

准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Enable Document AI API
/ 20
Create a processor
/ 20
Create a label
/ 20
Build processor version using foundation model
/ 20
Train the model
/ 20
Document AI 是一种文档理解解决方案,接受非结构化数据(例如文档、电子邮件、账单、表单等),使数据更易于理解、分析和使用。该 API 通过内容分类、实体提取、高级搜索等功能提供结构化数据。借助 Document AI Workbench,您可以使用自己的训练数据创建完全自定义的模型,从而提高文档处理准确率。
您可以创建专门适合特定文档的自定义文档提取器 (CDE),并使用您的数据进行训练和评估。此处理器会从您的文档中识别并提取实体。之后,您便可以将经过训练的处理器用于其他文档。通常,一个 CDE 应该用于同一种类型的文档,例如贵机构的注册表单。
在本实验中,您将学习如何使用 Document AI Workbench 创建和训练自定义文档提取器,用来专门处理 W-2(美国纳税表单)文档。我们已为您完成大部分的文档准备工作,您可以专注于创建 CDE 的其他操作。
在本实验中,您将学习如何执行以下任务:
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。为此,我们会向您提供新的临时凭据,您可以在该实验的规定时间内通过此凭据登录和访问 Google Cloud。
为完成此实验,您需要:
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。左侧是“实验详细信息”窗格,其中包含以下各项:
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:将这些标签页安排在不同的窗口中,并排显示。
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
您也可以在“实验详细信息”窗格中找到“用户名”。
点击下一步。
复制下面的密码,然后将其粘贴到欢迎对话框中。
您也可以在“实验详细信息”窗格中找到“密码”。
点击下一步。
继续在后续页面中点击以完成相应操作:
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

Cloud Shell 是一种装有开发者工具的虚拟机。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行。Cloud Shell 提供可用于访问您的 Google Cloud 资源的命令行工具。
点击 Google Cloud 控制台顶部的激活 Cloud Shell 
在弹出的窗口中执行以下操作:
如果您连接成功,即表示您已通过身份验证,且项目 ID 会被设为您的 Project_ID
gcloud 是 Google Cloud 的命令行工具。它已预先安装在 Cloud Shell 上,且支持 Tab 自动补全功能。
输出:
输出:
gcloud 的完整文档,请参阅 gcloud CLI 概览指南。
您必须先启用 Cloud Document AI API,然后才能开始使用 Document AI。
您应会看到类似下图的界面:
您应会看到类似下图的界面:
现在,您可以使用 Document AI API 了!
您需要先创建一个自定义文档提取器处理器,以便在本实验中使用。
您需要先创建一个表单解析器处理器实例,以便在本教程的 Document AI Platform 中使用。
点击创建自定义处理器。
在自定义提取器框中,点击创建处理器。
将其命名为 lab-custom-extractor,并从列表中选择 US(美国)区域。
点击创建以创建处理器。
点击检查我的进度以验证是否完成了以下目标:
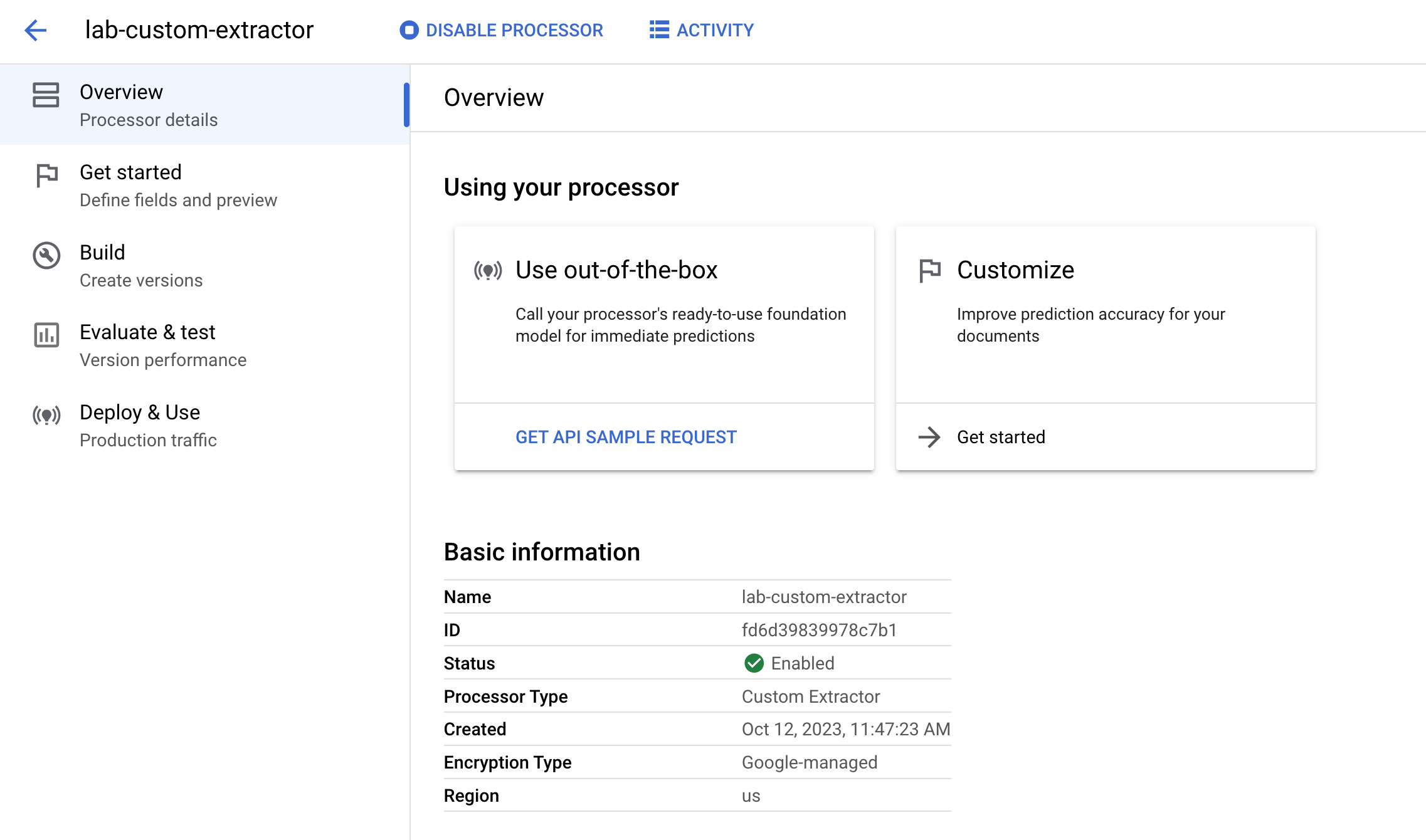
您现在位于刚刚创建的处理器的处理器概览页面。
您可以指定希望处理器提取的字段并开始为文档添加标签。
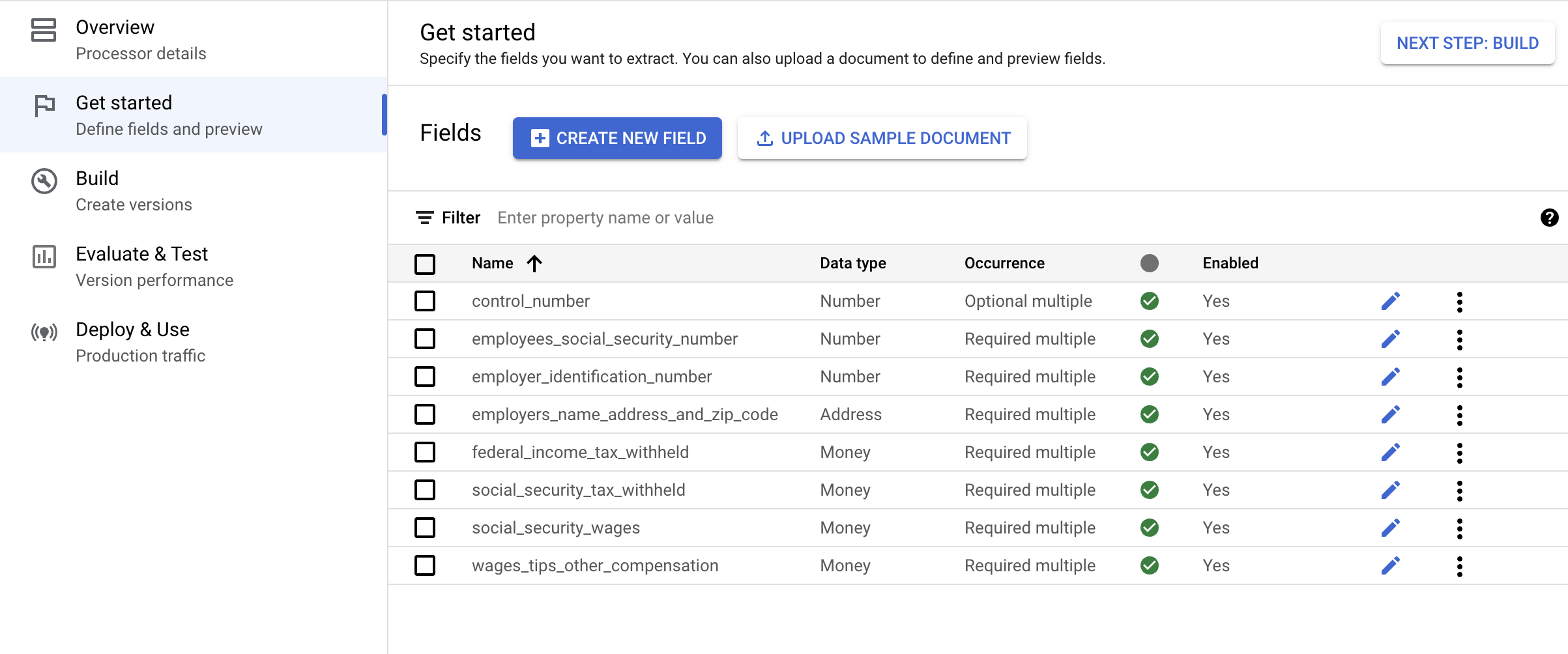
点击开始使用标签页。系统随即会显示字段菜单。
点击创建新字段。
输入字段的名称。选择数据类型和出现次数。点击创建。如需详细了解如何创建和修改架构,请参阅定义处理器架构。
为处理器架构创建以下标签。
| 名称 | 数据类型 | 出现次数 |
|---|---|---|
control_number |
数字 | 可选,数量不限 |
employees_social_security_number |
数字 | 必需,数量不限 |
employer_identification_number |
数字 | 必需,数量不限 |
employers_name_address_and_zip_code |
地址 | 必需,数量不限 |
federal_income_tax_withheld |
金额 | 必需,数量不限 |
social_security_tax_withheld |
金额 | 必需,数量不限 |
social_security_wages |
金额 | 必需,数量不限 |
wages_tips_other_compensation |
金额 | 必需,数量不限 |
您还可以在处理器架构中创建和使用其他类型的标签,例如复选框和表格实体。例如,W-2 表单包含法定雇员、养老金计划和第三方病假工资复选框,您也可以将这些复选框添加到架构。
点击检查我的进度以验证是否完成了以下目标:
接下来,上传一个 W-2 示例 PDF 并为其添加标签。
点击上传示例文档。
在边栏中,点击从 Google Cloud Storage 中导入文档。
在此示例中,在来源路径中输入此存储桶名称。这可直接链接到一个文档。
系统会将您重定向至标签控制台。
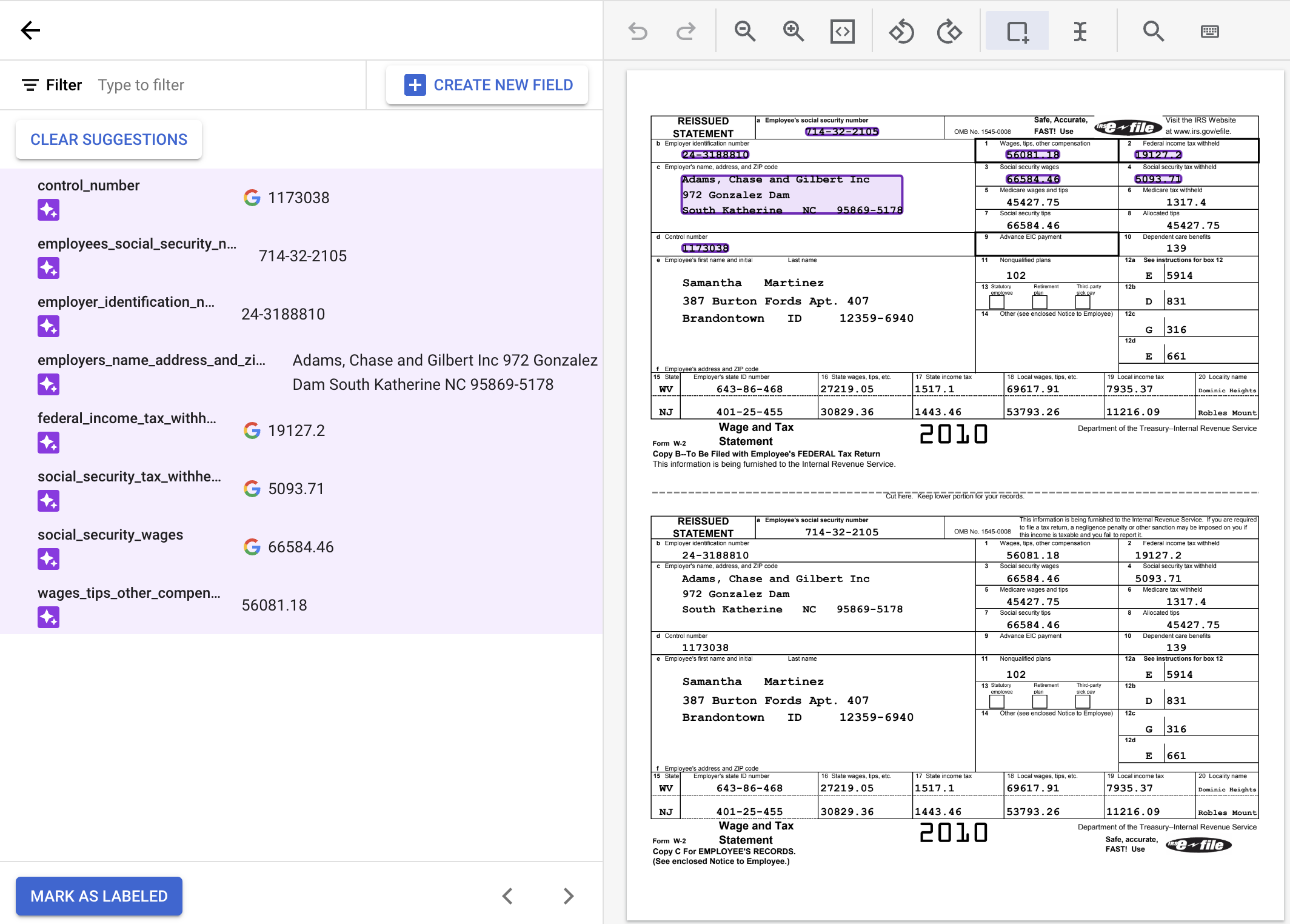
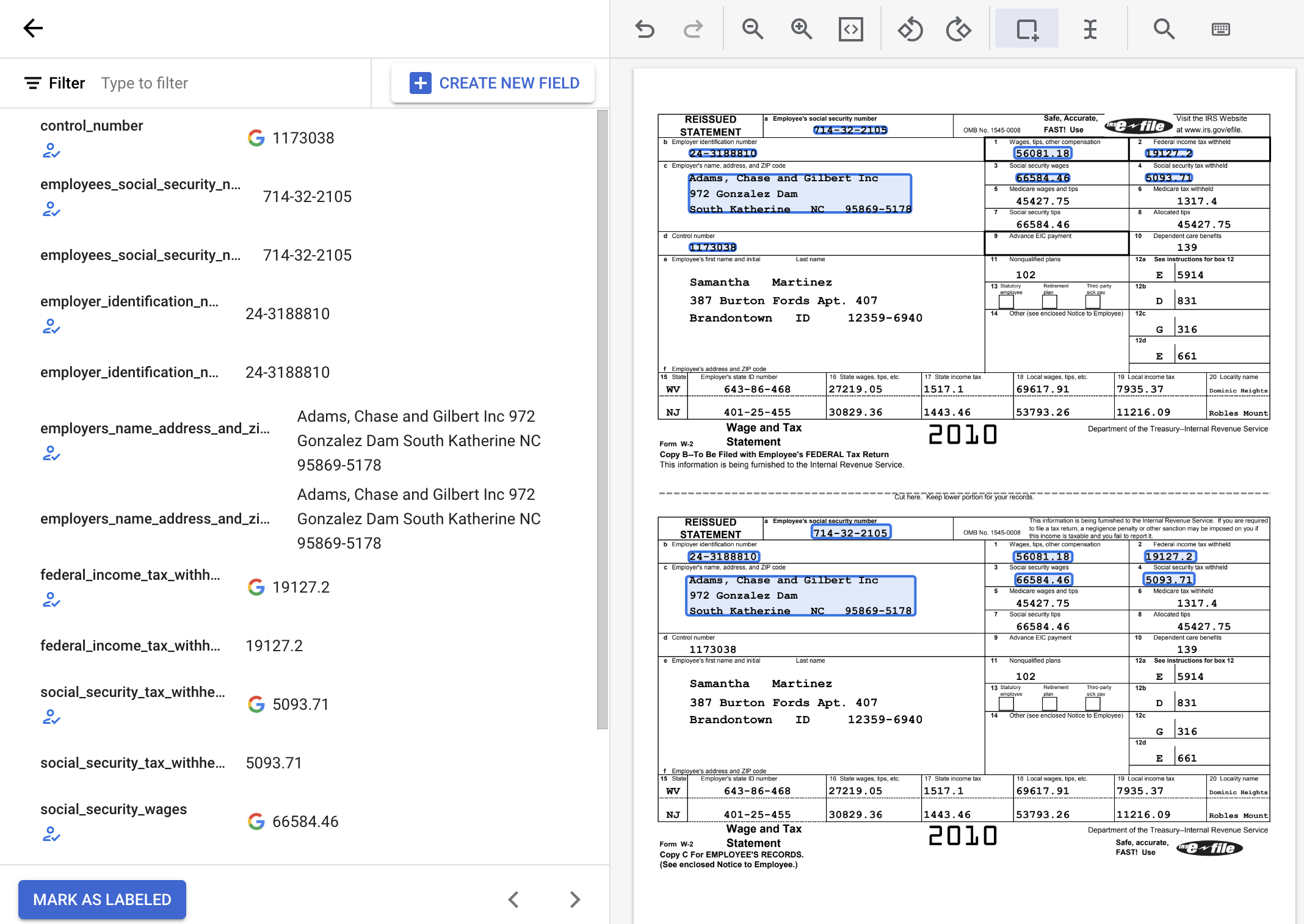
选择文档中的特定文本并为其添加标签的过程也称为“加批注”。
如需使用建议的标签,请将指针悬停在侧边栏中的每个标签上,然后点击对勾标记以确认标签正确无误。如果这些值与文档文本不匹配,您可以修改这些值。
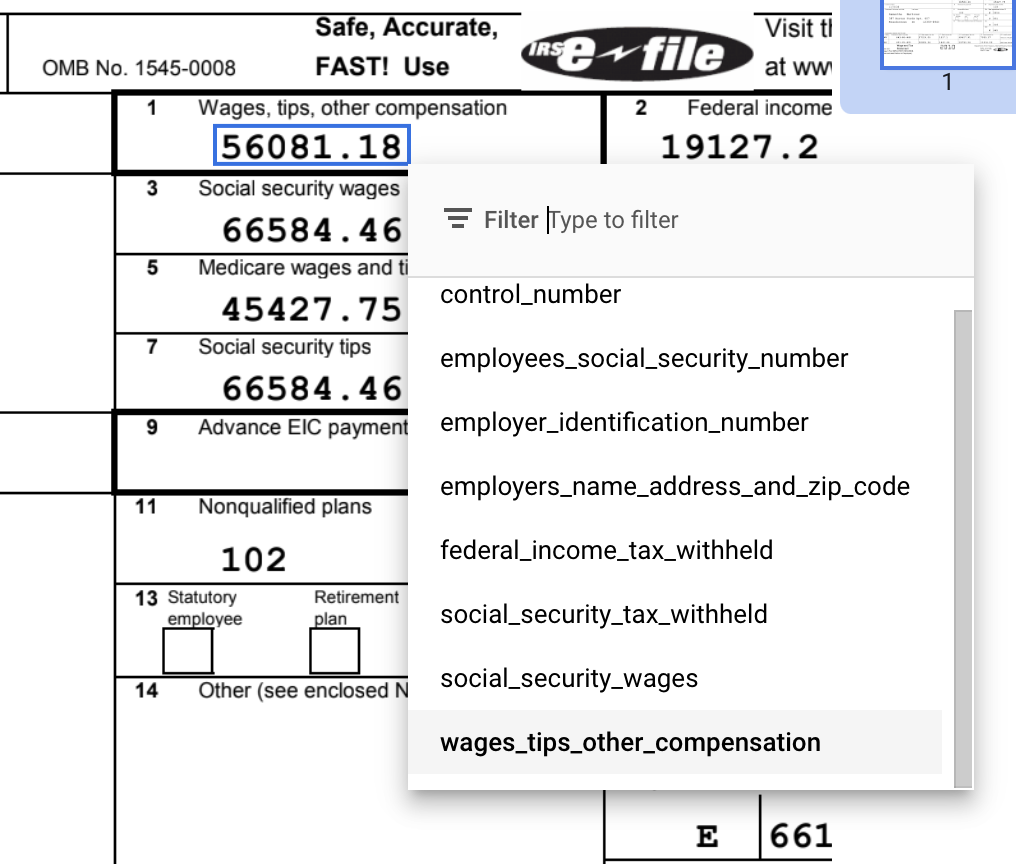
在此示例中,文档底部的值未自动识别,因此您需要手动为这些值添加标签。
默认情况下使用边界框工具,或使用选择文本工具设置多行值,以选择内容并应用标签。
wages_tips_other_compensation 的值并应用了标签。标签添加完成的 W-2 文档应如下所示:
如果需要,您可以选择创建新字段,通过此页面向架构添加新字段。
完成对文档的批注后,点击标记为已加标签。
系统会将您重定向至开始使用标签页。
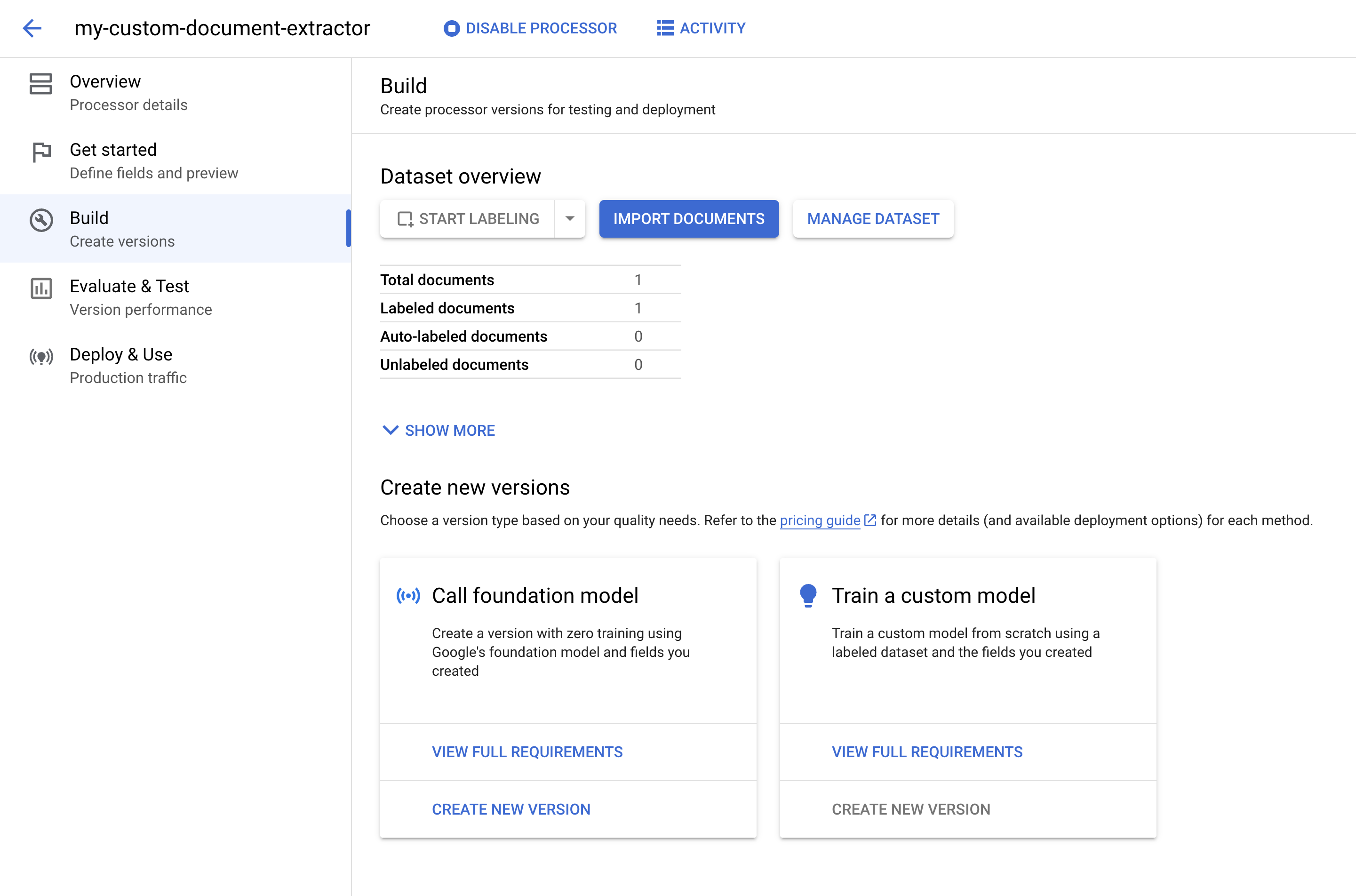
为单个文档添加标签后,您可以使用预训练的基础模型创建处理器版本来提取实体。
在调用基础模型下,点击创建新版本。
输入处理器版本的名称,例如 w2-foundation-model。
点击创建。创建过程需要几分钟的时间。
您将在本实验的后面部分测试和评估此版本。
点击检查我的进度以验证是否完成了以下目标:
基础模型可以准确提取各种文档类型的字段,不过您也可以提供额外的训练数据,提高模型针对特定文档结构的准确率。
Document AI Workbench 使用您定义的标签名称和之前的批注,通过自动添加标签功能更加轻松快捷地为文档大规模添加标签。
前往构建页面。
点击导入文档。
在边栏中,点击从 Google Cloud Storage 中导入文档。
在来源路径中输入此存储桶名称。此存储桶中包含未加标签的 W-2 PDF 文件。
在数据拆分列表中,选择自动拆分。这会自动拆分文档,将 80% 分配到训练集,20% 分配到测试集。
在自动加标签部分,选中使用自动添加标签功能导入复选框。
选择您刚刚创建的基础模型处理器版本,以便为文档添加标签。
点击导入,然后等待文档导入。您可以离开此页面,稍后再返回查看。
您必须先验证自动添加标签的文档,然后才能将其用于训练或测试。选择开始添加标签以查看自动添加标签的文档。
如需使用建议的标签,请将指针悬停在每个批注上,然后点击对勾标记以确认标签正确无误。如果这些值与文档文本不匹配,您可以修改这些值。
完成对文档的批注后,点击标记为已加标签。
针对每个自动添加标签的文档重复上述步骤。在本教程中,您可以跳过未成功自动添加标签的文档。
在本实验中,我们已为您提供了预先加标签的数据。如果您处理的是自己的项目,则需要确定如何为您的数据添加标签。如需了解详情,请参阅标签选项。一般来说,训练数据越多,准确性就越高。
前往构建页面。
点击导入文档。
在边栏中,点击从 Google Cloud Storage 中导入文档。
在来源路径中输入以下路径。此存储桶包含文档 JSON 格式的预先添加标签的文档。
在数据拆分列表中,选择自动拆分。这会自动拆分文档,将 80% 分配到训练集,20% 分配到测试集。请不要勾选使用自动添加标签功能导入。
点击导入。导入过程需要几分钟时间。
(可选)在构建页面中,您可以访问管理数据集控制台,查看和修改数据集中的文档和标签。
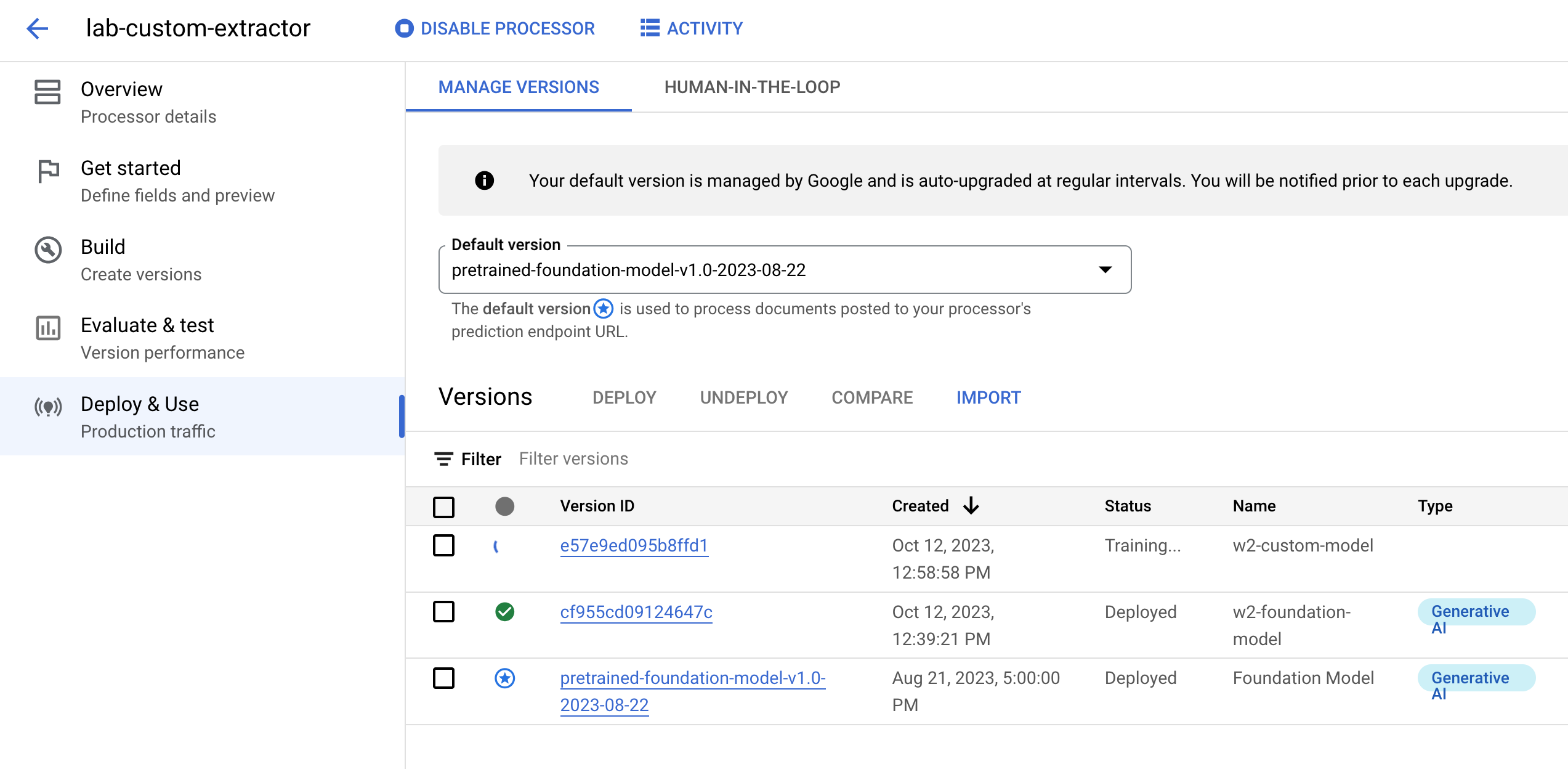
现在,您已经有了足够的训练和测试数据,可以训练处理器了。由于训练过程可能需要几个小时,因此在开始训练之前,请确保您已使用适当的数据和标签设置处理器。
在训练自定义模型下,点击创建新版本。
如果无法点击创建新版本,请点击查看完整要求,了解数据集要求。
在版本名称字段中,输入处理器版本的名称,例如 w2-custom-model。
(可选)点击查看标签统计信息,了解文档标签的相关信息。这有助于确定覆盖率。点击关闭即可返回训练设置。
在模型训练方法下,选择基于模型。
点击开始训练。
(可选)点击部署和使用标签页。在此页面上,您可以查看可用的处理器版本以及新版本的训练状态。
点击检查我的进度以验证是否完成了以下目标:
太棒了!您已成功开始训练第一个自定义 Document AI 处理器。由于训练作业大约需要几个小时,本实验将在此结束。如果您有兴趣了解如何部署和测试模型版本,可以查看文档中的以下部分。
恭喜!在本实验中,您已成功使用 Document AI 创建了自定义文档提取处理器、导入了数据集并为示例文档添加了标签。现在,您可以像使用任何特殊处理器一样,使用此处理器解析此格式的文档。您还可以使用处理器和自动加标签功能为新文档添加标签,并使用 Document AI Workbench 管理训练数据和训练作业。
请查看以下资源,详细了解 Document AI 和 Python 客户端库:
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
本手册的最后更新时间:2025 年 3 月 17 日
本实验的最后测试时间:2025 年 3 月 17 日
版权所有 2025 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验