

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
このラボでは、Google Cloud コンソールを使用して Spanner インスタンスとデータベースを作成します。
このラボでは、次の方法について学びます。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ご自身でラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
Google Cloud Shell は、デベロッパー ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Google Cloud Shell では、コマンドラインで GCP リソースにアクセスできます。
GCP Console の右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境のプロビジョニングと接続には少し時間がかかります。接続すると、すでに認証されており、プロジェクトは PROJECT_ID に設定されています。例えば:
gcloud は Google Cloud Platform のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
gcloud auth list
出力:
ACTIVE: *
ACCOUNT: student-01-xxxxxxxxxxxx@qwiklabs.net
To set the active account, run:
$ gcloud config set account `ACCOUNT`
次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
gcloud config list project
出力:
[core]
project = <project_ID>
出力例:
[core]
project = qwiklabs-gcp-44776a13dea667a6
Google Cloud コンソールのタイトルバーで、ナビゲーション メニュー(
[プロビジョニングされたインスタンスを作成] ボタンをクリックし、インスタンス名を「my-first-instance」にします。[構成を選択] プルダウンからリージョン
インスタンスが作成されるまで待ちます。作成が終わると、[インスタンスの概要] ページにリダイレクトされます。[データベースを作成] ボタンをクリックします。このボタンは、一番下までスクロールしないと見つからない場合があります。データベースに「my-database」という名前を付け、[Google 標準 SQL] を選択します。次に、下にスクロールして [作成] ボタンをクリックします。
左側のリストメニューで [Spanner Studio] をクリックします。
上部のリボンで青い [+] アイコンをクリックします。
次の CREATE TABLE ステートメントを入力し、[実行] ボタンをクリックします。
オペレーションが完了するのを待ちます。作成したテーブルが、そのデータベースのテーブルのリストに表示されます。左側の [エクスプローラ] メニューの [テーブル] セクションを開いて、テーブル名を確認します。
[クエリをクリア] をクリックし、次の INSERT クエリを実行して、新しいテーブルに行を追加します。構文エラーがなければ、行が 1 行挿入されたことを伝えるメッセージが表示されます。このクエリでは、単にレコードを挿入します。
前の手順を繰り返し、さらにレコードをいくつか追加します。TableID フィールドを毎回変更してレコードが一意になるようにしてください。Field1 には任意の値を入力できます。レコードを 2~3 個追加します。
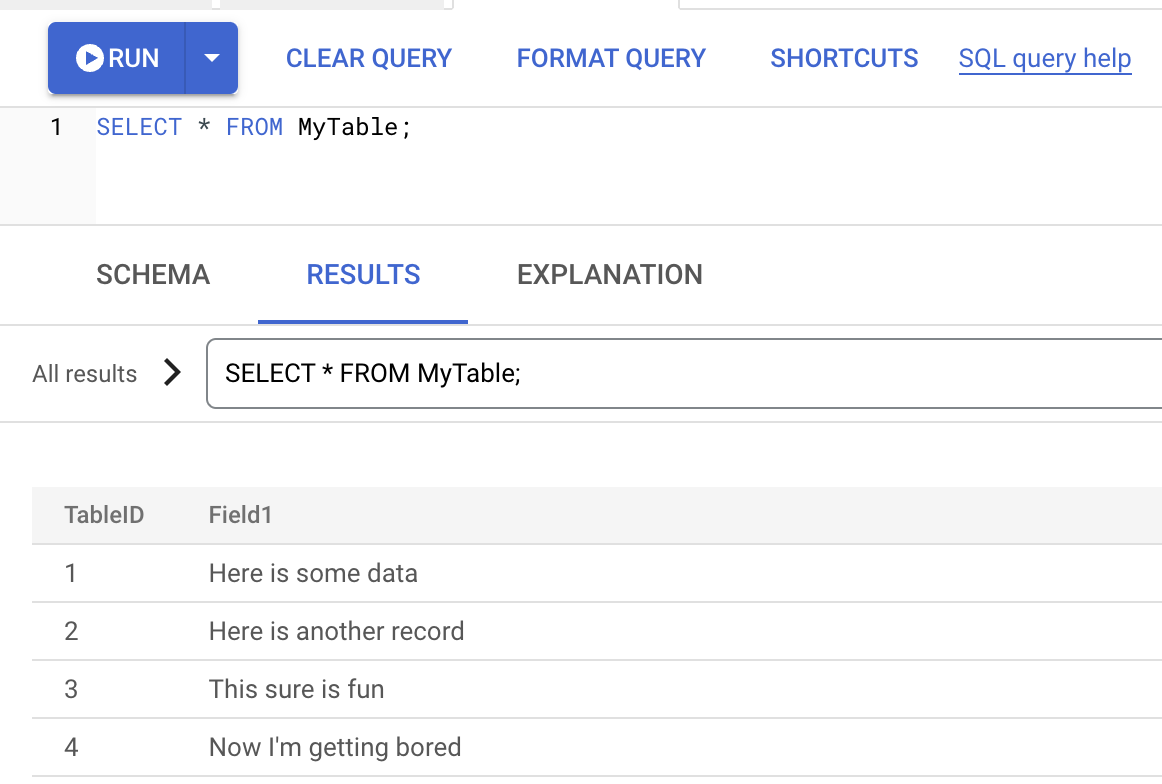
[クエリをクリア] をクリックし、次の SELECT クエリを実行します。
Spanner ワークスペースの左上にある [すべてのインスタンス] リンクをクリックします。
[インスタンスを作成] ボタンをクリックし、インスタンス名を「my-second-instance」にします。
[構成を選択] セクションで、[リージョン構成の比較] ボタンをクリックします。
us-central1 (Iowa) を選択します。2 つ目のプルダウンで、マルチリージョン構成 nam3 (Northern Virginia/South Carolina/Iowa) を選択します。nam-eur-asia1 (Iowa/Oklahoma/Belgium/Taiwan/South Carolina) に変更し、2 つのマルチリージョン構成でレプリカと費用を比較します。[リージョン構成の比較] ペインを閉じます。構成画面に戻り、構成を [リージョン] と [
[コンピューティング容量の割り当て] セクションで、[単位] プルダウンを [ノード] に変更します。
[概要] セクションにある、費用と最大ストレージ容量をメモします。ノードの数を増やして、費用と容量の変化を確認します。
[コンピューティング容量の割り当て] セクションで、[単位] プルダウンを [処理ユニット] に変更します。処理ユニットは 100 単位で追加されます。値を 100 に設定します(これは、設定可能な最小の Spanner インスタンスです)。
費用と容量をメモします。[作成] をクリックしてインスタンスを作成します。
先ほどと同じように、2 つ目のインスタンスに pets-db というデータベースを作成します。
Spanner Studio で次の DDL コードを使用して、Owners テーブルと Pets テーブルをデータベースに追加します。
注: このデータベースの主キーは整数ではなく、36 文字の文字列です。これらのキーは、ユニバーサルな固有識別子(UUID)として使用することを想定しています。36 文字以下の一意な文字列を入力すれば機能します。適切な UUID を生成したい場合は、ブラウザで次のリクエストを実行するとページ上部に UUID が表示されます。
Spanner インスタンスに「my-second-instance」という名前の 2 つ目のデータベースを作成します。データベースの名前を「pets-postgres」にします。今回は、データベース言語の選択を求められたら PostgreSQL を選択します。なお、[インスタンスの概要] ページが表示されていることを確認してください。[データベースを作成] ボタンをクリックします。
PostgreSQL 構文を使用した Pets データベースの DDL コードは次のとおりです。Spanner Studio を使用して、前の手順と同じ方法でテーブルを作成します。
ラボでの学習が完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Qwiklabs から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバック、ご提案、修正事項がございましたら、[サポート] タブからお知らせください。
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください