개요
이번 실습에서는 Vertex AI를 사용하여 커스텀 컨테이너에서 코드로 TensorFlow 모델을 학습시키고 서빙하는 방법을 알아봅니다.
여기에서는 모델 코드를 위해 TensorFlow를 사용하지만 다른 프레임워크로 쉽게 교체할 수 있습니다.
학습 목표
- Vertex Notebooks에서 모델 학습 코드를 빌드하고 컨테이너화합니다.
- Vertex AI에 커스텀 모델 학습 작업을 제출합니다.
- 학습된 모델을 엔드포인트에 배포하고 이 엔드포인트를 사용해 예측을 수행합니다.
Vertex AI 소개
이 실습에서는 Google Cloud에서 제공되는 최신 AI 제품을 사용합니다. Vertex AI는 Google Cloud 전반의 ML 제품을 원활한 개발 환경으로 통합합니다. 예전에는 AutoML로 학습된 모델과 커스텀 모델은 별도의 서비스를 통해 액세스할 수 있었습니다. 새 서비스는 다른 새로운 제품과 함께 두 가지 모두를 단일 API로 결합합니다. 기존 프로젝트를 Vertex AI로 마이그레이션할 수도 있습니다. 의견이 있는 경우 지원 페이지를 참조하세요.
Vertex AI에는 엔드 투 엔드 ML 워크플로를 지원하는 다양한 제품이 포함되어 있습니다. 이 실습에서는 아래에 강조 표시된 학습, 예측, Notebooks 제품에 중점을 둡니다.
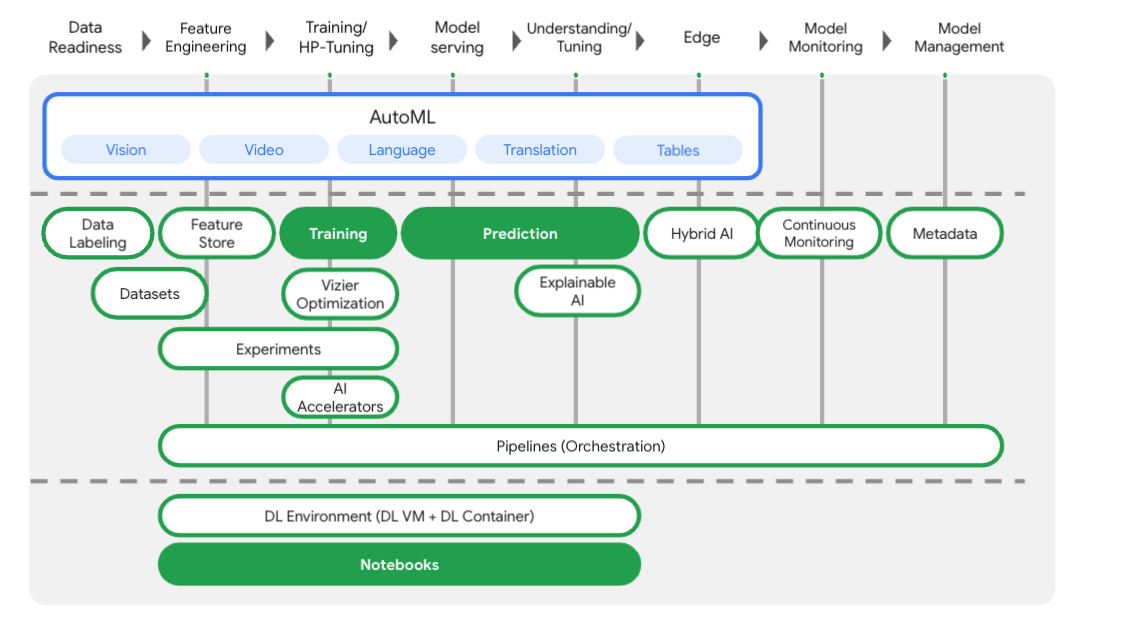
작업 1. 환경 설정하기
각 실습에서는 정해진 기간 동안 새 Google Cloud 프로젝트와 리소스 집합이 무료로 제공됩니다.
-
시크릿 창을 사용하여 Qwiklabs에 로그인합니다.
-
실습 사용 가능 시간(예: 1:15:00)을 참고하여 해당 시간 내에 완료합니다.
일시중지 기능은 없습니다. 필요한 경우 다시 시작할 수 있지만 처음부터 시작해야 합니다.
-
준비가 되면 실습 시작을 클릭합니다.
-
실습 사용자 인증 정보(사용자 이름 및 비밀번호)를 기록해 두세요. Google Cloud Console에 로그인합니다.
-
Google Console 열기를 클릭합니다.
-
다른 계정 사용을 클릭한 다음, 안내 메시지에 이 실습에 대한 사용자 인증 정보를 복사하여 붙여넣습니다.
다른 사용자 인증 정보를 사용하는 경우 오류가 발생하거나 요금이 부과됩니다.
-
약관에 동의하고 리소스 복구 페이지를 건너뜁니다.
Compute Engine API 사용 설정
아직 사용 설정되지 않은 경우 Compute Engine API로 이동하여 사용 설정을 선택합니다. Workbench 인스턴스를 생성하는 데 필요합니다.
Container Registry API 사용 설정
아직 사용 설정되지 않은 경우 Container Registry로 이동하여 사용 설정을 선택합니다. 이를 사용하여 커스텀 학습 작업을 위한 컨테이너를 생성합니다.
Vertex AI Workbench 인스턴스 실행
-
Google Cloud 콘솔의 탐색 메뉴( )에서 Vertex AI를 선택합니다.
)에서 Vertex AI를 선택합니다.
-
모든 권장 API 사용 설정을 클릭합니다.
-
탐색 메뉴에서 Workbench를 클릭합니다.
Workbench 페이지 상단에서 인스턴스 뷰에 있는지 확인합니다.
-
 새로 만들기를 클릭합니다.
새로 만들기를 클릭합니다.
-
인스턴스를 구성합니다.
-
이름: lab-workbench
-
리전: 리전을 (으)로 설정합니다.
-
영역: 영역을 (으)로 설정합니다.
-
고급 옵션(선택사항): 필요한 경우 '고급 옵션'을 클릭하여 추가로 맞춤설정(예: 머신 유형, 디스크 크기)할 수 있습니다.

-
만들기를 클릭합니다.
인스턴스를 만드는 데 몇 분 정도 걸립니다. 준비되면 이름 옆에 녹색 체크표시가 나타납니다.
- 인스턴스 이름 옆에 있는 JupyterLab 열기를 클릭하여 JupyterLab 인터페이스를 실행합니다. 그러면 브라우저에서 새 탭이 열립니다.

내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
Vertex AI Workbench 인스턴스 실행
작업 2. 학습 코드 컨테이너화
학습 코드를 Docker 컨테이너에 넣고 이 컨테이너를 Google Container Registry로 푸시하여 이 학습 작업을 Vertex에 제출합니다. 이 방식을 사용하면 모든 프레임워크로 빌드된 모델을 학습시킬 수 있습니다.
시작하려면 런처 메뉴에서 Workbench 인스턴스의 터미널 창을 엽니다.
mpg라는 새 디렉터리를 만들고 여기로 디렉터리를 변경합니다.
mkdir mpg
cd mpg
Dockerfile 만들기
코드를 컨테이너화하는 첫 번째 단계는 Dockerfile을 만드는 것입니다. Dockerfile에는 이미지를 실행하는 데 필요한 모든 명령어가 포함됩니다. 사용 중인 모든 라이브러리를 설치하고 학습 코드의 진입점을 설정합니다. 터미널에서 빈 Dockerfile을 만듭니다.
touch Dockerfile
mpg > Dockerfile로 이동하여 Dockerfile을 열고 다음을 복사하여 붙여넣습니다.
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /root
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
이 Dockerfile은 Deep Learning Container TensorFlow Enterprise 2.3 Docker 이미지를 사용합니다. Google Cloud의 Deep Learning Containers에는 많은 수의 일반적인 ML 및 데이터 과학 프레임워크가 사전 설치된 상태로 제공됩니다. 사용 중인 버전에는 TF Enterprise 2.3, Pandas, Scikit-learn 등이 포함되어 있습니다. Dockerfile은 해당 이미지를 다운로드한 후 학습 코드의 진입점을 설정합니다. 아직 이 파일을 만들지 않았습니다. 다음 단계에서 모델을 학습시키고 내보내기 위한 코드를 추가하게 됩니다.
Cloud Storage 버킷 만들기
학습 작업에서는 학습된 TensorFlow 모델을 Cloud Storage 버킷으로 내보냅니다. Vertex는 이를 사용하여 내보낸 모델 애셋을 읽고 모델을 배포합니다. 터미널에서 다음을 실행하여 프로젝트의 env 변수를 정의하고 your-cloud-project를 프로젝트의 ID로 바꿉니다.
참고: 터미널에서 gcloud config list --format 'value(core.project)'를 실행하여 프로젝트 ID를 얻을 수 있습니다.
PROJECT_ID='your-cloud-project'
다음으로, 터미널에서 다음을 실행하여 프로젝트에 새 버킷을 만듭니다. -l (위치) 플래그는 이 튜토리얼의 뒷부분에서 모델 엔드포인트를 배포할 리전과 동일한 리전에 있어야 하므로 중요합니다.
BUCKET_NAME="gs://${PROJECT_ID}-bucket"
gsutil mb -l {{{ project_0.default_region | "REGION" }}} $BUCKET_NAME
모델 학습 코드 추가
터미널에서 다음을 실행하여 학습 코드용 디렉터리와 코드를 추가할 Python 파일을 만듭니다.
mkdir trainer
touch trainer/train.py
이제 mpg/ 디렉터리에 다음이 포함됩니다.
+ Dockerfile
+ trainer/
+ train.py
다음으로, mpg > trainer > train.py로 이동하여 방금 만든 train.py 파일을 열고 아래 코드(TensorFlow 문서의 튜토리얼에서 가져옴)를 복사합니다.
파일의 시작 부분에서 BUCKET 변수를 이전 단계에서 만든 스토리지 버킷의 이름으로 업데이트합니다.
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path
"""Import it using pandas"""
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset.tail()
# TODO: replace `your-gcs-bucket` with the name of the Storage bucket you created earlier
BUCKET = 'gs://your-gcs-bucket'
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple, drop those rows."""
dataset = dataset.dropna()
"""The `"Origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
You will use the test set in the final evaluation of your model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation, in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then it will automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
컨테이너를 로컬에서 빌드하고 테스트
터미널에서 Google Container Registry에 있는 컨테이너 이미지의 URI로 변수를 정의합니다.
IMAGE_URI="gcr.io/$PROJECT_ID/mpg:v1"
그런 다음 mpg 디렉터리의 루트에서 다음을 실행하여 컨테이너를 빌드합니다.
docker build ./ -t $IMAGE_URI
Workbench 인스턴스 내에서 컨테이너를 실행하여 올바르게 작동하는지 확인합니다.
docker run $IMAGE_URI
모델은 1~2분 내에 학습을 완료해야 하며 검증 정확도는 약 72%여야 합니다(정확도는 다를 수 있음). 컨테이너를 로컬에서 실행하는 작업을 마쳤으면 Google Container Registry에 푸시합니다.
docker push $IMAGE_URI
컨테이너가 Container Registry로 푸시되었으므로 이제 커스텀 모델 학습 작업을 시작할 준비가 되었습니다.
작업 3. Vertex AI에서 학습 작업 실행
Vertex AI는 학습 모델을 위한 두 가지 옵션을 제공합니다.
-
AutoML: 최소한의 수고와 ML 지식만으로 고품질 모델을 학습시킵니다.
-
커스텀 학습: Google Cloud의 사전 빌드된 컨테이너 또는 자체 컨테이너를 사용하여 클라우드에서 커스텀 학습 애플리케이션을 실행합니다.
이 실습에서는 Google Container Registry의 자체 커스텀 컨테이너를 통한 커스텀 학습을 사용합니다. 시작하려면 Cloud 콘솔의 Vertex 섹션에서 Model Registry 섹션으로 이동합니다.
학습 작업 시작
만들기를 클릭하여 학습 작업 및 배포된 모델을 위한 파라미터를 입력합니다.
-
데이터 세트에서 관리형 데이터 세트 없음을 선택합니다.
- 그런 다음 학습 방법으로 커스텀 학습(고급)을 선택하고 계속을 클릭합니다.
-
새 모델 학습을 선택하고 모델 이름에 mpg(또는 원하는 모델 이름)를 입력합니다.
-
계속을 클릭합니다.
컨테이너 설정 단계에서 커스텀 컨테이너를 선택합니다.
첫 번째 상자(GCR의 컨테이너 이미지)에 위의 IMAGE_URI 변수 값을 입력합니다. 사용자 고유의 프로젝트 이름이 포함된 gcr.io/your-cloud-project/mpg:v1이어야 합니다. 나머지 필드는 비워 두고 계속을 클릭합니다.
이 튜토리얼에서는 하이퍼파라미터 조정을 사용하지 않으므로 하이퍼파라미터 조정 사용 설정 체크박스를 선택 해제하고 계속을 클릭합니다.
컴퓨팅 및 가격 책정에서 리전 을 선택하고 새 작업자 풀에 배포를 선택한 다음 머신 유형으로 e2-standard-4를 선택하고 계속을 클릭합니다.
이 데모의 모델은 빠르게 학습되므로 더 작은 머신 유형을 사용합니다.
참고: 원하는 경우 더 큰 머신 유형과 GPU를 사용해 실험해 볼 수 있습니다. GPU를 사용하는 경우 GPU 지원 기본 컨테이너 이미지를 사용해야 합니다.
예측 컨테이너 단계에서사전 빌드된 컨테이너를 선택하고 모델 프레임워크 버전으로 2.11을 선택합니다.
사전 빌드된 컨테이너의 기본 설정을 그대로 둡니다. 모델 디렉터리의 경우 mpg 하위 디렉터리가 있는 GCS 버킷을 탐색합니다. 이 경로로 모델 학습 스크립트에서 학습된 모델을 내보냅니다. 예를 들면 다음과 같습니다.

Vertex는 모델을 배포할 때 이 위치를 살펴봅니다. 이제 학습을 진행할 준비가 되었습니다. 학습 시작을 클릭하여 학습 작업을 시작합니다. 콘솔의 학습 섹션에서 리전 을 선택하면 다음과 같은 내용이 표시됩니다.
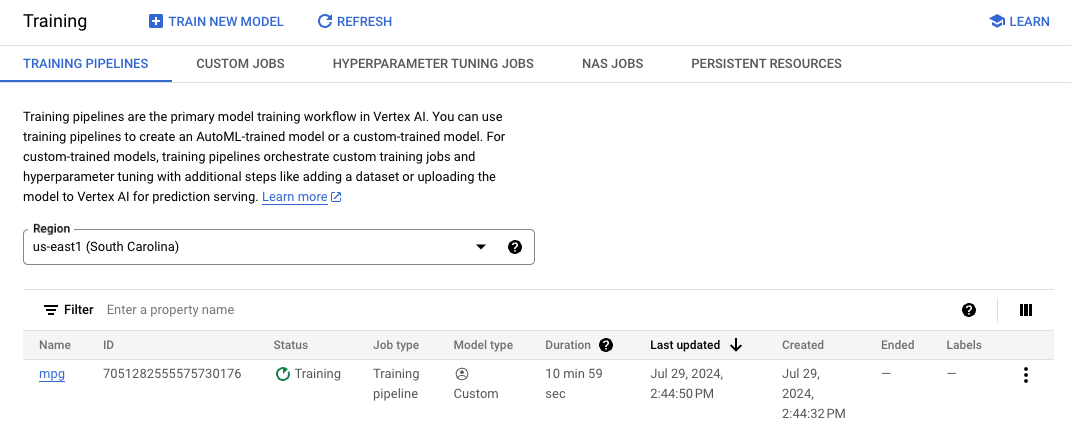
참고: 학습 작업을 완료하는 데 약 15~20분이 걸립니다.
작업 4. 모델 엔드포인트 배포
학습 작업을 설정할 때 Vertex AI가 찾을 수 있도록 내보낸 모델 애셋 위치를 지정했습니다. 학습 파이프라인의 일부로 Vertex는 이 애셋 경로를 기반으로 모델 리소스를 만듭니다. 모델 리소스 자체는 배포된 모델이 아니지만 모델이 있으면 엔드포인트에 배포할 준비가 된 것입니다. Vertex AI의 모델과 엔드포인트에 대해 자세히 알아보려면 Vertex AI의 시작하기 문서를 확인해 보세요.
이 단계에서는 학습된 모델의 엔드포인트를 만듭니다. 이 엔드포인트를 사용하면 Vertex AI API를 통해 모델에 대한 예측을 얻을 수 있습니다.
엔드포인트 배포
학습 작업이 완료되면 콘솔의 Model Registry 섹션에 mpg라는 이름(또는 사용자가 지정한 이름)의 모델이 표시됩니다.
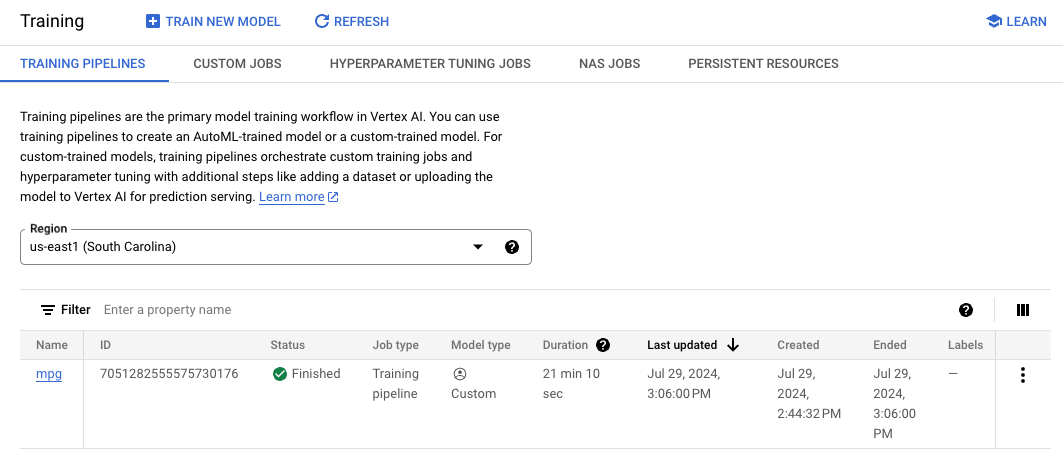
학습 작업이 실행되면 Vertex가 모델 리소스를 생성합니다. 이 모델을 사용하려면 엔드포인트를 배포해야 합니다. 모델당 여러 엔드포인트를 가질 수 있습니다. 모델을 클릭하고 배포 및 테스트 탭을 선택한 다음 엔드포인트에 배포를 클릭합니다.
새 엔드포인트 만들기를 선택하고 v1과 같은 이름을 지정한 다음 계속을 클릭합니다. 트래픽 분할을 100으로 두고 최소 컴퓨팅 노드 수에 1을 입력합니다. 머신 유형에서 e2-standard-2(또는 원하는 머신 유형)를 선택합니다. 그런 다음 완료를 클릭한 후 배포를 클릭합니다.
엔드포인트를 배포하는 데 10~15분이 소요됩니다. 엔드포인트 배포가 완료되면 다음 화면이 표시되고 모델 리소스에 배포된 하나의 엔드포인트를 확인할 수 있습니다.
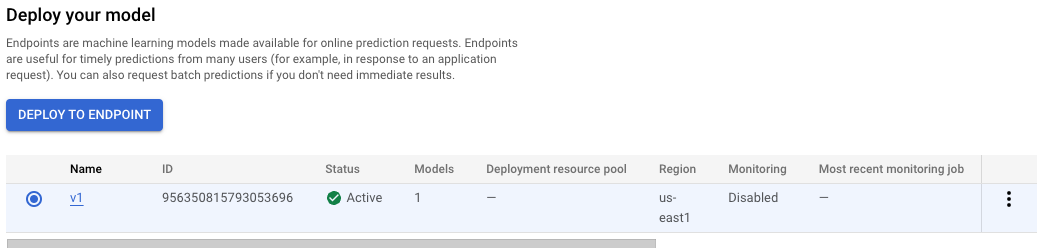
참고: 버킷 리전과 모델 엔드포인트를 배포하는 데 사용되는 리전은 동일해야 합니다.
배포된 모델에 대한 예측 수행
Vertex Python API를 사용하여 Python 노트북에서 학습된 모델에 대한 예측을 가져옵니다. Workbench 인스턴스로 돌아가서 런처에서 Python 3 노트북을 만듭니다.

노트북의 셀에서 다음을 실행하여 Vertex AI SDK를 설치합니다.
!pip3 install google-cloud-aiplatform --upgrade --user
그런 다음 노트북에 셀을 추가하여 SDK를 가져오고 방금 배포한 엔드포인트에 대한 참조를 생성합니다.
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="projects/YOUR-PROJECT-NUMBER/locations/{{{ project_0.default_region | REGION }}}/endpoints/YOUR-ENDPOINT-ID"
)
위의 endpoint_name 문자열에서 두 개의 값을 프로젝트 번호와 엔드포인트로 바꿔야 합니다. 프로젝트 번호는 프로젝트 대시보드로 이동하여 프로젝트 번호 값을 확인한 후 가져오면 됩니다.
엔드포인트 ID는 콘솔의 엔드포인트 섹션에서 찾을 수 있습니다.

마지막으로 아래 코드를 새 셀에 복사하고 실행하여 엔드포인트에 대한 예측을 수행합니다.
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
이 예시에는 모델이 기대하는 형식의 정규화된 값이 있습니다.
이 셀을 실행하면 갤런당 약 16마일의 예측 출력이 표시됩니다.
작업 5. 삭제
-
다음 중 하나를 수행합니다.
- 이 실습에서 만든 노트북을 계속 사용하려면 사용하지 않을 때 노트북을 끄는 것이 좋습니다. Cloud 콘솔의 Notebooks UI에서 노트북을 선택한 다음 중지를 클릭합니다.
- 노트북을 완전히 삭제하려면 삭제를 클릭합니다.
-
배포한 엔드포인트를 삭제하려면 Vertex AI 콘솔의 온라인 예측 섹션에 있는 드롭다운 메뉴에서 리전 을 선택하고 v1을 클릭합니다. 이제 엔드포인트 옆에 있는 점 3개 아이콘  을 클릭하고 엔드포인트에서 모델 배포 취소를 선택합니다. 마지막으로 배포 취소를 클릭합니다.
을 클릭하고 엔드포인트에서 모델 배포 취소를 선택합니다. 마지막으로 배포 취소를 클릭합니다.
-
엔드포인트를 삭제하려면 엔드포인트 섹션으로 돌아가서 작업 아이콘 을 클릭한 다음 엔드포인트 삭제를 클릭합니다.
-
Cloud Storage 버킷을 삭제하려면 Cloud Storage 페이지에서 버킷을 선택한 다음 삭제를 클릭합니다.
수고하셨습니다
지금까지 Vertex AI를 사용하여 다음을 수행하는 방법을 배웠습니다.
- 커스텀 컨테이너에 학습 코드를 제공하여 모델을 학습시킵니다. 이 예에서는 TensorFlow 모델을 사용했지만 커스텀 컨테이너를 사용하여 모든 프레임워크로 빌드된 모델을 학습시킬 수 있습니다.
- 학습에 사용한 것과 동일한 워크플로의 일부로 사전 빌드된 컨테이너를 사용하여 TensorFlow 모델을 배포합니다.
- 모델 엔드포인트를 만들고 예측을 생성합니다.
실습 종료
실습을 완료하면 실습 종료를 클릭합니다. Qwiklabs에서 사용된 리소스를 자동으로 삭제하고 계정을 지웁니다.
실습 경험을 평가할 수 있습니다. 해당하는 별표 수를 선택하고 의견을 입력한 후 제출을 클릭합니다.
별점의 의미는 다음과 같습니다.
- 별표 1개 = 매우 불만족
- 별표 2개 = 불만족
- 별표 3개 = 중간
- 별표 4개 = 만족
- 별표 5개 = 매우 만족
의견을 제공하고 싶지 않다면 대화상자를 닫으면 됩니다.
의견이나 제안 또는 수정할 사항이 있다면 지원 탭을 사용하세요.
Copyright 2020 Google LLC All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.





