SCBL069
Présentation
L'autoscaler pour Cloud Spanner est un outil Open Source qui vous permet d'augmenter ou de réduire automatiquement la capacité de calcul d'une ou de plusieurs instances Spanner en fonction de leur utilisation.
Cloud Spanner est une base de données relationnelle entièrement gérée offrant une évolutivité illimitée, une cohérence forte et une disponibilité pouvant aller jusqu'à 99,999 %.
Quand vous créez une instance Cloud Spanner, vous choisissez le nombre de nœuds ou d'unités de traitement qui fournissent des ressources de calcul pour l'instance. Lorsque la charge de travail de l'instance évolue, Cloud Spanner n'ajuste pas automatiquement le nombre de nœuds ou d'unités de traitement dans l'instance.
L'autoscaler surveille vos instances et ajoute ou supprime automatiquement de la capacité de calcul pour s'assurer qu'elles respectent les valeurs maximales recommandées pour l'utilisation du processeur et la limite conseillée pour le volume de stockage par nœud.
Dans cet atelier, vous allez déployer l'autoscaler dans une configuration par projet. Dans ce type de configuration de déploiement, l'autoscaler se trouve dans le même projet que l'instance Cloud Spanner faisant l'objet d'un autoscaling.
Architecture
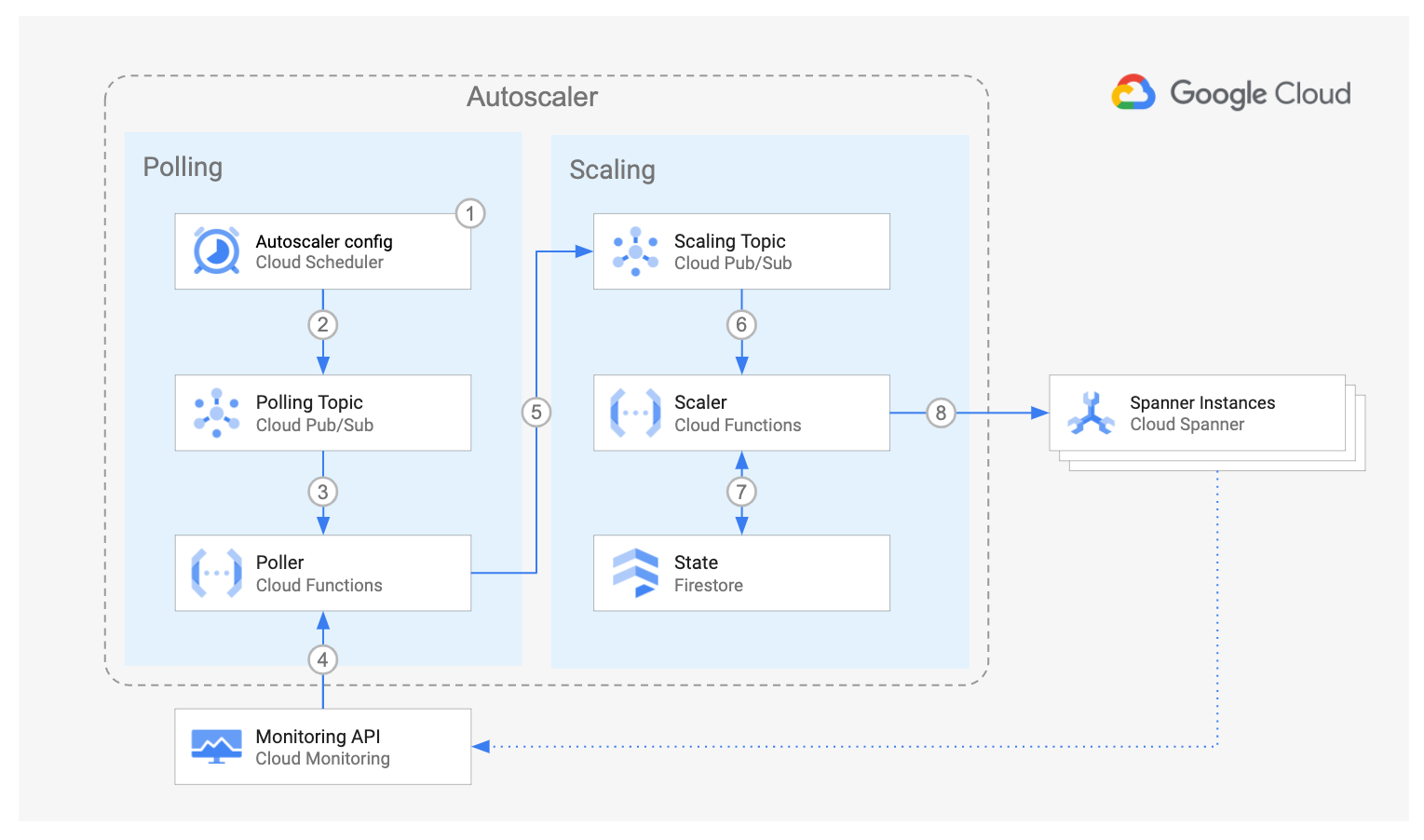
Le diagramme ci-dessus illustre les composants de l'autoscaler Cloud Spanner et le flux d'interaction :
-
Le composant Poller, qui s'appuie sur Cloud Scheduler, Cloud Pub/Sub et la fonction Cloud Run Poller, interroge l'API Cloud Monitoring pour récupérer les métriques d'utilisation de chaque instance Spanner. Pour chaque instance, la fonction Poller transmet au sujet Pub/Sub "Scaling" un message qui contient les métriques d'utilisation de l'instance Spanner spécifique ainsi que certains de ses paramètres de configuration associés.
-
Le composant Scaler s'appuie sur Cloud Pub/Sub, la fonction Cloud Run Scaler et Cloud Firestore. Pour chaque message, la fonction Scaler compare les métriques d'instance Spanner aux seuils recommandés, avec une marge autorisée. À l'aide de la méthode de scaling choisie, elle détermine si l'instance doit évoluer à la hausse ou à la baisse et, le cas échéant, le nombre de nœuds ou d'unités de traitement concernés par le scaling.
Tout au long du flux, l'autoscaler pour Spanner consigne un résumé étape par étape de ses recommandations et actions dans Cloud Logging à des fins de suivi et d'audit.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
Remarque : Ouvrez une fenêtre de navigateur en mode incognito/navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- vous disposez d'un temps limité ; n'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Si vous possédez déjà votre propre compte ou projet Google Cloud, veillez à ne pas l'utiliser pour réaliser cet atelier afin d'éviter que des frais supplémentaires ne vous soient facturés.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google.
L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue Se connecter. Cliquez sur Suivant.
-
Copiez le mot de passe inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue de bienvenue. Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis dans le panneau de gauche. Ne saisissez pas vos identifiants Google Cloud Skills Boost.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
-
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas aux essais offerts.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Vous pouvez afficher le menu qui contient la liste des produits et services Google Cloud en cliquant sur le menu de navigation en haut à gauche.

Activer Google Cloud Shell
Google Cloud Shell est une machine virtuelle qui contient des outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud.
Google Cloud Shell offre un accès en ligne de commande à vos ressources GCP.
-
Dans la console GCP, dans la barre d'outils située en haut à droite, cliquez sur le bouton Ouvrir Cloud Shell.
-
Cliquez sur Continue (Continuez):
Il faut quelques instants pour mettre en service et se connecter à l'environnement. Lorsque vous êtes connecté, vous êtes déjà authentifié et le projet est défini sur votre PROJECT_ID. Par exemple:

gcloud est l'outil de ligne de commande associé à Google Cloud Platform. Pré-installé sur Cloud Shell, il est également compatible avec la saisie semi-automatique via la touche de tabulation.
Vous pouvez répertorier les noms des comptes actifs à l'aide de cette commande :
gcloud auth list
Résultat :
ACTIVE: *
ACCOUNT: student-01-xxxxxxxxxxxx@qwiklabs.net
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Pour répertorier les ID de projet, exécutez la commande suivante :
gcloud config list project
Résultat :
[core]
project = <ID_Projet>
Exemple de résultat :
[core]
project = qwiklabs-gcp-44776a13dea667a6
Remarque : Lorsque vous exécutez gcloud sur votre propre machine, les paramètres de configuration sont conservés d'une session à l'autre. En revanche, dans Cloud Shell, vous devrez définir ces paramètres à chaque nouvelle session ou reconnexion.
Tâche 1 : Configurer l'autoscaler et l'environnement
- Dans Cloud Shell, clonez les fichiers nécessaires pour l'atelier :
git clone https://github.com/cloudspannerecosystem/autoscaler
- Définissez les variables d'environnement pour le projet et les dossiers :
gcloud config set project {{{project_0.project_id|Project ID}}}
export WORKING_DIR=`pwd`
export AUTOSCALER_DIR=${WORKING_DIR}/autoscaler/terraform/cloud-functions/per-project
export AUTOSCALER_MODS=${WORKING_DIR}/autoscaler/terraform/modules
export PROJECT_ID={{{project_0.project_id|Project ID}}}
- Définissez les paramètres de région et zone, ainsi que l'emplacement App Engine où sera située l'infrastructure de l'autoscaler :
export REGION={{{project_0.default_region|Lab Region}}}
export ZONE={{{project_0.default_zone|Lab Zone}}}
export APP_ENGINE_LOCATION={{{project_0.default_region|Lab Region}}}
- Activez les API Cloud requises :
gcloud services enable iam.googleapis.com \
cloudresourcemanager.googleapis.com \
appengine.googleapis.com \
firestore.googleapis.com \
spanner.googleapis.com \
pubsub.googleapis.com \
cloudfunctions.googleapis.com \
cloudbuild.googleapis.com \
cloudscheduler.googleapis.com \
run.googleapis.com \
eventarc.googleapis.com
- Créez une application App Engine dans la région où vous souhaitez déployer l'autoscaler. Une nouvelle instance Cloud Firestore est alors créée pour votre projet :
gcloud app create --region=${APP_ENGINE_LOCATION}
- Modifiez les valeurs figurant dans le fichier de variables Terraform (variables.tf) afin qu'elles correspondent à votre projet Qwiklabs :
sed -i "s/us-central1-c/$ZONE/g; s/us-central1/$REGION/g" ${AUTOSCALER_DIR}/variables.tf
sed -i "s/us-central1/$REGION/g" ${AUTOSCALER_MODS}/autoscaler-functions/variables.tf
sed -i "s/us-central/$REGION/g" ${AUTOSCALER_MODS}/scheduler/variables.tf
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer une base de données Firestore
Tâche 2 : Déployer l'autoscaler
- Définissez l'ID du projet, la région et la zone dans les variables d'environnement Terraform correspondantes :
export TF_VAR_project_id=${PROJECT_ID}
export TF_VAR_region=${REGION}
export TF_VAR_zone=${ZONE}
- Définissez
TF_VAR_spanner_name sur autoscale-test, qui est le nom de l'instance Spanner créée pour vous lors de la préparation de l'atelier :
export TF_VAR_spanner_name=autoscale-test
Terraform configure alors l'autoscaler pour l'instance Cloud Spanner autoscale-test et met à jour IAM dans cette instance créée pour vous lors de la préparation de l'atelier.
L'utilisateur doit généralement spécifier le nom d'une instance existante pour les déploiements de production, où un déploiement Cloud Spanner a déjà été lancé.
- Accédez au répertoire Terraform par projet et initialisez-le :
cd ${AUTOSCALER_DIR}
terraform init
- Importez l'application App Engine existante dans l'état Terraform :
terraform import module.scheduler.google_app_engine_application.app ${PROJECT_ID}
- Créez l'infrastructure de l'autoscaler :
terraform apply -parallelism=2
- Lorsque vous y êtes invité, répondez
yes (oui) après avoir examiné les ressources que Terraform compte créer.
Remarque : Si vous rencontrez des problèmes d'autorisation, patientez une minute, puis exécutez de nouveau la commande terraform apply -parallelism=2 dans Cloud Shell.
Remarque : Si vous rencontrez une erreur 443: connect: cannot assign requested address (443 – Connexion : impossible d'attribuer l'adresse demandée) dans Cloud Shell, essayez de réduire la valeur du paramètre parallelism.
-
Accédez au menu de navigation > Firestore, puis cliquez sur l'ID de votre base de données (default).
-
Cliquez ensuite sur le bouton Passer au mode natif, puis sur Changer de mode.
Remarque : Si une erreur telle que Collections failed to load s'affiche, patientez quelques minutes et actualisez la page.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Déployer l'autoscaler
Tâche 3 : Observer l'autoscaling
-
Cliquez sur l'icône à trois barres en haut à gauche pour ouvrir le menu de navigation. Ensuite, cliquez successivement sur Afficher tous les produits, Bases de données et enfin Spanner. La page principale de Spanner se charge.
-
Cliquez sur le nom de l'instance autoscale-test, puis sur Insights sur le système à gauche. Vous y verrez différentes métriques Spanner.
Remarque : Vous devrez peut-être patienter quelques minutes pour que les données commencent à alimenter les graphiques et que vous puissiez observer l'autoscaling. L'autoscaler vérifie l'instance toutes les deux minutes.
- Faites défiler la page vers le bas pour afficher l'utilisation du processeur. La génération de charge va entraîner des pics d'utilisation du processeur à priorité élevée, semblables au graphique suivant :
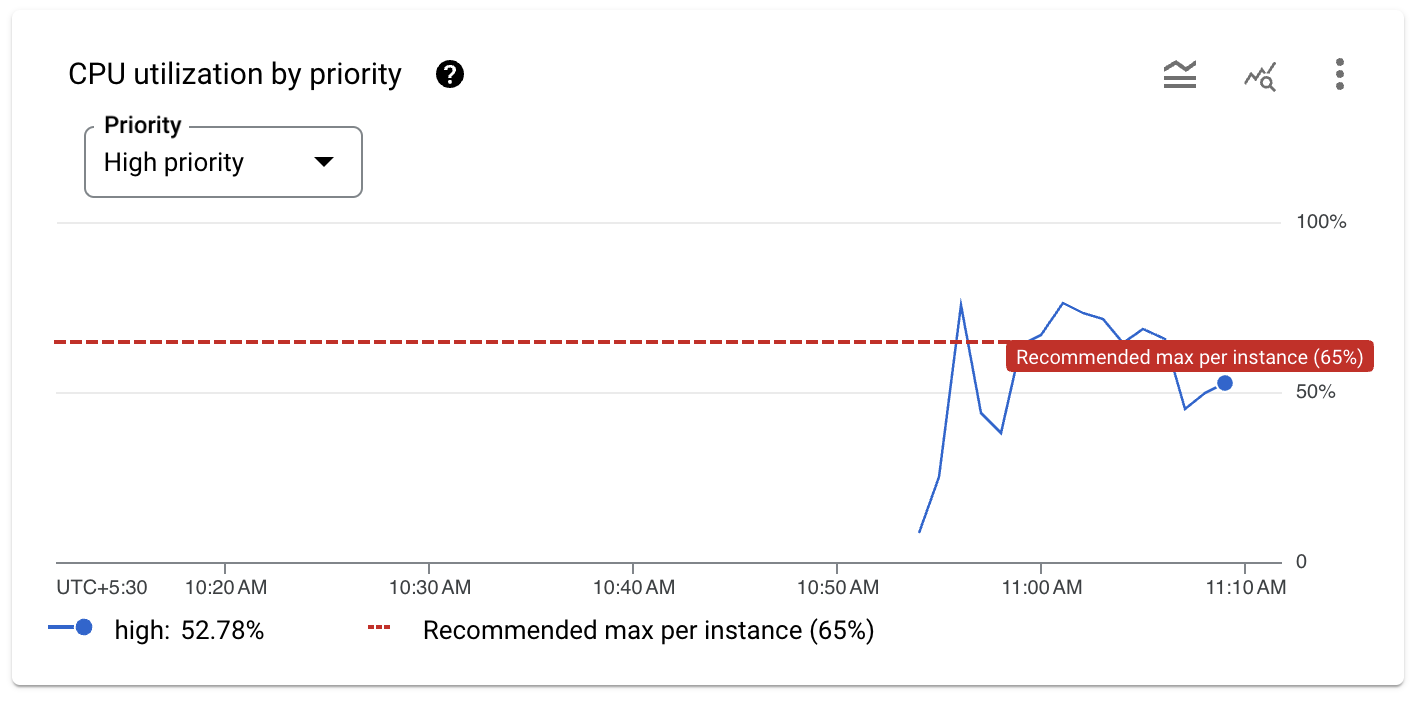
Sur le graphique, vous pouvez observer deux pics qui dépassent le seuil recommandé de 65 % pour l'utilisation du processeur.
- Faites défiler la page vers le bas pour afficher le graphique de la capacité de calcul. Pour Unité de calcul, sélectionnez Unités de traitement.
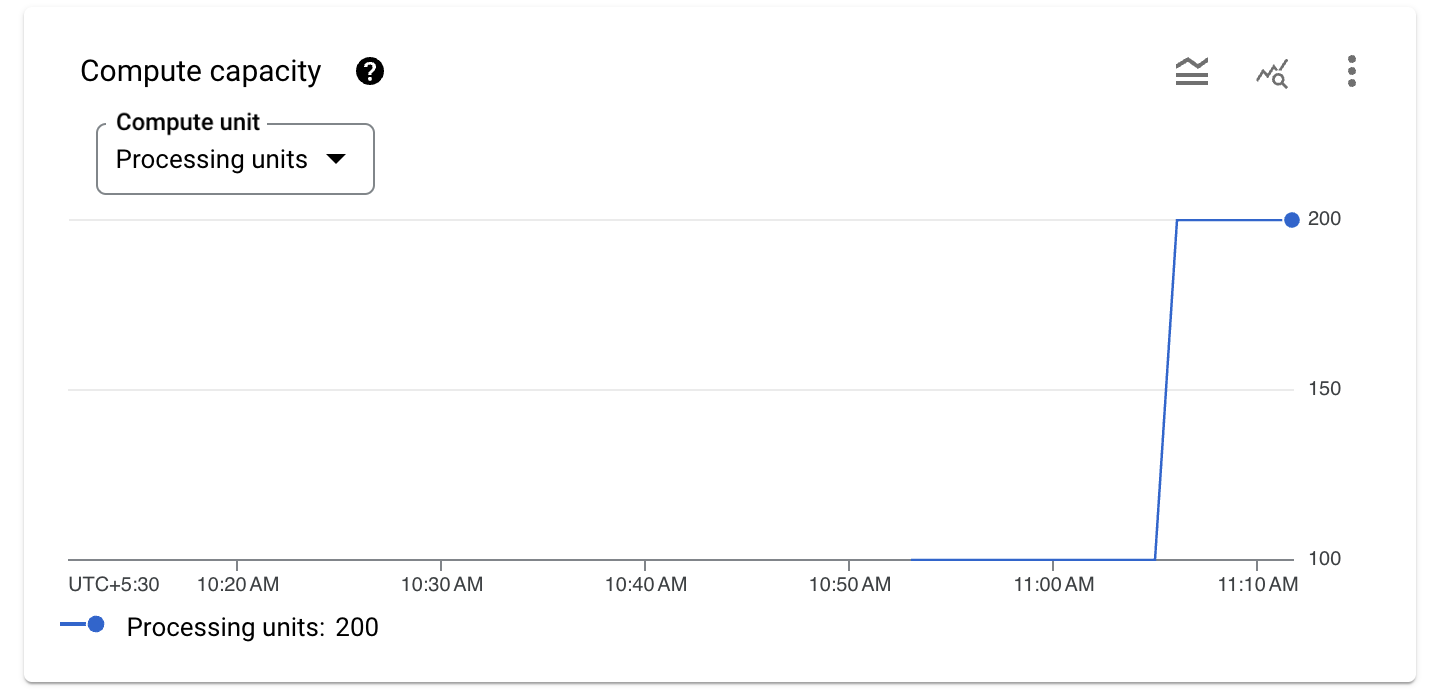
L'autoscaler surveille l'instance Spanner et, lorsque l'utilisation du processeur dépasse 65 %, il ajoute de la capacité de calcul. Dans cet exemple, il ajoute des unités de traitement à chaque fois. Le nombre d'unités de traitement ou de nœuds ajoutés par cet outil est déterminé par la méthode de scaling qu'il utilise.
Vérifier les journaux de l'autoscaler
- Pour afficher les journaux des fonctions Cloud Run Poller et Scaler de l'autoscaler, accédez au menu de navigation > Journalisation.
- Saisissez le filtre suivant dans la zone de texte du générateur de requêtes :
resource.labels.configuration_name=~"tf-.*-function"
- Cliquez sur Exécuter la requête tout à droite.
Sous Résultats de la requête, vous pouvez voir tous les messages des fonctions de l'autoscaler. Comme la fonction Poller ne s'exécute que toutes les deux minutes, vous devrez peut-être exécuter de nouveau la requête pour recevoir les messages de journal.
- Pour n'afficher que les messages de la fonction Poller, saisissez le filtre suivant dans la zone de texte du générateur de requêtes :
resource.labels.configuration_name="tf-poller-function"
- Cliquez sur Exécuter la requête tout à droite.
Sous Résultats de la requête, vous ne verrez que les messages de la fonction Poller. Comme la fonction Poller ne s'exécute que toutes les deux minutes, vous devrez peut-être exécuter de nouveau la requête pour recevoir les messages de journal.
- Examinez les journaux à l'heure correspondant approximativement au déclenchement de l'autoscaling.
La fonction Poller surveille en permanence l'instance Spanner :

Dans cet exemple, la fonction Poller récupère les métriques concernant le processeur à priorité élevée, la moyenne glissante d'utilisation du processeur sur 24 heures et l'espace de stockage, puis publie un message pour la fonction Scaler. Notez que l'utilisation du processeur à priorité élevée est, à ce stade, de 78,32 %.
- Pour n'afficher que les messages de la fonction Scaler, saisissez le filtre suivant dans la zone de texte du générateur de requêtes :
resource.labels.configuration_name="tf-scaler-function"
- Cliquez sur Exécuter la requête tout à droite.
- Sous Résultats de la requête, vous ne verrez que les messages de la fonction Scaler associés aux suggestions concernant les nœuds et aux décisions de scaling.
Remarque : À l'aide de ces filtres ou de filtres similaires, vous pouvez créer des métriques basées sur les journaux qui peuvent être utiles. Par exemple, elles peuvent vous servir à suivre la fréquence des événements d'autoscaling, ou vous pouvez les utiliser dans les graphiques et règles d'alerte de Cloud Monitoring.
La fonction Scaler reçoit ce message et décide si l'instance Spanner doit faire l'objet d'un scaling.

Dans cet exemple, sur la base de la valeur d'utilisation du processeur à priorité élevée, la méthode de scaling linéaire (LINEAR) suggère de passer de 300 à 400 unités de traitement. Comme la dernière opération de scaling a eu lieu il y a plus de cinq minutes, la fonction Scaler prend la décision de passer à 400 unités de traitement.
Félicitations !
Vous avez maintenant implémenté l'autoscaler pour Cloud Spanner, qui vous permet d'augmenter ou de réduire automatiquement le nombre de nœuds en fonction des besoins de la charge de travail. Vous vous êtes entraîné à utiliser Cloud Run Functions, Spanner et Scheduler, ainsi que Cloud Monitoring.
Dernière mise à jour du manuel : 19 novembre 2024
Dernier test de l'atelier : 19 novembre 2024
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.





