En este lab, aprenderás a usar Vertex AI para entrenar y entregar un modelo de TensorFlow con código alojado en un contenedor personalizado.
Si bien aquí usaremos TensorFlow para el código del modelo, puedes reemplazarlo fácilmente por otro framework.
Objetivos de aprendizaje
Compilar código de entrenamiento de modelos y alojarlo en contenedores en Notebooks de Vertex
Enviar un trabajo de entrenamiento de modelo personalizado a Vertex AI
Implementar el modelo entrenado en un extremo y usar ese extremo para obtener predicciones
Introducción a Vertex AI
En este lab, se utiliza la oferta de productos de IA más reciente de Google Cloud. Vertex AI integra las ofertas de AA de Google Cloud en una experiencia de desarrollo fluida. Anteriormente, se podía acceder a los modelos personalizados y a los entrenados con AutoML mediante servicios independientes. La nueva oferta combina ambos en una sola API, junto con otros productos nuevos. También puedes migrar proyectos existentes a Vertex AI. Para enviarnos comentarios, visita la página de asistencia.
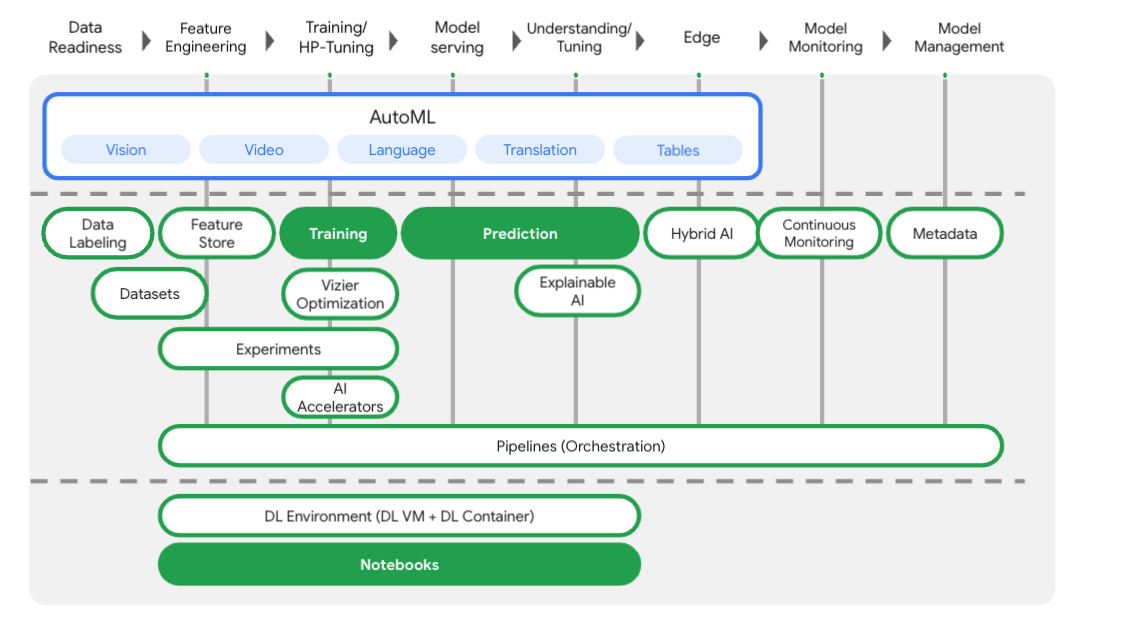
Vertex AI incluye muchos productos distintos para respaldar flujos de trabajo de AA de extremo a extremo. Este lab se centrará en los productos que se destacan a continuación: Training, Prediction y Notebooks.
Tarea 1. Configura tu entorno
En cada lab, recibirá un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Qwiklabs desde una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesita, puede reiniciar el lab, pero deberá hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usa otras credenciales, se generarán errores o incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Habilita la API de Compute Engine
Ve a Compute Engine API y selecciona Habilitar si aún no está habilitada. La necesitarás para crear la instancia de Workbench.
Habilita la API de Container Registry
Ve a Container Registry API y selecciona Habilitar si aún no lo has hecho. La usarás para crear un contenedor para tu trabajo de entrenamiento personalizado.
Inicia la instancia de Vertex AI Workbench
En el menú de navegación () de la consola de Google Cloud, selecciona Vertex AI.
Haz clic en Habilitar todas las APIs recomendadas.
En el menú de navegación, haz clic en Workbench.
En la parte superior de la página de Workbench, asegúrate de estar en la vista Instancias.
Haz clic en Crear nueva.
Configura la instancia:
Nombre: lab-workbench
Región: Configura la región como
Zona: Establece la zona en
Opciones avanzadas (opcional): Si es necesario, haz clic en "Opciones avanzadas" para realizar personalizaciones adicionales (p. ej., tipo de máquina, tamaño del disco).
Haz clic en Crear.
La instancia tardará algunos minutos en crearse. Se mostrará una marca de verificación verde junto a su nombre cuando esté lista.
Haz clic en ABRIR JUPYTERLAB junto al nombre de la instancia para iniciar la interfaz de JupyterLab. Se abrirá una pestaña nueva en el navegador.
Haz clic en Revisar mi progreso para verificar el objetivo.
Iniciar la instancia de Vertex AI Workbench
Tarea 2: Aloja el código de entrenamiento en contenedores
Para enviar este trabajo de entrenamiento a Vertex, tendrás que colocar el código de entrenamiento en un contenedor de Docker y enviarlo a Google Container Registry. Con este enfoque, puedes entrenar un modelo compilado con cualquier framework.
Para comenzar, en el menú Selector, abre una ventana de terminal en tu instancia de Workbench:
Crea un directorio nuevo llamado mpg y cambia a él con el comando cd:
mkdir mpg
cd mpg
Crea un Dockerfile
El primer paso para alojar el código en un contenedor es crear un Dockerfile. En él, incluirás todos los comandos necesarios para ejecutar la imagen. Así, se instalarán todas las bibliotecas que utilices y se configurará el punto de entrada para el código de entrenamiento. En la terminal, crea un Dockerfile vacío:
touch Dockerfile
Para abrir el Dockerfile, navega a mpg > Dockerfile y copia lo siguiente:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /root
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Este Dockerfile usa la imagen de Docker con TensorFlow Enterprise 2.3 para contenedores de aprendizaje profundo. Los contenedores de aprendizaje profundo en Google Cloud tienen preinstalados muchos frameworks comunes de AA y ciencia de datos. El que estás utilizando incluye TF Enterprise 2.3, Pandas, scikit-learn y más. Después de descargar esa imagen, este Dockerfile configura el punto de entrada para el código de entrenamiento. Aún no creas estos archivos; en el siguiente paso, agregarás el código para entrenar y exportar el modelo.
Crea un bucket de Cloud Storage
En el trabajo de entrenamiento, exportarás el modelo entrenado de TensorFlow a un bucket de Cloud Storage. Vertex lo usará para leer los recursos exportados del modelo y, además, implementarlo. En la terminal, ejecuta el siguiente comando para definir una variable de entorno en tu proyecto. Asegúrate de reemplazar your-cloud-project por el ID del proyecto:
Nota: Puedes obtener el ID del proyecto ejecutando gcloud config list --format 'value(core.project)' en la terminal.
PROJECT_ID='your-cloud-project'
Luego, ejecuta el siguiente comando en la terminal para crear un nuevo bucket en el proyecto. La marca -l (location) es importante, ya que debe estar en la misma región en la que implementarás un extremo del modelo más adelante en el instructivo:
En la terminal, ejecuta el siguiente comando para crear un directorio para el código de entrenamiento y un archivo de Python en el que agregarás el código:
mkdir trainer
touch trainer/train.py
Ahora, deberías tener lo siguiente en el directorio mpg/:
+ Dockerfile
+ trainer/
+ train.py
A continuación, abre el archivo train.py que acabas de crear. Para ello, navega a mpg > trainer > train.py y copia el siguiente código (se trata de una adaptación del instructivo que se proporciona en la documentación de TensorFlow).
Al comienzo del archivo, actualiza la variable BUCKET con el nombre del bucket de Storage que creaste en el paso anterior:
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path
"""Import it using pandas"""
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset.tail()
# TODO: replace `your-gcs-bucket` with the name of the Storage bucket you created earlier
BUCKET = 'gs://your-gcs-bucket'
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple, drop those rows."""
dataset = dataset.dropna()
""La columna "Origen"" es realmente categórica, no numérica. So convert that to a one-hot:"""
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
You will use the test set in the final evaluation of your model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
Este gráfico muestra poca mejora, o incluso degradación, en el error de validación después de cerca de 100 ciclos de entrenamiento. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then it will automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
Compila y prueba el contenedor de manera local
En la terminal, define una variable con el URI de la imagen de contenedor en Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/mpg:v1"
Luego, compila el contenedor ejecutando el siguiente comando desde la raíz del directorio mpg:
docker build ./ -t $IMAGE_URI
Ejecuta el contenedor en tu instancia de Workbench para asegurarte de que esté funcionando correctamente:
docker run $IMAGE_URI
El modelo debería terminar el entrenamiento entre 1 y 2 minutos con una exactitud de la validación de alrededor del 72% (este valor puede variar). Cuando termines de ejecutar el contenedor de manera local, envíalo a Google Container Registry:
docker push $IMAGE_URI
Ahora que enviaste el contenedor a Container Registry, puedes iniciar un trabajo de entrenamiento de modelo personalizado.
Tarea 3: Ejecuta un trabajo de entrenamiento en Vertex AI
Vertex AI proporciona las siguientes dos opciones para entrenar modelos:
AutoML: Entrena modelos de alta calidad con poco esfuerzo y experiencia en AA.
Entrenamiento personalizado: Ejecuta aplicaciones de entrenamiento personalizado en la nube con tu propio contenedor o uno de los creados previamente de Google Cloud.
En este lab, usarás un entrenamiento personalizado a través de tu propio contenedor personalizado en Google Container Registry. Para comenzar, ve a Model Registry en la sección Vertex de la consola de Cloud:
Inicia el trabajo de entrenamiento
Haz clic en Crear para ingresar los parámetros del trabajo de entrenamiento y el modelo implementado:
En Conjunto de datos, selecciona No hay ningún conjunto de datos administrado.
Selecciona Entrenamiento personalizado (avanzado) como método de entrenamiento y haz clic en Continuar.
Selecciona Entrenar un modelo nuevo y, luego, ingresa mpg (o el nombre que quieras asignarle a tu modelo) en Nombre del modelo.
Haz clic en Continuar.
En el paso Configuración del contenedor, selecciona Contenedor personalizado:
En la primera casilla (Imagen del contenedor en GCR), ingresa el valor de la variable IMAGE_URI anterior. Debería ser: gcr.io/your-cloud-project/mpg:v1, con el nombre de tu proyecto. Deja el resto de los campos en blanco y haz clic en Continuar.
No usarás el ajuste de hiperparámetros en este instructivo, así que deja desmarcada la casilla Enable hyperparameter tuning y haz clic en Continuar.
En Procesamiento y precios, selecciona la Región y, luego, Implementa en un grupo de trabajadores nuevo. En Tipo de máquina, selecciona e2-standard-4 y haz clic en Continuar.
Debido a que el modelo que usamos en esta demostración se entrena rápidamente, emplearemos un tipo de máquina más pequeño.
Nota: Si lo deseas, puedes probar con tipos de máquinas y GPU más grandes. Si usas GPU, tendrás que usar una imagen de contenedor base habilitada con GPU.
En el paso Contenedor de predicción, selecciona Pre-built container y 2.11 como la versión del framework de modelo.
Deja la configuración predeterminada para el contenedor previamente compilado sin modificar. En el directorio del modelo, ingresa el bucket de GCS con el subdirectorio mpg. Esta es la ruta de acceso en la secuencia de comandos de entrenamiento de modelos en la que exportas el modelo entrenado. Se verá de la siguiente manera:
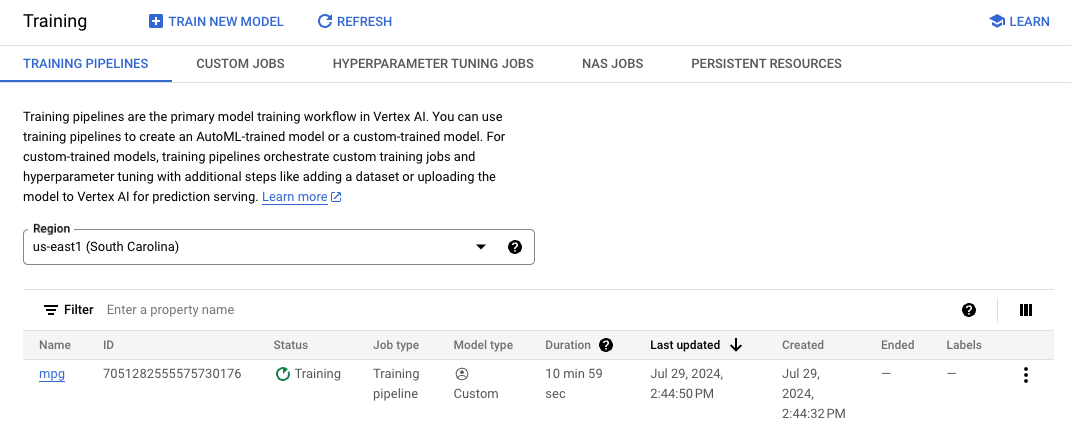
Vertex buscará en esta ubicación cuando implemente el modelo. Ahora puedes realizar el entrenamiento. Haz clic en Comenzar el entrenamiento para iniciar el trabajo de entrenamiento. En la sección Entrenamiento de la consola, selecciona Región y verás algo como esto:
Nota: El trabajo de entrenamiento tardará alrededor de 15 a 20 minutos en completarse.
Tarea 4: Implementa un extremo del modelo
Cuando configuraste el trabajo de entrenamiento, especificaste el lugar en el que Vertex AI debería buscar los recursos exportados del modelo. Como parte de nuestra canalización de entrenamiento, Vertex creará un recurso del modelo según esta ruta del recurso. El recurso del modelo en sí no es un modelo implementado, pero una vez que tienes un modelo puedes implementarlo en un extremo. Para obtener más información sobre los modelos y los extremos en Vertex AI, consulta la documentación de primeros pasos para Vertex AI.
En este paso, crearás un extremo para nuestro modelo entrenado. Puedes usar esta opción para obtener predicciones en nuestro modelo a través de la API de Vertex AI.
Implementa el extremo
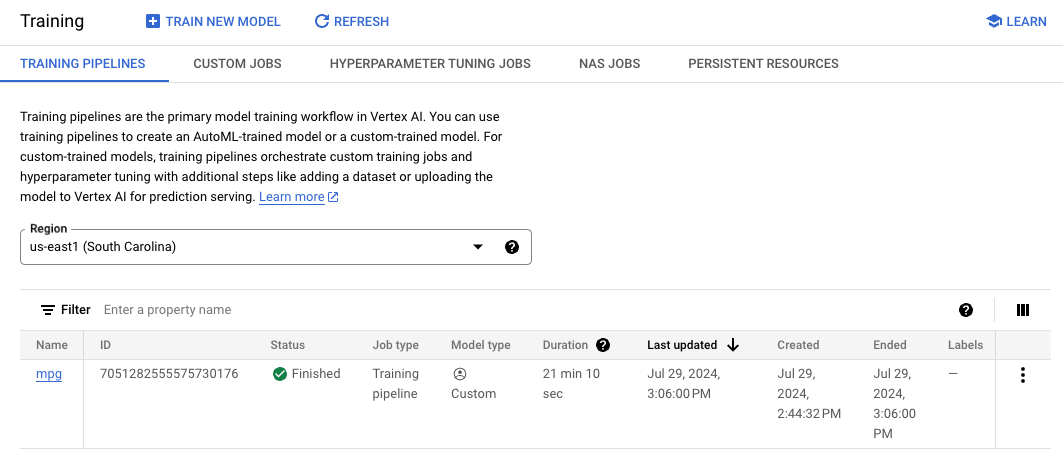
Cuando se complete el trabajo de entrenamiento, deberías ver un modelo llamado mpg (o el nombre que le hayas asignado) en la sección Model Registry de la consola:
Cuando se ejecutaba tu trabajo de entrenamiento, Vertex creó un recurso de modelo por ti. Para usar este modelo, debes implementar un extremo. Puedes tener muchos extremos por modelo. Haz clic en el modelo y selecciona la pestaña Implementa y prueba. Luego, haz clic en Implementar en el extremo.
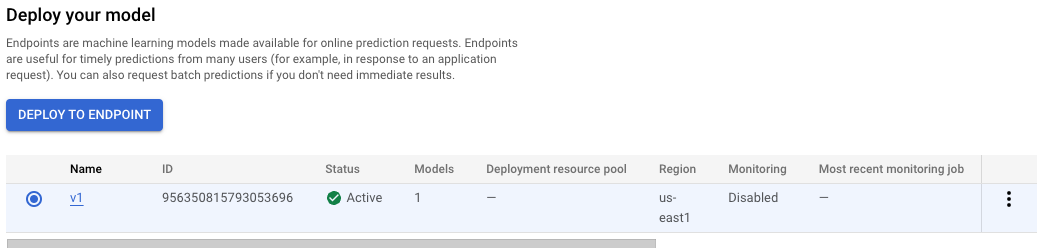
Selecciona Crear extremo nuevo, asígnale un nombre (por ejemplo, v1) y haz clic en Continuar. Deja la opción División del tráfico en 100 y, luego, ingresa 1 para Cantidad mínima de nodos de procesamiento. En Tipo de máquina, selecciona e2-standard-2 (o cualquier tipo de máquina que quieras). Luego, haz clic en Listo y, a continuación, en Implementar.
La implementación del extremo tardará entre 10 y 15 minutos. Cuando el extremo haya terminado de implementarse, verás lo siguiente, que muestra un extremo implementado en el recurso del modelo:
Nota: La región del bucket y la región que se usó para implementar el extremo del modelo deben ser las mismas.
Obtén predicciones en el modelo implementado
Obtendrás predicciones en nuestro modelo entrenado a partir de un notebook de Python con la API de Vertex Python. Regresa a la instancia de Workbench y crea un notebook de Python 3 en el selector:
En el notebook, ejecuta lo siguiente en una celda para instalar el SDK de Vertex AI:
Luego, agrega una celda en el notebook para importar el SDK y crear una referencia al extremo que acabas de implementar:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="projects/YOUR-PROJECT-NUMBER/locations/{{{ project_0.default_region | REGION }}}/endpoints/YOUR-ENDPOINT-ID"
)
Deberás reemplazar dos valores en la cadena endpoint_name anterior por el número y el extremo de tu proyecto. Para encontrar el número de tu proyecto, ve al panel del proyecto y obtén el valor del número de proyecto.
Puedes encontrar el ID de extremo en la sección Extremos de la consola aquí:
Por último, realiza una predicción en el extremo; para ello, copia y ejecuta el código que figura a continuación en una celda nueva:
Este ejemplo ya tiene valores normalizados, que es el formato que espera nuestro modelo.
Ejecuta esta celda y deberías ver un resultado de predicción de alrededor de 16 millas por galón.
Tarea 5: Realiza una limpieza
Realiza una de las acciones siguientes:
Para continuar utilizando el notebook que creaste en este lab, se recomienda que lo desactives cuando no lo uses. En la IU de Notebooks de la consola de Cloud, selecciona el notebook y, luego, haz clic en Detener.
Para borrar el notebook, haz clic en Borrar.
Para borrar el extremo que implementaste, en la sección Predicción en línea de la consola de Vertex AI, selecciona Región en el menú desplegable y haz clic en v1. Ahora, haz clic en el ícono de tres puntos junto a tu extremo y selecciona Anular la implementación del modelo en el extremo. Por último, haz clic en Anular implementación.
Para quitar el extremo, vuelve a la sección Extremos y haz clic en el ícono de acciones y, luego, en Borrar extremo.
Para borrar el bucket de Cloud Storage, ve a la página Cloud Storage, selecciona el bucket y, luego, haz clic en Borrar.
¡Felicitaciones!
Aprendiste a usar Vertex AI para hacer lo siguiente:
Entrenar un modelo proporcionando el código de entrenamiento en un contenedor personalizado (en este ejemplo, usaste un modelo de TensorFlow, pero puedes entrenar un modelo creado con cualquier framework a través de contenedores personalizados)
Implementar un modelo de TensorFlow con un contenedor previamente compilado como parte del mismo flujo de trabajo que usaste para el entrenamiento
Crear un extremo del modelo y generar una predicción
Finalice su lab
Cuando haya completado su lab, haga clic en Finalizar lab. Qwiklabs quitará los recursos que usó y limpiará la cuenta por usted.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Neutral
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2020 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usa una ventana de navegación privada o de Incógnito para ejecutar el lab. Así
evitarás cualquier conflicto entre tu cuenta personal y la cuenta
de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
En este lab, usarás Vertex AI para entrenar y entregar un modelo de TensorFlow con código alojado en un contenedor personalizado.
Duración:
0 min de configuración
·
Acceso por 120 min
·
120 min para completar
 ) de la consola de Google Cloud, selecciona Vertex AI.
) de la consola de Google Cloud, selecciona Vertex AI. Crear nueva.
Crear nueva.




 junto a tu extremo y selecciona Anular la implementación del modelo en el extremo. Por último, haz clic en Anular implementación.
junto a tu extremo y selecciona Anular la implementación del modelo en el extremo. Por último, haz clic en Anular implementación.




