GSP1040

Übersicht
BigLake ist eine einheitliche Speicher-Engine, die den Datenzugriff für Data Warehouses und Lakes vereinfacht. Sie bietet eine einheitliche, detaillierte Zugriffssteuerung für Multi-Cloud-Speicher und offene Formate.
BigLake erweitert BigQuerys fein abgestimmte Sicherheit auf Zeilen- und Spaltenebene für Tabellen in datenlokalen Objektspeichern wie Amazon S3, Azure Data Lake Storage Gen2 und Google Cloud Storage. BigLake entkoppelt den Zugriff auf die Tabelle durch die Zugriffsdelegation von den zugrunde liegenden Cloud-Speicherdaten. Mit diesem Feature können Sie Nutzern und Pipelines in Ihrer Organisation sicher Zugriff auf Zeilen- und Spaltenebene gewähren, ohne ihnen vollen Zugriff auf die Tabelle zu gewähren.
Nachdem Sie eine BigLake-Tabelle erstellt haben, können Sie sie wie andere BigQuery-Tabellen abfragen. BigQuery erzwingt Zugriffssteuerung auf Zeilen- und Spaltenebene und jeder Nutzer sieht nur das Datenelement, für das er autorisiert ist. Governance-Richtlinien werden für den gesamten Zugriff auf die Daten über BigQuery APIs durchgesetzt. Die BigQuery Storage API ermöglicht Nutzern beispielsweise den Zugriff auf autorisierte Daten mithilfe von Open-Source-Abfrage-Engines wie Apache Spark, wie im folgenden Diagramm dargestellt:

Lernziele
Aufgaben in diesem Lab:
- Verbindungsressource erstellen und aufrufen
- Zugriff auf einen Cloud Storage-Data Lake einrichten
- BigLake-Tabelle erstellen
- BigLake-Tabelle über BigQuery abfragen
- Zugriffssteuerungsrichtlinien einrichten
- Upgrade externer Tabellen auf BigLake-Tabellen ausführen
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange Google Cloud-Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
Hinweis: Nutzen Sie den privaten oder Inkognitomodus (empfohlen), um dieses Lab durchzuführen. So wird verhindert, dass es zu Konflikten zwischen Ihrem persönlichen Konto und dem Teilnehmerkonto kommt und zusätzliche Gebühren für Ihr persönliches Konto erhoben werden.
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Hinweis: Verwenden Sie für dieses Lab nur das Teilnehmerkonto. Wenn Sie ein anderes Google Cloud-Konto verwenden, fallen dafür möglicherweise Kosten an.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Dialogfeld geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
Auf der linken Seite befindet sich der Bereich „Details zum Lab“ mit diesen Informationen:
- Schaltfläche „Google Cloud Console öffnen“
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite „Anmelden“ geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden.
-
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}}
Sie finden den Nutzernamen auch im Bereich „Details zum Lab“.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}}
Sie finden das Passwort auch im Bereich „Details zum Lab“.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos.
Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen.
-
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.
Hinweis: Wenn Sie auf Google Cloud-Produkte und ‑Dienste zugreifen möchten, klicken Sie auf das Navigationsmenü oder geben Sie den Namen des Produkts oder Dienstes in das Feld Suchen ein.

Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Mit Cloud Shell erhalten Sie Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen.
-
Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren  .
.
-
Klicken Sie sich durch die folgenden Fenster:
- Fahren Sie mit dem Informationsfenster zu Cloud Shell fort.
- Autorisieren Sie Cloud Shell, Ihre Anmeldedaten für Google Cloud API-Aufrufe zu verwenden.
Wenn eine Verbindung besteht, sind Sie bereits authentifiziert und das Projekt ist auf Project_ID, eingestellt. Die Ausgabe enthält eine Zeile, in der die Project_ID für diese Sitzung angegeben ist:
Ihr Cloud-Projekt in dieser Sitzung ist festgelegt als {{{project_0.project_id | "PROJECT_ID"}}}
gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
- (Optional) Sie können den aktiven Kontonamen mit diesem Befehl auflisten:
gcloud auth list
- Klicken Sie auf Autorisieren.
Ausgabe:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
Um das aktive Konto festzulegen, führen Sie diesen Befehl aus:
$ gcloud config set account `ACCOUNT`
- (Optional) Sie können die Projekt-ID mit diesem Befehl auflisten:
gcloud config list project
Ausgabe:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Hinweis: Die vollständige Dokumentation für gcloud finden Sie in Google Cloud in der Übersicht zur gcloud CLI.
Aufgabe 1: Verbindungsressource erstellen
BigLake-Tabellen greifen über eine Verbindungsressource auf Google Cloud Storage-Daten zu. Eine Verbindungsressource kann einer einzelnen Tabelle oder einer beliebigen Gruppe von Tabellen im Projekt zugeordnet werden.
-
Rufen Sie im Navigationsmenü BigQuery > BigQuery Studio auf. Klicken Sie auf Fertig.
-
Klicken Sie auf + HINZUFÜGEN und dann auf Verbindungen zu externen Datenquellen herstellen, um eine Verbindung zu erstellen.
Hinweis: Wenn Sie die Option + Hinzufügen gefolgt von Verbindungen zu externen Datenquellen herstellen nicht sehen, können Sie alternativ auf + Daten hinzufügen klicken und dann in der Suchleiste für Datenquellen nach Vertex AI suchen. Klicken Sie auf das Ergebnis für Vertex AI.
Hinweis: Wenn Sie aufgefordert werden, die BigQuery Connection API zu aktivieren, klicken Sie auf API aktivieren.
-
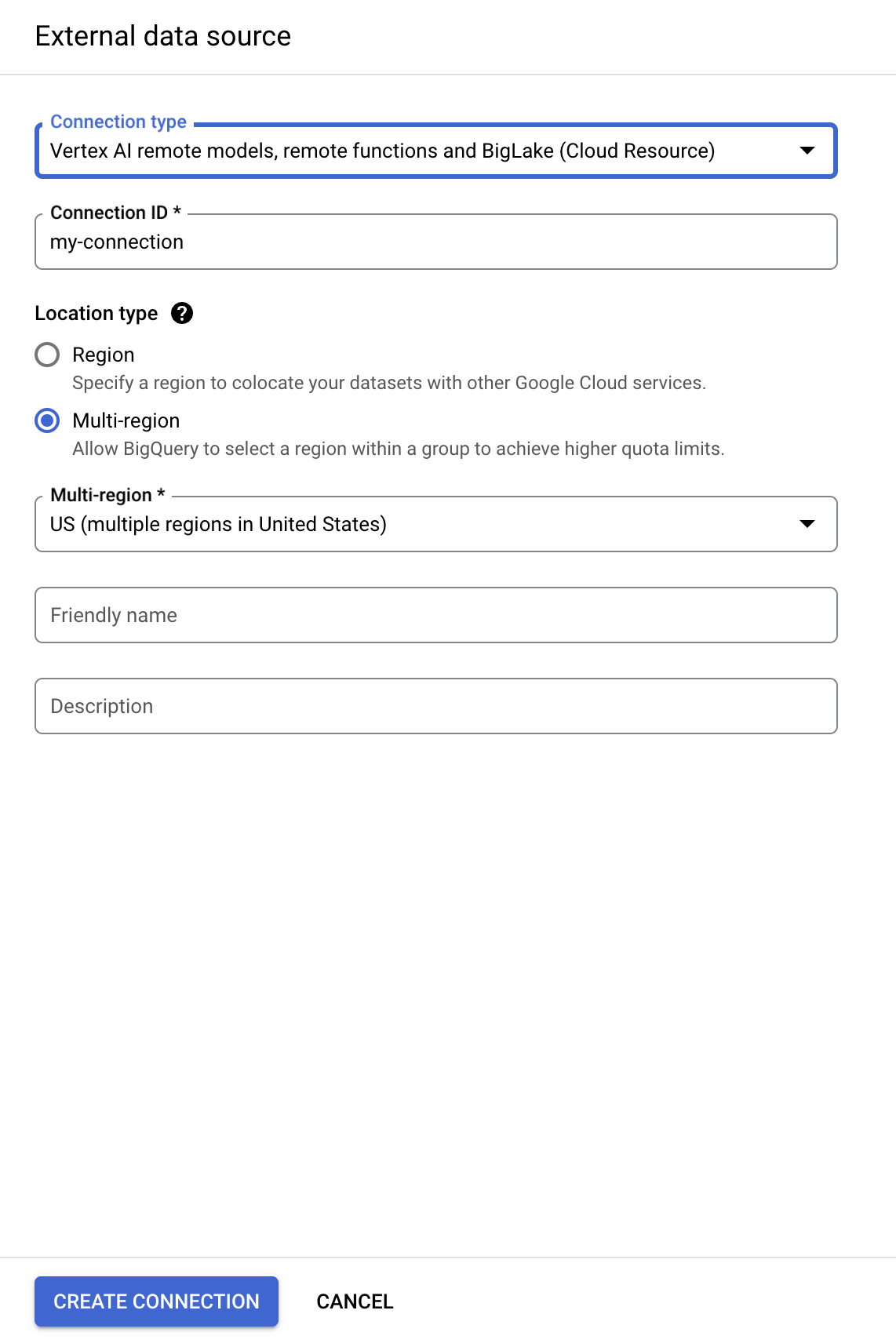
Wählen Sie in der Liste „Verbindungstyp“ die Option Vertex AI-Remote-Modelle, Remote-Funktionen und BigLake (Cloud-Ressource) aus.
-
Geben Sie im Feld „Verbindungs-ID“ my-connection ein.
-
Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus.
-
Klicken Sie auf Verbindung erstellen.
-
Wählen Sie die Verbindung im Navigationsmenü aus, um Ihre Verbindungsinformationen aufzurufen.
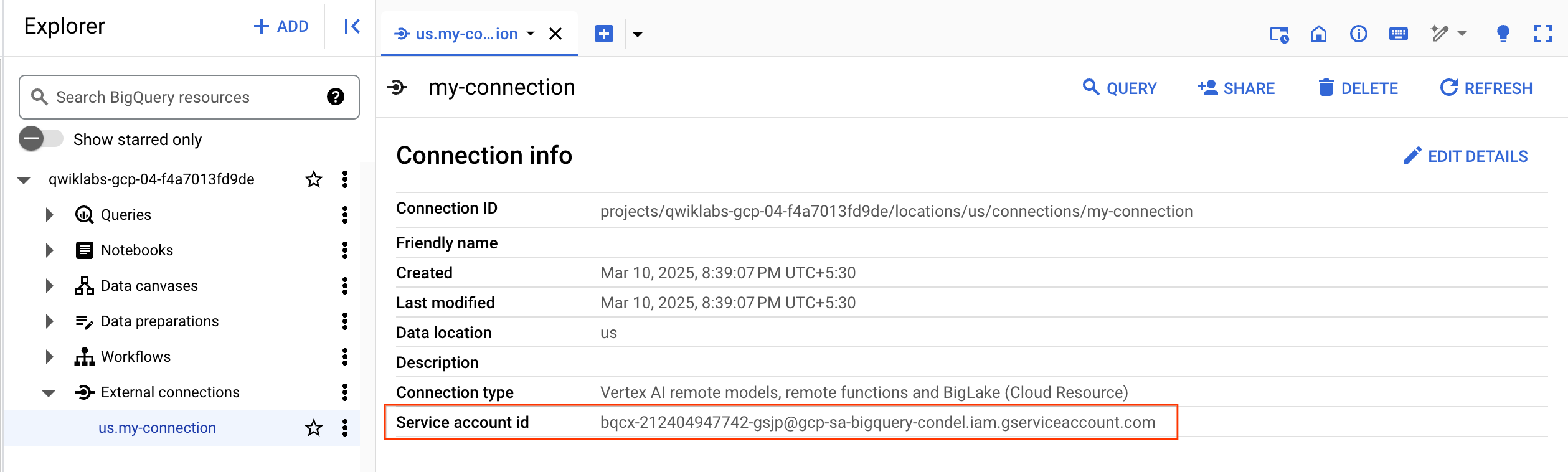
- Kopieren Sie im Abschnitt Verbindungsinformationen die Dienstkonto-ID. Die benötigen sie im nächsten Abschnitt.
Klicken Sie auf Fortschritt prüfen.
Verbindungsressource erstellen
Aufgabe 2: Zugriff auf einen Cloud Storage-Data Lake einrichten
In diesem Abschnitt gewähren Sie der neuen Verbindungsressource Lesezugriff auf den Cloud Storage-Data Lake, damit BigQuery im Namen der Nutzer auf Cloud Storage-Dateien zugreifen kann. Wir empfehlen, dem Dienstkonto der Verbindungsressource die IAM-Rolle Storage-Object Viewer zuzuweisen, damit das Dienstkonto auf Cloud Storage-Buckets zugreifen kann.
-
Klicken Sie im Navigationsmenü auf IAM und Verwaltung > IAM.
-
Klicken Sie auf +Zugriff gewähren.
-
Geben Sie im Feld Neue Hauptkonten die Dienstkonto-ID ein, die Sie zuvor kopiert haben.
-
Wählen Sie im Feld Rolle auswählen die Option Cloud Storage und dann Storage Object Viewer aus.
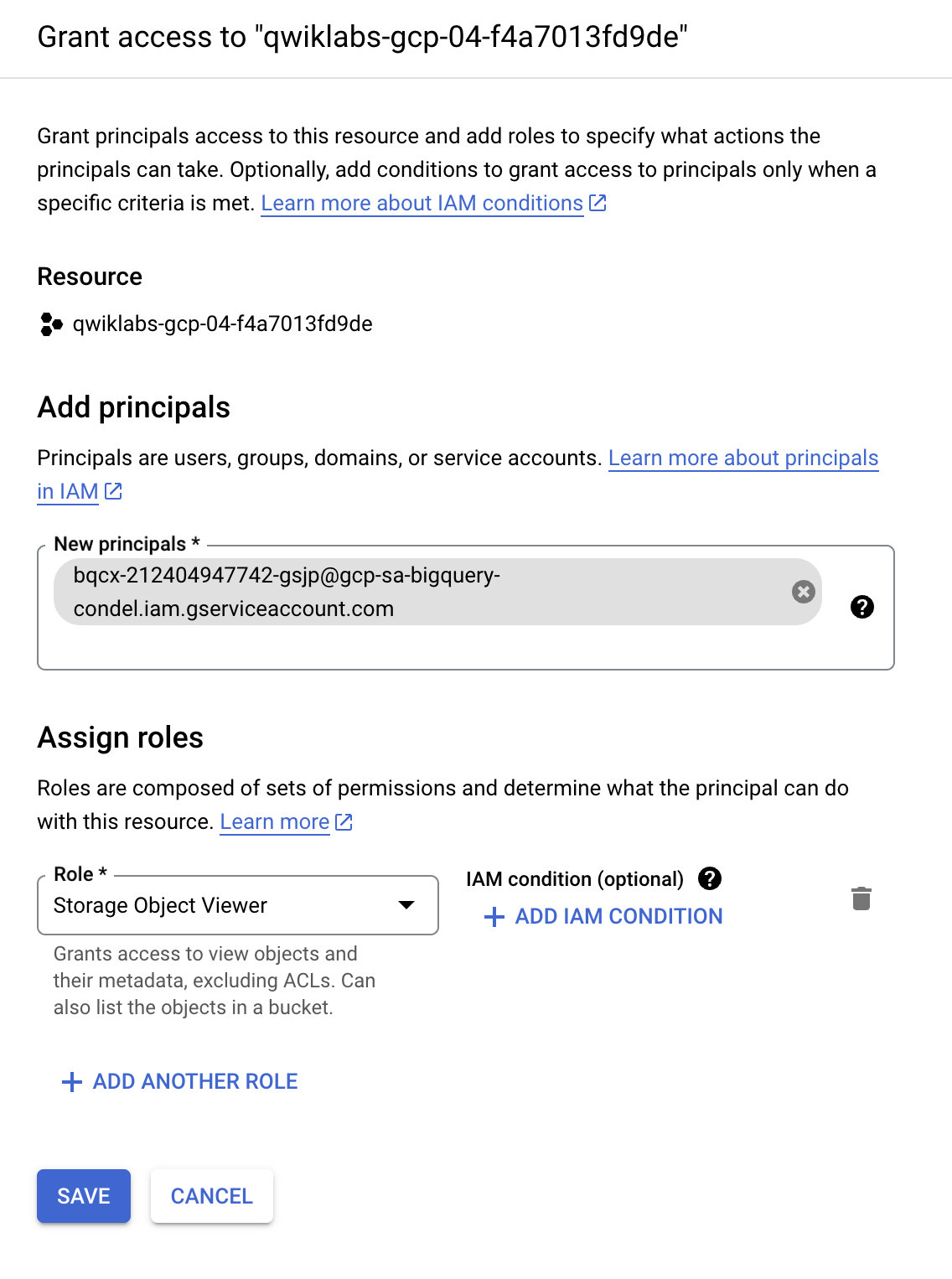
- Klicken Sie auf Speichern.
Hinweis: Nachdem Sie Nutzer zu BigLake-Tabellen migriert haben, entfernen Sie die direkten Cloud Storage-Berechtigungen vorhandener Nutzer. Durch den direkten Dateizugriff können Nutzer Governance-Richtlinien (z. B. Sicherheit auf Zeilen- und Spaltenebene) umgehen, die für BigLake-Tabellen festgelegt sind.
Klicken Sie auf Fortschritt prüfen.
Zugriff auf einen Cloud Storage-Data Lake einrichten
Aufgabe 3: BigLake-Tabelle erstellen
Im folgenden Beispiel wird das CSV-Dateiformat verwendet. Sie können jedoch jedes von BigLake unterstützte Format verwenden, wie unter Einschränkungen gezeigt. Wenn Sie mit dem Erstellen von Tabellen in BigQuery vertraut sind, sollte dieser Vorgang ähnlich sein. Der einzige Unterschied besteht darin, dass Sie die zugehörige Cloud-Ressourcenverbindung angeben.
Hinweis: Für eine optimale Leistung empfehlen wir die Verwendung von Cloud Storage-Buckets mit einer oder zwei Regionen und nicht mit Buckets mit mehreren Regionen.
Wenn kein Schema angegeben wurde und dem Dienstkonto im vorherigen Schritt kein Zugriff auf den Bucket gewährt wurde, schlägt dieser Schritt mit einer Meldung über den Zugriff fehl.
Dataset erstellen
-
Kehren Sie zu BigQuery > Studio zurück.
-
Klicken Sie auf die drei Punkte neben Ihrem Projektnamen und wählen Sie Dataset erstellen aus.
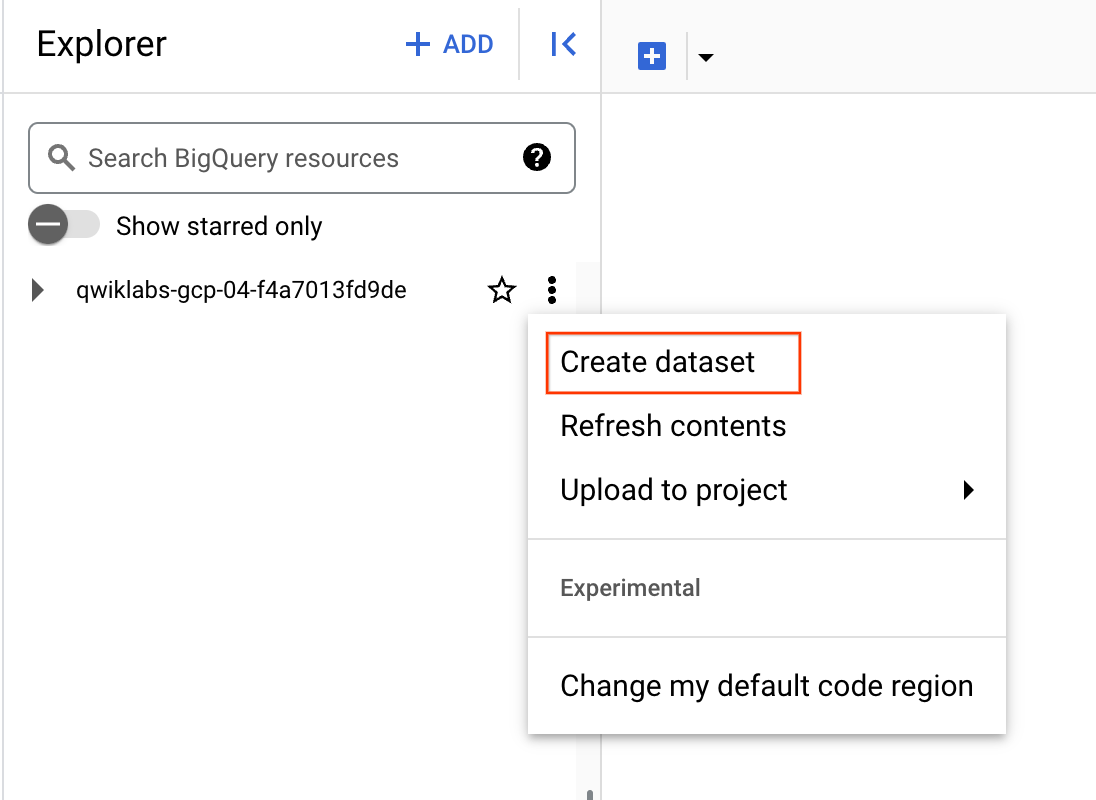
-
Verwenden Sie für die Dataset-ID den Wert demo_dataset.
-
Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus.
-
Übernehmen Sie für alle anderen Felder die Standardeinstellungen und klicken Sie auf Dataset erstellen.
Nachdem Sie ein Dataset erstellt haben, können Sie ein vorhandenes Dataset aus Cloud Storage in BigQuery kopieren.
Erstellen Sie die Tabelle:
- Klicken Sie auf das Dreipunkt-Menü neben demo_dataset und wählen Sie Tabelle erstellen aus.
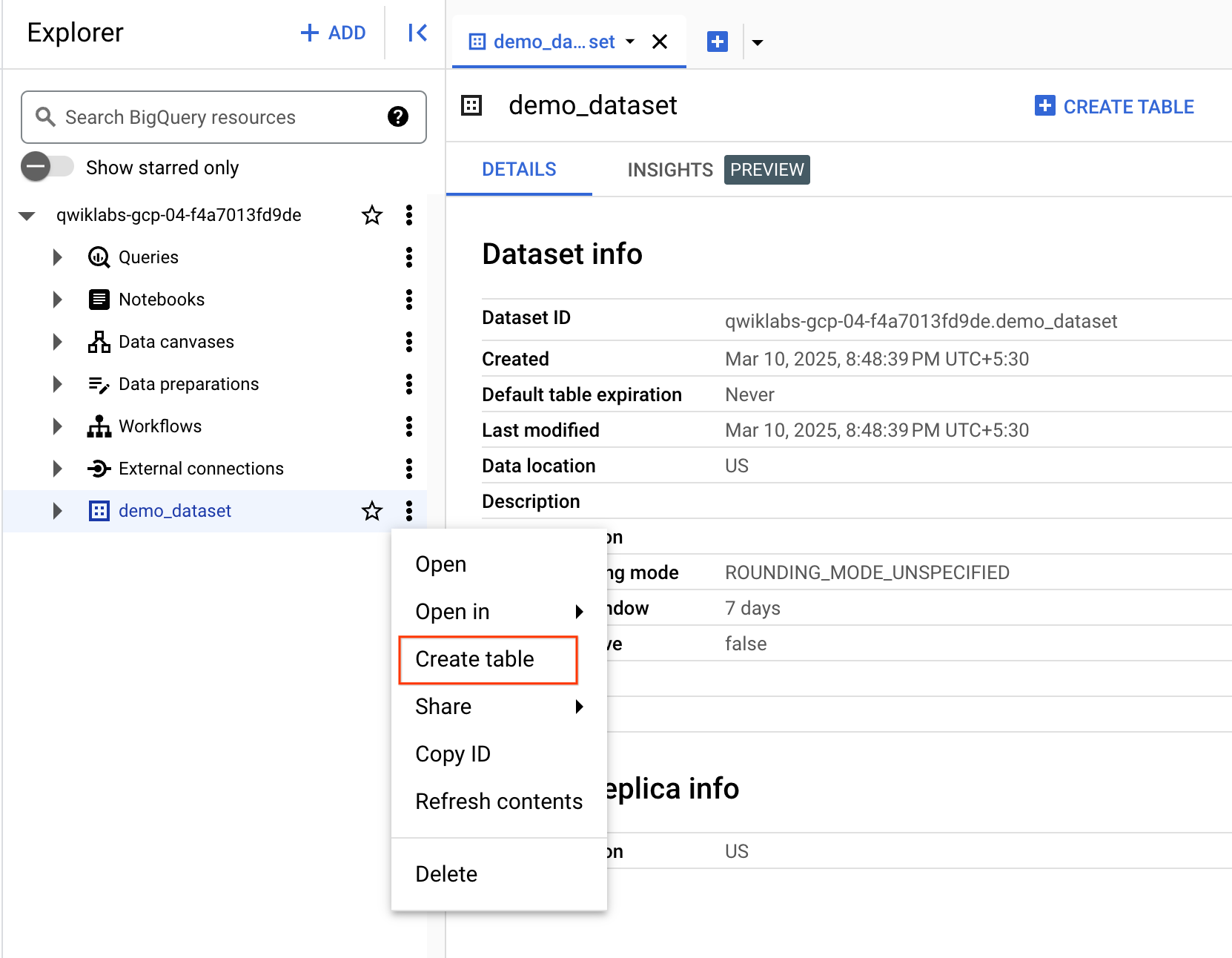
- Wählen Sie unter „Quelle“ für Tabelle erstellen aus die Option Google Cloud Storage aus.
Hinweis: Es wurde ein Cloud Storage-Bucket mit zwei Datasets erstellt, die Sie in diesem Lab verwenden werden.
-
Klicken Sie auf Durchsuchen, um das Dataset auszuwählen. Rufen Sie den Bucket mit dem Namen und dann die Datei customer.csv auf, um sie in BigQuery zu importieren, und klicken Sie auf Auswählen.
-
Prüfen Sie unter Ziel, ob Ihr Lab-Projekt ausgewählt ist und Sie das demo_dataset verwenden.
-
Verwenden Sie biglake_table als Tabellennamen.
-
Ändern Sie den Tabellentyp zu Externe Tabelle.
-
Klicken Sie auf das Kästchen BigLake-Tabelle mit einer Cloud-Ressourcenverbindung erstellen.
Prüfen Sie, ob die Verbindungs-ID us.my-connection ausgewählt ist. Die Konfiguration sollte in etwa so aussehen:

- Aktivieren Sie unter Schema die Option Als Text bearbeiten und kopieren Sie das folgende Schema in das Textfeld:
[
{
"name": "customer_id",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "first_name",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "last_name",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "company",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "address",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "city",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "state",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "country",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "postal_code",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "phone",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "fax",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "email",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "support_rep_id",
"type": "INTEGER",
"mode": "NULLABLE"
}
]
Hinweis: Data Lakes haben in der Regel kein vordefiniertes Schema. Für dieses Lab verwenden wir eines, um das Festlegen von Richtlinien auf Spaltenebene zu verdeutlichen.
- Klicken Sie auf Tabelle erstellen.
Klicken Sie auf Fortschritt prüfen.
BigLake-Tabelle erstellen
Aufgabe 4: BigLake-Tabelle über BigQuery abfragen
Nachdem Sie die BigLake-Tabelle erstellt haben, können Sie mit einem beliebigen BigQuery-Client eine Abfrage senden.
-
Klicken Sie in der Symbolleiste der Vorschau von biglake_table auf Abfrage.
-
Führen Sie Folgendes aus, um die BigLake-Tabelle über den BigQuery-Editor abzufragen:
SELECT * FROM `{{{project_0.project_id|Project ID}}}.demo_dataset.biglake_table`
-
Klicken Sie auf Ausführen.
-
Prüfen Sie, ob alle Spalten und Daten in der resultierenden Tabelle angezeigt werden.
Aufgabe 5: Zugriffssteuerungsrichtlinien einrichten
Nachdem eine BigLake-Tabelle erstellt wurde, kann sie ähnlich wie BigQuery-Tabellen verwaltet werden. Zum Erstellen von Zugriffssteuerungsrichtlinien für BigLake-Tabellen erstellen Sie zuerst in BigQuery eine Taxonomie von Richtlinien-Tags. Anschließend wenden Sie die Richtlinien-Tags auf die sensiblen Zeilen oder Spalten an. In diesem Abschnitt erstellen Sie eine Richtlinie auf Spaltenebene. Eine Anleitung zum Einrichten der Sicherheit auf Zeilenebene finden Sie im Sicherheitsleitfaden auf Zeilenebene.
Dafür wurde eine BigQuery-Taxonomie mit dem Namen und ein zugehöriges Richtlinien-Tag mit dem Namen biglake-policy für Sie erstellt.
Richtlinien-Tags zu Spalten hinzufügen
Jetzt verwenden Sie das erstellte Richtlinien-Tag, um den Zugriff auf bestimmte Spalten in der BigQuery-Tabelle einzuschränken. In diesem Beispiel beschränken Sie den Zugriff auf sensible Informationen wie Adresse, Postleitzahl und Telefonnummer.
-
Klicken Sie im Navigationsmenü auf BigQuery > Studio.
-
Gehen Sie zu demo-dataset > biglake_table und klicken Sie auf die Tabelle, um die Seite mit dem Tabellenschema zu öffnen.
-
Klicken Sie auf Schema bearbeiten.
-
Setzen Sie Häkchen in die Kästchen neben den Feldern address, postal_code und phone.
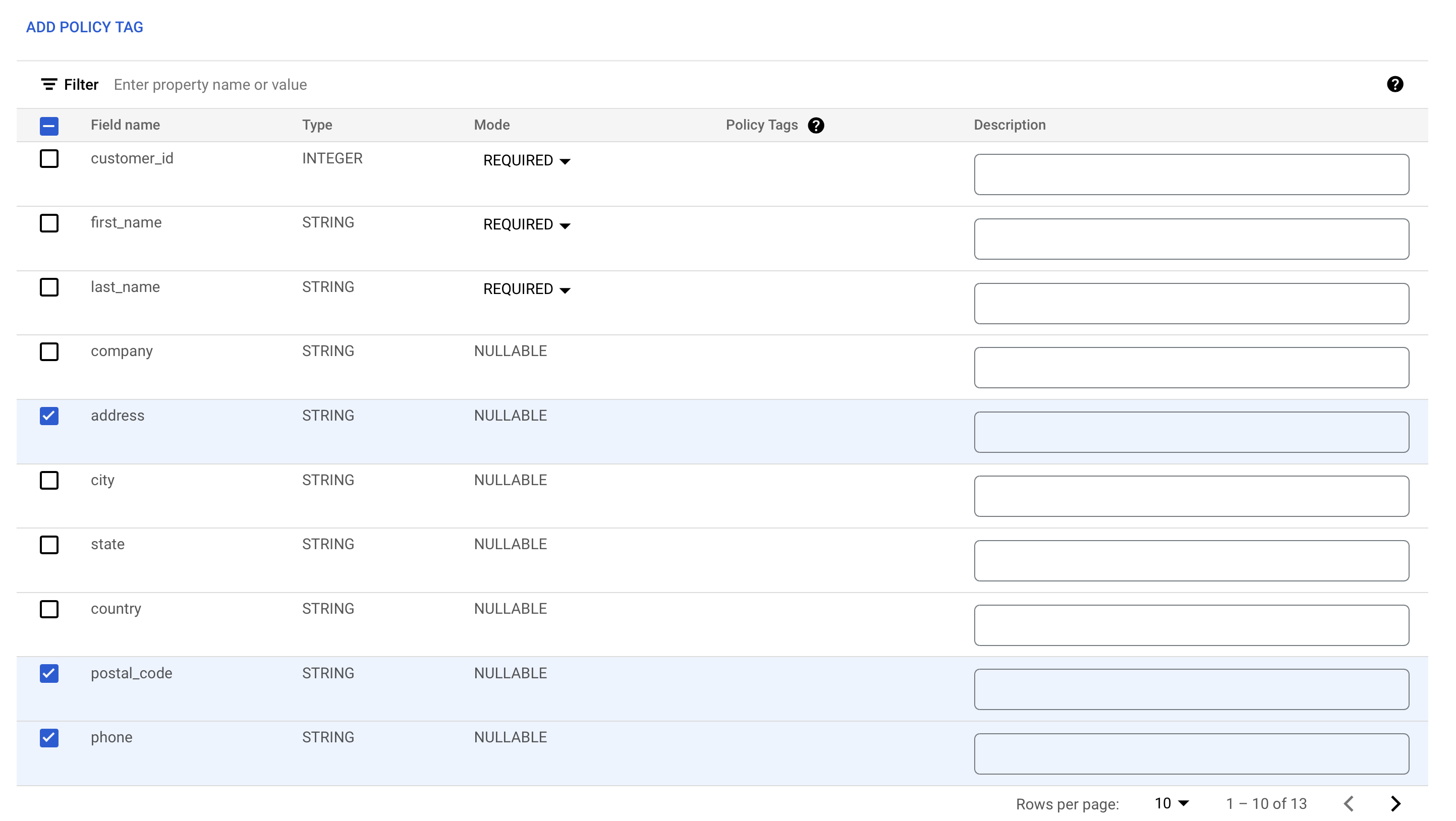
-
Klicken Sie auf Richtlinien-Tag hinzufügen.
-
Klicken Sie auf , um es zu maximieren und biglake-policy auszuwählen.
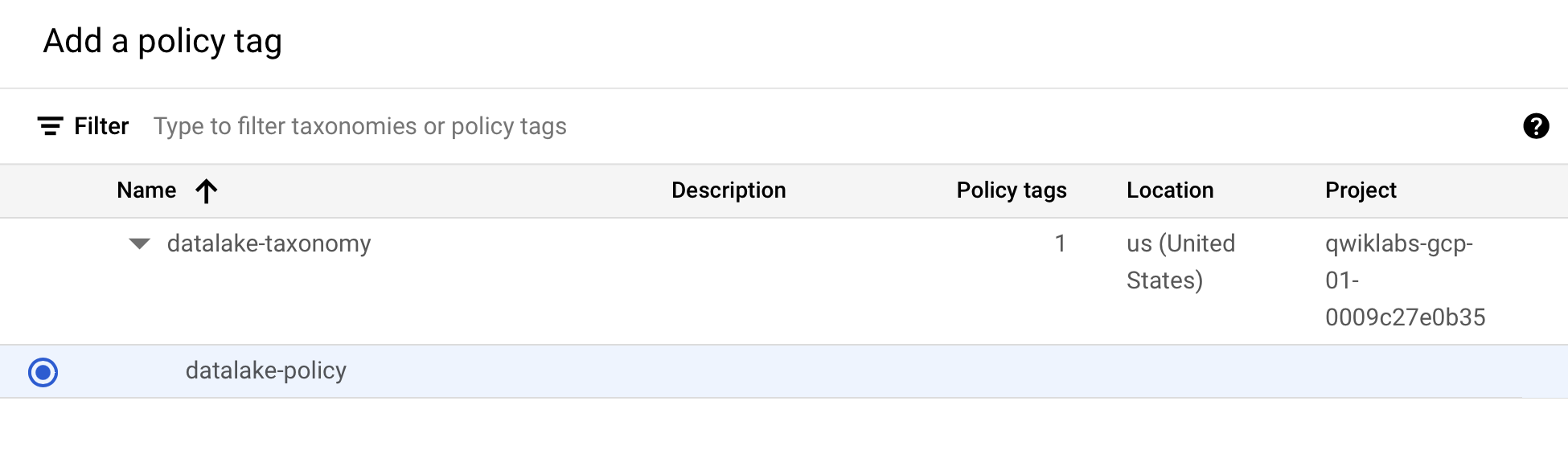
-
Klicken Sie auf Auswählen.
Ihren Spalten sollten jetzt die Richtlinien-Tags angehängt sein.
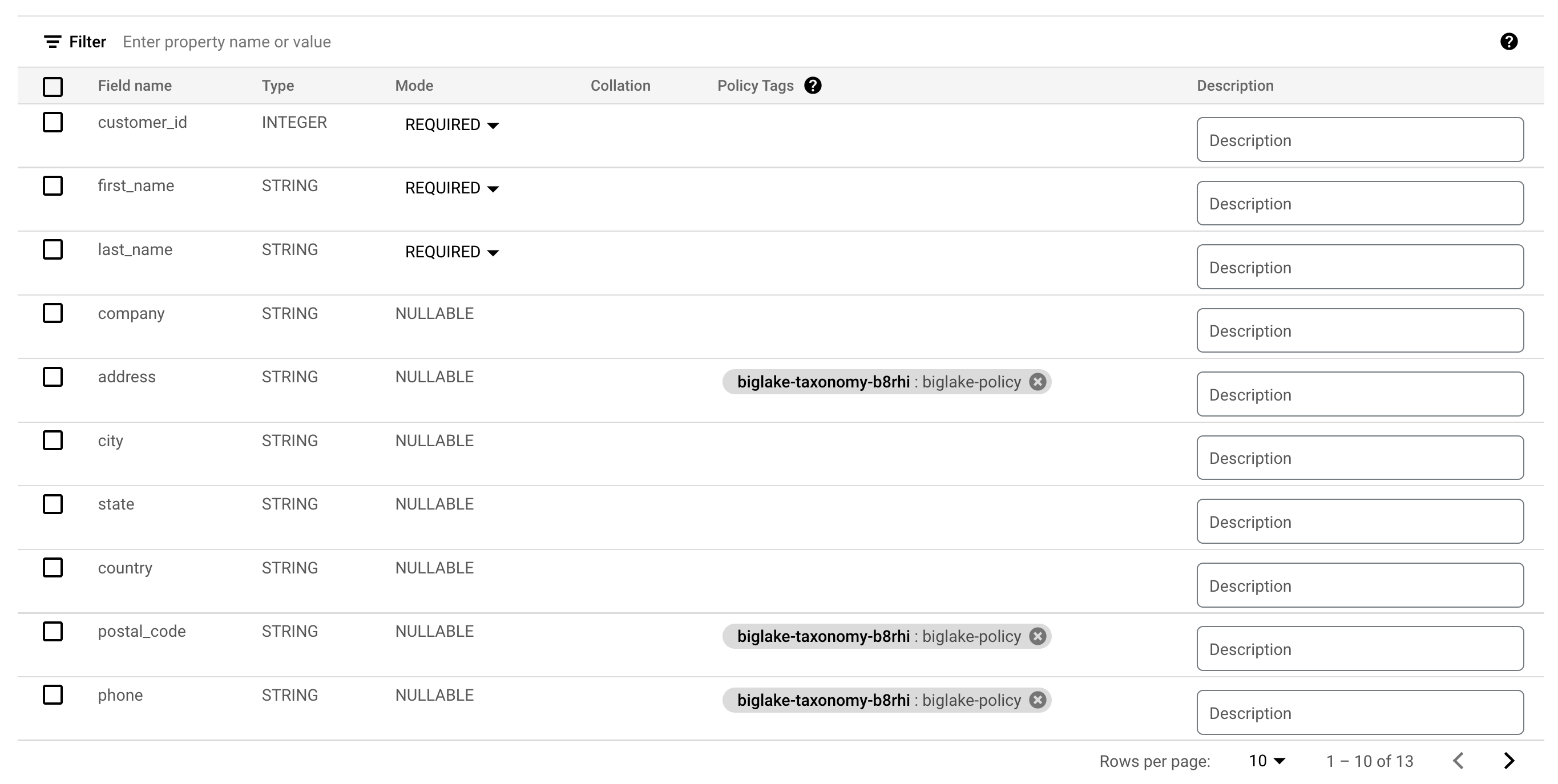
-
Klicken Sie auf Speichern.
-
Prüfen Sie, ob Ihr Tabellenschema jetzt so aussieht:
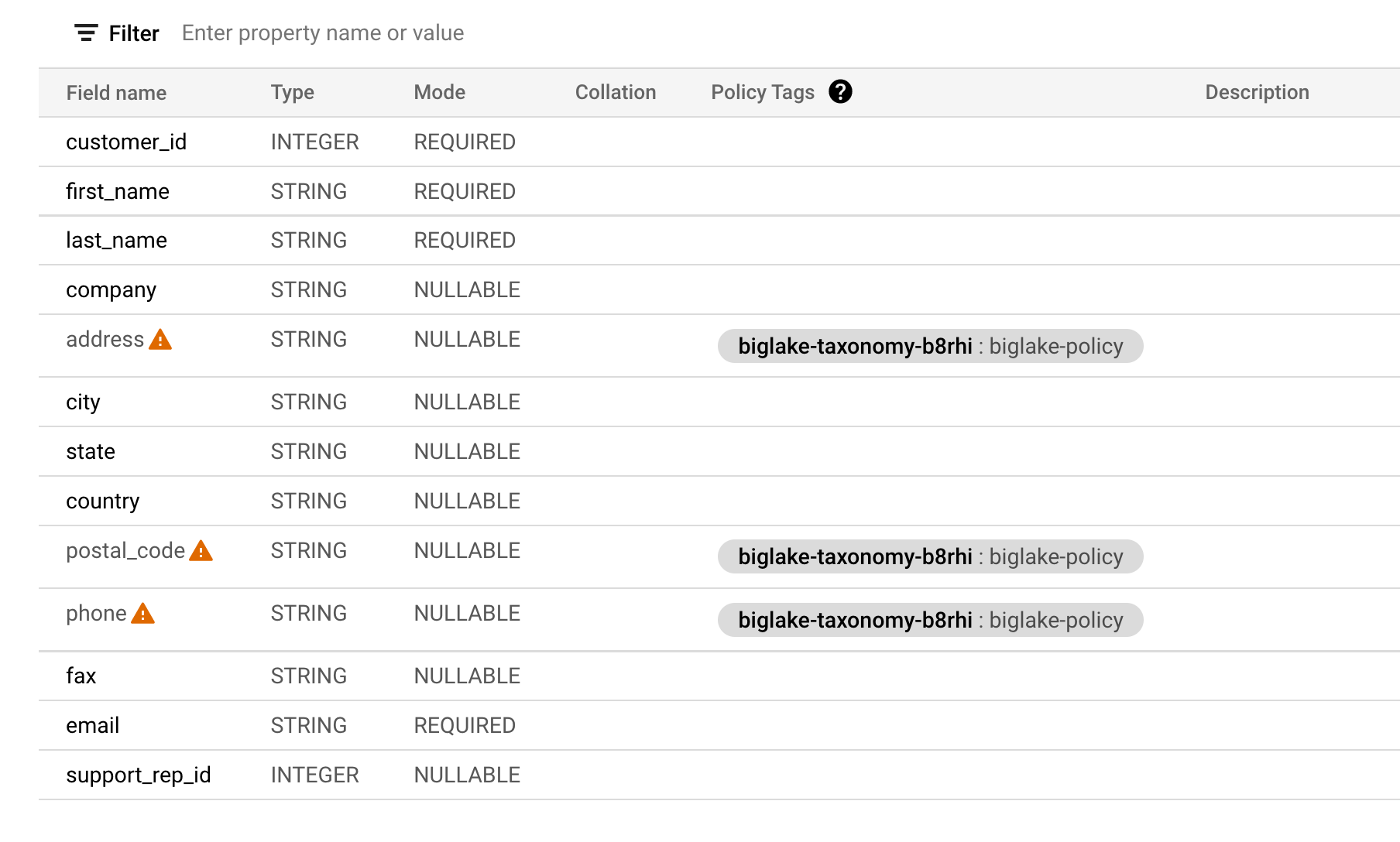
Hinweis: Die Warnsymbole in den Spalten zeigen an, dass Sie aufgrund der geltenden Sicherheitsrichtlinien keinen Zugriff auf diese Felder haben.
Sicherheit auf Spaltenebene prüfen
-
Öffnen Sie den Abfrageeditor für biglake_table.
-
Führen Sie Folgendes aus, um die BigLake-Tabelle über den BigQuery-Editor abzufragen:
SELECT * FROM `{{{project_0.project_id|Project ID}}}.demo_dataset.biglake_table`
-
Klicken Sie auf Ausführen.
Sie sollten eine Fehlermeldung erhalten, dass der Zugriff verweigert wurde:
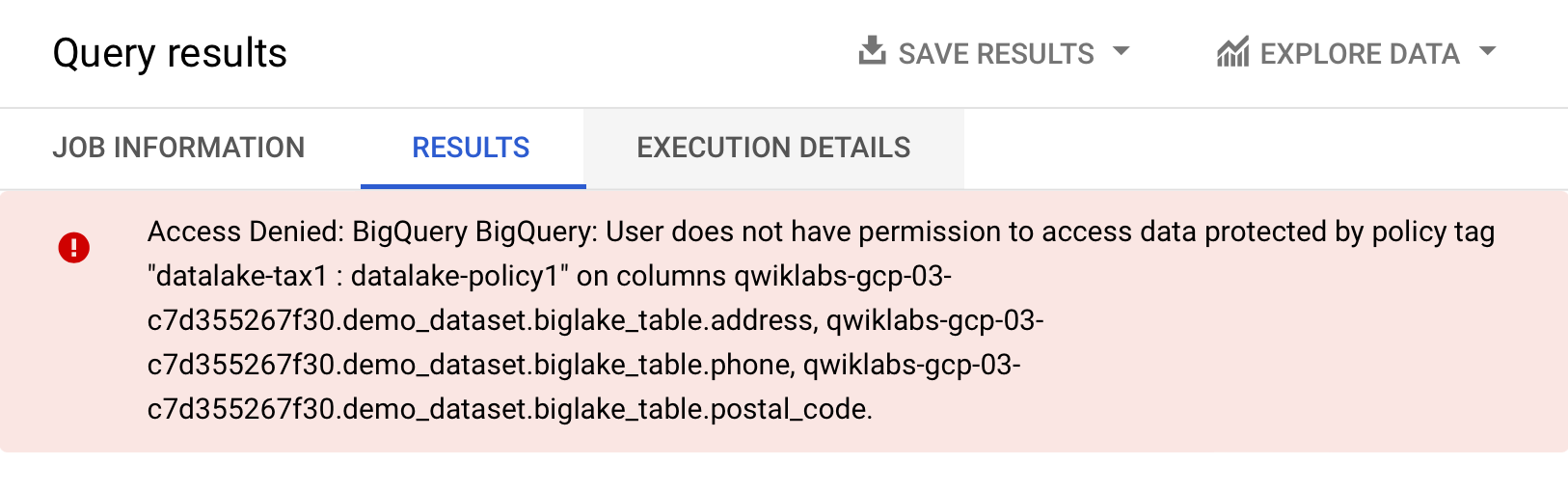
- Führen Sie nun die folgende Abfrage aus und lassen Sie die Spalten weg, auf die Sie keinen Zugriff haben:
SELECT * EXCEPT(address, phone, postal_code)
FROM `{{{project_0.project_id|Project ID}}}.demo_dataset.biglake_table`
Die Abfrage sollte ohne Probleme ausgeführt werden und die Spalten zurückgeben, auf die Sie Zugriff haben. Dieses Beispiel zeigt, dass die Sicherheit auf Spaltenebene, die über BigQuery erzwungen wird, auch auf BigLake-Tabellen angewendet werden kann.
Aufgabe 6: Upgrade externer Tabellen auf BigLake-Tabellen ausführen
Sie können vorhandene Tabellen auf BigLake-Tabellen aktualisieren, indem Sie die vorhandene Tabelle mit einer Cloud-Ressourcenverbindung verknüpfen. Eine vollständige Liste der Flags und Argumente finden Sie unter bq update und bq mkdef.
Externe Tabelle erstellen
-
Klicken Sie auf das Dreipunkt-Menü neben demo_dataset und wählen Sie Tabelle erstellen aus.
-
Wählen Sie unter „Quelle“ für Tabelle erstellen aus die Option Google Cloud Storage aus.
-
Klicken Sie auf Durchsuchen, um das Dataset auszuwählen. Rufen Sie den Bucket mit dem Namen und dann die Datei invoice.csv auf, um sie in BigQuery zu importieren, und klicken Sie auf Auswählen.
-
Prüfen Sie unter Ziel, ob Ihr Lab-Projekt ausgewählt ist und Sie das demo_dataset verwenden.
-
Verwenden Sie external_table als Tabellennamen.
-
Ändern Sie den Tabellentyp zu Externe Tabelle.
Hinweis: Geben Sie noch keine Cloud-Ressourcenverbindung an.
- Aktivieren Sie unter Schema die Option Als Text bearbeiten und kopieren Sie das folgende Schema in das Textfeld:
[
{
"name": "invoice_id",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "customer_id",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "invoice_date",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "billing_address",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "billing_city",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "billing_state",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "billing_country",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "billing_postal_code",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "total",
"type": "NUMERIC",
"mode": "REQUIRED"
}
]
- Klicken Sie auf Tabelle erstellen.
Klicken Sie auf Fortschritt prüfen.
Externe Tabelle erstellen
Externe Tabelle auf BigLake-Tabelle aktualisieren
- Öffnen Sie ein neues Cloud Shell-Fenster und führen Sie den folgenden Befehl aus, um eine neue externe Tabellendefinition zu generieren, die die zu verwendende Verbindung angibt:
export PROJECT_ID=$(gcloud config get-value project)
bq mkdef \
--autodetect \
--connection_id=$PROJECT_ID.US.my-connection \
--source_format=CSV \
"gs://$PROJECT_ID/invoice.csv" > /tmp/tabledef.json
- Prüfen Sie, ob die Tabellendefinition erstellt wurde:
cat /tmp/tabledef.json
- Rufen Sie das Schema aus Ihrer Tabelle ab:
bq show --schema --format=prettyjson demo_dataset.external_table > /tmp/schema
- Aktualisieren Sie die Tabelle mit der neuen externen Tabellendefinition:
bq update --external_table_definition=/tmp/tabledef.json --schema=/tmp/schema demo_dataset.external_table
Klicken Sie auf Fortschritt prüfen.
Externe Tabelle in BigLake-Tabelle umwandeln
Aktualisierte Tabelle prüfen
-
Klicken Sie im Navigationsmenü auf BigQuery > Studio.
-
Gehen Sie zu demo-dataset und doppelklicken Sie auf external_table.
-
Öffnen Sie den Tab Details.
-
Prüfen Sie unter „Externe Datenkonfiguration“, ob die Tabelle jetzt die richtige Verbindungs-ID verwendet.
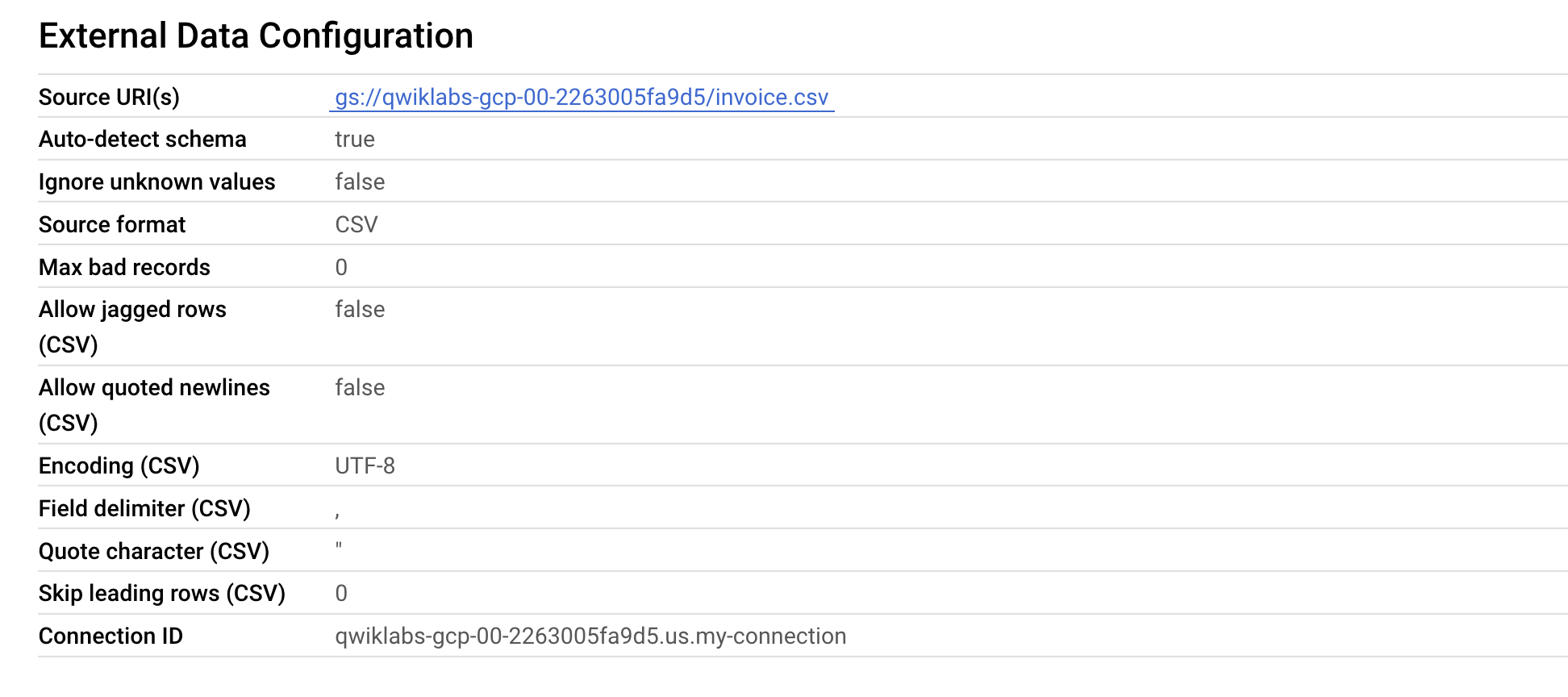
Sehr gut. Sie haben die vorhandene externe Tabelle erfolgreich auf eine BigLake-Tabelle aktualisiert, indem Sie sie einer Cloud-Ressourcenverbindung zugeordnet haben.
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
In diesem Lab haben Sie eine Verbindungsressource erstellt, den Zugriff auf einen Cloud Storage-Data Lake eingerichtet und daraus eine BigLake-Tabelle erstellt. Anschließend haben Sie die BigLake-Tabelle über BigQuery abgefragt und Zugriffssteuerungsrichtlinien auf Spaltenebene eingerichtet. Zum Schluss haben Sie eine vorhandene externe Tabelle mithilfe der Verbindungsressource in eine BigLake-Tabelle umgewandelt.
Weitere Informationen
In der folgenden Dokumentation finden Sie weitere praktische Übungen zu BigLake:
Google Cloud-Schulungen und -Zertifizierungen
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 21. März 2025 aktualisiert
Lab zuletzt am 21. März 2025 getestet
© 2025 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.





