



始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create a Firestore Database
/ 50
Deploy the Autoscaler
/ 50
Cloud Spanner のオートスケーラー ツールは、1 つ以上の Spanner インスタンスのコンピューティング容量を、その使用状況に応じて自動的に増減できるオープンソース ツールです。
Cloud Spanner は、無制限のスケール、強整合性、最大 99.999% の可用性を備えたフルマネージド リレーショナル データベースです。
Cloud Spanner インスタンスを作成するときに、インスタンスのコンピューティング リソースを提供するノードの数または処理ユニットの数を選択します。インスタンスのワークロードが変化しても、Cloud Spanner ではインスタンス内のノード数と処理ユニット数が自動的に調整されません。
オートスケーラーはインスタンスをモニタリングし、CPU 使用率の推奨最大値とノードあたりのストレージの推奨上限内に収まるようにコンピューティング容量を自動的に追加または削除します。
このラボでは、プロジェクト単位の構成でオートスケーラーをデプロイします。このデプロイ構成では、オートスケーラーは自動スケーリングされる Cloud Spanner インスタンスと同じプロジェクトに配置されます。
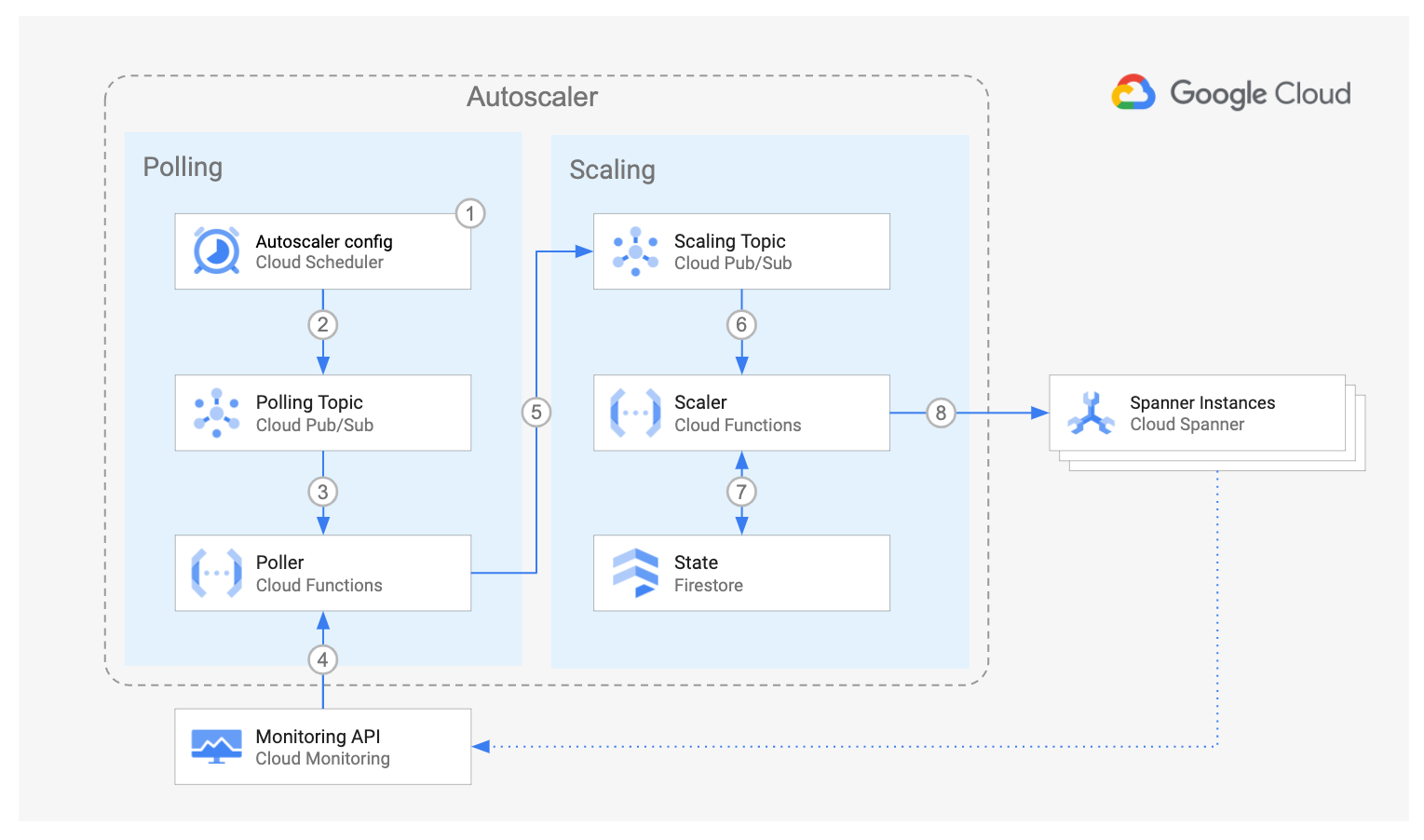
上の図は、Cloud Spanner オートスケーラーのコンポーネントとそのインタラクションの流れを示しています。
Cloud Scheduler、Cloud Pub/Sub、Cloud Run functions の Poller 関数で構成される Poller コンポーネントは、Cloud Monitoring API にクエリを実行して、各 Spanner インスタンスの使用率指標を取得します。インスタンスごとに、Poller 関数は 1 つのメッセージをスケーリング Pub/Sub トピックに push し、特定の Spanner インスタンスの使用率指標と、対応する構成パラメータの一部を格納します。
Scaler コンポーネントは、Cloud Pub/Sub、Cloud Run functions の Scaler 関数、Cloud Firestore で構成されています。各メッセージについて、Scaler 関数は Spanner インスタンスの指標を推奨されるしきい値と比較し、許容されるマージンを増減します。選択したスケーリング方式を使用して、インスタンスをスケールする必要があるかどうか、またスケールする必要があるノード数や処理ユニット数を決定します。
フロー全体で、Spanner Autoscaler は推奨事項やアクションの詳細を Cloud Logging に記録し、追跡や監査を可能にします。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ご自身でラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
その後次のように進みます。
その後このタブで Cloud Console が開きます。

Google Cloud Shell は、デベロッパー ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Google Cloud Shell では、コマンドラインで GCP リソースにアクセスできます。
GCP Console の右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境のプロビジョニングと接続には少し時間がかかります。接続すると、すでに認証されており、プロジェクトは PROJECT_ID に設定されています。例えば:
gcloud は Google Cloud Platform のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
gcloud auth list
出力:
ACTIVE: *
ACCOUNT: student-01-xxxxxxxxxxxx@qwiklabs.net
To set the active account, run:
$ gcloud config set account `ACCOUNT`
次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
gcloud config list project
出力:
[core]
project = <project_ID>
出力例:
[core]
project = qwiklabs-gcp-44776a13dea667a6
gcloud を実行する場合はセッション間で config 設定が維持されますが、Cloud Shell で実行する場合はセッションごと、または再接続するたびに設定する必要があります。[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
TF_VAR_spanner_name を autoscale-test に設定します。これは、ラボのセットアップ時に作成された Spanner インスタンスの名前です。これにより、Terraform は autoscale-test という名前の Cloud Spanner のオートスケーラーを構成し、Cloud Spanner インスタンスの IAM を更新します。この Cloud Spanner インスタンスは、ラボのセットアップ時に作成されています。
既存のインスタンスの名前を指定する場合は、通常、Cloud Spanner のデプロイメントがすでに存在する本番環境のデプロイで行うことになります。
yes」と入力します。terraform apply -parallelism=2 コマンドを再実行します。ナビゲーション メニュー > [Firestore] に移動し、データベース ID(default)をクリックします。
次に、[ネイティブ モードに切り替える] ボタンをクリックし、[モードを切り替え] をクリックします。
Collections failed to load などのエラーが表示された場合は、数分待ってからページを更新してください。[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
左上の 3 本の線のアイコンをクリックしてナビゲーション メニューを開き、[すべてのプロダクトを表示] をクリックしてから、[データベース] をクリックし、最後に [Spanner] をクリックします。Spanner のメインページが読み込まれます。
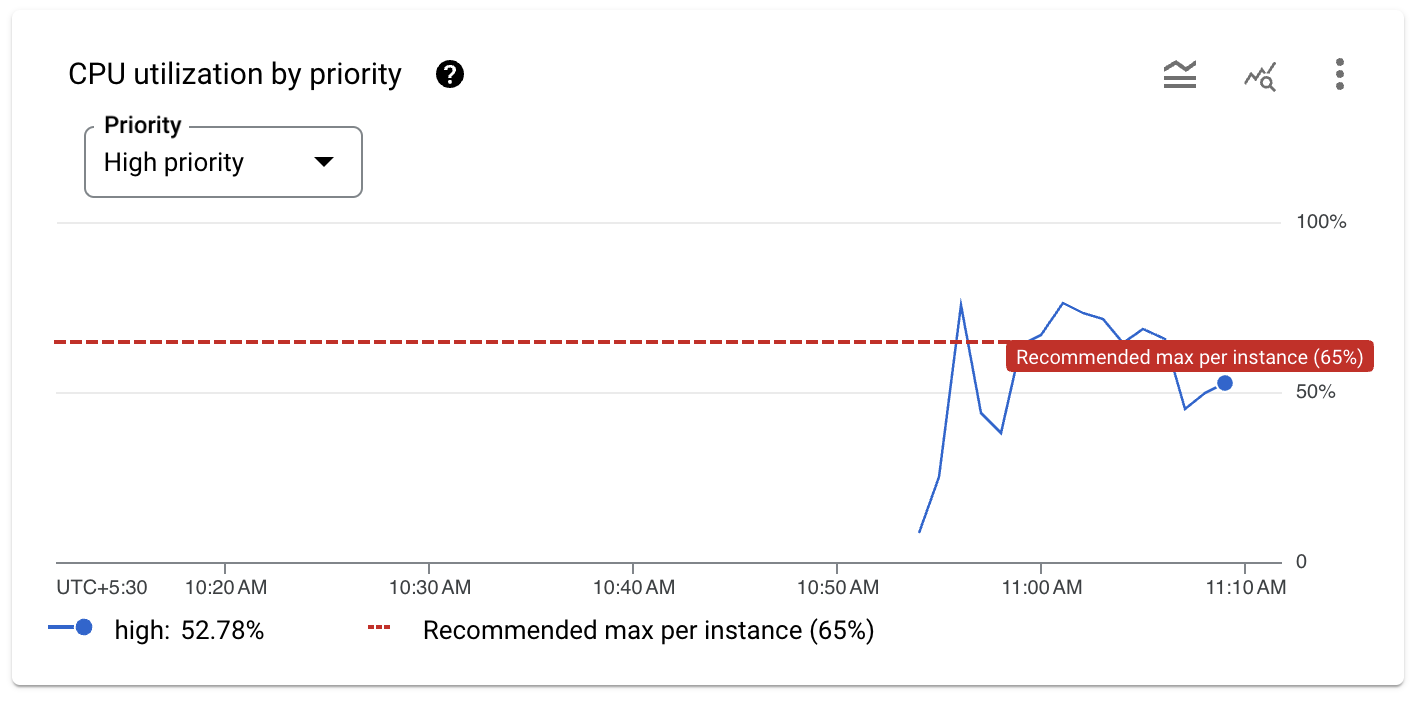
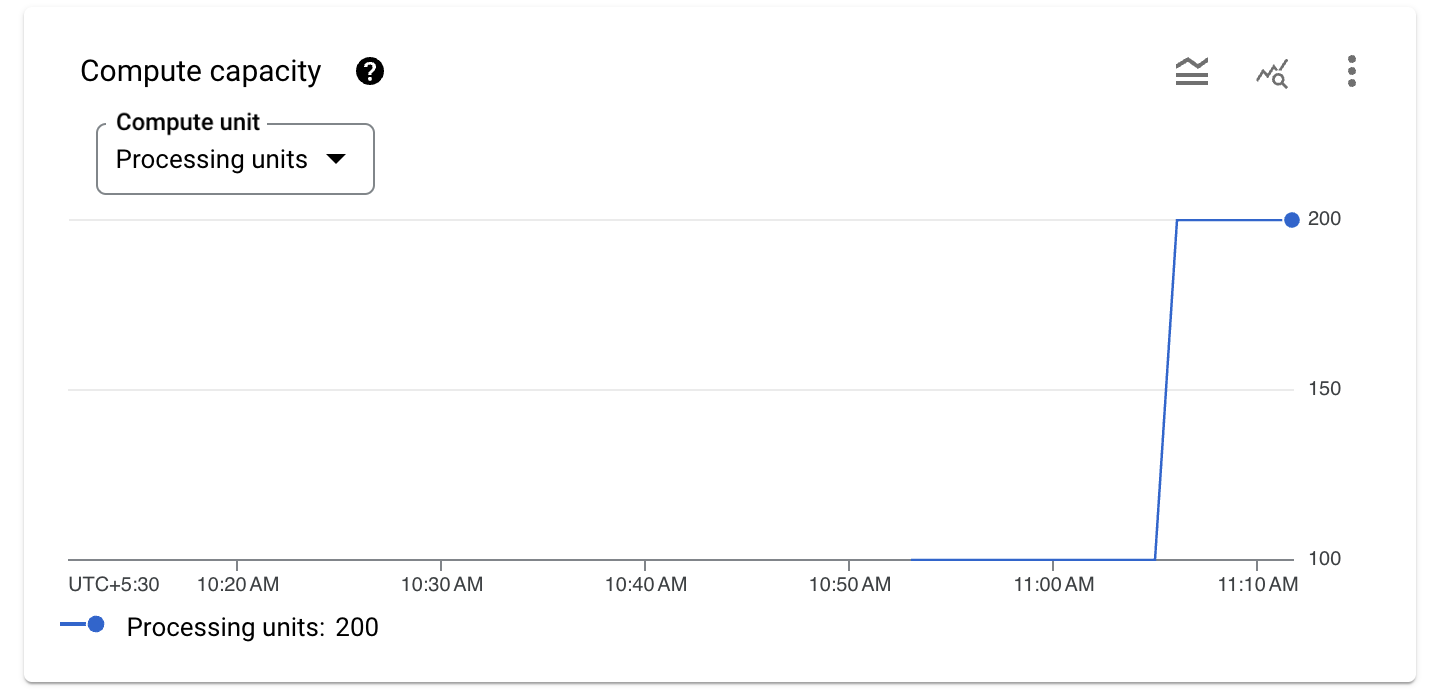
インスタンス名 autoscale-test をクリックし、左側の [システム分析情報] をクリックすると、さまざまな Spanner 指標が表示されます。
グラフには、CPU 使用率の推奨しきい値である 65% を超える 2 つの急増が示されています。
オートスケーラーは Spanner インスタンスをモニタリングし、CPU 使用率が 65% を超えるとコンピューティング容量を追加します。この例では、毎回処理ユニットを追加しています。オートスケーラーが追加する処理ユニットまたはノードの数は、オートスケーラーが使用するスケーリング方法によって決まります。
[クエリ結果] で、Autoscaler 関数からのすべてのメッセージを確認できます。Poller は 2 分間隔でのみ実行されるため、ログメッセージを受信するためにクエリの再実行が必要になる場合があります。
[クエリ結果] には、Poller 関数からのメッセージのみが表示されます。Poller は 2 分間隔でのみ実行されるため、ログメッセージを受信するためにクエリの再実行が必要になる場合があります。
Poller 関数は、Spanner インスタンスを継続的にモニタリングします。
この例では、Poller 関数が優先度の高い CPU、24 時間の CPU の変化、ストレージ指標を取得し、Scaler 関数にメッセージをパブリッシュします。この時点で、優先度の高い CPU は 78.32% であることに注意してください。
Scaler 関数は、そのメッセージを受信し、Spanner インスタンスをスケールする必要があるかどうかを判断します。
この例では、線形スケーリング方法が、優先度の高い CPU の値に基づいて 300 から 400 の処理ユニットにスケールすることを提案しています。前回のスケーリング操作が 5 分以上前に行われたため、スケーラーは 400 個の処理ユニットにスケールすることを決定します。
これで、ワークロードのニーズに応じてノードの数を自動的に増減できる Cloud Spanner 用のオートスケーラー ツールを実装できました。Cloud Run functions、Spanner、Scheduler、Cloud Monitoring の使用方法を練習しました。
マニュアルの最終更新日: 2024 年 11 月 19 日
ラボの最終テスト日: 2024 年 11 月 19 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください