BigQuery est la base de données d'analyse NoOps, économique et entièrement gérée de Google. Avec BigQuery, vous pouvez interroger plusieurs téraoctets de données sans avoir à gérer d'infrastructure ni faire appel à un administrateur de base de données. Basé sur le langage SQL et le modèle de paiement à l'usage, BigQuery vous permet de vous concentrer sur l'analyse des données pour en dégager des insights pertinents.
Cet atelier va vous donner toutes les ficelles pour utiliser des données semi-structurées (ingestion d'ensembles de données JSON, types de données tableau) dans BigQuery. Dénormaliser votre schéma en une table unique avec des champs imbriqués et répétés permet d'améliorer les performances, mais l'utilisation de la syntaxe SQL avec les données de tableau (array) peut être délicate. Vous allez vous entraîner à charger, interroger, corriger et désimbriquer divers ensembles de données semi-structurées.
Objectifs
Dans cet atelier, vous allez apprendre à :
ingérer des ensembles de données JSON ;
créer des objets ARRAY et STRUCT ;
désimbriquer des données semi-structurées pour obtenir des insights.
Avant de commencer l'atelier
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Qwiklabs dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à Google Cloud Console.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ouvrir la console BigQuery
Dans Google Cloud Console, sélectionnez le menu de navigation > BigQuery :
Le message Welcome to BigQuery in the Cloud Console (Bienvenue sur BigQuery dans Cloud Console) s'affiche. Il contient un lien vers le guide de démarrage rapide et répertorie les mises à jour de l'interface utilisateur.
Cliquez sur Done (OK).
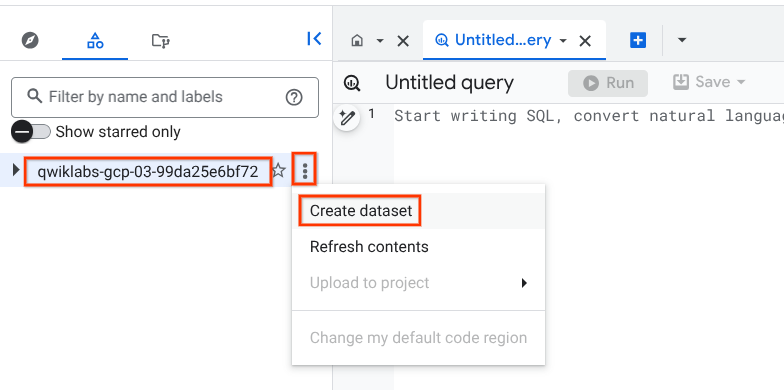
Tâche 1 : Créer un ensemble de données
Pour créer un ensemble de données, cliquez sur l'icône Afficher les actions à côté de votre ID de projet, puis sélectionnez Créer un ensemble de données.
Nommez le nouvel ensemble de données fruit_store. Laissez les valeurs par défaut des autres options, "Emplacement des données" et "Expiration de la table par défaut".
Cliquez sur CRÉER UN ENSEMBLE DE DONNÉES.
Tâche 2 : S'entraîner à utiliser des tableaux en SQL
Normalement, en langage SQL, chaque ligne est associée à une seule valeur, comme dans la liste de fruits ci-dessous :
Ligne
Fruit
1
raspberry
2
blackberry
3
strawberry
4
cherry
Comment procéder si vous voulez une liste de fruits pour chaque personne dans le magasin ? La liste pourrait alors se présenter comme suit :
Ligne
Fruit
Person
1
raspberry
sally
2
blackberry
sally
3
strawberry
sally
4
cherry
sally
5
orange
frederick
6
apple
frederick
Dans une base de données relationnelle SQL traditionnelle, vous remarqueriez la répétition des noms et penseriez immédiatement à diviser la table ci-dessus en deux tables distinctes : Fruits et People (Personnes).
Dans BigQuery, vous allez recourir à une méthode plus rapide qui consiste à utiliser le type de données Array pour obtenir le résultat suivant :
Ligne
Fruit (tableau)
Person
1
raspberry
sally
blackberry
strawberry
cherry
2
orange
frederick
apple
Observez les différences entre cette table et les tables précédentes.
Celle-ci ne comporte que deux lignes.
Une même ligne contient plusieurs valeurs du champ Fruit.
Les personnes sont associées à toutes les valeurs du champ.
Il existe une méthode plus simple pour interpréter le tableau Fruit :
Ligne
Fruit (tableau)
Person
1
[raspberry, blackberry, strawberry, cherry]
sally
2
[orange, apple]
frederick
Ces deux tables sont exactement identiques. Deux points importants sont à retenir ici :
Un tableau est simplement une liste d'éléments entre crochets [ ].
BigQuery (en mode SQL standard) affiche les tableaux sous une forme aplatie. BigQuery liste simplement la valeur verticalement dans le tableau (notez que toutes les valeurs appartiennent toujours à une ligne unique).
À votre tour ! Saisissez la commande suivante dans l'éditeur de requête BigQuery :
#standardSQL
SELECT
['raspberry', 'blackberry', 'strawberry', 'cherry'] AS fruit_array
Cliquez sur Exécuter.
Essayez maintenant d'exécuter cette requête :
#standardSQL
SELECT
['raspberry', 'blackberry', 'strawberry', 'cherry', 33] AS fruit_array
Vous allez normalement recevoir un message d'erreur ressemblant à celui-ci :
Error: Array elements of types {INT64, STRING} do not have a common supertype at [3:1]
Les objets array ne peuvent contenir qu'un seul type de données (seulement des chaînes ou seulement des nombres). À ce stade, vous vous demandez peut-être s'il est possible de créer un tableau de tableaux ? Oui, c'est possible ! Ce sujet sera traité ultérieurement.
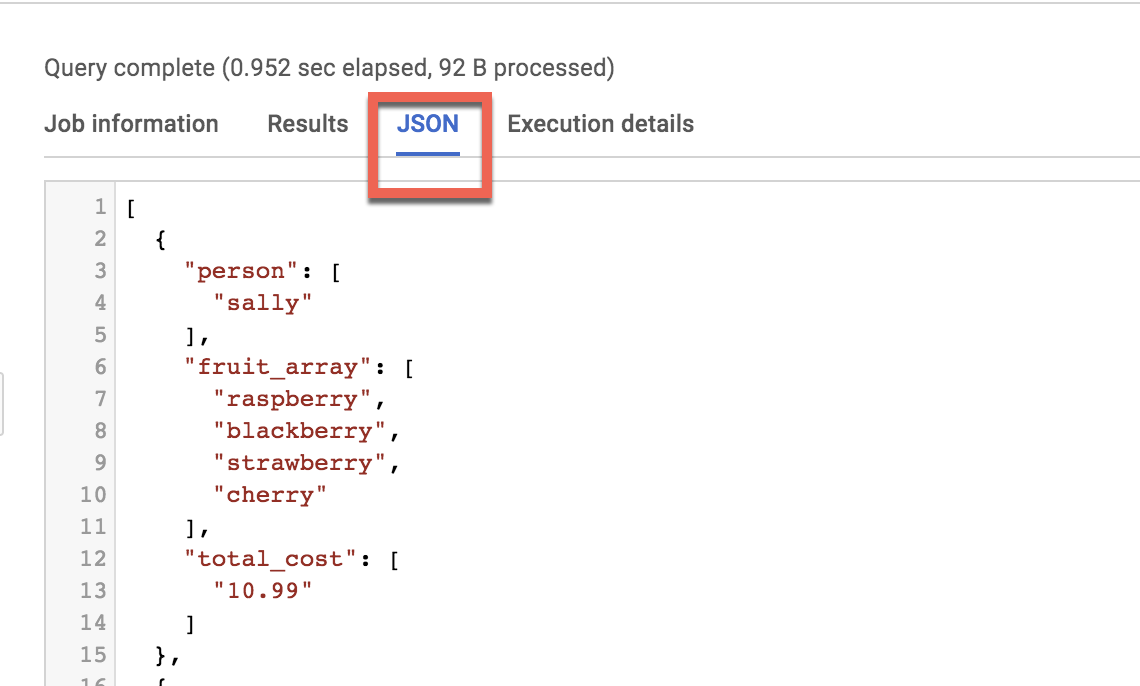
Voici la requête finale, qui indique la table à interroger :
#standardSQL
SELECT person, fruit_array, total_cost FROM `data-to-insights.advanced.fruit_store`;
Cliquez sur Exécuter.
Après avoir observé les résultats, cliquez sur l'onglet JSON pour afficher la structure imbriquée des résultats.
Importer des fichiers JSON
Comment procéderiez-vous si vous deviez ingérer un fichier JSON dans BigQuery ? Vous allez maintenant essayer de le faire.
Créez une table dans l'ensemble de données fruit_store.
Pour cela, cliquez sur l'icône Afficher les actions à côté de l'ensemble de données fruit_store, puis sélectionnez Ouvrir.
Cliquez ensuite sur Créer une table dans le panneau de droite.
Remarque : Vous devrez peut-être agrandir votre fenêtre de navigateur pour voir l'option "Créer une table".
Ajoutez les informations suivantes pour la table :
Source : choisissez Google Cloud Storage dans la liste déroulante Créer une table à partir de.
Sélectionner un fichier dans le bucket GCS : cloud-training/data-insights-course/labs/optimizing-for-performance/shopping_cart.json.
Format de fichier : JSONL (fichier JSON délimité par un retour à la ligne).
Nommez la nouvelle tablefruit_details.
Sous Schéma, cochez la case Détection automatique.
Cliquez sur Créer une table.
Cliquez sur la table fruit_details.
Dans le schéma, notez que fruit_array est marqué comme REPEATED (RÉPÉTÉ), ce qui signifie qu'il s'agit d'un tableau.
Tâche 3 : Stocker des données concernant une entité ayant différents types de données
Comme vous l'avez vu précédemment, les tableaux ne peuvent contenir qu'un seul type de données. Il existe cependant un type de données qui permet d'avoir à la fois plusieurs noms et types de champs : le type de données STRUCT.
L'ensemble de données suivant contient les temps mis par des coureurs pour réaliser un tour de piste. Chaque tour sera nommé "split" (tour de piste).
Avec cette requête, essayez la syntaxe STRUCT et notez les différents types de champ présents dans le conteneur struct :
#standardSQL
SELECT STRUCT("Rudisha" as name, 23.4 as split) as runner
Ligne
runner.name
runner.split
1
Rudisha
23.4
Que remarquez-vous concernant les alias de champ ? En raison de la présence de champs imbriqués dans l'objet struct ("name" et "split" sont un sous-ensemble de "runner"), vous obtenez une notation par points.
Comment procéder si l'enregistrement du coureur comprend plusieurs tours de piste ? Comment avoir plusieurs temps de tour de piste dans un enregistrement unique ? Indice : les tours de piste possèdent tous le même type de données numérique.
Réponse : avec un tableau, bien sûr !
Exécutez la requête ci-dessous pour vérifier :
#standardSQL
SELECT STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as splits) AS runner
Ligne
runner.name
runner.split
1
Rudisha
23.4 26.3 26.4 26.1
En résumé :
Les objets struct sont des conteneurs qui peuvent présenter plusieurs noms de champ et types de données imbriqués.
Un objet struct peut contenir un champ de type array (comme on peut le voir ci-dessus avec le champ "splits").
Charger les résultats d'autres coureurs dans une nouvelle table
Créez un ensemble de données nommé racing.
Créez une table intitulée race_results.
Procédez à l'ingestion de ce fichier JSON Google Cloud Storage :
cloud-training/data-insights-course/labs/optimizing-for-performance/race_results.json.
Source : sélectionnez Google Cloud Storage dans la liste déroulante Créer une table à partir de.
Sélectionner un fichier dans le bucket GCS : indiquez le chemin cloud-training/data-insights-course/labs/optimizing-for-performance/race_results.json.
Format de fichier : JSONL (fichier JSON délimité par un retour à la ligne). Définissez race_results comme Nom de la table.
Cliquez sur Modifier sous forme de texte et ajoutez les lignes suivantes :
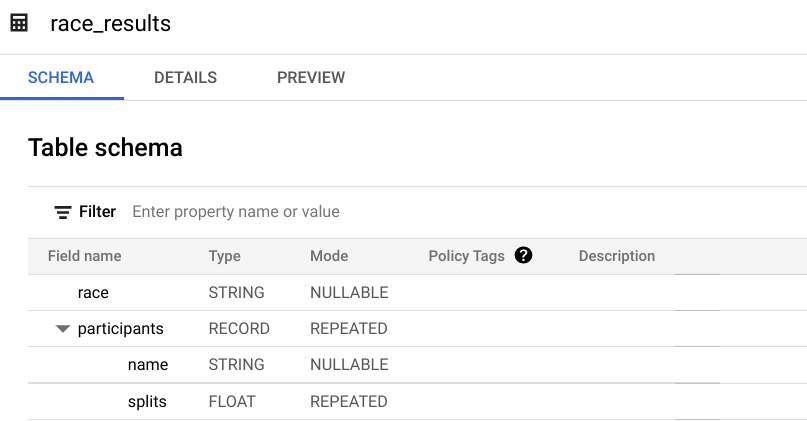
Une fois le chargement effectué, affichez l'aperçu du schéma associé à la table que vous venez de créer.
Quel champ correspond à l'objet STRUCT ? Comment le savez-vous ?
Réponse : le champ participants correspond à l'objet STRUCT, car il est du type RECORD.
Quel champ correspond à l'objet ARRAY ?
Réponse : le champ participants.splits est un tableau de valeurs flottantes à l'intérieur de l'objet struct participants parent. Il possède un mode REPEATED qui indique un tableau. On dit que les valeurs de ce tableau sont imbriquées, car plusieurs valeurs sont présentes dans un champ unique.
S'entraîner à interroger des champs imbriqués et répétés
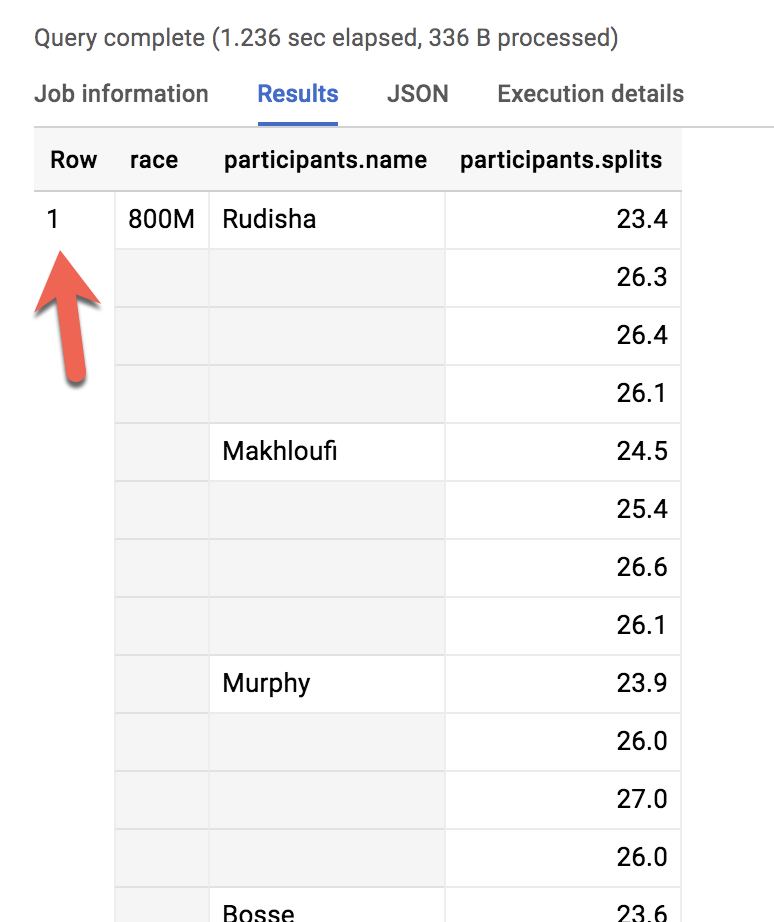
Examinons l'ensemble des coureurs pour le 800 mètres :
#standardSQL
SELECT * FROM racing.race_results
Comment procéder si vous voulez lister le nom de chaque coureur et le type de course ?
Exécutez la requête ci-dessous et observez le résultat :
#standardSQL
SELECT race, participants.name
FROM racing.race_results
Error: Cannot access field name on a value with type ARRAY<STRUCT<name STRING, splits ARRAY<FLOAT64>>>> at [2:27]
Le résultat est très semblable à celui qui vous serait renvoyé si vous omettiez l'instruction GROUP BY avec les fonctions d'agrégation. Il existe ici deux niveaux de précision différents : une ligne pour la course et trois lignes pour les noms des participants. Comment transformer ceci :
Ligne
race
participants.name
1
800M
Rudisha
2
???
Makhloufi
3
???
Murphy
...en ceci :
Ligne
race
participants.name
1
800M
Rudisha
2
800M
Makhloufi
3
800M
Murphy
Avec une base de données relationnelle SQL traditionnelle comportant une table des courses et une table des participants, comment procéderiez-vous pour obtenir des informations à partir de ces deux tables ? Vous utiliseriez la commande JOIN pour les joindre. Ici, l'objet STRUCT des participants (qui est très semblable du point de vue conceptuel à une table) fait déjà partie de votre table des courses, mais il n'est pas encore correctement corrélé à votre champ non-STRUCT "race".
Quelle commande SQL en deux mots pourriez-vous utiliser pour corréler la course de 800 mètres avec chacun des coureurs de la première table ?
Réponse : CROSS JOIN
Parfait.
Essayez maintenant d'exécuter cette requête :
#standardSQL
SELECT race, participants.name
FROM racing.race_results
CROSS JOIN
participants # this is the STRUCT (it's like a table within a table)
Error: Table name "participants" missing dataset while no default dataset is set in the request.
Bien que l'objet STRUCT des participants soit semblable à une table, techniquement il s'agit toujours d'un champ de la table racing.race_results.
Ajoutez le nom de l'ensemble de données à la requête :
#standardSQL
SELECT race, participants.name
FROM racing.race_results
CROSS JOIN
race_results.participants # full STRUCT name
Cliquez ensuite sur Exécuter.
Félicitations ! Vous avez réussi à afficher la liste de tous les coureurs de chaque course.
Ligne
race
name
1
800M
Rudisha
2
800M
Makhloufi
3
800M
Murphy
4
800M
Bosse
5
800M
Rotich
6
800M
Lewandowski
7
800M
Kipketer
8
800M
Berian
Pour simplifier la dernière requête, vous pouvez :
ajouter un alias pour la table initiale ;
remplacer les mots "CROSS JOIN" par une virgule (la virgule représente implicitement une jointure croisée).
Le résultat de la requête sera identique :
#standardSQL
SELECT race, participants.name
FROM racing.race_results AS r, r.participants
S'il y a plusieurs types de courses (800M, 100M, 200M), une commande CROSS JOIN n'aurait-elle pas seulement pour effet d'associer chaque nom de coureur à chaque course possible de la même manière qu'un produit cartésien ?
Réponse : Non. Il s'agit ici d'une jointure croisée corrélée qui ne désimbrique que les éléments associés à une ligne unique. Pour plus de détails, consultez la documentation de référence sur l'utilisation des objets ARRAY et STRUCT.
Résumé concernant les objets STRUCT :
Un objet SQL STRUCT est simplement un conteneur d'autres champs de données qui peuvent être de types différents. Le mot "struct" signifie "structure de données". Souvenez-vous de l'exemple précédent : STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as splits) AS runner.
Les objets STRUCT reçoivent un alias (comme "runner" dans l'exemple ci-dessus) et peuvent être conceptuellement assimilés à une table contenue dans votre table principale.
Vous devez désimbriquer les éléments des objets STRUCT (et ARRAY) afin de pouvoir exécuter des opérations sur ces éléments. Appliquez la fonction UNNEST() autour du nom de l'objet STRUCT lui-même ou du champ STRUCT se présentant sous forme de tableau, pour le désimbriquer et l'aplatir.
Questions de l'atelier : STRUCT()
Répondez aux questions ci-dessous en vous servant de la table racing.race_results que vous avez créée précédemment.
Tâche : écrire une requête pour compter (COUNT) le nombre total de coureurs.
Pour commencer, utilisez la requête partiellement rédigée ci-dessous :
#standardSQL
SELECT COUNT(participants.name) AS racer_count
FROM racing.race_results
Astuce : N'oubliez pas que vous devrez utiliser une jointure croisée dans votre nom d'objet struct en tant que source de données supplémentaire après l'instruction FROM.
Solution possible :
#standardSQL
SELECT COUNT(p.name) AS racer_count
FROM racing.race_results AS r, UNNEST(r.participants) AS p
Ligne
racer_count
1
8
Réponse : 8 coureurs ont participé à cette course.
Tâche 4 : Désimbriquer des tableaux à l'aide de l'opérateur UNNEST( )
Maintenant que vous êtes familiarisé avec l'utilisation des objets STRUCT, il est temps d'appliquer ces connaissances pour désimbriquer les objets ARRAY en plusieurs tableaux traditionnels.
Rappelez-vous que l'opérateur UNNEST s'applique à un objet ARRAY et renvoie une table comportant une ligne pour chaque élément de cet objet.
Vous pouvez ensuite effectuer des opérations SQL classiques, telles que :
l'agrégation de valeurs dans un tableau ;
le filtrage de tableaux pour des valeurs particulières ;
le classement et le tri de tableaux.
Pour rappel, un tableau est une liste ordonnée d'éléments possédant le même type de données.
Voici un tableau de chaînes comportant le nom des huit coureurs :
Vous pouvez créer des tableaux dans BigQuery en ajoutant des crochets [ ] entre lesquels vous insérez des valeurs séparées par une virgule.
Essayez la requête ci-dessous et veillez à noter le nombre de lignes renvoyées. Le total sera-t-il de huit lignes ?
#standardSQL
SELECT
['Rudisha','Makhloufi','Murphy','Bosse','Rotich','Lewandowski','Kipketer','Berian'] AS normal_array
Réponse : le résultat est une seule ligne comportant huit éléments de tableau.
Ligne
normal_array
1
Rudisha
Makhloufi
Murphy
Bosse
Rotich
Lewandowski
Kipketer
Berian
Conseil : Si vous avez déjà un champ qui n'est pas dans un format de tableau, vous pouvez agréger ces valeurs dans un tableau à l'aide de la commande ARRAY_AGG().
Pour rechercher les coureurs dont le nom commence par la lettre M, vous devez désimbriquer les éléments du tableau ci-dessus sous la forme de lignes séparées afin de pouvoir utiliser une clause WHERE.
Pour désimbriquer les éléments du tableau, vous devez l'encapsuler (ou encapsuler son nom) à l'aide de l'opérateur UNNEST() comme indiqué ci-dessous.
Exécutez la requête ci-dessous et notez le nombre de lignes renvoyées :
#standardSQL
SELECT * FROM
UNNEST(['Rudisha','Makhloufi','Murphy','Bosse','Rotich','Lewandowski','Kipketer','Berian']) AS unnested_array_of_names
Le résultat se présente normalement comme suit :
Ligne
unnested_array_of_names
1
Rudisha
2
Makhloufi
3
Murphy
4
Bosse
5
Rotich
6
Lewandowski
7
Kipketer
8
Berian
Vous avez réussi à dégrouper le tableau. Cette opération est également appelée aplatissement du tableau.
Ajoutez maintenant une clause WHERE normale pour filtrer ces lignes, puis exécutez la requête :
#standardSQL
SELECT * FROM
UNNEST(['Rudisha','Makhloufi','Murphy','Bosse','Rotich','Lewandowski','Kipketer','Berian']) AS unnested_array_of_names
WHERE unnested_array_of_names LIKE 'M%'
Ligne
unnested_array_of_names
1
Makhloufi
2
Murphy
Question de l'atelier : Désimbriquer les éléments d'un objet ARRAY avec UNNEST( )
Rédigez une requête qui listera le temps de course total pour les coureurs dont le nom commence par R. Classez les résultats par ordre décroissant du meilleur temps total. Utilisez l'opérateur UNNEST() en commençant avec la requête partiellement rédigée ci-dessous.
Complétez la requête :
#standardSQL
SELECT
p.name,
SUM(split_times) as total_race_time
FROM racing.race_results AS r
, r.participants AS p
, p.splits AS split_times
WHERE
GROUP BY
ORDER BY
;
Indice :
Vous devrez désimbriquer à la fois l'objet STRUCT et l'objet ARRAY contenu dans l'objet STRUCT sous la forme de sources de données après votre clause FROM.
Veillez à utiliser des alias si nécessaire.
Solution possible :
#standardSQL
SELECT
p.name,
SUM(split_times) as total_race_time
FROM racing.race_results AS r
, UNNEST(r.participants) AS p
, UNNEST(p.splits) AS split_times
WHERE p.name LIKE 'R%'
GROUP BY p.name
ORDER BY total_race_time ASC;
Ligne
name
total_race_time
1
Rudisha
102.19999999999999
2
Rotich
103.6
Tâche 5 : Filtrer les valeurs d'un tableau
Vous avez pu constater que le tour de piste le plus rapide enregistré pour la course de 800 mètres a été effectué en 23,2 secondes, mais vous n'avez pas identifié le coureur qui a réalisé ce temps. Créez une requête qui renvoie ce résultat.
Complétez la requête partiellement rédigée :
#standardSQL
SELECT
p.name,
split_time
FROM racing.race_results AS r
, r.participants AS p
, p.splits AS split_time
WHERE split_time = ;
Solution possible :
#standardSQL
SELECT
p.name,
split_time
FROM racing.race_results AS r
, UNNEST(r.participants) AS p
, UNNEST(p.splits) AS split_time
WHERE split_time = 23.2;
Ligne
name
split_time
1
Kipketer
23.2
Félicitations !
Vous avez ingéré des ensembles de données JSON, créé des objets ARRAY et STRUCT, et désimbriqué des données semi-structurées pour en dégager des insights.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2020 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Ouvrez une fenêtre de navigateur en mode navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez utiliser des données semi-structurées (ingestion d'ensembles de données JSON, types de données Array) dans BigQuery. Vous allez vous entraîner à charger, interroger, corriger et désimbriquer divers ensembles de données semi-structurées.
Durée :
0 min de configuration
·
Accessible pendant 75 min
·
Terminé après 60 min