

准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Enable Document AI API
/ 20
Create a processor
/ 20
Create a label
/ 20
Build processor version using foundation model
/ 20
Train the model
/ 20
Document AI 是文件解讀解決方案,可擷取並處理文件、電子郵件、帳單和表單等非結構化資料,方便您解讀、分析和使用。Document AI API 會透過內容分類、實體擷取、進階搜尋等功能,將文件轉換成結構化資料。有了 Document AI Workbench,您就能使用自己的訓練資料建立完全自訂的模型,提高文件處理的準確率。
您可以為自家文件打造專屬的自訂文件擷取器 (CDE),並用自有資料加以訓練和評估效能。這個處理器會辨識並擷取文件中的實體,完成訓練後,就可以用來處理更多文件。自訂文件擷取器一般適合用在單一類型的文件,例如機構的註冊表單。
在這個實驗室,您會瞭解如何使用 Document AI Workbench 建立及訓練自訂文件擷取器,以便處理 W-2 (美國稅務表單) 文件。我們已為您完成大部分的文件準備工作,因此您可以專注於自訂文件擷取器的其他建立步驟。
在本實驗室中,您將瞭解如何執行下列工作:
請詳閱以下操作說明。實驗室活動會計時,且中途無法暫停。點選「Start Lab」後就會開始計時,顯示可使用 Google Cloud 資源的時間。
您將在真正的雲端環境完成實作實驗室活動,而不是模擬或示範環境。為此,我們會提供新的暫時憑證,供您在實驗室活動期間登入及存取 Google Cloud。
為了順利完成這個實驗室,請先確認:
點選「Start Lab」按鈕。如果實驗室會產生費用,畫面上會出現選擇付款方式的對話方塊。左側的「Lab Details」窗格會顯示下列項目:
點選「Open Google Cloud console」;如果使用 Chrome 瀏覽器,也能按一下滑鼠右鍵,選取「在無痕視窗中開啟連結」。
接著,實驗室會啟動相關資源,並開啟另一個分頁,顯示「登入」頁面。
提示:您可以在不同的視窗中並排開啟分頁。
如有必要,請將下方的 Username 貼到「登入」對話方塊。
您也可以在「Lab Details」窗格找到 Username。
點選「下一步」。
複製下方的 Password,並貼到「歡迎使用」對話方塊。
您也可以在「Lab Details」窗格找到 Password。
點選「下一步」。
按過後續的所有頁面:
Google Cloud 控制台稍後會在這個分頁開啟。

Cloud Shell 是搭載多項開發工具的虛擬機器,提供永久的 5 GB 主目錄,而且在 Google Cloud 中運作。Cloud Shell 提供指令列存取權,方便您使用 Google Cloud 資源。
點按 Google Cloud 控制台頂端的「啟用 Cloud Shell」圖示 
系統顯示視窗時,請按照下列步驟操作:
連線建立完成即代表已通過驗證,而且專案已設為您的 Project_ID:
gcloud 是 Google Cloud 的指令列工具,已預先安裝於 Cloud Shell,並支援 Tab 鍵自動完成功能。
輸出內容:
輸出內容:
gcloud 的完整說明,請前往 Google Cloud 參閱 gcloud CLI 總覽指南。
您必須先啟用 API,才能使用 Document AI。
畫面應如下所示:
畫面應如下所示:
現在,您可以開始使用 Document AI API 了!
您必須先建立自訂文件擷取器的處理器,才能在本實驗室中使用。
在本教學課程中,您必須先建立表單剖析器的處理器執行個體,才能在 Document AI Platform 中使用。
點選「建立自訂處理器」。
在「自訂擷取器」方塊中,點選「建立處理器」。
將名稱設為 lab-custom-extractor,然後從清單中選取「US (美國)」區域。
點按「建立」即可建立處理器。
點選「Check my progress」確認目標已達成。
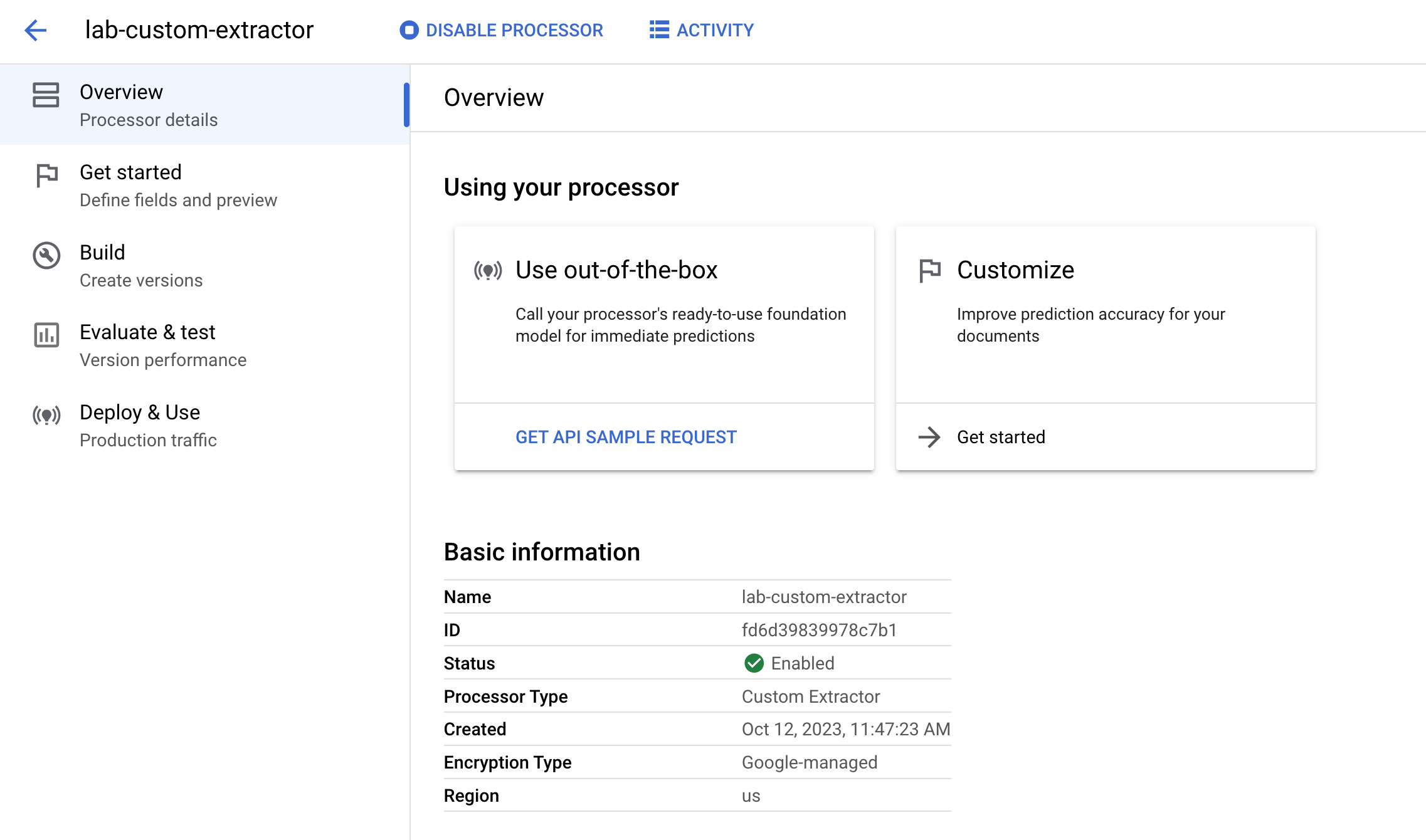
您現在位於新建處理器的總覽頁面。
您可以指定要讓處理器擷取的欄位,並開始為文件加上標籤。
按一下「開始」分頁標籤。畫面上會出現「欄位」選單。
按一下「建立新欄位」。
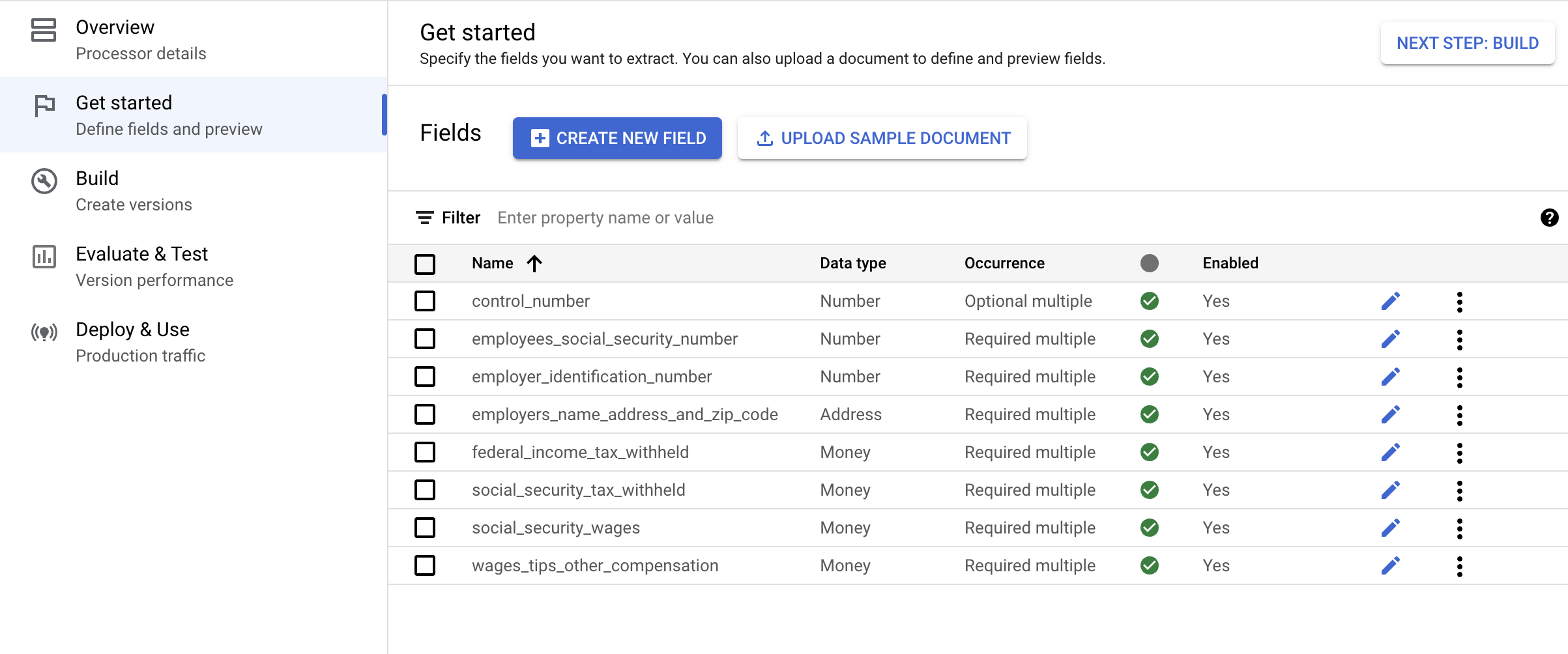
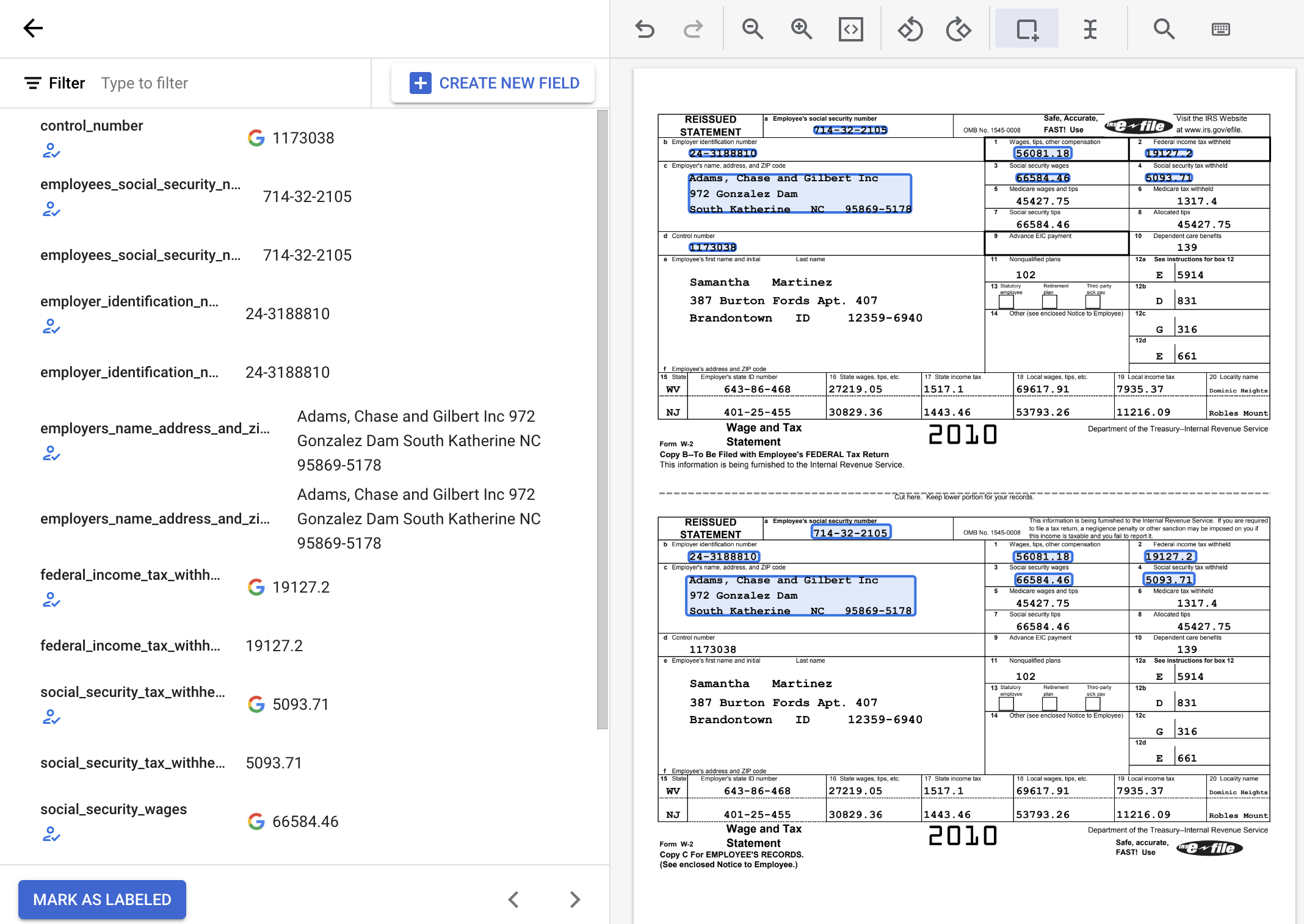
輸入欄位名稱。選取「資料類型」和「出現次數」。點選「建立」。如需建立與編輯結構定義的詳細操作說明,請參閱「定義處理器結構定義」一文。
為處理器結構定義建立下列標籤。
| 名稱 | 資料類型 | 出現次數 |
|---|---|---|
control_number |
數字 | 選用 (可出現多次) |
employees_social_security_number |
數字 | 必要 (可出現多次) |
employer_identification_number |
數字 | 必要 (可出現多次) |
employers_name_address_and_zip_code |
地址 | 必要 (可出現多次) |
federal_income_tax_withheld |
金額 | 必要 (可出現多次) |
social_security_tax_withheld |
金額 | 必要 (可出現多次) |
social_security_wages |
金額 | 必要 (可出現多次) |
wages_tips_other_compensation |
金額 | 必要 (可出現多次) |
您也可以在處理器結構定義中建立及使用其他類型的標籤,例如核取方塊和表格實體。舉例來說,W-2 表單含有「Statutory employee」(法定員工)、「Retirement plan」(退休計畫) 和「Third party sick pay」(第三方病假薪酬) 核取方塊,您可一併新增至結構定義。
點選「Check my progress」確認目標已達成。
接著,請上傳範例 W-2 PDF 檔案並加上標籤。
按一下「上傳範例文件」。
按一下側欄中的「從 Google Cloud Storage 匯入文件」。
在本範例中,請在「來源路徑」輸入下列 bucket 名稱,這樣就會直接連結至某份文件。
系統會將您重新導向至標籤控制台。
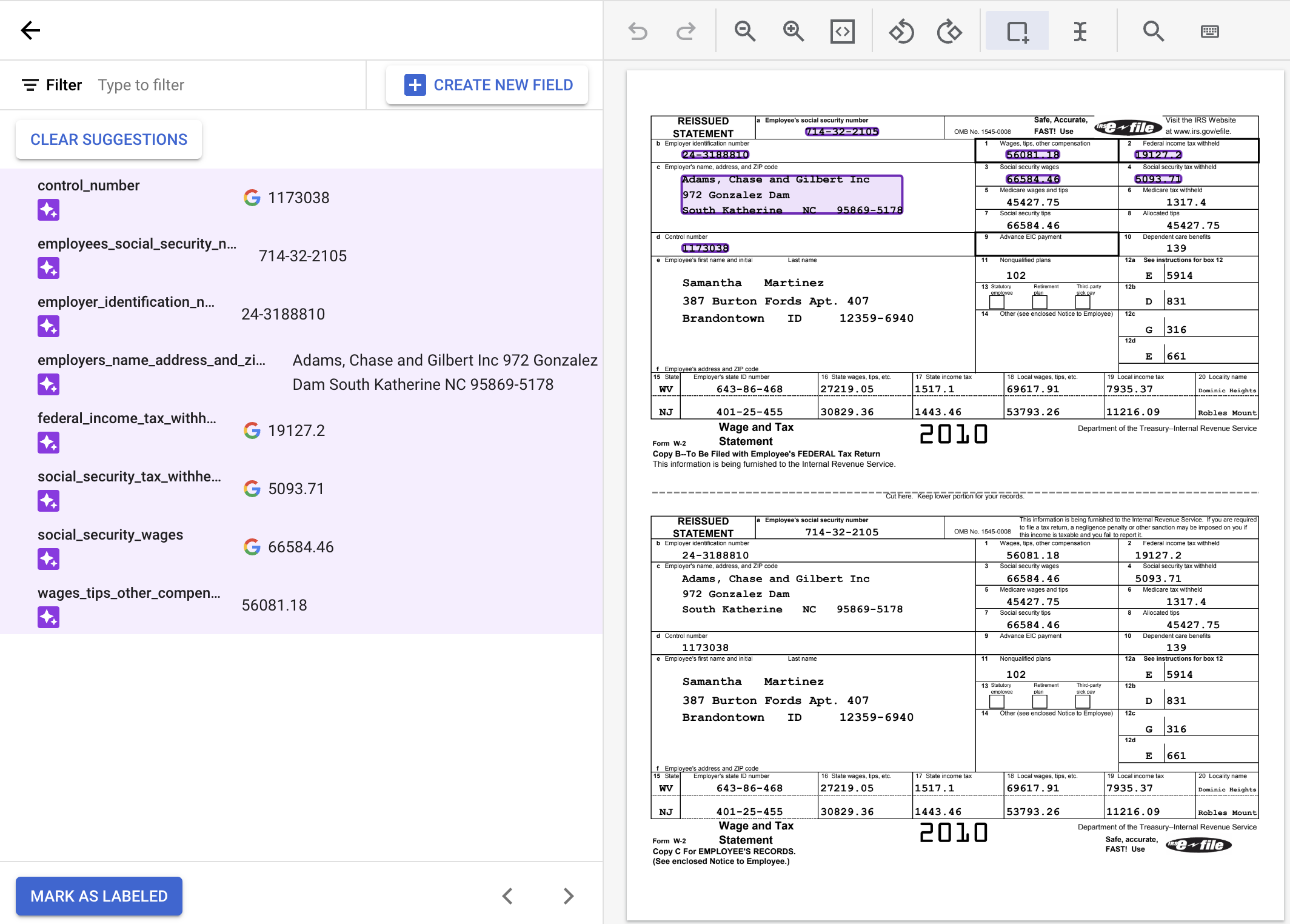
在文件中選取文字及套用標籤的程序稱為「註解」。
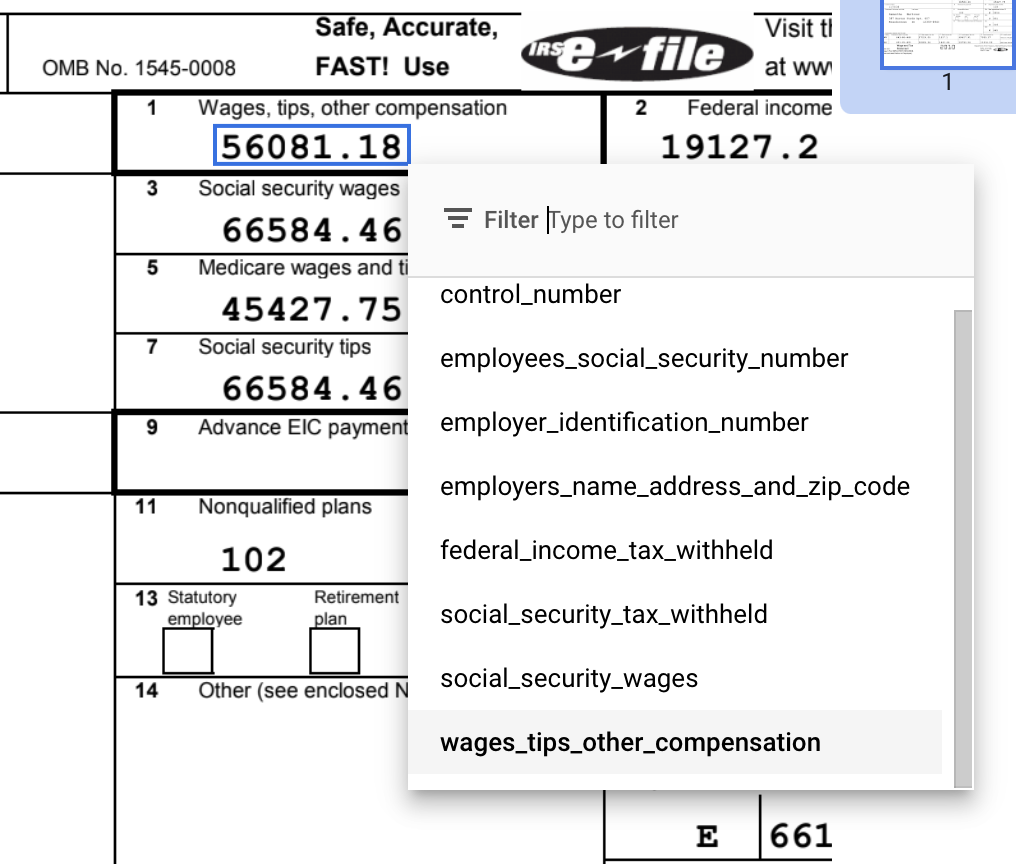
如要使用建議的標籤,請將滑鼠游標懸停在側邊面板中的標籤上,然後按一下勾號來確認標籤正確無誤。如果值與文件內容不符,請修改這些值。
在這個範例中,系統沒有自動識別文件底部的值,因此您必須手動為這些值加上標籤。
使用預設的「邊框」工具選取內容並套用標籤,如果值有多行,則使用「選取文字」工具執行操作。
wages_tips_other_compensation 的值並套用標籤。完成後,加上標籤的 W-2 文件看起來應該像這樣:
如有需要,您可以按一下「建立新欄位」,在這個頁面中將新欄位加進結構定義。
順利為文件加上註解後,請按一下「標示為已加上標籤」。
系統會將您重新導向至「開始」分頁。
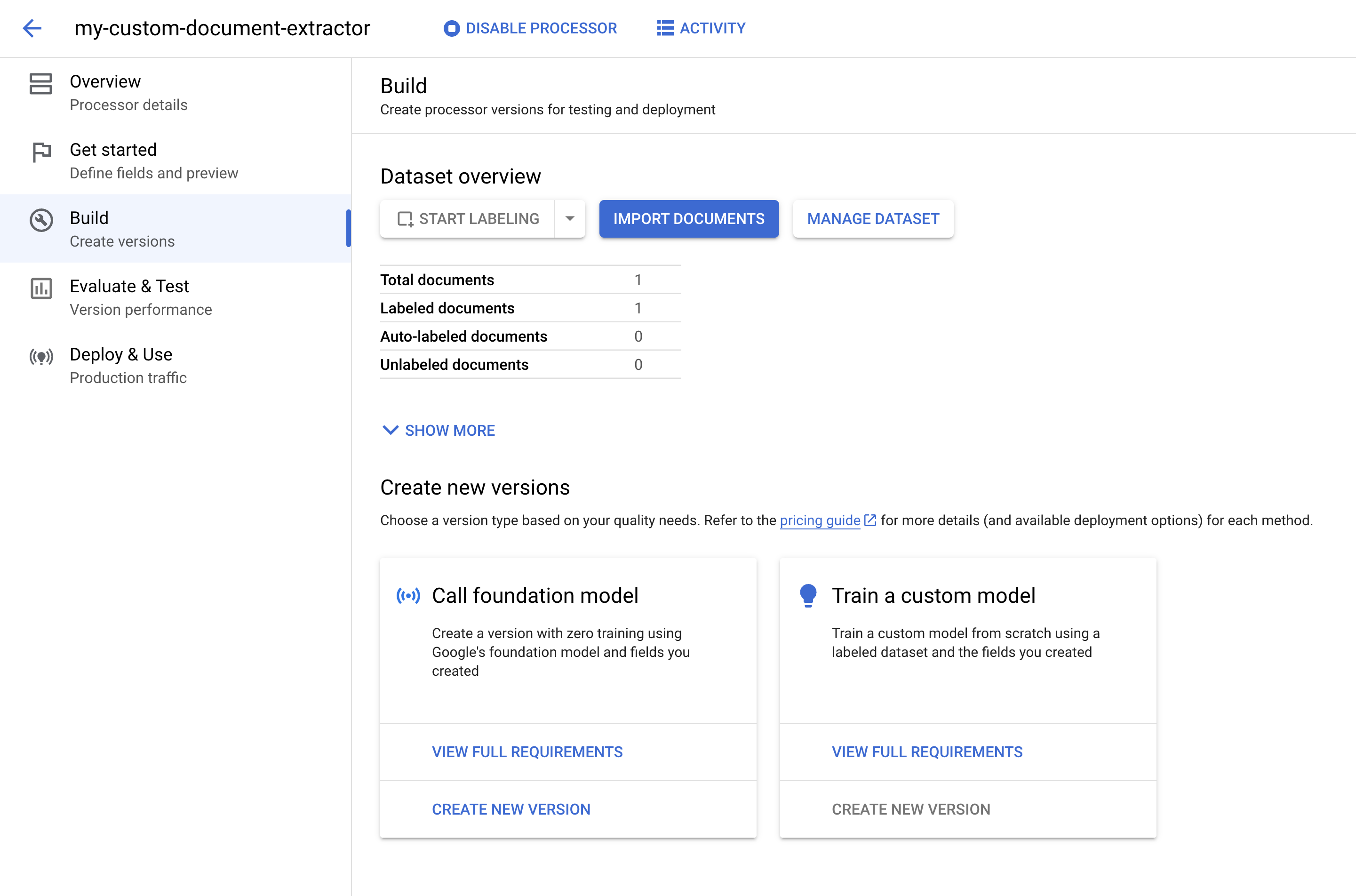
為單一文件加上標籤後,您可以使用預先訓練的基礎模型建立處理器版本,藉此擷取實體。
在「呼叫基礎模型」下方,按一下「建立新版本」。
輸入處理器版本的名稱,例如 w2-foundation-model。
按一下「建立」。建立作業需要幾分鐘才能完成。
稍後,您將測試並評估這個版本。
點選「Check my progress」確認目標已達成。
基礎模型能精準地擷取各種文件類型的欄位,但您也可以提供其他訓練資料,提高模型處理特定文件結構的準確度。
您可以輕鬆運用 Document AI Workbench 的自動加上標籤功能,依據已定義的標籤名稱和先前的註解,快速為大量文件加上標籤。
前往「版本」頁面。
按一下「匯入文件」。
按一下側欄中的「從 Google Cloud Storage 匯入文件」。
在「來源路徑」輸入下列 bucket 名稱,內含未加上標籤的 W-2 PDF 檔案。
在「資料分割」清單中,選取「自動分割」。這樣系統就會自動分割文件,其中 80% 用於訓練集,20% 用於測試集。
在「自動加上標籤」專區中,勾選「使用自動加上標籤功能匯入」核取方塊。
選取剛剛建立的基礎模型處理器版本,為文件加上標籤。
按一下「匯入」,然後等待系統匯入文件。您可以先離開這個頁面,稍後再返回查看。
您必須先驗證已自動加上標籤的文件,才能使用這些文件進行訓練或測試。只要按一下「開始設定標籤」,即可查看已自動加上標籤的文件。
如要使用建議的標籤,請將滑鼠游標懸停在註解上,然後按一下勾號來確認標籤正確無誤。如果值與文件內容不符,請修改這些值。
順利為文件加上註解後,請按一下「標示為已加上標籤」。
請為每份已自動加上標籤的文件重複執行上述步驟。在本教學課程中,您可以略過任何未成功自動加上標籤的文件。
本實驗室會提供預先加上標籤的資料。如果您是處理自有專案,則必須決定如何為資料加上標籤。詳情請參閱「標籤選項」。一般來說,訓練資料越多,準確率就會越高。
前往「版本」頁面。
按一下「匯入文件」。
按一下側欄中的「從 Google Cloud Storage 匯入文件」。
在「來源路徑」輸入下列路徑,這個 bucket 包含預先加上標籤的 Document JSON 格式文件。
在「資料分割」清單中,選取「自動分割」。這樣系統就會自動分割文件,其中 80% 用於訓練集,20% 用於測試集。取消勾選「使用自動加上標籤功能匯入」。
按一下「匯入」。匯入作業需要幾分鐘才能完成。
視需要前往「版本」頁面的「管理資料集」控制台,查看及編輯資料集中的所有文件與標籤。
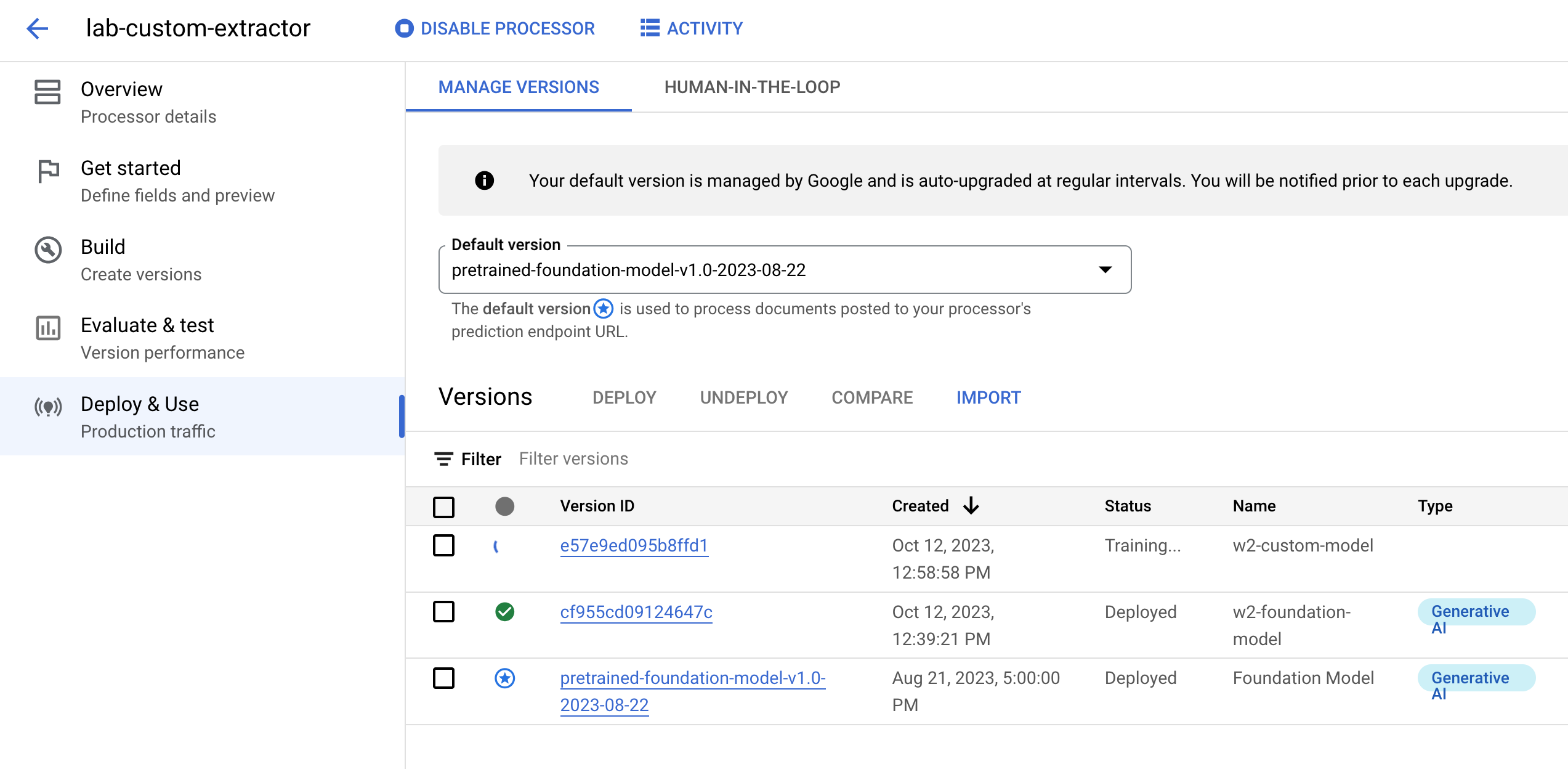
現在您已擁有充足的訓練和測試資料,接著可以開始訓練處理器。訓練作業可能需要數小時才能完成,因此在開始前,請務必確認您已使用適當的資料和標籤設定處理器。
在「訓練自訂模型」下方,按一下「建立新版本」。
如果無法點選「建立新版本」,請按一下「查看完整需求條件」,瞭解資料集相關規定。
在「版本名稱」欄位中,輸入這個處理器版本的名稱,例如 w2-custom-model。
(選用) 按一下「查看標籤統計資料」 即可看到文件標籤的相關資訊,這有助於確定涵蓋範圍。接著按一下「關閉」,返回訓練設定頁面。
在「模型訓練方法」下方,選取「以模型為基準」。
點選「開始訓練」。
(選用) 按一下「部署及使用」分頁標籤。在這個頁面中,您可以查看可用的處理器版本,以及新版本的訓練狀態。
點選「Check my progress」確認目標已達成。
太好了!您已開始訓練第一個自訂 Document AI 處理器。由於訓練作業需要數小時才能完成,本實驗室先到此結束。如要瞭解如何部署及測試模型版本,請參閱本說明文件的相關章節。
恭喜!在本實驗室中,您已成功使用 Document AI 建立自訂文件擷取功能的處理器、匯入資料集,並為範例文件加上標籤。現在,就像使用任何專業處理器一樣,您可以透過這個處理器剖析這類格式的文件。您也可以使用這個處理器的自動加上標籤功能,為新文件加上標籤,並在 Document AI Workbench 管理訓練資料和訓練工作。
如要進一步瞭解 Document AI 和 Python 用戶端程式庫,請參閱下列資源:
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2025 年 3 月 17 日
實驗室上次測試日期:2025 年 3 月 17 日
Copyright 2025 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验