GSP461

概览
BigQuery 是 Google 推出的全托管式、无需运维、费用低廉的分析数据库。借助 BigQuery,您可以查询 TB 级的数据,而不必管理基础设施,也无需数据库管理员。BigQuery 使用 SQL,并且支持随用随付模式。有了 BigQuery,您就可以专心分析数据,从中发掘有意义的数据洞见。
有了 BigQuery ML,数据分析师可以利用掌握的 SQL 知识,在 BigQuery 内存储了其数据的位置快速构建机器学习模型。
在 BigQuery 中,有一个关于 NCAA(全美大学生体育协会)篮球比赛、队伍和球员的公开数据集。比赛数据包含追溯到 2009 年的比赛详情和得分记录表,以及追溯到 1996 年的决赛比分。关于胜负的其他数据,部分球队可追溯到 1894-5 赛季。
在本实验中,您将使用 BigQuery ML 来开发原型,以及进行训练和评估,并预测两只 NCAA 篮球锦标赛参赛队伍之间的胜负结果。
您将执行的操作
在本实验中,您将学习如何完成以下操作:
- 使用 BigQuery 访问关于 NCAA 的公开数据集
- 研究 NCAA 数据集,熟悉可用数据的架构和范围
- 做好准备并将现有数据转换成特征和标签
- 将数据集拆分成训练子集和评估子集
- 根据 NCAA 锦标赛数据集,使用 BigQuery ML 构建一个模型
- 使用新构建的模型,预测您所制定的 NCAA 锦标赛对阵方案的胜负结果
前提条件
本实验是中级实验。在进行本实验之前,您应该对 SQL 及该语言的关键字有一定了解,最好还能熟悉一下 BigQuery。如果您需要快速上手,应该在尝试本实验之前至少进行过以下一项实验:
设置和要求
点击“开始实验”按钮前的注意事项
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。我们会为您提供新的临时凭据,让您可以在实验规定的时间内用来登录和访问 Google Cloud。
为完成此实验,您需要:
- 能够使用标准的互联网浏览器(建议使用 Chrome 浏览器)。
注意:请使用无痕模式或无痕浏览器窗口运行此实验。这可以避免您的个人账号与学生账号之间发生冲突,这种冲突可能导致您的个人账号产生额外费用。
注意:如果您已有自己的个人 Google Cloud 账号或项目,请不要在此实验中使用,以避免您的账号产生额外的费用。
如何开始实验并登录 Google Cloud 控制台
-
点击开始实验按钮。如果该实验需要付费,系统会打开一个弹出式窗口供您选择付款方式。左侧是实验详细信息面板,其中包含以下各项:
-
打开 Google Cloud 控制台按钮
- 剩余时间
- 进行该实验时必须使用的临时凭据
- 帮助您逐步完成本实验所需的其他信息(如果需要)
-
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示登录页面。
提示:请将这些标签页安排在不同的窗口中,并将它们并排显示。
注意:如果您看见选择账号对话框,请点击使用其他账号。
-
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
{{{user_0.username | "<用户名>"}}}
您也可以在实验详细信息面板中找到用户名。
-
点击下一步。
-
复制下面的密码,然后将其粘贴到欢迎对话框中。
{{{user_0.password | "<密码>"}}}
您也可以在实验详细信息面板中找到密码。
-
点击下一步。
重要提示:您必须使用实验提供的凭据。请勿使用您的 Google Cloud 账号凭据。
注意:在本次实验中使用您自己的 Google Cloud 账号可能会产生额外费用。
-
继续在后续页面中点击以完成相应操作:
- 接受条款及条件。
- 由于该账号为临时账号,请勿添加账号恢复选项或双重验证。
- 请勿注册免费试用。
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。
注意:如需查看列有 Google Cloud 产品和服务的菜单,请点击左上角的导航菜单。

打开 BigQuery 控制台
- 在 Google Cloud 控制台中,选择导航菜单 > BigQuery。
您会看到欢迎在 Cloud 控制台中使用 BigQuery 消息框,其中提供了指向快速入门指南和版本说明的链接。
- 点击完成。
BigQuery 控制台即会打开。
任务 1. 打开 BigQuery 控制台
-
在 Cloud 控制台中打开导航菜单并选择 BigQuery。
-
点击完成,进入 Beta 版界面。确保“探索器”标签页中已设置您的项目 ID,如下所示:
如果您点击项目名称旁边的展开节点箭头,不会看到任何数据库或表格。原因是您尚未将任何数据库或表格添加到项目。
幸运的是,BigQuery 中有大量开放的公共数据集供您使用。您将先详细了解 NCAA 数据集,然后了解如何将该数据集添加到您的 BigQuery 项目。
任务 2. NCAA March Madness
全美大学生体育协会 (NCAA) 每年在美国主办两项重要大学篮球锦标赛,分别是男子和女子大学生篮球锦标赛。在 3 月份举办的 NCAA 男子锦标赛中,有 68 只队伍参加单场淘汰制比赛,最终一只队伍成为 March Madness 的总冠军。
NCAA 提供一个公开数据集,其中包含本赛季和最终锦标赛中男女篮球比赛和球员的统计数据。比赛数据包含追溯到 2009 年的比赛详情和得分记录表,以及追溯到 1996 年的决赛比分。关于胜负的其他数据,部分球队可追溯到 1894-5 赛季。
任务 3. 在 BigQuery 中找到 NCAA 公开数据集
-
在执行此步骤前,请确保您仍然在 BigQuery 控制台中。在“探索器”标签中点击 + 添加按钮,然后选择公开数据集。
-
在搜索栏中输入 NCAA Basketball 并点击 Enter 键。此时将弹出一个结果,选择该结果,然后点击查看数据集:
这将打开一个新的 BigQuery 标签页并会加载数据集。您可继续在此标签页中操作,或关闭此标签页并在另一个标签页中刷新您的 BigQuery 控制台,以便显示公开数据集。
注意:如果无法看到“ncaa_basketball”,则点击 + 添加 > 按名称为项目加星标。输入 bigquery-public-data 作为项目名称,然后点击 加星标。
- 展开 bigquery-public-data > ncaa_basketball 数据集,以便显示其表格:
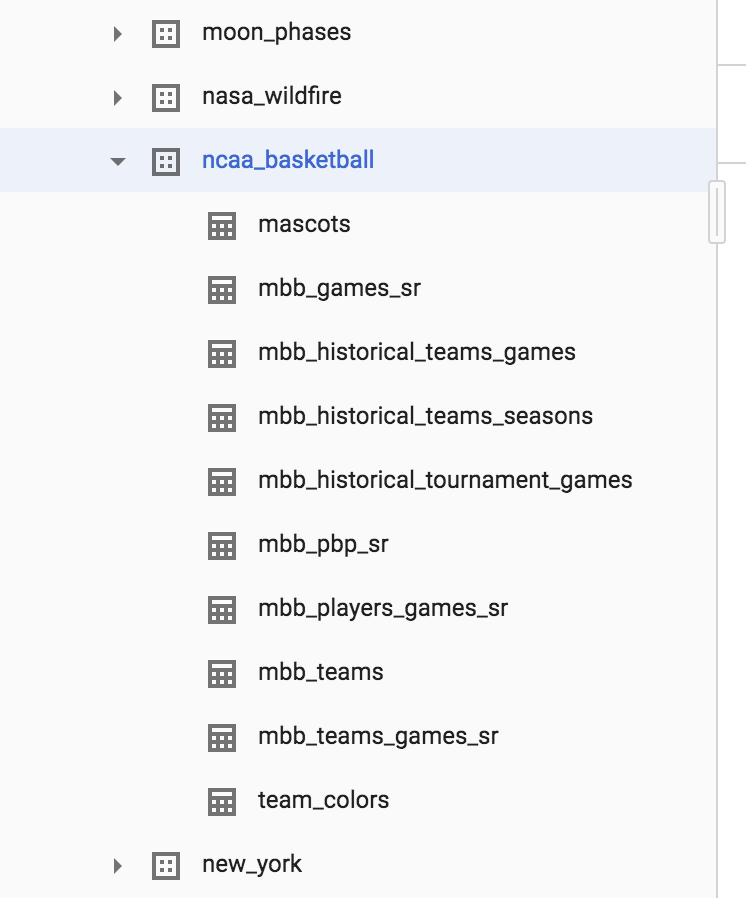
您在该数据集中应该会看到 10 份表格。
-
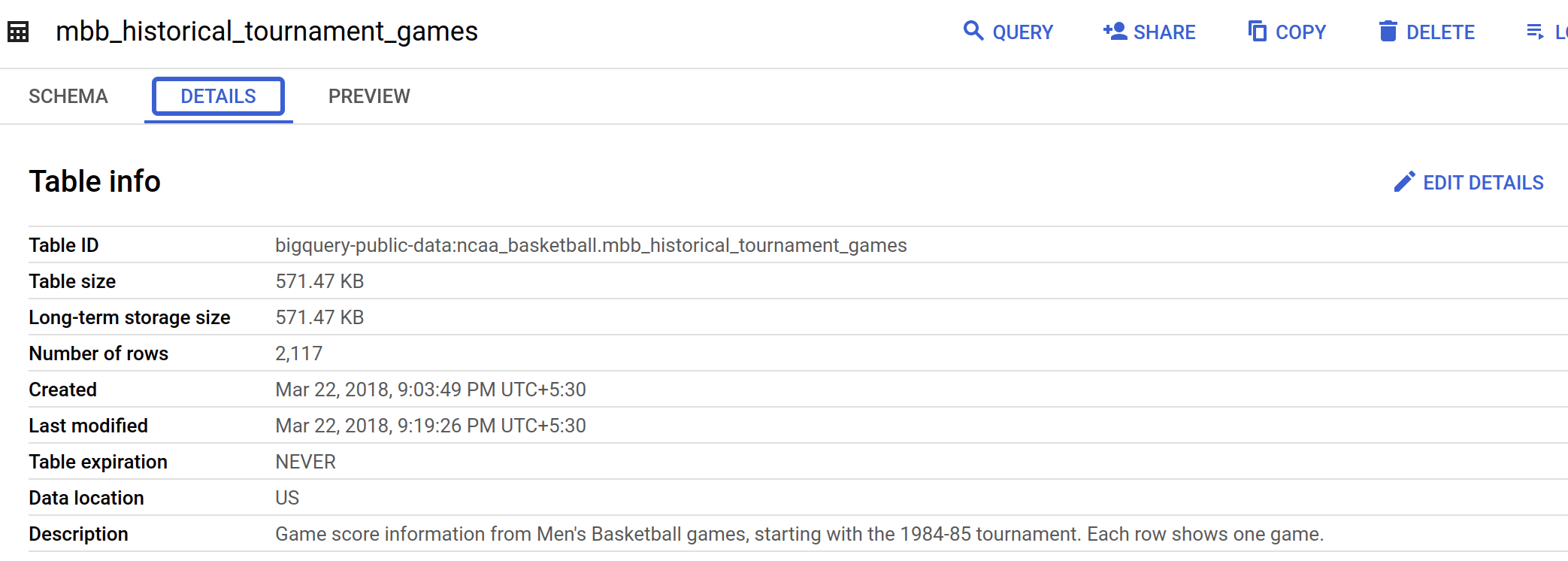
点击 mbb_historical_tournament_games,然后点击预览,查看数据行样本。
-
再点击详细信息,获取有关该表格的元数据。
您应该会看到类似下图的页面:
任务 4. 编写一个查询来确定能浏览到的赛季和比赛
您将编写一个简单的 SQL 查询,以便确定在我们的 mbb_historical_tournament_games 表格中能浏览到多少赛季和比赛。
- 在查询编辑器(位于表格详细信息部分的上方)中,复制和粘贴以下内容:
SELECT
season,
COUNT(*) as games_per_tournament
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
GROUP BY season
ORDER BY season # default is Ascending (low to high)
- 点击运行。您应该很快会看到下面的输出内容:
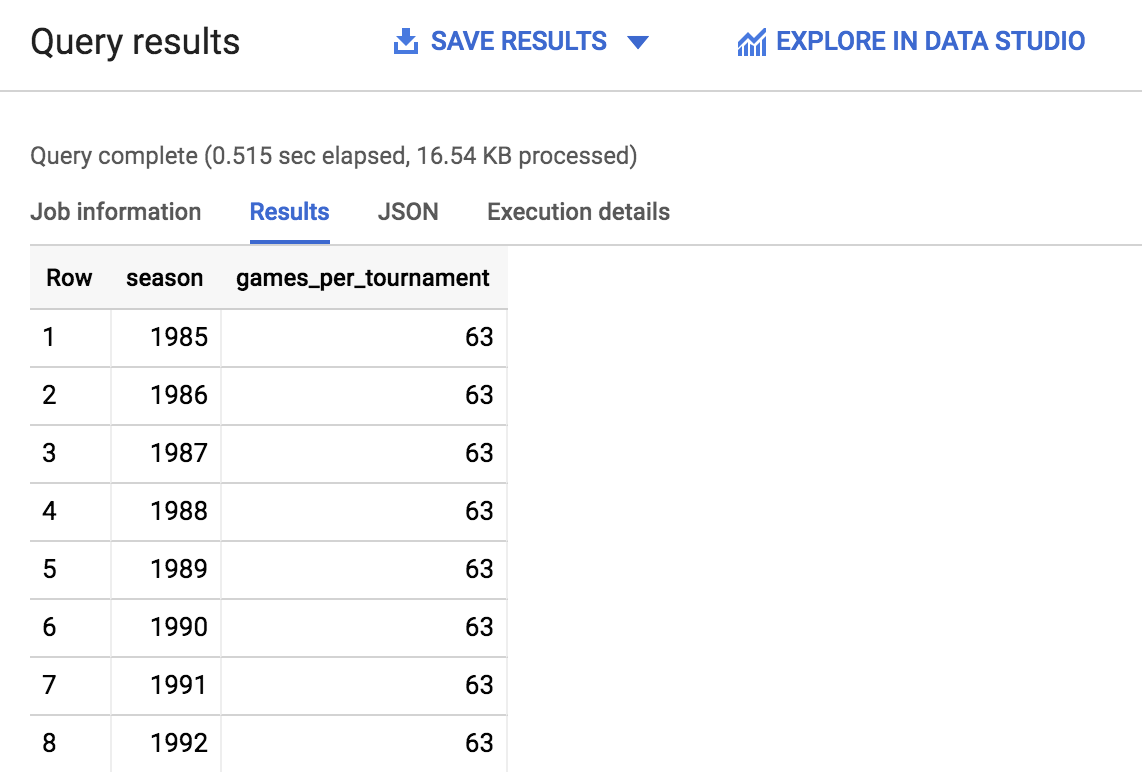
- 滚动浏览输出内容,并记录赛季数和每个赛季的比赛场次,您将使用这些信息回答以下问题。此外,您还可以在右下角分页箭头旁边,快速查看返回了多少行结果。
点击检查我的进度,验证已完成以下目标:
编写一个查询来确定能浏览到的赛季和比赛
检验您的掌握情况
下列多选题可以强化您对目前为止所涉概念的理解。请尽您所能回答。
任务 5. 理解机器学习中的特征和标签
本实验的最终目标是利用历史比赛数据,预测特定场次 NCAA 男子篮球比赛的胜负结果。在机器学习中,每一列能帮助我们确定结果(一场锦标赛比赛的胜负)的数据都被称为特征。
要预测的那列数据则被称为“标签”。机器学习模型会“学习”特征之间的关联,来预测标签的结果。
历史数据集的特征样本可能包括:
- 赛季
- 队伍名称
- 对阵队伍的名称
- 队伍种子(排名)
- 对阵队伍的种子排名
您为未来比赛尝试预测的标签将是“比赛结果”,即队伍胜负。
检验您的掌握情况
下列多选题可以强化您对目前为止所涉概念的理解。请尽您所能回答。
任务 6. 创建加标签的机器学习数据集
构建机器学习模型需要大量高质量的训练数据。幸运的是,我们的 NCAA 数据集足够强大,我们可以依靠它构建有效的模型。
-
返回到 BigQuery 控制台,您上次中断的地方应该是您所运行查询的结果位置。
-
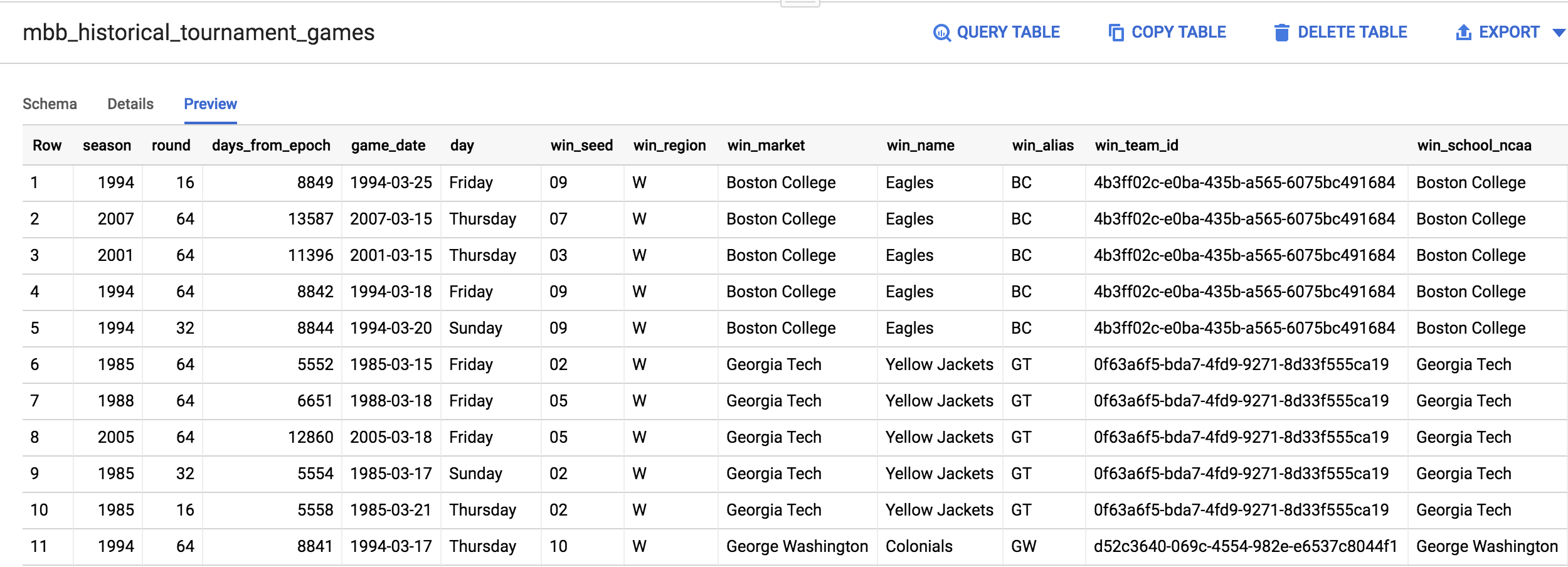
在左侧菜单点击 mbb_historical_tournament_games 表格名称,打开该表格。表格加载后,点击预览。您应该会看到类似下图的页面:
检验您的掌握情况
下列多选题可以强化您对目前为止所涉概念的理解。请尽您所能回答。
-
检查数据集后,您会发现数据集中有一行既包含 win_market 列,也包含 lose_market 列。您需要将单个比赛记录拆分成每支队伍的记录,以便为每行加上“获胜队”或“失败队”的标签。
-
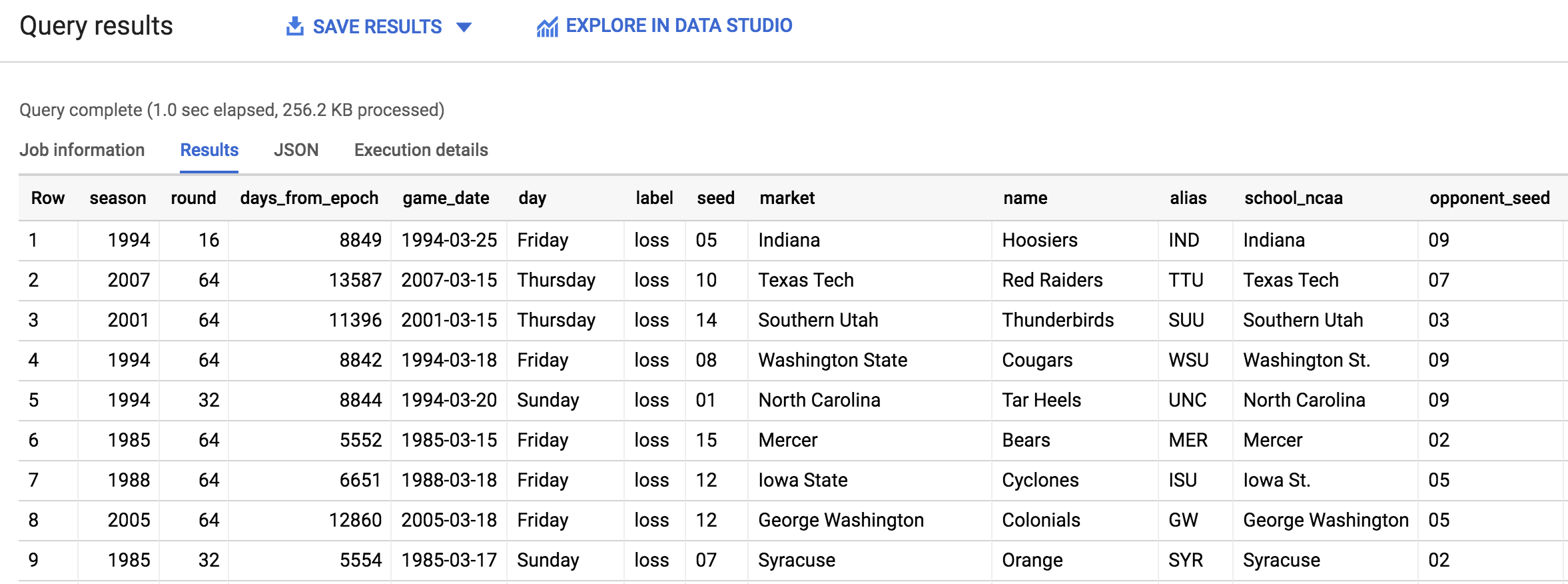
在查询编辑器中复制和粘贴以下查询,然后点击运行:
# create a row for the winning team
SELECT
# features
season, # ex: 2015 season has March 2016 tournament games
round, # sweet 16
days_from_epoch, # how old is the game
game_date,
day, # Friday
'win' AS label, # our label
win_seed AS seed, # ranking
win_market AS market,
win_name AS name,
win_alias AS alias,
win_school_ncaa AS school_ncaa,
# win_pts AS points,
lose_seed AS opponent_seed, # ranking
lose_market AS opponent_market,
lose_name AS opponent_name,
lose_alias AS opponent_alias,
lose_school_ncaa AS opponent_school_ncaa
# lose_pts AS opponent_points
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
UNION ALL
# create a separate row for the losing team
SELECT
# features
season,
round,
days_from_epoch,
game_date,
day,
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_market AS market,
lose_name AS name,
lose_alias AS alias,
lose_school_ncaa AS school_ncaa,
# lose_pts AS points,
win_seed AS opponent_seed, # ranking
win_market AS opponent_market,
win_name AS opponent_name,
win_alias AS opponent_alias,
win_school_ncaa AS opponent_school_ncaa
# win_pts AS opponent_points
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
您应该会看到下面的输出内容:
点击检查我的进度,验证已完成以下目标:
创建加标签的机器学习数据集
现在,您已经知道结果中有哪些特征,请回答下列问题来强化您对数据集的理解。
任务 7. 根据种子排名和队伍名称,创建一个机器学习模型来预测胜负结果。
现在我们已经浏览了数据,该训练一个机器学习模型了。
- 请根据自己的判断来回答以下问题,以便了解本节内容。
选择模型类型
对于此特定问题,您将构建一个分类模型。由于我们的模型有胜和负两个类别,因此也被称为二元分类模型。一支队伍在比赛中既可能获胜,也可能失败。
如果您有兴趣,可以在本实验之后使用预测模型来预测一支队伍将获得的总积分,但这并非本实验的重点。
要轻松分辨您是在做预测还是在做分类,可以看一下您要预测的数据标签(列)的类型:
- 如果列值是数字(例如销售数量或比赛积分),那么您是在做预测
- 如果列值是字符串,那么您是在做分类(该行既可以是这个类别,也可以是另外一个类别)
- 如果有两个以上类别(例如胜、负或平),那么您是在做多类别分类
我们的分类模型将利用一种称为“逻辑回归”的统计模型来进行机器学习,这种模型的使用十分广泛。
我们需要的模型能为每个可能的离散标签值生成一个概率,在我们的案例中,标签值是“胜”或“负”。为此,逻辑回归是一个很好的入门模型类型。好消息是机器学习模型会在模型训练过程中为您承担所有的数学计算和优化工作,而这正是计算机真正擅长的事情!
注意:还有许多其他机器学习模型,它们在执行分类任务方面的复杂程度各不相同。Google 常用的一种模型是深度学习和神经网络。
利用 BigQuery ML 创建机器学习模型
要在 BigQuery 中创建分类模型,只需编写 SQL 语句 CREATE MODEL 并提供一些选项。
但在创建模型之前,我们需要先在项目中找个地方存放模型。
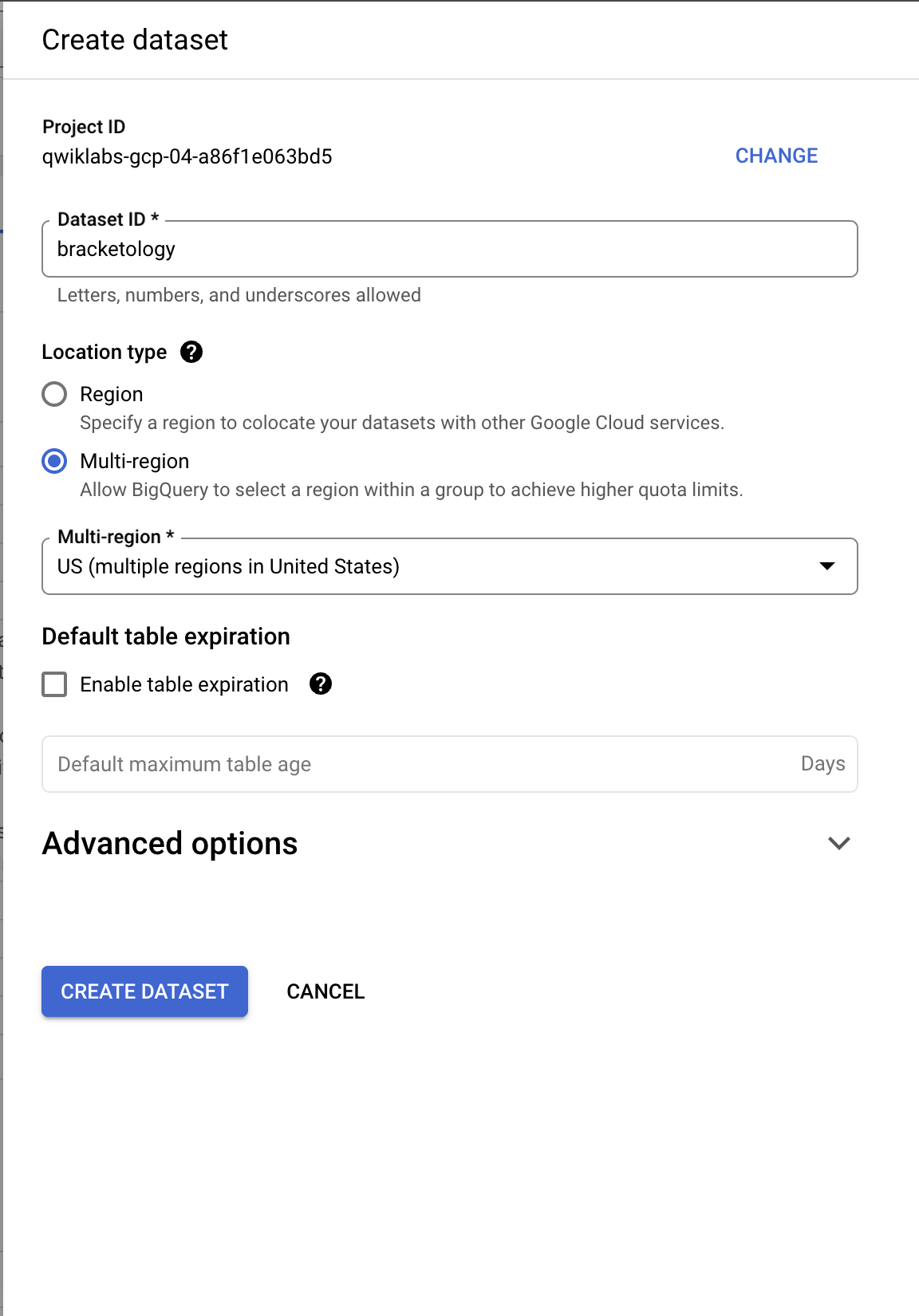
- 在“探索器”标签页中点击项目 ID 旁边的查看操作图标,并选择创建数据集。
- 这将打开创建数据集对话框。将您的数据集 ID 设置到
bracketology 并点击创建数据集。
- 现在,在查询编辑器中运行以下命令
CREATE OR REPLACE MODEL
`bracketology.ncaa_model`
OPTIONS
( model_type='logistic_reg') AS
# create a row for the winning team
SELECT
# features
season,
'win' AS label, # our label
win_seed AS seed, # ranking
win_school_ncaa AS school_ncaa,
lose_seed AS opponent_seed, # ranking
lose_school_ncaa AS opponent_school_ncaa
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
WHERE season <= 2017
UNION ALL
# create a separate row for the losing team
SELECT
# features
season,
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_school_ncaa AS school_ncaa,
win_seed AS opponent_seed, # ranking
win_school_ncaa AS opponent_school_ncaa
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
# now we split our dataset with a WHERE clause so we can train on a subset of data and then evaluate and test the model's performance against a reserved subset so the model doesn't memorize or overfit to the training data.
# tournament season information from 1985 - 2017
# here we'll train on 1985 - 2017 and predict for 2018
WHERE season <= 2017
在我们的代码中,您会发现创建模型只需几行 SQL 代码。最重要的选项之一是为我们的分类任务选择模型类型 logistic_reg。
注意:参阅 BigQuery ML 文档向导,查看所有可用模型选项和设置清单。在我们的案例中,我们已经有一个名为“标签”的字段,因此我们可以使用模型选项 input_label_cols 来避免指定标签列。
训练模型需要 3 到 5 分钟时间。该作业完成时,您应该会看到下面的输出内容:

- 点击控制台右侧的前往模型按钮。
点击检查我的进度,验证已完成以下目标:
创建机器学习模型
查看关于模型训练的详细信息
- 现在您已进入模型详细信息页面,向下滚动到训练选项部分并查看模型实际进行的迭代训练。
如果您已经有使用机器学习的经验,请注意,您可以在 OPTIONS 语句中定义所有这些超参数(模型运行前设置的选项)的值,从而对其进行自定义。
如果您是机器学习方面的新手,BigQuery ML 将为任何未设置的选项设置智能默认值。
请参阅 BigQuery ML 模型选项清单了解详情。
查看模型训练统计数据
机器学习模型会“学习”已知特征和未知标签之间的关联。您凭直觉可能会猜到,相较比赛在星期几举行等数据列(特征),“种子排名”或“学校名称”等特征可能更有助于确定胜负结果的预测。
机器学习模型是在没有此类直觉的情况下开始训练过程的,并且通常会随机确定每个特征的权重。
在训练过程中,模型将对确定每个特征最佳权重的路径进行优化。模型每次运行时都会尽量减少训练数据损失和评估数据损失。
如果您发现最终评估损失远高于最终训练损失,这说明您的模型出现过拟合或者是在记忆训练数据,而不是学习可概括的关系。
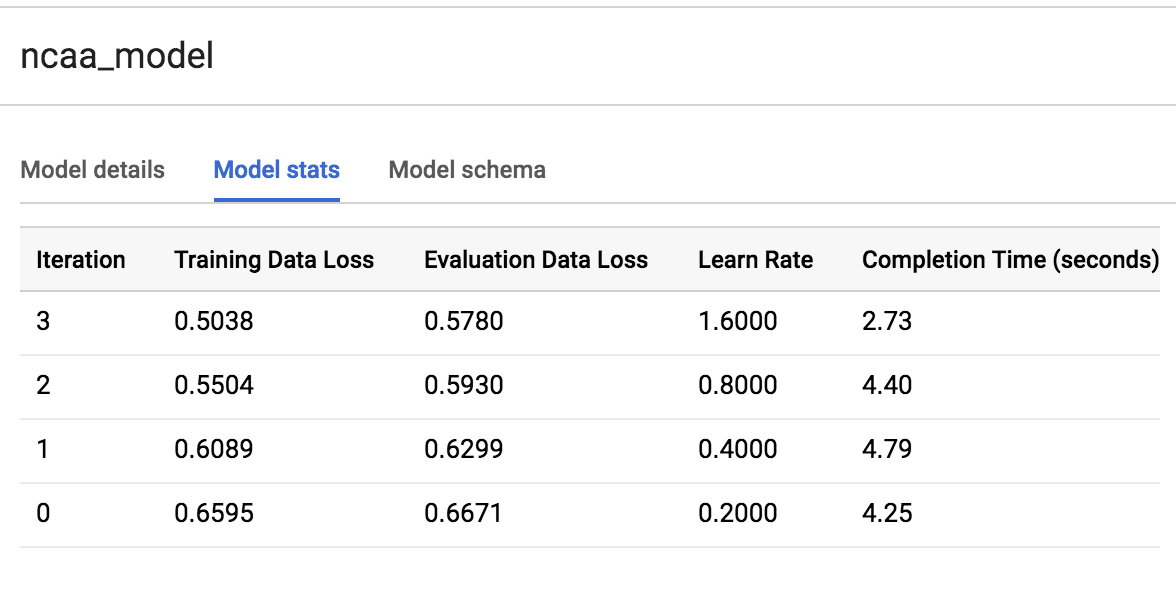
点击训练标签页并选择“查看方式”选项下的表格,可以查看模型的训练运行次数。
在我们的特定运行过程中,模型在大约 20 秒内完成了 3 次训练迭代。您的运行过程可能会有所不同。
查看模型对特征的了解程度
您可在训练后检查权重,了解哪些特征为模型提供的价值最大。
SELECT
category,
weight
FROM
UNNEST((
SELECT
category_weights
FROM
ML.WEIGHTS(MODEL `bracketology.ncaa_model`)
WHERE
processed_input = 'seed')) # try other features like 'school_ncaa'
ORDER BY weight DESC
输出应类似于以下内容:
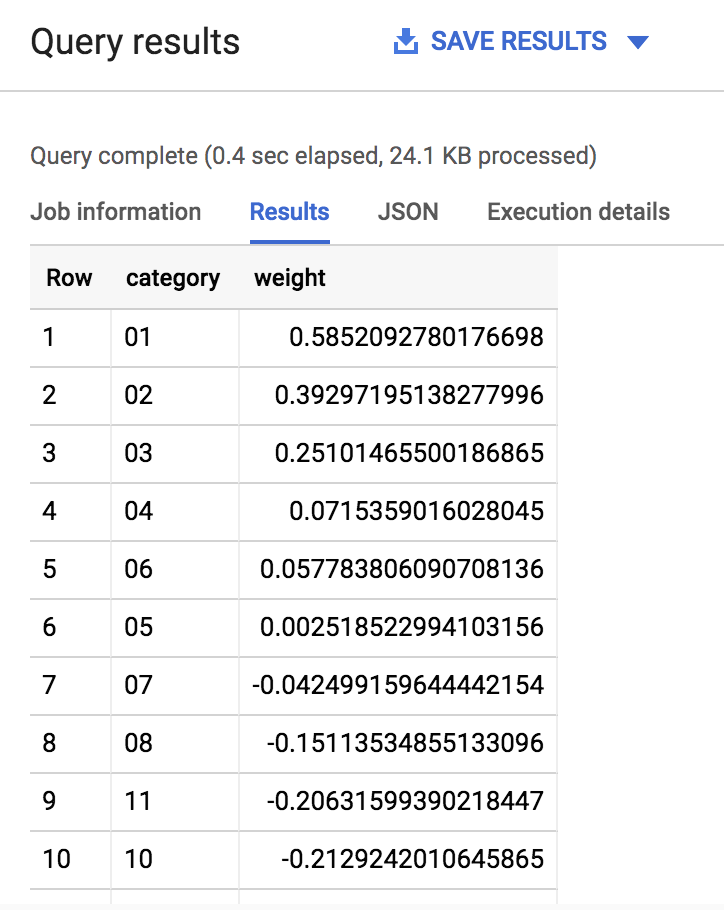
如您所见,如果一支队伍的种子排名很靠前(1、2、3)或很很靠后(14、15、16),那么模型在确定胜负结果时会赋予“种子排名”绝对值较高的权重(最高为 1.0)。凭直觉而言,这是有道理的,因为我们预计种子排名很靠前的队伍在锦标赛中会有良好表现。
机器学习的真正魔力在于,我们并未在 SQL 中创建大量硬编码的 IF THEN 语句,告诉模型 IF 种子排名为 1,THEN 队伍获胜的概率增加 80%。机器学习摒弃了硬编码规则和逻辑,而是依靠自己来学习这些关系。查看 BQML 语法权重文档了解详情。
任务 8. 评估模型性能
要评估模型的性能,可以对经过训练的模型运行一个简单的 ML.EVALUATE。
SELECT
*
FROM
ML.EVALUATE(MODEL `bracketology.ncaa_model`)
您应该会收到类似如下输出结果:

准确率的值约为 69%。虽然此结果比扔硬币准确一些,但仍有改进的空间。
注意:对于分类模型而言,模型准确率并非唯一应该考量的输出指标。
由于您执行的是逻辑回归,因此可以根据下列所有指标来评估模型性能(结果越接近 1.0 越好):
精确率:分类模型指标。精确率指模型正确预测正类别的频率。
召回率:分类模型指标,可为您提供以下信息:在所有可能的正例标签中,模型正确识别了多少个标签?
准确率:准确率是分类模型做出正确预测的比例。
F1 得分:用于衡量模型的准确率。F1 得分是精确率和召回率的调和平均数。F1 得分的最佳值为 1。最差值为 0。
log_loss:逻辑回归中所用的损失函数。该指标用于衡量模型的预测结果与正确标签之间的差距。
roc_auc:ROC 曲线下面积。这是指分类服务认为相比于随机选择的负例,随机选择的正例确实为正的概率更高。
任务 9. 进行预测
现在,您已经根据截至 2017 赛季(包括 2017 赛季)的历史数据(这是您所掌握的全部数据)训练了一个模型,可以对 2018 赛季进行预测了。您的数据科学团队刚刚在一份单独的表格中为您提供了 2018 年锦标赛的比赛结果,而您的原始数据集中没有这些数据。
进行预测非常简单,只需在经过训练的模型上调用 ML.PREDICT,然后传入为预测提供依据的数据集即可。
CREATE OR REPLACE TABLE `bracketology.predictions` AS (
SELECT * FROM ML.PREDICT(MODEL `bracketology.ncaa_model`,
# predicting for 2018 tournament games (2017 season)
(SELECT * FROM `data-to-insights.ncaa.2018_tournament_results`)
)
)
您应该很快会收到类似如下输出结果:

点击检查我的进度,验证已完成以下目标:
评估模型性能并创建表格
注意:您正将预测结果保存在一份表格内,以便日后查询并获取分析洞见,而无需不断重新运行以上查询。
现在,您将看到原始数据集和新增的三列:
既然您恰好知道 2018 年 March Madness 锦标赛的结果,那就让我们看看模型的预测结果如何。(提示:如果您要预测今年 March Madness 锦标赛的结果,你只需传入一个包含 2019 年种子排名和队伍名称的数据集。当然,由于比赛尚未进行,标签栏将是空的,这是您要预测的内容!)
任务 10. 对于 2018 年 NCAA 锦标赛,我们的模型预测准确率如何?
SELECT * FROM `bracketology.predictions`
WHERE predicted_label <> label
您应该会收到类似如下输出结果:
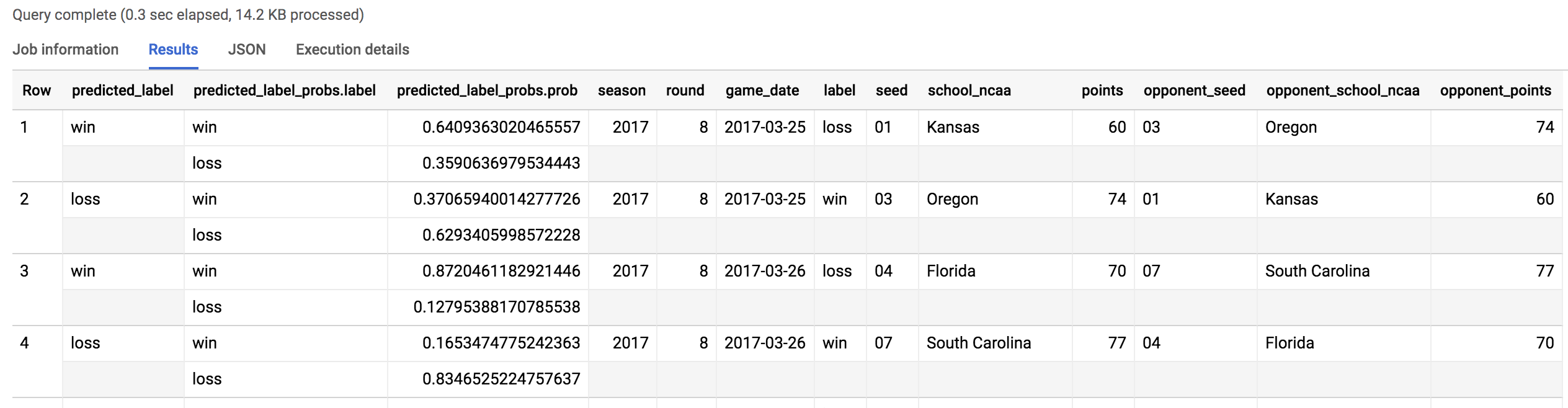
在 134 次预测中(67 场 3 月份锦标赛比赛),我们的模型有 38 次预测错误。即模型对于 2018 年锦标赛比赛的总体预测准确率为 70%。
任务 11. 模型只能做到这种程度…
任何一次 March Madness 锦标赛中都会出现模型很难预测到的险胜和爆冷结局,这其中有许多其他因素和特征在起作用。
让我们根据模型找出 2017 年锦标赛的最大爆冷。我们将看看模型以高于 80% 的置信度做出的错误预测。
- 在查询编辑器中运行以下命令:
SELECT
model.label AS predicted_label,
model.prob AS confidence,
predictions.label AS correct_label,
game_date,
round,
seed,
school_ncaa,
points,
opponent_seed,
opponent_school_ncaa,
opponent_points
FROM `bracketology.predictions` AS predictions,
UNNEST(predicted_label_probs) AS model
WHERE model.prob > .8 AND predicted_label <> predictions.label
结果应如下所示:
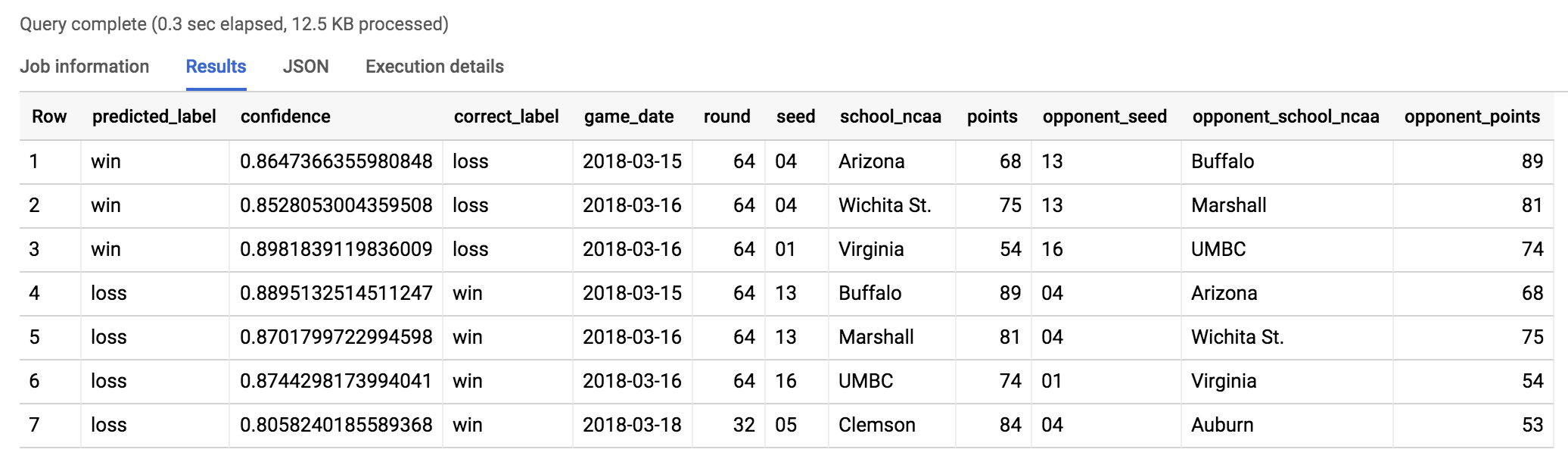
预测:模型以 87% 的置信度预测 1 号种子弗吉尼亚大学 (Virginia) 将击败 16 号种子马里兰大学巴尔的摩郡分校队 (UMBC)。这个结果似乎很合理,对吗?
看一下视频“16-seed UMBC pulls off a miracle upset over 1-seed Virginia”(16 号种子 UMBC 爆冷战胜头号种子弗吉尼亚大学),了解一下比赛的实际情况吧!
教练 Odom (UMBC) 赛后表示:“难以置信,我只能这么说。”参阅 2018 UMBC vs. Virginia men's basketball game(2018 年男子篮球 UMBC 对战弗吉尼亚大学)一文。
回顾
- 您创建了一个机器学习模型来预测比赛结果。
- 您评估了模型性能,并以种子排名和队伍名称作为主要特征实现了 69% 的预测准确率
- 您预测了 2018 年锦标赛的结果
- 您分析了结果,获取了洞见
我们的下一个挑战将是:不以种子排名和队伍名称作为特征来构建一个更好的模型。
任务 12. 使用技术性机器学习模型特征
在本实验的第二部分,您将使用新提供的详细特征再构建一个机器学习模型。
既然您已经熟悉了使用 BigQuery ML 来构建机器学习模型,您的数据科学团队便为您提供了一个新的比赛详情数据集,并在其中创建了新的队伍指标来供您的模型学习。其中包括:
- 基于对历史比赛详情进行分析而得出的长期得分效率。
- 长期持球回合。
利用这些技术特征来创建一个新的机器学习数据集
# create training dataset:
# create a row for the winning team
CREATE OR REPLACE TABLE `bracketology.training_new_features` AS
WITH outcomes AS (
SELECT
# features
season, # 1994
'win' AS label, # our label
win_seed AS seed, # ranking # this time without seed even
win_school_ncaa AS school_ncaa,
lose_seed AS opponent_seed, # ranking
lose_school_ncaa AS opponent_school_ncaa
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games` t
WHERE season >= 2014
UNION ALL
# create a separate row for the losing team
SELECT
# features
season, # 1994
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_school_ncaa AS school_ncaa,
win_seed AS opponent_seed, # ranking
win_school_ncaa AS opponent_school_ncaa
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games` t
WHERE season >= 2014
UNION ALL
# add in 2018 tournament game results not part of the public dataset:
SELECT
season,
label,
seed,
school_ncaa,
opponent_seed,
opponent_school_ncaa
FROM
`data-to-insights.ncaa.2018_tournament_results`
)
SELECT
o.season,
label,
# our team
seed,
school_ncaa,
# new pace metrics (basketball possession)
team.pace_rank,
team.poss_40min,
team.pace_rating,
# new efficiency metrics (scoring over time)
team.efficiency_rank,
team.pts_100poss,
team.efficiency_rating,
# opposing team
opponent_seed,
opponent_school_ncaa,
# new pace metrics (basketball possession)
opp.pace_rank AS opp_pace_rank,
opp.poss_40min AS opp_poss_40min,
opp.pace_rating AS opp_pace_rating,
# new efficiency metrics (scoring over time)
opp.efficiency_rank AS opp_efficiency_rank,
opp.pts_100poss AS opp_pts_100poss,
opp.efficiency_rating AS opp_efficiency_rating,
# a little feature engineering (take the difference in stats)
# new pace metrics (basketball possession)
opp.pace_rank - team.pace_rank AS pace_rank_diff,
opp.poss_40min - team.poss_40min AS pace_stat_diff,
opp.pace_rating - team.pace_rating AS pace_rating_diff,
# new efficiency metrics (scoring over time)
opp.efficiency_rank - team.efficiency_rank AS eff_rank_diff,
opp.pts_100poss - team.pts_100poss AS eff_stat_diff,
opp.efficiency_rating - team.efficiency_rating AS eff_rating_diff
FROM outcomes AS o
LEFT JOIN `data-to-insights.ncaa.feature_engineering` AS team
ON o.school_ncaa = team.team AND o.season = team.season
LEFT JOIN `data-to-insights.ncaa.feature_engineering` AS opp
ON o.opponent_school_ncaa = opp.team AND o.season = opp.season
您应该很快会收到类似如下输出结果:

点击检查我的进度,验证已完成以下目标:
使用技术性机器学习模型特征
任务 13. 预览新特征
- 点击控制台右侧的前往表格按钮。然后点击预览标签页。
您的表格应该与下面的示例类似:
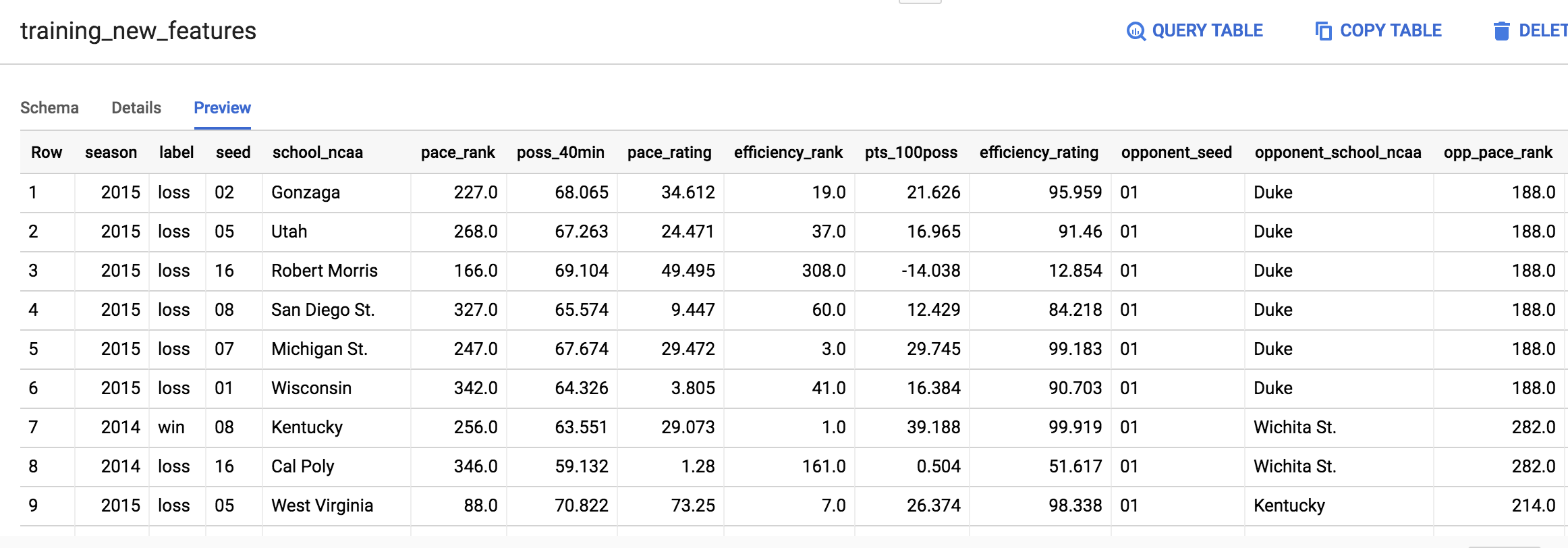
如果您的输出结果与以上屏幕截图不完全相同,请不要担心。
任务 14. 解释所选指标
opp_efficiency_rank
对手的效率排名:在所有队伍中,我们对手的长期得分效率(每 100 次持球回合内的得分)排名如何。数字越小越好。
opp_pace_rank
对手的回合数排名:在所有队伍中,我们对手的持球回合(40 分钟内的回合数)排名如何。数字越小越好。
现在,您已获得关于队伍得分和持球能力的特征来帮助您获取分析洞见,那么让我们再训练一个模型吧。
为进一步防止您的模型“记忆历史战绩好的队伍”,将队伍名称和种子排名从下一个模型中剔除,只专注于得分和持球指标。
任务 15. 训练新模型
CREATE OR REPLACE MODEL
`bracketology.ncaa_model_updated`
OPTIONS
( model_type='logistic_reg') AS
SELECT
# this time, don't train the model on school name or seed
season,
label,
# our pace
poss_40min,
pace_rank,
pace_rating,
# opponent pace
opp_poss_40min,
opp_pace_rank,
opp_pace_rating,
# difference in pace
pace_rank_diff,
pace_stat_diff,
pace_rating_diff,
# our efficiency
pts_100poss,
efficiency_rank,
efficiency_rating,
# opponent efficiency
opp_pts_100poss,
opp_efficiency_rank,
opp_efficiency_rating,
# difference in efficiency
eff_rank_diff,
eff_stat_diff,
eff_rating_diff
FROM `bracketology.training_new_features`
# here we'll train on 2014 - 2017 and predict on 2018
WHERE season BETWEEN 2014 AND 2017 # between in SQL is inclusive of end points
您应很快看到类似于以下示例的输出:
任务 16. 评估新模型的性能
SELECT
*
FROM
ML.EVALUATE(MODEL `bracketology.ncaa_model_updated`)
您的输出应如下所示:

哇!您刚刚用不同的特征训练了一个新模型,并且将准确率提高到了 75% 左右,即在原模型的基础上提高了约 5%。
这是我们在机器学习中获得的最有益经验之一,即高质量的特征数据集会对模型的准确率产生巨大的影响。
点击检查我的进度,验证已完成以下目标:
训练新模型并进行评估
任务 17. 检查模型的学习成果
- 模型在预测胜/负结果时对哪些特征赋予了最高权重?在查询编辑器中运行以下命令来了解这一点:
SELECT
*
FROM
ML.WEIGHTS(MODEL `bracketology.ncaa_model_updated`)
ORDER BY ABS(weight) DESC
输出的内容应如下所示:
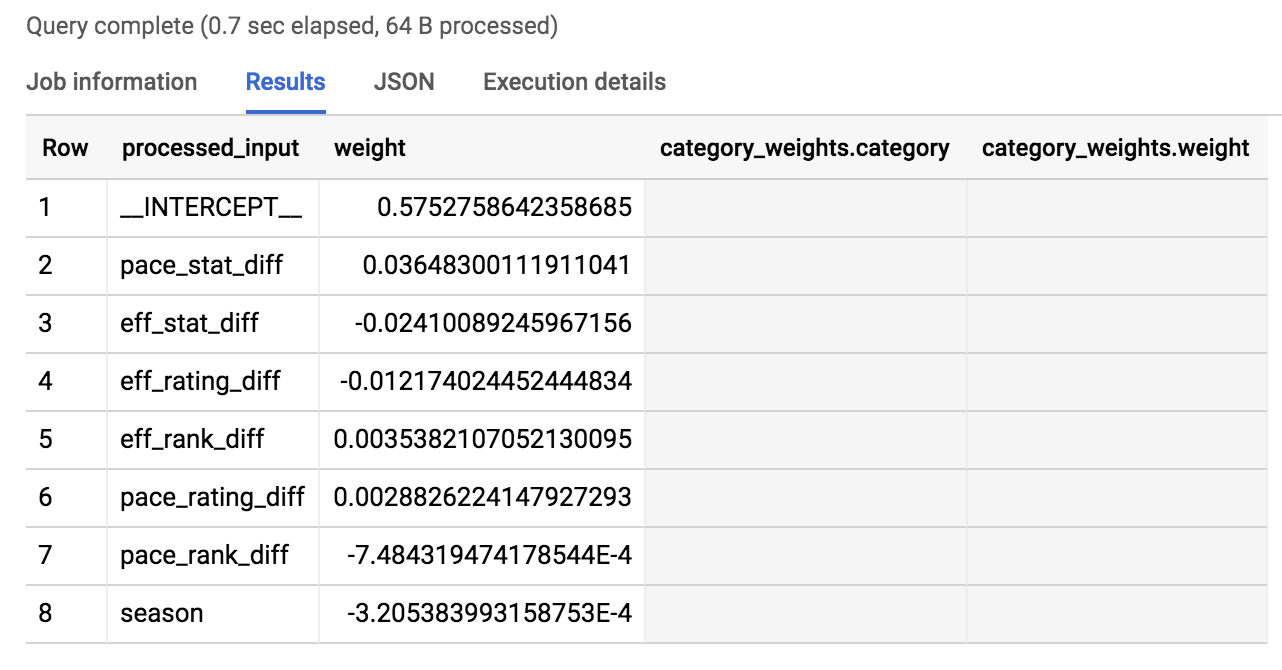
我们在排序时取权重的绝对值,以便(对胜负)影响最大的特征排列在最前面。
如结果所示,排在前 3 的是 pace_stat_diff、eff_stat_diff 和 eff_rating_diff。我们稍微深入研究一下。
pace_stat_diff
队伍之间(持球回合/ 40 分钟)的实际统计数据有多大差异。根据本模型,这是选择比赛结果的最大驱动因素。
eff_stat_diff
队伍之间(净得分/ 100 个持球回合)的实际统计数据有多大差异。
eff_rating_diff
队伍之间得分效率的标准化排名有多大差异。
模型在预测中对哪些特征赋予的权重不高?赛季。它在以上权重排名输出中位列最后。原因是模型认为赛季(2013 年、2014 年、2015 年)对预测比赛结果不是很有用。对于所有队伍来说,“2014”这个年份的影响都不大。
一个有趣的分析洞见是:模型更看重队伍的持球回合(控球能力)而不是得分效率。
任务 18. 预测时间!
CREATE OR REPLACE TABLE `bracketology.ncaa_2018_predictions` AS
# let's add back our other data columns for context
SELECT
*
FROM
ML.PREDICT(MODEL `bracketology.ncaa_model_updated`, (
SELECT
* # include all columns now (the model has already been trained)
FROM `bracketology.training_new_features`
WHERE season = 2018
))
输出应该类似于以下内容:

点击检查我的进度,验证已完成以下目标:
运行查询来创建表格 ncaa_2018_predictions
任务 19. 预测分析:
既然您已经知道比赛结果了,就可以使用新的测试数据集来了解模型做出了哪些错误预测。
SELECT * FROM `bracketology.ncaa_2018_predictions`
WHERE predicted_label <> label
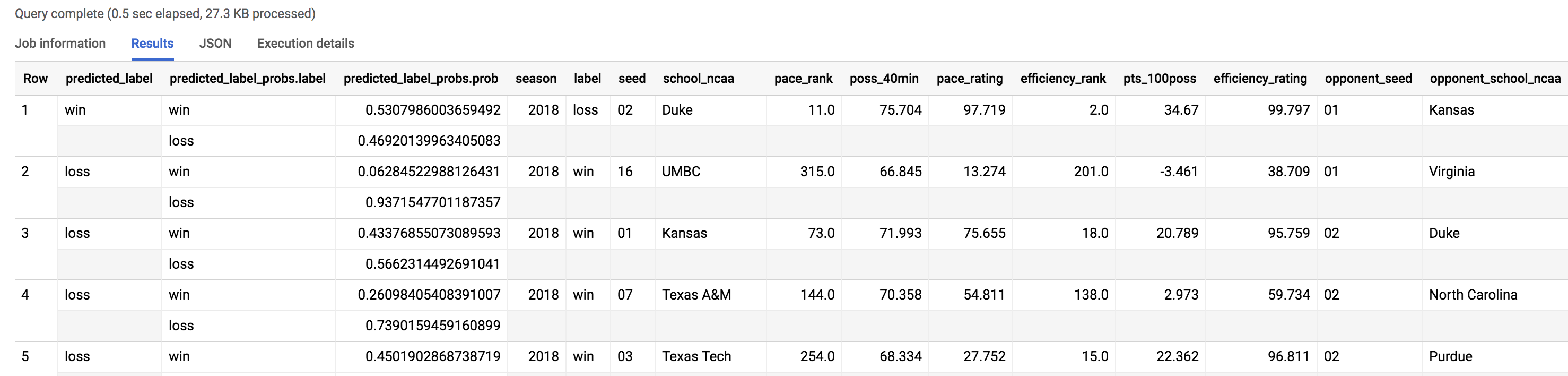
从查询所返回的记录数可以看出,在锦标赛所有对阵中,模型对 48 场对阵(24 场比赛)的预测错误,说明其对 2018 年锦标赛的预测准确率为 64%。2018 年锦标赛一定极具戏剧性,让我们看看有哪些爆冷出现。
任务 20. 2018 年 3 月的比赛中出现了哪些爆冷?
SELECT
CONCAT(school_ncaa, " was predicted to ",IF(predicted_label="loss","lose","win")," ",CAST(ROUND(p.prob,2)*100 AS STRING), "% but ", IF(n.label="loss","lost","won")) AS narrative,
predicted_label, # what the model thought
n.label, # what actually happened
ROUND(p.prob,2) AS probability,
season,
# us
seed,
school_ncaa,
pace_rank,
efficiency_rank,
# them
opponent_seed,
opponent_school_ncaa,
opp_pace_rank,
opp_efficiency_rank
FROM `bracketology.ncaa_2018_predictions` AS n,
UNNEST(predicted_label_probs) AS p
WHERE
predicted_label <> n.label # model got it wrong
AND p.prob > .75 # by more than 75% confidence
ORDER BY prob DESC
结果应如下所示:
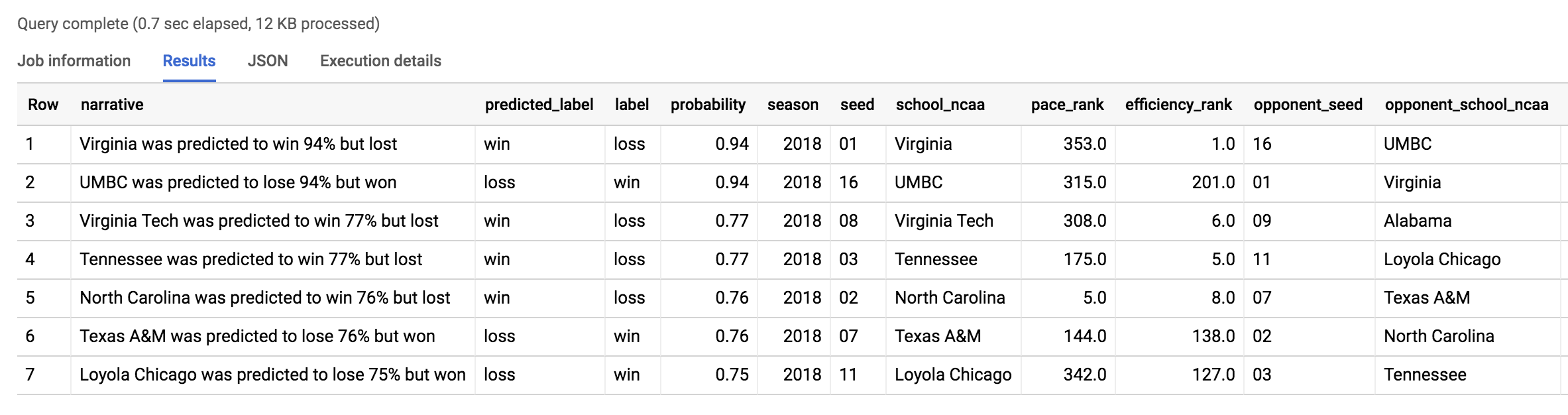
最大爆冷就是我们上一个模型所发现的:UMBC 队对阵弗吉尼亚大学队。2018 年锦标赛频频爆冷,详情请参阅 Has This Been the “Maddest” March?(这是最“疯狂”的 3 月吗?)一文。2019 年是否也会如此具有戏剧性?
任务 21. 比较模型性能
简单模型(比较种子排名)做出错误预测而先进模型做出正确预测的比赛有哪些?
SELECT
CONCAT(opponent_school_ncaa, " (", opponent_seed, ") was ",CAST(ROUND(ROUND(p.prob,2)*100,2) AS STRING),"% predicted to upset ", school_ncaa, " (", seed, ") and did!") AS narrative,
predicted_label, # what the model thought
n.label, # what actually happened
ROUND(p.prob,2) AS probability,
season,
# us
seed,
school_ncaa,
pace_rank,
efficiency_rank,
# them
opponent_seed,
opponent_school_ncaa,
opp_pace_rank,
opp_efficiency_rank,
(CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) AS seed_diff
FROM `bracketology.ncaa_2018_predictions` AS n,
UNNEST(predicted_label_probs) AS p
WHERE
predicted_label = 'loss'
AND predicted_label = n.label # model got it right
AND p.prob >= .55 # by 55%+ confidence
AND (CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) > 2 # seed difference magnitude
ORDER BY (CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) DESC
结果应如下所示:

模型预测 9 号种子佛罗里达州立大学队 (Florida St.) 将爆冷击败头号种子哈维尔大学队 (Xavier),事实的确如此!
根据持球回合和投篮效率等新的技术特征,新模型准确预测出这次爆冷(即便根据种子排名的预测结果正好相反)。在 YouTube 上观看比赛精彩片段。
任务 22. 对 2019 年 March Madness 锦标赛进行预测
既然我们已经知道 2019 年 3 月锦标赛的参赛队伍及其种子排名了,那么让我们预测一下未来比赛的结果吧。
研究 2019 年锦标赛的数据
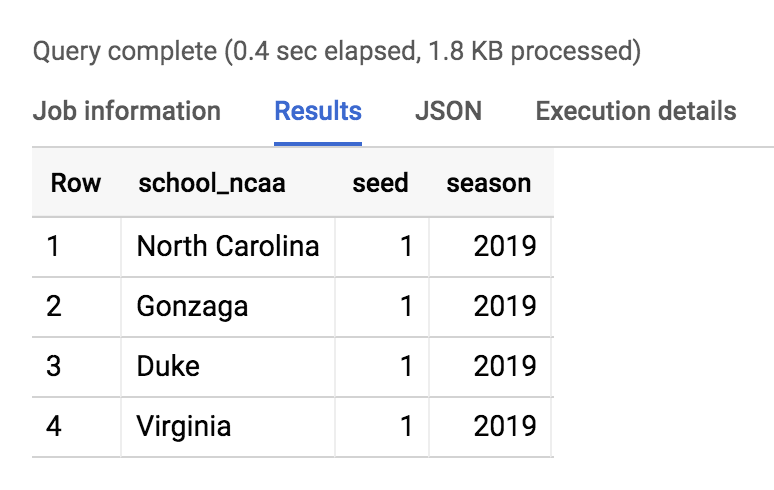
SELECT * FROM `data-to-insights.ncaa.2019_tournament_seeds` WHERE seed = 1
结果应如下所示:
创建一个矩阵,其中包含所有可能进行的比赛
我们不知道随着锦标赛的进行各队伍的对阵情况,因此我们简单预测一支队伍将会与所有其他支队伍对阵。
在 SQL 中,要编制一份显示一支队伍与所有其他支队伍对阵的表格,一个比较简单的方法是采用交叉联接。
SELECT
NULL AS label,
team.school_ncaa AS team_school_ncaa,
team.seed AS team_seed,
opp.school_ncaa AS opp_school_ncaa,
opp.seed AS opp_seed
FROM `data-to-insights.ncaa.2019_tournament_seeds` AS team
CROSS JOIN `data-to-insights.ncaa.2019_tournament_seeds` AS opp
# teams cannot play against themselves :)
WHERE team.school_ncaa <> opp.school_ncaa
添加 2018 年锦标赛参赛队伍的统计数据(持球回合、效率)
CREATE OR REPLACE TABLE `bracketology.ncaa_2019_tournament` AS
WITH team_seeds_all_possible_games AS (
SELECT
NULL AS label,
team.school_ncaa AS school_ncaa,
team.seed AS seed,
opp.school_ncaa AS opponent_school_ncaa,
opp.seed AS opponent_seed
FROM `data-to-insights.ncaa.2019_tournament_seeds` AS team
CROSS JOIN `data-to-insights.ncaa.2019_tournament_seeds` AS opp
# teams cannot play against themselves :)
WHERE team.school_ncaa <> opp.school_ncaa
)
, add_in_2018_season_stats AS (
SELECT
team_seeds_all_possible_games.*,
# bring in features from the 2018 regular season for each team
(SELECT AS STRUCT * FROM `data-to-insights.ncaa.feature_engineering` WHERE school_ncaa = team AND season = 2018) AS team,
(SELECT AS STRUCT * FROM `data-to-insights.ncaa.feature_engineering` WHERE opponent_school_ncaa = team AND season = 2018) AS opp
FROM team_seeds_all_possible_games
)
# Preparing 2019 data for prediction
SELECT
label,
2019 AS season, # 2018-2019 tournament season
# our team
seed,
school_ncaa,
# new pace metrics (basketball possession)
team.pace_rank,
team.poss_40min,
team.pace_rating,
# new efficiency metrics (scoring over time)
team.efficiency_rank,
team.pts_100poss,
team.efficiency_rating,
# opposing team
opponent_seed,
opponent_school_ncaa,
# new pace metrics (basketball possession)
opp.pace_rank AS opp_pace_rank,
opp.poss_40min AS opp_poss_40min,
opp.pace_rating AS opp_pace_rating,
# new efficiency metrics (scoring over time)
opp.efficiency_rank AS opp_efficiency_rank,
opp.pts_100poss AS opp_pts_100poss,
opp.efficiency_rating AS opp_efficiency_rating,
# a little feature engineering (take the difference in stats)
# new pace metrics (basketball possession)
opp.pace_rank - team.pace_rank AS pace_rank_diff,
opp.poss_40min - team.poss_40min AS pace_stat_diff,
opp.pace_rating - team.pace_rating AS pace_rating_diff,
# new efficiency metrics (scoring over time)
opp.efficiency_rank - team.efficiency_rank AS eff_rank_diff,
opp.pts_100poss - team.pts_100poss AS eff_stat_diff,
opp.efficiency_rating - team.efficiency_rating AS eff_rating_diff
FROM add_in_2018_season_stats
做出预测
CREATE OR REPLACE TABLE `bracketology.ncaa_2019_tournament_predictions` AS
SELECT
*
FROM
# let's predicted using the newer model
ML.PREDICT(MODEL `bracketology.ncaa_model_updated`, (
# let's predict on March 2019 tournament games:
SELECT * FROM `bracketology.ncaa_2019_tournament`
))
点击检查我的进度,验证已完成以下目标:
运行查询,创建表格 ncaa_2019_tournament 和 ncaa_2019_tournament_predictions
获得预测结果
SELECT
p.label AS prediction,
ROUND(p.prob,3) AS confidence,
school_ncaa,
seed,
opponent_school_ncaa,
opponent_seed
FROM `bracketology.ncaa_2019_tournament_predictions`,
UNNEST(predicted_label_probs) AS p
WHERE p.prob >= .5
AND school_ncaa = 'Duke'
ORDER BY seed, opponent_seed
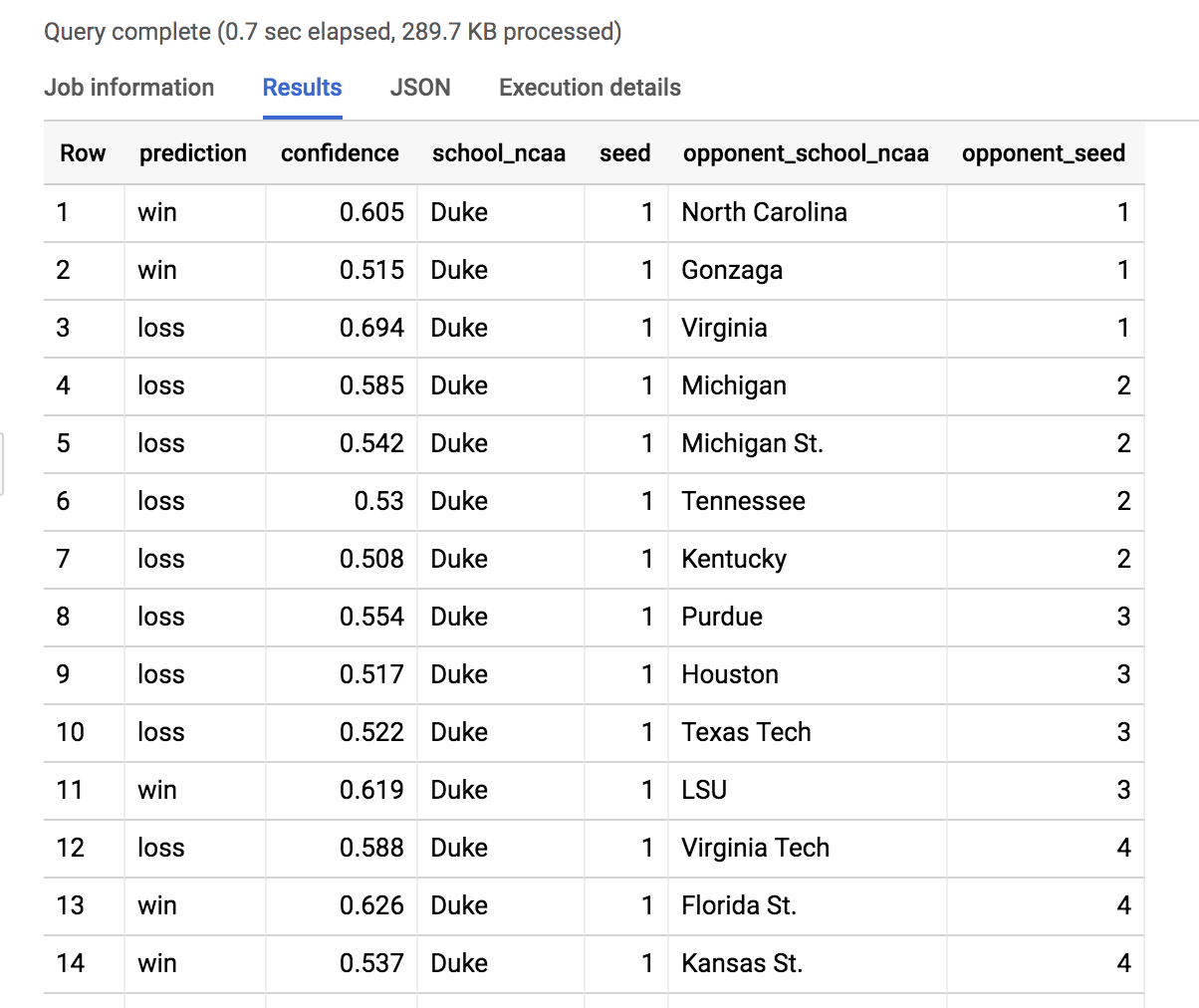
- 我们在其中对模型结果进行过滤,查看杜克大学队可能会参加的所有比赛。滚动找到杜克大学队对北达科他州立大学队 (North Dakota St.) 这场比赛。
分析洞见:在 2019 年 3 月 22 日进行的比赛中,头号种子杜克大学队有 88.5% 的概率击败 16 号种子北达科他州立大学队。
通过更改以上 school_ncaa 过滤条件来进行实验,从而对您所制定的对阵方案中的比赛结果做出预测。写下模型置信度,然后欣赏比赛吧!
恭喜!
您已使用 BigQuery ML 来预测 NCAA 男子篮球锦标赛的胜负。
后续步骤/了解详情
- 想详细了解篮球比赛指标和分析吗?查看 Google Cloud NCAA 锦标赛广告和预测团队所做的其他分析。
- 请查看以下实验:
Google Cloud 培训和认证
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
上次更新手册的时间:2024 年 3 月 19 日
上次测试实验的时间:2024 年 3 月 19 日
版权所有 2024 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。

