projekts erstellten Daten gelöscht.
- Benutzerdefinierte Projekt-IDs gehen verloren. Beim Erstellen dieses Projekts haben Sie möglicherweise eine benutzerdefinierte Projekt-ID erstellt, die Sie weiterhin verwenden möchten. Damit die URLs, die die Projekt-ID nutzen, z. B. eine appspot.com-URL, erhalten bleiben, sollten Sie ausgewählte Ressourcen innerhalb des Projekts löschen, anstatt das gesamte Projekt.
Wenn Sie weitere Architekturen, Tutorials oder Anleitungen nutzen möchten, können Sie vorhandene Projekte verwenden und somit vermeiden, Projektkontingente zu überschreiten.
-
Rufen Sie in der Google Cloud Console die Seite IAM und Verwaltung > Ressourcen verwalten auf.
-
Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
-
Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Trotzdem beenden, um das Projekt zu löschen.
Ressourcen durch Entfernen einzelner Ressourcen bereinigen
Zur Vermeidung von Gebühren können Sie die Tabelle und das Modell aus diesem Lab löschen, indem Sie den folgenden Code in einer neuen Codezelle des Notebooks ausführen:
# Delete customer_stats table
client.delete_table(f"{project_id}.{dataset_name}.{table_name}", not_found_ok=True)
print(f"Deleted table: {project_id}.{dataset_name}.{table_name}")
# Delete K-means model
client.delete_model(f"{project_id}.{dataset_name}.{model_name}", not_found_ok=True)
print(f"Deleted model: {project_id}.{dataset_name}.{model_name}")
Aktualisieren Sie nach dem Ausführen der Zelle den Inhalt Ihres Projekts in BigQuery Studio, um zu prüfen, ob die Tabelle und das Modell gelöscht wurden.
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
In diesem Lab haben Sie Folgendes gelernt:
- Colab Enterprise-Python-Notebooks in BigQuery Studio verwenden
- BigQuery DataFrames in BigQuery Studio verwenden
- Mit Gemini und Prompts in natürlicher Sprache Code generieren
- K‑Means-Clusteringmodell erstellen
- Cluster visualisieren
- Mit Gemini die nächsten Schritte einer Marketingkampagne entwickeln
Weiterführende Lektüre
Sie haben Cymbal Superstore mit Gemini, Vertex AI und BigQuery beim Identifizieren, Kategorisieren und Gewinnen von Neukunden unterstützt. Weitere Informationen zu Gemini finden Sie unter den folgenden Links:
Lab beenden
Wenn Sie das Lab abgeschlossen haben, klicken Sie auf Lab beenden. Qwiklabs entfernt daraufhin die von Ihnen genutzten Ressourcen und bereinigt das Konto.
Anschließend erhalten Sie die Möglichkeit, das Lab zu bewerten. Wählen Sie die entsprechende Anzahl von Sternen aus, schreiben Sie einen Kommentar und klicken Sie anschließend auf Senden.
Die Anzahl der Sterne hat folgende Bedeutung:
- 1 Stern = Sehr unzufrieden
- 2 Sterne = Unzufrieden
- 3 Sterne = Neutral
- 4 Sterne = Zufrieden
- 5 Sterne = Sehr zufrieden
Wenn Sie kein Feedback geben möchten, können Sie das Dialogfeld einfach schließen.
Verwenden Sie für Feedback, Vorschläge oder Korrekturen den Tab Support.
Anleitung zuletzt am 03. September 2025 aktualisiert
Lab zuletzt am 03. September 2025 getestet
© 2024 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.





