Контрольні точки
Create a Dataproc cluster
/ 50
Submit a job
/ 30
Update a cluster
/ 20
Dataproc: Qwik Start – консоль
GSP103

Огляд
Dataproc – це швидкий, зручний і простий у керуванні хмарний сервіс для запуску кластерів Apache Spark та Apache Hadoop без зайвих клопотів і витрат. Дії, що раніше тривали кілька годин або днів, тепер можна виконати за лічені хвилини чи навіть секунди. Завдяки цьому сервісу можна швидко створювати кластери Dataproc і будь-коли змінювати їх розмір відповідно до розміру конвеєрів для обробки даних.
Під час цієї практичної роботи ви навчитеся створювати кластер Dataproc, виконувати в ньому просте завдання Apache Spark і змінювати кількість робочих вузлів за допомогою Google Cloud Console.
Завдання
Під час цієї практичної роботи ви навчитеся виконувати наведені нижче дії.
- Створювати кластер Dataproc у Google Cloud Console
- Виконувати просте завдання Apache Spark
- Змінювати кількість робочих вузлів у кластері
Налаштування й вимоги
Перш ніж натиснути кнопку Start Lab (Почати практичну роботу)
Ознайомтеся з наведеними нижче вказівками. На виконання практичної роботи відводиться обмежений час, і її не можна призупинити. Щойно ви натиснете Start Lab (Почати практичну роботу), з’явиться таймер, який показуватиме, скільки часу для роботи з ресурсами Google Cloud у вас залишилося.
Ви зможете виконати практичну роботу в дійсному робочому хмарному середовищі (не в симуляції або демонстраційному середовищі). Для цього на час виконання практичної роботи вам надаються тимчасові облікові дані для реєстрації і входу в Google Cloud.
Щоб виконати цю практичну роботу, потрібно мати:
- стандартний веб-переглядач, наприклад Chrome (рекомендовано)
- достатню кількість часу, оскільки почавши практичну роботу, ви не зможете призупинити її
Як почати виконувати практичну роботу й увійти в Google Cloud Console
-
Натисніть кнопку Start Lab (Почати практичну роботу). Якщо за практичну роботу необхідно заплатити, відкриється спливаюче вікно, де ви зможете обрати спосіб оплати. Ліворуч розміщено панель Lab Details (Відомості про практичну роботу) з такими даними:
- кнопка Open Google Console (Відкрити Google Console);
- час до закінчення;
- тимчасові облікові дані, які потрібно використовувати для доступу до цієї практичної роботи;
- інша необхідна для виконання цієї практичної роботи інформація.
-
Натисніть Open Google Console (Відкрити Google Console). Завантажаться необхідні ресурси. Потім відкриється нова вкладка зі сторінкою Sign in (Вхід).
Порада. Упорядковуйте вкладки в окремих вікнах, розміщуючи їх поруч.
Примітка. Якщо з’явиться вікно Choose an account (Виберіть обліковий запис), натисніть Use Another Account (Увійти в інший обліковий запис). -
За потреби скопіюйте Username (Ім’я користувача) з панелі Lab Details (Відомості про практичну роботу) і вставте його у вікні Sign in (Вхід). Натисніть Next (Далі).
-
Скопіюйте Password (Пароль) з панелі Lab Details (Відомості про практичну роботу) і вставте його у вікні Welcome (Привітання). Натисніть Next (Далі).
Важливо. Обов’язково використовуйте облікові дані з панелі ліворуч. Не використовуйте облікові дані Google Cloud Skills Boost. Примітка. Якщо ввійти у власний обліковий запис Google Cloud, може стягуватися додаткова плата. -
Виконайте наведені нижче дії.
- Прийміть Умови використання.
- Не додавайте способи відновлення та двохетапну перевірку (оскільки це тимчасовий обліковий запис).
- Не реєструйте безкоштовні пробні версії.
Через кілька секунд Cloud Console відкриється в новій вкладці.

Переконайтеся, що Cloud Dataproc API увімкнено
Щоб створити кластер Dataproc у Google Cloud, слід увімкнути Cloud Dataproc API. Переконайтеся, що API увімкнено.
-
Натисніть меню навігації > APIs & Services (API і сервіси) > Library (Бібліотека):
-
Введіть Cloud Dataproc у вікні Search for APIs & Services (Пошук API і сервісів). У результатах пошуку на консолі з’явиться Cloud Dataproc API.
-
Натисніть Cloud Dataproc API, щоб переглянути статус API. Якщо API не ввімкнено, натисніть кнопку Enable (Увімкнути).
Увімкнувши API, дотримуйтеся вказівок щодо виконання практичної роботи.
Надайте сервісному обліковому запису необхідні дозволи
Щоб створити кластер, потрібно надати сервісному обліковому запису дозвіл на доступ до сховища.
-
Відкрийте меню навігації > IAM & Admin (Адміністрування й керування ідентифікацією і доступом) > IAM.
-
Натисніть значок олівця біля сервісного облікового запису
compute@developer.gserviceaccount.com. -
Натисніть кнопку + ADD ANOTHER ROLE (+ ДОДАТИ ІНШУ РОЛЬ) і виберіть роль Storage Admin (Адміністратор сховища)
Вибравши потрібну роль, натисніть Save (Зберегти)
Завдання 1. Створіть кластер
-
У меню навігації консолі Cloud Platform виберіть Dataproc > Clusters (Кластери), а потім натисніть Create cluster (Створити кластер).
-
Натисніть Create (Створити) біля Cluster on Compute Engine (Кластер у Compute Engine).
-
Налаштуйте наведені нижче поля кластера, а в решті полів підтвердьте значення за умовчанням.
| Поле | Значення |
|---|---|
| Name (Назва) | example-cluster |
| Region (Регіон) | |
| Zone (Зона) | |
| Machine Series (Серія машини) | E2 |
| Machine Type (Тип машини) | e2-standard-2 |
| Number of Worker Nodes (Кількість робочих вузлів) | 2 |
| Primary disk size (Розмір основного диска) | 30 ГБ |
| Internal IP only (Лише внутрішні IP-адреси) | Зніміть прапорець Configure all instances to have only internal IP addresses (Налаштувати для всіх екземплярів лише внутрішні IP-адреси) |
us-central1 або europe-west1, щоб ізолювати ресурси (зокрема екземпляри віртуальних машин та Cloud Storage) і місця збереження метаданих, що використовуються в Cloud Dataproc, у межах указаного користувачем регіону.
- Щоб створити кластер, натисніть Create (Створити).
Новий кластер з’явиться в списку Clusters (Кластери) через кілька хвилин. Спочатку він матиме статус Provisioning (Надання доступу), а коли буде готовий до використання – статус Running (Активний).
Перевірка виконаного завдання
Щоб підтвердити виконання завдання, натисніть Підтвердити виконання.
Завдання 2. Надішліть завдання
Щоб запустити просте завдання Spark, виконайте наведені нижче дії.
-
На панелі ліворуч натисніть Jobs (Завдання), щоб перейти до перегляду завдань Dataproc, а потім натисніть Submit job (Надіслати завдання).
-
Налаштуйте наведені нижче поля, щоб оновити завдання, а в решті полів підтвердьте значення за умовчанням.
| Поле | Значення |
|---|---|
| Region (Регіон) | |
| Cluster (Кластер) | example-cluster |
| Вид завдання | Spark |
| Main class or jar (Основний клас або файл JAR) | org.apache.spark.examples.SparkPi |
| Файли JAR | file:///usr/lib/spark/examples/jars/spark-examples.jar |
| Аргументи | 1000 (це показник кількості завдань) |
- Натисніть Submit (Надіслати).
Завдання має з’явитися в списку на сторінці Jobs (Завдання), де відображається інформація про завдання вашого проекту, зокрема про відповідний кластер, тип і поточний статус завдання. Спочатку завдання матиме статус Running (Активне), а після виконання – Succeeded (Виконано).
Перевірка виконаного завдання
Щоб підтвердити виконання завдання, натисніть Підтвердити виконання.
Завдання 3. Перегляньте вивід завдання
Щоб переглянути вивід завдання, виконайте наведені нижче дії.
-
Натисніть ідентифікатор завдання в списку Jobs (Завдання).
-
Щоб переглянути значення числа пі, увімкніть опцію LINE WRAP (ПЕРЕНЕСЕННЯ РЯДКА) (значення
ON) або прокрутіть сторінку до кінця праворуч. Після цього вивід виглядатиме десь так:
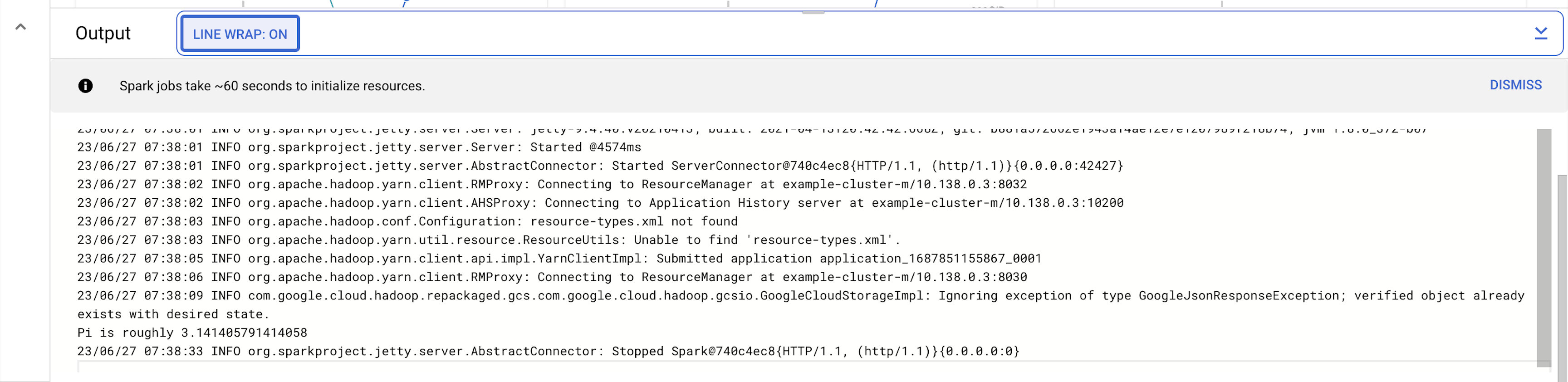
Приблизне значення числа пі отримано.
Завдання 4. Змініть кількість робочих вузлів у кластері
Щоб змінити кількість робочих екземплярів у кластері, виконайте наведені нижче дії.
-
Виберіть Clusters (Кластери) на панелі навігації ліворуч, щоб повернутися до перегляду кластерів Dataproc.
-
У списку Clusters (Кластери) натисніть example-cluster. За умовчанням на сторінці відображається показник використання ЦП кластером.
-
Щоб переглянути поточні налаштування кластера, натисніть Configuration (Конфігурація).
-
Натисніть Edit (Редагувати). Тепер можна змінювати кількість робочих вузлів.
-
Введіть 4 в полі Worker nodes (Робочі вузли).
-
Натисніть Зберегти.
Кластер оновлено. Перевірте кількість екземплярів віртуальної машини в кластері.
Перевірка виконаного завдання
Щоб підтвердити виконання завдання, натисніть Підтвердити виконання.
-
Щоб повторно виконати завдання з оновленим кластером, потрібно натиснути Jobs (Завдання) на панелі ліворуч, а потім – SUBMIT JOB (НАДІСЛАТИ ЗАВДАННЯ).
-
Налаштуйте ті самі поля, що й у розділі Submit a job (Надіслати завдання):
| Поле | Значення |
|---|---|
| Region (Регіон) | |
| Cluster (Кластер) | example-cluster |
| Вид завдання | Spark |
| Main class or jar (Основний клас або файл JAR) | org.apache.spark.examples.SparkPi |
| Файли JAR | file:///usr/lib/spark/examples/jars/spark-examples.jar |
| Аргументи | 1000 (це показник кількості завдань) |
- Натисніть Submit (Надіслати).
Завдання 5. Перевірте свої знання
Дайте відповіді на запитання з кількома варіантами відповіді нижче, щоб закріпити розуміння понять, які зустрічаються в практичній роботі.
Вітаємо!
Тепер ви знаєте, як створити й оновити кластер Dataproc, а також надіслати в ньому завдання за допомогою Google Cloud Console.
Наступні кроки/Докладніше
Це завдання також входить до низки практичних робіт під назвою Qwik Starts. Вони призначені для ознайомлення з функціями Google Cloud. Такі практичні роботи можна знайти в каталозі за запитом "Qwik Starts".
Навчання й сертифікація Google Cloud
…допомагають ефективно використовувати технології Google Cloud. Наші курси передбачають опанування технічних навичок, а також ознайомлення з рекомендаціями, що допоможуть вам швидко зорієнтуватися й вивчити матеріал. Ми пропонуємо курси різних рівнів – від базового до високого. Ви можете вибрати формат навчання (за запитом, онлайн або офлайн) відповідно до власного розкладу. Пройшовши сертифікацію, ви перевірите й підтвердите свої навички та досвід роботи з технологіями Google Cloud.
Посібник востаннє оновлено 21 березня 2024 року
Практичну роботу востаннє протестовано 21 березня 2024 року
© Google LLC 2024. Усі права захищено. Назва та логотип Google є торговельними марками Google LLC. Усі інші назви компаній і продуктів можуть бути торговельними марками відповідних компаній, з якими вони пов’язані.