Neste laboratório, você vai aprender a usar a Vertex AI para treinar e fornecer um modelo do TensorFlow usando código em um contêiner personalizado.
Ainda que você esteja usando o TensorFlow para o código do modelo agora, ele pode ser facilmente substituído por outro framework.
Objetivos de aprendizagem
Criar e conteinerizar o código de treinamento de modelo nos Notebooks da Vertex.
Enviar um job de treinamento de modelo personalizado para a Vertex AI.
Implantar seu modelo treinado em um endpoint e usar esse endpoint para coletar previsões.
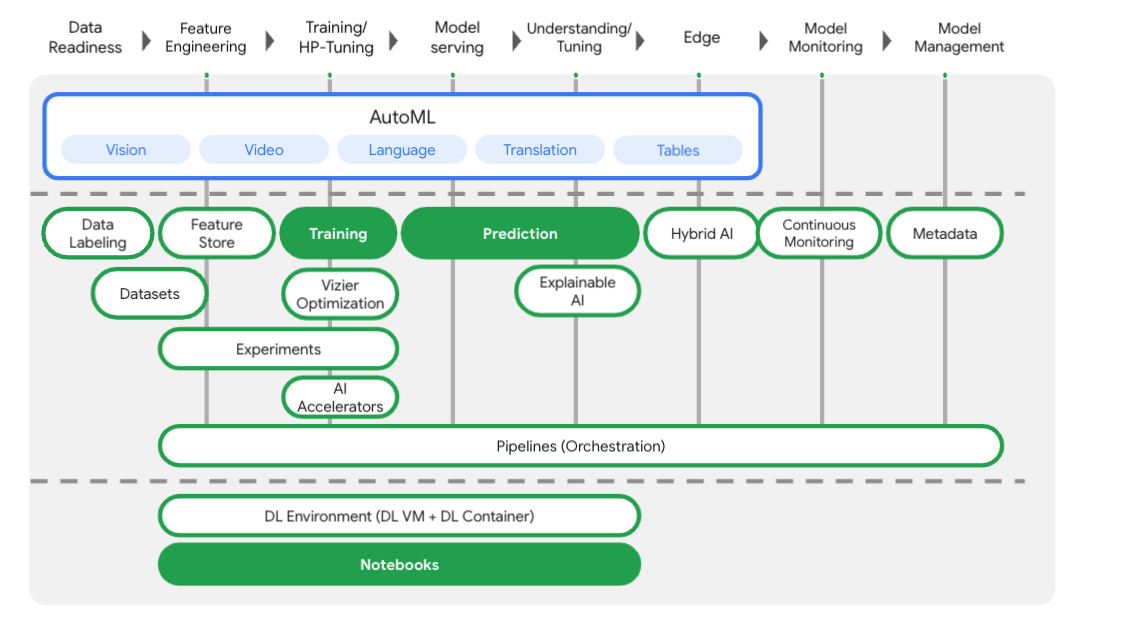
Introdução à Vertex AI
Este laboratório usa a mais nova oferta de produtos de IA disponível no Google Cloud. A Vertex AI integra as ofertas de ML do Google Cloud em uma experiência de desenvolvimento intuitiva. Anteriormente, modelos treinados com o AutoML e modelos personalizados eram acessíveis por serviços separados. A nova oferta combina ambos em uma única API, com outros novos produtos. Você também pode migrar projetos existentes para a Vertex AI. Se você tiver algum feedback, consulte a página de suporte.
A Vertex AI inclui vários produtos diferentes para dar suporte a fluxos de trabalho de ML completos. Este laboratório se concentra nestes produtos em destaque: Vertex Training, Vertex Prediction e os Notebooks.
Tarefa 1: configure o ambiente
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Ative a API Compute Engine
Acesse o Compute Engine e selecione Ativar, caso essa opção ainda não esteja ativada. Você vai precisar disso para criar sua instância do Workbench.
Ativar a API Container Registry
Navegue até o Container Registry e selecione Ativar se a opção ainda não estiver ativada. Use isso para criar um contêiner para seu job de treinamento personalizado.
Iniciar a instância do Vertex AI Workbench
No console do Google Cloud, no menu de navegação (), clique em Vertex AI.
Selecione Ativar todas as APIs recomendadas.
No menu de navegação, clique em Workbench.
Verifique se você está na visualização Instâncias do topo da página do Workbench.
Clique em Criar.
Configure a instância:
Nome: lab-workbench
Região: configure a região como
Zona: configure a zona como
Opções avançadas (opcional): se necessário, clique em "Opções avançadas" para personalizar mais (ex.: tipo de máquina, tamanho do disco).
Clique em Criar.
O processo vai levar alguns minutos, e uma marca de seleção verde vai aparecer ao lado do nome da instância quando ela estiver pronta.
Clique em ABRIR O JUPYTERLAB ao lado do nome da instância para iniciar a interface do ambiente. Uma nova guia será aberta no navegador.
Clique em Verificar meu progresso para conferir o objetivo.
Iniciar a instância do Vertex AI Workbench
Tarefa 2. Conteinerizar o código de treinamento
Você vai enviar este job de treinamento para a Vertex adicionado o código do treinamento a um contêiner do Docker e enviando esse contêiner por push para o Google Container Registry. Nessa abordagem, é possível treinar um modelo criado com qualquer framework.
Para começar, no menu de acesso rápido, abra uma janela do terminal na instância do Workbench.
Crie um novo diretório chamado mpg e entre nele com cd:
mkdir mpg
cd mpg
Crie um Dockerfile
Sua primeira etapa na conteinerização do código é a criação de um Dockerfile. No seu Dockerfile, você vai incluir todos os comandos necessários para executar sua imagem. Isso vai resultar na instalação de todas as bibliotecas que você estiver usando e na configuração do ponto de entrada do seu código de treinamento. No seu terminal, crie um Dockerfile vazio:
touch Dockerfile
Abra o Dockerfile navegando até mpg > Dockerfile e copie o seguinte nele:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /root
WORKDIR /
# Copia o código trainer para a imagem Docker.
COPY trainer /trainer
# Define o ponto de entrada para invocar o trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Este Dockerfile usa a imagem do Docker do TensorFlow Enterprise 2.3 no Deep Learning Containers. O componente Deep Learning Containers no Google Cloud vem com muitos frameworks comuns de ML e ciência de dados pré-instalados. O que você está usando inclui TF Enterprise 2.3, Pandas, Scikit-learn e outros. Depois de fazer o download dessa imagem, este Dockerfile configura o ponto de entrada para seu código de treinamento. Você ainda não criou esses arquivos. Na próxima etapa, adicione o código para treinar e exportar seu modelo.
Crie um bucket do Cloud Storage
No seu job de treinamento, você vai exportar seu modelo treinado do TensorFlow para um bucket do Cloud Storage. Dessa forma, a Vertex vai conseguir ler os ativos do seu modelo exportado e implantá-lo. No Terminal, execute o seguinte para definir uma variável de ambiente para seu projeto. Não se esqueça de substituir your-cloud-project pelo ID do seu projeto:
Observação: para conferir o ID do projeto, execute gcloud config list --format 'value(core.project)' no seu terminal.
PROJECT_ID='your-cloud-project'
Depois execute o comando abaixo no terminal para criar um novo bucket no projeto. O flag -l (localização) é importante, já que é necessário estar na mesma região onde você vai implantar um endpoint de modelo mais adiante no tutorial:
No seu Terminal, execute o seguinte para criar um diretório para seu código de treinamento e um arquivo Python onde você vai adicionar o código:
mkdir trainer
touch trainer/train.py
Agora você deve ter o seguinte no seu diretório mpg/:
+ Dockerfile
+ trainer/
+ train.py
Em seguida, abra o arquivo train.py que você acabou de criar navegando até mpg > trainer > train.py e copie o código abaixo (adaptado do tutorial da documentação do TensorFlow).
No começo do seu arquivo, atualize a variável BUCKET com o nome do bucket que você criou na etapa anterior:
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## O conjunto de dados Auto MPG
O conjunto de dados está disponível no [Repositório de Machine Learning da UCI](https://archive.ics.uci.edu/ml/).
### Baixar os dados
Primeiro, faça o download do conjunto de dados.
"""
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path
"""Use o pandas para importar"""
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset.tail()
# TODO: substituir `your-gcs-bucket` pelo nome do bucket do Storage que você criou antes
BUCKET = 'gs://your-gcs-bucket'
"""### Limpar os dados
O conjunto de dados contém alguns valores desconhecidos.
"""
dataset.isna().sum()
"""Para simplificar este tutorial inicial, vamos fazer drop nessas linhas."""
dataset = dataset.dropna()
"""A coluna `"Origin"` tem mais a ver com categorização do que com numeração. Então vamos convertê-la para uma one-hot:"""
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Dividir os dados entre treinamento e teste
Agora vamos separar o conjunto de dados, criando um conjunto de treinamento e um de testes.
Você vai usar o conjunto de teste na avaliação final do seu modelo.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspecionar os dados
Dê uma olhada na distribuição conjunta de alguns pares de colunas do conjunto de treinamento.
E também nas estatísticas gerais:
"""
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats
"""### Separar recursos de rótulos
Separe o valor desejado (o rótulo, ou "label") dos recursos. Este rótulo é o valor que o modelo será treinado para prever.
"""
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
"""### Normalizar os dados
Perceba como são diferentes os intervalos de cada recurso no bloco `train_stats` acima.
É prática recomendada normalizar recursos que usam diferentes escalas e intervalos. O modelo *pode* convergir sem a normalização dos recursos, mas isso dificulta o treinamento e resulta em um modelo dependente da escolha de unidades usada na entrada.
Observação: nós geramos estas estatísticas intencionalmente com base apenas no conjunto de dados de treinamento, mas elas também serão usadas para normalizar o conjunto de dados de teste. Precisamos fazer isso para projetar o conjunto de dados de teste com a mesma distribuição usada no treinamento do modelo.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""Estes dados normalizados serão usados para treinar o modelo.
Cuidado: as estatísticas usadas aqui para normalizar as entradas (média e desvio padrão) precisam ser aplicadas a quaisquer dados que forem usados para alimentar o modelo, assim como a codificação one-hot que fizemos antes. Isso inclui o conjunto de teste, assim como os dados reais quando o modelo estiver sendo usado em produção.
## O modelo
### Contruir o modelo
Vamos construir nosso modelo. Vamos usar um modelo `Sequential` com duas camadas ocultas densamente conectadas e uma camada de saída que conta um valor único e contínuo. As etapas de construção do modelo estão ao redor de uma função, a `build_model`, já que criaremos um segundo modelo mais tarde.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspecionar o modelo
Use o método `.summary` para mostrar uma descrição simples do modelo
"""
model.summary()
"""Agora teste o modelo. Separe um lote com `10` exemplos dos dados de treinamento e chame `model.predict` nele.
Parece estar funcionando, e produz um resultado de formato e tipo esperados.
### Treinar o modelo
Treine o modelo por 1000 períodos e grave a acurácia tanto do treinamento quanto da validação no objeto `history`.
Use as estatísticas armazenadas no objeto `history` para visualizar o progresso do treinamento do modelo.
Este gráfico mostra pouca melhoria — talvez até degradação — na pontuação de validação após 100 períodos. Vamos atualizar a chamada a `model.fit` para interromper o treinamento automaticamente quando a pontuação de validação não melhorar. Usaremos um *callback do tipo EarlyStopping* que testa uma condição de treinamento para cada período. Se uma quantidade definida de períodos passarem sem que se observe melhoria, o treinamento será parado.
Saiba mais sobre esse callback [neste link](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# O parâmetro `patience` é a quantidade de períodos a serem verificados em busca de melhorias
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Exporta o modelo e salva no GCS
model.save(BUCKET + '/mpg/model')
Crie e teste o contêiner de forma local
No seu terminal, defina uma variável com o URI da imagem do seu contêiner no Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/mpg:v1"
Agora execute seguinte o comando na raiz do diretório mpg para criar o contêiner:
docker build ./ -t $IMAGE_URI
Execute o contêiner na sua instância do Workbench para verificar se ela funciona corretamente:
docker run $IMAGE_URI
O modelo deve encerrar o treinamento dentro de 1 a 2 minutos com uma precisão de validação de aproximadamente 72% (a precisão exata pode variar). Quando terminar de executar o contêiner localmente, envie-o para o Google Container Registry:
docker push $IMAGE_URI
Depois que nosso contêiner for enviado para o Container Registry, estará tudo pronto para iniciar um job de treinamento de modelo personalizado.
Tarefa 3: execute um job de treinamento na Vertex AI
Há duas opções de modelos de treinamento na Vertex AI:
AutoML: treine modelos de alta qualidade com esforço mínimo e experiência em ML.
Treinamento personalizado: execute seus aplicativos de treinamento personalizados na nuvem usando um dos contêineres pré-criados do Google Cloud ou seus próprios.
Neste laboratório, você vai usar o treinamento exclusivo do nosso próprio contêiner personalizado no Google Container Registry. Para começar, acesse a seção Model Registry na seção "Vertex" do console do Cloud:
Iniciar o job de treinamento
Clique em Criar para inserir os parâmetros do seu job de treinamento e modelo implantado:
Em Conjunto de dados, selecione Sem conjunto de dados gerenciado.
Selecione Treinamento personalizado (avançado) como seu método de treinamento e clique em Continuar.
Escolha Treinar novo modelo e insira mpg (ou o nome que quiser) em "Nome do modelo".
Clique em Continuar.
Na etapa Configurações do contêiner, selecione Contêiner personalizado:
Na primeira caixa (Imagem de contêiner no GCR), insira o valor da sua variável IMAGE_URI acima. Deve ficar assim: gcr.io/your-cloud-project/mpg:v1, com seu próprio nome de projeto. Deixe os demais campos em branco e clique em Continuar.
Você não vai usar o ajuste de hiperparâmetros neste tutorial, então pode deixar a caixa Ativar o ajuste de hiperparâmetrosdesmarcada e clicar em Continuar.
Em Computação e preços, selecione a Região e Implantar em um novo pool de workers. Em "Tipo de máquina", selecione e2-standard-4 e clique em Continuar.
Como o modelo desta demonstração treina rapidamente, você vai usar um tipo de máquina menor.
Observação: se você quiser, fique à vontade para testar tipos de máquina maiores e GPUs. Se você usar as GPUs, terá que utilizar uma imagem de contêiner base habilitada para GPU.
Na etapa Contêiner de previsão, selecione Contêiner pré-criado e 2.11 como a Versão do framework do modelo.
Não mexa nas configurações padrão do contêiner pré-criado. Em Diretório do modelo, insira seu bucket do GCS com o subdiretório mpg. Esse é o caminho no seu script de treinamento do modelo onde você exporta o modelo treinado. Ele será parecido com o seguinte:
A Vertex vai procurar neste local quando implantar seu modelo. Agora está tudo pronto para o treinamento! Clique em Iniciar treinamento para começar seu job de treinamento. Na seção Treinamento do console, selecione Região e você vai encontrar algo assim:
Observação: a conclusão do job de treinamento vai levar de 15 a 20 minutos.
Tarefa 4. Implantar um endpoint de modelo
Ao configurar seu job de treinamento, você especificou onde a Vertex AI deve procurar os ativos do seu modelo exportado. Como parte do nosso pipeline de treinamento, a Vertex vai criar um recurso de modelo com base nesse caminho de ativo. O recurso de modelo em si não é um modelo implantado, mas quando você tiver um modelo, estará com tudo pronto para implantá-lo em um endpoint. Para saber mais sobre modelos e endpoints na Vertex AI, consulte a Documentação de introdução da Vertex AI.
Nesta etapa, você vai criar um endpoint para o modelo treinado. Ele pode ser usado para gerar previsões sobre nosso modelo pela API Vertex AI.
Implantar o endpoint
Quando o job de treinamento for concluído, um modelo chamado mpg (ou com algum outro nome que você tiver escolhido) vai aparecer na seção Model Registry do seu console:
Quando o seu job de treinamento foi executado, a Vertex criou um recurso do modelo para você. Para usar esse modelo, é necessário implantar um endpoint. É possível ter diversos endpoints por modelo. Clique no modelo e selecione a guia Implantar e testar. Em seguida, clique em Implantar no endpoint.
Selecione Criar novo endpoint e dê um nome a ele, como v1, e depois clique em Continuar. Deixe a Divisão de tráfego em 100 e insira 1 em Número mínimo de nós de computação. Em Tipo de máquina, selecione e2-standard-2 (ou qualquer tipo de máquina que você quiser). Em seguida, clique em Pronto e depois em Implantar.
A implantação do endpoint vai levar de 10 a 15 minutos. Quando a implantação do endpoint for concluída, o seguinte conteúdo será exibido, mostrando um endpoint implantado no seu recurso do modelo:
Observação: a região do bucket e a região usada para implantar o endpoint do modelo precisam ser iguais.
Acesse previsões no modelo implantado
Você vai receber previsões sobre nosso modelo treinado em um notebook Python, usando a API Vertex Python. Volte à sua instância do Workbench e crie um notebook Python 3 na tela de início:
No notebook, execute o seguinte em uma célula para instalar o SDK da Vertex AI:
Depois adicione uma célula no seu notebook para importar o SDK e criar uma referência ao endpoint que você acabou de implantar:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="projects/YOUR-PROJECT-NUMBER/locations/{{{ project_0.default_region | REGION }}}/endpoints/YOUR-ENDPOINT-ID"
)
Você terá que substituir dois valores no string endpoint_name acima pelo endpoint e número do seu projeto. O valor do Número do projeto pode ser encontrado no painel.
O seu ID do endpoint pode ser encontrado na seção de endpoints do console, como mostrado abaixo:
Por último, faça uma previsão para seu endpoint copiando e executando o código a seguir em uma célula nova:
Este exemplo já tem valores normalizados, que é o formato esperado pelo modelo.
Quando essa célula for executada, será exibida uma previsão em torno de 7 km por litro.
Tarefa 5: limpeza
Escolha uma destas opções:
Para continuar usando o notebook criado neste laboratório, é recomendável que você o desative quando não estiver em uso. A partir da IU de Notebooks no Console do Cloud, selecione o notebook e depois clique em Parar.
Para excluir totalmente o notebook, clique em Excluir.
Para excluir o endpoint implantado, na seção Previsão on-line do console da Vertex AI, selecione Região no menu suspenso e clique em v1. Agora, clique no ícone de três pontos ao lado do endpoint e escolha Cancelar a implantação do modelo do endpoint. Por fim, clique em Cancelar a implantação.
Para remover o endpoint, volte à seção "Endpoints", clique no ícone de ações e em Excluir endpoint.
Para excluir o bucket do Cloud Storage, na página do Cloud Storage, selecione seu bucket e depois clique em Excluir.
Parabéns!
Você aprendeu a usar a Vertex AI para:
Treinar um modelo fornecendo o código de treinamento em um contêiner personalizado. Neste exemplo, você usou um modelo do TensorFlow, mas é possível treinar um modelo criado com qualquer framework usando contêineres personalizados.
Implantar um modelo do TensorFlow usando um contêiner predefinido como parte do mesmo fluxo de trabalho usado no treinamento.
Criar um endpoint de modelo e gerar uma previsão.
Finalize o laboratório
Após terminar seu laboratório, clique em End Lab. O Qwiklabs removerá os recursos usados e limpará a conta para você.
Você poderá avaliar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Submit.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Support.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Neste laboratório, você vai usar a Vertex AI para treinar e disponibilizar um modelo do TensorFlow usando código em um contêiner personalizado.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 120 minutos
·
Tempo para conclusão: 120 minutos
 ), clique em Vertex AI.
), clique em Vertex AI. Criar.
Criar.




 ao lado do endpoint e escolha Cancelar a implantação do modelo do endpoint. Por fim, clique em Cancelar a implantação.
ao lado do endpoint e escolha Cancelar a implantação do modelo do endpoint. Por fim, clique em Cancelar a implantação.




