Checkpoints
Open the lab notebook and run each cell
/ 100
Generative AI for Video Analytics with Vertex AI
GSP1200

Overview
In today's data-driven world, understanding the perspectives of influencers is crucial for making informed business decisions. With Google's Generative AI capabilities, you can now harness the power of large language models (LLMs) to analyze influencer sentiment on YouTube, gaining valuable insights into brand perception, product reviews and industry trends.
Unleash the Power of Influencer Insights with Google's Generative AI
LLMs, trained on massive datasets of text and code, can effectively process, analyze, and interpret the opinions expressed by influencers on YouTube. By leveraging these advanced AI capabilities, you can:
-
Identify key influencers: Uncover the most influential voices in your industry, allowing you to focus your efforts on the most impactful individuals.
-
Analyze sentiment and opinions: Gauge the overall sentiment towards your company, products, or competitors, gaining insights into customer perceptions and market dynamics.
-
Track trends and emerging topics: Stay ahead of the curve by identifying emerging trends and topics that are being discussed by influencers, enabling you to adapt your strategies accordingly.
Harnessing Influencer Insights for Business Success
By understanding the views of influencers on YouTube, you can make informed decisions that drive business success. Here are some key applications:
-
Brand reputation management: Monitor influencer sentiment to identify and address potential reputational issues promptly.
-
Product development: Gather insights into product features and user experiences, informing product development decisions.
-
Marketing and communications: Craft effective marketing campaigns and communications that resonate with your target audience.
The YouTube video you will analyze is below:
What you will learn:
In this lab, you will use the PaLM 2 model in Vertex AI and LangChain to analyze a YouTube video in a jupyter notebook.
PaLM 2 is Google's next generation Large Language Model (LLM) that builds on Google's legacy of breakthrough research in machine learning and responsible AI. PaLM 2 excels at tasks like advanced reasoning, translation, and code generation because of how it was built.
LangChain is an open-source framework for developing applications powered by large language models (LLMs). It provides a modular and extensible architecture that makes it easy to combine LLMs with other data sources and tools to create powerful applications.
By the end of this lab, you will have an understanding of:
- Utilizing Vertex AI LLMs in a LangChain application or use case
- Loading video content from YouTube to create embeddings
- Using a vector search database to index embeddings
- How to use the Stuffing method to pass data to a LLM via prompt templates
Let's begin!
Setup and requirements
Before you click the Start Lab button
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources will be made available to you.
This hands-on lab lets you do the lab activities yourself in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials that you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
- Access to a standard internet browser (Chrome browser recommended).
- Time to complete the lab---remember, once you start, you cannot pause a lab.
How to start your lab and sign in to the Google Cloud console
-
Click the Start Lab button. If you need to pay for the lab, a pop-up opens for you to select your payment method. On the left is the Lab Details panel with the following:
- The Open Google Cloud console button
- Time remaining
- The temporary credentials that you must use for this lab
- Other information, if needed, to step through this lab
-
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
Note: If you see the Choose an account dialog, click Use Another Account. -
If necessary, copy the Username below and paste it into the Sign in dialog.
{{{user_0.username | "Username"}}} You can also find the Username in the Lab Details panel.
-
Click Next.
-
Copy the Password below and paste it into the Welcome dialog.
{{{user_0.password | "Password"}}} You can also find the Password in the Lab Details panel.
-
Click Next.
Important: You must use the credentials the lab provides you. Do not use your Google Cloud account credentials. Note: Using your own Google Cloud account for this lab may incur extra charges. -
Click through the subsequent pages:
- Accept the terms and conditions.
- Do not add recovery options or two-factor authentication (because this is a temporary account).
- Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.

Task 1. Vertex AI Workbench
In your Google Cloud project, navigate to Vertex AI Workbench. In the top search bar, enter Vertex AI Workbench of the Google Cloud console.

- Go to User-managed-notebooks.
- Click Open JupyterLab for
generative-ai-jupyterlab. - The JupyterLab will run in a new tab.

Task 2. Open the lab notebook
In the left hand menu navigation of the notebook:
- Double Click on the
youtube_analysis.ipynbfile. - Follow the steps in the notebook and run each cell one at a time. Where appropriate use the region:
to complete steps in the notebook. - After running the last cell of the notebook, refer back to the lab instructions to complete the task in the next section of this lab.

Click Check my progress to verify the objective.
Task 3. Submit a question to the LLM
Once the last cell of the notebook has been run successfully, you will see a user interface presented in the jupyter notebook. This is available through a python package called gradio which provides a user interface to integrate with machine learning models.
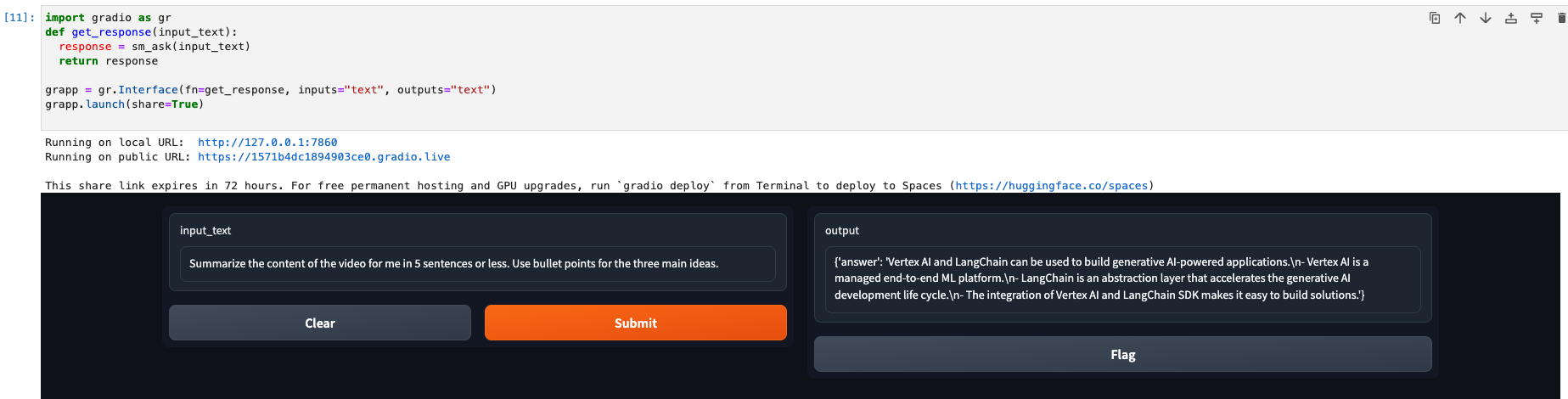
Enter the following question in the prompt input and observe the results.
The results will be similar to the output below:
Task 4. Notebook review
In this section, you will review key cells run in the notebook of this lab and review their importance.
- To begin you installed the required python packages for the notebook to function. These include
chromadb,gradio,pytube,youtube-transcript-api,pydantcandlangchainin addition to Google Cloud packages.
- You then initialized your project and imported
text-bison@001which is a Vertex AI LLM model used for a variety of natrual language tasks such as:
-
Summarization: Create a shorter version of a document that incorporates pertinent information from the original text. For example, you might want to summarize a chapter from a textbook. Or, you could create a succinct product description from a long paragraph that describes the product in detail. Question answering: Provide answers to questions in text. For example, you might automate the creation of a Frequently Asked Questions (FAQ) document from knowledge base content.
-
Sentiment analysis: This is a form of classification that identifies the sentiment of text. The sentiment is turned into a label that's applied to the text. For example, the sentiment of text might be polarities like positive or negative, or sentiments like anger or happiness.
-
Entity extraction: Extract a piece of information from text. For example, you can extract the name of a movie from the text of an article.
-
Classification: Assign a label to provided text. For example, a label might be applied to text that describes how grammatically correct it is.
-
Question answering: Provide answers to questions in text. For example, you might automate the creation of a Frequently Asked Questions (FAQ) document from knowledge base content.
-
Summarization: Create a shorter version of a document that incorporates pertinent information from the original text. For example, you might want to summarize a chapter from a textbook. Or, you could create a succinct product description from a long paragraph that describes the product in detail. Question answering: Provide answers to questions in text. For example, you might automate the creation of a Frequently Asked Questions (FAQ) document from knowledge base content.
The model is ideal for tasks that can be completed with one API response, without the need for continuous conversation. For text tasks that require back-and-forth interactions, use the Generative AI on Vertex AI API for chat.
- After initializing the Vertex AI LLM, you utilized the
VertexAIEmbeddingsLangChain library to convert video chunks to embeddings.
Chunking: in generative AI is the process of breaking down large content into smaller, manageable pieces or chunks. This is done because generative AI models have limits on how much data they can process at once. By chunking the data, the model can focus on one chunk at a time and generate more accurate and coherent outputs.
Embeddings: are a way of representing content as a vector of numbers. This allows computers to understand the meaning of data in a more sophisticated way than traditional methods, such as shot detection or keyframe extraction, if it's for videos and bag-of-words, if it's for language data.
- After initilizing the Vertex AI embedding, you use the YouTube loader library to load the video referenced and then split it into text documents for processing.
- After loading and chunking the video content, you store the documents in a local vector search database, in this case
ChromaDB, to retrieve vector embeddings for use with LLMs and to perform semantic search over the data. You can also use Vertex AI Vector Search for the same purposes.
- Next, a Retrieval QA Chain is created using the Stuffing methodology.
The Retreival QA Chain uses ChromaDB to retrieve embeddings and associates the text-bison@001 Vertex AI model with the retriever. The chain_type being set to stuff implies that the Stuffing prompt methodology is used for questions asked to the retriever.
Stuffing is the simplest method to pass data to a language model. It "stuffs" text into a prompt as context so that all of the relevant information can be processed by the model to get back meaninful results.
The prompt in the notebook is defined in the sm_ask python function call. Notice that the question and context parameters are passed into the prompt template at the time a question is asked to the large language model.
By using the method above, the prompt template is created by asking a question to the RetrievalQAChain setup earlier. The results are retrieved from the vector store and used as context in the prompt template.
Hence the term stuffed. The context is not reduced in size when used as an input to the prompt template, rather it is "stuffed" into the context parameter of the template.
The context is then utilized in the prompt template to retrieve results from the LLM which typically yields better results.
Congratulations!
You have now completed the lab! In this lab, you learned how to ask questions to a large language model using a LangChain application. By using the Stuffing method of document retrieval you were able to ask questions to the LLM using a prompt template that provides context with a question to get meaningful results.
Next steps
- Check out the Generative AI on Vertex AI documentation.
- Learn more about Generative AI on the Google Cloud Tech YouTube channel.
Google Cloud training and certification
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Updated June 12, 2024
Lab Last Tested June 12, 2024
Copyright 2024 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.