概要
このラボでは、Vertex AI を活用して、カスタム コンテナ内のコードを使用した TensorFlow モデルのトレーニングとサービングを行う方法を学びます。
ここではモデルのコードに TensorFlow を使用していますが、別のフレームワークに簡単に置き換えることができます。
学習目標
- Vertex Notebooks でモデルのトレーニング コードを構築してコンテナ化する。
- カスタムモデルのトレーニング ジョブを Vertex AI に送信する。
- トレーニングしたモデルをエンドポイントにデプロイし、そのエンドポイントを使用して予測を行う。
Vertex AI の概要
このラボでは、Google Cloud で利用できる最新の AI プロダクトを使用します。Vertex AI は Google Cloud 全体の ML サービスを統合してシームレスな開発エクスペリエンスを提供します。以前は、AutoML でトレーニングしたモデルやカスタムモデルには、個別のサービスを介してアクセスする必要がありました。Vertex AI は、これらの個別のサービスを他の新しいプロダクトとともに 1 つの API へと結合します。既存のプロジェクトを Vertex AI に移行することもできます。ご意見やご質問がありましたら、サポートページからお寄せください。
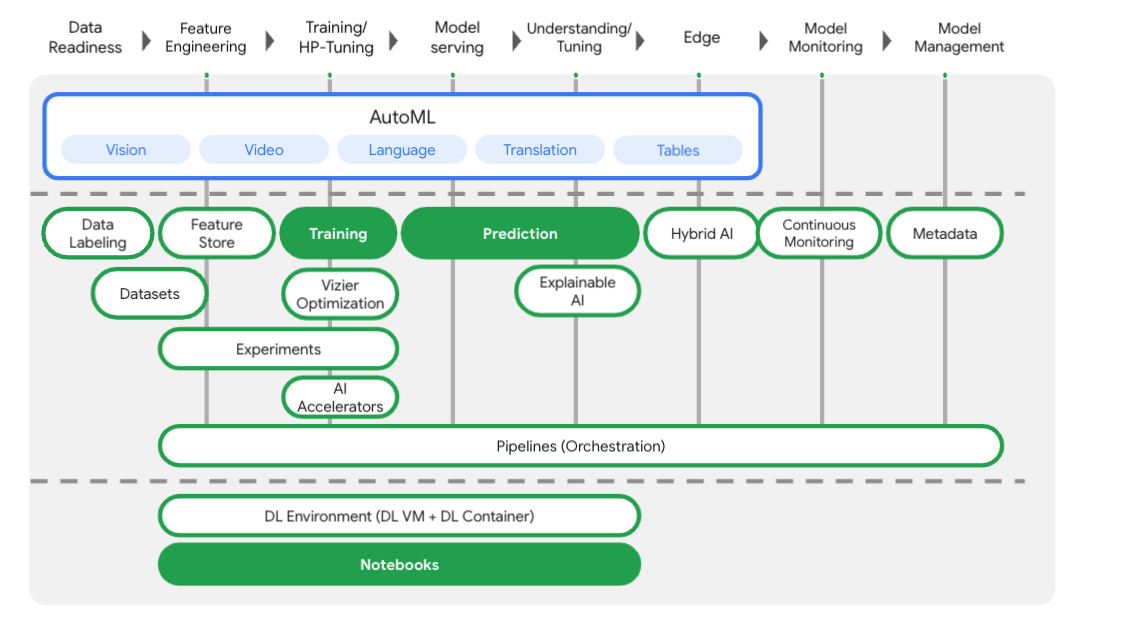
Vertex AI には、エンドツーエンドの ML ワークフローをサポートするさまざまなプロダクトが含まれています。このラボでは、以下でハイライト表示されたプロダクト(Training、Prediction、Notebooks)を取り上げます。
タスク 1. 環境を設定する
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
-
Qwiklabs にシークレット ウィンドウでログインします。
-
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
-
準備ができたら、[ラボを開始] をクリックします。
-
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
-
[Google Console を開く] をクリックします。
-
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
-
利用規約に同意し、再設定用のリソースページをスキップします。
Compute Engine API を有効にする
まだ有効になっていない場合は、[Compute Engine API] に移動して [有効にする] を選択します。これは Workbench インスタンスを作成するために必要です。
Container Registry API を有効にする
まだ有効になっていない場合は、[Container Registry] に移動して [有効にする] を選択します。これは、カスタム トレーニング ジョブのコンテナを作成するために使用します。
Vertex AI Workbench のインスタンスを起動する
-
Google Cloud コンソールのナビゲーション メニュー( )で [Vertex AI] を選択します。
)で [Vertex AI] を選択します。
-
[すべての推奨 API を有効化] をクリックします。
-
ナビゲーション メニューで [ワークベンチ] をクリックします。
[ワークベンチ] ページの上部で、[インスタンス] ビューになっていることを確認します。
-
[ 新規作成] をクリックします。
新規作成] をクリックします。
-
インスタンスの構成:
-
名前: lab-workbench
-
リージョン: リージョンを に設定します
-
ゾーン: ゾーンを に設定します
-
詳細オプション(任意): 必要に応じて [詳細オプション] をクリックして、より詳細なカスタマイズを行います(マシンタイプ、ディスクサイズなど)。

- [作成] をクリックします。
インスタンスが作成されるまで数分かかります。作成が完了するとインスタンスの名前の横に緑色のチェックマークが付きます。
- インスタンスの名前の横に表示されている [JupyterLab を開く] をクリックして JupyterLab インターフェースを起動します。ブラウザで新しいタブが開きます。

[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Vertex AI Workbench のインスタンスを起動する
タスク 2. トレーニング コードをコンテナ化する
このトレーニング ジョブを Vertex に送信しましょう。トレーニング コードを Docker コンテナに格納して、このコンテナを Google Container Registry に push します。この方法を使用すると、どのフレームワークで構築されたモデルでもトレーニングできます。
まず、Launcher メニューから、Workbench インスタンスでターミナル ウィンドウを開きます。
mpg という新しいディレクトリを作成し、cd コマンドでワーキング ディレクトリに変更します。
mkdir mpg
cd mpg
Dockerfile を作成する
コードをコンテナ化する最初のステップは、Dockerfile の作成です。Dockerfile には、イメージの実行に必要なすべてのコマンドを含めます。使用しているすべてのライブラリがインストールされ、トレーニング コードのエントリ ポイントが設定されます。ターミナルで、空の Dockerfile を作成します。
touch Dockerfile
mpg > Dockerfile に移動して Dockerfile を開き、次の内容をコピーします。
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /root
WORKDIR /
# トレーナー コードを Docker イメージにコピーします。
COPY trainer /trainer
# トレーナーを呼び出すエントリ ポイントを設定します。
ENTRYPOINT ["python", "-m", "trainer.train"]
この Dockerfile は、Deep Learning Containers TensorFlow Enterprise 2.3 Docker イメージを使用します。Google Cloud の Deep Learning Containers には一般的な ML およびデータ サイエンスのフレームワークが数多くプリインストールされています。使用しているものには、TF Enterprise 2.3、Pandas、Scikit-learn などが含まれます。この Dockerfile は、該当するイメージをダウンロードした後、トレーニング コードのエントリ ポイントを設定します。これらのファイルはまだ作成していません。次のステップで、モデルのトレーニングおよびエクスポート用のコードを追加します。
Cloud Storage バケットを作成する
トレーニング ジョブでは、トレーニング済みの TensorFlow モデルを Cloud Storage バケットにエクスポートします。Vertex はこれを使用して、エクスポートされたモデルアセットを読み取り、モデルをデプロイします。ターミナルで以下のコマンドを実行して、プロジェクトの環境変数を定義します。その際、your-cloud-project の部分は使用しているプロジェクト ID に置き換えてください。
注: プロジェクト ID を取得するには、ターミナルで gcloud config list --format 'value(core.project)' を実行します。
PROJECT_ID='your-cloud-project'
次に、ターミナルで次のコマンドを実行して、プロジェクトに新しいバケットを作成します。-l(ロケーション)フラグは、チュートリアルの後半でモデル エンドポイントをデプロイするのと同じリージョンに存在する必要があるため、重要です。
BUCKET_NAME="gs://${PROJECT_ID}-bucket"
gsutil mb -l {{{ project_0.default_region | "REGION" }}} $BUCKET_NAME
モデルのトレーニング コードを追加する
ターミナルで次のコマンドを実行して、トレーニング コード用のディレクトリと、コードを追加する Python ファイルを作成します。
mkdir trainer
touch trainer/train.py
mpg/ ディレクトリに次のものが作成されます。
+ Dockerfile
+ trainer/
+ train.py
次に、mpg > trainer > train.py に移動して、作成した train.py ファイルを開き、以下のコードをコピーします(これは TensorFlow ドキュメントのチュートリアルから引用しています)。
ファイルの先頭で、前のステップで作成した Storage バケットの名前で BUCKET 変数を更新します。
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path
"""Import it using pandas"""
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset.tail()
# TODO: replace `your-gcs-bucket` with the name of the Storage bucket you created earlier
BUCKET = 'gs://your-gcs-bucket'
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple, drop those rows."""
dataset = dataset.dropna()
"""The `"Origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
You will use the test set in the final evaluation of your model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation, in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then it will automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
コンテナをローカルで構築してテストする
ターミナルから、Google Container Registry 内のコンテナ イメージの URI を示す変数を定義します。
IMAGE_URI="gcr.io/$PROJECT_ID/mpg:v1"
続いて、mpg ディレクトリのルートで次のコマンドを実行してコンテナをビルドします。
docker build ./ -t $IMAGE_URI
Workbench インスタンス内でコンテナを実行して、正しく動作していることを確認します。
docker run $IMAGE_URI
モデルのトレーニングは 1~2 分で終了し、検証精度は 72% 程度になります(正確な精度は異なる場合があります)。コンテナのローカルでの実行が終了したら、Google Container Registry に push します。
docker push $IMAGE_URI
コンテナを Container Registry に push したら、カスタムモデルのトレーニング ジョブをいつでも開始できます。
タスク 3. Vertex AI でトレーニング ジョブを実行する
Vertex AI では、次の 2 つの方法でモデルをトレーニングできます。
-
AutoML: 最小限の労力と ML の専門知識で高品質なモデルをトレーニングする
-
カスタム トレーニング: Google Cloud のビルド済みコンテナまたは独自のコンテナのいずれかを使用して、クラウド内でカスタム トレーニング アプリケーションを実行する
このラボでは、Google Container Registry 上の独自のカスタム コンテナを使用してカスタム トレーニングを行います。まず、Cloud コンソールの [Vertex] セクションにある [Model Registry] セクションに移動します。
トレーニング ジョブを開始する
[作成] をクリックして、トレーニング ジョブとデプロイされたモデルのパラメータを入力します。
- [データセット] で [マネージド データセットなし] を選択します。
- トレーニング方法として [カスタム トレーニング(上級者向け)] を選択し、[続行] をクリックします。
- [新しいモデルのトレーニング] を選択し、[モデル名] に「mpg」(または任意のモデル名)を入力します。
- [続行] をクリックします。
[コンテナ設定] ステップで、[カスタム コンテナ] を選択します。
最初のボックス(GCR 上のコンテナ イメージ)で、上述の IMAGE_URI 変数の値を入力します。これは、gcr.io/your-cloud-project/mpg:v1(your-cloud-project は使用しているプロジェクト名で置き換える)のようになります。その他のフィールドは空白のままにして、[続行] をクリックします。
このチュートリアルでは、[Enable hyperparameter tuning] ボックスのチェックをオフのままにして、[続行] をクリックします。
[コンピューティングと料金] で [リージョン] を選択し、[新しいワーカープールにデプロイ] を選択します。[マシンタイプ] として「e2-standard-4」を選択し、[続行] をクリックします。
このデモのモデルは短時間でトレーニングが完了するため、小さめのマシンタイプを使用しています。
注: 必要に応じて、より大きなマシンタイプや GPU を試してみることも可能です。GPU を使用する場合は、GPU 対応のベース コンテナ イメージを使用する必要があります。
[予測コンテナ] ステップで、[ビルド済みコンテナ] を選択し、[モデル フレームワークのバージョン] として「2.11」を選択します。
ビルド済みコンテナのデフォルト設定はそのままにしておきます。[モデル ディレクトリ] として、GCS バケットの mpg サブディレクトリを参照して選択します。これは、トレーニング済みモデルをエクスポートするモデル トレーニング スクリプト内のパスです。次のようになります。

Vertex はモデルをデプロイするときにこの場所を検索します。これでトレーニングの準備が整いました。[トレーニングを開始] をクリックして、トレーニング ジョブを開始します。コンソールの [トレーニング] セクションで [リージョン] を選択すると、次のように表示されます。
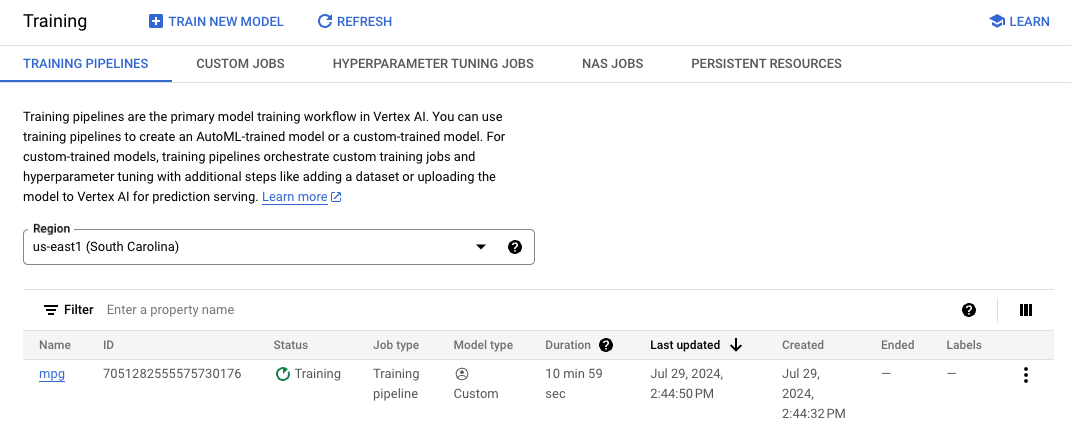
注: トレーニング ジョブが完了するまでに約 15~20 分かかります。
タスク 4. モデルのエンドポイントをデプロイする
トレーニング ジョブを設定するときに、Vertex AI がエクスポートしたモデルアセットを検索する場所を指定しました。トレーニング パイプラインの一部として、Vertex はこのアセットパスに基づいてモデルリソースを作成します。モデルリソース自体はデプロイされたモデルではありませんが、モデルが作成できたら、それをエンドポイントにデプロイする準備が整います。Vertex AI のモデルとエンドポイントの詳細については、Vertex AI のスタートガイド ドキュメントをご覧ください。
このステップでは、トレーニング済みモデルのエンドポイントを作成します。これを使用して、Vertex AI API 経由でモデルの予測を取得できます。
エンドポイントをデプロイする
トレーニング ジョブが完了すると、コンソールの [Model Registry] セクションに mpg という名前(または自身で付けた名前)のモデルが表示されます。
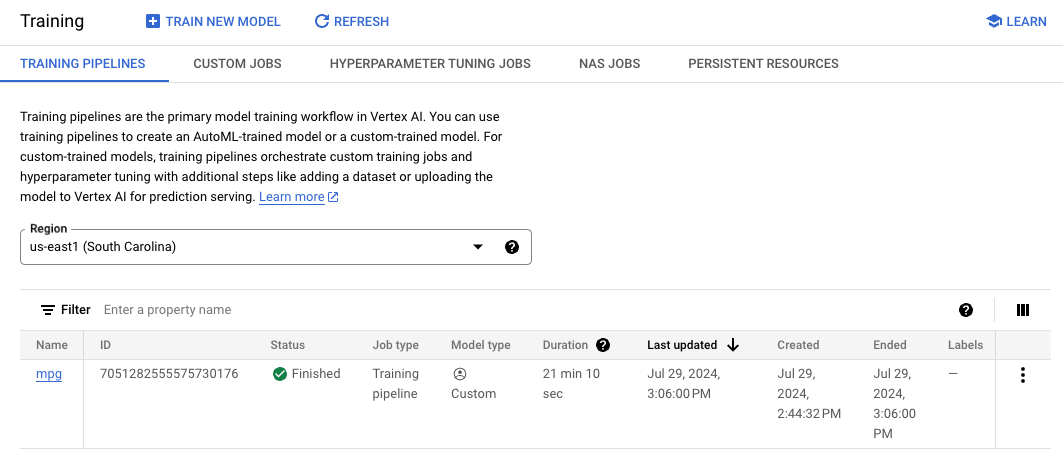
トレーニング ジョブが実行されると、Vertex がモデルリソースを作成します。このモデルを使用するには、エンドポイントをデプロイする必要があります。モデルごとに多数のエンドポイントを作成できます。モデルをクリックして [デプロイとテスト] タブを選択し、[エンドポイントにデプロイ] をクリックします。
[新しいエンドポイントを作成する] を選択し、「v1」などの名前を付けて [続行] をクリックします。[トラフィック分割] は 100 のままにし、[コンピューティング ノードの最小数] に「1」を入力します。[マシンタイプ] で、「e2-standard-2」(または任意のマシンタイプ)を選択します。[完了]、[デプロイ] の順にクリックします。
エンドポイントのデプロイには 10~15 分かかります。エンドポイントのデプロイが完了すると、モデルリソースの下にデプロイされた 1 つのエンドポイントが次のように表示されます。
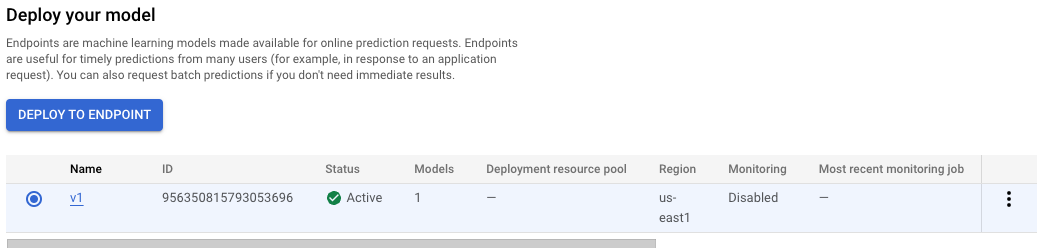
注: バケット リージョンとモデル エンドポイントのデプロイに使用するリージョンは同じである必要があります。
デプロイしたモデルの予測を取得する
Vertex Python API を使用して、Python ノートブックからトレーニング済みモデルの予測を取得します。Workbench インスタンスに戻り、Launcher から Python 3 ノートブックを作成します。

ノートブックで、下のコマンドをセル内で実行し、Vertex AI SDK をインストールします。
!pip3 install google-cloud-aiplatform --upgrade --user
次に、SDK をインポートするためのセルをノートブックに追加し、デプロイしたエンドポイントへの参照を作成します。
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="projects/YOUR-PROJECT-NUMBER/locations/{{{ project_0.default_region | REGION }}}/endpoints/YOUR-ENDPOINT-ID"
)
上記の endpoint_name 文字列内の 2 つの値を、使用しているプロジェクト番号とエンドポイントに置き換える必要があります。プロジェクト番号を確認するには、プロジェクト ダッシュボードに移動し、プロジェクト番号の値を取得します。
エンドポイント ID は、コンソールのエンドポイント セクションで確認できます。

最後に、以下のコードを新しいセルにコピーして実行し、エンドポイントに対する予測を作成します。
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
この例には、モデルが期待する形式である正規化された値がすでに含まれています。
このセルを実行すると、1 ガロンあたり約 16 マイルの予測出力が表示されるはずです。
タスク 5. クリーンアップ
-
次のいずれかを行います。
- このラボで作成したノートブックを使い続ける場合は、未使用時にオフにすることをおすすめします。Cloud コンソールの Notebooks UI で、ノートブックを選択して [停止] をクリックします。
- ノートブックを完全に削除するには、[削除] をクリックします。
-
デプロイしたエンドポイントを削除するには、Vertex AI コンソールの [オンライン予測] セクションで、プルダウンから [リージョン] を選択し、[v1] をクリックします。エンドポイントの横にあるその他アイコン  をクリックし、[エンドポイントからモデルのデプロイを解除] を選択します。最後に、[デプロイ解除] をクリックします。
をクリックし、[エンドポイントからモデルのデプロイを解除] を選択します。最後に、[デプロイ解除] をクリックします。
-
エンドポイントを削除するには、[エンドポイント] セクションに戻り、アクション アイコン をクリックし、[エンドポイントを削除] をクリックします。
-
Cloud Storage バケットを削除するには、[Cloud Storage] ページでバケットを選択して [削除] をクリックします。
お疲れさまでした
Vertex AI を使って次のことを行う方法を学びました。
- カスタム コンテナにトレーニング コードを提供してモデルをトレーニングする。ここでは例として TensorFlow モデルを使用しましたが、カスタム コンテナを使って任意のフレームワークで構築されたモデルをトレーニングすることができます。
- トレーニングに使用したのと同じワークフローの一環として、ビルド済みコンテナを使用して TensorFlow モデルをデプロイする。
- モデルのエンドポイントを作成し、予測を生成する。
ラボを終了する
ラボでの学習が完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Qwiklabs から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
- 星 1 つ = 非常に不満
- 星 2 つ = 不満
- 星 3 つ = どちらともいえない
- 星 4 つ = 満足
- 星 5 つ = 非常に満足
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバック、ご提案、修正が必要な箇所については、[サポート] タブからお知らせください。
Copyright 2020 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。





