SCBL069
Visão geral
O escalonador automático do Cloud Spanner é uma ferramenta de código aberto que permite aumentar ou reduzir automaticamente a capacidade de computação em uma ou mais instâncias do Spanner com base na utilização.
O Cloud Spanner é um banco de dados relacional totalmente gerenciado com escala ilimitada, consistência forte e disponibilidade de até 99,999%.
Ao criar uma instância do Cloud Spanner, escolha o número de nós ou unidades de processamento que vão fornecer recursos de computação para a instância. Conforme a carga de trabalho da instância é alterada, o Cloud Spanner não ajusta automaticamente o número de nós ou unidades de processamento na instância.
O escalonador automático monitora as instâncias e adiciona ou remove automaticamente a capacidade de computação para garantir que elas permaneçam dentro dos valores máximos recomendados para a utilização da CPU e do limite recomendado de armazenamento por nó.
Neste laboratório, você vai implantar o escalonador automático na configuração por projeto. Nessa configuração de implantação, o escalonador automático está localizado no mesmo projeto que a instância do Cloud Spanner que está sendo escalonada automaticamente.
Arquitetura
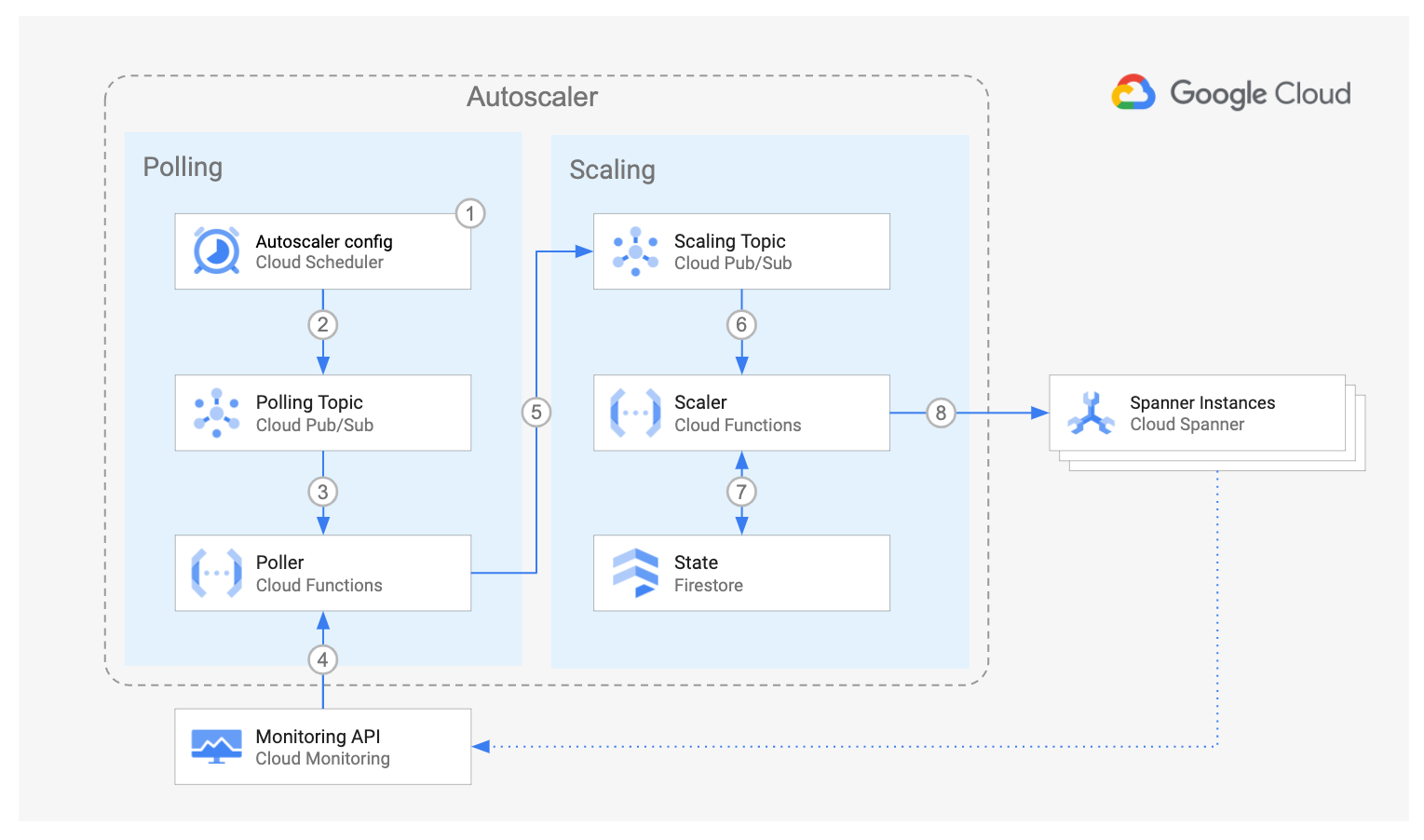
O diagrama acima mostra os componentes do escalonador automático do Cloud Spanner e o fluxo de interação:
-
O componente de pesquisa, composto pelo Cloud Scheduler, pelo Cloud Pub/Sub e pela função de pesquisa do Cloud Run, consulta a API Cloud Monitoring para recuperar as métricas de utilização de cada instância do Spanner. Para cada instância, a função de pesquisa envia uma mensagem ao tópico de escalonamento do Pub/Sub, contendo as métricas de utilização da instância específica do Spanner e alguns dos parâmetros de configuração correspondentes.
-
O componente Escalonador é composto pelo Cloud Pub/Sub, pela função de escalonamento do Cloud Run e pelo Cloud Firestore. Para cada mensagem, a função de escalonamento compara as métricas da instância do Spanner com os limites recomendados, mais ou menos uma margem permitida. Usando o método de escalonamento escolhido, ele determina se a instância precisa ser escalonada, e o número de nós ou unidades de processamento que ela precisa ter.
Durante o fluxo, o escalonador automático do Spanner cria um resumo detalhado das recomendações e ações no Cloud Logging para rastreamento e auditoria.
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça, depois de começar, não será possível pausar o laboratório.
Observação: não use seu projeto ou conta pessoal do Google Cloud neste laboratório para evitar cobranças extras.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento.
No painel Detalhes do laboratório à esquerda, você verá o seguinte:
- O botão Abrir Console do Cloud
- Tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações se forem necessárias
-
Clique em Abrir Console do Google.
O laboratório ativa recursos e depois abre outra guia com a página Fazer login.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Caso seja preciso, copie o Nome de usuário no painel Detalhes do laboratório e cole esse nome na caixa de diálogo Fazer login. Clique em Avançar.
-
Copie a Senha no painel Detalhes do laboratório e a cole na caixa de diálogo Olá. Clique em Avançar.
Importante: você precisa usar as credenciais do painel à esquerda. Não use suas credenciais do Google Cloud Ensina.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do GCP vai ser aberto nesta guia.
Observação: para ver uma lista dos produtos e serviços do Google Cloud, clique no Menu de navegação no canto superior esquerdo.

Ative o Google Cloud Shell
O Google Cloud Shell é uma máquina virtual com ferramentas de desenvolvimento. Ele conta com um diretório principal permanente de 5 GB e é executado no Google Cloud.
O Google Cloud Shell permite acesso de linha de comando aos seus recursos do GCP.
-
No Console do GCP, na barra de ferramentas superior direita, clique no botão Abrir o Cloud Shell.
-
Clique em Continue (continuar):
Demora alguns minutos para provisionar e conectar-se ao ambiente. Quando você está conectado, você já está autenticado e o projeto é definido como seu PROJECT_ID . Por exemplo:

gcloud é a ferramenta de linha de comando do Google Cloud Platform. Ele vem pré-instalado no Cloud Shell e aceita preenchimento com tabulação.
É possível listar o nome da conta ativa com este comando:
gcloud auth list
Saída:
ACTIVE: *
ACCOUNT: student-01-xxxxxxxxxxxx@qwiklabs.net
To set the active account, run:
$ gcloud config set account `ACCOUNT`
É possível listar o ID de projeto com este comando:
gcloud config list project
Saída:
[core]
project = <project_ID>
Exemplo de saída:
[core]
project = qwiklabs-gcp-44776a13dea667a6
Observação: quando você executava o gcloud na sua máquina, as definições de configurações permaneciam entre as sessões. No Cloud Shell, será necessário configurar para cada nova sessão ou reconexão.
Tarefa 1: Configurar o escalonador automático e o ambiente
- No Cloud Shell, clone os arquivos necessários para o laboratório:
git clone https://github.com/cloudspannerecosystem/autoscaler
- Defina as variáveis de ambiente do projeto e da pasta:
gcloud config set project {{{project_0.project_id|Project ID}}}
export WORKING_DIR=`pwd`
export AUTOSCALER_DIR=${WORKING_DIR}/autoscaler/terraform/cloud-functions/per-project
export AUTOSCALER_MODS=${WORKING_DIR}/autoscaler/terraform/modules
export PROJECT_ID={{{project_0.project_id|Project ID}}}
- Defina a região e a zona e o local do App Engine onde a infraestrutura do escalonador automático vai ficar:
export REGION={{{project_0.default_region|Lab Region}}}
export ZONE={{{project_0.default_zone|Lab Zone}}}
export APP_ENGINE_LOCATION={{{project_0.default_region|Lab Region}}}
- Ative as APIs do Cloud necessárias:
gcloud services enable iam.googleapis.com \
cloudresourcemanager.googleapis.com \
appengine.googleapis.com \
firestore.googleapis.com \
spanner.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
cloudbuild.googleapis.com \
cloudscheduler.googleapis.com \
run.googleapis.com \
eventarc.googleapis.com
- Crie um aplicativo do App Engine na região em que você quer implantar o escalonador automático. Isso vai criar uma instância do Cloud Firestore para o projeto:
gcloud app create --region=${APP_ENGINE_LOCATION}
- Atualize os valores nos arquivos de variáveis do Terraform (variables.tf) para que eles correspondam ao projeto do Qwiklabs:
sed -i "s/us-central1-c/$ZONE/g; s/us-central1/$REGION/g" ${AUTOSCALER_DIR}/variables.tf
sed -i "s/us-central1/$REGION/g" ${AUTOSCALER_MODS}/autoscaler-functions/variables.tf
sed -i "s/us-central/$REGION/g" ${AUTOSCALER_MODS}/scheduler/variables.tf
Clique em Verificar meu progresso para conferir o objetivo.
Crie um banco de dados do Firestore
Tarefa 2: Implantar o escalonador automático
- Defina o ID do projeto, a região e a zona nas variáveis de ambiente correspondentes do Terraform:
export TF_VAR_project_id=${PROJECT_ID}
export TF_VAR_region=${REGION}
export TF_VAR_zone=${ZONE}
- Defina
TF_VAR_spanner_name como autoscale-test, o nome da instância do Spanner que foi criada para você durante a configuração do laboratório:
export TF_VAR_spanner_name=autoscale-test
Isso faz com que o Terraform configure o escalonador automático para um Cloud Spanner chamado autoscale-test e atualize o IAM na instância do Cloud Spanner. Essa instância do Cloud Spanner foi criada para você durante a configuração do laboratório.
Especificar o nome de uma instância é o que você normalmente faria para implantações de produção em que já há uma implantação do Cloud Spanner.
- Mude para o diretório por projeto do Terraform e inicialize-o:
cd ${AUTOSCALER_DIR}
terraform init
- Importe o aplicativo atual do App Engine para o estado do Terraform:
terraform import module.scheduler.google_app_engine_application.app ${PROJECT_ID}
- Crie a infraestrutura do escalonador automático:
terraform apply -parallelism=2
- Responda
yes quando solicitado, depois de revisar os recursos que o Terraform pretende criar.
Observação: se você encontrar problemas de permissão, aguarde um minuto e execute novamente o comando terraform apply -parallelism=2 no Cloud Shell.
Observação: se você estiver no Cloud Shell e encontrar o problema "443: connect: cannot assign requested address" ("443: não é possível atribuir o endereço solicitado"), tente reduzir o parâmetro de paralelismo.
-
Acesse Menu de navegação > Firestore e clique no ID do seu banco de dados (default).
-
Agora, clique no botão Mudar para o modo nativo e depois em Mudar modos.
Observação: se aparecer algum erro, como Collections failed to load, aguarde alguns minutos e atualize a página.
Clique em Verificar meu progresso para conferir o objetivo.
Implante o escalonador automático
Tarefa 3: Estudar o escalonamento automático
-
Clique no ícone de três linhas no canto superior esquerdo para abrir o menu de navegação. Depois clique em Visualizar todos os produtos, Bancos de dados e, por fim, Spanner. A página principal do Spanner é carregada.
-
Clique no nome da instância autoscale-test e depois em Insights do sistema à esquerda, onde você vai encontrar várias métricas do Spanner.
Observação: talvez seja necessário esperar alguns minutos para que os gráficos comecem a ser preenchidos e para acompanhar o escalonamento automático. O escalonador automático verifica a instância a cada 2 minutos.
- Role para baixo para conferir a utilização da CPU. A geração de carga vai produzir picos na utilização da CPU de alta prioridade, que serão parecidos com o seguinte gráfico:
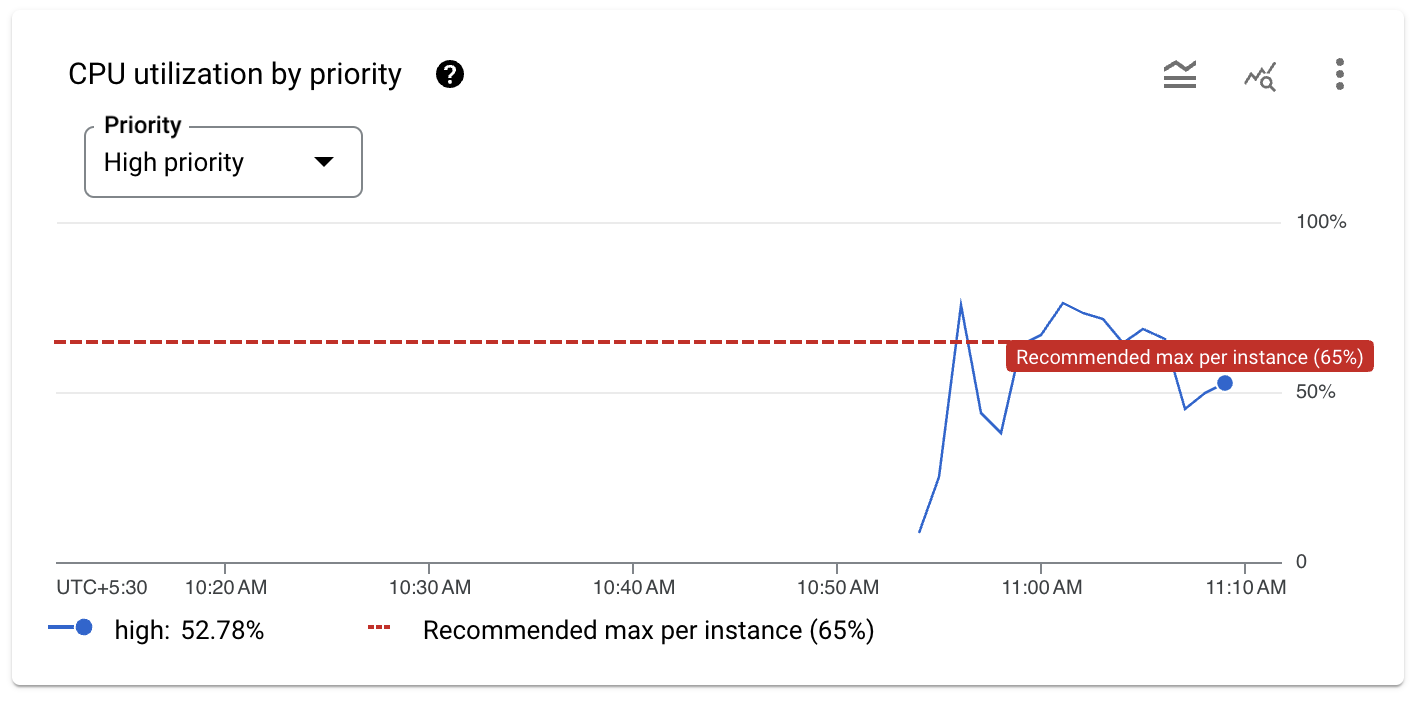
No gráfico, é possível visualizar dois picos que ultrapassam o limite recomendado de 65% de utilização da CPU.
- Role para baixo e confira o gráfico de capacidade de computação. Em Unidade de computação, selecione Unidades de processamento.
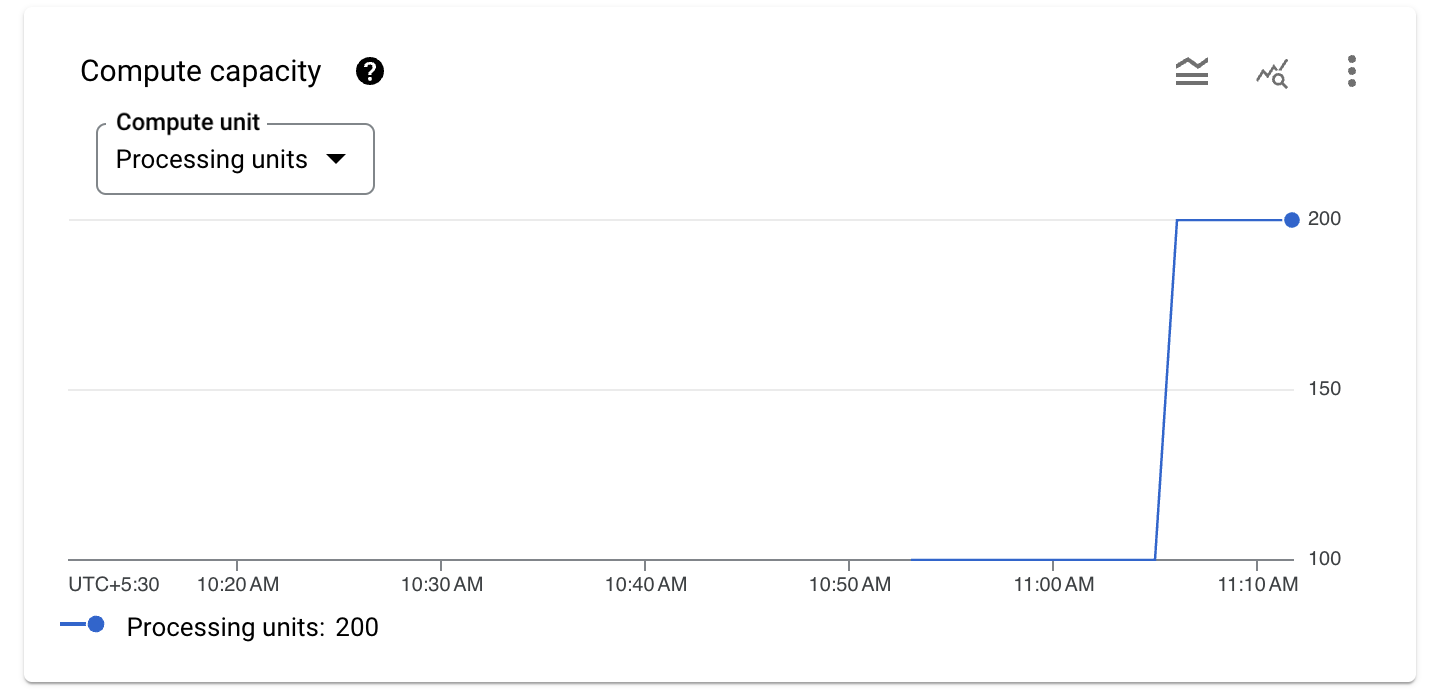
O escalonador automático monitora a instância do Spanner e, quando a utilização da CPU ultrapassa 65%, ele adiciona capacidade de computação. Neste exemplo, ele adiciona mais unidades de processamento a cada vez. O número de unidades de processamento ou nós que o escalonador automático adiciona é determinado pelo método de escalonamento que ele usa.
Verifique os registros do escalonador automático
- Para conferir os registros de pesquisas e de escalonamento do escalonador automático do Cloud Run Functions, acesse Menu de navegação > Geração de registros.
- Insira o seguinte filtro na caixa de texto Criador de consultas:
resource.labels.configuration_name=~"tf-.*-function"
- Clique em Executar consulta à direita.
Em Resultados da consulta, é possível visualizar todas as mensagens das funções do escalonador automático. Como o aplicativo de pesquisa só é executado a cada 2 minutos, talvez seja necessário executar novamente a consulta para receber as mensagens de registro.
- Para visualizar apenas mensagens da função de pesquisa, insira o seguinte filtro na caixa de texto Criador de consultas:
resource.labels.configuration_name="tf-poller-function"
- Clique em Executar consulta à direita.
Em Resultados da consulta, você vai encontrar apenas as mensagens da função de pesquisa. Como o aplicativo de pesquisa só é executado a cada 2 minutos, talvez seja necessário executar novamente a consulta para receber as mensagens de registro.
- Confira os registros nos horários aproximados em que o escalonamento automático foi acionado.
A função de pesquisa monitora continuamente a instância do Spanner:

Neste exemplo, a função de pesquisa recebe as métricas de CPU de alta prioridade, CPU contínua de 24 horas e armazenamento e publica uma mensagem para a função de escalonamento. Repare que a CPU de alta prioridade é 78,32% neste momento.
- Para visualizar apenas mensagens da função de escalonamento, insira o seguinte filtro na caixa de texto do Criador de consultas:
resource.labels.configuration_name="tf-scaler-function"
- Clique em Executar consulta à direita.
- Em Resultados da consulta, você vai encontrar apenas as mensagens da função de escalonamento relacionadas a sugestões de "nós" e decisões de escalonamento.
Observação: com esses filtros ou outros semelhantes, é possível criar métricas com base em registros, o que pode ser útil, por exemplo, para rastrear a frequência de eventos de escalonamento automático ou para usar em gráficos e políticas de alertas do Cloud Monitoring.
A função de escalonamento recebe essa mensagem e decide se a instância do Spanner deve ser escalonada.

Neste exemplo, o método de escalonamento LINEAR sugere escalonar de 300 para 400 unidades de processamento com base no valor de CPU de alta prioridade. Como a última operação de escalonamento foi feita há mais de cinco minutos, o escalonador decide escalonar para 400 unidades de processamento.
Parabéns!
Agora você implementou a ferramenta escalonador automático para o Cloud Spanner, que permite aumentar ou reduzir automaticamente o número de nós com base nas necessidades de carga de trabalho. Você praticou o uso do Cloud Run Functions, do Spanner, do Scheduler e do Cloud Monitoring.
Manual atualizado em 19 de novembro de 2024
Laboratório testado em 19 de novembro de 2024
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.





