Points de contrôle
Create a Kubernetes cluster and deployments (Auth, Hello, and Frontend)
/ 50
Canary Deployment
/ 50
Gestion des déploiements avec Kubernetes Engine
- GSP053
- Présentation
- Objectifs
- Présentation des déploiements
- Préparation
- Définir la zone
- Télécharger l'exemple de code pour cet atelier
- Tâche 1 : Découvrir l'objet Déploiement
- Tâche 2 : Créer un déploiement
- Tâche 3 : Effectuer une mise à jour progressive
- Tâche 4 : Effectuer un déploiement Canary
- Tâche 5 : Effectuer un déploiement bleu-vert
- Félicitations !
GSP053

Présentation
Les équipes DevOps font souvent appel à différents types de déploiements pour gérer divers scénarios de déploiement d'applications, comme les "déploiements continus", les "déploiements bleu-vert" et les "déploiements Canary", entre autres. Cet atelier vous explique comment effectuer le scaling de conteneurs et comment les gérer pour apprendre à mettre en place ces scénarios courants composés de plusieurs déploiements hétérogènes.
Objectifs
Dans cet atelier, vous apprendrez à effectuer les tâches suivantes :
- Utiliser l'outil
kubectl - Créer des fichiers de déploiement
yaml - Lancer, modifier et faire évoluer des déploiements
- Modifier des déploiements et découvrir les styles de déploiements
Prérequis
Pour profiter pleinement de cet atelier de formation, vous devez respecter les recommandations suivantes :
- Vous avez suivi les ateliers Google Cloud Skills Boost suivants :
- Vous possédez des compétences en administration système sous Linux.
- Vous disposez de connaissances théoriques en DevOps (principes du déploiement continu).
Présentation des déploiements
Les déploiements hétérogènes consistent généralement à connecter au moins deux environnements ou régions ayant des infrastructures distinctes dans le but de répondre à des besoins techniques ou opérationnels spécifiques. Selon leurs spécificités, ces déploiements peuvent être "hybrides", "multicloud" ou "public-privé".
Dans le cadre de cet atelier, nous aborderons des déploiements hétérogènes qui s'étendent sur diverses régions dans un environnement cloud unique, dans plusieurs environnements cloud publics (multicloud) ou dans une combinaison d'environnements sur site et cloud public (hybride ou public-privé).
Différents problèmes d'ordre opérationnel et technique peuvent se présenter lors des déploiements qui se limitent à un environnement ou une région :
- Ressources insuffisantes : dans un environnement donné, en particulier s'il s'agit d'un environnement sur site, les ressources de calcul, de stockage ou réseau disponibles ne suffisent pas toujours à répondre aux besoins de production.
- Portée géographique limitée : dans un environnement unique, des utilisateurs géographiquement éloignés doivent tous accéder au même déploiement. Leur trafic peut être réparti sur toute la planète et converger vers une position centrale.
- Disponibilité restreinte : un trafic à l'échelle du Web exige des applications ayant une certaine tolérance aux pannes et de la résilience.
- Dépendance vis-à-vis d'un fournisseur : les abstractions de plate-forme et d'infrastructure liées à certains fournisseurs peuvent empêcher le portage des applications.
- Manque de flexibilité des ressources : vos ressources peuvent être limitées à un ensemble spécifique de fonctionnalités de calcul, de stockage ou réseau.
Les déploiements hétérogènes peuvent aider à résoudre ces problèmes, à condition d'être structurés par des processus et des procédures programmatiques et déterministes. Les procédures ponctuelles ou ad hoc peuvent donner lieu à des déploiements ou des processus fragiles et peu tolérants aux pannes. Les processus ad hoc peuvent entraîner des pertes de données ou de trafic. Pour être efficaces, les processus de déploiement doivent être reproductibles et mettre en œuvre des méthodes éprouvées de gestion des comptes, de configuration et de maintenance.
Les trois scénarios de déploiement hétérogènes les plus courants sont :
- les déploiements multicloud ;
- les déploiements appliqués à des données sur site ;
- les processus d'intégration et de livraison continues (CI/CD).
Les exercices suivants illustrent certains cas d'utilisation courants des déploiements hétérogènes, ainsi que des méthodes de déploiement bien structurées basées sur Kubernetes et d'autres ressources d'infrastructure qui vous aideront à les réaliser.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- vous disposez d'un temps limité ; une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google Cloud
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte. -
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}} Vous trouverez également le nom d'utilisateur dans le panneau Détails concernant l'atelier.
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}} Vous trouverez également le mot de passe dans le panneau Détails concernant l'atelier.
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud. Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés. -
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais gratuits.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
- Cliquez sur Activer Cloud Shell
en haut de la console Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Le résultat contient une ligne qui déclare YOUR_PROJECT_ID (VOTRE_ID_PROJET) pour cette session :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- (Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
-
Cliquez sur Autoriser.
-
Vous devez à présent obtenir le résultat suivant :
Résultat :
- (Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
Résultat :
Exemple de résultat :
gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
Définir la zone
Exécutez la commande suivante pour définir votre zone Google Cloud de travail, en veillant à remplacer la zone locale par
Télécharger l'exemple de code pour cet atelier
- Téléchargez l'exemple de code permettant de créer et d'exécuter des conteneurs et des déploiements :
- Créez un cluster avec trois nœuds (cette opération prend quelques minutes) :
Tâche 1 : Découvrir l'objet Déploiement
Commencez par examiner l'objet Déploiement.
- Dans
kubectl, la commandeexplainnous permet d'en savoir plus sur l'objet Déploiement :
- Vous pouvez aussi afficher l'ensemble des champs en ajoutant l'option
--recursive:
- Vous pourrez utiliser la commande explain tout au long de l'atelier pour comprendre la structure d'un objet Déploiement et voir l'effet des différents champs :
Tâche 2 : Créer un déploiement
- Mettez à jour le fichier de configuration
deployments/auth.yaml:
- Lancez l'éditeur :
- Modifiez le champ
imagedans la section "containers" du déploiement comme suit :
- Pour enregistrer le fichier
auth.yaml, appuyez sur<Échap>, puis saisissez la commande ci-dessous :
- Appuyez sur
<Entrée>. À présent, créez un déploiement simple. Examinez le fichier de configuration du déploiement :
Résultat :
Notez que le déploiement crée une instance dupliquée et utilise la version 1.0.0 du conteneur auth.
L'exécution de la commande kubectl create pour créer le déploiement auth crée un pod conforme aux données du fichier manifeste du déploiement. Vous pouvez donc faire évoluer le nombre de pods en modifiant le nombre spécifié dans le champ replicas.
- Créez maintenant votre objet Déploiement avec la commande
kubectl create:
- Vérifiez ensuite que le déploiement a bien été créé :
- Une fois le déploiement généré, Kubernetes crée un
ReplicaSetpour celui-ci. Vous pouvez vérifier si ceReplicaSeta bien été créé pour le déploiement :
Vous devriez voir apparaître un ReplicaSet portant un nom du type auth-xxxxxxx.
- Affichez les pods créés pour le déploiement. Kubernetes crée un pod en même temps que le
ReplicaSet:
Nous allons maintenant créer un service pour le déploiement auth. Comme vous avez déjà vu les fichiers manifestes des services, nous ne nous pencherons pas en détail sur ce sujet ici.
- Utilisez la commande
kubectl createpour créer le service auth :
- Procédez de la même façon pour créer et exposer le déploiement
hello:
- Répétez encore une fois l'opération pour créer et exposer le déploiement
frontend:
ConfigMap pour le déploiement frontend.- Interagissez avec le déploiement frontend en capturant son adresse IP externe, puis en l'appelant avec curl :
Vous obtenez la réponse "hello".
- Vous pouvez également associer la fonctionnalité de modélisation de sortie de
kubectlà la commande curl, sur une seule ligne :
Tester la tâche terminée
Cliquez sur Vérifier ma progression ci-dessous pour valider votre progression dans l'atelier. Si le cluster Kubernetes et les déploiements auth, hello et frontend ont correctement été créés, vous recevrez une note d'évaluation.
Effectuer le scaling d'un déploiement
Maintenant que vous avez créé le déploiement, vous pouvez effectuer son scaling. Pour ce faire, mettez à jour le champ spec.replicas.
- La commande
kubectl explainvous permet de consulter la description de ce champ, si vous le souhaitez :
- La méthode la plus simple pour mettre à jour le champ "replicas" consiste à utiliser la commande
kubectl scale:
Une fois le déploiement modifié, Kubernetes met automatiquement à jour le ReplicaSet associé et lance les nouveaux pods de façon à obtenir un nombre total de cinq pods.
- Vérifiez que cinq pods
hellosont en cours d'exécution :
- Maintenant, effectuez le scaling inverse de l'application :
- Vérifiez à nouveau que vous avez le bon nombre de pods :
Vous avez découvert les déploiements Kubernetes, et appris à gérer un groupe de pods et à effectuer son scaling.
Tâche 3 : Effectuer une mise à jour progressive
Dans un déploiement, vous pouvez mettre à jour les images vers une nouvelle version par le biais d'un mécanisme de mise à jour progressive. Ainsi, votre déploiement augmente progressivement le nombre d'instances dupliquées dans le nouveau ReplicaSet qu'il a créé, à mesure qu'il réduit le nombre d'instances dupliquées dans l'ancien ReplicaSet.
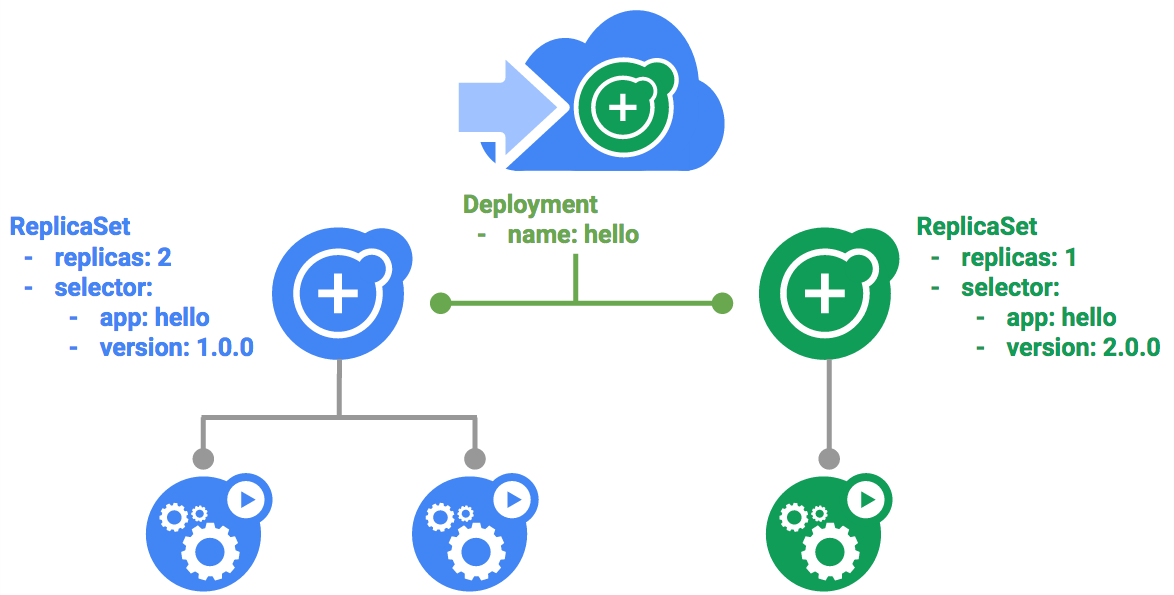
Déclencher une mise à jour progressive
- Pour mettre à jour votre déploiement, exécutez la commande suivante :
- Modifiez le champ
imagedans la section "containers" du déploiement comme suit :
- Enregistrez et quittez.
Le déploiement modifié est enregistré dans votre cluster et Kubernetes lance une mise à jour progressive.
- Affichez le nouveau
ReplicaSetcréé par Kubernetes :
- Vous pouvez voir une nouvelle entrée dans l'historique des déploiements :
Suspendre une mise à jour progressive
Si vous constatez des problèmes liés à un déploiement en cours d'exécution, suspendez la mise à jour.
- Exécutez la commande suivante pour suspendre le déploiement :
- Vérifiez l'état actuel du déploiement :
- Vous pouvez également le vérifier directement sur les pods :
Reprendre une mise à jour progressive
Le déploiement est suspendu. Par conséquent, certains pods utilisent la nouvelle version, et d'autres l'ancienne.
- Poursuivez le déploiement avec la commande
resume:
- Une fois le déploiement terminé, la commande
statusdevrait afficher le résultat suivant :
Résultat :
Lancer le rollback d'une mise à jour
Supposons qu'un bug ait été détecté dans votre nouvelle version. Tous les utilisateurs connectés aux nouveaux pods rencontreront les problèmes associés à cette nouvelle version.
Dans un tel cas, vous devez revenir à la version précédente pour analyser et corriger la nouvelle version avant de la redéployer.
- La commande
rolloutvous permet de lancer un rollback vers la version précédente :
- Vérifiez le rollback dans l'historique :
- Enfin, vérifiez que le rollback vers la version précédente a été effectué pour tous les pods :
Parfait ! Vous en savez plus sur les mises à jour progressives des déploiements Kubernetes et vous avez appris à mettre à jour des applications sans temps d'arrêt.
Tâche 4 : Effectuer un déploiement Canary
Les déploiements Canary vous permettent de tester un nouveau déploiement en production sur un sous-ensemble d'utilisateurs. Cette technique est idéale pour déployer des modifications auprès d'un petit groupe d'utilisateurs et limiter ainsi les risques associés aux nouvelles versions.
Créer un déploiement Canary
Un déploiement Canary se compose d'un déploiement distinct incluant votre nouvelle version et d'un service qui cible à la fois votre déploiement normal (stable) et votre déploiement Canary.
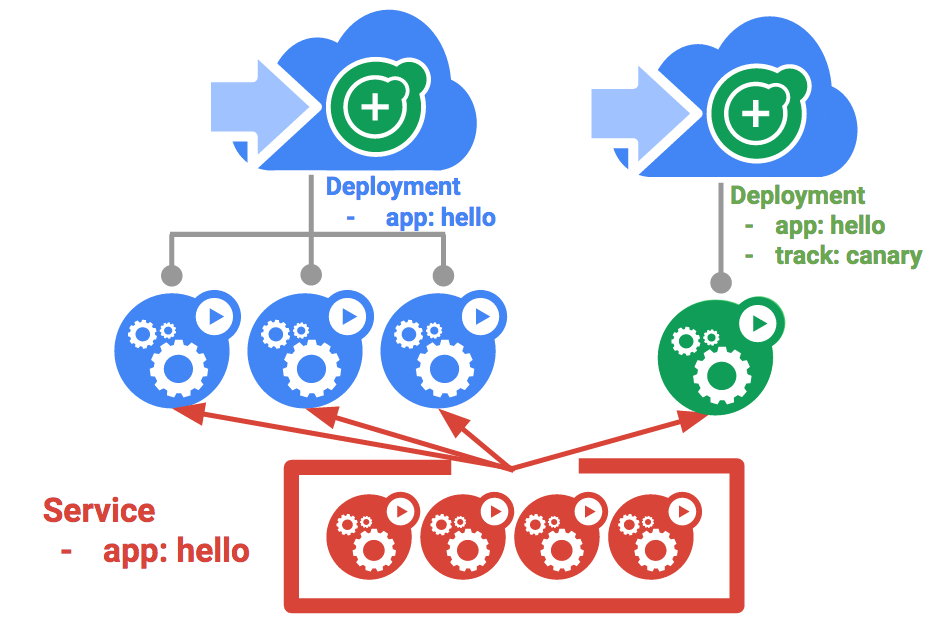
- Commencez par créer un déploiement Canary pour la nouvelle version :
Résultat :
- À présent, créez le déploiement Canary :
- Vous devriez ensuite avoir un déploiement
helloet un déploiementhello-canary. Vérifiez-le avec cette commandekubectl:
Sur le service hello, le sélecteur app:hello se rapporte à la fois aux pods du déploiement de production et du déploiement Canary. Cependant, le déploiement Canary étant associé à un nombre inférieur de pods, il ne sera visible que pour quelques utilisateurs.
Vérifier le déploiement Canary
- Pour savoir quelle version de
helloest diffusée par la requête, exécutez cette commande :
- Si vous exécutez cette commande plusieurs fois, vous verrez que certaines requêtes sont diffusées par hello 1.0.0 et qu'un sous-ensemble d'entre elles (1/4 = 25 %) est diffusé par la version 2.0.0.
Tester la tâche terminée
Cliquez sur Vérifier ma progression ci-dessous pour valider votre progression dans l'atelier. Si le déploiement Canary a correctement été créé, vous recevrez une note d'évaluation.
Déploiements Canary en production – Affinité de session
Au cours de cet atelier, chaque requête envoyée au service Nginx pouvait être diffusée par le déploiement Canary. Cependant, comment faire pour s'assurer qu'un utilisateur ne soit pas affecté par le déploiement Canary ? Cela peut s'avérer utile, par exemple, si vous souhaitez éviter qu'une modification apportée à l'UI d'une application vienne perturber l'utilisateur. Il s'agit alors de maintenir l'association entre l'utilisateur et l'un ou l'autre des déploiements concernés.
Vous pouvez y parvenir en créant un service avec affinité de session, de sorte que la même version soit toujours déployée pour le même utilisateur. Dans l'exemple ci-dessous, le service est le même que précédemment, à l'exception du champ sessionAffinity qui a été ajouté et défini sur la valeur ClientIP. Ainsi, les requêtes associées à une même adresse IP de client seront toujours envoyées à la même version de l'application hello.
Il aurait été difficile de configurer un environnement permettant de tester cette méthode. Vous n'aurez donc pas à le faire ici. Notez toutefois que vous pouvez utiliser le champ sessionAffinity pour les déploiements Canary en production.
Tâche 5 : Effectuer un déploiement bleu-vert
Les mises à jour progressives sont idéales si vous souhaitez déployer une application en douceur, en limitant au minimum les frais, l'impact sur les performances et les interruptions. Or, il peut parfois s'avérer judicieux de modifier les équilibreurs de charge de sorte qu'ils pointent vers la nouvelle version, mais après son déploiement complet. Si tel est votre cas, optez pour un déploiement bleu-vert.
Pour y parvenir, Kubernetes crée deux déploiements distincts : un "bleu" pour l'ancienne version et un "vert" pour la nouvelle. Votre déploiement hello actuel sera la version "bleue". L'accès aux déploiements se fera à l'aide d'un service agissant comme un routeur. Une fois que la nouvelle version "verte" sera opérationnelle, vous généraliserez son utilisation en mettant à jour le service.
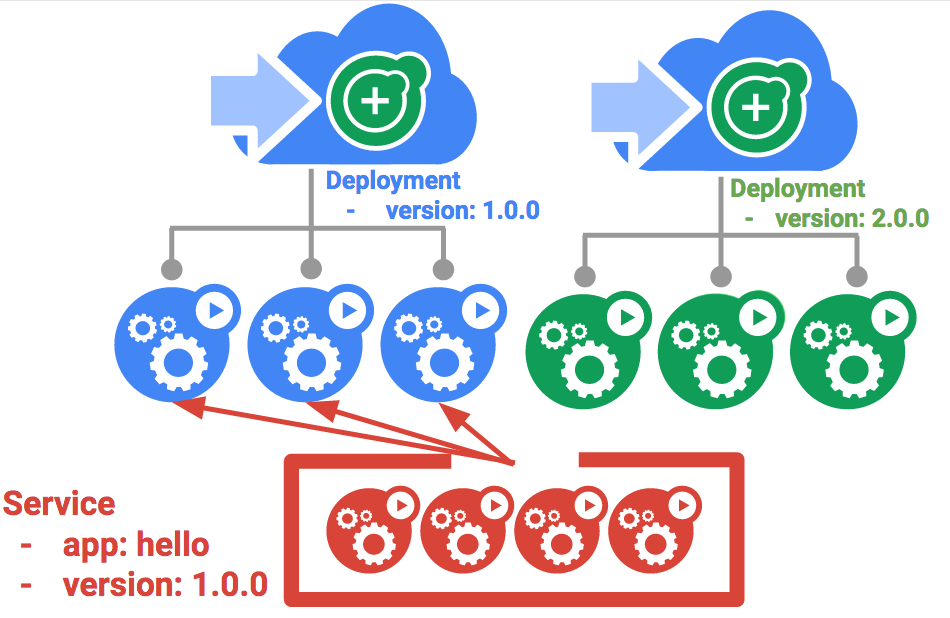
Le service
Utilisez le service hello existant, mais modifiez son sélecteur comme suit : app:hello, version: 1.0.0. Ainsi, le sélecteur désignera le déploiement "bleu", mais pas le déploiement "vert" qui est associé à une autre version.
- Commencez par mettre à jour le service :
resource service/hello is missing), car la correction est automatique.Effectuer une mise à jour par déploiement bleu-vert
Afin de procéder à un déploiement bleu-vert, vous allez créer un déploiement vert pour la nouvelle version. Le déploiement vert met à jour l'étiquette de la version et le chemin d'accès de l'image.
- Créez le déploiement vert :
- Une fois que votre déploiement vert a démarré correctement, vérifiez que la version 1.0.0 actuelle est toujours utilisée :
- À présent, mettez à jour le service de sorte qu'il pointe vers la nouvelle version :
- Une fois le service mis à jour, le déploiement vert est utilisé immédiatement. Vous pouvez maintenant vérifier que la nouvelle version est utilisée systématiquement :
Effectuer un rollback bleu-vert
Si nécessaire, vous pouvez effectuer un rollback vers l'ancienne version de la même manière.
- Pendant l'exécution du déploiement bleu, il vous suffit de mettre à jour le service pour qu'il revienne à l'ancienne version :
- Le rollback est effectué une fois le service mis à jour. Comme tout à l'heure, vérifiez que la bonne version est en cours d'utilisation :
Bravo ! Vous avez découvert les déploiements bleu-vert et appris à déployer des mises à jour d'applications nécessitant un basculement immédiat entre deux versions.
Félicitations !
Vous avez eu l'occasion de pratiquer davantage l'outil de ligne de commande kubectl et différents types de configurations de déploiement par fichiers YAML pour assurer le lancement, la mise à jour et le scaling de vos déploiements. Ces exercices fondamentaux vous permettront de mettre en pratique vos compétences dans vos propres activités DevOps.
Étapes suivantes et informations supplémentaires
-
Solutions et guides DevOps dans la documentation de Google Cloud
-
Sur le site Web Kubernetes, rejoignez la communauté Kubernetes.
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 2 avril 2024
Dernier test de l'atelier : 14 août 2023
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.