GSP410

개요
BigQuery는 Google의 완전 관리형, 노옵스(NoOps), 저비용 분석 데이터베이스입니다. BigQuery를 사용하면 관리할 인프라나 데이터베이스 관리자가 없어도 테라바이트 단위의 대규모 데이터를 쿼리할 수 있습니다. BigQuery는 SQL을 사용하므로 사용한 만큼만 지불하는 모델의 장점을 활용할 수 있습니다. BigQuery는 데이터를 분석하여 의미 있고 유용한 정보를 찾는 데 집중할 수 있게 해줍니다.
이 실습에서 사용할 데이터는 Google Merchandise Store에 대한 Google 애널리틱스 레코드 수백만 개가 BigQuery에 로드된 전자상거래 데이터 세트입니다. 이 실습에서는 해당 데이터 세트의 복사본에서 사용 가능한 필드와 행을 탐색하여 유용한 정보를 파악합니다.
이 실습에서는 기존 전자상거래 데이터 세트에서 새로운 영구 보고 테이블과 논리적 검토를 만드는 방법을 알아봅니다.
설정 및 요건
실습 시작 버튼을 클릭하기 전에
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지를 표시합니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
- 표준 인터넷 브라우저 액세스 권한(Chrome 브라우저 권장)
참고: 이 실습을 실행하려면 시크릿 모드(권장) 또는 시크릿 브라우저 창을 사용하세요. 개인 계정과 학습자 계정 간의 충돌로 개인 계정에 추가 요금이 발생하는 일을 방지해 줍니다.
- 실습을 완료하기에 충분한 시간(실습을 시작하고 나면 일시중지할 수 없음)
참고: 이 실습에는 학습자 계정만 사용하세요. 다른 Google Cloud 계정을 사용하는 경우 해당 계정에 비용이 청구될 수 있습니다.
실습을 시작하고 Google Cloud 콘솔에 로그인하는 방법
-
실습 시작 버튼을 클릭합니다. 실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 대화상자가 열립니다.
왼쪽에는 다음과 같은 항목이 포함된 실습 세부정보 창이 있습니다.
- Google Cloud 콘솔 열기 버튼
- 남은 시간
- 이 실습에 사용해야 하는 임시 사용자 인증 정보
- 필요한 경우 실습 진행을 위한 기타 정보
-
Google Cloud 콘솔 열기를 클릭합니다(Chrome 브라우저를 실행 중인 경우 마우스 오른쪽 버튼으로 클릭하고 시크릿 창에서 링크 열기를 선택합니다).
실습에서 리소스가 가동되면 다른 탭이 열리고 로그인 페이지가 표시됩니다.
팁: 두 개의 탭을 각각 별도의 창으로 나란히 정렬하세요.
참고: 계정 선택 대화상자가 표시되면 다른 계정 사용을 클릭합니다.
-
필요한 경우 아래의 사용자 이름을 복사하여 로그인 대화상자에 붙여넣습니다.
{{{user_0.username | "Username"}}}
실습 세부정보 창에서도 사용자 이름을 확인할 수 있습니다.
-
다음을 클릭합니다.
-
아래의 비밀번호를 복사하여 시작하기 대화상자에 붙여넣습니다.
{{{user_0.password | "Password"}}}
실습 세부정보 창에서도 비밀번호를 확인할 수 있습니다.
-
다음을 클릭합니다.
중요: 실습에서 제공하는 사용자 인증 정보를 사용해야 합니다. Google Cloud 계정 사용자 인증 정보를 사용하지 마세요.
참고: 이 실습에 자신의 Google Cloud 계정을 사용하면 추가 요금이 발생할 수 있습니다.
-
이후에 표시되는 페이지를 클릭하여 넘깁니다.
- 이용약관에 동의합니다.
- 임시 계정이므로 복구 옵션이나 2단계 인증을 추가하지 않습니다.
- 무료 체험판을 신청하지 않습니다.
잠시 후 Google Cloud 콘솔이 이 탭에서 열립니다.
참고: Google Cloud 제품 및 서비스에 액세스하려면 탐색 메뉴를 클릭하거나 검색창에 제품 또는 서비스 이름을 입력합니다.

BigQuery 콘솔 열기
- Google Cloud 콘솔에서 탐색 메뉴 > BigQuery를 선택합니다.
Cloud 콘솔의 BigQuery에 오신 것을 환영합니다라는 메시지 상자가 열립니다. 이 메시지 상자에서는 빠른 시작 가이드 및 출시 노트로 연결되는 링크가 제공됩니다.
-
완료를 클릭합니다.
BigQuery 콘솔이 열립니다.
작업 1. 테이블을 저장할 새 데이터 세트 만들기
-
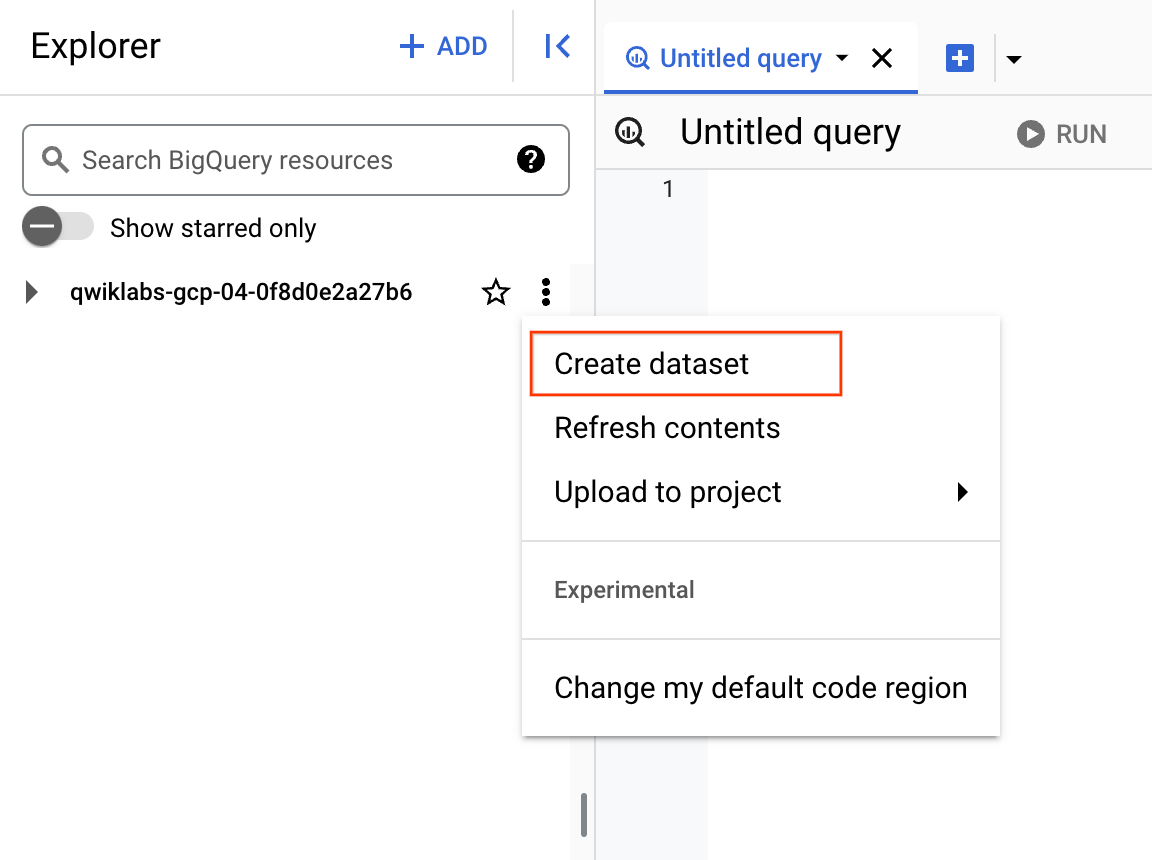
BigQuery에서 프로젝트 ID 옆에 있는 작업 보기 아이콘을 클릭하고 데이터 세트 만들기를 선택합니다.
-
데이터 세트 ID를 ecommerce로 설정하고 다른 옵션은 기본값으로 둡니다(데이터 위치, 기본 테이블 만료).
-
데이터 세트 만들기를 클릭합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
테이블을 저장할 새 데이터 세트 만들기
작업 2. CREATE TABLE 문 문제 해결
데이터 분석가팀에서 새로운 전자상거래 데이터 세트에 영구 테이블을 만들기 위해 설계된 아래와 같은 쿼리 문을 제공했습니다. 하지만 아쉽게도 제대로 작동하지 않습니다.
각 쿼리가 실패하는 이유를 진단하고 해결책을 제시하세요.
BigQuery에서 SQL로 테이블을 만드는 규칙
다음 테이블 만들기 규칙을 읽어보세요. 잘못된 쿼리를 수정할 때 이 규칙을 가이드로 사용합니다.
- 지정된 열 목록 또는 query_statement에서 도출된 열(또는 둘 다)이 있어야 합니다.
- 열 목록과 as query_statement 절이 모두 있는 경우 BigQuery는 as query_statement 절의 이름을 무시하고 위치를 기준으로 열 목록과 열을 일치시킵니다.
- as query_statement 절이 있고 열 목록이 없는 경우 BigQuery는 as query_statement 절에서 열 이름과 유형을 확인합니다.
- 열 이름은 열 목록 또는 as query_statement 절을 통해 지정되어야 합니다.
- 중복 열 이름은 허용되지 않습니다.
쿼리 1: 열, 열, 열
- BigQuery 편집기에 다음 쿼리를 추가해 실행하고, 오류를 진단하고, 이어지는 질문에 답합니다.
#standardSQL
# copy one day of ecommerce data to explore
CREATE OR REPLACE TABLE ecommerce.all_sessions_raw_20170801
OPTIONS(
description="Raw data from analyst team into our dataset for 08/01/2017"
) AS
SELECT fullVisitorId, * FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20170801' #56,989 records
;
Error: CREATE TABLE has columns with duplicate name fullVisitorId at [7:2]
위 쿼리에서 위반된 테이블 만들기 규칙은 무엇인가요?
쿼리 2: 열 재검토
- BigQuery 편집기에 다음 쿼리를 추가해 실행하고, 오류를 진단하고, 이어지는 질문에 답합니다.
#standardSQL
# copy one day of ecommerce data to explore
CREATE OR REPLACE TABLE ecommerce.all_sessions_raw_20170801
#schema
(
fullVisitorId STRING OPTIONS(description="Unique visitor ID"),
channelGrouping STRING OPTIONS(description="Channel e.g. Direct, Organic, Referral...")
)
OPTIONS(
description="Raw data from analyst team into our dataset for 08/01/2017"
) AS
SELECT * FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20170801' #56,989 records
;
Error: The number of columns in the column definition list does not match the number of columns produced by the query at [5:1]
위 쿼리에서 위반된 테이블 만들기 규칙은 무엇인가요?
참고: 새 테이블의 필드 스키마는 쿼리 문에서 반환되는 열의 개수와 일치해야 합니다. 위의 예시에서는 fullVisitorId 및 channelGrouping으로 두 개의 열 스키마를 지정했지만 쿼리 문에서는 모든 열이 반환되도록(\*) 지정했습니다.
쿼리 3: 확인이 필요한 유효한 쿼리
- BigQuery 편집기에 다음 쿼리를 추가해 실행하고, 오류를 진단하고, 이어지는 질문에 답합니다.
#standardSQL
# copy one day of ecommerce data to explore
CREATE OR REPLACE TABLE ecommerce.all_sessions_raw_20170801
#schema
(
fullVisitorId STRING OPTIONS(description="Unique visitor ID"),
channelGrouping STRING OPTIONS(description="Channel e.g. Direct, Organic, Referral...")
)
OPTIONS(
description="Raw data from analyst team into our dataset for 08/01/2017"
) AS
SELECT fullVisitorId, city FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20170801' #56,989 records
;
Valid: This query will process 1.1 GiB when run.
열 목록과 as query_statement 절이 모두 있는 경우 BigQuery는 as query_statement 절의 이름을 무시하고 위치를 기준으로 열 목록과 열을 일치시킨다는 규칙 2를 기억하세요.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
테이블 만들기
쿼리 4: 게이트키퍼
- BigQuery 편집기에 아래 쿼리를 실행하고, 오류를 진단하고, 이어지는 질문에 답합니다.
#standardSQL
# copy one day of ecommerce data to explore
CREATE OR REPLACE TABLE ecommerce.all_sessions_raw_20170801
#schema
(
fullVisitorId STRING NOT NULL OPTIONS(description="Unique visitor ID"),
channelGrouping STRING NOT NULL OPTIONS(description="Channel e.g. Direct, Organic, Referral..."),
totalTransactionRevenue INT64 NOT NULL OPTIONS(description="Revenue * 10^6 for the transaction")
)
OPTIONS(
description="Raw data from analyst team into our dataset for 08/01/2017"
) AS
SELECT fullVisitorId, channelGrouping, totalTransactionRevenue FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20170801' #56,989 records
;
Valid: This query will process 907.52 MiB when run.
쿼리를 수정한 후 수정된 쿼리를 다시 실행하여 성공적으로 실행되는지 확인합니다.
쿼리 5: 의도한 대로 작동
- BigQuery 편집기에서 다음 쿼리를 실행하고 이어지는 질문에 답합니다.
#standardSQL
# copy one day of ecommerce data to explore
CREATE OR REPLACE TABLE ecommerce.all_sessions_raw_20170801
#schema
(
fullVisitorId STRING NOT NULL OPTIONS(description="Unique visitor ID"),
channelGrouping STRING NOT NULL OPTIONS(description="Channel e.g. Direct, Organic, Referral..."),
totalTransactionRevenue INT64 OPTIONS(description="Revenue * 10^6 for the transaction")
)
OPTIONS(
description="Raw data from analyst team into our dataset for 08/01/2017"
) AS
SELECT fullVisitorId, channelGrouping, totalTransactionRevenue FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20170801' #56,989 records
;
-
ecommerce 데이터 세트 패널을 살펴보고
all_sessions_raw_(1)이 있는지 확인합니다.
전체 테이블 이름이 표시되지 않는 이유는 무엇인가요?
답변: 테이블 서픽스 20170801이 일별로 자동으로 파티션되기 때문입니다. 다른 날짜에 대한 테이블을 더 만들면 all_sessions_raw_(N)의 N 값이 고유한 날짜 데이터만큼 증가합니다. 데이터 테이블을 파티셔닝하는 다양한 방법을 살펴보는 또 다른 실습도 있습니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
의도한 대로 작동
쿼리 6: 실습 단계
목표: 쿼리 편집기에서 2017년 8월 1일에 수익이 있는 모든 트랜잭션을 저장하는 새 영구 테이블을 만듭니다.
아래 규칙을 가이드로 사용하세요.
-
revenue_transactions_20170801이라는 이름의 새 테이블을 전자상거래 데이터 세트에 만듭니다. 테이블이 이미 있는 경우 바꿉니다.
-
data-to-insights.ecommerce.all_sessions_raw 테이블을 원시 데이터 소스로 사용합니다.
- 수익 필드를 1,000,000으로 나누고 INTEGER 대신 FLOAT64로 저장합니다.
- 최종 테이블에는 수익이 있는 트랜잭션만 포함합니다(힌트: WHERE 절 사용).
- 20170801의 트랜잭션만 포함합니다.
- 다음 필드를 포함합니다.
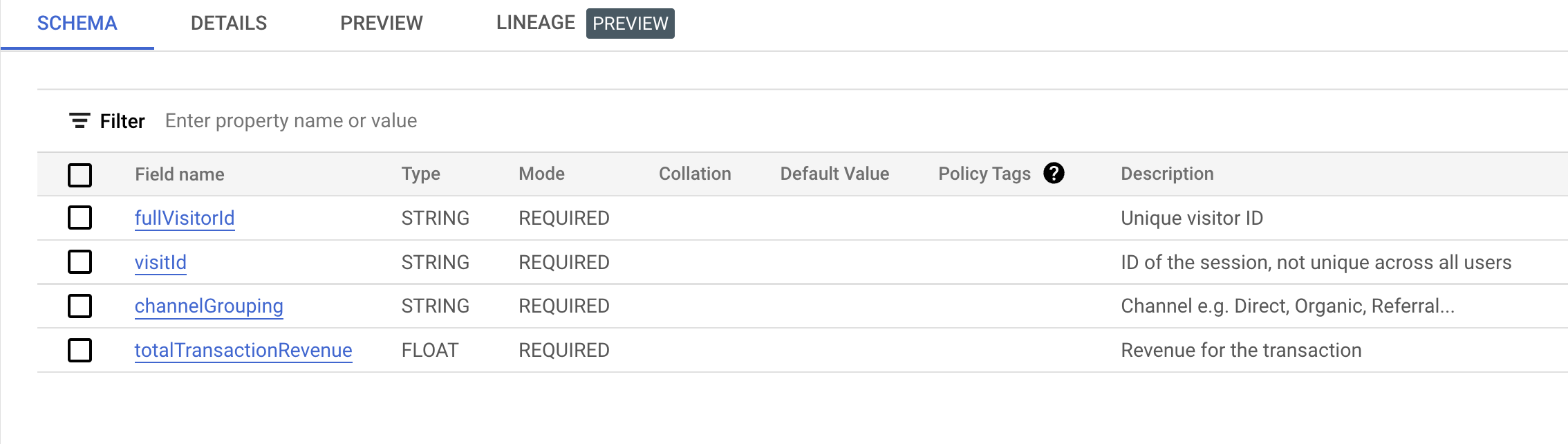
- fullVisitorId를 필수 문자열 필드로 설정합니다.
- visitId를 필수 문자열 필드로 설정합니다(힌트: 유형 변환 필요).
- channelGrouping을 필수 문자열 필드로 설정합니다.
- totalTransactionRevenue를 FLOAT64 필드로 설정합니다.
-
스키마를 참조하여 위의 4개 필드에 대한 간단한 설명을 추가합니다.
-
fullVisitorId와 visitId가 같은 레코드는 중복 삭제해야 합니다(힌트: DISTINCT 사용).
- BigQuery에서 위의 프롬프트에 대한 답안을 작성하고 아래의 답안과 비교합니다.
예시 답안:
#standardSQL
# copy one day of ecommerce data to explore
CREATE OR REPLACE TABLE ecommerce.revenue_transactions_20170801
#schema
(
fullVisitorId STRING NOT NULL OPTIONS(description="Unique visitor ID"),
visitId STRING NOT NULL OPTIONS(description="ID of the session, not unique across all users"),
channelGrouping STRING NOT NULL OPTIONS(description="Channel e.g. Direct, Organic, Referral..."),
totalTransactionRevenue FLOAT64 NOT NULL OPTIONS(description="Revenue for the transaction")
)
OPTIONS(
description="Revenue transactions for 08/01/2017"
) AS
SELECT DISTINCT
fullVisitorId,
CAST(visitId AS STRING) AS visitId,
channelGrouping,
totalTransactionRevenue / 1000000 AS totalTransactionRevenue
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20170801'
AND totalTransactionRevenue IS NOT NULL #XX transactions
;
-
쿼리를 성공적으로 실행한 후 ecommerce 데이터 세트에서 새 테이블의 이름이 revenue_transactions_20170801인지 확인하고 선택합니다.
-
아래 예시와 비교하여 스키마를 확인합니다. 필드 유형, 필수, 설명(선택사항)을 확인하세요.
업스트림 소스 데이터 업데이트 처리
비활성 데이터를 해결하는 방법은 무엇인가요?
보고 테이블의 비활성 데이터를 해결하는 방법은 두 가지입니다.
- 새 레코드를 삽입하는 쿼리를 다시 실행하여 영구 테이블을 주기적으로 새로고침합니다. 이는 BigQuery 예약 쿼리 또는 Cloud Dataprep/Cloud Dataflow 워크플로를 통해 수행할 수 있습니다.
- 논리적 뷰를 사용하여 뷰가 선택될 때마다 저장된 쿼리를 다시 실행합니다.
이 실습의 나머지 부분에서는 논리적 뷰를 만드는 방법을 중점적으로 다룹니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
테이블 만들기
작업 3. 뷰 만들기
뷰는 뷰가 호출될 때마다 실행되는 저장된 쿼리입니다. BigQuery에서 뷰는 논리적이며 구체화되지 않습니다. 뷰의 일부로 저장되는 것은 쿼리뿐이며, 기본 데이터는 저장되지 않습니다.
최근 100건의 트랜잭션 쿼리
- 아래 쿼리를 복사하여 붙여넣고 BigQuery에서 실행합니다.
#standardSQL
SELECT DISTINCT
date,
fullVisitorId,
CAST(visitId AS STRING) AS visitId,
channelGrouping,
totalTransactionRevenue / 1000000 AS totalTransactionRevenue
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE totalTransactionRevenue IS NOT NULL
ORDER BY date DESC # latest transactions
LIMIT 100
;
- 검토하며 결과를 필터링합니다. 2,000달러를 초과하는 최근 트랜잭션은 무엇인가요?
답변:
|
date
|
fullVisitorId
|
visitId
|
channelGrouping
|
totalTransactionRevenue
|
|
20170801
|
9947542428111966715
|
1501608078
|
추천
|
2934.61
|
이 공개 전자상거래 데이터 세트에 새 레코드가 추가되면 최근 트랜잭션도 업데이트됩니다.
- 시간을 절약하고 더 나은 조직화 및 공동작업을 지원하기 위해 아래와 같이 일반적인 보고 쿼리를 뷰로 저장할 수 있습니다.
#standardSQL
CREATE OR REPLACE VIEW ecommerce.vw_latest_transactions
AS
SELECT DISTINCT
date,
fullVisitorId,
CAST(visitId AS STRING) AS visitId,
channelGrouping,
totalTransactionRevenue / 1000000 AS totalTransactionRevenue
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE totalTransactionRevenue IS NOT NULL
ORDER BY date DESC # latest transactions
LIMIT 100
;
참고: 이름만 보고 테이블에서 SELECT를 수행하는지 뷰에서 SELECT를 수행하는지 알기 어려운 경우가 많습니다. 간단한 규칙은 뷰 이름에 vw_를 프리픽스로 붙이거나 _vw 또는 _view와 같은 서픽스를 추가하는 것입니다.
OPTIONS를 사용하여 뷰에 설명과 라벨을 지정할 수도 있습니다.
- 아래 쿼리를 복사하여 붙여넣고 BigQuery에서 실행합니다.
#standardSQL
CREATE OR REPLACE VIEW ecommerce.vw_latest_transactions
OPTIONS(
description="latest 100 ecommerce transactions",
labels=[('report_type','operational')]
)
AS
SELECT DISTINCT
date,
fullVisitorId,
CAST(visitId AS STRING) AS visitId,
channelGrouping,
totalTransactionRevenue / 1000000 AS totalTransactionRevenue
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE totalTransactionRevenue IS NOT NULL
ORDER BY date DESC # latest transactions
LIMIT 100
;
-
ecommerce 데이터 세트에서 새로 만든 vw_latest_transactions 테이블을 찾아 선택합니다.
-
세부정보 탭을 선택합니다.
-
뷰의 설명과 라벨이 BigQuery UI에 제대로 표시되는지 확인합니다.
세부정보 페이지에서 뷰를 정의하는 쿼리도 볼 수 있습니다. 이는 본인 또는 팀원이 만든 뷰의 논리를 이해하는 데 유용합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
뷰 만들기
- 이제 다음 쿼리를 실행하여 새 뷰를 만듭니다.
#standardSQL
# top 50 latest transactions
CREATE VIEW ecommerce.vw_latest_transactions # CREATE
OPTIONS(
description="latest 50 ecommerce transactions",
labels=[('report_type','operational')]
)
AS
SELECT DISTINCT
date,
fullVisitorId,
CAST(visitId AS STRING) AS visitId,
channelGrouping,
totalTransactionRevenue / 1000000 AS totalTransactionRevenue
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE totalTransactionRevenue IS NOT NULL
ORDER BY date DESC # latest transactions
LIMIT 50
;
Error: Already Exists: Table project-name:ecommerce.vw_latest_transactions
이전에 이미 뷰를 만들었다면 오류가 표시될 수 있습니다. 이유를 알 수 있나요?
답변: 뷰 생성 문이 CREATE OR REPLACE 대신 단순하게 CREATE로 업데이트되어 기존 테이블이나 뷰가 이미 존재하는 경우 덮어쓰지 않게 되었습니다. 세 번째 옵션인 CREATE VIEW IF NOT EXISTS를 사용하면 테이블이나 뷰가 존재하지 않는 경우에만 생성할 수 있으며, 그렇지 않으면 생성을 건너뛰고 오류가 발생하지 않습니다.
뷰 만들기: 실습 단계
시나리오: 사기 방지팀에서 수동으로 검토할 수 있도록 주문 금액이 1,000 이상인 최근 10건의 트랜잭션을 나열하는 보고서를 생성해 달라고 요청했습니다.
작업: 2017년 1월 1일 이후에 발생한 수익이 1,000을 초과하는 최근 10개 트랜잭션을 모두 반환하는 새 뷰를 만듭니다.
다음 규칙을 가이드로 사용하세요.
-
전자상거래 데이터 세트에 'vw_large_transactions'라는 이름의 새 뷰를 만듭니다. 뷰가 이미 존재하면 바꿉니다.
-
뷰에 'large transactions for review'라는 설명을 지정합니다.
-
뷰에 [("org_unit", "loss_prevention")]이라는 라벨을 지정합니다.
-
data-to-insights.ecommerce.all_sessions_raw 테이블을 원시 데이터 소스로 사용합니다.
-
수익 필드를 1,000,000으로 나눕니다.
-
수익이 1,000 이상인 트랜잭션만 포함합니다.
-
20170101 이후의 트랜잭션만 포함하고 최근 트랜잭션 순으로 표시합니다.
-
currencyCode = 'USD'만 포함합니다.
-
다음 필드를 반환합니다.
- date
- fullVisitorId
- visitId
- channelGrouping
- totalTransactionRevenue AS revenue
- currencyCode
- v2ProductName
-
레코드는 중복 삭제해야 합니다(힌트: DISTINCT 사용).
-
다음을 시도해 보세요.
/*
write the answer to the above prompt in BigQuery and compare it to the answer given below
*/
예시 답안:
#standardSQL
CREATE OR REPLACE VIEW ecommerce.vw_large_transactions
OPTIONS(
description="large transactions for review",
labels=[('org_unit','loss_prevention')]
)
AS
SELECT DISTINCT
date,
fullVisitorId,
visitId,
channelGrouping,
totalTransactionRevenue / 1000000 AS revenue,
currencyCode
#v2ProductName
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE
(totalTransactionRevenue / 1000000) > 1000
AND currencyCode = 'USD'
ORDER BY date DESC # latest transactions
LIMIT 10
;
별칭이 지정된 필드 이름은 필터로 사용할 수 없으므로 WHERE 절에서 나눗셈을 반복해야 합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
최근 10개의 트랜잭션을 반환하는 새 뷰 만들기
추가 크레딧
시나리오: 사기 방지 부서는 제공된 쿼리에 만족하며 의심스러운 주문을 매일 모니터링합니다. 이번에는 각 주문에 포함된 제품 샘플을 이전에 반환된 쿼리 결과에 포함해 달라고 요청했습니다.
BigQuery 문자열 집계 함수 STRING_AGG와 v2ProductName 필드를 사용하여 이전 쿼리를 수정하면 각 순서에 따라 알파벳 순으로 나열된 제품 이름 10개를 반환합니다.
예시 답안:
#standardSQL
CREATE OR REPLACE VIEW ecommerce.vw_large_transactions
OPTIONS(
description="large transactions for review",
labels=[('org_unit','loss_prevention')]
)
AS
SELECT DISTINCT
date,
fullVisitorId,
visitId,
channelGrouping,
totalTransactionRevenue / 1000000 AS totalTransactionRevenue,
currencyCode,
STRING_AGG(DISTINCT v2ProductName ORDER BY v2ProductName LIMIT 10) AS products_ordered
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE
(totalTransactionRevenue / 1000000) > 1000
AND currencyCode = 'USD'
GROUP BY 1,2,3,4,5,6
ORDER BY date DESC # latest transactions
LIMIT 10
여기서는 두 가지가 추가되었는데 하나는 각 주문의 제품 목록을 집계하는 STRING_AGG()이고 다른 하나는 집계를 수행 중이므로 필요한 GROUP BY가 다른 필드에 추가되었습니다.
데이터 액세스 제한을 위해 뷰에서 SESSION_USER() 사용
시나리오: 데이터팀 팀장은 방금 만든 뷰에서 반환된 데이터를 볼 수 있는 조직 내 사용자를 제한하는 방법을 제공해 달라고 요청했습니다. 주문 정보는 특히 민감한 정보이므로 이러한 정보를 확인해야 하는 사용자와만 공유해야 합니다.
작업: qwiklabs.net 세션 도메인을 사용하는 로그인 사용자만 기본 뷰의 데이터를 볼 수 있도록 앞서 만든 뷰를 수정합니다. (참고: 나중에 액세스 권한에 대한 실습에서 특정 사용자 그룹 허용 목록을 만들 예정이며, 지금은 세션 사용자의 도메인을 기준으로 검증합니다.)
- 자신의 세션 로그인 정보를 보려면 SESSION_USER()를 사용하는 아래 쿼리를 실행합니다.
#standardSQL
SELECT
SESSION_USER() AS viewer_ldap;
xxxx@qwiklabs.net이 표시됩니다.
- 아래 쿼리를 수정하여
qwiklabs.net 도메인의 사용자만 결과를 볼 수 있도록 필터를 추가합니다.
#standardSQL
SELECT DISTINCT
SESSION_USER() AS viewer_ldap,
REGEXP_EXTRACT(SESSION_USER(), r'@(.+)') AS domain,
date,
fullVisitorId,
visitId,
channelGrouping,
totalTransactionRevenue / 1000000 AS totalTransactionRevenue,
currencyCode,
STRING_AGG(DISTINCT v2ProductName ORDER BY v2ProductName LIMIT 10) AS products_ordered
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE
(totalTransactionRevenue / 1000000) > 1000
AND currencyCode = 'USD'
# add filter here
GROUP BY 1,2,3,4,5,6,7,8
ORDER BY date DESC # latest transactions
LIMIT 10
예시 답안:
#standardSQL
SELECT DISTINCT
SESSION_USER() AS viewer_ldap,
REGEXP_EXTRACT(SESSION_USER(), r'@(.+)') AS domain,
date,
fullVisitorId,
visitId,
channelGrouping,
totalTransactionRevenue / 1000000 AS totalTransactionRevenue,
currencyCode,
STRING_AGG(DISTINCT v2ProductName ORDER BY v2ProductName LIMIT 10) AS products_ordered
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE
(totalTransactionRevenue / 1000000) > 1000
AND currencyCode = 'USD'
AND REGEXP_EXTRACT(SESSION_USER(), r'@(.+)') IN ('qwiklabs.net')
GROUP BY 1,2,3,4,5,6,7,8
ORDER BY date DESC # latest transactions
LIMIT 10
- 위 쿼리를 실행하여 반환된 레코드를 볼 수 있는지 확인합니다.
이제 IN 필터 REGEXP_EXTRACT(SESSION_USER(), r'@(.+)') IN ('')에서 모든 도메인을 삭제하고 쿼리를 다시 실행하면 0개의 레코드가 반환되는 것을 확인할 수 있습니다.
- 위의 새 쿼리를 사용하여 vw_large_transactions 뷰를 다시 만들고 바꿉니다. 추가 OPTIONS 파라미터로 전체 뷰의
expiration_timestamp를 지금부터 90일 후로 설정합니다.
expiration_timestamp=TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 90 DAY).
예시 답안:
#standardSQL
CREATE OR REPLACE VIEW ecommerce.vw_large_transactions
OPTIONS(
description="large transactions for review",
labels=[('org_unit','loss_prevention')],
expiration_timestamp=TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)
)
AS
#standardSQL
SELECT DISTINCT
SESSION_USER() AS viewer_ldap,
REGEXP_EXTRACT(SESSION_USER(), r'@(.+)') AS domain,
date,
fullVisitorId,
visitId,
channelGrouping,
totalTransactionRevenue / 1000000 AS totalTransactionRevenue,
currencyCode,
STRING_AGG(DISTINCT v2ProductName ORDER BY v2ProductName LIMIT 10) AS products_ordered
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE
(totalTransactionRevenue / 1000000) > 1000
AND currencyCode = 'USD'
AND REGEXP_EXTRACT(SESSION_USER(), r'@(.+)') IN ('qwiklabs.net')
GROUP BY 1,2,3,4,5,6,7,8
ORDER BY date DESC # latest transactions
LIMIT 10;
참고: expiration_timestamp 옵션은 영구 테이블에 적용될 수도 있습니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
데이터 액세스 제한을 위한 뷰에서 session_user를 사용해 쿼리 실행
- 아래 SELECT 문을 사용하여 뷰에서 반환된 데이터(도메인 액세스 권한이 있는 경우)와 뷰 세부정보의 만료 타임스탬프를 볼 수 있는지 확인합니다.
#standardSQL
SELECT * FROM ecommerce.vw_large_transactions;
수고하셨습니다
BigQuery 내에서 SQL DDL(데이터 정의 언어)을 사용하여 테이블과 액세스 제어 뷰를 만들었습니다.
다음 단계/더 학습하기
이미 Google 애널리틱스 계정이 있고 BigQuery에서 자체 데이터 세트를 쿼리하고 싶으신가요? 이 내보내기 가이드를 따르세요.
설명서 최종 업데이트: 2024년 12월 24일
실습 최종 테스트: 2024년 12월 24일
Copyright 2025 Google LLC. All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.





