Agregar parámetros de línea de comandos personalizados a una canalización
Convertir una canalización personalizada en una plantilla personalizada de Flex de Dataflow
Ejecutar una plantilla de Flex de Dataflow
Requisitos previos:
Conocimientos básicos de Java
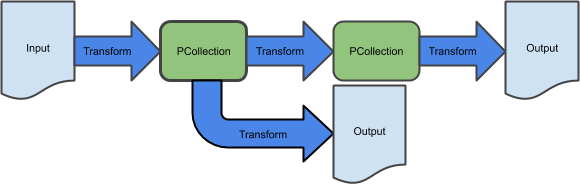
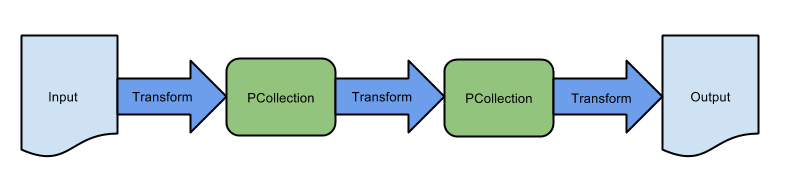
En el lab anterior, creaste una canalización secuencial de extracción, transformación y carga básica, y utilizaste una plantilla de Dataflow equivalente para transferir el almacenamiento de datos por lotes en Google Cloud Storage. Esta canalización consta de una secuencia de transformaciones:
Sin embargo, muchas canalizaciones no mostrarán una estructura tan simple. En este lab, crearás una canalización no secuencial más sofisticada.
El caso de uso aquí es optimizar el consumo de recursos. Los productos varían según la forma en que consumen los recursos. Además, no todos los datos se utilizan de la misma manera dentro de una empresa. Algunos datos se consultarán con regularidad (por ejemplo, dentro de cargas de trabajo analíticas) y, otros, solo se usarán para la recuperación. En este lab, optimizarás la canalización del primer lab en pos del consumo de recursos. Para ello, almacenarás solo los datos que los analistas usarán en BigQuery y archivarás los demás datos en un servicio de almacenamiento muy duradero y de bajo costo, Coldline Storage en Google Cloud Storage.
Configuración y requisitos
Configuración de Qwiklabs
En cada lab, recibirá un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Qwiklabs desde una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesita, puede reiniciar el lab, pero deberá hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
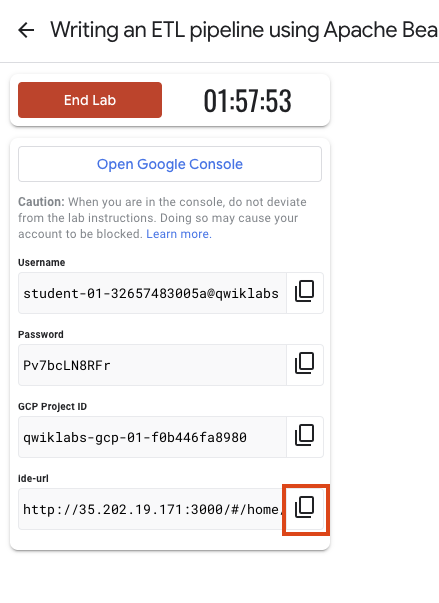
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usa otras credenciales, se generarán errores o incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Activa Google Cloud Shell
Google Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud.
Google Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
En la consola de Cloud, en la barra de herramientas superior derecha, haz clic en el botón Abrir Cloud Shell.
Haz clic en Continuar.
El aprovisionamiento y la conexión al entorno demorarán unos minutos. Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu PROJECT_ID. Por ejemplo:
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con el completado de línea de comando.
Puedes solicitar el nombre de la cuenta activa con este comando:
Antes de comenzar a trabajar en Google Cloud, asegúrate de que tu proyecto tenga los permisos correctos en Identity and Access Management (IAM).
En la consola de Google Cloud, en el Menú de navegación (), selecciona IAM y administración > IAM.
Confirma que aparezca la cuenta de servicio predeterminada de Compute {número-del-proyecto}-compute@developer.gserviceaccount.com, y que tenga asignado el rol Editor. El prefijo de la cuenta es el número del proyecto, que puedes encontrar en el Menú de navegación > Descripción general de Cloud > Panel.
Nota: Si la cuenta no aparece en IAM o no tiene asignado el rol Editor, sigue los pasos que se indican a continuación para asignar el rol necesario.
En la consola de Google Cloud, en el Menú de navegación, haz clic en Descripción general de Cloud > Panel.
Copia el número del proyecto (p. ej., 729328892908).
En el Menú de navegación, selecciona IAM y administración > IAM.
En la parte superior de la tabla de funciones, debajo de Ver por principales, haz clic en Otorgar acceso.
Reemplaza {número-del-proyecto} por el número de tu proyecto.
En Rol, selecciona Proyecto (o Básico) > Editor.
Haz clic en Guardar.
Configura tu IDE
Para los fines de este lab, usará principalmente un IDE web de Theia alojado en Google Compute Engine. El IDE tiene el repositorio de labs clonado previamente. Se ofrece compatibilidad con el servidor de lenguaje Java y una terminal para el acceso programático a las API de Google Cloud mediante la herramienta de línea de comandos de gcloud, similar a Cloud Shell.
Para acceder al IDE de Theia, copie y pegue en una pestaña nueva el vínculo que se muestra en Qwiklabs.
NOTA: Es posible que deba esperar entre 3 y 5 minutos para que se aprovisione por completo el entorno, incluso después de que aparezca la URL. Hasta ese momento, se mostrará un error en el navegador.
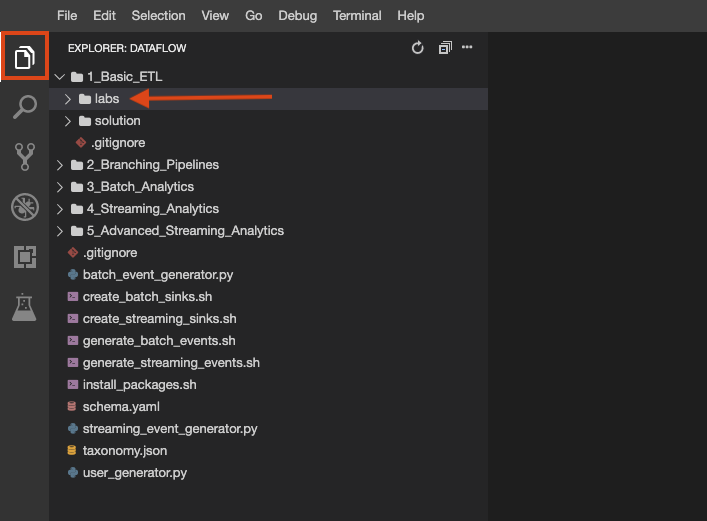
El repositorio del lab se clonó en su entorno. Cada lab se divide en una carpeta labs con un código que debe completar y una carpeta solution con un ejemplo viable que puede consultar como referencia si no sabe cómo continuar. Haga clic en el botón File Explorer para ver lo siguiente:
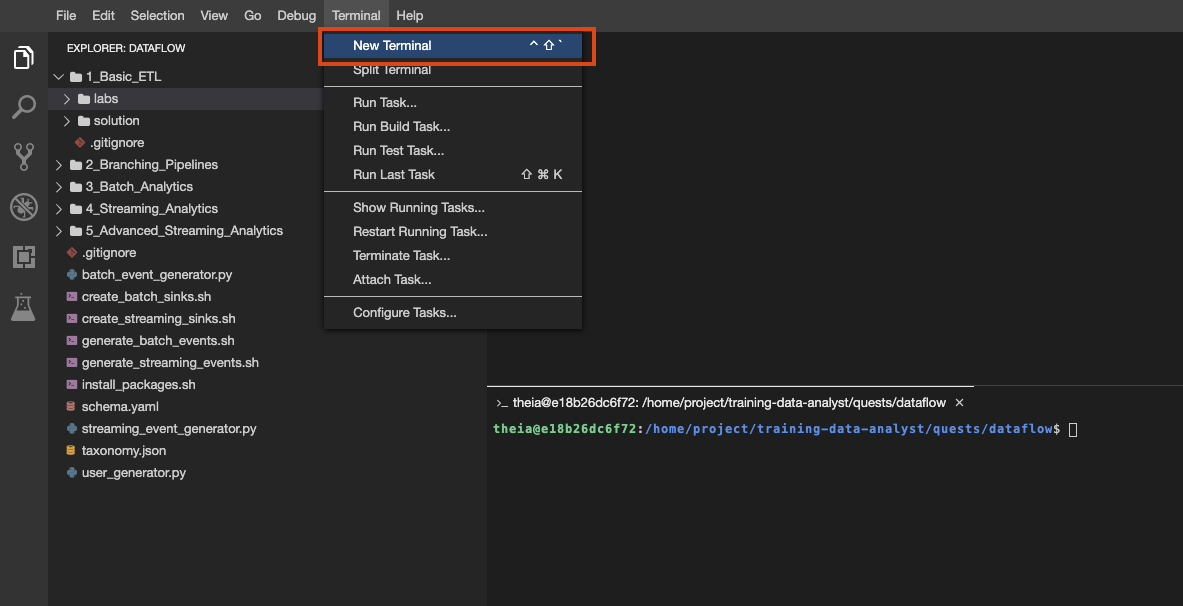
También puede crear varias terminales en este entorno, como lo haría con Cloud Shell:
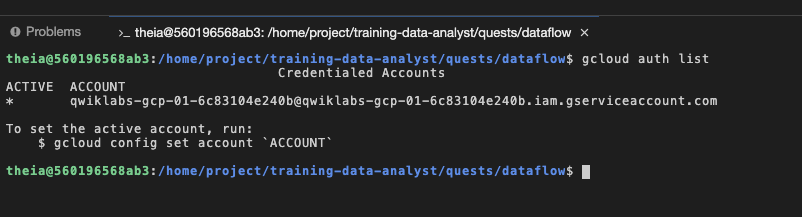
Para verificarlo, ejecute gcloud auth list en la terminal con la que accedió como cuenta de servicio proporcionada, que tiene exactamente los mismos permisos que su cuenta de usuario del lab:
Si en algún momento su entorno deja de funcionar, intente restablecer la VM en la que se aloja el IDE desde la consola de GCE de la siguiente manera:
Parte 1 del lab: Escribe canalizaciones con ramas
En esta parte del lab, escribirás una canalización con ramas que, a su vez, escribirá datos en Google Cloud Storage y en BigQuery.
Las transformaciones múltiples procesan la misma PCollection
Una forma de escribir una canalización con ramas es aplicar dos transformaciones diferentes a la misma PCollection, lo que da como resultado dos PCollections diferentes.
Si no puedes avanzar en esta sección o en secciones posteriores, la solución está disponible aquí.
Tarea 1: Agrega una rama para escribir en Cloud Storage
Para completar esta tarea, modifica una canalización existente agregando una rama que escriba en Cloud Storage.
Abre el lab adecuado
Si aún no lo has hecho, crea una terminal nueva en tu entorno de IDE y, luego, copia y pega el siguiente comando:
# Change directory into the lab
cd 2_Branching_Pipelines/labs
# Download dependencies
mvn clean dependency:resolve
export BASE_DIR=$(pwd)
Configura el entorno de datos
# Create GCS buckets and BQ dataset
cd $BASE_DIR/../..
source create_batch_sinks.sh
# Generate event dataflow
source generate_batch_events.sh
# Change to the directory containing the practice version of the code
cd $BASE_DIR
Haz clic en Revisar mi progreso para verificar el objetivo.
Configura el entorno de datos
Abre MyPipeline.java en su IDE, que puedes encontrar en 2_Branching_Pipelines/labs/src/main/java/com/mypackage/pipeline. Desplázate hacia abajo hasta el método run(), en el que se define el cuerpo de la canalización. Actualmente, se ve de la siguiente manera:
Modifica este código incorporando una transformación de ramificación nueva que escriba en Cloud Storage con TextIO.write() antes de que cada elemento se convierta de JSON a <CommonLog>.
Si no puedes avanzar en esta sección o en secciones posteriores, consulta la solución que está disponible aquí.
Primero, ¿por qué usar esquemas?
Los esquemas nos proporcionan un sistema de tipos para registros de Beam que es independiente de cualquier tipo de lenguaje de programación específico. Es posible que existan múltiples clases de Java con el mismo esquema (por ejemplo, una clase de búfer de protocolo o una clase POJO); Beam nos permitirá realizar conversiones sin problemas entre estos tipos. Los esquemas también proporcionan una manera sencilla de razonar sobre los tipos en diferentes API de lenguaje de programación.Una PCollection con un esquema no necesita tener un codificador especificado, ya que Beam sabe cómo codificar y decodificar filas de esquema. Beam utiliza un codificador especial para codificar tipos de esquema. Antes de la introducción de la API de Schema, Beam debía saber cómo codificar todos los objetos de la canalización.
Tarea 2: Filtra datos por campo
Por el momento, la canalización nueva no consume menos recursos, puesto que todos los datos se almacenan dos veces. Para comenzar a mejorar el consumo de recursos, debemos reducir la cantidad de datos duplicados. El bucket de Google Cloud Storage está diseñado para funcionar como almacenamiento de archivos y copias de seguridad, por lo que es importante que todos los datos se guarden allí. Sin embargo, no es necesario que todos los datos se envíen a BigQuery.
Supongamos que los analistas de datos suelen observar a qué recursos acceden los usuarios en el sitio web y cómo esos patrones de acceso difieren en función de la geografía y el tiempo. Solo se necesitaría un subconjunto de los campos.
Aunque podrías escribir una DoFn que transforme cada objeto y solo muestre un subconjunto de los campos, Apache Beam proporciona una amplia variedad de transformaciones relacionales para las PCollection que tienen un esquema. El hecho de que cada registro se componga de campos con nombre permite agregaciones sencillas y legibles que hacen referencia a los campos por nombre, similares a las agregaciones en una expresión SQL.
Select y DropFields son dos de estas transformaciones:
NOTA: Cada uno de estos ejemplos mostrará PCollection<Row> en lugar de PCollection<MyClass>. La clase Row puede admitir cualquier esquema y se puede considerar un objeto esquematizado genérico. Cualquier PCollection con un esquema puede convertirse en una PCollection de filas. Debido a que se quitan los campos, las transformaciones anteriores no mostrarán un objeto CommonLog completo, sino que se volverá a mostrar una Row. Aunque podrías crear un esquema con un nombre nuevo o registrar un esquema POJO intermedio, es más fácil usar la clase Row.
Para completar esta tarea, agrega las siguientes importaciones y cambia el conjunto de campos que se guardan en BigQuery. De esta forma, cuando se agregue una de estas transformaciones a la canalización, solo se enviarán los campos que usarán los analistas.
NOTA: Si ya tienes encadenado el método BigQueryIO.<CommonLog>write(), deberás cambiarlo a <Row> debido al tipo nuevo.
Tarea 3: Filtra datos por elemento
Existen muchas formas de filtrar en Apache Beam. El método que vimos en la tarea anterior fue usar una transformación de esquema. En esa implementación, filtraste partes de cada elemento, lo que generó un nuevo objeto Row con un esquema y un subconjunto de los campos restantes. También puedes usar ese método para filtrar con la misma facilidad elementos enteros, como se muestra en el siguiente ejemplo.
purchases.apply(Filter.<MyObject>create()
.whereFieldName(“costCents”, (Long c) -> c > 100 * 20)
.whereFieldName(“shippingAddress.country”, (String c) -> c.equals(“de”));
NOTA: No se debe confundir esta transformación de filtro (org.apache.beam.sdk.schemas.transforms.Filter) con la función de filtro anterior que no es de esquema (org.apache.beam.sdk.transforms.Filter).
Para completar esta tarea, primero agrega las siguientes instrucciones de importación al código y, luego, agrega una transformación de filtro a la canalización. Puedes filtrar según los criterios que desees. Es posible que debas agregar sugerencias de tipo a la función lambda, p. ej., (Integer c) -> c > 100.
Tarea 4: Agrega parámetros personalizados de la línea de comandos
Actualmente, la canalización tiene una serie de parámetros hard-coded, incluida la ruta de acceso a la entrada y la ubicación de la tabla en BigQuery. Sin embargo, la canalización sería más útil si pudiera leer cualquier archivo JSON en Cloud Storage. Para incluir esta función, es necesario agregar elementos al conjunto de parámetros de la línea de comandos.
Actualmente, la canalización usa una clase PipelineOptionsFactory para generar una instancia de una clase personalizada llamada Options. Sin embargo, esta clase no cambia nada de la clase PipelineOptions, por lo que, de hecho, es una instancia de PipelineOptions.
public interface Options extends PipelineOptions {
}
public static void main(String[] args) {
Options options = PipelineOptionsFactory.fromArgs(args).withValidation().as(Options.class);
run(options);
}
La clase PipelineOptions interpreta los argumentos de la línea de comandos que siguen este formato:
--<option>=<value>
Sin embargo, solo puede contener un conjunto pequeño de parámetros predefinidos. Puedes ver las funciones get- aquí. Para agregar un parámetro personalizado, debes realizar dos acciones. Primero, agrega una variable de estado a la clase Options, como se muestra en el siguiente ejemplo:
public interface Options extends PipelineOptions {
@Description("My custom command line argument.")
@Default.String("DEFAULT")
String getMyCustomOption();
void setMyCustomOption(String myCustomOption);
}
A continuación, registra tu interfaz con PipelineOptionsFactory dentro del método main() y, luego, pasa la interfaz cuando crees el objeto PipelineOptions. Cuando registras tu interfaz con PipelineOptionsFactory, el comando --help puede encontrar tu interfaz de opciones personalizadas y agregarla al resultado del comando --help. PipelineOptionsFactory también validará que sus opciones personalizadas sean compatibles con todas las otras opciones registradas.
En el siguiente código de ejemplo, se muestra cómo registrar tu interfaz de opciones personalizadas con PipelineOptionsFactory:
Para completar esta tarea, primero agrega las siguientes sentencias de importación. Luego, agrega los parámetros de la línea de comandos para la ruta de entrada, la ruta de salida de Google Cloud Storage y el nombre de la tabla de BigQuery. Por último, actualiza el código de la canalización para acceder a esos parámetros en lugar de acceder a las constantes.
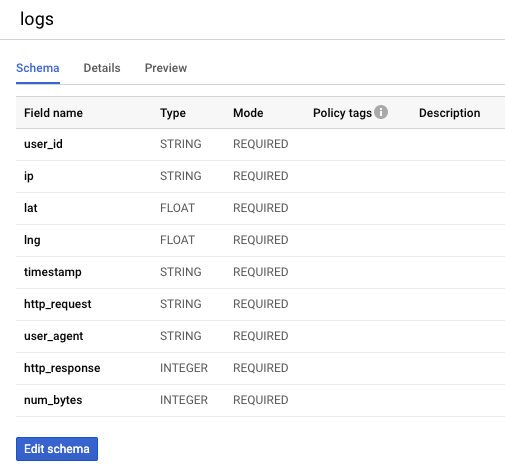
Probablemente notaste que la tabla de BigQuery creada en el último lab tenía un esquema con todos los campos REQUIRED como el siguiente:
Es posible que quieras crear un esquema de Apache Beam con campos NULLABLE en los que falten datos, tanto para la ejecución de la canalización, como para una tabla de BigQuery resultante con un esquema que refleje esto.
Puedes agregar notaciones de Javax a la definición de la clase, que, luego, se incorporan al esquema de Apache Beam de la siguiente manera:
@DefaultSchema(JavaFieldSchema.class)
class MyClass {
int field1;
@javax.annotation.Nullable String field2;
}
Para completar esta tarea, marca los campos lat y lon como anulables en la definición de la clase.
Tarea 6: Ejecuta tu canalización desde la línea de comandos
Para completar esta tarea, ejecuta tu canalización desde la línea de comandos y pasa los parámetros adecuados. Recuerda tomar nota del esquema resultante de BigQuery para los campos NULLABLE. El código debería ser similar al siguiente:
# Set up environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION='us-central1'
export BUCKET=gs://${PROJECT_ID}
export COLDLINE_BUCKET=${BUCKET}-coldline
export PIPELINE_FOLDER=${BUCKET}
export MAIN_CLASS_NAME=com.mypackage.pipeline.MyPipeline
export RUNNER=DataflowRunner
export INPUT_PATH=${PIPELINE_FOLDER}/events.json
export OUTPUT_PATH=${PIPELINE_FOLDER}-coldline
export TABLE_NAME=${PROJECT_ID}:logs.logs_filtered
cd $BASE_DIR
mvn compile exec:java \
-Dexec.mainClass=${MAIN_CLASS_NAME} \
-Dexec.cleanupDaemonThreads=false \
-Dexec.args=" \
--project=${PROJECT_ID} \
--region=${REGION} \
--stagingLocation=${PIPELINE_FOLDER}/staging \
--tempLocation=${PIPELINE_FOLDER}/temp \
--runner=${RUNNER} \
--inputPath=${INPUT_PATH} \
--outputPath=${OUTPUT_PATH} \
--tableName=${TABLE_NAME}"
Si tu canalización se compila correctamente, pero ves muchos errores debido a código o a una configuración incorrecta en el servicio de Dataflow, puedes volver a configurar RUNNER como “DirectRunner” para ejecutarlo de manera local y recibir comentarios más rápido. Este enfoque funciona en este caso porque el conjunto de datos es pequeño y no está usando ninguna función que no sea compatible con DirectRunner.
Haz clic en Revisar mi progreso para verificar el objetivo.
Ejecuta tu canalización desde la línea de comandos
Tarea 7: Verifica los resultados de la canalización
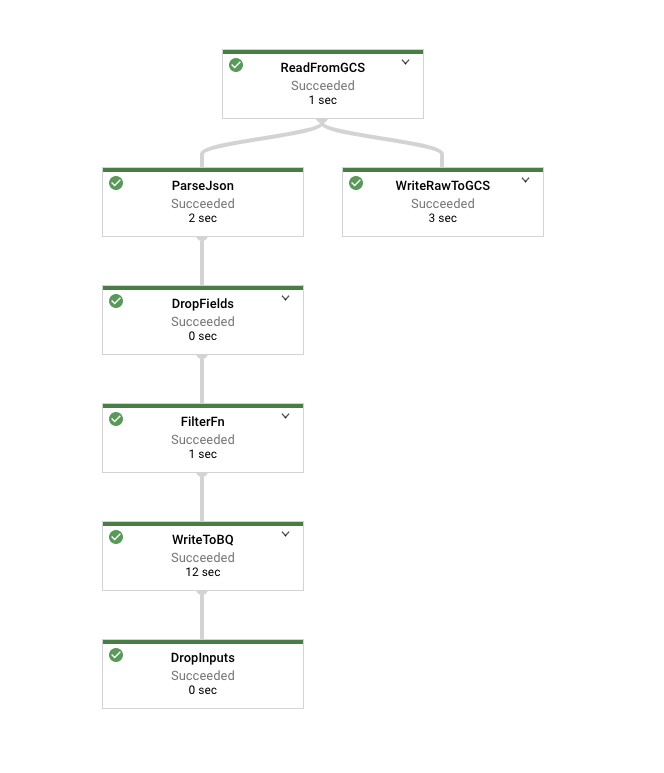
Haz clic en el nodo que representa tu función Filter que, en la imagen anterior, se llama FilterFn. En el panel que aparece en el lado derecho, deberías ver que se agregaron más elementos como entradas que los que se escribieron como salidas.
Ahora, haz clic en el nodo que representa la escritura en Cloud Storage. Dado que se escribieron todos los elementos, esta cantidad debe coincidir con la cantidad de elementos de la entrada de la función de filtro.
Una vez finalizada la canalización, consulta tu tabla para examinar los resultados en BigQuery. Ten en cuenta que la cantidad de registros en la tabla debe coincidir con la cantidad de elementos que generó la función de filtro.
Parte 2 del Lab: Personaliza plantillas de Dataflow
Una canalización que acepta parámetros de la línea de comandos es mucho más útil que una que tiene esos parámetros en modalidad hard-coded. Sin embargo, para ejecutar la canalización, se debe crear un entorno de desarrollo. Si se espera que múltiples usuarios diferentes vuelvan a ejecutar la canalización, o que la canalización se vuelva a ejecutar en una variedad de contextos diferentes, una opción todavía mejor sería usar una plantilla de Dataflow.
Hay muchas plantillas de Dataflow que ya se crearon como parte de Google Cloud Platform (puedes explorarlas aquí). Sin embargo, ninguna realiza la misma función que la canalización de este lab. En esta parte del lab, convertirás la canalización en una plantilla personalizada de Flex de Dataflow más nueva (en lugar de una plantilla tradicional personalizada).
Convertir una canalización en una plantilla personalizada de Flex de Dataflow requiere el uso de un archivo Uber JAR a fin de empaquetar no solo tu código, sino también las dependencias, un Dockerfile (para describir qué código compilar), Cloud Build (para crear el contenedor subyacente que se ejecutará en el entorno de ejecución y generar el trabajo real) y un archivo de metadatos (para describir los parámetros del trabajo).
Tarea 1: Crea una imagen de contenedor de la plantilla personalizada de Flex de Dataflow
Para completar esta tarea, primero agrega el siguiente complemento al archivo pom.xml para habilitar la creación de un archivo Uber JAR. En primer lugar, agrega lo siguiente a la etiqueta de propiedades:
Ahora, puedes crear un archivo Uber JAR con este comando:
cd $BASE_DIR
mvn clean package
Observa el tamaño. Este archivo Uber JAR tiene todas las dependencias incorporadas. Puedes ejecutar el archivo como una aplicación independiente sin dependencias externas en otras bibliotecas.
ls -lh target/*.jar
En el mismo directorio en que está el archivo pom.xml, crea un archivo llamado Dockerfile con el siguiente texto. Asegúrate de establecer FLEX_TEMPLATE_JAVA_MAIN_CLASS con el nombre completo de su clase y YOUR_JAR_HERE con el archivo Uber JAR que creaste.
FROM gcr.io/dataflow-templates-base/java11-template-launcher-base:latest
# Define the Java command options required by Dataflow Flex Templates.
ENV FLEX_TEMPLATE_JAVA_MAIN_CLASS="YOUR-CLASS-HERE"
ENV FLEX_TEMPLATE_JAVA_CLASSPATH="/template/pipeline.jar"
# Make sure to package as an uber-jar including all dependencies.
COPY target/YOUR-JAR-HERE.jar ${FLEX_TEMPLATE_JAVA_CLASSPATH}
A continuación, usa Cloud Build para que descargue la compilación del contenedor por ti, en lugar de compilarlo de manera local. Primero, activa el almacenamiento en caché para acelerar las compilaciones futuras:
gcloud config set builds/use_kaniko True
Luego, ejecuta la compilación. Esto agregará el archivo tar a todo el directorio (incluido el Dockerfile) con instrucciones sobre qué compilar y subir al servicio, y cómo compilar un contenedor y enviarlo a Google Container Registry en tu proyecto para usarlo más adelante.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crea una imagen de contenedor de una plantilla personalizada de Flex de Dataflow
Tarea 2: Crea la plantilla de Flex y almacénala en etapa intermedia
Para ejecutar una plantilla, debes crear un archivo de especificaciones de la plantilla en Cloud Storage que contenga toda la información necesaria a fin de ejecutar el trabajo, como la información y los metadatos del SDK.
Para completar esta tarea, crea un archivo metadata.json en el siguiente formato que considere todos los parámetros de entrada que espera tu canalización. Si es necesario, consulta la solución aquí. Para hacerlo, debes escribir tu propia comprobación de regex de parámetros. Aunque no es una práctica recomendada, ".*" coincidirá con cualquier entrada.
{
"name": "Your pipeline name",
"description": "Your pipeline description",
"parameters": [
{
"name": "inputSubscription",
"label": "Pub/Sub input subscription.",
"helpText": "Pub/Sub subscription to read from.",
"regexes": [
"[-_.a-zA-Z0-9]+"
]
},
{
"name": "outputTable",
"label": "BigQuery output table",
"helpText": "BigQuery table spec to write to, in the form 'project:dataset.table'.",
"is_optional": true,
"regexes": [
"[^:]+:[^.]+[.].+"
]
}
]
}
Luego, compila la plantilla real y almacénala en etapa intermedia:
export TEMPLATE_PATH="gs://${PROJECT_ID}/templates/mytemplate.json"
# Will build and upload the template to GCS
# You may need to opt-in to beta gcloud features
gcloud beta dataflow flex-template build $TEMPLATE_PATH \
--image "$TEMPLATE_IMAGE" \
--sdk-language "JAVA" \
--metadata-file "metadata.json"
Verifica que el archivo se haya subido a la ubicación de la plantilla en Cloud Storage.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear la plantilla de Flex y almacenarla en etapa intermedia
Tarea 3: Ejecuta la plantilla desde la IU
Para completar la tarea, sigue estas instrucciones.
Haz clic en CREAR UN TRABAJO A PARTIR DE UNA PLANTILLA.
Ingresa un nombre válido para el trabajo en el campo Nombre del trabajo.
Selecciona Plantilla personalizada en el menú desplegable de plantillas de Cloud Dataflow.
Ingresa la ruta de Cloud Storage a tu archivo de plantilla en el campo de la ruta de la plantilla de Cloud Storage.
Ingresa los elementos adecuados en Parámetros obligatorios.
Haz clic en Ejecutar trabajo.
NOTA: No necesitas especificar un bucket de etapa de pruebas, ya que Dataflow creará uno privado en tu proyecto con el número de proyecto, similar a “gs://dataflow-staging-us-central1-/staging”.
Si revisas la consola de Compute Engine, verás una VM de iniciador temporal que se creó para ejecutar el contenedor y poder iniciar tu canalización con los parámetros proporcionados.
Tarea 4: Ejecuta la plantilla con gcloud
Uno de los beneficios de usar las plantillas de Dataflow es que puedes ejecutarlas desde muchos contextos distintos del entorno de desarrollo. Para demostrarlo, usa gcloud a fin de ejecutar una plantilla de Dataflow desde la línea de comandos.
Para completar esta tarea, ejecuta el siguiente comando en tu terminal y modifica los parámetros según corresponda:
Asegúrate de que tu canalización se complete correctamente.
Haz clic en Revisar mi progreso para verificar el objetivo.
Ejecuta la plantilla desde la IU y con gcloud
Finalice su lab
Cuando haya completado el lab, haga clic en Finalizar lab. Google Cloud Skills Boost quitará los recursos que usó y limpiará la cuenta.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Neutral
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2020 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usa una ventana de navegación privada o de Incógnito para ejecutar el lab. Así
evitarás cualquier conflicto entre tu cuenta personal y la cuenta
de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
En este lab, a) implementarás una canalización con ramas, b) filtrarás los datos antes de escribir, c) agregarás parámetros personalizados de la línea de comandos a una canalización, d) convertirás una canalización personalizada en una plantilla de Flex de Dataflow y e) ejecutará una plantilla de Flex de Dataflow.
Duración:
1 min de configuración
·
Acceso por 120 min
·
120 min para completar


 ), selecciona IAM y administración > IAM.
), selecciona IAM y administración > IAM.