
![[ビルド] タブをクリックする](https://cdn.qwiklabs.com/Xg4wxI6jM0OQe%2FFiyttxUJs29KLt42FEkHLzjozVwv0%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Enable Document AI API
/ 20
Create a processor
/ 20
Create a label
/ 20
Build processor version using foundation model
/ 20
Train the model
/ 20
Document AI は、ドキュメント、メール、請求書、フォームなどの非構造化データを簡単に理解、分析、利用できるようにするドキュメント理解ソリューションです。この API は、コンテンツ分類、エンティティ抽出、高度な検索機能などを利用して、データに構造を与えます。Document AI Workbench では、独自のトレーニング データを使用して完全にカスタマイズされたモデルを作成し、より高い精度のドキュメント処理を実現できます。
お使いのドキュメントに特化し、データを用いてトレーニングと評価を行うカスタム ドキュメント エクストラクタ(CDE)を作成できます。このプロセッサは、ドキュメントからエンティティを識別して抽出します。このトレーニング済みプロセッサを追加のドキュメントに使用できます。通常は、教育機関の入学願書など、同じタイプのドキュメントに対して CDE を使用します。
このラボでは、Document AI Workbench を使用して W-2(米国税務フォーム)ドキュメントを処理するカスタム ドキュメント エクストラクタを作成してトレーニングする方法について説明します。ドキュメントの準備作業はほとんど完了しているので、CDE 作成の他のメカニズムに集中できます。
このラボでは、次のタスクの実行方法について学びます。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン 
ウィンドウで次の操作を行います。
接続した時点で認証が完了しており、プロジェクトに各自の Project_ID、
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力:
gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
Document AI を使用するには、API を有効にする必要があります。
次のように表示されます。
次のように表示されます。
これで、Document AI API を使用する準備ができました。
まず、このラボで使用するカスタム ドキュメント エクストラクタのプロセッサを作成します。
このチュートリアルでは最初に、Document AI Platform で使用する Form Parser プロセッサのインスタンスを作成する必要があります。
[カスタム プロセッサを作成] をクリックします。
[カスタム エクストラクタ] ボックス内で、[プロセッサを作成] をクリックします。
名前を「lab-custom-extractor」にして、リージョンの一覧から [US(米国)] を選択します。
[作成] をクリックして、プロセッサを作成します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
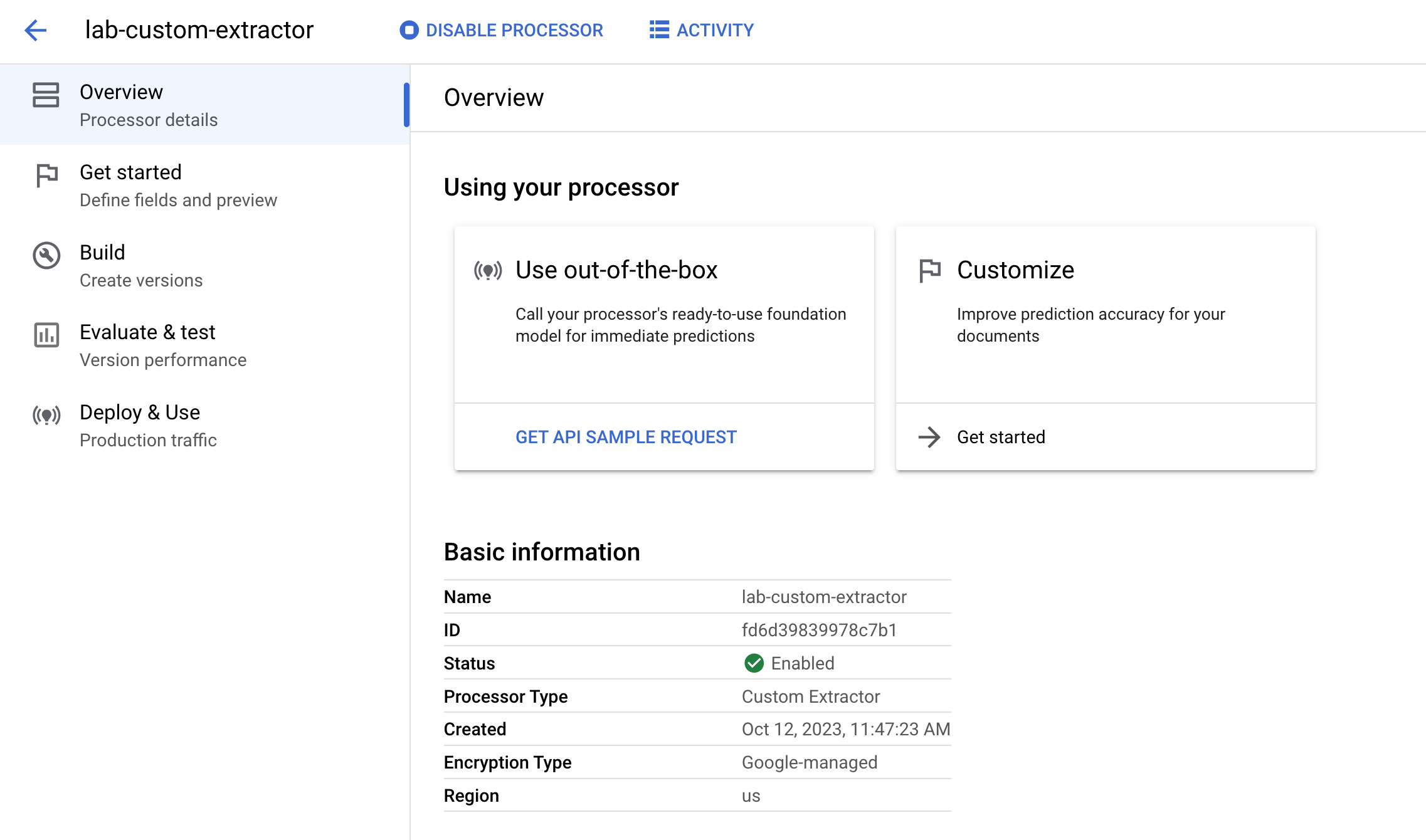
作成したプロセッサの [プロセッサの概要] ページが表示されます。
プロセッサにドキュメントの抽出とラベル付けの開始をさせるフィールドを指定できます。
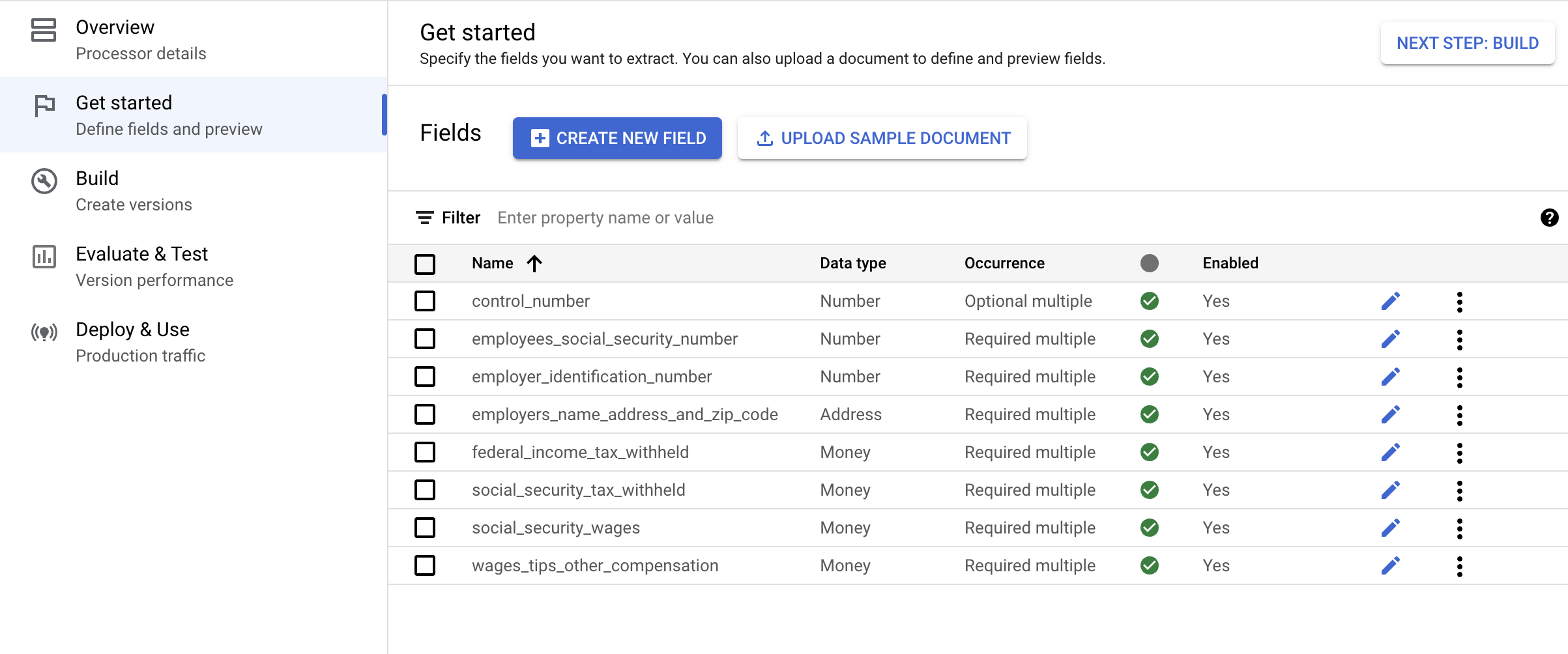
[開始] タブをクリックします。[フィールド] メニューが表示されます。
[新しいフィールドを作成] をクリックします。
フィールドの名前を入力します。[データ型] と [オカレンス] を選択し、[作成] をクリックします。スキーマの作成と編集の詳細な手順については、プロセッサ スキーマを定義するをご覧ください。
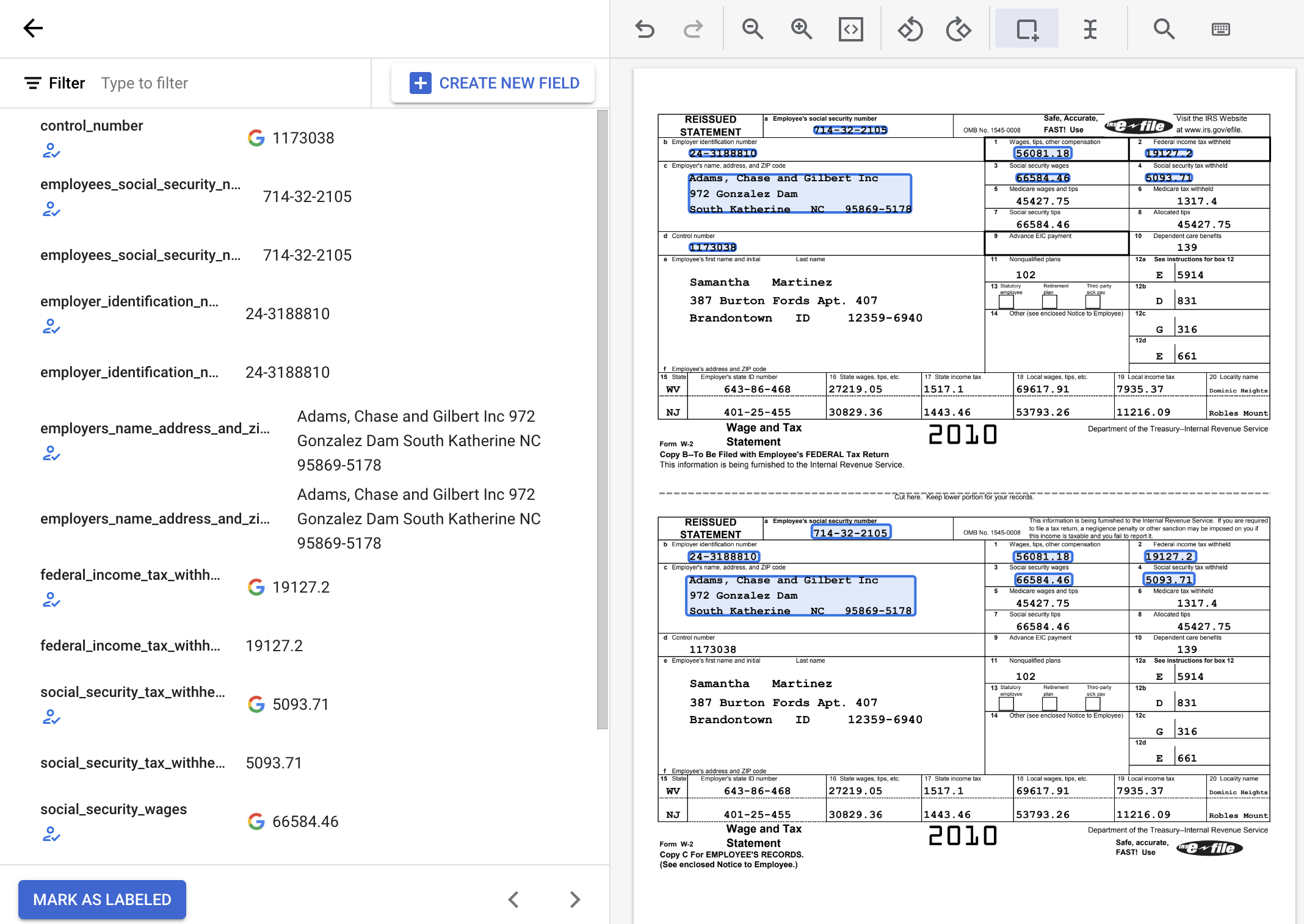
プロセッサ スキーマ用に次のラベルをそれぞれ作成します。
| 名前 | データ型 | オカレンス |
|---|---|---|
control_number |
番号 | オプションの複数回 |
employees_social_security_number |
番号 | 必須の複数回 |
employer_identification_number |
番号 | 必須の複数回 |
employers_name_address_and_zip_code |
住所 | 必須の複数回 |
federal_income_tax_withheld |
金額 | 必須の複数回 |
social_security_tax_withheld |
金額 | 必須の複数回 |
social_security_wages |
金額 | 必須の複数回 |
wages_tips_other_compensation |
金額 | 必須の複数回 |
プロセッサ スキーマでは、その他の種類のラベル(チェックボックスや表形式エンティティなど)を作成して使用することもできます。たとえば、W-2 フォームには、スキーマにも追加できる [Statutory employee]、[Retirement plan]、[Third party sick pay] のチェックボックスが含まれています。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
次に、サンプルの W-2 PDF をアップロードしてラベルを付けます。
[サンプル ドキュメントをアップロード] をクリックします。
サイドバーで、[Google Cloud Storage からドキュメントをインポートする] をクリックします。
この例では、このバケット名を [ソースのパス] に入力します。これは 1 つのドキュメントに直接リンクしています。
ラベル付けコンソールにリダイレクトされます。
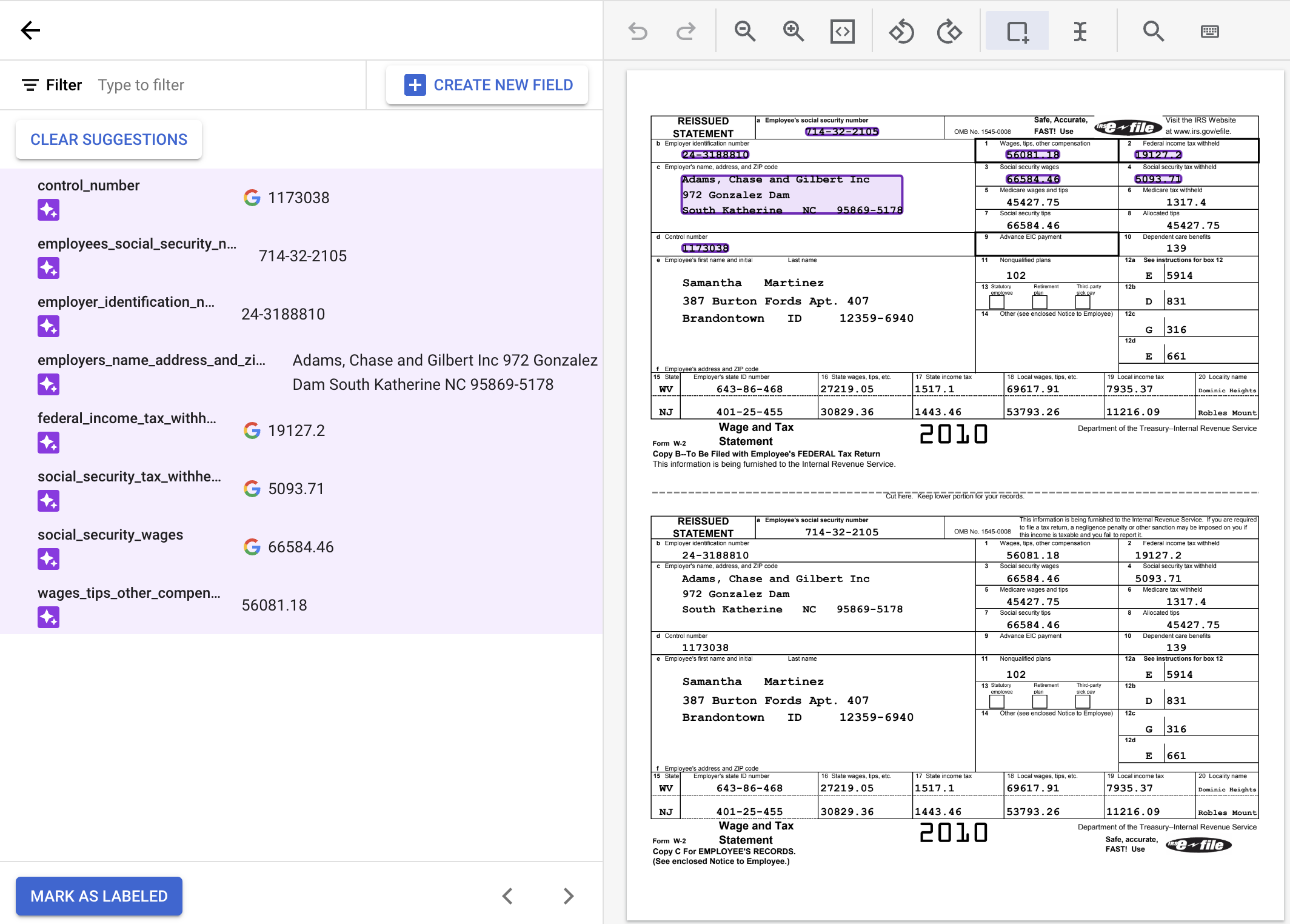
ドキュメント内のテキストを選択してラベルを適用するプロセスを「アノテーション」と呼びます。
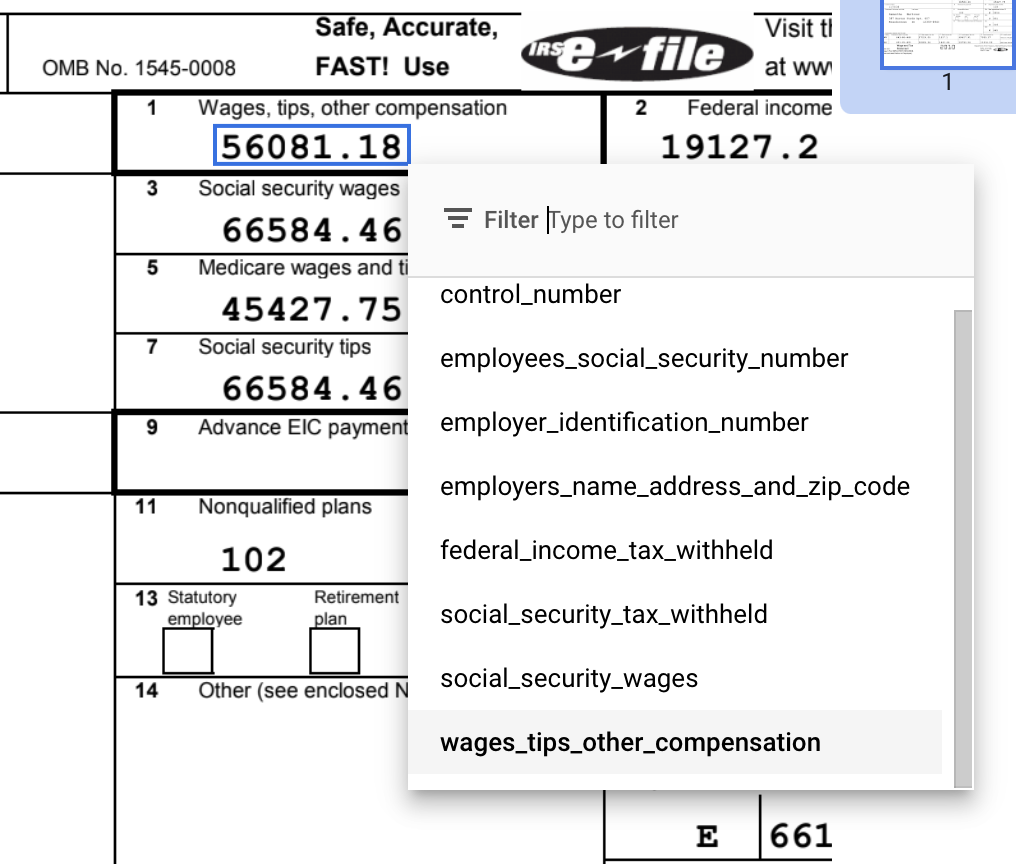
提案されたラベルを使用するには、サイドパネルの各ラベルにポインタを合わせ、チェックマークを選択してラベルが正しいことを確認します。値がドキュメントのテキストと一致しない場合は、編集できます。
この例では、ドキュメントの下部にある値は自動的に識別されなかったため、手動でラベルを付ける必要があります。
デフォルトで [境界ボックス] ツールを使用するか、複数行値の場合は [テキスト選択] ツールを使用して、コンテンツを選択し、ラベルを適用します。
wages_tips_other_compensation の値が選択され、そのラベルが適用されています。完了すると、ラベル付きの W-2 ドキュメントは次のように表示されます。
必要に応じて、[新しいフィールドを作成] をクリックして、このページからスキーマに新しいフィールドを追加できます。
ドキュメントのアノテーションが完成したら、[ラベル付きとしてマーク] をクリックします。
[開始] タブにリダイレクトされます。
1 つのドキュメントにラベルを付けたら、事前トレーニング済みの基盤モデルを使用してプロセッサ バージョンを作成し、エンティティを抽出できます。
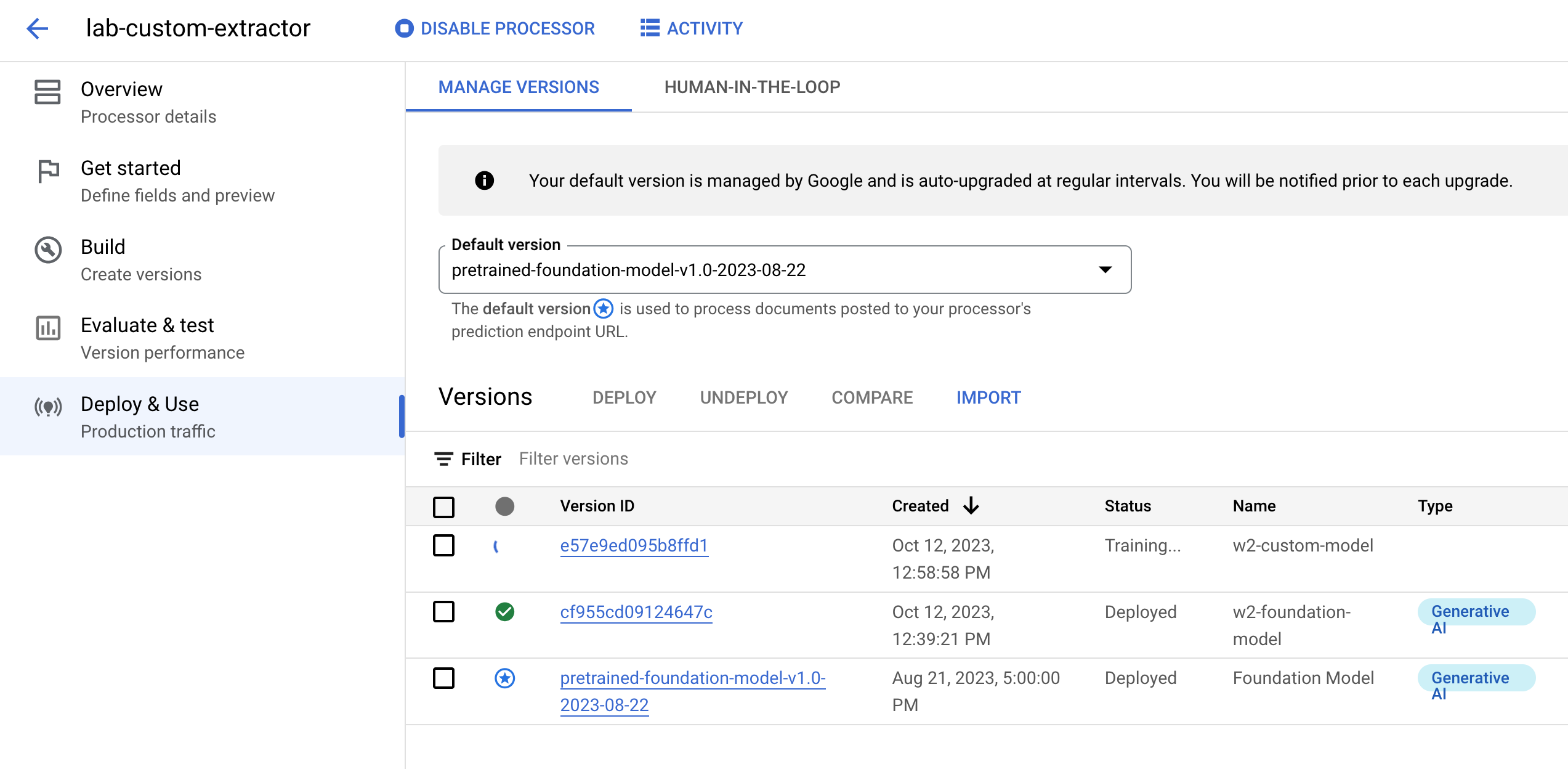
[基盤モデルを呼び出す] で [新しいバージョンを作成] をクリックします。
プロセッサ バージョンの名前(w2-foundation-model など)を入力します。
[作成] をクリックします。作成には数分かかります。
このバージョンは後ほどラボでテストし、評価します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
基盤モデルは、さまざまなドキュメント タイプのフィールドを正確に抽出できますが、追加のトレーニング データを提供して、特定のドキュメント構造に対するモデルの精度を向上させることもできます。
Document AI Workbench は、定義したラベル名と以前のアノテーションを使用して、自動ラベル付けで素早く簡単にドキュメントを大規模にラベル付けすることができます。
[ビルド] ページに移動します。
[ドキュメントをインポート] をクリックします。
サイドバーで、[Google Cloud Storage からドキュメントをインポートする] をクリックします。
このバケット名を [ソースのパス] に入力します。これには、ラベルのない W-2 PDF ファイルが含まれています。
[データ分割] リストから [自動分割] を選択します。これにより、トレーニング セットが 80%、テストセットが 20% になるようにドキュメントが自動的に分割されます。
[自動ラベル付け] セクションで、[自動ラベル付けを使用したインポート] のチェックボックスをオンにします。
作成した基盤モデル プロセッサのバージョンを選択して、ドキュメントのラベル付けを行います。
[インポート] をクリックして、ドキュメントがインポートされるのを待ちます。このページを離れて、後で戻ってくることもできます。
自動でラベル付けされたドキュメントを、トレーニングやテストに使用する前に、確認する必要があります。[ラベル付けを開始] をクリックして、自動的にラベル付けされたドキュメントを表示します。
提案されたラベルを使用するには、各アノテーションにポインタを合わせて、チェックマークをクリックしてラベルが正しいことを確認します。値がドキュメントのテキストと一致しない場合は、編集できます。
ドキュメントのアノテーションが完成したら、[ラベル付きとしてマーク] をクリックします。
自動的にラベル付けされたドキュメントごとに繰り返します。このチュートリアルでは、自動ラベル付けに失敗したドキュメントはスキップできます。
このラボでは、あらかじめラベル付けされたデータが用意されています。独自のプロジェクトで作業する場合は、データのラベル付けの方法を決定する必要があります。詳しくは、ラベル付けの方法をご覧ください。一般に、トレーニング データが多くなるほど、精度が高くなります。
[ビルド] ページに移動します。
[ドキュメントをインポート] をクリックします。
サイドバーで、[Google Cloud Storage からドキュメントをインポートする] をクリックします。
[ソースのパス] に次のパスを入力します。このバケットには、事前にラベル付けされたドキュメントが Document JSON 形式で含まれています。
[データ分割] リストから [自動分割] を選択します。これにより、トレーニング セットが 80%、テストセットが 20% になるようにドキュメントが自動的に分割されます。[自動ラベル付けを使用したインポート] をオフのままにします。
[インポート] をクリックします。インポートには数分かかります。
[ビルド] ページから [データセットの管理] コンソールにアクセスし、データセット内のすべてのドキュメントとラベルを表示および編集できます。
トレーニング データとテストデータが十分にそろったところで、次にプロセッサをトレーニングできます。トレーニングには数時間かかる場合があるため、トレーニングを開始する前に、適切なデータとラベルがプロセッサに設定されていることを確認してください。
[カスタムモデルのトレーニング] で [新しいバージョンを作成] をクリックします。
[新しいバージョンを作成] をクリックできない場合は、[要件の詳細を見る] をクリックしてデータセットの要件を確認します。
[バージョン名] フィールドに、このプロセッサ バージョンの名前(w2-custom-model など)を入力します。
(省略可)[ラベルの統計データを表示] をクリックして、ドキュメント ラベルに関する情報を確認します。これにより、対応範囲を判断できます。[閉じる] をクリックしてトレーニングの設定に戻ります。
[モデル トレーニング方法] で、[モデルベース] を選択します。
[トレーニングを開始] をクリックします。
(省略可)[デプロイと使用] タブをクリックします。このページで、利用可能なプロセッサ バージョンと新しいバージョンのトレーニング ステータスを確認できます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
これで、最初のカスタム Document AI プロセッサのトレーニングが開始されました。トレーニング ジョブには数時間かかるため、このラボはここで終了します。モデル バージョンをデプロイしてテストする方法について詳しくは、ドキュメントの次のセクションをご覧ください。
このラボでは、Document AI を使用してカスタム ドキュメント抽出プロセッサを作成し、データセットをインポートして、サンプル ドキュメントにラベルを付けました。専用プロセッサと同じように、このプロセッサを使ってこの形式のドキュメントを解析することができます。また、このプロセッサを使用して自動ラベル付けで新しいドキュメントにラベルを付けたり、Document AI Workbench を使用してトレーニング データとトレーニング ジョブを管理したりすることもできます。
Document AI と Python クライアント ライブラリの詳細については、以下のリソースをご覧ください。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2025 年 3 月 17 日
ラボの最終テスト日: 2025 年 3 月 17 日
Copyright 2025 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください