Checkpoints
Write a query to determine available seasons and games
/ 10
Create a labeled machine learning dataset
/ 10
Create a machine learning model
/ 20
Evaluate model performance and create table
/ 10
Using skillful ML model features
/ 10
Train the new model and make evaluation
/ 10
Run a query to create a table ncaa_2018_predictions
/ 10
Run queries to create tables ncaa_2019_tournament and ncaa_2019_tournament_predictions
/ 20
Chaveamento com o machine learning do Google
- GSP461
- Visão geral
- Configuração e requisitos
- Abra o console do BigQuery
- NCAA March Madness
- Localize o conjunto de dados público da NCAA no BigQuery
- Crie uma consulta para ver quais temporadas e partidas estão disponíveis
- Fundamentos dos atributos e rótulos de machine learning
- Crie um conjunto de dados rotulado para machine learning
- Parte 1: crie um modelo de machine learning para prever o vencedor com base na classificação e no nome do time
- Avalie o desempenho do modelo
- Como fazer previsões
- Quantos resultados do campeonato NCAA 2018 o modelo acertou?
- Os modelos também têm limitações
- Parte 2: como usar atributos especializados de modelos de ML
- Veja os novos atributos
- Como interpretar as métricas selecionadas
- Treine o novo modelo
- Avalie o desempenho do novo modelo
- Analise o que o modelo aprendeu
- Hora da previsão
- Análise das previsões:
- Quais foram as zebras em março de 2018?
- Como comparar o desempenho de modelos
- Previsão do campeonato March Madness 2019
- Parabéns!
GSP461

Visão geral
Neste laboratório, você irá prever o vencedor de um campeonato masculino da liga de basquete universitário dos EUA (NCAA, na sigla em inglês) usando BigQuery, machine learning (ML) e o conjunto de dados de basquete masculino da NCAA.
Este laboratório usa BigQuery Machine Learning (BQML), uma ferramenta para criar modelos de ML com SQL para classificação e previsão.
Atividades do laboratório
Neste laboratório, você aprenderá a fazer o seguinte:
- Usar o BigQuery para acessar o conjunto de dados público da NCAA
- Explorar o conjunto de dados da NCAA para se familiarizar com o esquema e o escopo dos dados disponíveis
- Preparar e transformar os dados em atributos e rótulos
- Dividir o conjunto de dados em subconjuntos de treinamento e avaliação
- Usar o BQML para criar um modelo baseado no conjunto de dados do campeonato da NCAA
- Usar o modelo que foi criado para prever os vencedores em uma chave do campeonato da NCAA
Pré-requisitos
Este é um laboratório de nível fundamental. Antes de realizar o laboratório, você deve ter alguma experiência com SQL e com as palavras-chave dessa linguagem. Também recomendamos conhecimento sobre BigQuery. Se for necessário se atualizar nessas áreas, faça ao menos os laboratórios abaixo antes de tentar fazer este:
Quando tudo estiver pronto, role para baixo, conheça os serviços disponíveis e aprenda como configurar corretamente o ambiente do laboratório.
BigQuery
O BigQuery é um banco de dados de análise NoOps, totalmente gerenciado e de baixo custo desenvolvido pelo Google. Com o BigQuery, é possível consultar vários terabytes de dados sem gerenciar infraestrutura e sem precisar de um administrador de banco de dados. O BigQuery usa SQL e é cobrado no modelo de pagamento por utilização. Assim, você pode se concentrar na análise dos dados para encontrar informações relevantes.
Um conjunto de dados de partidas, times e jogadores de basquete da NCAA foi recentemente disponibilizado. Os dados de partidas incluem informações de cada jogada e tabelas de pontos desde 2009, além de placares finais desde 1996. Outras dados sobre vitórias e derrotas remontam à temporada de 1894-1985 no caso de alguns times.
Machine Learning
O Google Cloud oferece diversas opções de machine learning para analistas e cientistas de dados. As mais comuns são:
- APIs Machine Learning: use APIs pré-treinadas, como Cloud Vision, para realizar tarefas comuns de machine learning.
- AutoML: crie modelos de machine learning personalizados sem precisar programar.
- BigQuery ML: use seu conhecimento de SQL para criar modelos de machine learning diretamente no BigQuery, onde os dados estão.
- AI Platform: crie modelos de machine learning personalizados e coloque-os em produção com a infraestrutura do Google.
Neste laboratório, você usará o BigQuery ML para prototipar, treinar, avaliar e prever os "vencedores" e os "derrotados" entre dois times de basquete do campeonato da NCAA.
Configuração e requisitos
Configuração do Qwiklabs
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como começar o laboratório e fazer login no Console
-
Clique no botão Start Lab. Se precisar pagar pelo laboratório, aparecerá uma caixa pop-up para selecionar a forma de pagamento. À esquerda, o painel Detalhes da conexão é preenchido com as credenciais temporárias que devem ser usadas no laboratório.
-
Copie o nome de usuário e clique em Abrir Console do Google. O laboratório inicia os recursos e depois abre a página Escolher uma conta em outra guia.
Dica: abra as guias em janelas separadas, lado a lado.
-
Na página "Escolher uma conta", clique em Usar outra conta.
-
A página de login é aberta. Cole o nome de usuário que foi copiado do painel "Detalhes da conexão". Em seguida, copie e cole a senha.
Importante: é preciso usar as credenciais do painel "Detalhes da conexão". Não use as credenciais do Qwiklabs. Não use sua conta pessoal do GCP, caso tenha uma, neste laboratório (isso evita cobranças).
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em avaliações gratuitas.


Depois de alguns instantes, o Console do GCP será aberto nesta guia.
Abra o console do BigQuery
No Console do Google Cloud, abra o Menu de navegação e selecione BigQuery:
Clique em Concluído para acessar a IU beta. Verifique se o ID do projeto do GCP no Qwiklabs aparece no menu "Recursos" à esquerda, como neste exemplo:
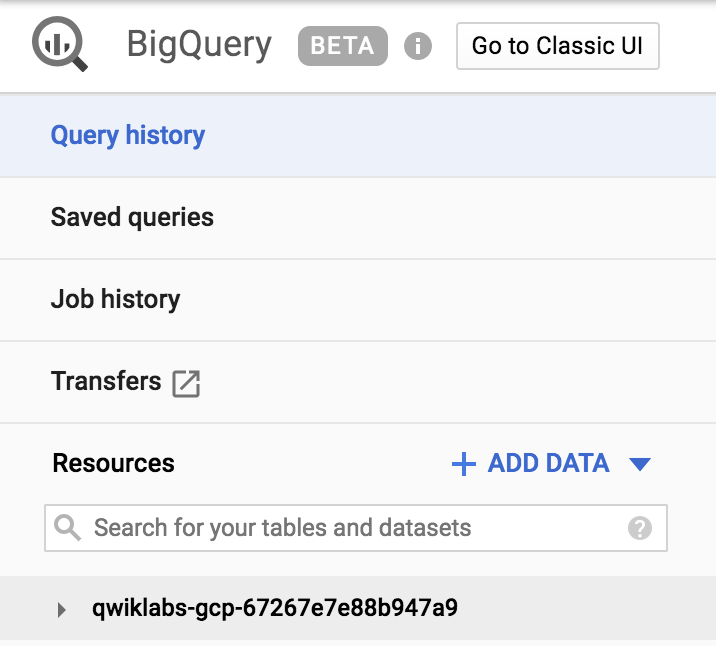
Se você clicar na seta suspensa ao lado do projeto, não aparecerá nenhum banco de dados ou tabela. Isso porque você ainda não os adicionou ao projeto.
Felizmente, há vários conjuntos de dados públicos disponíveis no BigQuery para você usar. Agora, você aprenderá mais sobre o conjunto de dados da NCAA e verá como adicionar o conjunto ao projeto do BigQuery.
NCAA March Madness
A Associação Nacional Atlética Universitária (NCAA, na sigla em inglês) realiza dois grandes campeonatos de basquete universitário nos Estados Unidos a cada ano, para times masculinos e femininos. No campeonato masculino da NCAA, conhecido como "March Madness", 68 times disputam partidas eliminatórias e um time sai como vencedor geral.
A NCAA oferece um conjunto de dados público que contém estatísticas sobre as partidas e jogadores das ligas masculina e feminina, para a temporada e campeonatos finais. Os dados de partidas incluem informações de cada jogada e tabelas de pontos desde 2009, além de placares finais desde 1996. Outras dados sobre vitórias e derrotas remontam à temporada de 1894-1985 no caso de alguns times.
Confira a campanha de marketing do Google Cloud sobre previsão de insights ao vivo, com mais informações sobre o conjunto de dados e as utilidades dele, e acompanhe o campeonato deste ano em: G.co/marchmadness
Localize o conjunto de dados público da NCAA no BigQuery
Esta etapa deve ser realizada no Console do BigQuery. Localize a guia "Recursos" no menu à esquerda. Clique no botão + ADICIONAR DADOS e selecione Explorar conjuntos de dados públicos.
Na barra de pesquisa, digite "NCAA Basketball" e pressione enter. Selecione o resultado que aparecer e clique em VER CONJUNTO DE DADOS:
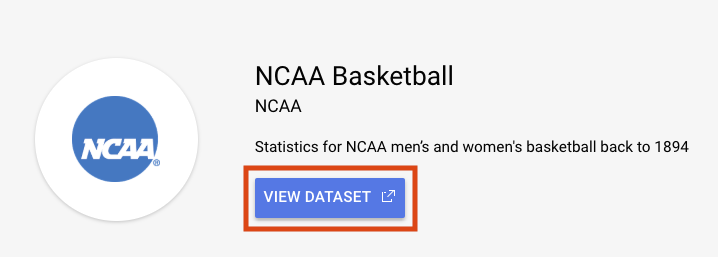
Será aberta uma nova guia do BigQuery com o conjunto de dados carregado. Continue trabalhando nessa guia ou feche-a e atualize o Console do BigQuery na outra guia para exibir o conjunto de dados público.
Clique na seta ao lado do conjunto de dados ncaa_basketball para exibir as tabelas:
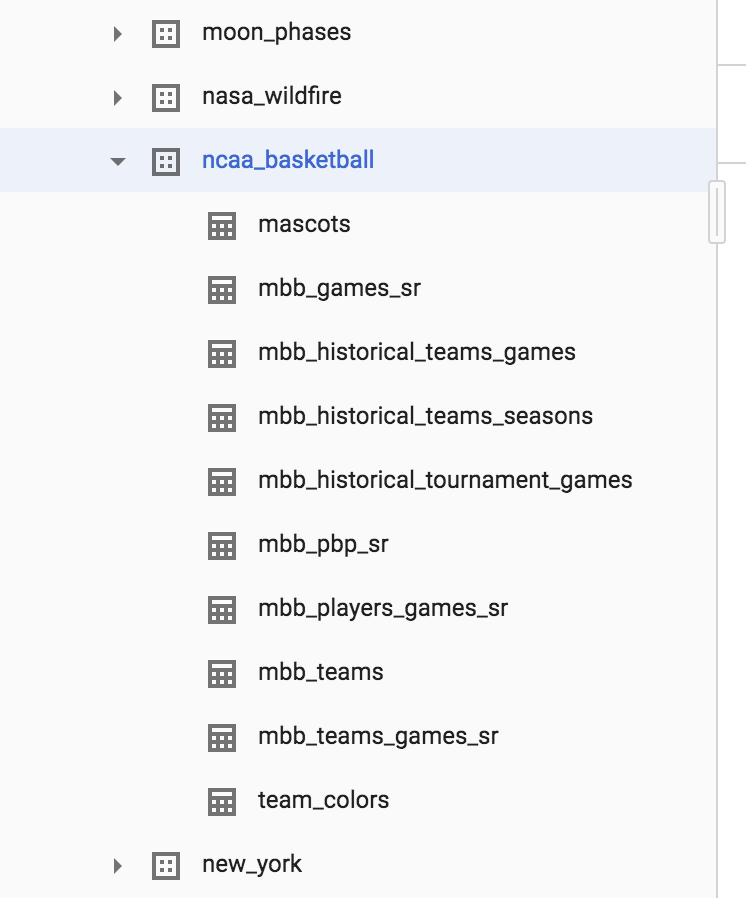
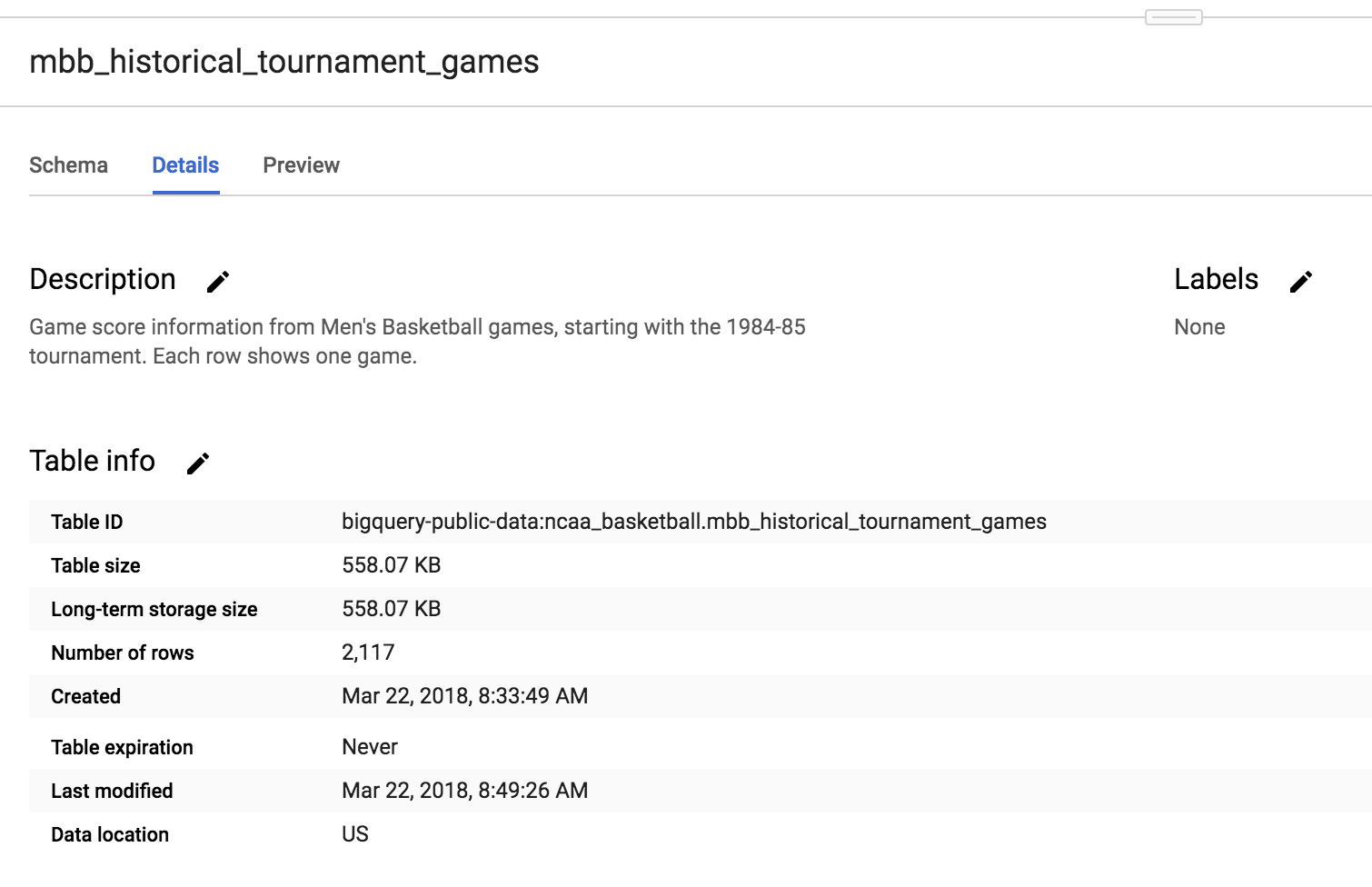
O conjunto de dados contém 10 tabelas. Clique na tabela mbb_historical_tournament_games e depois em Visualizar para ver uma amostra das linhas de dados. Clique em Detalhes para ver os metadados da tabela. Sua página deve ser semelhante a esta:
Crie uma consulta para ver quais temporadas e partidas estão disponíveis
Agora, você criará uma consulta SQL simples para ver quantas temporadas e jogos a tabela mbb_historical_tournament_games contém.
Localize o editor de consultas, que está acima da seção de detalhes da tabela. Em seguida, copie e cole o texto abaixo nesse campo:
SELECT
season,
COUNT(*) as games_per_tournament
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
GROUP BY season
ORDER BY season # default is Ascending (low to high)
Clique em Executar. Logo depois, você verá uma resposta parecida com esta:
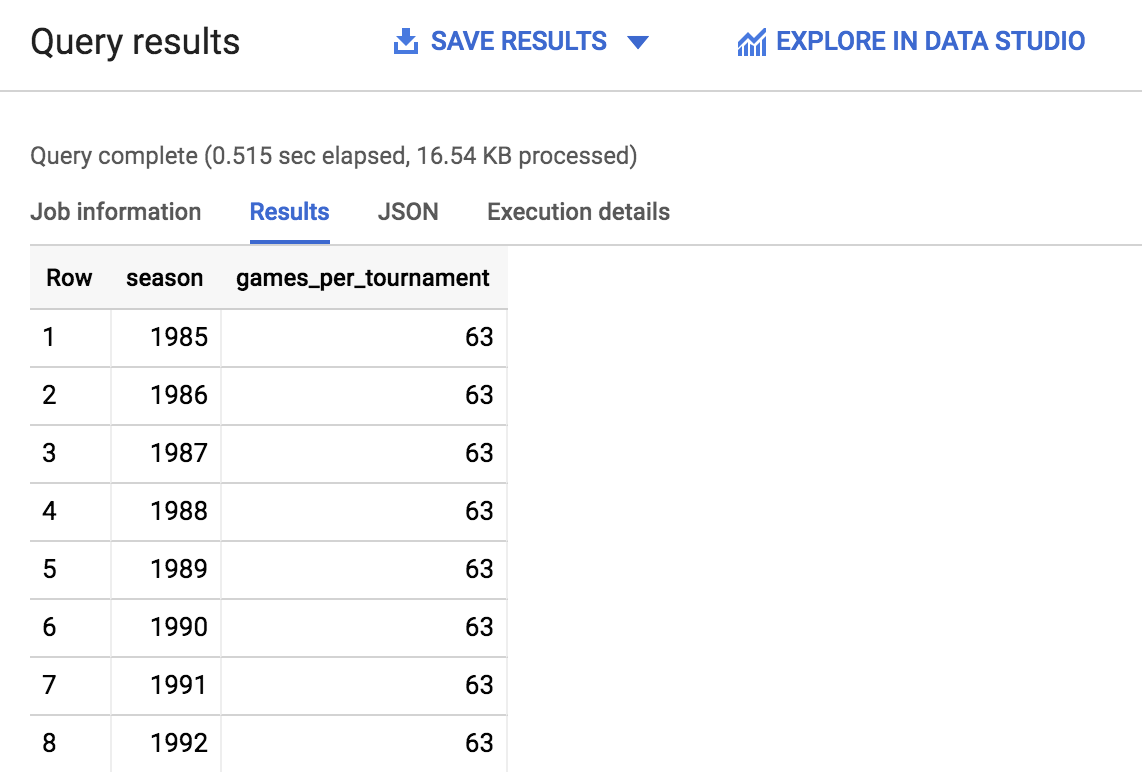
Role pelos dados e anote o número de temporadas e de partidas em cada temporada. Você usará essas informações para responder às perguntas a seguir. O número de linhas que foram retornadas é exibido no canto inferior direito, próximo às setas de paginação.
Clique em Verificar meu progresso para conferir o objetivo.
Teste seus conhecimentos
Responda às perguntas de múltipla escolha abaixo para reforçar os conceitos que você aprendeu até agora. Use tudo o que você aprendeu até aqui.
Fundamentos dos atributos e rótulos de machine learning
O objetivo deste laboratório é prever o vencedor de uma determinada partida de basquete masculino da NCAA usando conhecimento sobre jogos anteriores. Em machine learning, cada coluna de dados que ajuda a determinar o resultado (vitória ou derrota, no caso de uma partida) é chamada de atributo.
A coluna de dados que você tentará prever é chamada de rótulo. Modelos de machine learning "aprendem" qual é a associação entre os atributos para prever o resultado de um rótulo.
Veja exemplos de atributos no conjunto de dados histórico:
- Temporada
- Nome do time
- Nome do time adversário
- Classificação do time
- Classificação do time adversário
O rótulo que você tentará prever em partidas futuras é o resultado do jogo, ou seja, se um time venceu ou perdeu.
Teste seus conhecimentos
Responda às perguntas de múltipla escolha abaixo para reforçar os conceitos que você aprendeu até agora. Use tudo o que você aprendeu até aqui.
Crie um conjunto de dados rotulado para machine learning
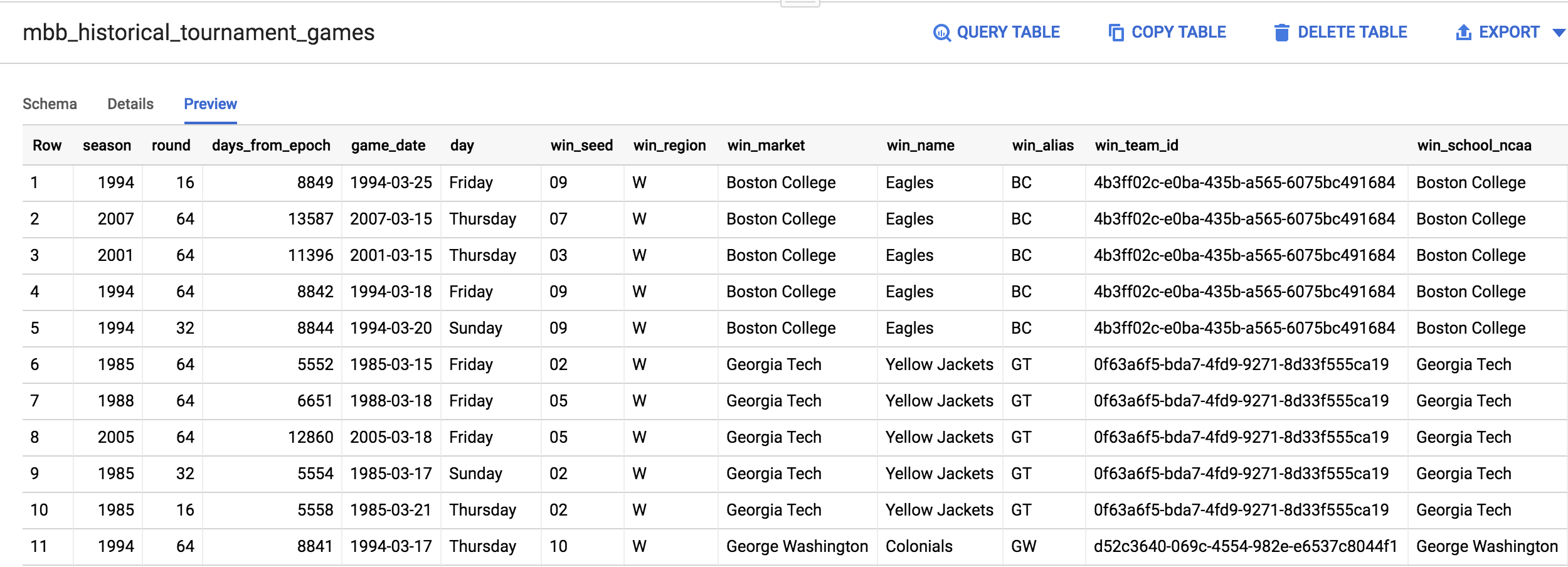
Para criar um modelo de machine learning, é preciso ter muitos dados de alta qualidade para treinamento. Felizmente, o conjunto de dados da NCAA é grande o suficiente para podermos criar um modelo eficaz com ele. Volte ao Console do BigQuery, que você deve ter deixado com o resultado da consulta executada.
No menu à esquerda, clique no nome mbb_historical_tournament_games para abrir a tabela. Quando ela carregar, clique em Visualizar. Sua página deve ser semelhante a esta:
Teste seus conhecimentos
Responda às perguntas de múltipla escolha abaixo para reforçar os conceitos que você aprendeu até agora. Use tudo o que você aprendeu até aqui.
Após inspecionar o conjunto de dados, perceba que uma linha contém as colunas de win_market e lose_market. É preciso dividir o registro da partida em um registro para cada time, a fim de rotular cada linha como "vencedor" ou "derrotado".
No Editor de consultas, copie e cole a consulta abaixo, depois clique em Executar:
# create a row for the winning team
SELECT
# features
season, # ex: 2015 season has March 2016 tournament games
round, # sweet 16
days_from_epoch, # how old is the game
game_date,
day, # Friday
'win' AS label, # our label
win_seed AS seed, # ranking
win_market AS market,
win_name AS name,
win_alias AS alias,
win_school_ncaa AS school_ncaa,
# win_pts AS points,
lose_seed AS opponent_seed, # ranking
lose_market AS opponent_market,
lose_name AS opponent_name,
lose_alias AS opponent_alias,
lose_school_ncaa AS opponent_school_ncaa
# lose_pts AS opponent_points
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
UNION ALL
# create a separate row for the losing team
SELECT
# features
season,
round,
days_from_epoch,
game_date,
day,
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_market AS market,
lose_name AS name,
lose_alias AS alias,
lose_school_ncaa AS school_ncaa,
# lose_pts AS points,
win_seed AS opponent_seed, # ranking
win_market AS opponent_market,
win_name AS opponent_name,
win_alias AS opponent_alias,
win_school_ncaa AS opponent_school_ncaa
# win_pts AS opponent_points
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
Você verá a seguinte resposta:
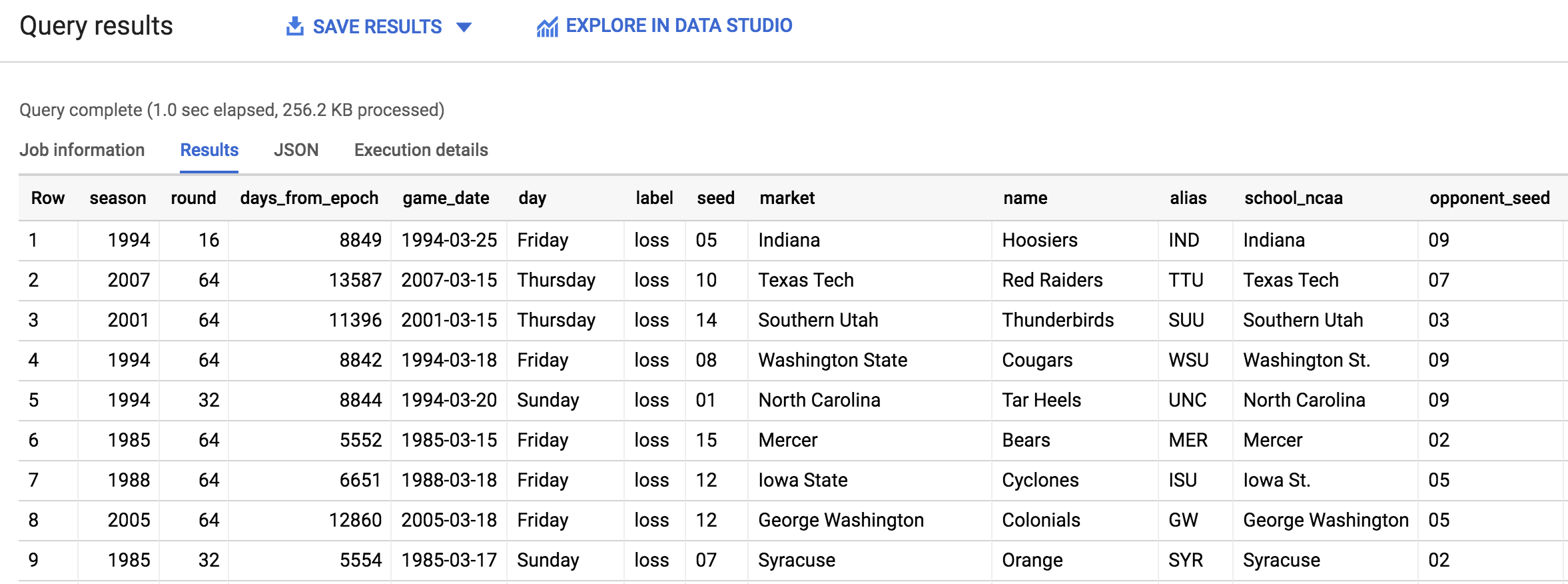
Clique em Verificar meu progresso para conferir o objetivo.
Agora que você sabe quais são os recursos disponíveis no resultado, responda à pergunta abaixo para entender melhor o conjunto de dados.
Parte 1: crie um modelo de machine learning para prever o vencedor com base na classificação e no nome do time
Agora que já exploramos os dados, é hora de treinar um modelo de machine learning. Responda à pergunta abaixo da melhor forma que puder, para se orientar melhor nesta seção.
Como escolher o tipo de modelo
Para este problema, você criará um modelo de classificação. Como há duas classes, vitória ou derrota, ele também é chamado de modelo de classificação binária. Um time pode ganhar ou perder uma partida.
Depois do laboratório, sugerimos que você tente usar um modelo de previsão para prever o número total de pontos que um time marcará, mas esse não será nosso foco aqui.
Um jeito fácil de diferenciar entre previsão e classificação é observar o tipo de rótulo (coluna) de dados que será previsto:
- Quando a coluna é numérica (por exemplo, unidades vendidas ou pontos em uma partida), trata-se de uma previsão.
- Quando é um valor de string, trata-se de uma classificação (a coluna ou está nesta classe ou está naquela outra classe).
- E quando há mais de duas classes (por exemplo, vitória, derrota ou empate), trata-se de uma classificação multiclasse.
Para realizar machine learning com um modelo de classificação, usaremos um modelo estatístico muito usado, chamado regressão logística. Precisamos de um modelo que gere uma probabilidade para cada valor discreto do rótulo, no nosso caso, "vitória" ou "derrota". Para fazer isso, a regressão logística é um bom tipo de modelo para começar. A parte boa é que o modelo de ML cuidará de toda a matemática e otimização no treinamento do modelo para você. É para isso que servem os computadores.
Como criar um modelo de machine learning com BigQuery ML
Para criar o modelo de classificação no BigQuery, basta escrever a instrução SQL CREATE MODEL e informar algumas opções.
Mas, antes de criar o modelo, precisamos de um local no nosso projeto para armazená-lo.
No menu à esquerda, selecione o projeto do Qwiklabs na lista "Recursos":
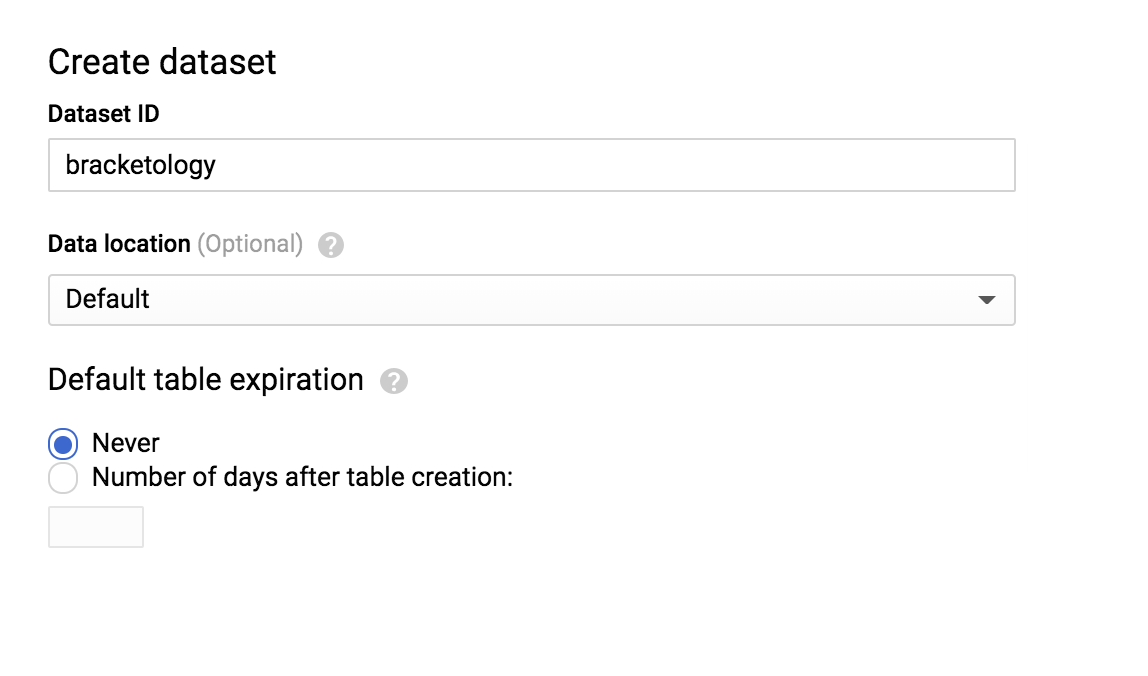
Em seguida, clique em CRIAR CONJUNTO DE DADOS no lado direito. Um menu será aberto. Escreva bracketology no ID do conjunto de dados e clique em Criar conjunto de dados:
Agora execute este comando no Editor de consultas:
CREATE OR REPLACE MODEL
`bracketology.ncaa_model`
OPTIONS
( model_type='logistic_reg') AS
# create a row for the winning team
SELECT
# features
season,
'win' AS label, # our label
win_seed AS seed, # ranking
win_school_ncaa AS school_ncaa,
lose_seed AS opponent_seed, # ranking
lose_school_ncaa AS opponent_school_ncaa
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
WHERE season <= 2017
UNION ALL
# create a separate row for the losing team
SELECT
# features
season,
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_school_ncaa AS school_ncaa,
win_seed AS opponent_seed, # ranking
win_school_ncaa AS opponent_school_ncaa
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
# now we split our dataset with a WHERE clause so we can train on a subset of data and then evaluate and test the model's performance against a reserved subset so the model doesn't memorize or overfit to the training data.
# tournament season information from 1985 - 2017
# here we'll train on 1985 - 2017 and predict for 2018
WHERE season <= 2017
No nosso código, a criação do modelo exige apenas algumas linhas de SQL. Uma das opções mais importantes é escolher o tipo de modelo logistic_reg para a tarefa de classificação.
O treinamento do modelo demora de três a cinco minutos. Quando o job terminar, será exibido o seguinte:

Clique no botão Ir para o modelo no lado direito do console.
Clique em Verificar meu progresso para conferir o objetivo.
Veja os detalhes do treinamento do modelo
Nos detalhes do modelo, role para baixo até a seção Opções de treinamento e veja as iterações que o modelo realizou no treinamento. Quem já tem experiência com machine learning pode personalizar todos esses hiperparâmetros (as opções definidas antes da execução do modelo). Para fazer isso, defina o valor deles na instrução OPTIONS. Para quem está começando, o BigQuery ML define valores padrão inteligentes para as opções que não foram definidas.
Veja mais informações na lista de opções de modelo do BigQuery ML.
Veja as estatísticas de treinamento do modelo
Modelos de machine learning "aprendem" a associação entre atributos conhecidos e rótulos desconhecidos. Como você deve imaginar, colunas (atributos) como "ranking seed" (classificação) ou "school name" (nome da faculdade) são mais úteis para prever a vitória ou derrota do que colunas como o dia da semana em que a partida foi realizada. Por não terem esse conhecimento intuitivo, os modelos de machine learning começam atribuindo pesos aleatórios a cada atributo.
No processo de treinamento, o modelo otimiza um caminho para a melhor ponderação de cada atributo. Em cada execução, ele tenta minimizar a perda de dados de treinamento e a perda de dados de avaliação. Quando a perda de avaliação final é muito maior do que a perda de treinamento, isso indica a ocorrência de overfitting, ou seja, o modelo está memorizando os dados de treinamento em vez de aprender relações genéricas.
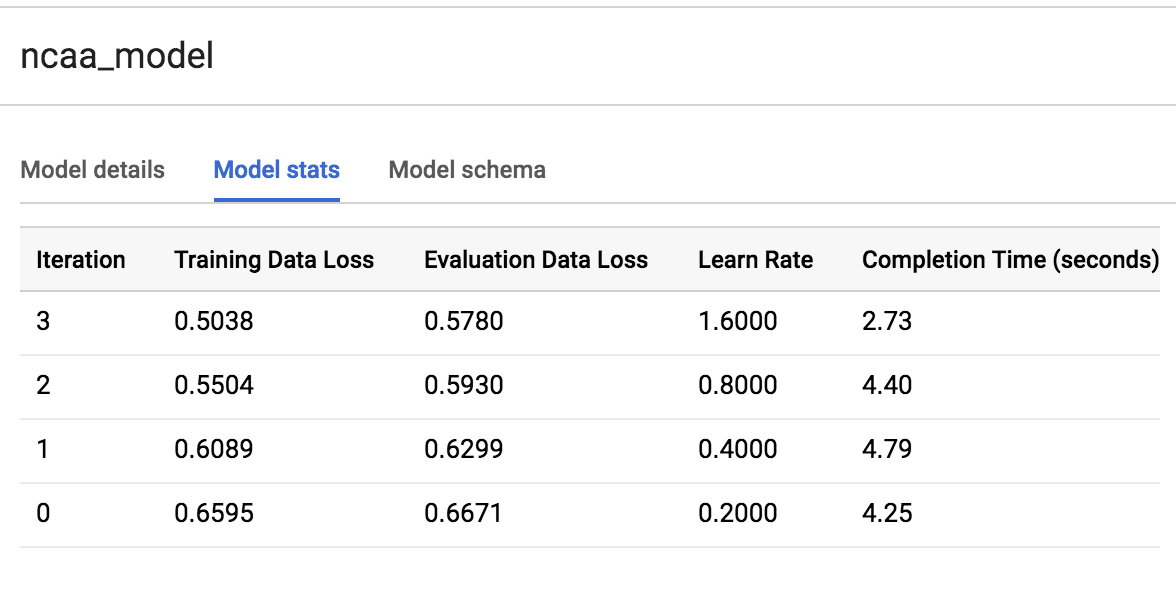
Para ver quantas execuções de treinamento o modelo realizou, clique na guia Estatísticas do modelo ou Treinamento. Na nossa execução, o modelo realizou três iterações de treinamento em cerca de 20 segundos. Sua execução provavelmente será diferente.
Veja o que o modelo aprendeu sobre os atributos
Após o treinamento, inspecione os pesos para ver quais atributos trouxeram mais valor ao modelo. Execute este comando no Editor de consultas:
SELECT
category,
weight
FROM
UNNEST((
SELECT
category_weights
FROM
ML.WEIGHTS(MODEL `bracketology.ncaa_model`)
WHERE
processed_input = 'seed')) # try other features like 'school_ncaa'
ORDER BY weight DESC
A resposta será parecida com esta:
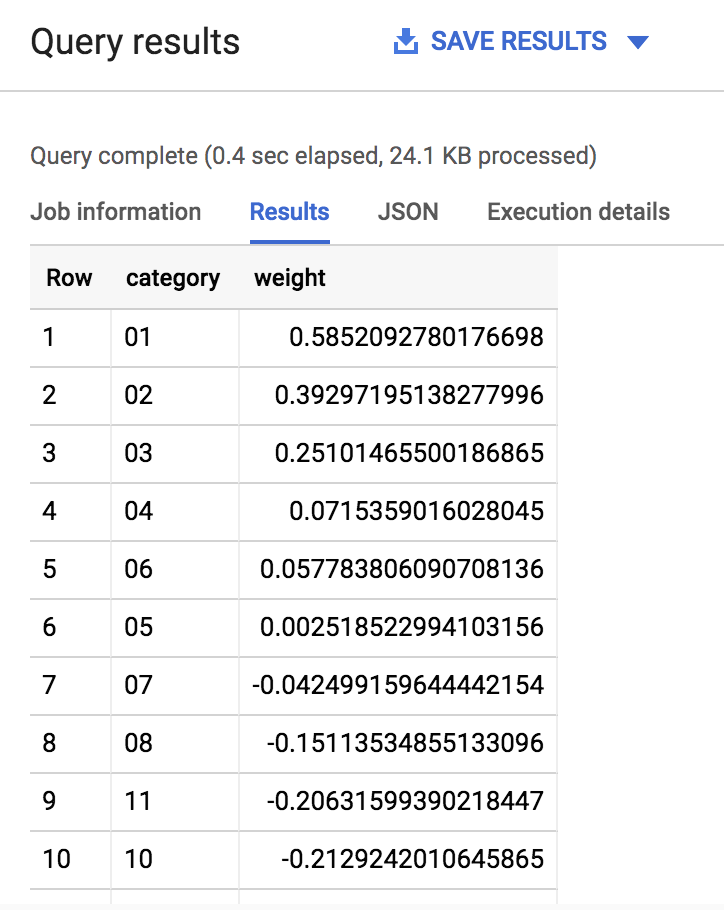
Como você pode ver, quando a seed (classificação) de um time é muito baixa (1,2,3) ou muito alta (14,15,16), o modelo atribui a ela um peso significativo (o máximo é 1) na determinação do resultado. Isso faz sentido, já que a expectativa é de que os times com classificação baixa tenham um bom desempenho no campeonato.
A grande vantagem do machine learning é que não foi preciso criar inúmeras instruções IF THEN manuais para dizer ao modelo que SE o "seed" for 1 ENTÃO dê à equipe 80% mais chance de vitória. O machine learning aprende essas relações por conta própria, eliminando regras e lógicas de codificação rígida. Veja mais informações na documentação de pesos da sintaxe do BQML.
Avalie o desempenho do modelo
Para avaliar o desempenho, execute uma instrução ML.EVALUATE simples no modelo treinado. Execute este comando no Editor de consultas:
SELECT
*
FROM
ML.EVALUATE(MODEL `bracketology.ncaa_model`)
Você verá uma resposta parecida com esta:

O valor tem acurácia de cerca de 69%. É mais preciso do que decidir por cara ou coroa, mas ainda podemos melhorar.
Como fazer previsões
Agora que você treinou um modelo com dados históricos até 2017 (que eram todos os dados disponíveis), é hora de fazer previsões para a temporada 2018. A equipe de ciência de dados forneceu a você os resultados do campeonato de 2018 em uma tabela separada, que não constava no conjunto de dados original.
Para fazer previsões, basta chamar ML.PREDICT em um modelo treinado, informando o conjunto de dados que será usado.
Execute este comando no Editor de consultas:
CREATE OR REPLACE TABLE `bracketology.predictions` AS (
SELECT * FROM ML.PREDICT(MODEL `bracketology.ncaa_model`,
# predicting for 2018 tournament games (2017 season)
(SELECT * FROM `data-to-insights.ncaa.2018_tournament_results`)
)
)
Logo depois, aparecerá um resultado como este:

Clique em Verificar meu progresso para conferir o objetivo.
Agora serão exibidos o conjunto de dados original e mais três novas colunas:
- Rótulo previsto
- Opções do rótulo previsto
- Probabilidade do rótulo previsto
Como você já sabe o resultado do campeonato March Madness de 2018, vejamos se o modelo acertou as previsões. Dica: para prever o campeonato March Madness deste ano, basta informar um conjunto de dados com as classificações e os nomes dos times de 2019. Obviamente, a coluna de rótulos estará vazia porque os jogos que você está tentando prever ainda não aconteceram.
Quantos resultados do campeonato NCAA 2018 o modelo acertou?
Execute este comando no Editor de consultas:
SELECT * FROM `bracketology.predictions`
WHERE predicted_label <> label
Você verá uma resposta parecida com esta:
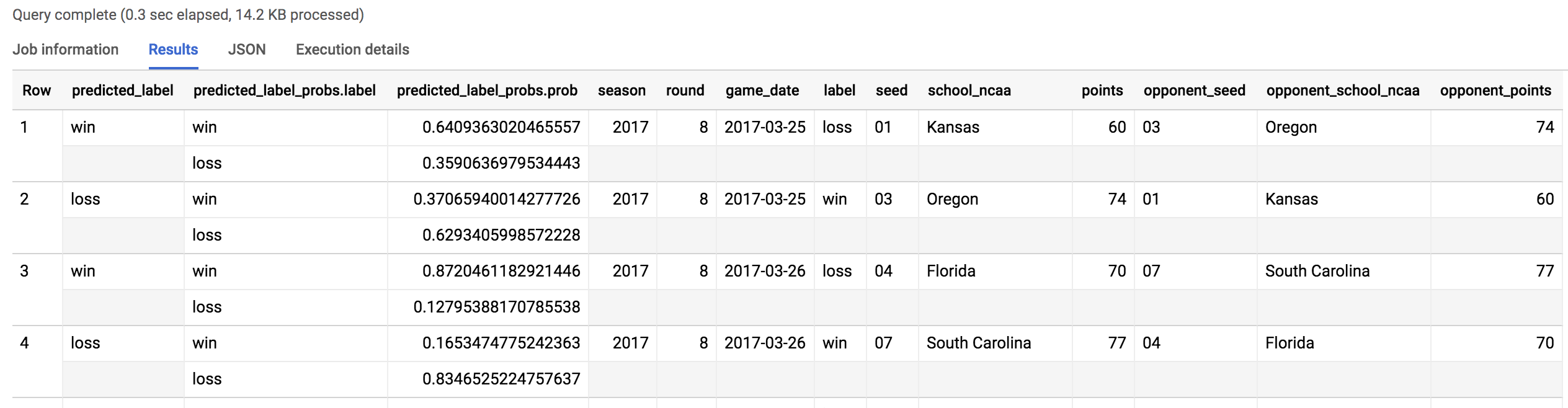
Dentre 134 previsões (67 partidas do campeonato), o modelo acertou 38 vezes. Índice geral de 70% para as disputas do campeonato de 2018.
Os modelos também têm limitações
Um modelo teria muita dificuldade em prever todos os outros fatores e atributos que estão envolvidos nas vitórias apertadas e "zebras" impressionantes dos campeonatos March Madness.
Vejamos qual foi a maior zebra do campeonato de 2017 de acordo com o modelo. Analisaremos as situações em que o modelo fez uma previsão com mais de 80% de confiança e ERROU.
Execute este comando no Editor de consultas:
SELECT
model.label AS predicted_label,
model.prob AS confidence,
predictions.label AS correct_label,
game_date,
round,
seed,
school_ncaa,
points,
opponent_seed,
opponent_school_ncaa,
opponent_points
FROM `bracketology.predictions` AS predictions,
UNNEST(predicted_label_probs) AS model
WHERE model.prob > .8 AND predicted_label <> predictions.label
O resultado será como este:
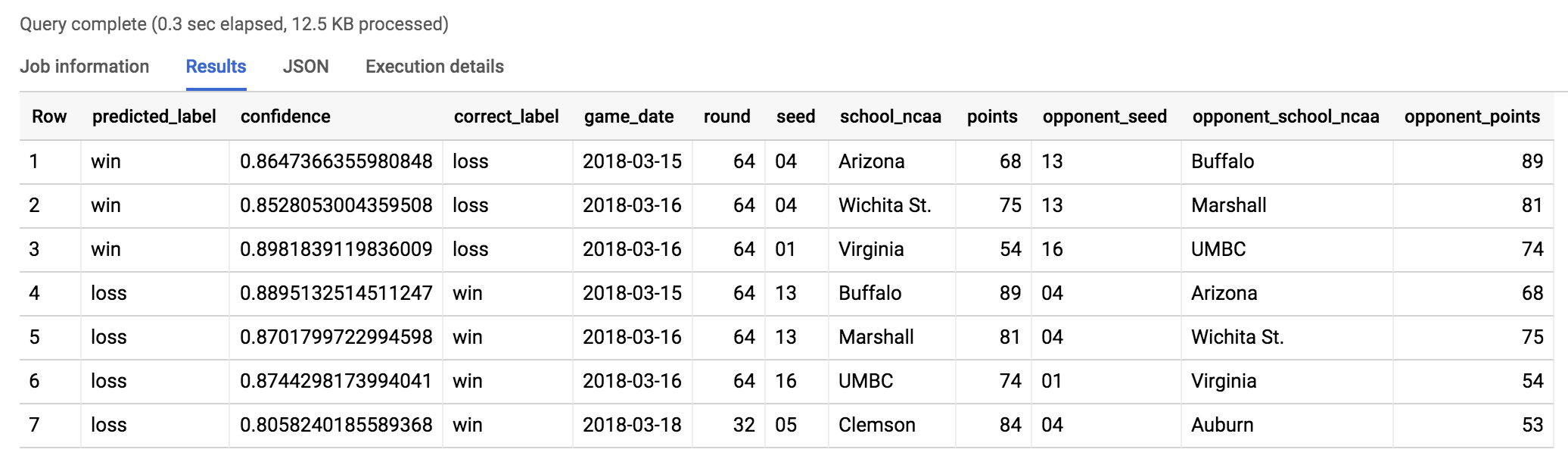
Assista a este vídeo e veja o que aconteceu de verdade.
Odom, técnico da UMBC, disse após o jogo: "Inacreditável, é só isso que dá para dizer".
Resumo
- Você criou um modelo de machine learning para prever o resultado de partidas.
- Você avaliou o desempenho e alcançou acurácia de 69% usando a classificação ("seed") e o nome do time como principais atributos.
- Você previu os resultados do campeonato de 2018.
- Você analisou os resultados para encontrar mais informações.
Nosso próximo desafio será criar um modelo melhor SEM usar a classificação e o nome da equipe como atributos.
Parte 2: como usar atributos especializados de modelos de ML
Na segunda parte deste laboratório, você criará um segundo modelo de ML usando novos atributos detalhados.
Agora que você já sabe como criar modelos de ML usando o BigQuery ML, sua equipe de ciência de dados forneceu um novo conjunto de dados de jogada a jogada, com novas métricas para o treinamento do modelo. São elas:
- Eficiência de pontuação ao longo do tempo, com base em análise histórica jogada a jogada.
- Posse de bola ao longo do tempo.
Crie um novo conjunto de dados de ML com esses atributos especializados
Execute este comando no Editor de consultas:
# create training dataset:
# create a row for the winning team
CREATE OR REPLACE TABLE `bracketology.training_new_features` AS
WITH outcomes AS (
SELECT
# features
season, # 1994
'win' AS label, # our label
win_seed AS seed, # ranking # this time without seed even
win_school_ncaa AS school_ncaa,
lose_seed AS opponent_seed, # ranking
lose_school_ncaa AS opponent_school_ncaa
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games` t
WHERE season >= 2014
UNION ALL
# create a separate row for the losing team
SELECT
# features
season, # 1994
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_school_ncaa AS school_ncaa,
win_seed AS opponent_seed, # ranking
win_school_ncaa AS opponent_school_ncaa
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games` t
WHERE season >= 2014
UNION ALL
# add in 2018 tournament game results not part of the public dataset:
SELECT
season,
label,
seed,
school_ncaa,
opponent_seed,
opponent_school_ncaa
FROM
`data-to-insights.ncaa.2018_tournament_results`
)
SELECT
o.season,
label,
# our team
seed,
school_ncaa,
# new pace metrics (basketball possession)
team.pace_rank,
team.poss_40min,
team.pace_rating,
# new efficiency metrics (scoring over time)
team.efficiency_rank,
team.pts_100poss,
team.efficiency_rating,
# opposing team
opponent_seed,
opponent_school_ncaa,
# new pace metrics (basketball possession)
opp.pace_rank AS opp_pace_rank,
opp.poss_40min AS opp_poss_40min,
opp.pace_rating AS opp_pace_rating,
# new efficiency metrics (scoring over time)
opp.efficiency_rank AS opp_efficiency_rank,
opp.pts_100poss AS opp_pts_100poss,
opp.efficiency_rating AS opp_efficiency_rating,
# a little feature engineering (take the difference in stats)
# new pace metrics (basketball possession)
opp.pace_rank - team.pace_rank AS pace_rank_diff,
opp.poss_40min - team.poss_40min AS pace_stat_diff,
opp.pace_rating - team.pace_rating AS pace_rating_diff,
# new efficiency metrics (scoring over time)
opp.efficiency_rank - team.efficiency_rank AS eff_rank_diff,
opp.pts_100poss - team.pts_100poss AS eff_stat_diff,
opp.efficiency_rating - team.efficiency_rating AS eff_rating_diff
FROM outcomes AS o
LEFT JOIN `data-to-insights.ncaa.feature_engineering` AS team
ON o.school_ncaa = team.team AND o.season = team.season
LEFT JOIN `data-to-insights.ncaa.feature_engineering` AS opp
ON o.opponent_school_ncaa = opp.team AND o.season = opp.season
Logo depois, aparecerá um resultado como este:

Clique em Verificar meu progresso para conferir o objetivo.
Veja os novos atributos
Clique no botão Ir para a tabela, no lado direito do console Em seguida, clique na guia Visualização.
A tabela será semelhante a esta:
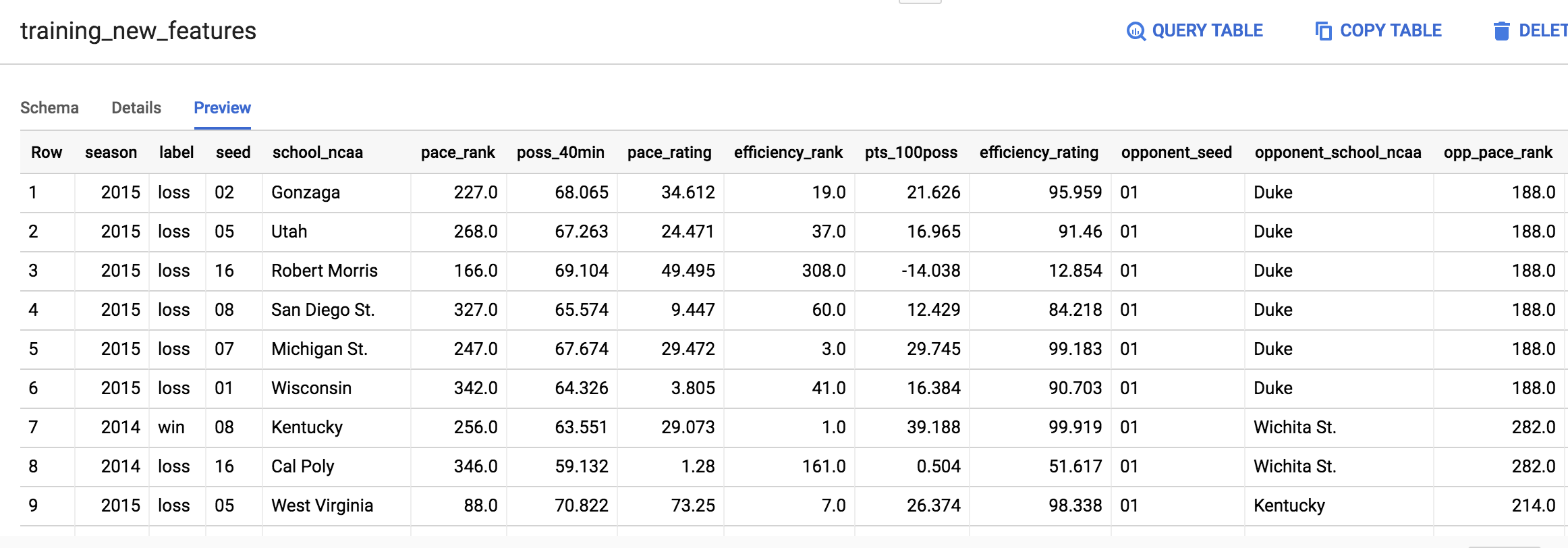
Não se preocupe caso o resultado não seja idêntico à captura de tela acima.
Como interpretar as métricas selecionadas
Agora você conhecerá alguns rótulos importantes que ajudam a realizar previsões.
opp_efficiency_rank
Cardinalidade de eficiência do adversário: de todos os times, qual é posição do adversário em termos de pontuação eficiente ao longo do tempo (pontos por cem posses de bola)? Quanto menor, melhor.
opp_pace_rank
Cardinalidade do ritmo do adversário: entre todas as equipes, qual é a posição do adversário em termos de posse de bola (número de posses em 40 minutos). Quanto menor, melhor.
Agora que você tem atributos que informam a capacidade de um time de pontuar e de manter a posse de bola, vamos treinar o segundo modelo.
Para evitar que o modelo memorize os times que tiveram sucesso anteriormente, exclua deste modelo o nome do time e o "seed" (classificação) e concentre-se apenas nas métricas.
Treine o novo modelo
Execute este comando no Editor de consultas:
CREATE OR REPLACE MODEL
`bracketology.ncaa_model_updated`
OPTIONS
( model_type='logistic_reg') AS
SELECT
# this time, dont train the model on school name or seed
season,
label,
# our pace
poss_40min,
pace_rank,
pace_rating,
# opponent pace
opp_poss_40min,
opp_pace_rank,
opp_pace_rating,
# difference in pace
pace_rank_diff,
pace_stat_diff,
pace_rating_diff,
# our efficiency
pts_100poss,
efficiency_rank,
efficiency_rating,
# opponent efficiency
opp_pts_100poss,
opp_efficiency_rank,
opp_efficiency_rating,
# difference in efficiency
eff_rank_diff,
eff_stat_diff,
eff_rating_diff
FROM `bracketology.training_new_features`
# here we'll train on 2014 - 2017 and predict on 2018
WHERE season BETWEEN 2014 AND 2017 # between in SQL is inclusive of end points
Logo depois, aparecerá um resultado semelhante a este:
Avalie o desempenho do novo modelo
Para avaliar o desempenho do modelo, execute este comando no Editor de consultas:
SELECT
*
FROM
ML.EVALUATE(MODEL `bracketology.ncaa_model_updated`)
O resultado será semelhante a este:

Incrível! Você treinou um novo modelo com atributos diferentes e aumentou a acurácia para cerca de 75%, um aumento de 5% em relação ao modelo original.
Esta é uma das lições mais importantes em machine learning: um conjunto de dados com atributos de alta qualidade pode fazer uma enorme diferença na acurácia do modelo.
Clique em Verificar meu progresso para conferir o objetivo.
Analise o que o modelo aprendeu
Qual atributo recebeu o maior peso do modelo nos resultados de vitória ou derrota? Para descobrir, execute este comando no Editor de consultas:
SELECT
*
FROM
ML.WEIGHTS(MODEL `bracketology.ncaa_model_updated`)
ORDER BY ABS(weight) DESC
A resposta será parecida com esta:
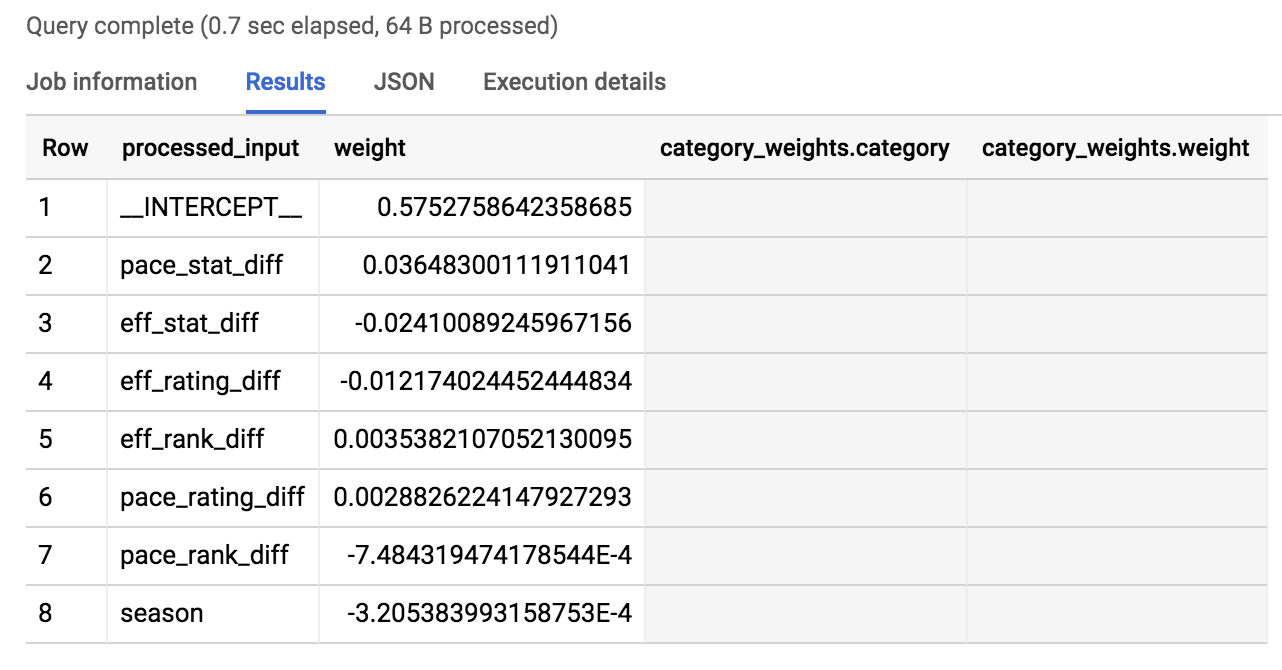
A ordenação considera o valor absoluto dos pesos, de modo que os mais importantes (para vitória ou derrota) aparecem primeiro.
Como pode ser visto nos resultados, os três principais são pace_stat_diff, eff_stat_diff, e eff_rating_diff. Vamos explorar esses pesos um pouco mais.
pace_stat_diff
A diferença entre os times na estatística real de (posse / 40 minutos). Segundo o modelo, esse é o principal fator para escolher o resultado da partida.
eff_stat_diff
A diferença entre os times na estatística real de (pontos líquidos / 100 posses).
eff_rating_diff
A diferença entre os times na classificação normalizada da eficiência em pontuação.
A quais fatores o modelo não atribuiu peso alto nas previsões? Temporada. Ficou em último lugar na lista ordenada de pesos acima. O modelo está dizendo que a temporada (2013, 2014, 2015) não é algo útil para prever o resultado da partida. Nada de mágico aconteceu com os times no ano "2014".
Um insight interessante é que o modelo deu maior valor ao ritmo de um time (posse de bola) do que à eficiência na pontuação.
Hora da previsão
Execute este comando no Editor de consultas:
CREATE OR REPLACE TABLE `bracketology.ncaa_2018_predictions` AS
# let's add back our other data columns for context
SELECT
*
FROM
ML.PREDICT(MODEL `bracketology.ncaa_model_updated`, (
SELECT
* # include all columns now (the model has already been trained)
FROM `bracketology.training_new_features`
WHERE season = 2018
))
O resultado deverá ser como este:

Clique em Verificar meu progresso para conferir o objetivo.
Análise das previsões:
Como você já sabe o resultado correto da partida, pode ver onde o modelo errou nas previsões com o novo conjunto de dados de teste. Execute este comando no Editor de consultas:
SELECT * FROM `bracketology.ncaa_2018_predictions`
WHERE predicted_label <> label
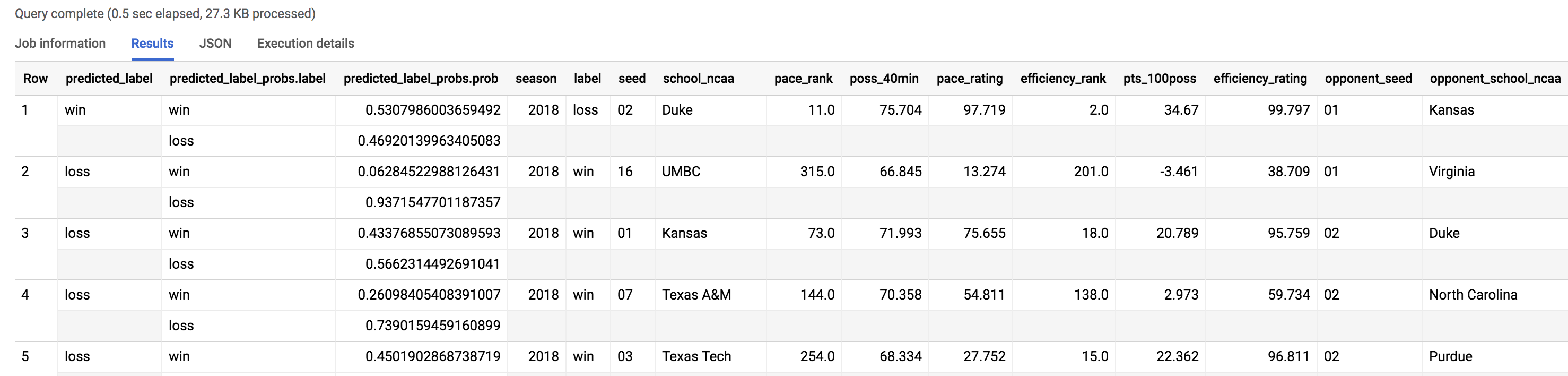
Como você pode ver no número de registros que a consulta retornou, o modelo errou 48 disputas (24 partidas) do total de disputas no campeonato de 2018, com acurácia de 64%. O ano de 2018 deve ter sido uma loucura. Vejamos as "zebras" que aconteceram.
Quais foram as zebras em março de 2018?
Execute este comando no Editor de consultas:
SELECT
CONCAT(school_ncaa, " was predicted to ",IF(predicted_label="loss","lose","win")," ",CAST(ROUND(p.prob,2)*100 AS STRING), "% but ", IF(n.label="loss","lost","won")) AS narrative,
predicted_label, # what the model thought
n.label, # what actually happened
ROUND(p.prob,2) AS probability,
season,
# us
seed,
school_ncaa,
pace_rank,
efficiency_rank,
# them
opponent_seed,
opponent_school_ncaa,
opp_pace_rank,
opp_efficiency_rank
FROM `bracketology.ncaa_2018_predictions` AS n,
UNNEST(predicted_label_probs) AS p
WHERE
predicted_label <> n.label # model got it wrong
AND p.prob > .75 # by more than 75% confidence
ORDER BY prob DESC
O resultado deverá ser como este:
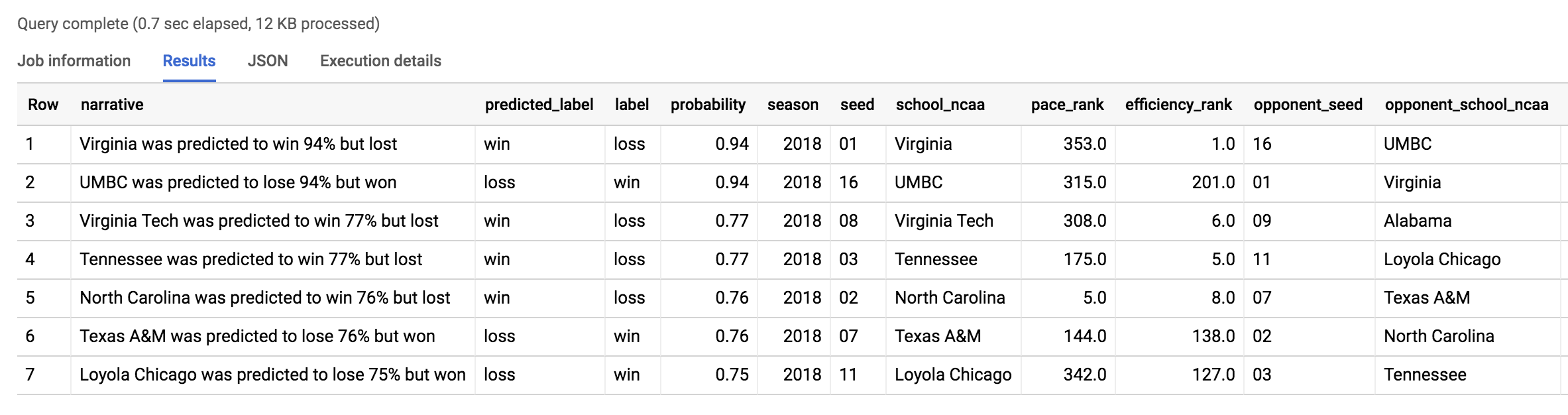
A maior zebra foi a mesma que o modelo anterior encontrou: UMBC x Virgínia. No geral, 2018 foi um ano cheio de zebras. Será que 2019 vai repetir a dose?
Como comparar o desempenho de modelos
Quais foram as disputas que o modelo simples (que comparava "seeds") errou, mas o modelo avançado acertou? Execute este comando no Editor de consultas:
SELECT
CONCAT(opponent_school_ncaa, " (", opponent_seed, ") was ",CAST(ROUND(ROUND(p.prob,2)*100,2) AS STRING),"% predicted to upset ", school_ncaa, " (", seed, ") and did!") AS narrative,
predicted_label, # what the model thought
n.label, # what actually happened
ROUND(p.prob,2) AS probability,
season,
# us
seed,
school_ncaa,
pace_rank,
efficiency_rank,
# them
opponent_seed,
opponent_school_ncaa,
opp_pace_rank,
opp_efficiency_rank,
(CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) AS seed_diff
FROM `bracketology.ncaa_2018_predictions` AS n,
UNNEST(predicted_label_probs) AS p
WHERE
predicted_label = 'loss'
AND predicted_label = n.label # model got it right
AND p.prob >= .55 # by 55%+ confidence
AND (CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) > 2 # seed difference magnitude
ORDER BY (CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) DESC
O resultado deverá ser como este:

O modelo previu uma vitória improvável da Florida St. (09) sobre a Xavier (01) e acertou.
O modelo previu a zebra corretamente (mesmo que a classificação indicasse o contrário), graças aos novos atributos especializados, como ritmo e eficiência nos arremessos. Assista aos destaques da partida no YouTube.
Previsão do campeonato March Madness 2019
Agora que sabemos os times e as classificações do March Madness de 2019, vamos prever o resultado das partidas futuras.
Explore os dados de 2019
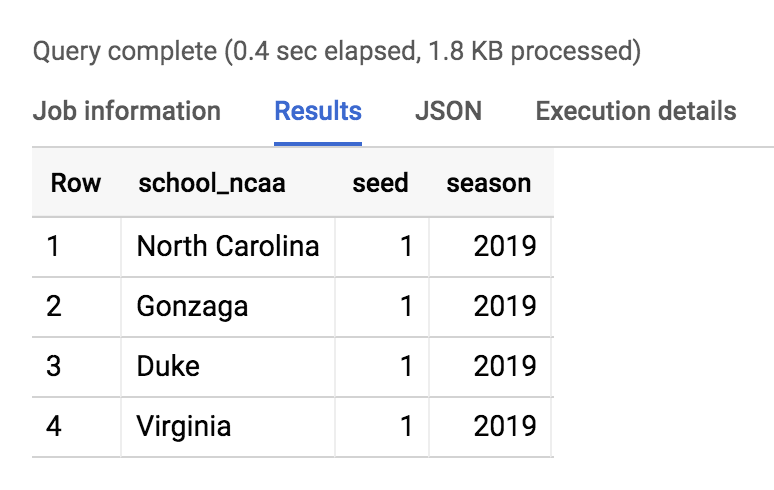
Execute a consulta abaixo para descobrir os principais "seeds"
SELECT * FROM `data-to-insights.ncaa.2019_tournament_seeds` WHERE seed = 1
O resultado deverá ser como este:
Crie uma matriz de todas as partidas possíveis
Não sabemos contra quem cada time jogará durante o campeonato, portanto, faremos com que cada time enfrente todos os outros.
No SQL, basta usar a instrução CROSS JOIN para fazer cada time enfrentar todos os demais.
Execute a consulta abaixo para identificar todas as partidas possíveis no campeonato.
SELECT
NULL AS label,
team.school_ncaa AS team_school_ncaa,
team.seed AS team_seed,
opp.school_ncaa AS opp_school_ncaa,
opp.seed AS opp_seed
FROM `data-to-insights.ncaa.2019_tournament_seeds` AS team
CROSS JOIN `data-to-insights.ncaa.2019_tournament_seeds` AS opp
# teams cannot play against themselves :)
WHERE team.school_ncaa <> opp.school_ncaa
Adicione as estatísticas de 2018 (ritmo, eficiência)
CREATE OR REPLACE TABLE `bracketology.ncaa_2019_tournament` AS
WITH team_seeds_all_possible_games AS (
SELECT
NULL AS label,
team.school_ncaa AS school_ncaa,
team.seed AS seed,
opp.school_ncaa AS opponent_school_ncaa,
opp.seed AS opponent_seed
FROM `data-to-insights.ncaa.2019_tournament_seeds` AS team
CROSS JOIN `data-to-insights.ncaa.2019_tournament_seeds` AS opp
# teams cannot play against themselves :)
WHERE team.school_ncaa <> opp.school_ncaa
)
, add_in_2018_season_stats AS (
SELECT
team_seeds_all_possible_games.*,
# bring in features from the 2018 regular season for each team
(SELECT AS STRUCT * FROM `data-to-insights.ncaa.feature_engineering` WHERE school_ncaa = team AND season = 2018) AS team,
(SELECT AS STRUCT * FROM `data-to-insights.ncaa.feature_engineering` WHERE opponent_school_ncaa = team AND season = 2018) AS opp
FROM team_seeds_all_possible_games
)
# Preparing 2019 data for prediction
SELECT
label,
2019 AS season, # 2018-2019 tournament season
# our team
seed,
school_ncaa,
# new pace metrics (basketball possession)
team.pace_rank,
team.poss_40min,
team.pace_rating,
# new efficiency metrics (scoring over time)
team.efficiency_rank,
team.pts_100poss,
team.efficiency_rating,
# opposing team
opponent_seed,
opponent_school_ncaa,
# new pace metrics (basketball possession)
opp.pace_rank AS opp_pace_rank,
opp.poss_40min AS opp_poss_40min,
opp.pace_rating AS opp_pace_rating,
# new efficiency metrics (scoring over time)
opp.efficiency_rank AS opp_efficiency_rank,
opp.pts_100poss AS opp_pts_100poss,
opp.efficiency_rating AS opp_efficiency_rating,
# a little feature engineering (take the difference in stats)
# new pace metrics (basketball possession)
opp.pace_rank - team.pace_rank AS pace_rank_diff,
opp.poss_40min - team.poss_40min AS pace_stat_diff,
opp.pace_rating - team.pace_rating AS pace_rating_diff,
# new efficiency metrics (scoring over time)
opp.efficiency_rank - team.efficiency_rank AS eff_rank_diff,
opp.pts_100poss - team.pts_100poss AS eff_stat_diff,
opp.efficiency_rating - team.efficiency_rating AS eff_rating_diff
FROM add_in_2018_season_stats
Faça previsões
CREATE OR REPLACE TABLE `bracketology.ncaa_2019_tournament_predictions` AS
SELECT
*
FROM
# let's predicted using the newer model
ML.PREDICT(MODEL `bracketology.ncaa_model_updated`, (
# let's predict on March 2019 tournament games:
SELECT * FROM `bracketology.ncaa_2019_tournament`
))
Clique em Verificar meu progresso para conferir o objetivo.
Gere as previsões
SELECT
p.label AS prediction,
ROUND(p.prob,3) AS confidence,
school_ncaa,
seed,
opponent_school_ncaa,
opponent_seed
FROM `bracketology.ncaa_2019_tournament_predictions`,
UNNEST(predicted_label_probs) AS p
WHERE p.prob >= .5
AND school_ncaa = 'Duke'
ORDER BY seed, opponent_seed
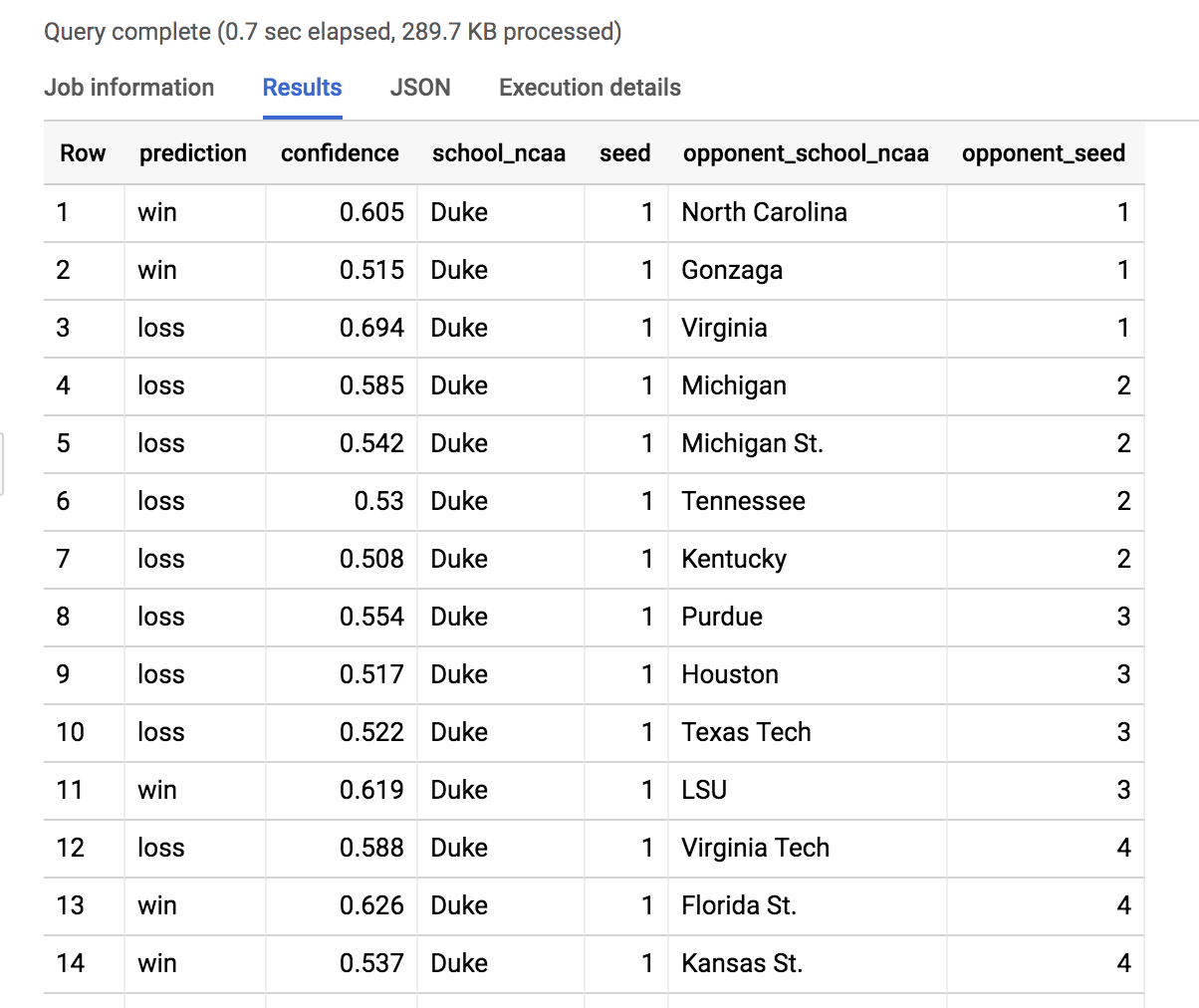
Aqui os resultados do modelo foram filtrados para exibir todas as partidas possíveis da Duke. Role a tela até a partida entre Duke e North Dakota St.
Insight: a Duke (1) tem 88,5% de chance de derrotar a North Dakota St. (16) no dia 22/03/19.
Faça alguns testes alterando o filtro school_ncaa acima, para fazer previsões para as disputas na sua chave. Anote o índice de confiança do modelo e bom jogo!
Parabéns!
Pronto! Você usou machine learning para prever os times vencedores do campeonato de basquete masculino da NCAA.


Termine a Quest
Este laboratório autoguiado faz parte das Quests NCAA® March Madness®: Bracketology with Google Cloud e BigQuery for Machine Learning. Uma Quest é uma série de laboratórios relacionados que formam o programa de aprendizado. Ao concluir uma Quest, você ganha um selo como reconhecimento da sua conquista. Publique os selos e coloque o link deles no seu currículo on-line ou nas mídias sociais. Caso você já tenha feito este laboratório, inscreva-se em uma Quest para ganhar os créditos de conclusão imediatamente. Veja outras Quests do Qwiklabs disponíveis (http://google.qwiklabs.com/catalog).
Comece o próximo laboratório
Esperamos que você tenha gostado de aprender sobre a exploração de big data e como criar rapidamente modelos de machine learning no BigQuery. Veja sugestões para fazer em seguida:
Próximas etapas / Saiba mais
- Quer saber mais sobre métricas e análises de basquete? Veja uma análise mais detalhada da equipe do Google Cloud por trás dos anúncios e previsões da NCAA.
- Veja as possibilidades de machine learning no artigo Como usar o machine learning no Compute Engine para fazer recomendações de produtos
- Quest Data Science
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 8 de outubro de 2020
Laboratório testado em 8 de outubro de 2020
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.