

![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Setup the data environment
/ 15
Run your pipeline from the command line
/ 10
Create a custom Dataflow Flex Template container image
/ 15
Create and stage the flex template
/ 10
Execute the template from the UI and using gcloud
/ 20
このラボの内容:
<Row> オブジェクトとして処理する前提条件:
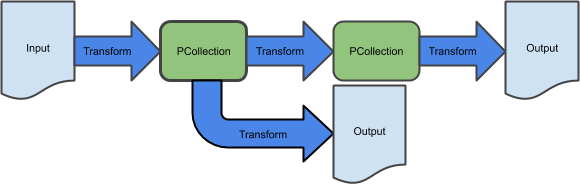
前のラボでは、基本的な抽出、変換、読み込みパイプラインを作成し、対応する Dataflow テンプレートを使用して Google Cloud Storage のバッチ データ ストレージを取り込みました。このパイプラインは、次の変換シーケンスで構成されています。
ところが、多くのパイプラインはこのような単純な構造ではありません。このラボでは、より高度な連続しないパイプラインを構築します。
今回のユースケースはリソース消費量の最適化です。プロダクトはリソースの利用状況によって変わります。また、ビジネスにおいてすべてのデータが同じように使われるわけではありません。分析ワークロードなどで定期的にクエリされるデータもあれば、復元にのみ使用されるデータもあります。このラボでは、最初のラボで作成したパイプラインのリソース消費量を最適化するために、アナリストが使用するデータのみを BigQuery に保存して、他のデータは低コストで耐久性の高いストレージ サービスである Google Cloud Storage の Coldline Storage にアーカイブします。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
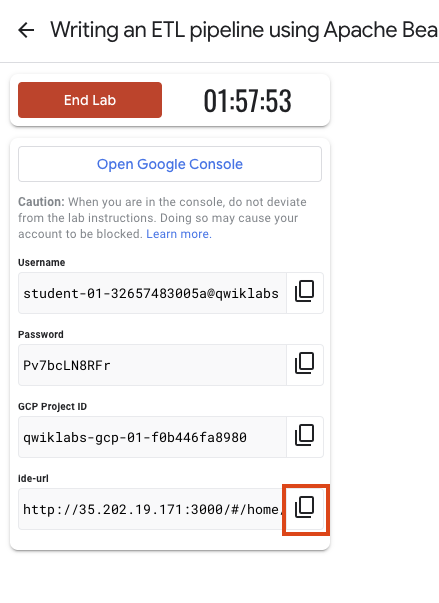
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力例:
出力:
出力例:
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
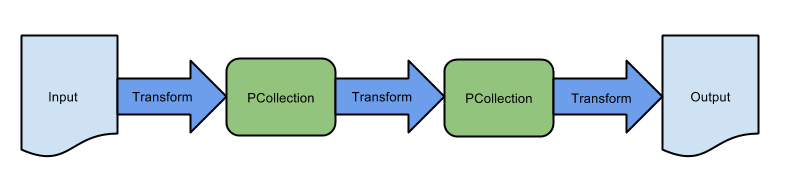
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。729328892908)をコピーします。{project-number} はプロジェクト番号に置き換えてください。このラボでは、Google Compute Engine でホストされる Theia Web IDE を主に使用します。これには、事前にクローンが作成されたラボリポジトリが含まれます。Java 言語サーバーがサポートされているとともに、Cloud Shell に似た仕組みで、gcloud コマンドライン ツールを通じて Google Cloud API へのプログラムによるアクセスが可能なターミナルも使用できます。
Theia IDE にアクセスするには、Qwiklabs に表示されたリンクをコピーして新しいタブに貼り付けます。
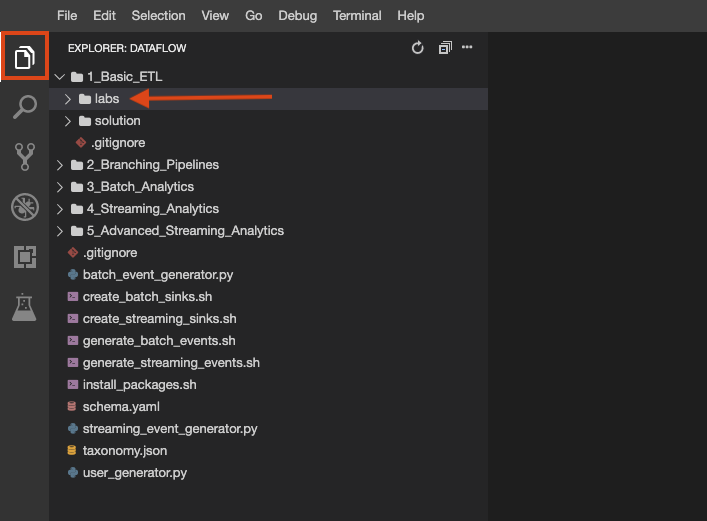
ラボリポジトリのクローンが環境に作成されました。各ラボは、完成させるコードが格納される labs フォルダと、ヒントが必要な場合に完全に機能するサンプルを参照できる solution フォルダに分けられています。ファイル エクスプローラ ボタンをクリックして確認します。
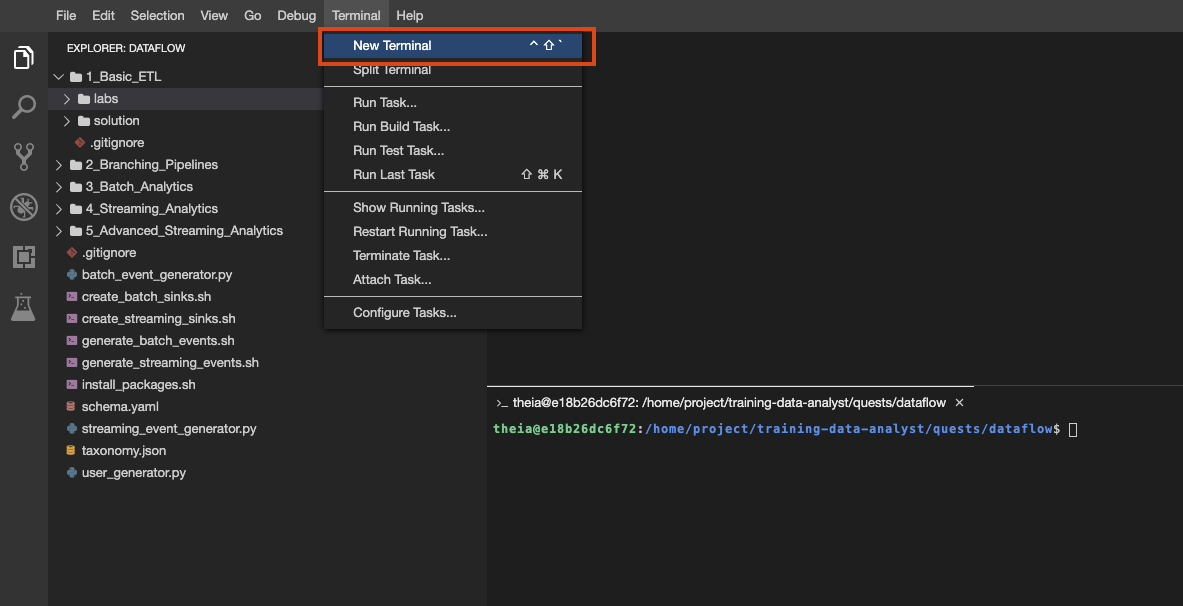
Cloud Shell で行うように、この環境で複数のターミナルを作成することも可能です。
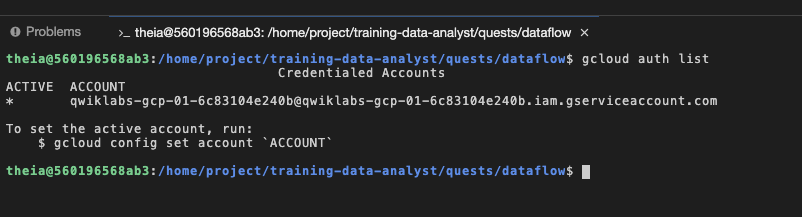
提供されたサービス アカウント(ラボのユーザー アカウントとまったく同じ権限がある)でログインしたターミナルで gcloud auth list を実行すれば、以下を確認できます。
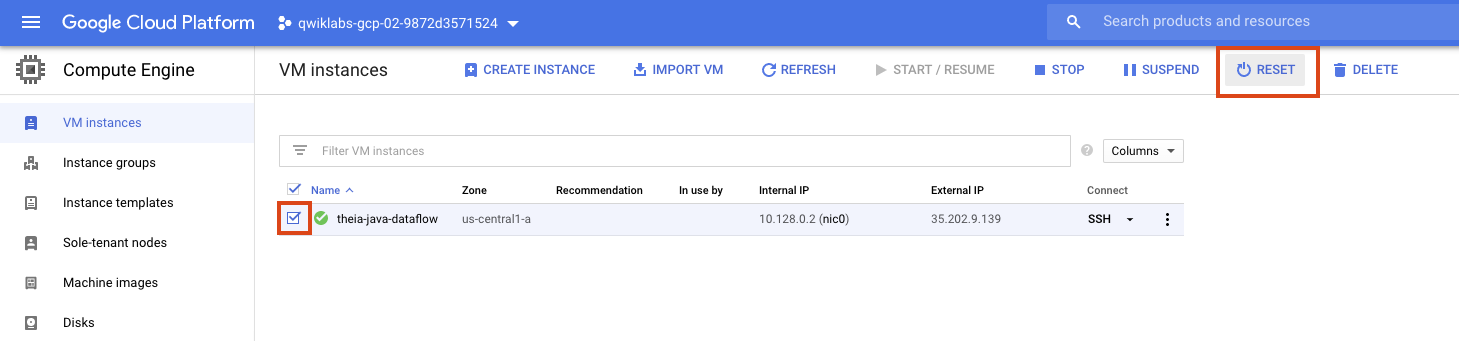
環境が機能しなくなった場合は、IDE をホストしている VM を GCE コンソールから次のようにリセットしてみてください。
ここでは、Google Cloud Storage と BigQuery の両方にデータを書き込む、分岐するパイプラインを作成します。
分岐するパイプラインを作成する方法の一つは、2 つの異なる変換を同じ PCollection に適用することにより、2 つの異なる PCollection を作成することです。
このセクションや後のセクションでヒントが必要な場合は、こちらのソリューションをご利用ください。
このタスクを完了するには、Cloud Storage への書き込みを行うブランチを追加して既存のパイプラインを変更します。
IDE 環境に新しいターミナルをまだ作成していない場合は作成し、次のコマンドをコピーして貼り付けます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
IDE で 2_Branching_Pipelines/labs/src/main/java/com/mypackage/pipeline にある MyPipeline.java を開きます。パイプラインの本体が定義されている run() メソッドまで下にスクロールします。現在は次のような内容です。
各要素が JSON から <CommonLog> に変換される前に、TextIO.write() を使用して Cloud Storage への書き込みを行う新しい分岐変換を追加することで、このコードを変更します
このセクションや後のセクションでヒントが必要な場合は、こちらにあるソリューションをご覧ください。
現状ではすべてのデータが 2 回保存されるため、新しいパイプラインでもリソースの消費量は減りません。リソースの消費量を改善するには、重複するデータの量を減らす必要があります。Google Cloud Storage バケットの目的はアーカイブおよびバックアップ ストレージとして機能することなので、すべてのデータをそこに保存する必要があります。ただし、必ずしもすべてのデータを BigQuery に送信する必要はありません。
たとえば、データ アナリストが頻繁に確認する対象が、ウェブサイトでユーザーがアクセスするリソースや、地域と時間に応じたアクセス パターンの違いである場合、必要なフィールドはごく一部です。
各オブジェクトを変換して一部のフィールドのみを返す DoFn を作成することもできますが、Apache Beam にはスキーマを含む PCollection 用にさまざまなリレーショナル変換が用意されています。各レコードは名前付きフィールドで構成されているので、SQL 式での集計と同様に、フィールドを名前で参照するシンプルでわかりやすい集計が可能になります。
Select および DropFields 変換はこのうちの 2 つです。
注: これらの各例は、PCollection<MyClass> ではなく PCollection<Row> を返します。Row クラスはあらゆるスキーマに対応できる、汎用スキーマ化されたオブジェクトと考えることができます。スキーマを含む PCollection を行の PCollection にキャストできます。上の 2 つの変換はフィールドを削除するため、どちらも完全な CommonLog オブジェクトを返しません。その結果、Row を返す変換に戻ります。新しい名前付きスキーマを作成するか、中間の POJO スキーマを登録することもできますが、当面は Row を使用する方が簡単です。
このタスクを完了するには、次の import を追加して BigQuery に保存される一連のフィールドを変更し、いずれかの変換をパイプラインに追加することでアナリストが使用するフィールドのみが送信されるようにします。
注: すでにメソッド チェーンで BigQueryIO.<CommonLog>write() メソッドを追加している場合は、新しいタイプなので <Row> に変更する必要があります。
Apache Beam にはフィルタリングの方法が数多くあります。前のタスクでスキーマ変換を使用した方法を説明しました。この実装では、各要素の一部を除外した結果、スキーマと残りのフィールドのサブセットを含む新しい Row オブジェクトが返されました。以下の例のように、簡単にすべての要素を除外できます。
このタスクを完了するには、まず次の import ステートメントをコードに追加してから、Filter 変換をパイプラインに追加します。あらゆる条件でフィルタできます。lambda 関数への型ヒントの追加が必要になる場合があります(例: (Integer c) -> c > 100)。
パイプラインには現在、BigQuery テーブルの入力と場所へのパスなど、多くのパラメータがハードコードされていますが、パイプラインで Cloud Storage の JSON ファイルを読み取ることができれば、さらに便利になります。この機能を追加するには、一連のコマンドライン パラメータに追加する必要があります。
現在パイプラインでは PipelineOptionsFactory を使用して Options というカスタムクラスのインスタンスが生成されていますが、このクラスは PipelineOptions クラスと何も変わらないので、実質的には PipelineOptions のインスタンスです。
PipelineOptions クラスは、次の形式のコマンドライン引数を処理します。
ただし、ごく一部の定義済みパラメータに限られる場合があります。get- 関数はこちらで確認できます。カスタム パラメータを追加するには、2 つの手順を行います。まずは、以下の例のように状態変数を Options クラスに追加します。
2 つ目の手順として、main() メソッド内に PipelineOptionsFactory でインターフェースを登録し、PipelineOptions オブジェクトの作成時にインターフェースを渡します。PipelineOptionsFactory でインターフェースを登録する場合、--help でカスタム オプション インターフェースを検索し、--help コマンドの出力に追加できます。PipelineOptionsFactory は、カスタム オプションが他のすべての登録済みオプションと互換であることも検証します。
次のコード例は、PipelineOptionsFactory でカスタム オプション インターフェースを登録する方法を示しています。
コード内のコマンドライン パラメータには、パラメータの get 関数を呼び出すだけでアクセスできます。
このタスクを完了するには、まず次の import ステートメントを追加してから、入力パス、Google Cloud Storage 出力パス、BigQuery テーブル名のコマンドライン パラメータを追加し、定数ではなくこれらのパラメータにアクセスするようにパイプライン コードを更新します。
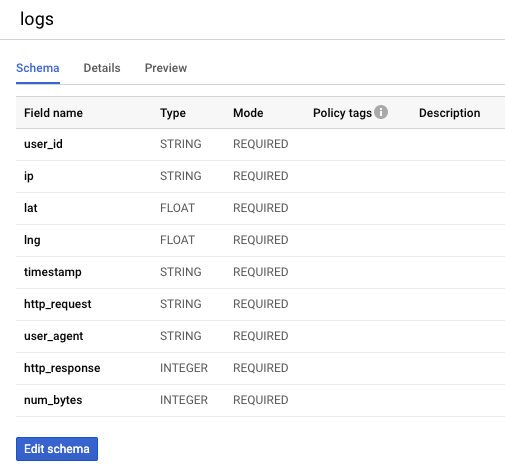
すでにお気づきかもしれませんが、前回のラボで作成した BigQuery テーブルに、すべてのフィールドが REQUIRED に設定された次のようなスキーマがありました。
パイプラインの実行自体とこれを反映するスキーマで構成される BigQuery テーブルの両方に対して、データがない NULLABLE フィールドを持つ Apache Beam スキーマを作成することをおすすめします。
Javax 表記をクラス定義に追加できます。これは次のように Apache Beam スキーマに組み込まれます。
このタスクを完了するには、クラス定義で lat および lon フィールドを null 可能としてマークします。
このタスクを完了するには、コマンドラインでパイプラインを実行して適切なパラメータを渡します。生成される BigQuery スキーマの NULLABLE フィールドを忘れずにメモしておいてください。コードは次のようになります。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
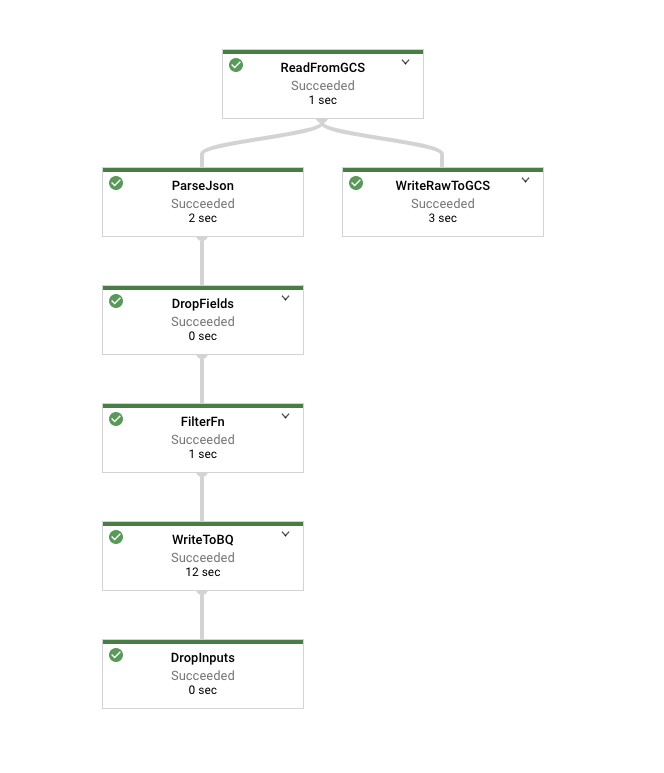
Cloud Dataflow の [ジョブ] ページに移動して、実行中のジョブを確認します。次のようなグラフが表示されます。
Filter 関数を表すノード(上の図では FilterFn)をクリックします。右側に表示されたパネルで、出力として書き込まれた要素よりも入力として追加された要素が多いことを確認します。
次は Cloud Storage への書き込みを表すノードをクリックします。すべての要素が書き込まれているので、この数字は Filter 関数への入力にある要素の数と一致する必要があります。
パイプラインが終了したら、テーブルに対してクエリを実行して BigQuery の結果を確認します。テーブル内のレコード数が Filter 関数で出力された要素の数と一致する必要があります。
コマンドライン パラメータを受け入れるパイプラインは、ハードコードされたパラメータを使うパイプラインよりもはるかに便利ですが、そのようなパイプラインを実行するには、開発環境を作成する必要があります。さまざまなユーザーによる再実行や、さまざまな状況での再実行が想定されるパイプラインには、Dataflow テンプレートを使う方が適しています。
Google Cloud Platform には多数の Dataflow テンプレートがすでに作成されており、こちらで確認できます。その中にこのラボのパイプラインと同じ動作をするテンプレートはありませんが、このパートでパイプラインを(従来のカスタム テンプレートではなく)新しいカスタム Dataflow Flex テンプレートに変換できます。
パイプラインをカスタム Dataflow Flex テンプレートに変換するには、コードだけでなく依存関係もパッケージ化する Uber JAR、ビルド対象のコードを記述する Dockerfile、実際のジョブを作成するためにランタイムで実行される基盤コンテナをビルドする Cloud Build、ジョブ パラメータを記述するメタデータ ファイルを使用する必要があります。
このタスクを完了するには、最初に次のプラグインを pom.xml ファイルに追加して、Uber JAR をビルドできるようにします。まず、プロパティタグに以下を追加します。
次に、ビルド プラグイン タグに以下を追加します。
これで、次のコマンドを使用して Uber JAR ファイルをビルドできます。
サイズに注意してください。この Uber JAR ファイルにはすべての依存関係が含まれます。このファイルは、他のライブラリで外部依存関係のないスタンドアロン アプリケーションとして実行できます。
pom.xml と同じディレクトリに、次のテキストを含む Dockerfile というファイルを作成します。FLEX_TEMPLATE_JAVA_MAIN_CLASS には完全なクラス名、YOUR_JAR_HERE には作成した Uber JAR を設定してください。
次は、このコンテナをビルドしますが、ローカルでビルドするのではなく、Cloud Build を使用してビルドをオフロードします。まず、今後のビルド時間を短縮するためにキャッシュを有効にします。
次に、実際のビルドを実行します。これで、実際のビルド内容についての指示が記述された Dockerfile を含むディレクトリ全体が 1 つにまとめられてサービスにアップロードされます。さらに、コンテナがビルドされてプロジェクトの Google Container Registry に push され、今後使用できるようになります。
Cloud Build UI でビルドのステータスをモニタリングすることもできます。また、ビルドされたコンテナが Google Container Registry にアップロードされたことも確認できます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
テンプレートを実行するには、SDK 情報やメタデータなど、ジョブの実行に必要なすべての情報を含むテンプレート仕様ファイルを Cloud Storage に作成する必要があります。
このタスクを完了するには、パイプラインで予期されるすべての入力パラメータを考慮した次の形式で、metadata.json ファイルを作成します。必要な場合は、こちらでソリューションを参照してください。独自の正規表現チェックを記述する必要があります。おすすめの方法ではありませんが、".*" はあらゆる入力に一致します。
次に、実際のテンプレートをビルドしてステージングします。
ファイルが Cloud Storage のテンプレート用の場所にアップロードされていることを確認します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクを完了するには、以下の手順に沿って操作します。
Compute Engine コンソールを確認すると、コンテナを実行して指定のパラメータでパイプラインを開始するために一時的なランチャー VM が作成されているのがわかります。
Dataflow テンプレートを使用する利点の一つは、開発環境以外のさまざまな場面で実行できることです。それを確認するために、gcloud を使用してコマンドラインで Dataflow テンプレートを実行します。
このタスクを完了するには、以下のコマンドを、適宜パラメータを変更してターミナルで実行します。
パイプラインが正常に完了することを確認します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2020 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください