Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
Créer un pipeline d'extraction, de transformation et de chargement (ETL, Extract-Transform-Load) par lot dans Apache Beam, qui extrait les données brutes de Google Cloud Storage et les écrit dans Google BigQuery
Exécuter le pipeline Apache Beam sur Dataflow
Paramétrer l'exécution du pipeline
Prérequis :
Connaître les bases de Python
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Qwiklabs dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à Google Cloud Console.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
Dans la console Google Cloud, accédez au menu de navigation (), puis sélectionnez IAM et administration > IAM.
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle editor (éditeur). Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation du cloud > Tableau de bord.
Remarque : Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle editor (éditeur), procédez comme suit pour lui attribuer le rôle approprié.
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation du cloud > Tableau de bord.
Copiez le numéro du projet (par exemple, 729328892908).
Dans le menu de navigation, sélectionnez IAM et administration > IAM.
Sous Afficher par compte principal, en haut de la table des rôles, cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez :
Remplacez {project-number} par le numéro de votre projet.
Dans le champ Rôle, sélectionnez Projet (ou Basique) > Éditeur.
Cliquez sur Enregistrer.
Configurer l'environnement de développement des instances Workbench
Dans cet atelier, vous exécuterez toutes les commandes dans un terminal à partir de votre notebook d'instance.
Dans le menu de navigation () de la console Google Cloud, sélectionnez Vertex AI.
Cliquez sur Activer toutes les API recommandées.
Dans le menu de navigation, cliquez sur Workbench.
En haut de la page "Workbench", vérifiez que vous vous trouvez dans la vue Instances.
Cliquez sur Créer.
Configurez l'instance :
Nom : lab-workbench
Région : définissez la région sur
Zone : définissez la zone sur
Options avancées (facultatif) : si nécessaire, cliquez sur "Options avancées" pour une personnalisation plus avancée (par exemple, type de machine, taille du disque).
Cliquez sur Créer.
La création de l'instance prend quelques minutes. Une coche verte apparaît à côté de son nom quand elle est prête.
Cliquez sur Ouvrir JupyterLab à côté du nom de l'instance pour lancer l'interface JupyterLab. Un nouvel onglet s'ouvre alors dans votre navigateur.
Cliquez ensuite sur Terminal. Le terminal qui s'affiche vous permet d'exécuter toutes les commandes de cet atelier.
Télécharger le dépôt de code
Maintenant, vous allez télécharger le dépôt de code que vous utiliserez dans cet atelier.
Dans le terminal que vous venez d'ouvrir, saisissez le code suivant :
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
cd /home/jupyter/training-data-analyst/quests/dataflow_python/
Dans le panneau de gauche de votre environnement de notebook, dans l'explorateur de fichiers, notez que le dépôt training-data-analyst a été ajouté.
Accédez au dépôt cloné /training-data-analyst/quests/dataflow_python/. Chaque atelier correspond à un dossier, divisé en deux sous-dossiers : le premier, intitulé lab, contient du code que vous devez compléter, tandis que le second, nommé solution, comporte un exemple concret que vous pouvez consulter si vous rencontrez des difficultés.
Remarque : Si vous souhaitez ouvrir un fichier pour le modifier, il vous suffit de le trouver et de cliquer dessus. Une fois ce fichier ouvert, vous pourrez y ajouter du code ou en modifier le code.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer une instance de notebook et cloner le dépôt du cours
Apache Beam et Dataflow
Environ 5 minutes
Dataflow est un service Google Cloud entièrement géré permettant d'exécuter des pipelines de traitement de données Apache Beam par lot et par flux.
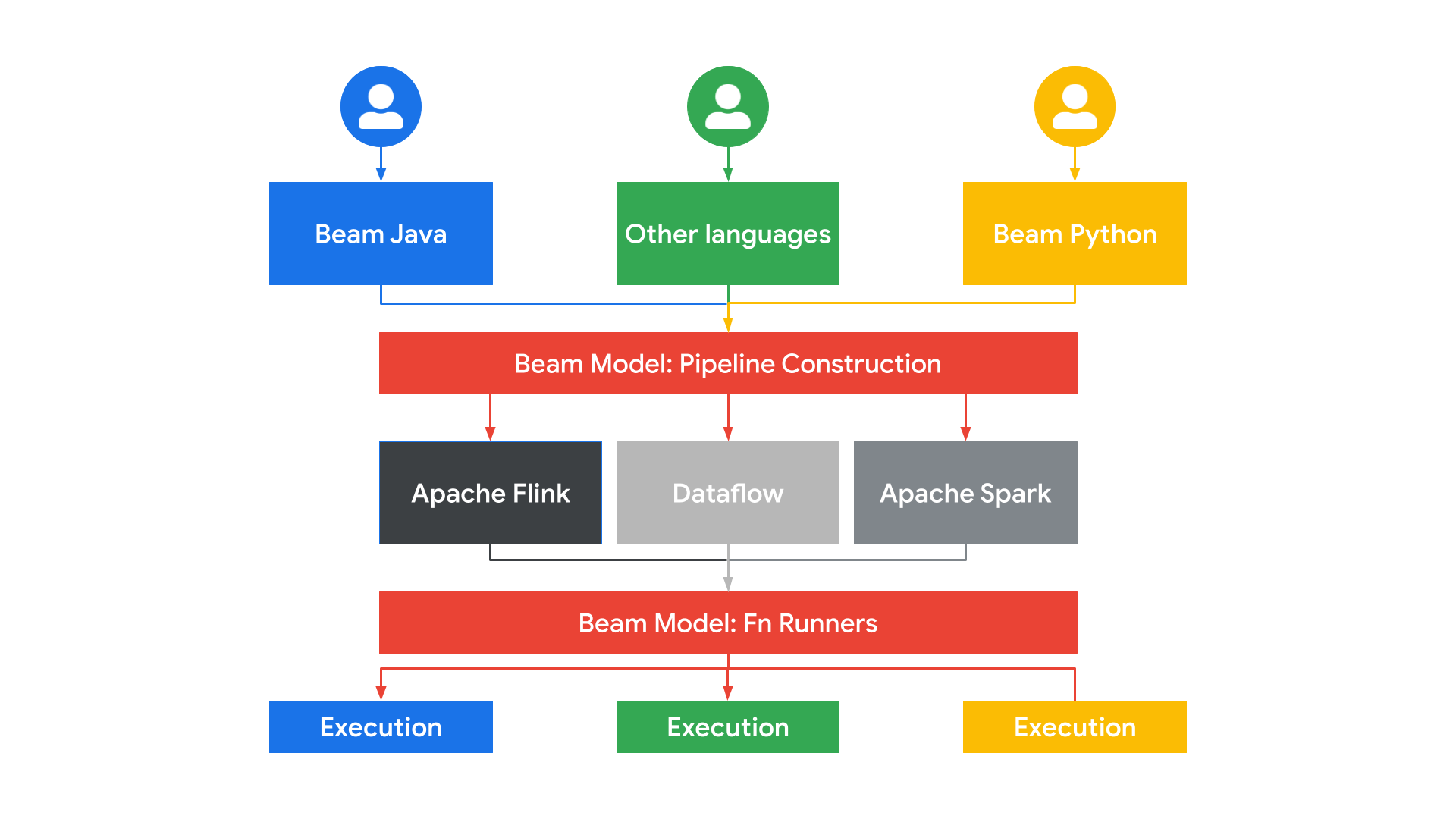
Apache Beam est un modèle de programmation Open Source avancé, unifié et portable pour le traitement des données. Il permet à l'utilisateur final de définir des pipelines de traitement parallèle des données par lot et par flux en Java, Python ou Go. Les pipelines Apache Beam peuvent être exécutés sur votre ordinateur de développement local pour les ensembles de données de taille réduite et à grande échelle sur Dataflow. Cependant, comme Apache Beam est Open Source, vous pouvez aussi exécuter les pipelines Beam sur Apache Flink et Apache Spark, entre autres.
Partie 1 de l'atelier : Écrire un pipeline ETL à partir de zéro
Introduction
Dans cette section, vous allez écrire un pipeline ETL Apache Beam à partir de zéro.
Examen de l'ensemble de données et du cas d'utilisation
Dans chaque atelier de cette quête, les données d'entrée doivent être semblables aux journaux de serveur Web Common Log Format, ainsi qu'aux autres données que peut potentiellement contenir un serveur Web. Dans ce premier atelier, les données sont traitées comme source par lot. Dans les prochains ateliers, les données seront traitées comme source par flux. Votre tâche consiste à lire, à analyser, puis à écrire les données dans BigQuery, un entrepôt de données sans serveur, afin de les analyser ultérieurement.
Ouvrir l'atelier approprié
Retournez dans le terminal de votre IDE, puis copiez et collez la commande suivante :
cd 1_Basic_ETL/lab
export BASE_DIR=$(pwd)
Configurer l'environnement virtuel et les dépendances
Avant de pouvoir modifier le code du pipeline, assurez-vous d'avoir installé les dépendances nécessaires.
Dans le terminal, créez un environnement virtuel pour votre travail dans cet atelier :
Exécutez la commande suivante dans le terminal pour cloner un dépôt contenant des scripts permettant de générer des journaux de serveur Web synthétiques :
cd $BASE_DIR/../..
source create_batch_sinks.sh
bash generate_batch_events.sh
head events.json
Le script crée un fichier nommé events.json contenant des lignes semblables à ce qui suit :
Il copie ensuite automatiquement ce fichier dans votre bucket Google Cloud Storage à l'adresse .
Dans un autre onglet de navigateur, accédez à Google Cloud Storage et vérifiez que votre bucket de stockage contient un fichier nommé events.json.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Générer des données synthétiques
Tâche 2 : Lire les données de votre source
Si vous rencontrez des difficultés dans cette section ou dans les sections suivantes, n'hésitez pas à consulter la solution.
Dans l'explorateur de fichiers, accédez au dossier de l'atelier 1_Basic_ETL/lab, puis cliquez sur my_pipeline.py. Le fichier s'ouvre dans un panneau d'édition. Assurez-vous que les packages suivants sont importés :
import argparse
import time
import logging
import json
import apache_beam as beam
from apache_beam.options.pipeline_options import GoogleCloudOptions
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import StandardOptions
from apache_beam.runners import DataflowRunner, DirectRunner
Faites défiler la page jusqu'à la méthode run(). Cette méthode contient actuellement un pipeline qui ne réalise aucune opération. Notez qu'un objet Pipeline est créé à l'aide d'un objet PipelineOptions. La dernière ligne de la méthode exécute le pipeline :
options = PipelineOptions()
# Set options
p = beam.Pipeline(options=options)
# Do stuff
p.run()
Toutes les données des pipelines Apache Beam résident dans des PCollections. Pour créer la première PCollection du pipeline, vous devez appliquer une transformation racine à l'objet de pipeline. Une transformation racine crée une PCollection à partir d'une source de données externe ou de certaines données locales que vous spécifiez.
Il existe deux types de transformations racines dans les SDK Beam : Read et Create. Les transformations Read lisent des données provenant d'une source externe, comme un fichier texte ou une table de base de données. Les transformations Create créent une PCollection à partir d'une liste en mémoire et sont particulièrement utiles pendant les tests.
L'exemple de code suivant montre comment appliquer une transformation racine ReadFromText pour lire des données à partir d'un fichier texte. Cette transformation est appliquée à un objet Pipeline, p, et renvoie un ensemble de données de pipeline sous la forme d'une PCollection[str] (à l'aide d'une notation issue des indicateurs de types paramétrés). "ReadLines" est le nom de la transformation, qui sera utile ultérieurement lorsque vous travaillerez avec des pipelines plus volumineux.
lines = p | "ReadLines" >> beam.io.ReadFromText("gs://path/to/input.txt")
Dans la méthode run(), créez une constante de chaîne nommée input et définissez sa valeur sur gs://<VOTRE-ID-DE--PROJET>/events.json. Dans un prochain atelier, vous utiliserez des paramètres de ligne de commande pour transmettre ces informations.
Créez une PCollection contenant les chaînes de tous les événements du fichier events.json en appelant la transformation textio.ReadFromText.
Ajoutez toute instruction d'importation appropriée en haut du fichier my_pipeline.py.
Pour enregistrer votre travail, cliquez sur Fichier, puis sélectionnez Enregistrer dans le menu de navigation en haut de l'écran.
Tâche 3 : Exécuter le pipeline pour vérifier qu'il fonctionne
Retournez dans le terminal, accédez au dossier $BASE_DIR et exécutez les commandes ci-dessous. Veillez à définir la variable d'environnement PROJECT_ID avant d'exécuter le pipeline :
cd $BASE_DIR
# Set up environment variables
export PROJECT_ID=$(gcloud config get-value project)
# Run the pipeline
python3 my_pipeline.py \
--project=${PROJECT_ID} \
--region={{{project_0.startup_script.lab_region|Region}}} \
--stagingLocation=gs://$PROJECT_ID/staging/ \
--tempLocation=gs://$PROJECT_ID/temp/ \
--runner=DirectRunner
Pour l'instant, votre pipeline ne réalise aucune opération. Il lit simplement les données.
Cependant, son exécution illustre un workflow utile, dans lequel vous vérifiez le pipeline localement et à moindre coût à l'aide de DirectRunner sur votre ordinateur local avant d'effectuer des calculs plus coûteux. Pour exécuter le pipeline avec Google Dataflow, vous pouvez remplacer runner par DataflowRunner.
Tâche 4 : Ajouter une transformation
Si vous rencontrez des difficultés, consultez la solution.
Les transformations modifient vos données. Dans Apache Beam, les transformations sont effectuées par la classe PTransform. Au moment de l'exécution, ces opérations seront effectuées sur un certain nombre de nœuds de calcul indépendants.
L'entrée et la sortie de chaque PTransform sont des PCollections. Même si vous ne l'avez peut-être pas remarqué, vous avez déjà utilisé une PTransform pour lire des données provenant de Google Cloud Storage. Que vous l'ayez affectée ou non à une variable, cela a créé une PCollection de chaînes.
Étant donné que Beam utilise une méthode d'application générique pour les PCollection, représentée par l'opérateur pipe | en Python, vous pouvez enchaîner les transformations de manière séquentielle. Par exemple, vous pouvez enchaîner des transformations pour créer un pipeline séquentiel comme celui-ci :
Pour cette tâche, vous allez utiliser un nouveau type de transformation : ParDo. ParDo est une transformation Beam pour le traitement parallèle générique.
Le paradigme de traitement ParDo est semblable à la phase de mappage d'un algorithme de type mappage/brassage/réduction (Map/Shuffle/Reduce) : une transformation ParDo prend en compte chaque élément de la PCollection d'entrée, exécute une fonction de traitement (votre code utilisateur) sur cet élément et émet zéro, un ou plusieurs éléments dans une PCollection de sortie.
ParDo est utile pour diverses opérations courantes de traitement de données, mais il existe des PTransform spéciales en Python pour simplifier le processus. Voici quelques exemples :
Filtrer un ensemble de données : vous pouvez utiliser Filter pour prendre en compte chaque élément d'une PCollection, puis générer cet élément dans une nouvelle PCollection ou le supprimer en fonction de la sortie d'une fonction Python appelable qui renvoie une valeur booléenne.
Mettre en forme ou convertir le type de chaque élément d'un ensemble de données : si votre PCollection d'entrée contient des éléments dont le type ou le format ne vous convient pas, vous pouvez utiliser Map pour effectuer la conversion de chaque élément et générer le résultat dans une nouvelle PCollection.
Extraire des parties de chaque élément d'un ensemble de données : si par exemple votre PCollection contient des enregistrements avec plusieurs champs, vous pouvez aussi utiliser Map ou FlatMap pour analyser uniquement les champs à prendre en compte dans une nouvelle PCollection.
Effectuer des calculs sur chaque élément d'un ensemble de données : vous pouvez utiliser ParDo, Map ou FlatMap pour effectuer des calculs simples ou complexes sur chaque élément, ou sur certains éléments, d'une PCollection et générer les résultats dans une nouvelle PCollection.
Pour réaliser cette tâche, vous devez écrire une transformation Map qui lit une chaîne JSON représentant un seul événement, qui l'analyse à l'aide du package json Python et qui génère le dictionnaire renvoyé par json.loads.
Les fonctions Map peuvent être implémentées de manière intégrée ou à l'aide d'une fonction appelable prédéfinie. Pour écrire des fonctions Map intégrées, exécutez une commande qui doit se présenter comme suit :
p | beam.Map(lambda x : something(x))
Vous pouvez également utiliser beam.Map avec une fonction appelable Python définie précédemment dans le script :
def something(x):
y = # Do something!
return y
p | beam.Map(something)
Si vous avez besoin de plus de flexibilité que celle proposée par beam.Map (et par d'autres fonctions légères DoFn), vous pouvez implémenter ParDo avec des DoFn personnalisés correspondant à une sous-classe de DoFn. Cela permet de les intégrer plus facilement aux frameworks de test.
class MyDoFn(beam.DoFn):
def process(self, element):
output = #Do Something!
yield output
p | beam.ParDo(MyDoFn())
Pour rappel, vous pouvez consulter la solution si vous rencontrez des difficultés.
Tâche 5 : Écrire dans un récepteur
À ce stade, le pipeline lit un fichier depuis Google Cloud Storage, analyse chaque ligne et émet un dictionnaire Python pour chaque élément. L'étape suivante consiste à écrire ces objets dans une table BigQuery.
Bien que vous puissiez demander à votre pipeline de créer une table BigQuery si nécessaire, vous devrez créer l'ensemble de données à l'avance. Cette opération a déjà été effectuée par le script generate_batch_events.sh. Vous pouvez examiner l'ensemble de données à l'aide du code suivant :
# Examine dataset
bq ls
# No tables yet
bq ls logs
Pour générer les PCollection finales du pipeline, vous devez appliquer une transformation Write à cette PCollection. Les transformations Write peuvent générer les éléments d'une PCollection vers un récepteur de données externe, tel qu'une table de base de données. Vous pouvez utiliser une transformation Write pour générer une PCollection à tout moment dans le pipeline, bien que l'écriture de données soit généralement effectuée à la fin du pipeline.
L'exemple de code suivant montre comment appliquer une transformation WriteToText pour écrire une PCollection de chaîne dans un fichier texte :
p | "WriteMyFile" >> beam.io.WriteToText("gs://path/to/output")
Dans ce cas, utilisez WriteToBigQuery au lieu de WriteToText.
Cette fonction nécessite de spécifier un certain nombre d'éléments, y compris la table dans laquelle écrire ainsi que le schéma de cette table. Vous pouvez indiquer si vous souhaitez ajouter des données à une table existante, recréer des tables existantes (ce qui est utile pour la première itération du pipeline) ou créer la table si elle n'existe pas. Par défaut, cette transformation créera des tables qui n'existent pas et n'écrira pas dans une table qui n'est pas vide.
Toutefois, nous devons spécifier notre schéma. Pour ce faire, deux moyens s'offrent à vous. Il est possible de spécifier le schéma sous la forme d'une chaîne unique ou au format JSON. Par exemple, supposons que notre dictionnaire comporte trois champs : "name" (de type str), "ID" (de type int) et "balance" (de type float). Vous pouvez ensuite spécifier le schéma sur une seule ligne :
Dans le premier cas (la chaîne unique), tous les champs sont considérés comme NULLABLE. Nous pouvons spécifier le mode si nous utilisons l'approche JSON à la place.
Une fois le schéma de la table défini, nous pouvons ajouter le récepteur à notre DAG :
p | 'WriteToBQ' >> beam.io.WriteToBigQuery(
'project:dataset.table',
schema=table_schema,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE
)
Remarque : WRITE_TRUNCATE supprimera et recréera votre table à chaque fois. Cette opération est utile lors de la première itération du pipeline, en particulier sur votre schéma. Toutefois, elle peut facilement entraîner des problèmes inattendus en production. Il est plus prudent d'utiliser WRITE_APPEND ou WRITE_EMPTY.
N'oubliez pas de définir le schéma de la table et d'ajouter le récepteur BigQuery à votre pipeline. Pour rappel, vous pouvez consulter la solution si vous rencontrez des difficultés.
Tâche 6 : Exécuter le pipeline
Retournez au terminal et exécutez votre pipeline en vous servant d'une commande presque identique à celle utilisée précédemment. Cependant, vous allez maintenant exécuter le pipeline sur Dataflow à l'aide de DataflowRunner.
# Set up environment variables
cd $BASE_DIR
export PROJECT_ID=$(gcloud config get-value project)
# Run the pipelines
python3 my_pipeline.py \
--project=${PROJECT_ID} \
--region={{{project_0.startup_script.lab_region|Region}}} \
--stagingLocation=gs://$PROJECT_ID/staging/ \
--tempLocation=gs://$PROJECT_ID/temp/ \
--runner=DataflowRunner
La forme globale doit correspondre à un seul chemin d'accès, commençant par la transformation Read et se terminant par la transformation Write. À mesure que votre pipeline s'exécute, des nœuds de calcul sont ajoutés automatiquement, car le service détermine les besoins de votre pipeline, puis ils disparaissent lorsqu'ils ne sont plus nécessaires. Pour observer cela, accédez à Compute Engine, où vous devriez voir les machines virtuelles créées par le service Dataflow.
Remarque : Si vous avez réussi à créer votre pipeline, mais que vous constatez de nombreuses erreurs dues au code ou à une mauvaise configuration dans le service Dataflow, vous pouvez redéfinir runner sur DirectRunner pour l'exécuter en local et obtenir plus rapidement des retours. Cette approche est efficace dans ce cas, étant donné que l'ensemble de données est de taille réduite et que vous n'utilisez aucune fonctionnalité non compatible avec DirectRunner.
Une fois votre pipeline terminé, retournez dans la fenêtre BigQuery du navigateur et interrogez votre table.
Si votre code ne fonctionne pas comme prévu et que vous ne savez pas quoi faire pour y remédier, consultez la solution.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Exécuter le pipeline
Partie 2 de l'atelier : Paramétrer un pipeline ETL de base
Environ 20 minutes
La plupart des tâches des ingénieurs de données sont prévisibles, comme les jobs récurrents, ou semblables à d'autres jobs. Cependant, le processus d'exécution des pipelines nécessite une expertise en ingénierie. Repensez aux étapes que vous venez de terminer :
Vous avez créé un environnement de développement et développé un pipeline. L'environnement comprenait le SDK Apache Beam ainsi que d'autres dépendances.
Vous avez exécuté le pipeline à partir de l'environnement de développement. Le SDK Apache Beam a préparé des fichiers dans Cloud Storage, a créé un fichier de requête de job et l'a envoyé au service Dataflow.
Ce serait beaucoup mieux s'il existait un moyen de démarrer un job avec un appel d'API ou sans avoir à configurer un environnement de développement (une opération inaccessible aux utilisateurs non techniques). Cela vous permettrait également d'exécuter des pipelines.
Les modèles Dataflow cherchent à résoudre ce problème en modifiant la représentation créée lorsqu'un pipeline est compilé afin de le rendre paramétrable. Malheureusement, il ne suffit pas d'exposer des paramètres de ligne de commande, même si cette approche sera abordée dans un prochain atelier. Avec les modèles Dataflow, le workflow ci-dessus se présente comme suit :
Les développeurs créent un environnement de développement et développent leur pipeline. L'environnement comprend le SDK Apache Beam ainsi que d'autres dépendances.
Les développeurs exécutent le pipeline et créent un modèle. Le SDK Apache Beam prépare les fichiers dans Cloud Storage, crée un fichier de modèle (comparable à une requête de job), puis l'enregistre dans Cloud Storage.
Les utilisateurs non techniques, ainsi que d'autres outils de workflow comme Airflow, peuvent facilement exécuter des jobs à l'aide de la console Google Cloud, de l'outil de ligne de commande gcloud ou de l'API REST pour envoyer des requêtes d'exécution de fichier de modèle au service Dataflow.
Dans cet atelier, vous allez vous entraîner à utiliser l'un des nombreux modèles Dataflow créés par Google pour effectuer la même tâche que le pipeline que vous avez créé dans la partie 1.
Tâche 1 : Créer un fichier de schéma JSON
Comme précédemment, vous devez transmettre au modèle Dataflow un fichier JSON représentant le schéma de cet exemple.
Retournez dans le terminal de votre IDE. Exécutez les commandes suivantes pour revenir au répertoire principal, puis récupérez le schéma de votre table logs.logs existante :
cd $BASE_DIR/../..
bq show --schema --format=prettyjson logs.logs
Capturez ensuite le résultat dans un fichier et importez-le dans GCS. Les commandes sed supplémentaires permettent de créer un objet JSON complet attendu par Dataflow.
bq show --schema --format=prettyjson logs.logs | sed '1s/^/{"BigQuery Schema":/' | sed '$s/$/}/' > schema.json
cat schema.json
export PROJECT_ID=$(gcloud config get-value project)
gcloud storage cp schema.json gs://${PROJECT_ID}/
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer un fichier de schéma JSON
Tâche 2 : Écrire une fonction définie par l'utilisateur en JavaScript
Le modèle Dataflow de Cloud Storage vers BigQuery nécessite une fonction JavaScript pour convertir le texte brut en code JSON valide. Dans ce cas, chaque ligne de texte correspond à du code JSON valide. Cette fonction est donc sans grand intérêt ici.
Pour effectuer cette tâche, créez un fichier dans le dossier dataflow_python de l'explorateur de fichiers de votre IDE.
Pour créer un fichier, cliquez sur Fichier >> Nouveau >> Fichier texte.
Renommez le fichier transform.js. Pour ce faire, effectuez un clic droit dessus.
Cliquez sur le fichier transform.js dans le panneau d'édition pour l'ouvrir.
Copiez la fonction ci-dessous dans le fichier transform.js et enregistrez-la :
function transform(line) {
return line;
}
Exécutez ensuite la commande suivante pour copier le fichier dans Google Cloud Storage :
Sous Modèle Dataflow, sélectionnez le modèle Fichiers texte dans Cloud Storage vers BigQuery dans la section Traiter les données de façon groupée (lot), et NON PAS dans la section "Flux".
Sous Fichier d'entrée Cloud Storage, saisissez le chemin d'accès vers le fichier events.json au format .
Sous Emplacement Cloud Storage de votre fichier de schéma BigQuery, écrivez le chemin d'accès à votre fichier schema.json, au format .
Sous Table BigQuery de sortie, saisissez .
Sous Répertoire BigQuery temporaire, créez un dossier dans ce même bucket. Le job va le créer pour vous.
Sous Emplacement temporaire, indiquez un deuxième nouveau dossier dans ce même bucket.
Laissez le champ Chiffrement défini sur Clé de chiffrement gérée par Google.
Cliquez pour ouvrir Paramètres facultatifs.
Sous Chemin d'accès aux fonctions JavaScript définies par l'utilisateur dans Cloud Storage, saisissez le chemin d'accès à votre fichier .js, au format .
Sous Nom des fonctions JavaScript définies par l'utilisateur, saisissez transform.
Cliquez sur le bouton Exécuter le job.
Vous pouvez inspecter votre job à partir de l'interface utilisateur Web de Dataflow pendant son exécution.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Exécuter un modèle Dataflow
Tâche 4 : Inspecter le code du modèle Dataflow
Le code du modèle Dataflow que vous venez d'utiliser se trouve dans ce guide TextIOToBigQuery.
Faites défiler la page jusqu'à la méthode main. Le code doit ressembler au pipeline que vous avez créé.
Il commence par un objet Pipeline, créé à l'aide d'un objet PipelineOptions.
Il se compose d'une chaîne de PTransform, commençant par une transformation TextIO.read().
La PTransform après la transformation Read est légèrement différente. Elle permet d'utiliser du code JavaScript pour transformer les chaînes d'entrée si, par exemple, le format source ne correspond pas tout à fait au format de la table BigQuery. Pour en savoir plus sur l'utilisation de cette fonctionnalité, consultez cette page.
La Write PTransform est légèrement différente, car au lieu d'utiliser un schéma connu au moment de la compilation du graphe, le code est destiné à accepter des paramètres qui ne seront connus qu'au moment de l'exécution. C'est la classe NestedValueProvider qui rend cela possible.
Ne manquez pas le prochain atelier, qui abordera la création de pipelines allant au-delà des simples chaînes de PTransform. Vous découvrirez également comment adapter un pipeline que vous avez créé pour en faire un modèle Dataflow personnalisé.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2020 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Ouvrez une fenêtre de navigateur en mode navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez : a) créer un pipeline ETL par lot dans Apache Beam, qui extrait des données brutes de Google Cloud Storage et les écrit dans Google BigQuery, b) exécuter le pipeline Apache Beam sur Dataflow, c) paramétrer l'exécution du pipeline.
Durée :
2 min de configuration
·
Accessible pendant 90 min
·
Terminé après 90 min
 ), puis sélectionnez IAM et administration > IAM.
), puis sélectionnez IAM et administration > IAM.
 Créer.
Créer.