BigQuery es la base de datos estadísticos de Google de bajo costo, no-ops y completamente administrada. Con BigQuery, puedes consultar muchos terabytes de datos sin tener que administrar infraestructuras y sin necesitar un administrador de base de datos. BigQuery usa SQL y puede aprovechar el modelo de pago por uso. BigQuery te permite enfocarte en el análisis de datos para buscar estadísticas valiosas.
En este lab, se explicará detalladamente cómo trabajar con datos semiestructurados (transferencia de archivos de tipo JSON y arrays) dentro de BigQuery. Desnormalizar tu esquema en una sola tabla con campos repetidos y anidados puede mejorar el rendimiento; no obstante, puede ser difícil usar la sintaxis de SQL para trabajar con arrays. Practicarás cómo cargar, consultar y desanidar diversos conjuntos de datos semiestructurados, además de cómo solucionar problemas en ellos.
Objetivos
En este lab, aprenderás a hacer lo siguiente:
Transferir conjuntos de datos JSON
Crear ARRAYS y STRUCTS
Desanidar datos semiestructurados para estadísticas
Configuración y requisitos
En cada lab, recibirá un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Qwiklabs desde una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesita, puede reiniciar el lab, pero deberá hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usa otras credenciales, se generarán errores o incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Abra BigQuery en Console
En Google Cloud Console, seleccione el menú de navegación > BigQuery.
Se abrirá el cuadro de mensaje Te damos la bienvenida a BigQuery en Cloud Console, que contiene un vínculo a la guía de inicio rápido y enumera las actualizaciones de la IU.
Haga clic en Listo.
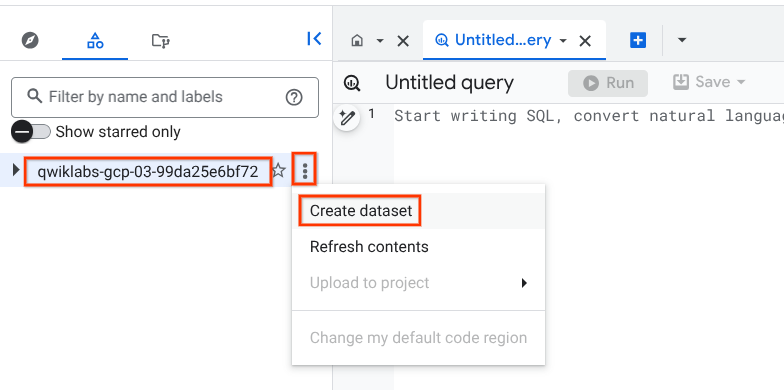
Tarea 1: Crea un conjunto de datos nuevo
Para crear un conjunto de datos, haz clic en el ícono de Ver acciones junto al ID de tu proyecto y selecciona Crear conjunto de datos.
Asígnale el nombre fruit_store al nuevo conjunto de datos. Deja todas las otras opciones en los valores predeterminados (Ubicación de los datos y Vencimiento predeterminado de la tabla).
Haz clic en CREAR CONJUNTO DE DATOS.
Tarea 2: Practica cómo trabajar con arrays en SQL
Normalmente, en SQL habrá un único valor para cada fila, como en esta lista de frutas:
Fila
Fruit
1
raspberry
2
blackberry
3
strawberry
4
cherry
¿Qué pasaría si quisieras tener una lista de frutas para cada persona que hay en la tienda? Tal vez se vería así:
Fila
Fruit
Person
1
raspberry
sally
2
blackberry
sally
3
strawberry
sally
4
cherry
sally
5
orange
frederick
6
apple
frederick
En una base de datos SQL relacional tradicional, tomarías la decisión de dividir la tabla en dos tablas diferentes de inmediato (Fruit y Person) al ver los nombres que se repiten.
En cambio, en BigQuery, usarás un enfoque más rápido que consiste en usar el tipo de datos “array” para lograr lo siguiente:
Fila
Fruit (array)
Person
1
raspberry
sally
blackberry
strawberry
cherry
2
orange
frederick
apple
Fíjate en las diferencias de esta tabla respecto a otras que hayas visto antes.
Solo tiene dos filas.
Hay muchos valores de campo para Fruit en una sola fila.
Las personas y todos los valores de campo están asociados.
Esta es una forma más sencilla de interpretar el arreglo Fruit:
Fila
Fruit (array)
Person
1
[raspberry, blackberry, strawberry, cherry]
sally
2
[orange, apple]
frederick
Ambas tablas son exactamente iguales. De aquí surgen dos aprendizajes clave:
Básicamente, un array es una lista de elementos entre corchetes [ ].
BigQuery (en modo SQL estándar) muestra arrays compactados. Solo ordena los valores del array verticalmente (ten en cuenta que todos esos valores siguen perteneciendo a una sola fila).
Compruébalo. Ingresa lo siguiente en el Editor de consultas de BigQuery:
#standardSQL
SELECT
['raspberry', 'blackberry', 'strawberry', 'cherry'] AS fruit_array
Haz clic en Ejecutar.
Ahora prueba ejecutar esta:
#standardSQL
SELECT
['raspberry', 'blackberry', 'strawberry', 'cherry', 33] AS fruit_array
Deberías ver un error parecido al siguiente:
Error: Array elements of types {INT64, STRING} do not have a common supertype at [3:1]
Los arrays solo pueden compartir un tipo de datos (todos los elementos deben ser cadenas o números). En este punto, podrías preguntarte si es posible tener un array de arrays. La respuesta es sí, pero abordaremos esto más adelante.
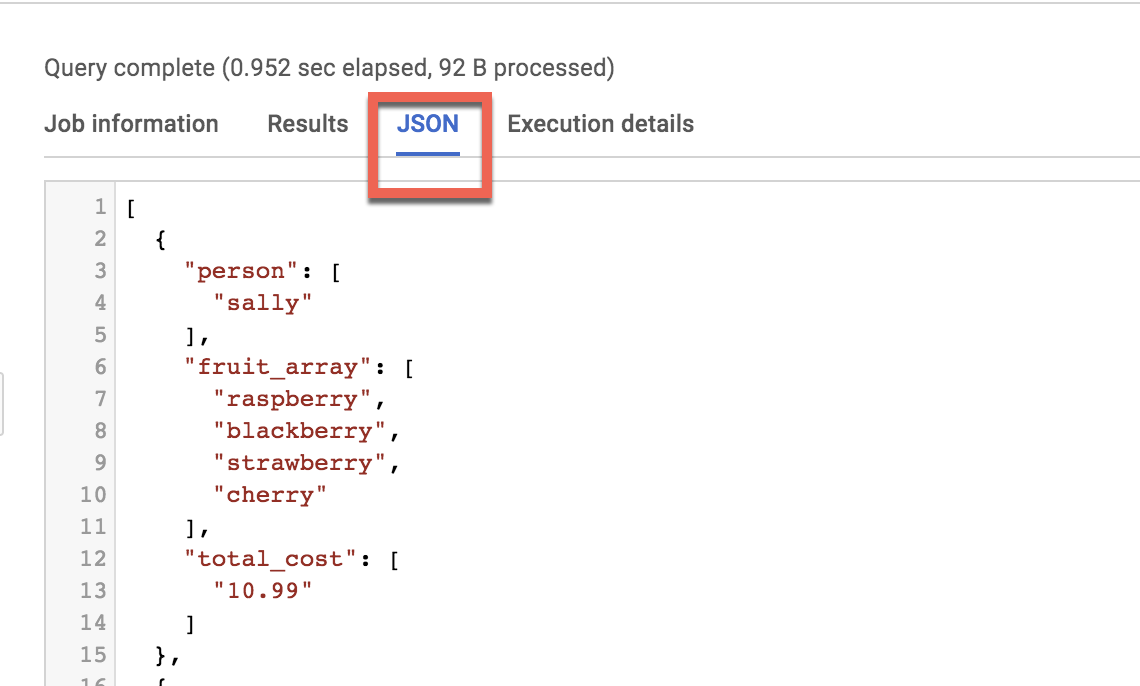
Esta es la tabla final para ejecutar la consulta:
#standardSQL
SELECT person, fruit_array, total_cost FROM `data-to-insights.advanced.fruit_store`;
Haz clic en Ejecutar.
Después de ver los resultados, haz clic en la pestaña JSON para visualizar la estructura anidada de los resultados.
Sube archivos JSON
¿Te preguntas cómo puedes transferir un archivo JSON a BigQuery? A continuación, lo intentarás.
Crea una tabla nueva en el conjunto de datos fruit_store.
Para crear la tabla, haz clic en el ícono de Ver acciones junto al conjunto de datos fruit_store y, luego, selecciona Abrir.
Luego, haz clic en Crear tabla en el panel derecho.
Nota: Es posible que debas ampliar la ventana del navegador para ver la opción Crear tabla.
Agrega los siguientes detalles a la tabla:
Fuente: Selecciona Google Cloud Storage en el menú desplegable Crear tabla desde
Selecciona el archivo del bucket de GCS:cloud-training/data-insights-course/labs/optimizing-for-performance/shopping_cart.json
Formato de archivo: JSONL (JSON delimitado por líneas nuevas)
Asigna el Nombre de la tabla nueva como fruit_details.
En Esquema, haz clic en la casilla de verificación de Detección automática.
Haz clic en Crear tabla.
Haz clic en la tabla fruit_details.
En el esquema, observa que fruit_array está marcado como REPEATED, lo que indica que es un array.
Tarea 3: Almacena datos sobre una entidad que tiene distintos tipos de datos
Como ya vimos, los arreglos solo pueden tener un tipo de datos. Sin embargo, existe un tipo de datos que permite tener varios tipos y nombres de campo: el tipo de datos struct.
El próximo conjunto de datos incluirá los tiempos de corredores en sus vueltas alrededor de una pista. A cada vuelta la llamaremos “split”.
Para esta consulta, prueba la sintaxis de STRUCT y observa los distintos tipos de campos dentro del contenedor de struct:
#standardSQL
SELECT STRUCT("Rudisha" as name, 23.4 as split) as runner
Fila
runner.name
runner.split
1
Rudisha
23.4
¿Qué puedes observar sobre los alias de campo? Puesto que nuestra “struct” contiene campos anidados (los nombres y las fracciones son un subconjunto de datos), se obtiene una notación de puntos.
¿Qué sucede si el corredor tiene varias splits en un registro?, ¿cómo podría haber varios tiempos de splits dentro de un solo registro? Pista: Todas las splits tienen el mismo tipo de datos numéricos.
Respuesta: Con un array.
Ejecuta la siguiente consulta para confirmar esto:
#standardSQL
SELECT STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as splits) AS runner
Fila
runner.name
runner.split
1
Rudisha
23.4 26.3 26.4 26.1
En resumen:
Los structs son contenedores que pueden tener varios tipos de datos y nombres de campos anidados.
Los arrays pueden ser uno de los tipos de campos dentro de una struct (como se mostró antes con el campo “split”).
Carga resultados de otras carreras en una tabla nueva
Crea un nuevo conjunto de datos llamado racing.
Crea una nueva tabla llamada race_results.
Transfiere este archivo JSON en Google Cloud Storage:
cloud-training/data-insights-course/labs/optimizing-for-performance/race_results.json.
Fuente: Selecciona Google Cloud Storage en el menú desplegable Crear tabla desde.
Selecciona el archivo del bucket de GCS:cloud-training/data-insights-course/labs/optimizing-for-performance/race_results.json.
Formato de archivo: Elige JSONL (JSON delimitado por líneas nuevas) y establece Nombre de la tabla en race_results.
Mueve el control deslizante Editar como texto y agrega lo siguiente:
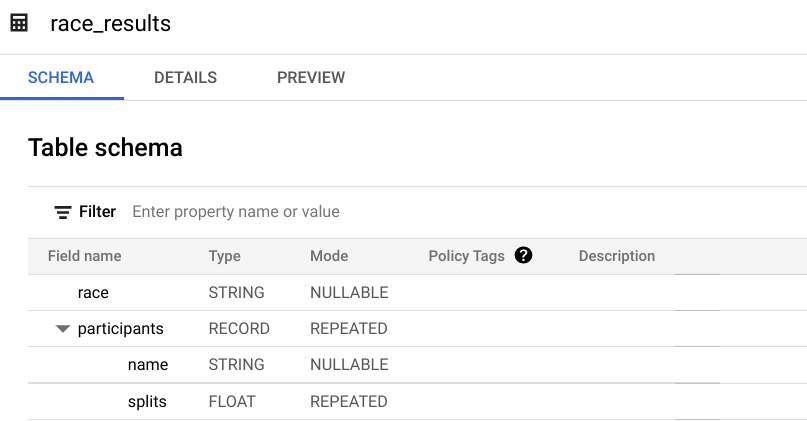
Una vez que se complete el trabajo de carga, obtén una vista previa del esquema de la tabla creada recientemente.
¿Cuál es el campo STRUCT?, ¿cómo lo sabes?
Respuesta: El campo participants es la STRUCT porque es del tipo RECORD.
¿Qué campo es el ARRAY?
Respuesta: El campo participants.splits es un array de números de punto flotante dentro de la struct principal participants. Tiene un modo REPEATED, lo que indica que es un array. Los valores de este array se llaman valores anidados porque hay varios valores dentro de un solo campo.
Practica cómo consultar campos repetidos y anidados
Veamos los tiempos de los corredores para la carrera de 800 metros:
#standardSQL
SELECT * FROM racing.race_results
¿Qué pasaría si quisieras mostrar el nombre de cada corredor y el tipo de carrera?
Ejecuta el siguiente esquema y ve qué sucede:
#standardSQL
SELECT race, participants.name
FROM racing.race_results
Error: Cannot access field name on a value with type ARRAY<STRUCT<name STRING, splits ARRAY<FLOAT64>>>> at [2:27]
Tal como sucede cuando olvidas la instrucción GROUP BY al usar funciones de suma, aquí tenemos dos niveles de detalle diferentes: una fila para la carrera y tres filas para los nombres de los participantes. ¿Qué puedes hacer para cambiar esto?
Fila
race
participants.name
1
800 m
Rudisha
2
???
Makhloufi
3
???
Murphy
…¿por esto?
Fila
race
participants.name
1
800 m
Rudisha
2
800 m
Makhloufi
3
800 m
Murphy
En SQL relacional tradicional, si tuvieras una tabla de carreras y una de participantes, ¿qué harías para obtener información de ambas tablas? Las UNIRÍAS. La STRUCT de participantes (que es conceptualmente muy similar a una tabla) ya es parte de tu tabla de carreras, pero aún no se correlaciona correctamente con tu campo “race” que no pertenece a la STRUCT.
¿Qué comando SQL de dos palabras usarías para correlacionar la carrera de 800 m con cada corredor de la primera tabla?
Respuesta: UNIÓN CRUZADA
Perfecto.
Ahora intenta ejecutar lo siguiente:
#standardSQL
SELECT race, participants.name
FROM racing.race_results
CROSS JOIN
participants # this is the STRUCT (it's like a table within a table)
Error: Table name "participants" missing dataset while no default dataset is set in the request.
Si bien la STRUCT de participantes es como una tabla, técnicamente sigue siendo un campo de la tabla racing.race_results.
Agregua el nombre del conjunto de datos a la consulta:
#standardSQL
SELECT race, participants.name
FROM racing.race_results
CROSS JOIN
race_results.participants # full STRUCT name
Luego, ejecútala.
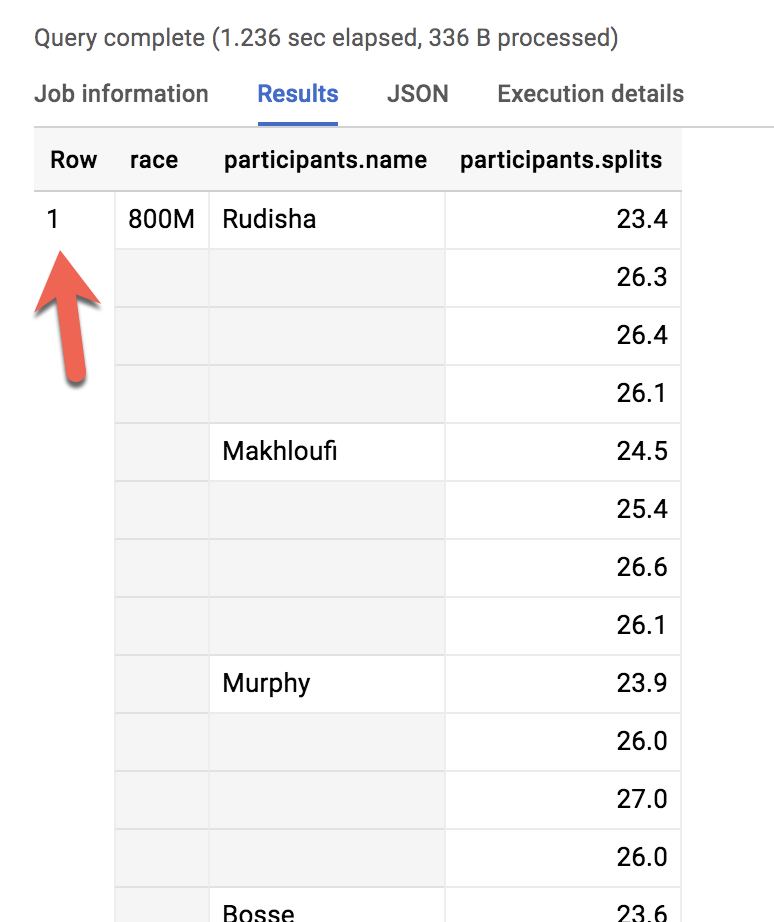
¡Bien! Mostraste correctamente la lista de todos los corredores de cada carrera.
Fila
race
name
1
800 m
Rudisha
2
800 m
Makhloufi
3
800 m
Murphy
4
800 m
Bosse
5
800 m
Rotich
6
800 m
Lewandowski
7
800 m
Kipketer
8
800 m
Berian
Para simplificar la última consulta, puedes hacer lo siguiente:
Agregar un alias para la tabla original
Reemplazar las palabras "CROSS JOIN" por una coma, ya que, implícitamente, realiza la unión cruzada
El resultado de la consulta será el mismo:
#standardSQL
SELECT race, participants.name
FROM racing.race_results AS r, r.participants
Si tienes más de un tipo de carrera (800 m, 100 m y 200 m), ¿una UNIÓN CRUZADA no asociaría el nombre de cada corredor con todas las carreras posibles como un producto cartesiano?
Respuesta: No. Esta es una unión cruzada correlacionada que solo descomprime los elementos asociados con una sola fila. Para obtener un análisis más detallado del tema, consulta la documentación de referencia sobre cómo trabajar con arrays y structs.
Resumen de las STRUCTS:
Una struct de SQL es básicamente un contenedor de otros campos de datos que pueden ser de distintos tipos. La palabra “struct” significa “estructura de datos”. Recuerda el ejemplo de antes: STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as splits) AS runner.
A las STRUCTS se les da un alias (como “runner” en el ejemplo anterior) y podemos entenderlas como una tabla dentro de una tabla principal.
Es necesario descomprimir las STRUCTS (y los arrays) para poder usar sus elementos. Incluye UNNEST() junto al nombre de la struct o del campo de la struct que es un array para descomprimirla y compactarla.
Pregunta del lab: STRUCT()
Usa la tabla racing.race_results que creaste anteriormente para responder la siguiente pregunta.
Tarea: Escribe una consulta para CONTAR cuántos corredores había en total.
Para comenzar, usa la siguiente consulta escrita parcialmente:
#standardSQL
SELECT COUNT(participants.name) AS racer_count
FROM racing.race_results
Pista: Recuerda que deberás realizar una unión cruzada en el nombre de tu struct como fuente adicional de datos después de FROM.
Solución posible:
#standardSQL
SELECT COUNT(p.name) AS racer_count
FROM racing.race_results AS r, UNNEST(r.participants) AS p
Fila
racer_count
1
8
Respuesta: 8 corredores participaron en la carrera.
Tarea 4: Desempaqueta arrays con UNNEST( )
Ahora que ya sabes cómo usar las structs, es el momento de aplicar ese conocimiento para desempaquetar algunos arrays tradicionales.
Recuerda que el operador UNNEST toma un array y devuelve una tabla con una fila para cada elemento en ese array.
Esto te permitirá realizar operaciones habituales de SQL como las siguientes:
Agregar valores dentro de un array
Filtrar arrays para valores específicos
Ordenar y clasificar arrays
Recuerda que un array es una lista ordenada de elementos que comparten un tipo de datos.
Este es un array de cadenas de los nombres de los 8 corredores.
Para crear arrays en BigQuery, debes usar corchetes [ ] y valores separados por comas.
Prueba la siguiente consulta y asegúrate de observar cuántas filas se muestran en los resultados. ¿Serán 8 filas?
#standardSQL
SELECT
['Rudisha','Makhloufi','Murphy','Bosse','Rotich','Lewandowski','Kipketer','Berian'] AS normal_array
Respuesta: Es una sola fila con 8 elementos del array:
Fila
normal_array
1
Rudisha
Makhloufi
Murphy
Bosse
Rotich
Lewandowski
Kipketer
Berian
Nota: Si ya tienes un campo sin el formato de un array, puedes usar ARRAY_AGG() para agregar esos valores a un array.
Si deseas hallar los corredores cuyos nombres comienzan con la letra “M”, debes desempaquetar el array anterior en filas individuales para usar una cláusula WHERE.
Para desempaquetarlo, debes unirlo (o unir su nombre) a UNNEST(), tal como se muestra abajo.
Ejecuta la siguiente consulta y observa cuántas filas se devuelven:
#standardSQL
SELECT * FROM
UNNEST(['Rudisha','Makhloufi','Murphy','Bosse','Rotich','Lewandowski','Kipketer','Berian']) AS unnested_array_of_names
Deberías ver lo siguiente:
Fila
unnested_array_of_names
1
Rudisha
2
Makhloufi
3
Murphy
4
Bosse
5
Rotich
6
Lewandowski
7
Kipketer
8
Berian
Desanidaste correctamente el array. A esto se le llama compactar el arreglo.
Ahora, agrega una cláusula WHERE normal para filtrar estas filas y ejecutar la consulta:
#standardSQL
SELECT * FROM
UNNEST(['Rudisha','Makhloufi','Murphy','Bosse','Rotich','Lewandowski','Kipketer','Berian']) AS unnested_array_of_names
WHERE unnested_array_of_names LIKE 'M%'
Fila
unnested_array_of_names
1
Makhloufi
2
Murphy
Pregunta del lab: Cómo descomprimir arrays con UNNEST( )
Escribe una consulta que muestre una lista del tiempo total de carrera correspondiente a los corredores cuyos nombres comiencen con R. Ordena los resultados de modo que el mejor tiempo total aparezca primero. Utiliza el operador UNNEST() y comienza con la consulta escrita parcialmente que figura a continuación.
Completa la consulta:
#standardSQL
SELECT
p.name,
SUM(split_times) as total_race_time
FROM racing.race_results AS r
, r.participants AS p
, p.splits AS split_times
WHERE
GROUP BY
ORDER BY
;
Pista:
Deberás descomprimir la struct y el array dentro de la struct como fuentes de datos después de la cláusula FROM.
Asegúrate de usar alias cuando corresponda.
Solución posible:
#standardSQL
SELECT
p.name,
SUM(split_times) as total_race_time
FROM racing.race_results AS r
, UNNEST(r.participants) AS p
, UNNEST(p.splits) AS split_times
WHERE p.name LIKE 'R%'
GROUP BY p.name
ORDER BY total_race_time ASC;
Fila
name
total_race_time
1
Rudisha
102.19999999999999
2
Rotich
103.6
Tarea 5: Filtra dentro de los valores de array
Descubriste que el tiempo por vuelta más rápido registrado para la carrera de 800 m fue 23.2 segundos, pero no viste qué corredor dio esa vuelta en particular. Crea una consulta que devuelva ese resultado.
Completa la consulta escrita parcialmente:
#standardSQL
SELECT
p.name,
split_time
FROM racing.race_results AS r
, r.participants AS p
, p.splits AS split_time
WHERE split_time = ;
Solución posible:
#standardSQL
SELECT
p.name,
split_time
FROM racing.race_results AS r
, UNNEST(r.participants) AS p
, UNNEST(p.splits) AS split_time
WHERE split_time = 23.2;
Fila
name
split_time
1
Kipketer
23.2
¡Felicitaciones!
Transferiste correctamente conjuntos de datos JSON, creaste arrays y structs, y desanidaste datos semiestructurados para estadísticas.
Finalice su lab
Cuando haya completado el lab, haga clic en Finalizar lab. Google Cloud Skills Boost quitará los recursos que usó y limpiará la cuenta.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Neutral
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2020 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usa una ventana de navegación privada o de Incógnito para ejecutar el lab. Así
evitarás cualquier conflicto entre tu cuenta personal y la cuenta
de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
En este lab, trabajarás con datos semiestructurados (transferencia de archivos de tipo JSON y arrays) dentro de BigQuery. Practicarás cómo cargar, consultar y desanidar diversos conjuntos de datos semiestructurados, además de cómo solucionar problemas en ellos.
Duración:
0 min de configuración
·
Acceso por 75 min
·
60 min para completar