概要
BigQuery は、Google が提供する低コスト、NoOps のフルマネージド分析データベースです。BigQuery では、インフラストラクチャを所有して管理したりデータベース管理者を置いたりすることなく、テラバイト単位の大規模なデータでクエリを実行できます。また、SQL が採用されており、従量課金制というメリットもあります。このような特徴を活かし、ユーザーは有用な情報を得るためのデータ分析に専念できます。
このラボでは、クエリのパフォーマンスを向上させるためのデータ ウェアハウスの構築方法について詳しく学習します。従来のリレーショナル スキーマで JOIN を使用する場合と非正規化スキーマを使用する場合を比較し、BigQuery のクエリ実行プランを使用してパフォーマンスのトレードオフを定量的に評価します。
演習内容
このラボでは、次のタスクの実行方法について学びます。
- ウェブ UI を使用してカンマ区切り値(CSV)ファイルを BigQuery のテーブルに読み込む
- コマンドライン インターフェース(CLI)を使用して JavaScript® Object Notation(JSON)ファイルを BigQuery テーブルに読み込む
- ウェブ UI を使用してデータを変換し、テーブルを結合する
- クエリ結果を送信先テーブルに保存する
- ウェブ UI を使用して送信先テーブルのクエリを実行し、データが正しく変換されて読み込まれたことを確認する
設定と要件
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
-
Qwiklabs にシークレット ウィンドウでログインします。
-
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
-
準備ができたら、[ラボを開始] をクリックします。
-
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
-
[Google Console を開く] をクリックします。
-
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
-
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud Shell の有効化
Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
-
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。

-
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。

gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
- 次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
gcloud auth list
出力:
Credentialed accounts:
- @.com (active)
出力例:
Credentialed accounts:
- google1623327_student@qwiklabs.net
- 次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
gcloud config list project
出力:
[core]
project =
出力例:
[core]
project = qwiklabs-gcp-44776a13dea667a6
注:
gcloud ドキュメントの全文については、
gcloud CLI の概要ガイド
をご覧ください。
BigQuery コンソールを開く
- Google Cloud Console で、ナビゲーション メニュー > [BigQuery] を選択します。
[Cloud Console の BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスにはクイックスタート ガイドへのリンクと、UI の更新情報が表示されます。
- [完了] をクリックします。
タスク 1. テーブルを保存する新しいデータセットの作成
BigQuery プロジェクトで、「liquor_sales」という名前の新しいデータセットを作成します。
- [エクスプローラ] パネルで、プロジェクト ID の横にある「アクションを表示」アイコンをクリックし、[データセットを作成] を選択します。
![[データセットを作成] へのナビゲーション パス](https://cdn.qwiklabs.com/nnYhypBE3%2FCwI9ybgxUmSNUJSmMUYMwLR3UXpczUnW0%3D)
[データセットを作成する] ダイアログが開きます。
- [データセット ID] に「
liquor_sales」と入力します。他の項目はデフォルト値のままにして、[データセットを作成] をクリックします。
左側のペインで、対象のプロジェクトに liquor_sales データセットが表示されます。
タスク 2. リレーショナル データの読み込みとクエリ
このセクションでは、BigQuery でリレーショナル データを使用する場合のクエリのパフォーマンスを測定します。
BigQuery は大規模な JOIN クエリをサポートしており、JOIN のパフォーマンスは良好です。ただし、BigQuery はカラム型データストアであるため、非正規化データセットで最大のパフォーマンスを発揮します。BigQuery ストレージは安価でスケーラブルであるため、データセットを非正規化して均質なテーブルに事前に JOIN することをおすすめします。つまり、コンピューティング リソースの代わりにストレージ リソースを利用するのです(後者の方がパフォーマンスとコスト効率に優れています)。
このセクションでは、次の作業を行います。
- リレーショナル スキーマから一連のテーブルを(第 3 正規形で)アップロードする。
- リレーショナル テーブルに対してクエリを実行する。
- クエリのパフォーマンスをメモする(後ほど同じ情報を含む非正規化スキーマのテーブルに対して同じクエリを実行した場合のパフォーマンスと比較するため)。
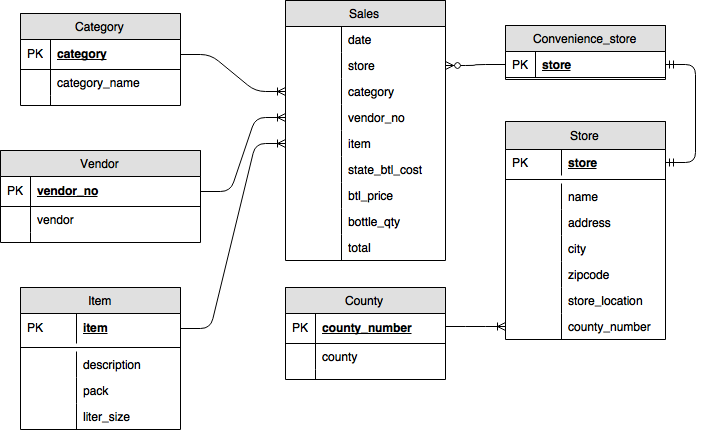
リレーショナル スキーマのテーブルをアップロードします。リレーショナル スキーマは、次のテーブルで構成されています。
| テーブル名 |
説明 |
| sales |
日付と売上の指標が含まれます。 |
| item |
販売した商品の説明です。 |
| vendor |
商品の生産者です。 |
| category |
商品の分類です。 |
| store |
商品を販売した店舗です。 |
| county |
商品が販売された地域(郡)です。 |
| convenience_store |
コンビニエンス ストアに分類される店舗のリストです。 |
次の図は、リレーショナル スキーマを表しています。
sales テーブルを作成する
- [エクスプローラ] セクションで、liquor_sales データセットの横にある「アクションを表示」アイコンをクリックし、[開く]、[テーブルを作成] の順にクリックします。
![[テーブルを作成] ボタン](https://cdn.qwiklabs.com/pMH9RUT4Pj10Wz2UflMlyF7%2BZ9sziyeKl0elEHdLA8k%3D)
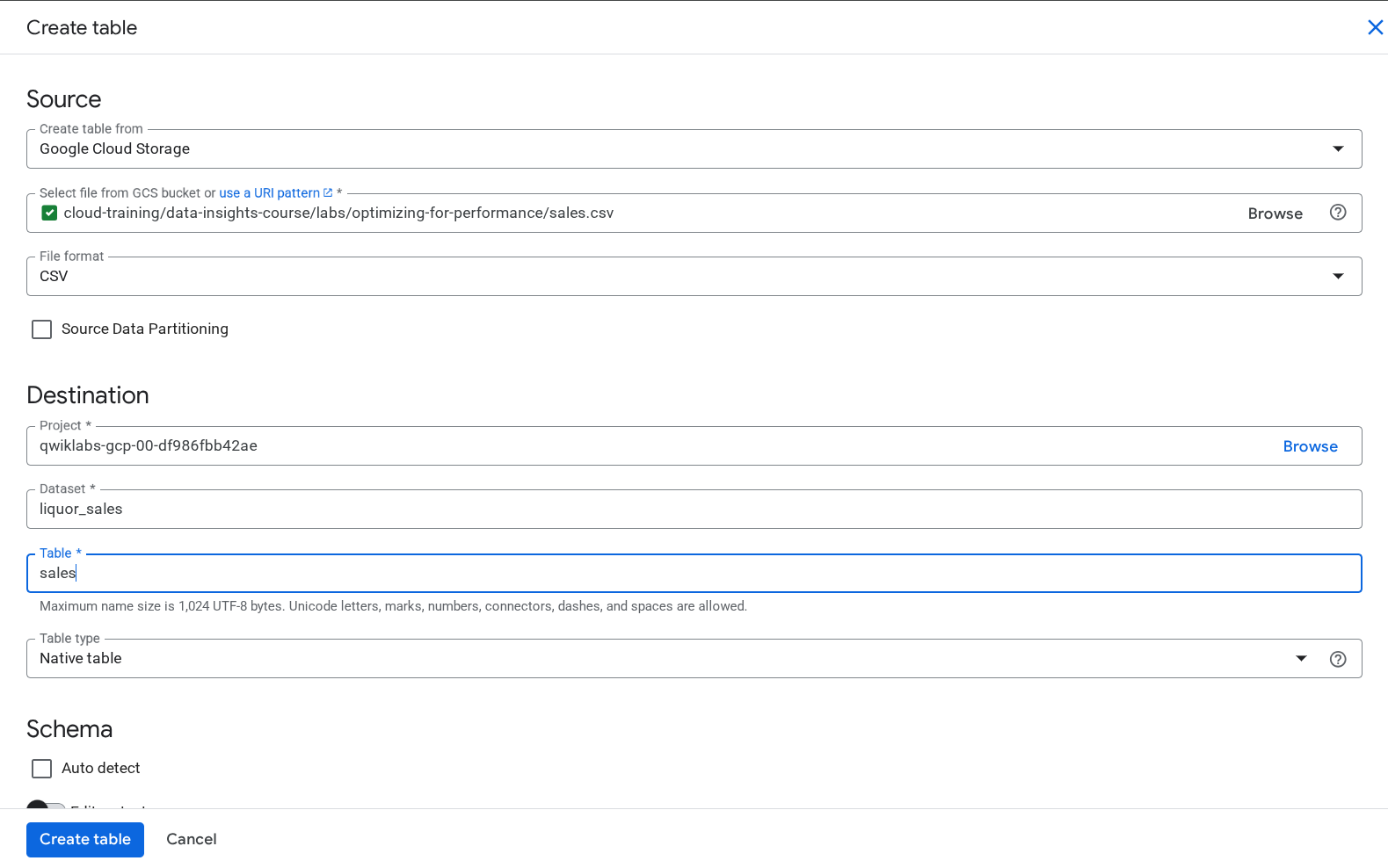
- [テーブルを作成] ページの [ソース] セクションで、次の操作を行います。
- [テーブルの作成元] で [Google Cloud Storage] を選択します。
- Google Cloud Storage バケットの名前へのパスを入力します。
cloud-training/data-insights-course/labs/optimizing-for-performance/sales.csv
メモ: 以前テーブルを作成したことがある場合は、[以前のジョブを選択] を選択すると、以前の設定を使用して同じようなテーブルをすばやく作成できます。
- [送信先] セクションで、以下の構成を行います。
- [テーブル] に「
sales」と入力します。
- その他の送信先フィールドはデフォルトのままにします。
- [スキーマ] セクションで、以下の構成を行います。
- [テキストとして編集] をクリックします。
- 以下のスキーマをコピーして貼り付けます。
[
{
"name": "date",
"type": "STRING"
},
{
"name": "store",
"type": "STRING"
},
{
"name": "category",
"type": "STRING"
},
{
"name": "vendor_no",
"type": "STRING"
},
{
"name": "item",
"type": "STRING"
},
{
"name": "state_btl_cost",
"type": "FLOAT"
},
{
"name": "btl_price",
"type": "FLOAT"
},
{
"name": "bottle_qty",
"type": "INTEGER"
},
{
"name": "total",
"type": "FLOAT"
}
]
- [詳細オプション] をクリックして次の項目を表示し、構成します。
- [フィールド区切り文字] で [カンマ] が選択されていることを確認します。
-
sales.csv には 1 行のヘッダーが含まれているため、[スキップするヘッダー行] に「1」を設定します。
- [引用された改行] チェックボックスをオンにします。
- 残りの設定はデフォルト値をそのまま使用して、[テーブルを作成] をクリックします。

BigQuery は、テーブルを作成してそのテーブルにデータをアップロードする読み込みジョブを作成します(これには数秒かかる場合があります)。
- [個人履歴] をクリックすると、ジョブの進行状況を確認できます。
残りのテーブルを作成する
Cloud Shell コマンドラインを使用して、リレーショナル スキーマに残りのテーブルを作成します。
-
category テーブルを作成します。
bq load --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines liquor_sales.category gs://cloud-training/data-insights-course/labs/optimizing-for-performance/category.csv category:STRING,category_name:STRING
-
convenience_store テーブルを作成します。
bq load --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines liquor_sales.convenience_store gs://cloud-training/data-insights-course/labs/optimizing-for-performance/convenience_store.csv store:STRING
-
county テーブルを作成します。
bq load --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines liquor_sales.county gs://cloud-training/data-insights-course/labs/optimizing-for-performance/county.csv county_number:STRING,county:STRING
-
item テーブルを作成します。
bq load --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines liquor_sales.item gs://cloud-training/data-insights-course/labs/optimizing-for-performance/item.csv item:STRING,description:string,pack:INTEGER,liter_size:INTEGER
-
store テーブルを作成します。
bq load --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines liquor_sales.store gs://cloud-training/data-insights-course/labs/optimizing-for-performance/store.csv store:STRING,name:STRING,address:STRING,city:STRING,zipcode:STRING,store_location:STRING,county_number:STRING
-
vendor テーブルを作成します。
bq load --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines liquor_sales.vendor gs://cloud-training/data-insights-course/labs/optimizing-for-performance/vendor.csv vendor_no:STRING,vendor:STRING
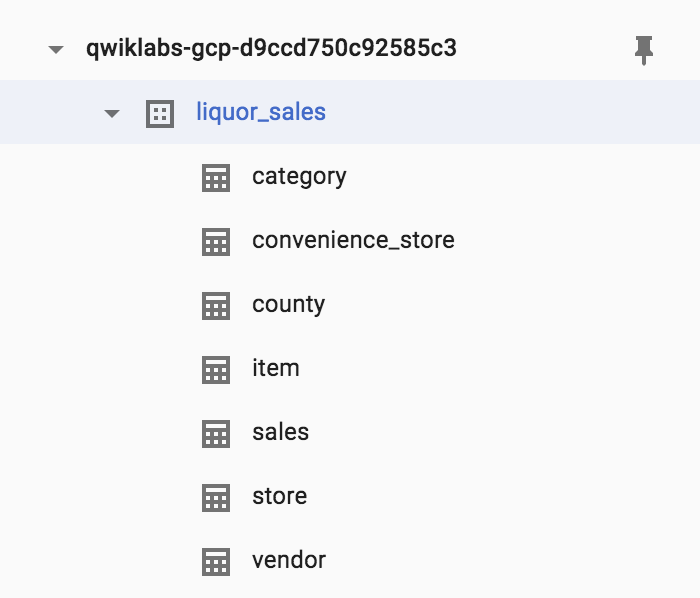
- BigQuery ウェブ UI に戻ります。新しいテーブルが
liquor_sales データセットに読み込まれていることを確認します。必要に応じてブラウザを更新します。
リレーショナル データにクエリを実行する
次に、[クエリエディタ] を使用してデータのクエリを実行します。
-
[クエリエディタ] コードボックスで、[展開] > [クエリ設定] の順にクリックします。
-
[リソース管理] の [キャッシュの設定] で、[キャッシュされた結果を使用] チェックボックスをオフにして [保存] をクリックします。クエリを複数回実行する必要がある場合は、キャッシュに保存された結果を使用しないでください。
-
[クエリエディタ] ウィンドウで、リレーショナル テーブルに対して次のクエリを入力し、[実行] をクリックします。
#standardSQL
SELECT
gstore.county AS county,
ROUND(cstore_total/gstore_total * 100,1) AS cstore_percentage
FROM (
SELECT
cy.county AS county,
SUM(total) AS gstore_total
FROM
`liquor_sales.sales` AS s
JOIN
`liquor_sales.store` AS st
ON
s.store = st.store
JOIN
`liquor_sales.county` AS cy
ON
st.county_number = cy.county_number
LEFT OUTER JOIN
`liquor_sales.convenience_store` AS c
ON
s.store = c.store
WHERE
c.store IS NULL
GROUP BY
county) AS gstore
JOIN (
SELECT
cy.county AS county,
SUM(total) AS cstore_total
FROM
`liquor_sales.sales` AS s
JOIN
`liquor_sales.store` AS st
ON
s.store = st.store
JOIN
`liquor_sales.county` AS cy
ON
st.county_number = cy.county_number
LEFT OUTER JOIN
`liquor_sales.convenience_store` AS c
ON
s.store = c.store
WHERE
c.store IS NOT NULL
GROUP BY
county) AS hstore
ON
gstore.county = hstore.county
- 画面下部にある [クエリ結果] セクションで [結果] タブをクリックし、クエリの完了にかかった時間をメモします。以下に例を示します(実行にかかる時間は変動します)。
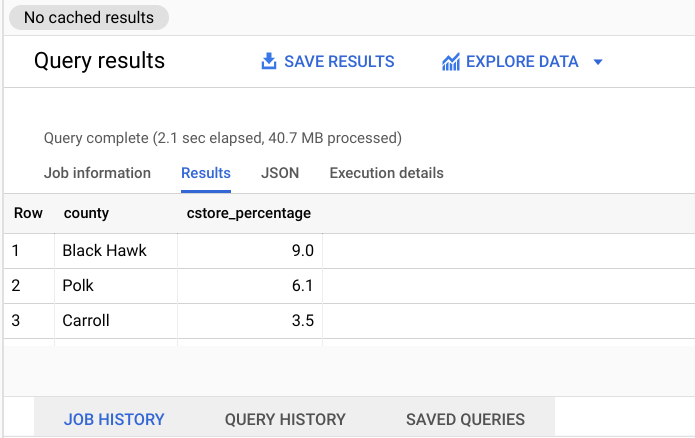
この時間と、この後のセクションで実践するフラット化されたデータセットのクエリ実行にかかる時間を比較します。
タスク 3. フラット化されたデータの読み込みとクエリ
このセクションでは、スキーマを非正規化し、フラット化されたデータを使用してアイオワ州の酒類の売上を分析します。フラット化されたデータに対して同じクエリを実行する場合、リレーショナル データの場合よりも処理が速くなることが予想されます。実行にかかった時間をメモし、比較して確認します。
非正規化スキーマは、すべてのリレーショナル データを 1 つの行にフラット化します。たとえば、非正規化スキーマの county_number、county、store、name、address、city、zipcode、store_location、county_number、cstore フィールドには、county、store、convenience_store テーブルのすべてのフィールドが含まれています。
メモ: (非正規化スキーマの)cstore フィールドは、上記のリレーショナル スキーマの convenience_store.store フィールドを表します。店舗がコンビニエンス ストアの場合の値は Y、それ以外の場合は null です。
次の図は、非正規化スキーマを表しています。
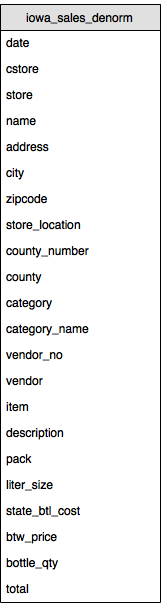
iowa_sales_denorm テーブルを作成する
- 左側のペインで liquor_sales データセットを選択して、右の [テーブルを作成] をクリックします。
[テーブルを作成] ダイアログが開きます。
- [ソース] セクションで、以下の構成を行います。
- [テーブルの作成元] で [Google Cloud Storage] を選択します。
- Google Cloud Storage バケットの名前へのパスを入力します。
cloud-training/data-insights-course/labs/optimizing-for-performance/iowa_sales_denorm.csv
- [送信先] セクションで、以下の構成を行います。
- [テーブル] に「
iowa_sales_denorm」と入力します。
- その他の送信先フィールドはデフォルトのままにします。
- [スキーマ] セクションで、以下の構成を行います。
- [テキストとして編集] をクリックします。
- 以下のスキーマをコピーして貼り付けます。
[
{
"name": "date",
"type": "STRING"
},
{
"name": "cstore",
"type": "STRING"
},
{
"name": "store",
"type": "STRING"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "address",
"type": "STRING"
},
{
"name": "city",
"type": "STRING"
},
{
"name": "zipcode",
"type": "STRING"
},
{
"name": "store_location",
"type": "STRING"
},
{
"name": "county_number",
"type": "STRING"
},
{
"name": "county",
"type": "STRING"
},
{
"name": "category",
"type": "STRING"
},
{
"name": "category_name",
"type": "STRING"
},
{
"name": "vendor_no",
"type": "STRING"
},
{
"name": "vendor",
"type": "STRING"
},
{
"name": "item",
"type": "STRING"
},
{
"name": "description",
"type": "STRING"
},
{
"name": "pack",
"type": "INTEGER"
},
{
"name": "liter_size",
"type": "INTEGER"
},
{
"name": "state_btl_cost",
"type": "FLOAT"
},
{
"name": "btl_price",
"type": "FLOAT"
},
{
"name": "bottle_qty",
"type": "INTEGER"
},
{
"name": "total",
"type": "FLOAT"
}
]
- [詳細オプション] セクションで、以下の構成を行います。
- [フィールド区切り文字] で [カンマ] が選択されていることを確認します。
-
iowa_sales_denorm.csv には 1 行のヘッダーが含まれているため、[スキップするヘッダー行] に「1」と入力します。
- [引用された改行] チェックボックスをオンにします。
- 残りの設定はデフォルト値をそのまま使用して、[テーブルを作成] をクリックします。
BigQuery は、テーブルを作成してそのテーブルにデータをアップロードする読み込みジョブを作成します(これには数秒かかる場合があります)。
-
[個人履歴] をクリックすると、ジョブの進行状況を確認できます。
-
非正規化スキーマのテーブルに対して次のクエリを入力し、[実行] をクリックします(このクエリでは、前のセクションのクエリと同じ結果が得られます)。
#standardSQL
SELECT
gstore.county AS county,
ROUND(cstore_total/gstore_total * 100,1) AS cstore_percentage
FROM (
SELECT
county,
sum(total) AS gstore_total
FROM
`liquor_sales.iowa_sales_denorm`
WHERE cstore is null
GROUP BY
county) AS gstore
JOIN (
SELECT
county,
sum(total) AS cstore_total
FROM
`liquor_sales.iowa_sales_denorm`
WHERE cstore is not null
GROUP BY
county) AS cstore
ON gstore.county = cstore.county
ORDER BY county
-
画面下部にある [クエリ結果] セクションで [結果] タブをクリックし、クエリの完了にかかった時間を確認します。この時間と、以下に記載するフラット化されたデータセットのクエリ実行にかかる時間を比較します。
-
クエリの実行にかかった時間を計算(終了時間から開始時間を差し引く)してメモします。
非正規化スキーマのテーブルに対するクエリの実行速度がわずかに速く、構文がシンプルであることがわかります。BigQuery のパフォーマンスを最適化するために、可能な限りデータセットを均質なテーブルに事前に JOIN してください。
クエリのパフォーマンスと実行の詳細を比較する
-
[プロジェクト履歴] を選択します。
-
正規化リレーショナル スキーマに対して最初に実行したクエリジョブをクリックし、[新規クエリとして開く] をクリックします。
-
[実行の詳細] を選択します。
実行プランは主に 2 つの部分で構成されています。
- まず、実行した各クエリのベンチマークの時間を比較します。
- 次に、ワーカーが最も時間を費やした作業のタイプを比較します。
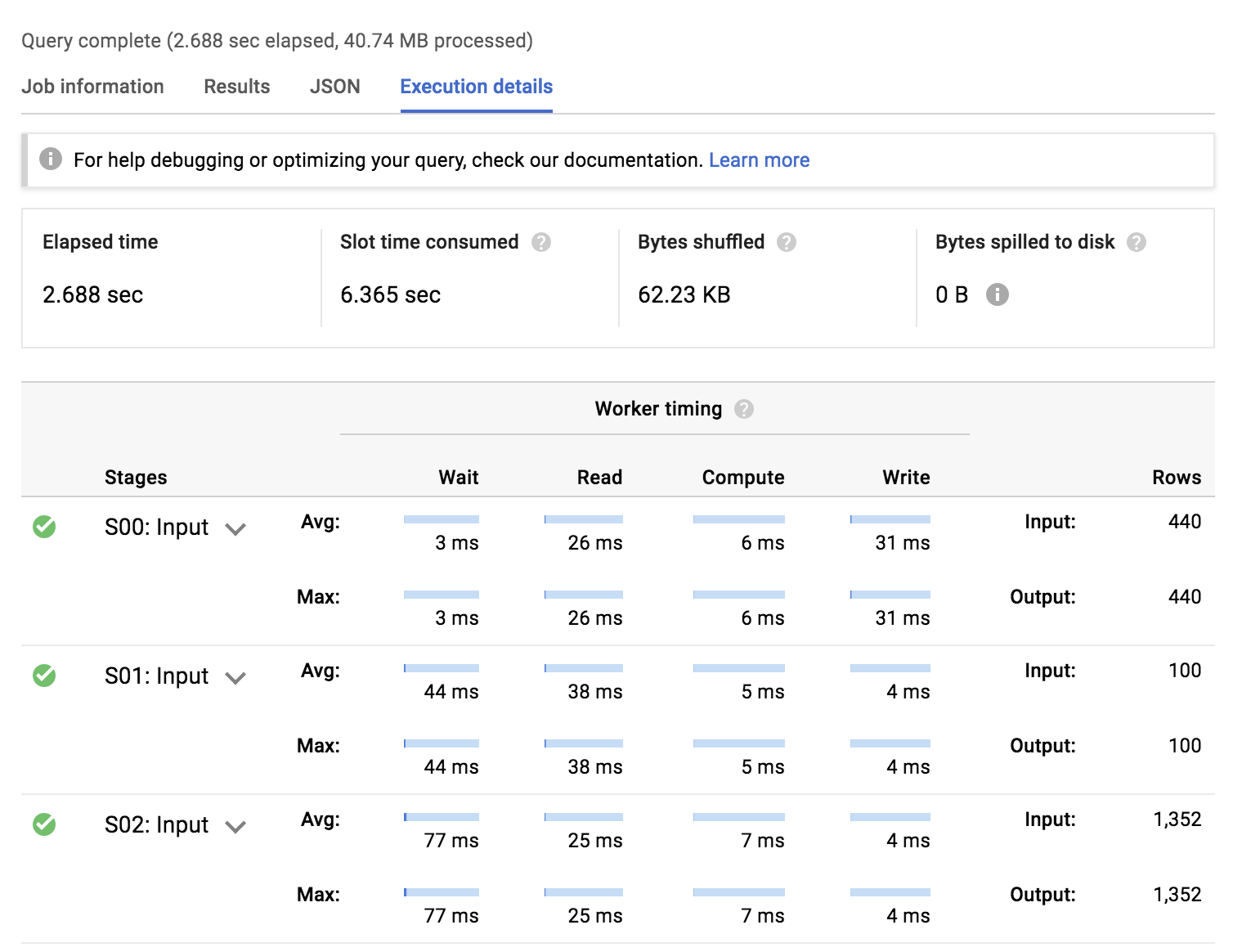
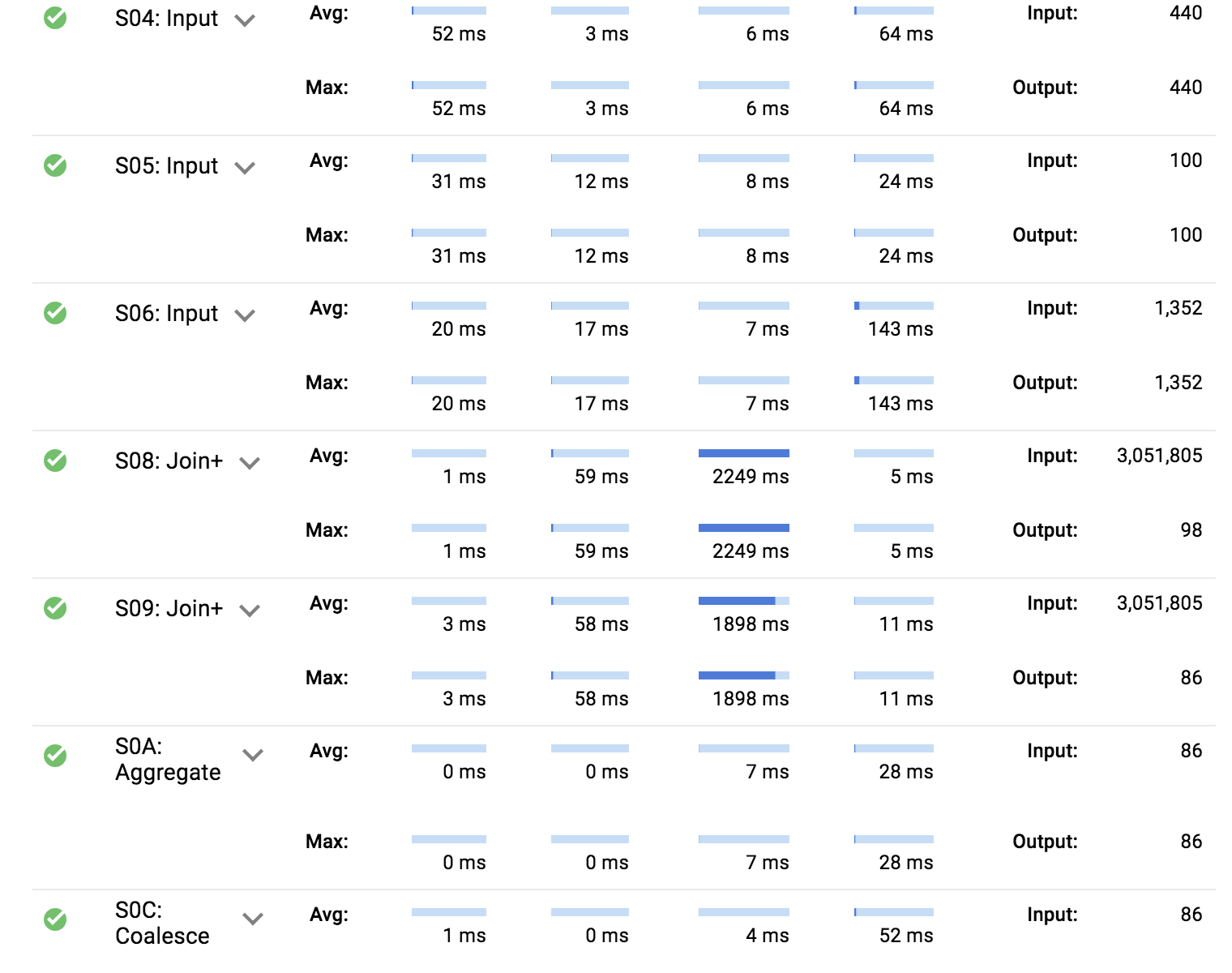
クエリ 1. リレーショナル スキーマでの実行の詳細
クエリ 2. 非正規化スキーマでの実行の詳細
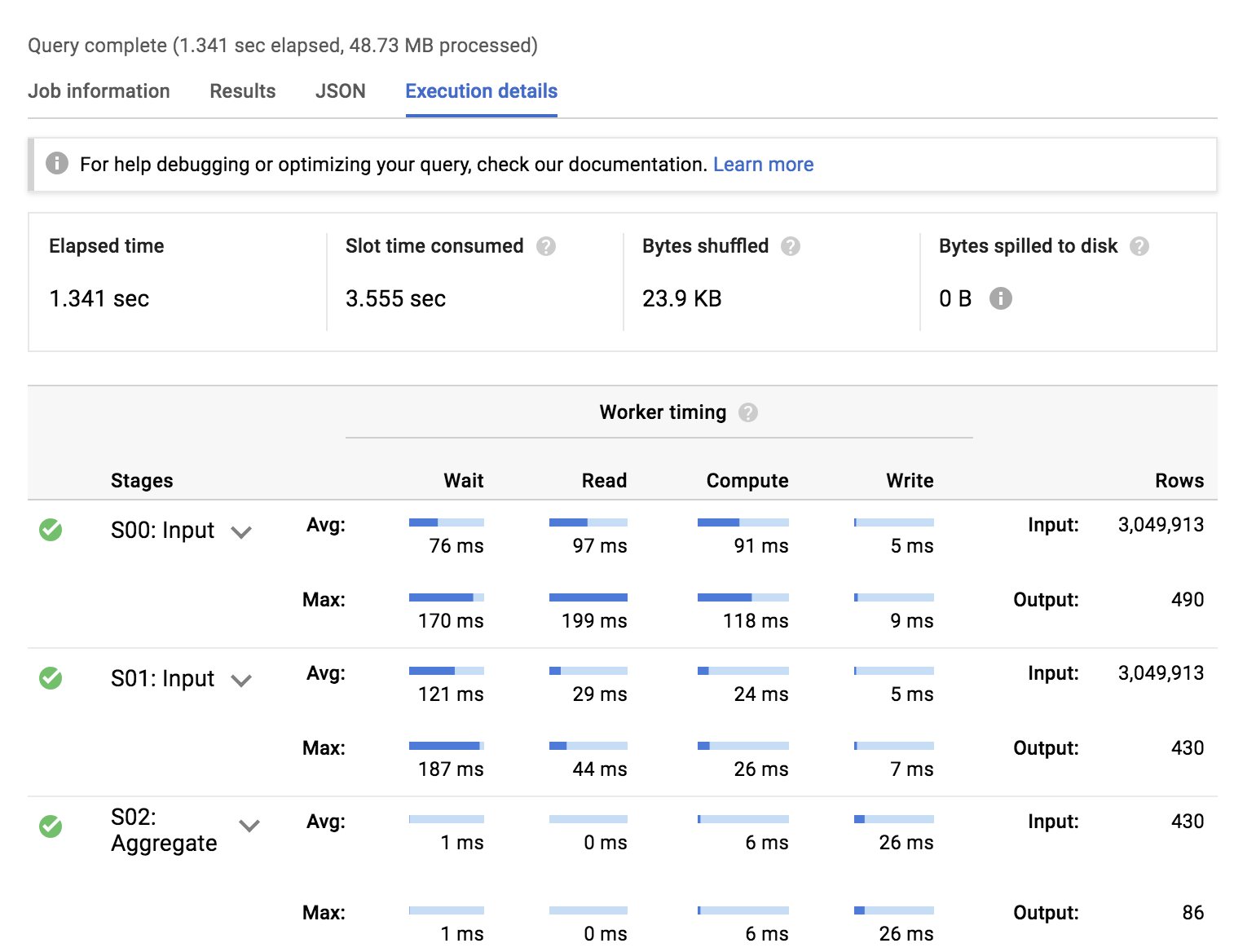

データからわかること:
- 非正規化スキーマでクエリを実行(#2)するほうが高速で、同じ結果を得るために必要なスロット時間が短い
- リレーショナル スキーマでクエリを実行(#1)するほうが多くの入力ステージがあり、データセットを結合する作業に最も時間がかかる
- 非正規化スキーマでクエリを実行(#2)する場合、入力データの読み取りと結果の出力に最も時間がかかり、集約と結合にかかる時間は最小限である
- どちらの場合でも、ディスクにオーバーフローしたバイト数はなく、データセットに偏りがある(または個々のワーカーのメモリからオーバーフローするほど大量になっている)可能性は低い
メモ: このラボで使用されているクエリはデモ専用です。データセットのサイズが大きく、JOIN 句が複雑であるほど、2 つのクエリの時間の差は大きくなります。
実行の詳細とクエリプランの最適化について詳しくは、クエリプランの説明リファレンス ガイドをご覧ください。
パフォーマンスのアンチパターンを回避する
効果的なデータベース スキーマ設計に慣れてきたので、今度は効率の悪いクエリを最適化する練習をしましょう。
以下のクエリは実行に時間がかかります。この場合、どのように修正すればよいでしょうか?
- 以下のクエリをコピーして [クエリエディタ] に貼り付け、[実行] をクリックしてクエリを実行し、ベンチマークを取得します。
目標: 2015 年に紙(非電子文書)を使用して納税申告を行った、米国のすべての非営利団体を数える
#standardSQL
# 2015 年の紙での申告をすべてカウント
SELECT * FROM `bigquery-public-data.irs_990.irs_990_2015`
WHERE UPPER(elf) LIKE '%P%' # 2015 年の紙での申告者
ORDER BY ein
# ページごとのカウントで 86,831(23 秒)
パフォーマンスを向上させるために何ができますか?
- 以下のクエリ方法と比較します。
#standardSQL
SELECT COUNT(*) AS paper_filers FROM `bigquery-public-data.irs_990.irs_990_2015`
WHERE elf = 'P' #2015 年の紙での申告者
# 86,831(2 秒)
/*
制限がない場合は ORDER BY を省略
集計関数を使用
データを確認、P は常に大文字
*/
-
更新したクエリを実行して時間を記録します。
-
[クエリエディタ] の内容をクリアします。
以下の新しいクエリも実行に時間がかかります(クエリを実行してベンチマークを取得します。完了しない場合は 30 秒後に停止してください)。
目標: 雇用主番号(ein)をリンク フィールドとして使用して、納税申告のテーブルと組織名のテーブルを結合し、2015 年に納税申告を行ったすべての組織の名前を返します。
- 以下のクエリを [クエリエディタ] に追加して [実行] をクリックします。
#standardSQL
# 2015 年に申告を行ったすべての組織の名称を取得
SELECT
tax.ein,
name
FROM
`bigquery-public-data.irs_990.irs_990_2015` tax
JOIN
`bigquery-public-data.irs_990.irs_990_ein` org
ON
tax.tax_pd = org.tax_period
- 上記のクエリを修正します(ヒント: このスキーマの正しい JOIN フィールドの条件を思い出してください)。
以下のクエリ方法と比較します。
- 以下のクエリを [クエリエディタ] に追加して [実行] をクリックします。
#standardSQL
# 2015 年に申告を行ったすべての組織の名称を取得
SELECT
tax.ein,
name
FROM
`bigquery-public-data.irs_990.irs_990_2015` tax
JOIN
`bigquery-public-data.irs_990.irs_990_ein` org
ON
tax.ein = org.ein
# ページごとのカウントで 86,831(23 秒)
/*
不適切な JOIN キーによる CROSS JOIN
正しい結果: 294,374(13 秒)
*/
- 更新したクエリを実行して時間を記録します。
改善されましたか?クエリの実行にかかる時間はどれくらい短くなりましたか?
学習した内容
お疲れさまでした
これで、BigQuery の効果的なスキーマ設計とクエリのパフォーマンスに関するハンズオンラボは終了です。このラボでは、CSV ファイルと JSON ファイルを BigQuery テーブルに読み込み、データの変換、テーブルの結合、クエリ結果の保存を行いました。そして、データが正しく変換されて読み込まれたことを確認しました。
ラボを終了する
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
- 星 1 つ = 非常に不満
- 星 2 つ = 不満
- 星 3 つ = どちらともいえない
- 星 4 つ = 満足
- 星 5 つ = 非常に満足
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2020 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。





