GSP461

總覽
BigQuery 是 Google 提供的全代管數據分析資料庫,不但免人工管理,而且價格低廉。您可以使用 BigQuery 查詢 TB 規模的資料,不必管理基礎架構,也不需靠資料庫管理員維護。BigQuery 使用 SQL 語法,並且採用「即付即用」模式。這項服務可讓您專心分析資料,找出有意義的深入分析結果。
BigQuery ML 可讓資料分析師運用自己的 SQL 知識,在 BigQuery 中儲存其資料的位置快速建構機器學習模型。
BigQuery 中有 NCAA 的公開資料集,含有籃球賽事、隊伍和球員等資料。球賽資料包括自 2009 年以來的比賽詳情和得分記錄,以及自 1996 年以來的最終比分。某些球隊的其他輸贏相關資料則可回溯至 1894 至 1895 年的球季。
在本實驗室中,您將使用 BigQuery ML 來設計原型,訓練、評估及預測兩支 NCAA 籃球錦標賽隊伍間的比賽結果。
學習內容
本實驗室的學習內容包括:
- 使用 BigQuery 存取 NCAA 公開資料集
- 探索 NCAA 資料集,熟悉可用資料的結構和範圍
- 進行準備,將現有資料轉換為特徵和標籤
- 將資料集分割為訓練集和評估集
- 使用 BigQuery ML,依據 NCAA 錦標賽資料集建構建構模型
- 使用新建立的模型,根據您設定的對戰組合,預測 NCAA 錦標賽的獲勝隊伍
先備知識
本實驗室的難度為中級,開始前,建議您對 SQL 和其語言的關鍵字有一定程度的瞭解。我們也建議您先熟悉 BigQuery。如果您希望能快速上手,在參與本實驗室前,應至少參加過下列其中一個實驗室:
設定和需求
點選「Start Lab」按鈕前的須知事項
請詳閱以下操作說明。研究室活動會計時,而且中途無法暫停。點選「Start Lab」 後就會開始計時,讓您瞭解有多少時間可以使用 Google Cloud 資源。
您將在真正的雲端環境中完成實作研究室活動,而不是在模擬或示範環境。為達此目的,我們會提供新的暫時憑證,讓您用來在研究室活動期間登入及存取 Google Cloud。
如要完成這個研究室活動,請先確認:
- 您可以使用標準的網際網路瀏覽器 (Chrome 瀏覽器為佳)。
注意:請使用無痕模式或私密瀏覽視窗執行此研究室。這可以防止個人帳戶和學生帳戶之間的衝突,避免個人帳戶產生額外費用。
- 是時候完成研究室活動了!別忘了,活動一開始將無法暫停。
注意:如果您擁有個人 Google Cloud 帳戶或專案,請勿用於本研究室,以免產生額外費用。
如何開始研究室及登入 Google Cloud 控制台
-
按一下「Start Lab」(開始研究室) 按鈕。如果研究室會產生費用,畫面中會出現選擇付款方式的彈出式視窗。左側的「Lab Details」窗格會顯示下列項目:
- 「Open Google Cloud console」按鈕
- 剩餘時間
- 必須在這個研究室中使用的暫時憑證
- 完成這個實驗室所需的其他資訊 (如有)
-
點選「Open Google Cloud console」;如果使用 Chrome 瀏覽器,也能按一下滑鼠右鍵,然後選取「在無痕式視窗中開啟連結」。
接著,實驗室會啟動相關資源並開啟另一個分頁,當中顯示「登入」頁面。
提示:您可以在不同的視窗中並排開啟分頁。
注意:如果頁面中顯示「選擇帳戶」對話方塊,請點選「使用其他帳戶」。
-
如有必要,請將下方的 Username 貼到「登入」對話方塊。
{{{user_0.username | "Username"}}}
您也可以在「Lab Details」窗格找到 Username。
-
點選「下一步」。
-
複製下方的 Password,並貼到「歡迎使用」對話方塊。
{{{user_0.password | "Password"}}}
您也可以在「Lab Details」窗格找到 Password。
-
點選「下一步」。
重要事項:請務必使用實驗室提供的憑證,而非自己的 Google Cloud 帳戶憑證。
注意:如果使用自己的 Google Cloud 帳戶來進行這個實驗室,可能會產生額外費用。
-
按過後續的所有頁面:
- 接受條款及細則。
- 由於這是臨時帳戶,請勿新增救援選項或雙重驗證機制。
- 請勿申請免費試用。
Google Cloud 控制台稍後會在這個分頁開啟。
注意:如要查看列出 Google Cloud 產品和服務的選單,請點選左上角的「導覽選單」。
開啟 BigQuery 控制台
- 在 Google Cloud 控制台中,依序選取「導覽選單」>「BigQuery」。
接著,畫面中會顯示「歡迎使用 Cloud 控制台中的 BigQuery」訊息方塊,當中會列出快速入門導覽課程指南的連結和版本資訊。
- 點選「完成」。
BigQuery 控制台會隨即開啟。
工作 1:開啟 BigQuery 控制台
-
在 Cloud 控制台中開啟「導覽選單」,然後選取「BigQuery」。
-
按一下「完成」,前往 Beta 版使用者介面。請確認您已在「Explorer」分頁中設定專案 ID,類似以下內容:
如果您點選專案旁的「展開」節點箭頭,不會看到任何資料集或資料表,這是因為您尚未在專案中新增內容。
幸運的是,BigQuery 中有大量的公開資料集可使用。您將進一步瞭解 NCAA 資料集,以及如何在 BigQuery 中新增資料集。
工作 2:NCAA March Madness
美國國家大學體育協會 (NCAA) 每年會在美國舉辦兩項重大的大學籃球錦標賽,分別是男子和女子大學籃球錦標賽。男子組是在三月比賽,有 68 支隊伍參與單淘汰賽,最後優勝的隊伍即為 March Madness (瘋狂三月) 的冠軍。
NCAA 提供公開資料集,內含本賽季和最終錦標賽男子組和女子組籃球賽事與球員的統計資料。球賽資料包括自 2009 年以來的比賽詳情和得分記錄,以及自 1996 年以來的最終比分。某些球隊的其他輸贏相關資料則可回溯至 1894 至 1895 年的球季。
工作 3:找出 BigQuery 中的 NCAA 公開資料集
-
進行此步驟時,請確認您仍在 BigQuery 控制台中。在「Explorer」分頁中,按一下「+ ADD」按鈕,接著選取「公開資料集」。
-
在搜尋列中輸入 NCAA Basketball,然後按下 Enter 鍵。畫面會顯示一個結果,請選取該結果並按一下「查看資料集」:
這麼做會開啟新的 BigQuery 分頁,並在其中載入資料集。您可以繼續在此分頁中操作,或關閉此分頁並在其他分頁重新整理 BigQuery 控制台,以顯示公開資料集。
注意:如果您看不到「ncaa_basketball」,請依序點選「+ 新增」>「依據名稱為專案加上星號」。輸入 bigquery-public-data 做為專案名稱,然後按一下「加上星號」。
- 依序展開「bigquery-public-data」>「ncaa_basketball」資料集,顯示其資料表:
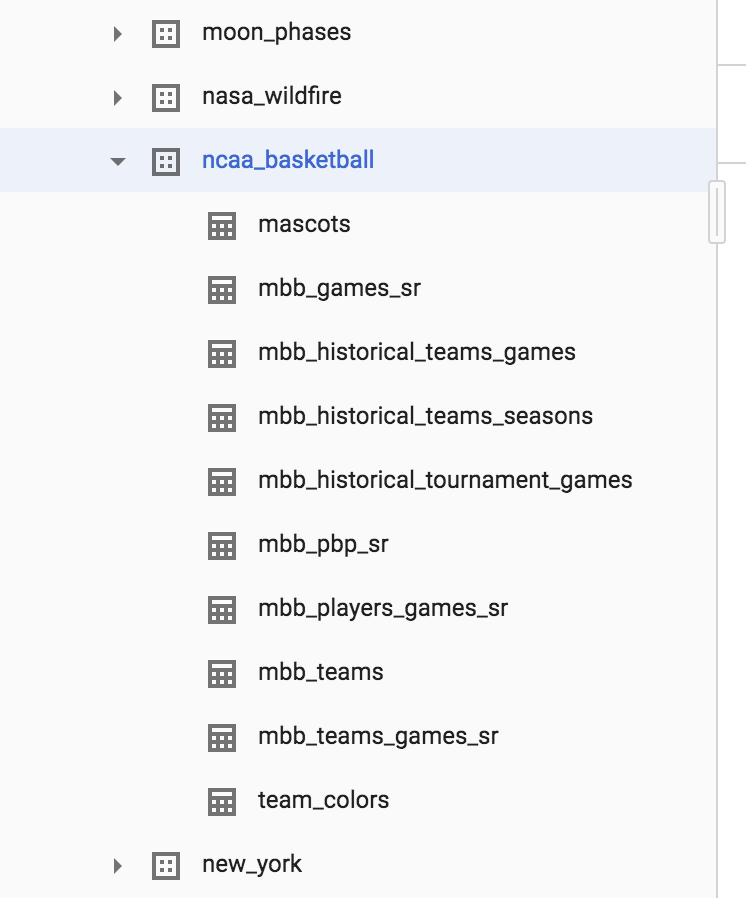
您應該會在資料集中看到 10 份資料表。
-
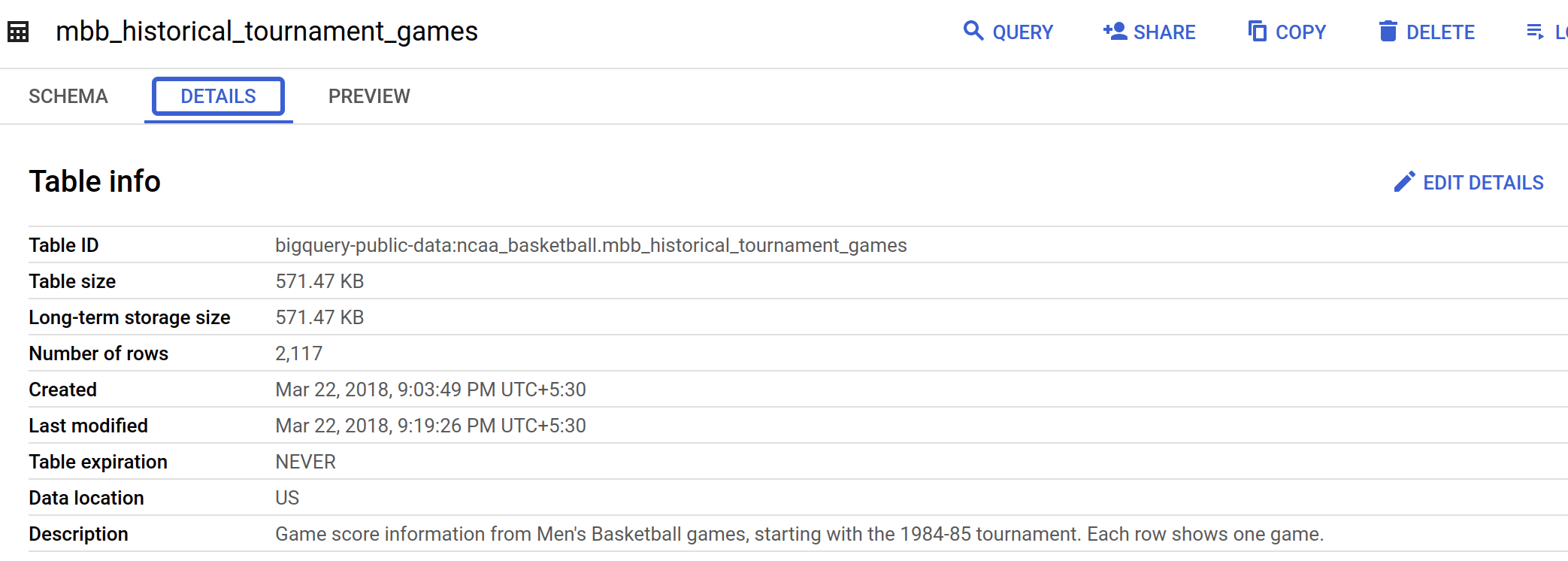
依序點選「mbb_historical_tournament_games」和「預覽」,查看資料列示例。
-
接著點選「詳細資料」,取得資料表的中繼資料。
您應該會看見類似下方的頁面:
工作 4:編寫查詢,決定可用的賽季和賽事
現在您要編寫簡易的 SQL 查詢,決定可在「mbb_historical_tournament_games」資料表中查看多少賽季和賽事。
- 在資料表「詳細資料」部分上方的查詢編輯器中,複製及貼上下列內容:
SELECT
season,
COUNT(*) as games_per_tournament
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
GROUP BY season
ORDER BY season # default is Ascending (low to high)
- 點選「執行」。不久後,您應該會收到類似下列的輸出內容:
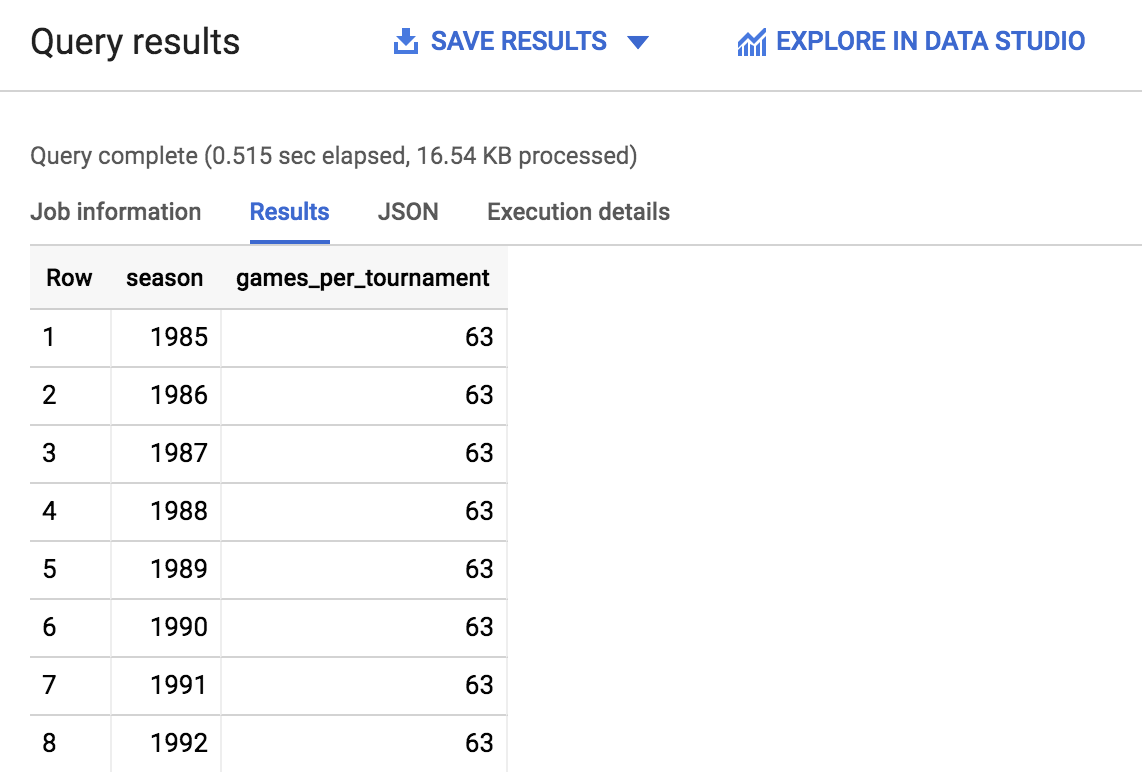
- 捲動輸出內容,記下賽季總數和各賽季的場次數量,您要使用這些資訊回答下列問題。此外,您還可以在右下角分頁箭頭旁邊,快速查看系統傳回了多少列結果。
點選「Check my progress」確認目標已達成。
編寫查詢,決定可用的賽季和賽事
隨堂測驗
完成下列選擇題能加深您的印象,更清楚本實驗室介紹的概念。盡力回答即可。
工作 5:瞭解機器學習功能和標籤
本實驗室的最終目標是依據過往賽事資料,預測 NCAA 男子籃球特定賽事的獲勝者。在機器學習中,能夠協助我們判斷錦標賽勝負結果的各資料欄,稱為「特徵」。
您要嘗試預測的資料欄則稱為「標籤」。機器學習模型會「學習」特徵間的關聯,進而預測標籤的結果。
歷來資料集的特徵範例可能包括:
- 賽季
- 隊伍名稱
- 對戰隊伍名稱
- 隊伍種子序 (排名)
- 對戰隊伍種子序
您要為未來賽事嘗試預測的標籤是「賽事結果」,即某支隊伍的勝負。
隨堂測驗
完成下列選擇題能加深您的印象,更清楚本實驗室介紹的概念。盡力回答即可。
工作 6:建立加上標籤的機器學習資料集
建構機器學習模型須擁有很多高品質的訓練資料。幸運的是,我們的 NCAA 資料集有足夠豐富的資料,可以建構有效的模型。
-
返回 BigQuery 控制台,上次中斷的地方應該是您執行的查詢結果。
-
在左選單中,點選「mbb_historical_tournament_games」來開啟該資料表。資料表載入後,按一下「預覽」。您應該會看見類似下方的頁面:
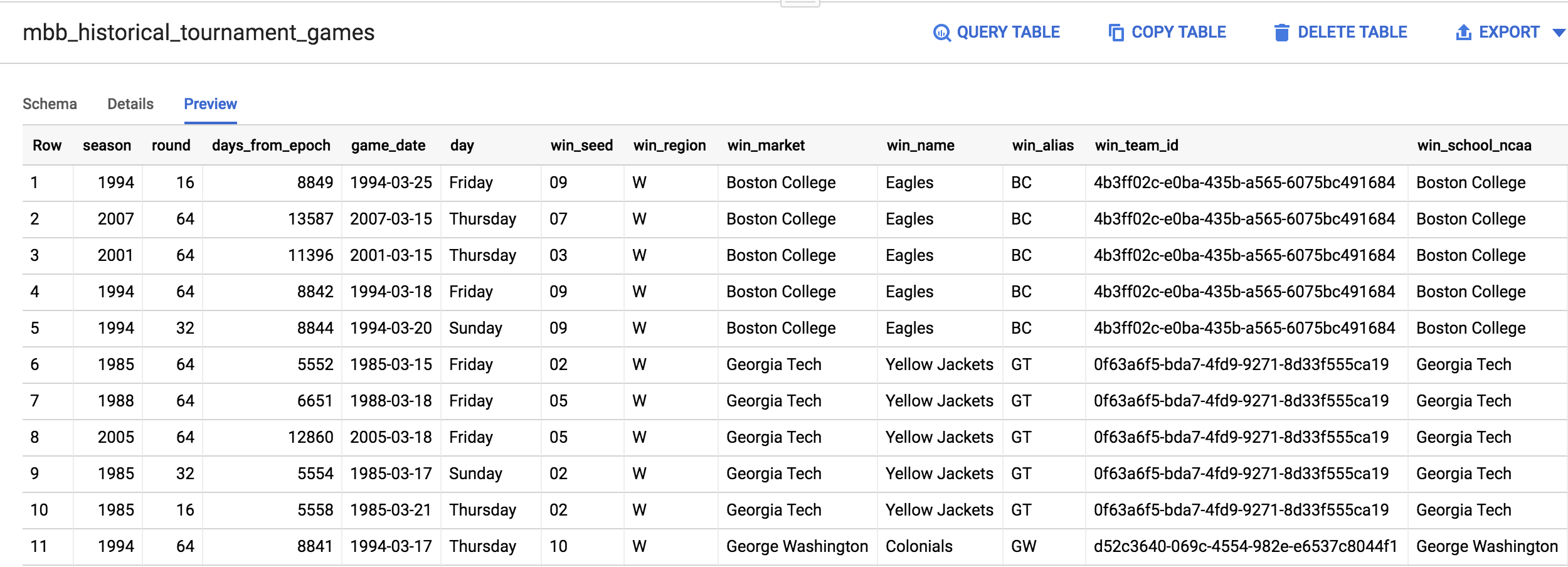
隨堂測驗
完成下列選擇題能加深您的印象,更清楚本實驗室介紹的概念。盡力回答即可。
-
檢查完資料集後,您會發現其中有一列含有「win_market」和「lose_market」資料欄。您需要將單一賽事記錄拆分為各隊伍的記錄,以便將各列標示為「勝方」或「敗方」
-
在查詢編輯器中複製及貼上下列查詢,然後按一下「執行」:
# create a row for the winning team
SELECT
# features
season, # ex: 2015 season has March 2016 tournament games
round, # sweet 16
days_from_epoch, # how old is the game
game_date,
day, # Friday
'win' AS label, # our label
win_seed AS seed, # ranking
win_market AS market,
win_name AS name,
win_alias AS alias,
win_school_ncaa AS school_ncaa,
# win_pts AS points,
lose_seed AS opponent_seed, # ranking
lose_market AS opponent_market,
lose_name AS opponent_name,
lose_alias AS opponent_alias,
lose_school_ncaa AS opponent_school_ncaa
# lose_pts AS opponent_points
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
UNION ALL
# create a separate row for the losing team
SELECT
# features
season,
round,
days_from_epoch,
game_date,
day,
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_market AS market,
lose_name AS name,
lose_alias AS alias,
lose_school_ncaa AS school_ncaa,
# lose_pts AS points,
win_seed AS opponent_seed, # ranking
win_market AS opponent_market,
win_name AS opponent_name,
win_alias AS opponent_alias,
win_school_ncaa AS opponent_school_ncaa
# win_pts AS opponent_points
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
您應該會收到下列輸出內容:
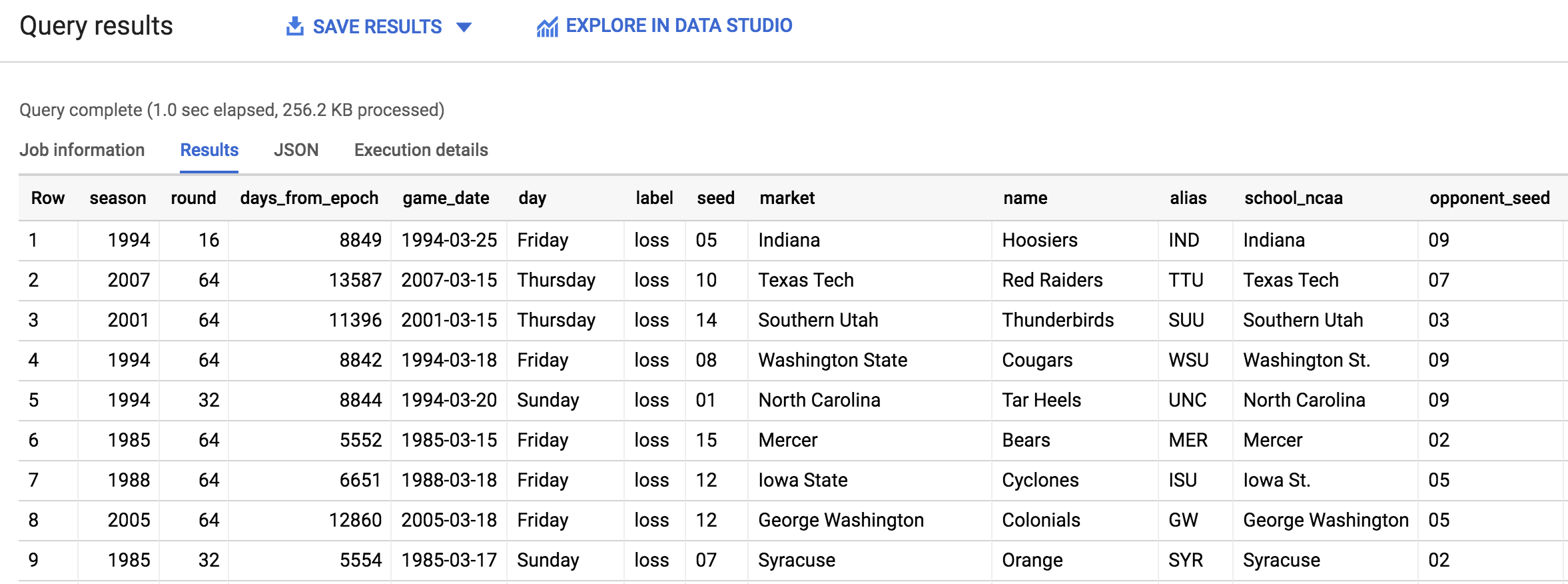
點選「Check my progress」確認目標已達成。
建立加上標籤的機器學習資料集
您已瞭解結果中有哪些特徵,請回答下列問題,加強您對資料集的瞭解。
工作 7:根據種子序和隊伍名稱,建立機器學習模型來預測獲勝者
我們已經看過資料,可以開始訓練機器學習模型了。
選擇模型類型
您將針對此特定問題建構分類模型。我們有獲勝或落敗兩種類別,因此也稱為二元分類模型。一支隊伍可能會贏得/輸掉比賽。
如果您有興趣,可以在本實驗室結束後,使用預測模型預測某支隊伍將獲得的總積分,但這並非本實驗室的重點。
要輕鬆辨別您是在預測還是分類,可以查看您要預測的資料標籤 (欄) 類型:
- 如果是數字欄 (例如銷售數量或賽事積分),表示您在進行預測
- 如果值是字串,表示您在進行分類 (該列可以是此類別,也可以是其他類別)
- 如果您有兩個以上的類別 (例如獲勝、落敗或平手),表示您在進行多元分類
我們的分類模型將透過常用的統計資料模型進行機器學習,此模型稱為邏輯迴歸。
我們需要的模型要能為每個可能的離散標籤值產生一個機率,本例中的值為「獲勝」或「落敗」。邏輯迴歸模型很適合達成這項目的。好消息是,機器學習模型會在模型訓練過程中,為您進行所有計算和最佳化作業,這就是電腦最擅長的領域!
注意:另外還有許多機器學習模型,它們在執行分類工作時的複雜度各不相同。Google 常用的一種模型是搭配深度學習與類神經網路。
透過 BigQuery ML 建立機器學習模型
如想在 BigQuery 中建立分類模型,只需要編寫 SQL 陳述式 CREATE MODEL,並提供幾個選項即可。
不過在建立模型前,我們要先在專案中準備模型的儲存位置。
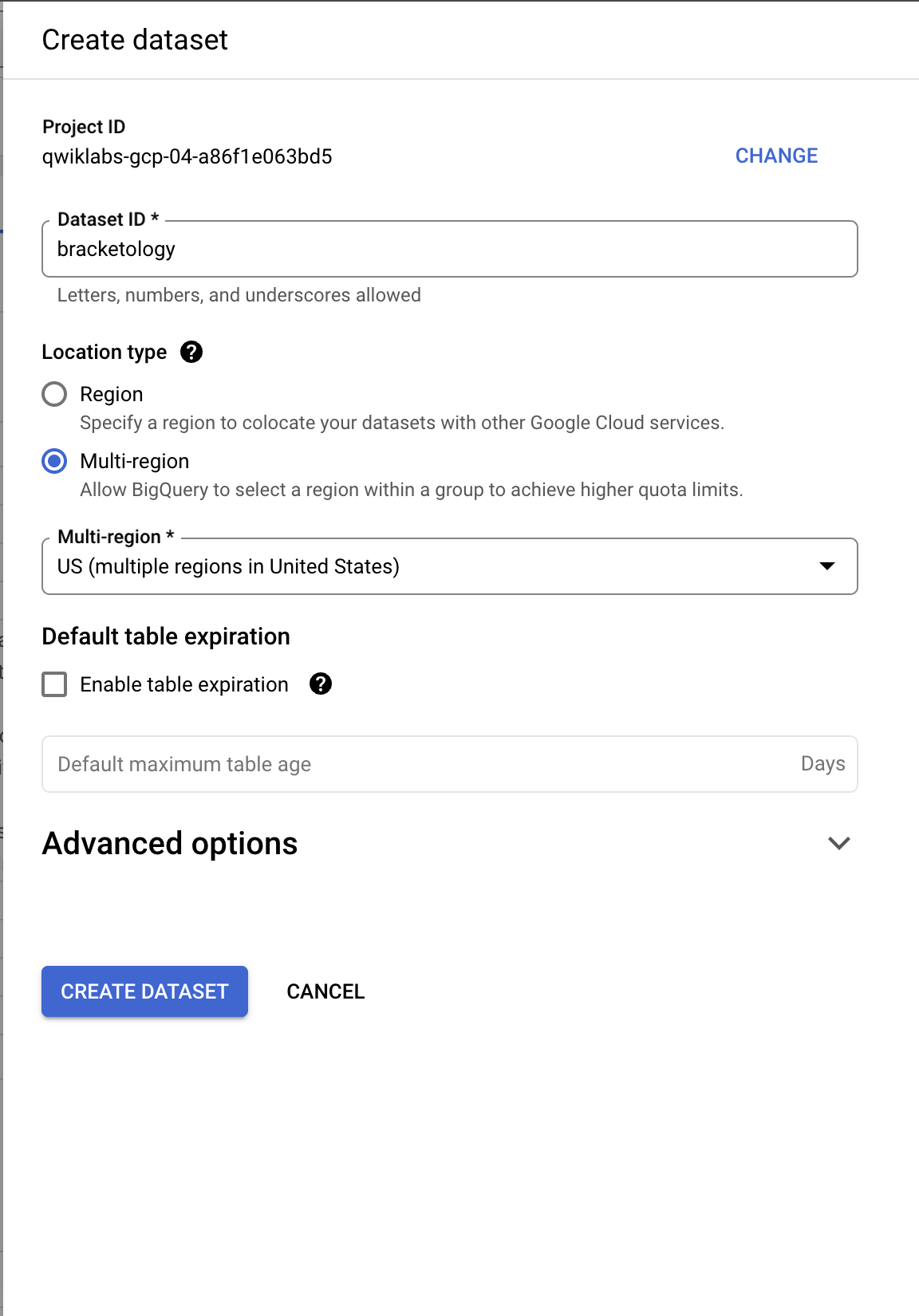
- 在「Explorer」分頁中,按一下專案 ID 旁邊的「查看動作」圖示,然後選取「建立資料集」。
- 這麼做會開啟「建立資料集」對話方塊。請將資料集 ID 設為
bracketology,然後按一下「建立資料集」。
- 接著在查詢編輯器中執行下列指令:
CREATE OR REPLACE MODEL
`bracketology.ncaa_model`
OPTIONS
( model_type='logistic_reg') AS
# create a row for the winning team
SELECT
# features
season,
'win' AS label, # our label
win_seed AS seed, # ranking
win_school_ncaa AS school_ncaa,
lose_seed AS opponent_seed, # ranking
lose_school_ncaa AS opponent_school_ncaa
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
WHERE season <= 2017
UNION ALL
# create a separate row for the losing team
SELECT
# features
season,
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_school_ncaa AS school_ncaa,
win_seed AS opponent_seed, # ranking
win_school_ncaa AS opponent_school_ncaa
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
# now we split our dataset with a WHERE clause so we can train on a subset of data and then evaluate and test the model's performance against a reserved subset so the model doesn't memorize or overfit to the training data.
# tournament season information from 1985 - 2017
# here we'll train on 1985 - 2017 and predict for 2018
WHERE season <= 2017
您可以發現,只需要幾行 SQL 程式碼就能夠建構模型。其中一個最重要的選項,是為分類工作選取「logistic_reg」模型類型。
注意:請參閱 BigQuery ML 說明文件指南,查看可用模型選項和設定的完整清單。本例中已有「標籤」欄位,因此我們要使用「input_label_cols」模型選項,避免指定標籤欄。
訓練模型需要 3 到 5 分鐘的時間。工作完成後,您應該會收到下列輸出內容:

- 按一下控制台右側的「前往模型」按鈕。
點選「Check my progress」確認目標已達成。
建立機器學習模型
查看模型訓練詳細資料
- 在模型詳細資料頁面中,向下捲動至「訓練選項」部分,查看模型實際進行的疊代訓練。
請注意,如果您有使用機器學習的經驗,可以在 OPTIONS 陳述式中定義這些超參數 (模型執行前所設定的選項),藉此自訂這些超參數。
如果您剛開始使用機器學習,BigQuery ML 會為所有未設定的選項設定智慧預設值。
詳情請參閱 BigQuery ML 模型選項清單。
查看模型訓練統計資料
機器學習模型會「學習」已知特徵和未知標籤之間的關聯。或許您已經憑直覺料到,與賽事舉辦日期等其他資料欄 (特徵)相比,「種子序」或「校名」等特徵可能更有助於判斷勝負結果。
機器學習模型不會憑藉這類直覺來開始訓練,通常會隨機決定各個特徵的權重。
在訓練過程中,模型會對特徵的判斷方法進行最佳化調整,決定各個特徵最適合的權重。每次執行時,模型都會盡量減少訓練資料遺失率和評估資料遺失率。
如果發現最終的評估資料遺失率高於訓練資料遺失率,表示您的模型過度配適,或是模型在記憶訓練資料,而非學習具有可推論性的關係。
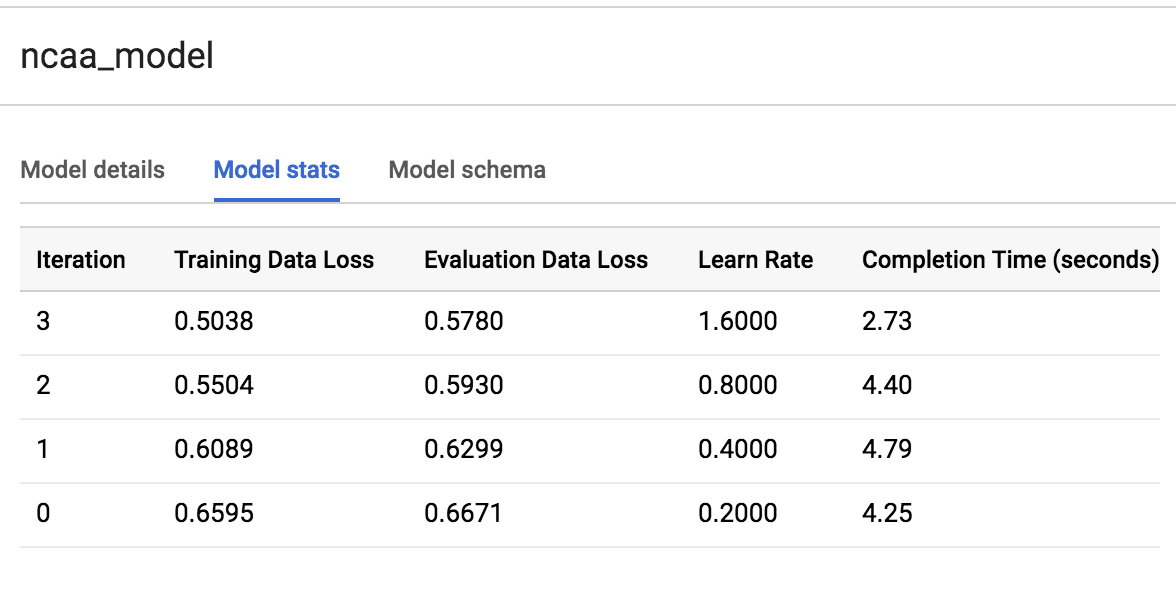
按一下「訓練」分頁,然後選取「查看」選項下方的「表格」,即可查看模型執行的訓練執行次數。
在我們的特定執行過程中,模型在約 20 秒內完成了 3 次訓練疊代。您的執行過程可能不同。
查看模型對特徵的學習情況
您可以在訓練後檢查權重,瞭解哪些特徵為模型提供了最大價值。
SELECT
category,
weight
FROM
UNNEST((
SELECT
category_weights
FROM
ML.WEIGHTS(MODEL `bracketology.ncaa_model`)
WHERE
processed_input = 'seed')) # try other features like 'school_ncaa'
ORDER BY weight DESC
您會看見類似下方的輸出內容:
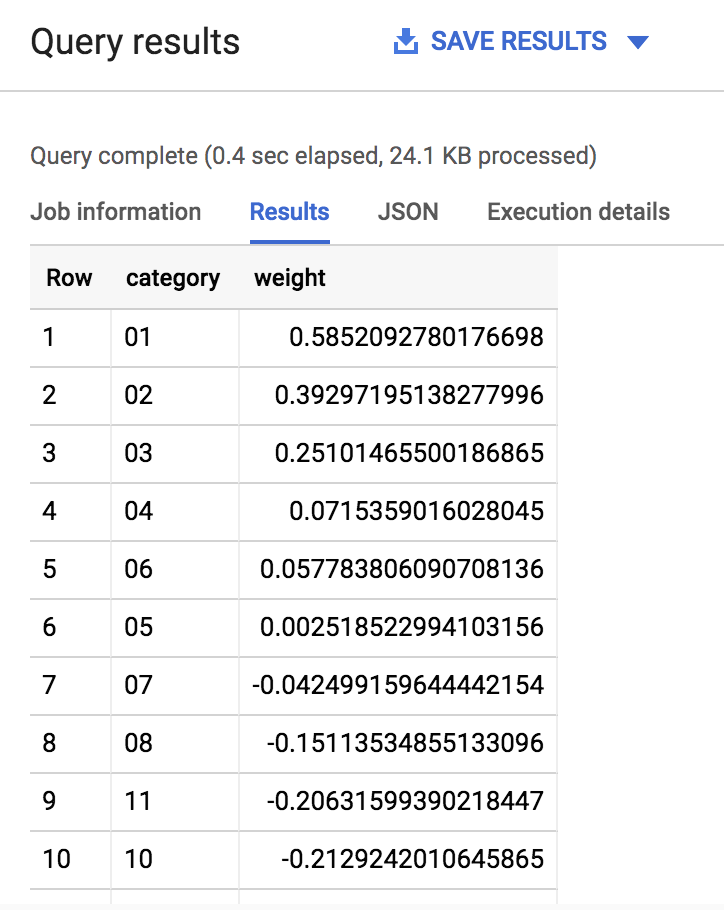
如您所見,如果隊伍的種子序非常靠前 (1 到 3) 或非常靠後 (14 到 16),模型在判斷勝負結果時,會賦予這支隊伍較高的權重 (最高為 1.0)。直覺來看這很有道理,因為我們預期種子序靠前的隊伍,通常在錦標賽中會有較佳表現。
機器學習最神奇的地方是,我們並未在 SQL 中建立大量的硬式編碼 IF THEN 陳述式,告知模型 IF 種子為 1,THEN 該隊獲勝的機率提高 80%。機器學習捨棄了硬式編碼規則和邏輯,而是自己學習這些關係。歡迎參閱 BQML 語法權重說明文件,瞭解更多資訊。
工作 8:評估模型效能
如要評估模型的效能,可以對訓練過的模型執行簡易的 ML.EVALUATE。
SELECT
*
FROM
ML.EVALUATE(MODEL `bracketology.ncaa_model`)
您應該會收到類似下列的輸出內容:

值的正確率約 69%。雖然比丟硬幣好一點,但依然有改善空間。
注意:對分類模型而言,模型準確率並非輸出內容中唯一要考量的指標。
由於您執行了邏輯迴歸,因此可以依據下列所有指標來評估模型效能 (越接近 1.0 表示結果越好):
precision:分類模型的指標,指的是模型正確預測到正類的頻率。
recall:分類模型的指標,可用來回答下列問題:在所有可能的正向標籤中,模型可以正確辨識出多少個標籤?
accuracy:準確率為分類模型預測成功的比例。
f1_score:衡量模型準確率的指標,F1 分數是精確度與喚回度的調和平均數,最佳值為 1,最差值為 0。
log_loss:用於邏輯迴歸中的損失函式,可衡量模型預測結果與正確標籤之間的差距。
roc_auc:ROC 曲線下面積,指的是分類器認為隨機挑選的正向樣本確實為正向的機率,比隨機挑選的負向樣本為正向的機率還要高。
工作 9:進行預測
現在您已經根據至 2017 年賽季 (含 2017 年) 為止的所有歷史資料 (這是您擁有的所有資料) 訓練了一個模型,可以開始預測 2018 年賽季的結果了。您的數據資料學團隊剛才在獨立的資料表中,為您建立了 2018 年錦標賽的結果,而您的原始資料集內沒有這份資料。
進行預測很簡單,只要在經過訓練的模型上呼叫 ML.PREDICT,然後透過您要用來預測的資料集傳遞即可。
CREATE OR REPLACE TABLE `bracketology.predictions` AS (
SELECT * FROM ML.PREDICT(MODEL `bracketology.ncaa_model`,
# predicting for 2018 tournament games (2017 season)
(SELECT * FROM `data-to-insights.ncaa.2018_tournament_results`)
)
)
不久後,您應該會收到類似下列的輸出內容:

點選「Check my progress」確認目標已達成。
評估模型效能並建立資料表
注意:將預測結果儲存到資料表中,這樣一來,您之後不必重複執行以上操作,就能查詢並取得深入分析。
現在您會看到原始資料集和三個新增的欄位:
由於您剛好知道 2018 年 March Madness 錦標賽的結果,讓我們來看看模型的預測結果如何。(提示:如果您要預測今年 March Madness 錦標賽的結果,只需要傳入一個含有 2019 年種子序和隊伍名稱的資料集即可。當然因為比賽尚未進行,因此標籤欄是空的,這是您要預測的結果!)
工作 10:我們的模型對 2018 年 NCAA 錦標賽的預測結果準確率如何?
SELECT * FROM `bracketology.predictions`
WHERE predicted_label <> label
您應該會收到類似下列的輸出內容:
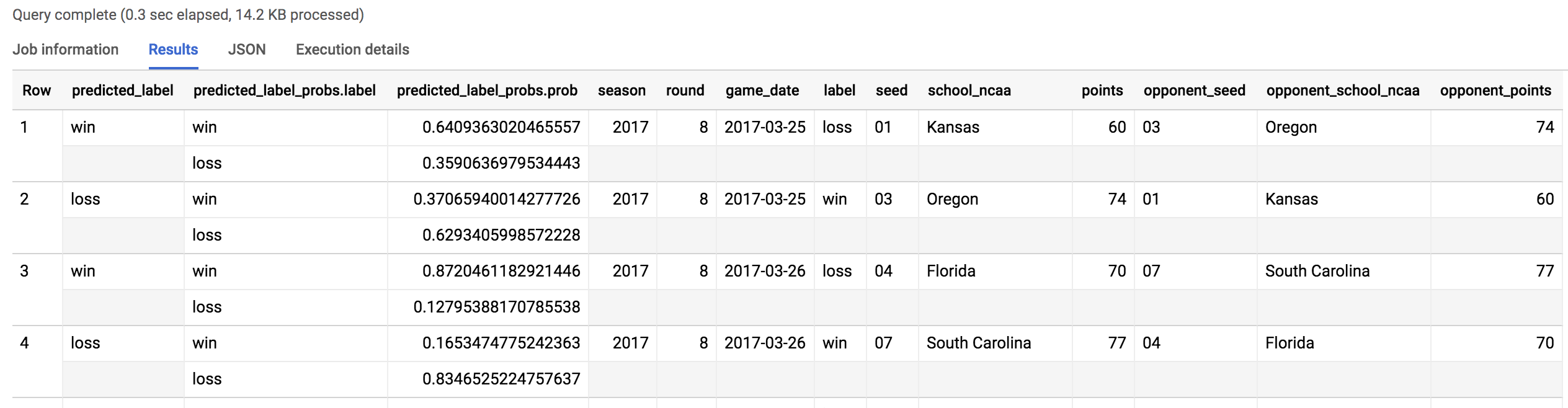
在 134 次預測中 (3 月有 67 場比賽),我們的模型錯了 38 次。模型對 2018 年錦標賽預測的正確率為 70%。
工作 11:模型只能幫您到這裡了..
由於還有其他因素和特徵,任何一次 March Madness 錦標賽都可能有模型難以預測的險勝和爆冷。
讓我們根據模型找出 2017 年錦標賽的最大爆冷賽事。我們來看看模型有 80% 以上可信度,但預測結果錯誤的賽事。
- 在查詢編輯器中執行下列指令:
SELECT
model.label AS predicted_label,
model.prob AS confidence,
predictions.label AS correct_label,
game_date,
round,
seed,
school_ncaa,
points,
opponent_seed,
opponent_school_ncaa,
opponent_points
FROM `bracketology.predictions` AS predictions,
UNNEST(predicted_label_probs) AS model
WHERE model.prob > .8 AND predicted_label <> predictions.label
您會看見類似下方的輸出結果:
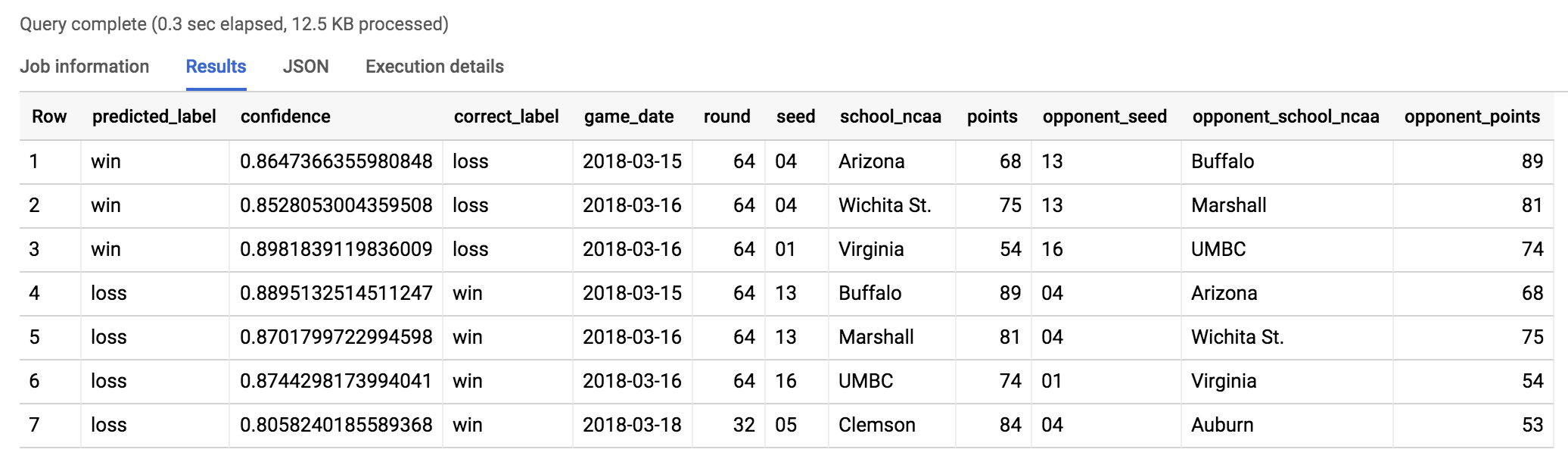
預測:模型預測第 1 種子維吉尼亞大學會擊敗第 16 種子 UMBC 大學,可信度有 87%。聽起來很合理對吧?
請觀看「16-seed UMBC pulls off a miracle upset over 1-seed Virginia」影片,看看發生了什麼事!
UMBC 大學教練 Odom 在賽後說到:「難以置信,我只能這麼說。」如想瞭解詳情,請參閱「2018 UMBC vs. Virginia men's basketball game」文章。
重點回顧
- 您建立了用來預測賽事結果的機器學習模型
- 您以種子序和隊伍名稱做為主要特徵來評估效能,達到了 69% 的準確率
- 您預測了 2018 年的錦標賽結果
- 您分析了結果,取得深入分析資料
接下來我們要挑戰不使用種子序和隊伍名稱做為特徵,建構效能更佳的模型。
工作 12:使用技術性機器學習模型特徵
在本實驗室的第二部分,您將使用新提供且詳細的特徵,建構第二個機器學習模型。
既然您已經熟悉如何使用 BigQuery ML 建構機器學習模型,您的數據資料學團隊提供了新的賽事詳情資料集,在其中建立了新的隊伍指標供模型學習。包括:
- 根據歷來的賽事詳情分析,得出得分效率趨勢。
- 持球回合數趨勢。
使用這些技術性特徵建立新的機器學習資料集
# create training dataset:
# create a row for the winning team
CREATE OR REPLACE TABLE `bracketology.training_new_features` AS
WITH outcomes AS (
SELECT
# features
season, # 1994
'win' AS label, # our label
win_seed AS seed, # ranking # this time without seed even
win_school_ncaa AS school_ncaa,
lose_seed AS opponent_seed, # ranking
lose_school_ncaa AS opponent_school_ncaa
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games` t
WHERE season >= 2014
UNION ALL
# create a separate row for the losing team
SELECT
# features
season, # 1994
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_school_ncaa AS school_ncaa,
win_seed AS opponent_seed, # ranking
win_school_ncaa AS opponent_school_ncaa
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games` t
WHERE season >= 2014
UNION ALL
# add in 2018 tournament game results not part of the public dataset:
SELECT
season,
label,
seed,
school_ncaa,
opponent_seed,
opponent_school_ncaa
FROM
`data-to-insights.ncaa.2018_tournament_results`
)
SELECT
o.season,
label,
# our team
seed,
school_ncaa,
# new pace metrics (basketball possession)
team.pace_rank,
team.poss_40min,
team.pace_rating,
# new efficiency metrics (scoring over time)
team.efficiency_rank,
team.pts_100poss,
team.efficiency_rating,
# opposing team
opponent_seed,
opponent_school_ncaa,
# new pace metrics (basketball possession)
opp.pace_rank AS opp_pace_rank,
opp.poss_40min AS opp_poss_40min,
opp.pace_rating AS opp_pace_rating,
# new efficiency metrics (scoring over time)
opp.efficiency_rank AS opp_efficiency_rank,
opp.pts_100poss AS opp_pts_100poss,
opp.efficiency_rating AS opp_efficiency_rating,
# a little feature engineering (take the difference in stats)
# new pace metrics (basketball possession)
opp.pace_rank - team.pace_rank AS pace_rank_diff,
opp.poss_40min - team.poss_40min AS pace_stat_diff,
opp.pace_rating - team.pace_rating AS pace_rating_diff,
# new efficiency metrics (scoring over time)
opp.efficiency_rank - team.efficiency_rank AS eff_rank_diff,
opp.pts_100poss - team.pts_100poss AS eff_stat_diff,
opp.efficiency_rating - team.efficiency_rating AS eff_rating_diff
FROM outcomes AS o
LEFT JOIN `data-to-insights.ncaa.feature_engineering` AS team
ON o.school_ncaa = team.team AND o.season = team.season
LEFT JOIN `data-to-insights.ncaa.feature_engineering` AS opp
ON o.opponent_school_ncaa = opp.team AND o.season = opp.season
不久後,您應該會收到類似下列的輸出內容:

點選「Check my progress」確認目標已達成。
使用技術性 ML 模型特徵
工作 13:預覽新功能
- 按一下控制台右側的「前往資料表」按鈕。接著點選「預覽」分頁標籤。
資料表應類似以下內容:
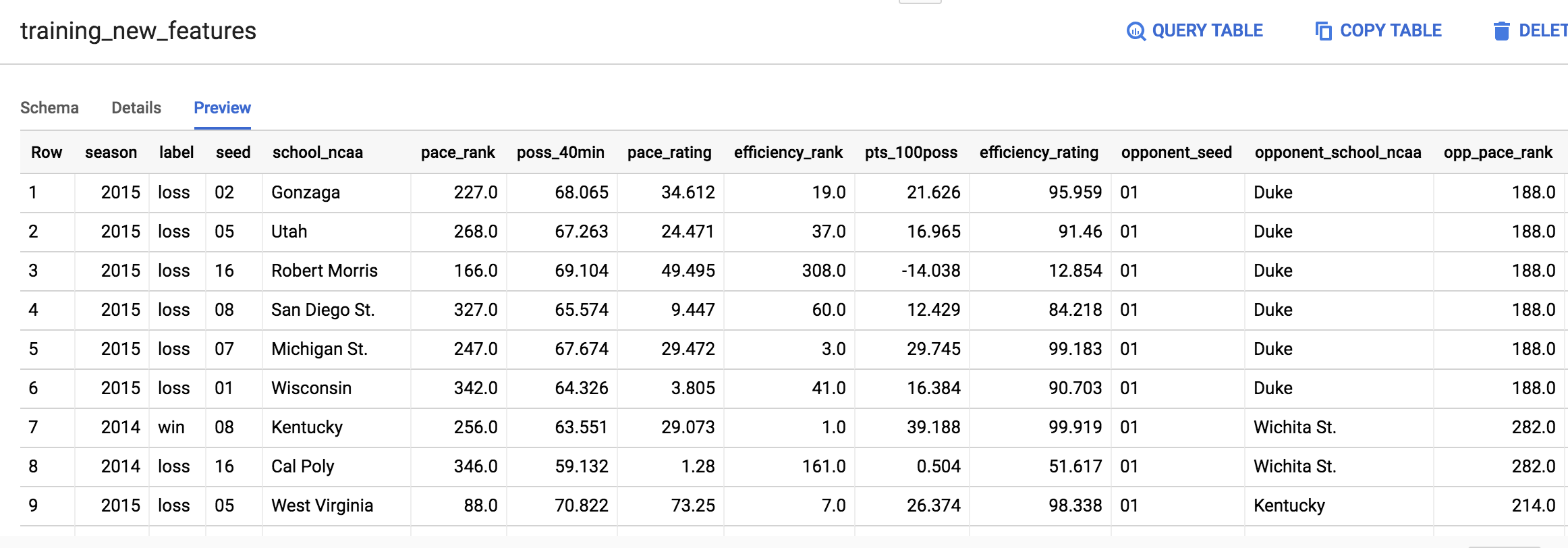
如果輸出內容與上方的螢幕截圖不同,也不必擔心。
工作 14:瞭解所選指標
opp_efficiency_rank
對手的效率排名:在所有隊伍中,對手的得分效率趨勢 (每 100 次持球回合的得分數) 排名。這個比率越低越好。
opp_pace_rank
對手的回合數排名:在所有隊伍中,我們對手的持球回合 (40 分鐘內的持球回合數) 排名。這個比率越低越好。
現在您已擁有隊伍得分效率和持球能力的特徵,可幫助您取得深入分析,接著我們再來訓練一個模型。
為了進一步避免模型「記憶過去戰績良好的隊伍」,請將隊伍名稱和種子序從下一個模型中排除,只專注於得分和持球指標。
工作 15:訓練新模型
CREATE OR REPLACE MODEL
`bracketology.ncaa_model_updated`
OPTIONS
( model_type='logistic_reg') AS
SELECT
# this time, don't train the model on school name or seed
season,
label,
# our pace
poss_40min,
pace_rank,
pace_rating,
# opponent pace
opp_poss_40min,
opp_pace_rank,
opp_pace_rating,
# difference in pace
pace_rank_diff,
pace_stat_diff,
pace_rating_diff,
# our efficiency
pts_100poss,
efficiency_rank,
efficiency_rating,
# opponent efficiency
opp_pts_100poss,
opp_efficiency_rank,
opp_efficiency_rating,
# difference in efficiency
eff_rank_diff,
eff_stat_diff,
eff_rating_diff
FROM `bracketology.training_new_features`
# here we'll train on 2014 - 2017 and predict on 2018
WHERE season BETWEEN 2014 AND 2017 # between in SQL is inclusive of end points
不久後,輸出內容應如下所示:
工作 16:評估新模型的成效
SELECT
*
FROM
ML.EVALUATE(MODEL `bracketology.ncaa_model_updated`)
輸出內容大致應如下所示:

太棒了!您剛剛使用不同特徵訓練了新模型,將準確率提高至約 75%,比原模型高了約 5%。
高品質的特徵資料集會大幅影響模型的準確率,這也是我們在機器學習中最重要的概念之一。
點選「Check my progress」確認目標已達成。
訓練新模型並進行評估
工作 17:檢查模型的學習內容
- 如想瞭解在評估勝負結果時,模型對哪些特徵賦予最大權重,請在查詢編輯器中執行下列指令:
SELECT
*
FROM
ML.WEIGHTS(MODEL `bracketology.ncaa_model_updated`)
ORDER BY ABS(weight) DESC
輸出內容應如下所示:
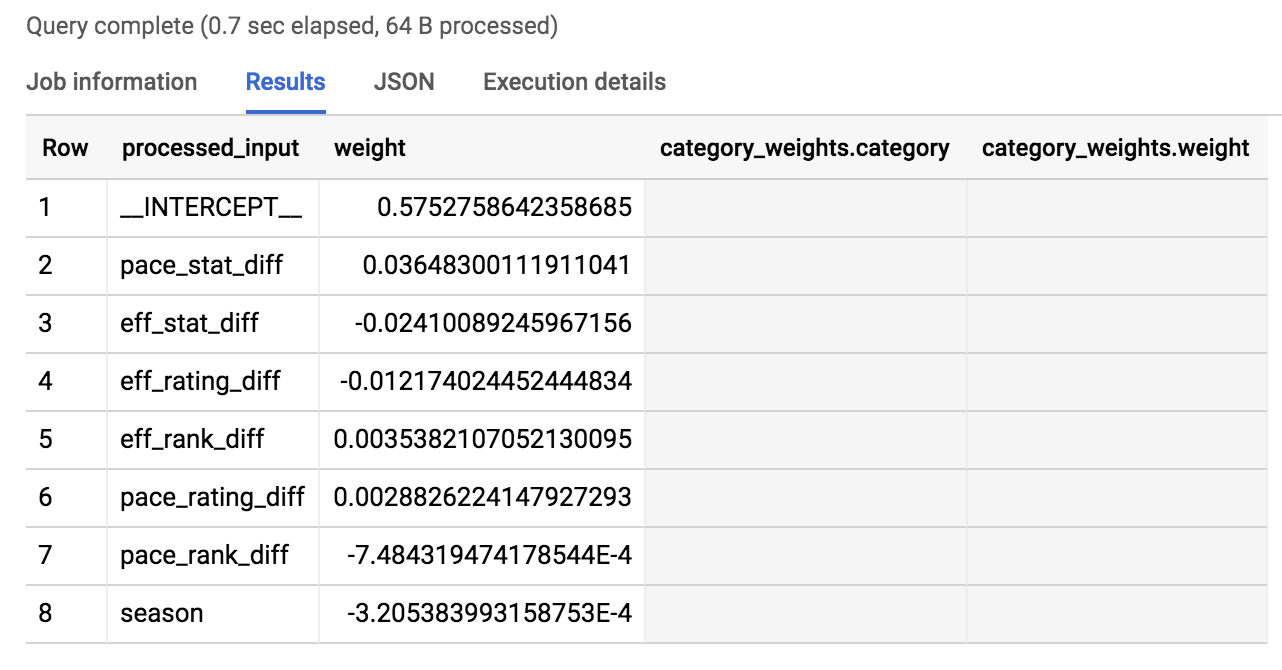
我們在排序時會使用權重的絕對值,以便將對勝負影響最大的特徵排在前面。
如結果所示,前 3 名是 pace_stat_diff、eff_stat_diff 和 eff_rating_diff。讓我們再稍微深入瞭解。
pace_stat_diff
隊伍間 (持球回合數/40 分鐘) 的實際統計資料差異。根據本模型,這是選擇賽事結果的最大驅動因素。
eff_stat_diff
隊伍間 (淨得分/100 個回合) 的實際統計資料差異。
eff_rating_diff
隊伍間得分效率的標準化排名差異。
模型在預測中對哪些特徵賦予的權重不高?答案是賽季。它在上述權重排序輸出內容中位於最後。原因是模型認為賽季 (2013、2014 及 2015 年) 對預測賽事結果的幫助不大。對所有隊伍來說,「2014」年沒有太大的戲劇性結果。
這裡有一個有趣的深入分析,模型更重視隊伍的持球回合 (控球能力),而非得分效率。
工作 18:預測時間到了!
CREATE OR REPLACE TABLE `bracketology.ncaa_2018_predictions` AS
# let's add back our other data columns for context
SELECT
*
FROM
ML.PREDICT(MODEL `bracketology.ncaa_model_updated`, (
SELECT
* # include all columns now (the model has already been trained)
FROM `bracketology.training_new_features`
WHERE season = 2018
))
您會看見類似下方的輸出內容:

點選「Check my progress」確認目標已達成。
執行查詢,建立「ncaa_2018_predictions」資料表
工作 19:預測結果分析:
您已經知道正確的比賽結果,因此可以使用新的測試資料集,確認模型做出了哪些錯誤預測。
SELECT * FROM `bracketology.ncaa_2018_predictions`
WHERE predicted_label <> label
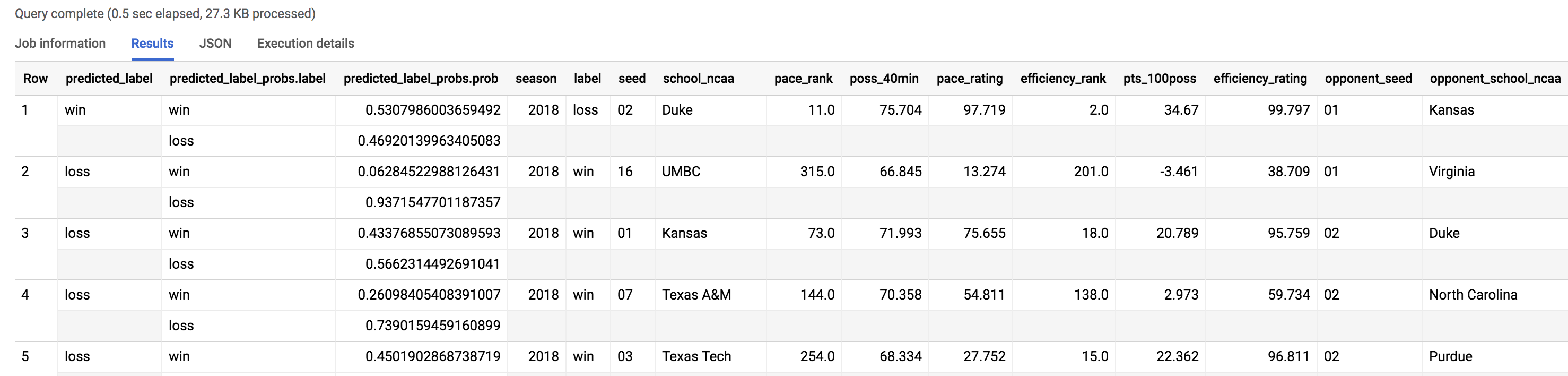
從查詢傳回的記錄數可以發現,在錦標賽所有賽事中,模型有 48 個預測錯誤的結果 (24 場比賽),因此它對 2018 年錦標賽的預測準確率為 64%。2018 一定是很戲劇性的一年,我們來看看有哪些爆冷賽事。
工作 20:2018 年 March Madness 錦標賽有哪些爆冷結果?
SELECT
CONCAT(school_ncaa, " was predicted to ",IF(predicted_label="loss","lose","win")," ",CAST(ROUND(p.prob,2)*100 AS STRING), "% but ", IF(n.label="loss","lost","won")) AS narrative,
predicted_label, # what the model thought
n.label, # what actually happened
ROUND(p.prob,2) AS probability,
season,
# us
seed,
school_ncaa,
pace_rank,
efficiency_rank,
# them
opponent_seed,
opponent_school_ncaa,
opp_pace_rank,
opp_efficiency_rank
FROM `bracketology.ncaa_2018_predictions` AS n,
UNNEST(predicted_label_probs) AS p
WHERE
predicted_label <> n.label # model got it wrong
AND p.prob > .75 # by more than 75% confidence
ORDER BY prob DESC
輸出內容應如下所示:
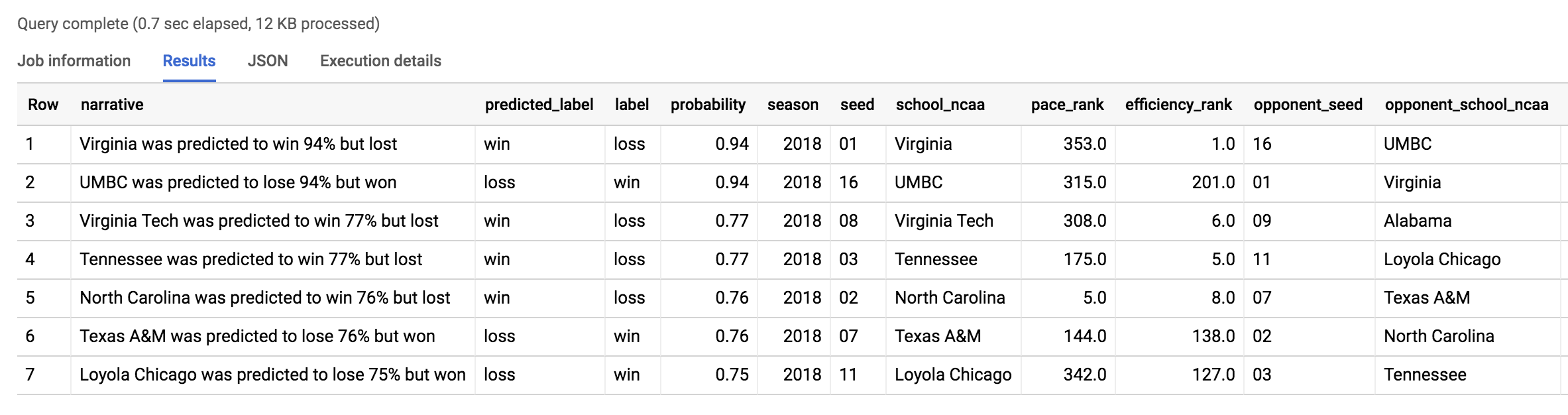
最大爆冷賽事與我們前一個模型找到的結果相同:UMBC 大學對維吉尼亞大學。如想進一步瞭解 2018 年有哪些重大爆冷賽事,請參閱「Has This Been the “Maddest” March?」。2019 年也會這麼有戲劇性嗎?
工作 21:比較模型效能
有哪些情況是簡單模型 (比較種子序) 做出錯誤預測,但進階模型的預測正確?
SELECT
CONCAT(opponent_school_ncaa, " (", opponent_seed, ") was ",CAST(ROUND(ROUND(p.prob,2)*100,2) AS STRING),"% predicted to upset ", school_ncaa, " (", seed, ") and did!") AS narrative,
predicted_label, # what the model thought
n.label, # what actually happened
ROUND(p.prob,2) AS probability,
season,
# us
seed,
school_ncaa,
pace_rank,
efficiency_rank,
# them
opponent_seed,
opponent_school_ncaa,
opp_pace_rank,
opp_efficiency_rank,
(CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) AS seed_diff
FROM `bracketology.ncaa_2018_predictions` AS n,
UNNEST(predicted_label_probs) AS p
WHERE
predicted_label = 'loss'
AND predicted_label = n.label # model got it right
AND p.prob >= .55 # by 55%+ confidence
AND (CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) > 2 # seed difference magnitude
ORDER BY (CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) DESC
輸出內容應如下所示:

模型預測佛羅里達州立大學 (第 9 種子) 會爆冷擊敗澤維爾大學 (第 1 種子),而他們確實辦到了!
新模型根據持球回合數和投籃效率等新的技術性特徵,正確預測出爆冷結果 (即便此結果與種子序相反)。歡迎在 YouTube 上觀看賽事集錦。
工作 22:預測 2019 年 March Madness 錦標賽
我們已經知道 2019 年 March Madness 錦標賽的隊伍和種子序,接著要預測未來賽事結果。
探索 2019 年的資料
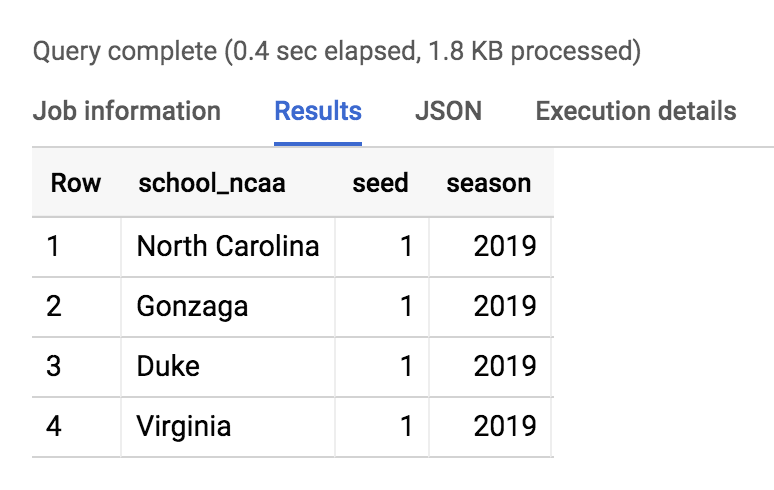
SELECT * FROM `data-to-insights.ncaa.2019_tournament_seeds` WHERE seed = 1
輸出內容應如下所示:
建立包含所有可能賽事的矩陣
我們不知道隨著賽程進行,哪些隊伍會彼此對上,因此我們簡單預測一支隊伍會與其他所有隊伍比賽。
在 SQL 中,如果想建立一份資料表,顯示一支隊伍與其他所有隊伍比賽的資料,較簡單的方法是使用交叉聯結。
SELECT
NULL AS label,
team.school_ncaa AS team_school_ncaa,
team.seed AS team_seed,
opp.school_ncaa AS opp_school_ncaa,
opp.seed AS opp_seed
FROM `data-to-insights.ncaa.2019_tournament_seeds` AS team
CROSS JOIN `data-to-insights.ncaa.2019_tournament_seeds` AS opp
# teams cannot play against themselves :)
WHERE team.school_ncaa <> opp.school_ncaa
加入 2018 年參賽隊伍的統計資料 (回合數、效率)
CREATE OR REPLACE TABLE `bracketology.ncaa_2019_tournament` AS
WITH team_seeds_all_possible_games AS (
SELECT
NULL AS label,
team.school_ncaa AS school_ncaa,
team.seed AS seed,
opp.school_ncaa AS opponent_school_ncaa,
opp.seed AS opponent_seed
FROM `data-to-insights.ncaa.2019_tournament_seeds` AS team
CROSS JOIN `data-to-insights.ncaa.2019_tournament_seeds` AS opp
# teams cannot play against themselves :)
WHERE team.school_ncaa <> opp.school_ncaa
)
, add_in_2018_season_stats AS (
SELECT
team_seeds_all_possible_games.*,
# bring in features from the 2018 regular season for each team
(SELECT AS STRUCT * FROM `data-to-insights.ncaa.feature_engineering` WHERE school_ncaa = team AND season = 2018) AS team,
(SELECT AS STRUCT * FROM `data-to-insights.ncaa.feature_engineering` WHERE opponent_school_ncaa = team AND season = 2018) AS opp
FROM team_seeds_all_possible_games
)
# Preparing 2019 data for prediction
SELECT
label,
2019 AS season, # 2018-2019 tournament season
# our team
seed,
school_ncaa,
# new pace metrics (basketball possession)
team.pace_rank,
team.poss_40min,
team.pace_rating,
# new efficiency metrics (scoring over time)
team.efficiency_rank,
team.pts_100poss,
team.efficiency_rating,
# opposing team
opponent_seed,
opponent_school_ncaa,
# new pace metrics (basketball possession)
opp.pace_rank AS opp_pace_rank,
opp.poss_40min AS opp_poss_40min,
opp.pace_rating AS opp_pace_rating,
# new efficiency metrics (scoring over time)
opp.efficiency_rank AS opp_efficiency_rank,
opp.pts_100poss AS opp_pts_100poss,
opp.efficiency_rating AS opp_efficiency_rating,
# a little feature engineering (take the difference in stats)
# new pace metrics (basketball possession)
opp.pace_rank - team.pace_rank AS pace_rank_diff,
opp.poss_40min - team.poss_40min AS pace_stat_diff,
opp.pace_rating - team.pace_rating AS pace_rating_diff,
# new efficiency metrics (scoring over time)
opp.efficiency_rank - team.efficiency_rank AS eff_rank_diff,
opp.pts_100poss - team.pts_100poss AS eff_stat_diff,
opp.efficiency_rating - team.efficiency_rating AS eff_rating_diff
FROM add_in_2018_season_stats
進行預測
CREATE OR REPLACE TABLE `bracketology.ncaa_2019_tournament_predictions` AS
SELECT
*
FROM
# let's predicted using the newer model
ML.PREDICT(MODEL `bracketology.ncaa_model_updated`, (
# let's predict on March 2019 tournament games:
SELECT * FROM `bracketology.ncaa_2019_tournament`
))
點選「Check my progress」確認目標已達成。
執行查詢,建立「ncaa_2019_tournament」和「ncaa_2019_tournament_predictions」資料表
取得預測
SELECT
p.label AS prediction,
ROUND(p.prob,3) AS confidence,
school_ncaa,
seed,
opponent_school_ncaa,
opponent_seed
FROM `bracketology.ncaa_2019_tournament_predictions`,
UNNEST(predicted_label_probs) AS p
WHERE p.prob >= .5
AND school_ncaa = 'Duke'
ORDER BY seed, opponent_seed
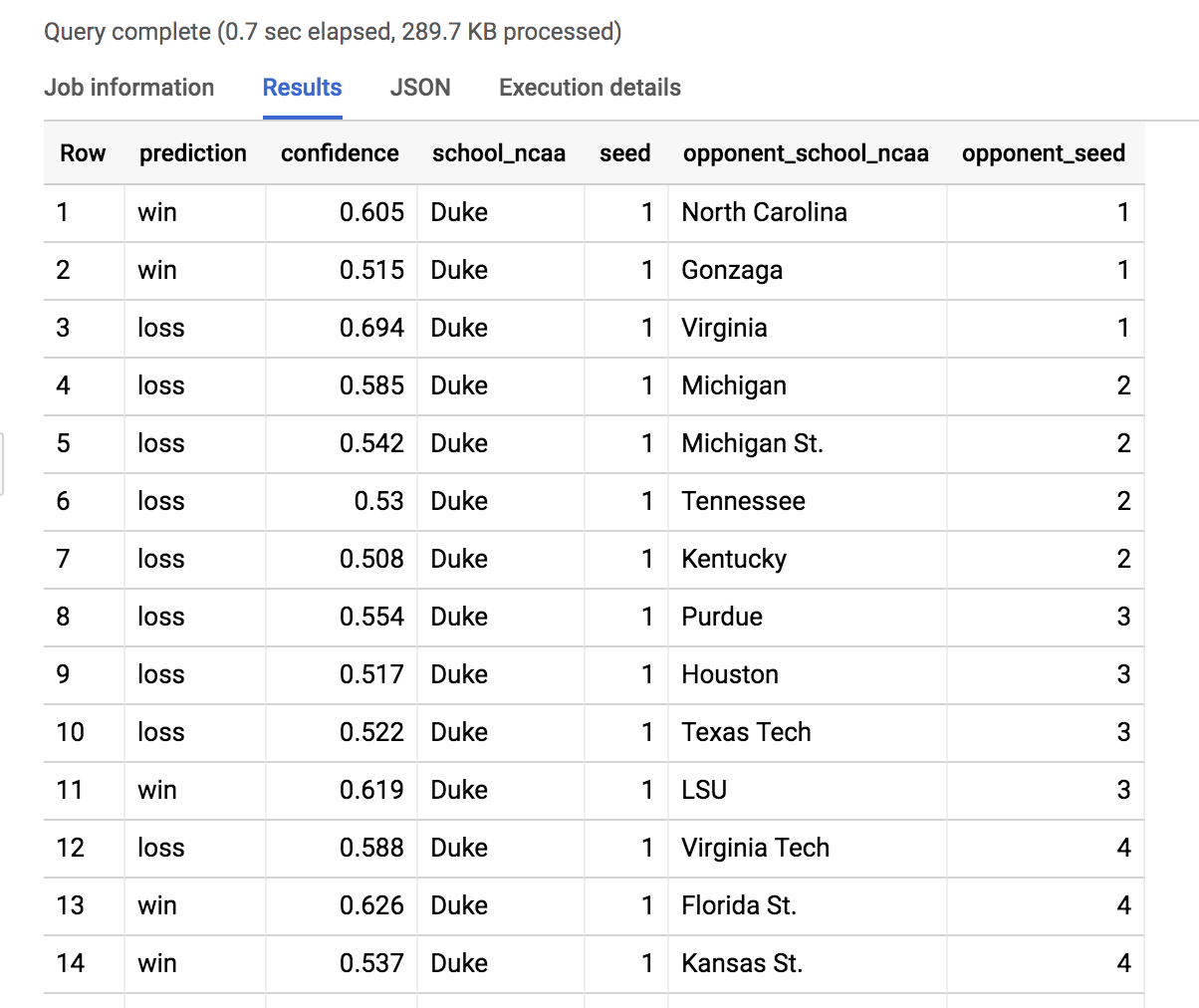
- 現在來篩選模型結果,查看所有杜克大學可能的對戰組合。捲動畫面,找出杜克大學對北達科塔州立大學的比賽。
深入分析:杜克大學 (第 1 種子) 有 88.5% 的機率在 2019 年 3 月 22 日擊敗北達科塔州立大學 (第 16 種子)。
您可以變更上方的「school_ncaa filter」篩選器,嘗試預測其他對戰組合的結果。寫下模型的可信度,然後開始欣賞比賽吧!
恭喜!
您已使用 BigQuery ML 預測 NCAA 男子籃球錦標賽的獲勝隊伍。
後續行動/瞭解詳情
- 想進一步瞭解籃球指標和相關分析嗎?歡迎參閱 Google Cloud NCAA 錦標賽廣告及預測團隊進行的其他分析。
- 參考以下實驗室:
Google Cloud 教育訓練與認證
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2024 年 3 月 19 日
實驗室上次測試日期:2024 年 3 月 19 日
Copyright 2024 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。

