GSP273

概要
このラボでは、Jupyter ノートブック形式での TensorFlow モデルの開発に使用する Vertex AI Workbench インスタンスを作成します。モデルをトレーニングし、入力データ パイプラインを作成してエンドポイントにデプロイしてから、予測を行います。
TensorFlow は、機械学習向けに開発されたエンドツーエンドのオープンソース プラットフォームです。TensorFlow には、ツール、ライブラリ、コミュニティ リソースを含む幅広い柔軟なエコシステムがあります。これにより、研究者は機械学習(ML)の最先端技術を発展させ、開発者は ML を利用したアプリケーションを簡単に構築してデプロイすることができます。
Vertex AI は、AutoML と AI Platform を一つにまとめたもので、統一された API、クライアント ライブラリ、ユーザー インターフェースを提供します。Vertex AI では、AutoML トレーニングとカスタム トレーニングの両方を利用できます。
Vertex AI Workbench は、データサービス(Dataproc、Dataflow、BigQuery、Dataplex など)や Vertex AI との緊密なインテグレーションを通じて、ノートブック ベースのエンドツーエンドのワークフローをすばやく構築するのに便利です。データ サイエンティストは Vertex AI Workbench を使用して、Google Cloud データサービスへの接続、データセットの分析、各種モデリング手法のテスト、トレーニング済みモデルの本番環境への導入、モデル ライフサイクルを通した MLOps の管理を行うことができます。
Vertex AI Workbench は、データ サイエンスのワークフロー全体に対応する単一の開発環境です。
このラボでは、書籍『Data Science on Google Cloud Platform, 2nd Edition』(O'Reilly Media, Inc. 刊)用に開発されたコードサンプルとスクリプトを使用します。
目標
- Vertex AI Workbench インスタンスをデプロイする
- 最小限のトレーニング データと検証データを作成する
- 入力データ パイプラインを作成する
- TensorFlow モデルを作成する
- モデルを Vertex AI にデプロイする
- Explainable AI モデルを Vertex AI にデプロイする
- モデル エンドポイントから予測を行う
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
注: このラボの実行には、シークレット モードまたはシークレット ブラウジング ウィンドウを使用してください。これにより、個人アカウントと受講者アカウント間の競合を防ぎ、個人アカウントに追加料金が発生することを防ぎます。
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
注: すでに個人の Google Cloud アカウントやプロジェクトをお持ちの場合でも、このラボでは使用しないでください。アカウントへの追加料金が発生する可能性があります。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。
左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google Cloud コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウでリンクを開く] を選択します)。
ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。
-
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
{{{user_0.username | "Username"}}}
[ラボの詳細] パネルでも [ユーザー名] を確認できます。
-
[次へ] をクリックします。
-
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
{{{user_0.password | "Password"}}}
[ラボの詳細] パネルでも [パスワード] を確認できます。
-
[次へ] をクリックします。
重要: ラボで提供された認証情報を使用する必要があります。Google Cloud アカウントの認証情報は使用しないでください。
注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。
-
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後、このタブで Google Cloud コンソールが開きます。
注: Google Cloud のプロダクトやサービスのリストを含むメニューを表示するには、左上のナビゲーション メニューをクリックします。
タスク 1. Vertex AI Workbench インスタンスをデプロイする
-
Google Cloud コンソールのナビゲーション メニューで、[Vertex AI] > [ワークベンチ] をクリックします。
-
[+ 新規作成] をクリックします。
-
[インスタンスの作成] ダイアログで、デフォルト名を使用するか、Vertex AI Workbench インスタンス用の一意の名前を入力します。リージョンを に、ゾーンを に設定し、残りの設定はデフォルトのままにします。
-
[作成] をクリックします。
-
[JUPYTERLAB を開く] をクリックします。
ノートブックを使用するには、セルにコマンドを入力します。セル内のコマンドを実行するには、Shift + Enter キーを押すか、ノートブックの上部メニューにある三角形をクリックして [Run selected cells and advance] を選択します。
Vertex AI Workbench インスタンスをデプロイする
タスク 2. 最小限のトレーニング データと検証データを作成する
- [ノートブック] ランチャー セクションで、[Python 3] をクリックして新しいノートブックを開きます。
- Python ライブラリをインポートし、環境変数を設定します。
import os, json, math, shutil
import numpy as np
import tensorflow as tf
!sudo apt install graphviz -y
# bash セルで使用する環境変数
PROJECT=!(gcloud config get-value project)
PROJECT=PROJECT[0]
REGION = '{{{project_0.default_region}}}'
BUCKET='{}-dsongcp'.format(PROJECT)
os.environ['ENDPOINT_NAME'] = 'flights'
os.environ['BUCKET'] = BUCKET
os.environ['REGION'] = REGION
os.environ['TF_VERSION']='2-' + tf.__version__[2:4]
注:
Jupyter ノートブックのセルにコマンドを貼り付けたときは、次のステップに進む前に必ずそのセルを実行して、一連の流れの中の最後のコマンドを確実に実行してください。
TensorRT Library Load または TensorFlow AVX2 FMA の警告は無視してください。
トレーニング データと検証データを含むファイルをエクスポートする
ラボを開始すると、BigQuery データセットにいくつかのテーブルが作成されます。このセクションでは、BigQuery を使用して必要なデータを含む一時的な BigQuery テーブルを作成し、Google Cloud Storage に CSV ファイルとしてエクスポートします。次に、一時テーブルを削除します。さらに、エクスポートした CSV データファイルを読み込んで処理し、カスタム TensorFlow モデルに必要なトレーニング データセット、検証データセット、および完全データセットを作成します。
- モデル トレーニング用の
flights_train_data トレーニング データセットを作成します。
%%bigquery
CREATE OR REPLACE TABLE dsongcp.flights_train_data AS
SELECT
IF(arr_delay < 15, 1.0, 0.0) AS ontime,
dep_delay,
taxi_out,
distance,
origin,
dest,
EXTRACT(hour FROM dep_time) AS dep_hour,
IF (EXTRACT(dayofweek FROM dep_time) BETWEEN 2 AND 6, 1, 0) AS is_weekday,
UNIQUE_CARRIER AS carrier,
dep_airport_lat,
dep_airport_lon,
arr_airport_lat,
arr_airport_lon
FROM dsongcp.flights_tzcorr f
JOIN dsongcp.trainday t
ON f.FL_DATE = t.FL_DATE
WHERE
f.CANCELLED = False AND
f.DIVERTED = False AND
is_train_day = 'True'
- モデル評価用の
flights_eval_data 評価データセットを作成します。
%%bigquery
CREATE OR REPLACE TABLE dsongcp.flights_eval_data AS
SELECT
IF(arr_delay < 15, 1.0, 0.0) AS ontime,
dep_delay,
taxi_out,
distance,
origin,
dest,
EXTRACT(hour FROM dep_time) AS dep_hour,
IF (EXTRACT(dayofweek FROM dep_time) BETWEEN 2 AND 6, 1, 0) AS is_weekday,
UNIQUE_CARRIER AS carrier,
dep_airport_lat,
dep_airport_lon,
arr_airport_lat,
arr_airport_lon
FROM dsongcp.flights_tzcorr f
JOIN dsongcp.trainday t
ON f.FL_DATE = t.FL_DATE
WHERE
f.CANCELLED = False AND
f.DIVERTED = False AND
is_train_day = 'False'
- 次のコードを使用して、
flights_all_data 完全データセットを作成します。
%%bigquery
CREATE OR REPLACE TABLE dsongcp.flights_all_data AS
SELECT
IF(arr_delay < 15, 1.0, 0.0) AS ontime,
dep_delay,
taxi_out,
distance,
origin,
dest,
EXTRACT(hour FROM dep_time) AS dep_hour,
IF (EXTRACT(dayofweek FROM dep_time) BETWEEN 2 AND 6, 1, 0) AS is_weekday,
UNIQUE_CARRIER AS carrier,
dep_airport_lat,
dep_airport_lon,
arr_airport_lat,
arr_airport_lon,
IF (is_train_day = 'True',
IF(ABS(MOD(FARM_FINGERPRINT(CAST(f.FL_DATE AS STRING)), 100)) < 60, 'TRAIN', 'VALIDATE'),
'TEST') AS data_split
FROM dsongcp.flights_tzcorr f
JOIN dsongcp.trainday t
ON f.FL_DATE = t.FL_DATE
WHERE
f.CANCELLED = False AND
f.DIVERTED = False
- トレーニング データセット、検証データセット、完全データセットを Google Cloud Storage バケットに CSV ファイル形式でエクスポートします。
完了するまでに 2 分ほどかかります。
- ノートブック セルで次の bash スクリプトを実行し、出力が完了するまで待ちます。
%%bash
PROJECT=$(gcloud config get-value project)
for dataset in "train" "eval" "all"; do
TABLE=dsongcp.flights_${dataset}_data
CSV=gs://${BUCKET}/ch9/data/${dataset}.csv
echo "Exporting ${TABLE} to ${CSV} and deleting table"
bq --project_id=${PROJECT} extract --destination_format=CSV $TABLE $CSV
bq --project_id=${PROJECT} rm -f $TABLE
done
- 次のコードを使用して、Google Cloud Storage バケットにエクスポートされたオブジェクトを一覧表示します。
!gsutil ls -lh gs://{BUCKET}/ch9/data
トレーニング データセットと検証データセットを作成する
タスク 3. 入力データを作成する
ノートブックでの設定
- 開発目的の場合は、少数のエポックでトレーニングを行います。NUM_EXAMPLES が少ないのはこれが理由です。
DEVELOP_MODE = True
NUM_EXAMPLES = 5000*1000
- トレーニング データと検証データの URI をそれぞれ
training_data_uri と validation_data_uri に設定します。
training_data_uri = 'gs://{}/ch9/data/train*'.format(BUCKET)
validation_data_uri = 'gs://{}/ch9/data/eval*'.format(BUCKET)
- 次のコードブロックを使用して、モデル パラメータを設定します。
NBUCKETS = 5
NEMBEDS = 3
TRAIN_BATCH_SIZE = 64
DNN_HIDDEN_UNITS = '64,32'
TensorFlow にデータを読み込む
- Google Cloud Storage 内の CSV ファイルを TensorFlow に読み込むには、
tf.data パッケージのメソッドを使用します。
if DEVELOP_MODE:
train_df = tf.data.experimental.make_csv_dataset(training_data_uri, batch_size=5)
for n, data in enumerate(train_df):
numpy_data = {k: v.numpy() for k, v in data.items()}
print(n, numpy_data)
if n==1: break
features_and_labels() 関数と read_dataset() 関数を定義します。read_dataset() 関数は、トレーニング データを読み取り、毎回 batch_size 個のサンプルを出力します。特定の数のサンプルを読み取った後、反復処理を停止できます。
データセットには CSV ファイル内のすべての列が含まれ、それぞれのヘッダー行に従って名前が付けられます。データは特徴量とラベルで構成されています。features_and_labels() 関数を作成して特徴量とラベルを分離すると、後続のコードが読みやすくなります。そのため、ディクショナリに pop() 関数を適用して特徴量とラベルのタプルを返します。
- 次のコードを入力して実行します。
def features_and_labels(features):
label = features.pop('ontime')
return features, label
def read_dataset(pattern, batch_size, mode=tf.estimator.ModeKeys.TRAIN, truncate=None):
dataset = tf.data.experimental.make_csv_dataset(pattern, batch_size, num_epochs=1)
dataset = dataset.map(features_and_labels)
if mode == tf.estimator.ModeKeys.TRAIN:
dataset = dataset.shuffle(batch_size*10)
dataset = dataset.repeat()
dataset = dataset.prefetch(1)
if truncate is not None:
dataset = dataset.take(truncate)
return dataset
if DEVELOP_MODE:
print("Checking input pipeline")
one_item = read_dataset(training_data_uri, batch_size=2, truncate=1)
print(list(one_item)) # 2 項目からなる 1 つのバッチを出力します
タスク 4. TensorFlow モデルを作成してトレーニングし、評価する
通常は、表形式データのすべての列についてそれぞれ 1 つの特徴量を作成します。Keras は特徴量列をサポートしているため、埋め込み、バケット化、特徴クロスなどの標準的な特徴量エンジニアリング手法を使用して構造化データを表現できます。数値データは ML モデルに直接渡せるので、実数値の列とスパース列(文字列型の列)を分けて保持します。
- 次のコードを入力して実行します。
import tensorflow as tf
real = {
colname : tf.feature_column.numeric_column(colname)
for colname in
(
'dep_delay,taxi_out,distance,dep_hour,is_weekday,' +
'dep_airport_lat,dep_airport_lon,' +
'arr_airport_lat,arr_airport_lon'
).split(',')
}
sparse = {
'carrier': tf.feature_column.categorical_column_with_vocabulary_list('carrier',
vocabulary_list='AS,VX,F9,UA,US,WN,HA,EV,MQ,DL,OO,B6,NK,AA'.split(',')),
'origin' : tf.feature_column.categorical_column_with_hash_bucket('origin', hash_bucket_size=1000),
'dest' : tf.feature_column.categorical_column_with_hash_bucket('dest', hash_bucket_size=1000),
}
これらすべての特徴量は入力ファイルに直接由来します(そして、フライトの予測を得ようとするクライアントから提供されます)。入力レイヤは入力特徴量とその型に 1:1 で対応するため、列名を繰り返すのではなく、列ごとに入力レイヤを作成して適切なデータ型(浮動小数点数または文字列)を指定します。
- 次のコードを入力して実行します。
inputs = {
colname : tf.keras.layers.Input(name=colname, shape=(), dtype='float32')
for colname in real.keys()
}
inputs.update({
colname : tf.keras.layers.Input(name=colname, shape=(), dtype='string')
for colname in sparse.keys()
})
バケット化
精度が過剰に高い(したがって、過学習を招く可能性がある)実数値の列は、離散化してカテゴリ列にすることができます。たとえば、機齢の列がある場合は、5 年未満、5~20 年、20 年超の 3 つのビンに離散化できます。離散化のショートカット、つまり緯度と経度を離散化してバケットを交差させる手法を使用できます。この手法を使用すると、国がグリッドに分割され、特定の緯度と経度に対応するグリッド点が得られます。
latbuckets = np.linspace(20.0, 50.0, NBUCKETS).tolist() # 米国
lonbuckets = np.linspace(-120.0, -70.0, NBUCKETS).tolist() # 米国
disc = {}
disc.update({
'd_{}'.format(key) : tf.feature_column.bucketized_column(real[key], latbuckets)
for key in ['dep_airport_lat', 'arr_airport_lat']
})
disc.update({
'd_{}'.format(key) : tf.feature_column.bucketized_column(real[key], lonbuckets)
for key in ['dep_airport_lon', 'arr_airport_lon']
})
# 組み合わせることに意味がある列同士を交差させます
sparse['dep_loc'] = tf.feature_column.crossed_column(
[disc['d_dep_airport_lat'], disc['d_dep_airport_lon']], NBUCKETS*NBUCKETS)
sparse['arr_loc'] = tf.feature_column.crossed_column(
[disc['d_arr_airport_lat'], disc['d_arr_airport_lon']], NBUCKETS*NBUCKETS)
sparse['dep_arr'] = tf.feature_column.crossed_column([sparse['dep_loc'], sparse['arr_loc']], NBUCKETS ** 4)
# すべてのスパース列を埋め込みます
embed = {
'embed_{}'.format(colname) : tf.feature_column.embedding_column(col, NEMBEDS)
for colname, col in sparse.items()
}
real.update(embed)
# スパース列をワンホット エンコードします
sparse = {
colname : tf.feature_column.indicator_column(col)
for colname, col in sparse.items()
}
if DEVELOP_MODE:
print(sparse.keys())
print(real.keys())
モデルのトレーニングと評価
- チェックポイントを保存します。
output_dir='gs://{}/ch9/trained_model'.format(BUCKET)
os.environ['OUTDIR'] = output_dir # デプロイに必要
print('Writing trained model to {}'.format(output_dir))
- ストレージ バケットにすでに存在するモデル チェックポイントを削除します。
!gsutil -m rm -rf $OUTDIR
モデルはまだ一度も保存されていないため、このコマンドを実行すると CommandException: 1 files/objects could not be removed というエラーが返されます。このエラーは、指定した場所にファイルが存在しないことを示します。これにより、モデルを保存する前にこの場所が空であることを確認できます。
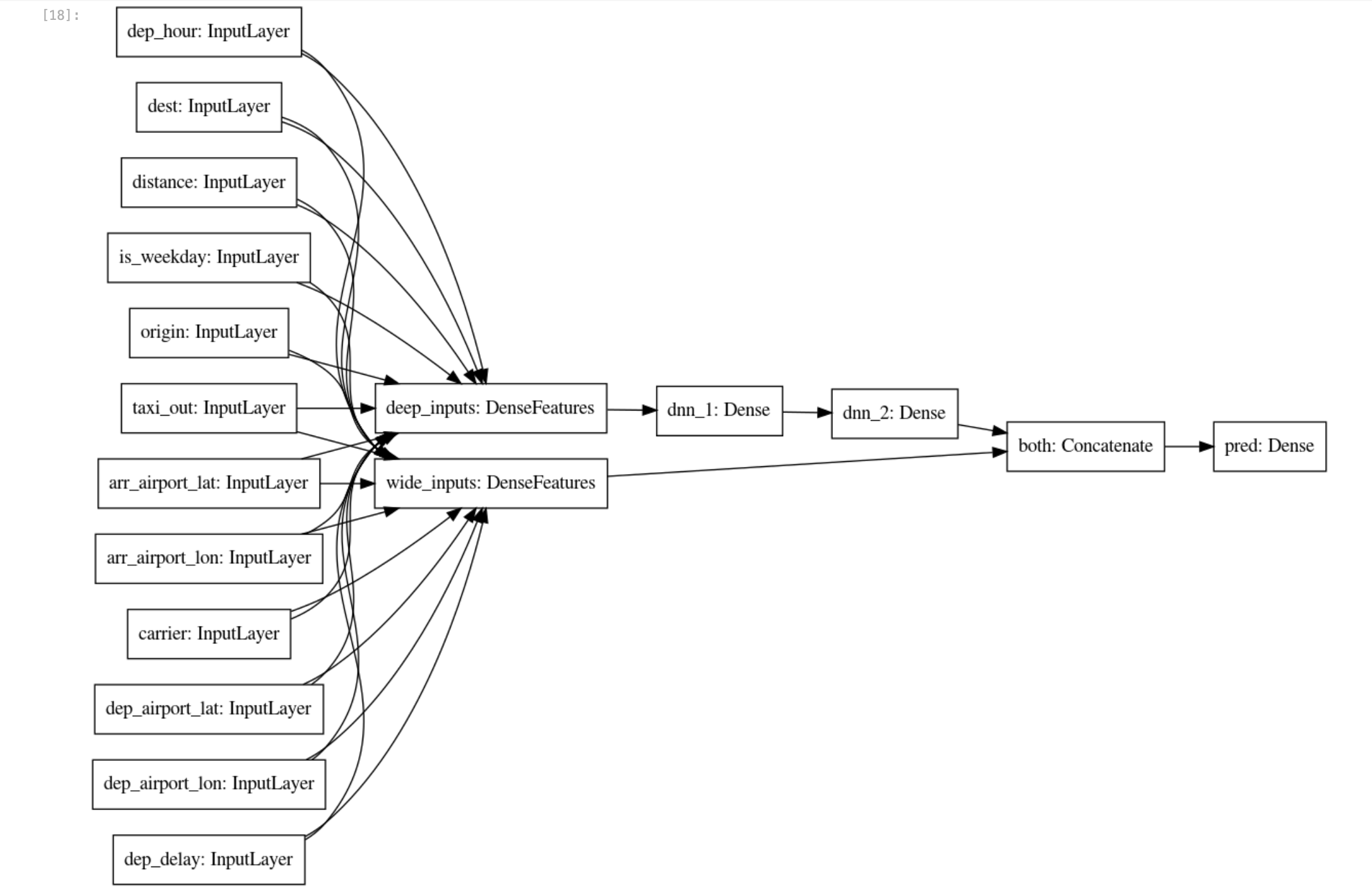
- スパース特徴量列と実数特徴量列が生の入力から拡張されたため、線形特徴量列とディープ特徴量列を別々に渡す
wide_and_deep_classifier を作成できます。
# ワイド&ディープモデルを構築します。
def wide_and_deep_classifier(inputs, linear_feature_columns, dnn_feature_columns, dnn_hidden_units):
deep = tf.keras.layers.DenseFeatures(dnn_feature_columns, name='deep_inputs')(inputs)
layers = [int(x) for x in dnn_hidden_units.split(',')]
for layerno, numnodes in enumerate(layers):
deep = tf.keras.layers.Dense(numnodes, activation='relu', name='dnn_{}'.format(layerno+1))(deep)
wide = tf.keras.layers.DenseFeatures(linear_feature_columns, name='wide_inputs')(inputs)
both = tf.keras.layers.concatenate([deep, wide], name='both')
output = tf.keras.layers.Dense(1, activation='sigmoid', name='pred')(both)
model = tf.keras.Model(inputs, output)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
return model
model = wide_and_deep_classifier(
inputs,
linear_feature_columns = sparse.values(),
dnn_feature_columns = real.values(),
dnn_hidden_units = DNN_HIDDEN_UNITS)
tf.keras.utils.plot_model(model, 'flights_model.png', show_shapes=False, rankdir='LR')
モデル トレーニング用の train_dataset とモデル評価用の eval_dataset を使用します。
- 次のコードブロックを使用してモデルを作成します。
# トレーニング用データセットと評価用データセット
train_batch_size = TRAIN_BATCH_SIZE
if DEVELOP_MODE:
eval_batch_size = 100
steps_per_epoch = 3
epochs = 2
num_eval_examples = eval_batch_size*10
else:
eval_batch_size = 100
steps_per_epoch = NUM_EXAMPLES // train_batch_size
epochs = 10
num_eval_examples = eval_batch_size * 100
train_dataset = read_dataset(training_data_uri, train_batch_size)
eval_dataset = read_dataset(validation_data_uri, eval_batch_size, tf.estimator.ModeKeys.EVAL, num_eval_examples)
checkpoint_path = '{}/checkpoints/flights.cpt'.format(output_dir)
shutil.rmtree(checkpoint_path, ignore_errors=True)
cp_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_path,
save_weights_only=True,
verbose=1)
history = model.fit(train_dataset,
validation_data=eval_dataset,
epochs=epochs,
steps_per_epoch=steps_per_epoch,
callbacks=[cp_callback])
-
matplotlib.pyplot を使用してモデル損失とモデル精度を可視化します。
import matplotlib.pyplot as plt
nrows = 1
ncols = 2
fig = plt.figure(figsize=(10, 5))
for idx, key in enumerate(['loss', 'accuracy']):
ax = fig.add_subplot(nrows, ncols, idx+1)
plt.plot(history.history[key])
plt.plot(history.history['val_{}'.format(key)])
plt.title('model {}'.format(key))
plt.ylabel(key)
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left');
出力は次のようになります。
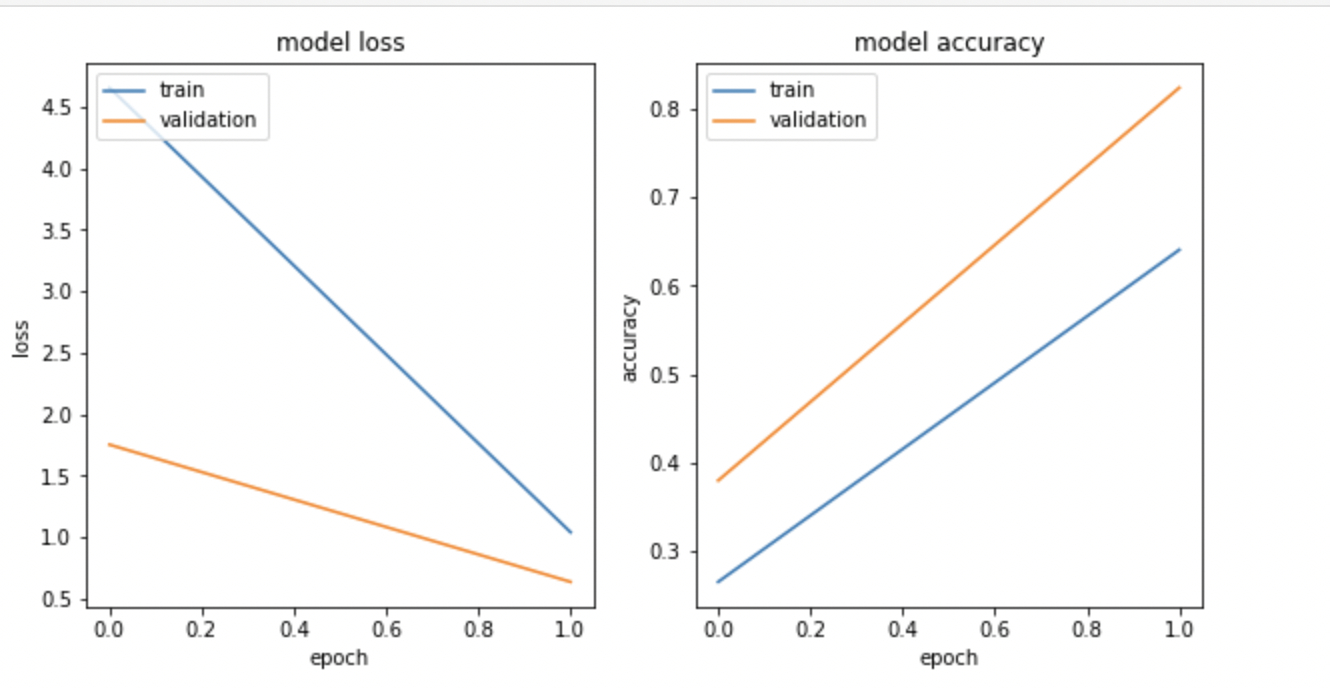
注: このラボでは非常に少ないランダム サンプルでトレーニングを行うため、トレーニング損失とモデル精度グラフは一致しない場合があります。
トレーニング済みモデルのエクスポート
- モデル アーティファクトを Google Cloud Storage バケットに保存します。
import time
export_dir = '{}/export/flights_{}'.format(output_dir, time.strftime("%Y%m%d-%H%M%S"))
print('Exporting to {}'.format(export_dir))
tf.saved_model.save(model, export_dir)
TensorFlow モデルを作成する
タスク 5. flights モデルを Vertex AI にデプロイする
Vertex AI は、機械学習モデル用のフルマネージドで自動スケーリングされるサーバーレス環境を備えています。CPU や GPU などのコンピューティング リソースは、使用した分だけ課金されます。モデルはコンテナ化されているため、依存関係管理が処理されます。エンドポイントがトラフィック分割を引き受けるため、A/B テストを簡単に実施できます。
メリットは、インフラストラクチャを管理しなくてよいことだけではありません。モデルを Vertex AI にデプロイした後は、追加のコードを記述しなくても、説明可能性、ドリフト検出、モニタリングなどの数多くの優れた機能を利用できます。
- 次のコードセルを使用して
flights というモデル エンドポイントを作成し、同じ名前を持つ既存のモデルを削除します。
%%bash
# TF_VERSION と ENDPOINT_NAME は最初のセルで設定されています
# TF_VERSION=2-6
# ENDPOINT_NAME=flights
TIMESTAMP=$(date +%Y%m%d-%H%M%S)
MODEL_NAME=${ENDPOINT_NAME}-${TIMESTAMP}
EXPORT_PATH=$(gsutil ls ${OUTDIR}/export | tail -1)
echo $EXPORT_PATH
# モデルをデプロイするためのモデル エンドポイントを作成します
if [[ $(gcloud beta ai endpoints list --region=$REGION \
--format='value(DISPLAY_NAME)' --filter=display_name=${ENDPOINT_NAME}) ]]; then
echo "Endpoint for $MODEL_NAME already exists"
else
echo "Creating Endpoint for $MODEL_NAME"
gcloud beta ai endpoints create --region=${REGION} --display-name=${ENDPOINT_NAME}
fi
ENDPOINT_ID=$(gcloud beta ai endpoints list --region=$REGION \
--format='value(ENDPOINT_ID)' --filter=display_name=${ENDPOINT_NAME})
echo "ENDPOINT_ID=$ENDPOINT_ID"
# 同じ名前を持つ既存のモデルを削除します
for MODEL_ID in $(gcloud beta ai models list --region=$REGION --format='value(MODEL_ID)' --filter=display_name=${MODEL_NAME}); do
echo "Deleting existing $MODEL_NAME ... $MODEL_ID "
gcloud ai models delete --region=$REGION $MODEL_ID
done
# Docker コンテナ イメージ URI とアーティファクト URI のパラメータを使用してモデルを作成します
gcloud beta ai models upload --region=$REGION --display-name=$MODEL_NAME \
--container-image-uri=us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.${TF_VERSION}:latest \
--artifact-uri=$EXPORT_PATH
MODEL_ID=$(gcloud beta ai models list --region=$REGION --format='value(MODEL_ID)' --filter=display_name=${MODEL_NAME})
echo "MODEL_ID=$MODEL_ID"
# モデルをエンドポイントにデプロイします
gcloud beta ai endpoints deploy-model $ENDPOINT_ID \
--region=$REGION \
--model=$MODEL_ID \
--display-name=$MODEL_NAME \
--machine-type=e2-standard-2 \
--min-replica-count=1 \
--max-replica-count=1 \
--traffic-split=0=100
注: このプロセスの開始から 5 分ほどでエラーが発生することがあります。サービス アカウントに Google Cloud Storage バケットにオブジェクトを書き込むための権限が不足しているといったモデル構築エラーが発生した場合は、このコードセルをもう一度実行してみます。また、Vertex AI API が有効になっていない場合は、有効にします。
注: モデルとモデル エンドポイントの作成、およびエンドポイントへのモデルのデプロイが完了するまでには 15~20 分ほどかかります。生成されたエンドポイント リンクにアクセスできない場合は、無視してください。Cloud コンソールで進行状況を確認するには、ナビゲーション メニュー > [Vertex AI] > [オンライン予測] > [エンドポイント] をクリックします。
flights モデルを Vertex AI にデプロイする
- 次のコードを使用して、
example_input.json というテスト入力ファイルを作成します。
%%writefile example_input.json
{"instances": [
{"dep_hour": 2, "is_weekday": 1, "dep_delay": 40, "taxi_out": 17, "distance": 41, "carrier": "AS", "dep_airport_lat": 58.42527778, "dep_airport_lon": -135.7075, "arr_airport_lat": 58.35472222, "arr_airport_lon": -134.57472222, "origin": "GST", "dest": "JNU"},
{"dep_hour": 22, "is_weekday": 0, "dep_delay": -7, "taxi_out": 7, "distance": 201, "carrier": "HA", "dep_airport_lat": 21.97611111, "dep_airport_lon": -159.33888889, "arr_airport_lat": 20.89861111, "arr_airport_lon": -156.43055556, "origin": "LIH", "dest": "OGG"}
]}
- モデル エンドポイントから予測を行います。次の例では、
example_input.json という JSON ファイルに入力データが格納されています。
%%bash
ENDPOINT_ID=$(gcloud beta ai endpoints list --region=$REGION \
--format='value(ENDPOINT_ID)' --filter=display_name=${ENDPOINT_NAME})
echo $ENDPOINT_ID
gcloud beta ai endpoints predict $ENDPOINT_ID --region=$REGION --json-request=example_input.json
上記のコードは、デプロイしたモデルをクライアント プログラムから呼び出す方法を示しています。
これは、example_input.json という JSON ファイルに入力データが格納されていることを前提としています。
- 次に、HTTP POST リクエストを送信して結果を JSON 形式で受け取ります。
%%bash
PROJECT=$(gcloud config get-value project)
ENDPOINT_ID=$(gcloud beta ai endpoints list --region=$REGION \
--format='value(ENDPOINT_ID)' --filter=display_name=${ENDPOINT_NAME})
curl -X POST \
-H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" \
-d @example_input.json \
"https://${REGION}-aiplatform.googleapis.com/v1/projects/${PROJECT}/locations/${REGION}/endpoints/${ENDPOINT_ID}:predict"
タスク 6. モデルの説明可能性
モデルの説明可能性は、機械学習において最も重要な問題の一つです。これは、機械学習モデルから返された結果を分析して理解するという広義の概念です。機械学習における説明可能性とは、入力から出力までの間にモデルで何が行われたかを説明できることを意味します。これにより、モデルが透明になり、ブラック ボックス問題が解消されます。Explainable AI(XAI)は、これをより明確な形で表現します。
- 次のコードを実行します。
%%bash
model_dir=$(gsutil ls ${OUTDIR}/export | tail -1)
echo $model_dir
saved_model_cli show --tag_set serve --signature_def serving_default --dir $model_dir
- モデルの説明用の入力と出力について記述したメタデータを含む
explanation-metadata.json という JSON ファイルを作成します。ここでは、説明の算出に sampled-shapley 法を使用します。
cols = ('dep_delay,taxi_out,distance,dep_hour,is_weekday,' +
'dep_airport_lat,dep_airport_lon,' +
'arr_airport_lat,arr_airport_lon,' +
'carrier,origin,dest')
inputs = {x: {"inputTensorName": "{}".format(x)}
for x in cols.split(',')}
expl = {
"inputs": inputs,
"outputs": {
"pred": {
"outputTensorName": "pred"
}
}
}
print(expl)
with open('explanation-metadata.json', 'w') as ofp:
json.dump(expl, ofp, indent=2)
-
cat コマンドを使用して explanation-metadata.json ファイルを表示します。
!cat explanation-metadata.json

flights_xai という別のモデルを作成して Vertex AI にデプロイする
- 次のコードを使用して
flights_xai というモデル エンドポイントを作成し、モデルをアップロードしてモデル エンドポイントにデプロイします。
%%bash
# ENDPOINT_NAME を変更します
ENDPOINT_NAME=flights_xai
TIMESTAMP=$(date +%Y%m%d-%H%M%S)
MODEL_NAME=${ENDPOINT_NAME}-${TIMESTAMP}
EXPORT_PATH=$(gsutil ls ${OUTDIR}/export | tail -1)
echo $EXPORT_PATH
# モデルをデプロイするためのモデル エンドポイントを作成します
if [[ $(gcloud beta ai endpoints list --region=$REGION \
--format='value(DISPLAY_NAME)' --filter=display_name=${ENDPOINT_NAME}) ]]; then
echo "Endpoint for $MODEL_NAME already exists"
else
# モデル エンドポイントを作成します
echo "Creating Endpoint for $MODEL_NAME"
gcloud beta ai endpoints create --region=${REGION} --display-name=${ENDPOINT_NAME}
fi
ENDPOINT_ID=$(gcloud beta ai endpoints list --region=$REGION \
--format='value(ENDPOINT_ID)' --filter=display_name=${ENDPOINT_NAME})
echo "ENDPOINT_ID=$ENDPOINT_ID"
# 同じ名前を持つ既存のモデルを削除します
for MODEL_ID in $(gcloud beta ai models list --region=$REGION --format='value(MODEL_ID)' --filter=display_name=${MODEL_NAME}); do
echo "Deleting existing $MODEL_NAME ... $MODEL_ID "
gcloud ai models delete --region=$REGION $MODEL_ID
done
# Docker コンテナ イメージ URI、アーティファクト URI、説明手法、説明パス数、
# 説明メタデータ JSON ファイル名(explanation-metadata.json)のパラメータを使用してモデルをアップロードします。
# ここでは、説明用の Shapley 値を近似するときに特徴順列の数を 10 に維持します。
gcloud beta ai models upload --region=$REGION --display-name=$MODEL_NAME \
--container-image-uri=us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.${TF_VERSION}:latest \
--artifact-uri=$EXPORT_PATH \
--explanation-method=sampled-shapley --explanation-path-count=10 --explanation-metadata-file=explanation-metadata.json
MODEL_ID=$(gcloud beta ai models list --region=$REGION --format='value(MODEL_ID)' --filter=display_name=${MODEL_NAME})
echo "MODEL_ID=$MODEL_ID"
# モデルをエンドポイントにデプロイします
gcloud beta ai endpoints deploy-model $ENDPOINT_ID \
--region=$REGION \
--model=$MODEL_ID \
--display-name=$MODEL_NAME \
--machine-type=e2-standard-2 \
--min-replica-count=1 \
--max-replica-count=1 \
--traffic-split=0=100
注: モデルとモデル エンドポイントの作成、およびエンドポイントへのモデルのデプロイが完了するまでには 15~20 分ほどかかります。生成されたエンドポイント リンクにアクセスできない場合は、無視してください。Cloud コンソールで進行状況を確認するには、ナビゲーション メニュー > [Vertex AI] > [オンライン予測] > [エンドポイント] をクリックします。
flights_xai モデルを Vertex AI にデプロイする
タスク 7. デプロイしたモデルを呼び出す
ここでは、デプロイしたモデルをクライアント プログラムから呼び出す方法を示します。これは、example_input.json という JSON ファイルに入力データが格納されていることを前提としています。次に、HTTP POST リクエストを送信して結果を JSON 形式で受け取ります。
%%bash
PROJECT=$(gcloud config get-value project)
ENDPOINT_NAME=flights_xai
ENDPOINT_ID=$(gcloud beta ai endpoints list --region=$REGION \
--format='value(ENDPOINT_ID)' --filter=display_name=${ENDPOINT_NAME})
curl -X POST \
-H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" \
-d @example_input.json \
"https://${REGION}-aiplatform.googleapis.com/v1/projects/${PROJECT}/locations/${REGION}/endpoints/${ENDPOINT_ID}:explain"
お疲れさまでした
これで完了です。このラボでは、Vertex AI を使用してモデルを作成する方法と Vertex AI エンドポイントをデプロイする方法を学習しました。また、Vertex AI Explainable AI(XAI)の機能を使用してモデルの予測を説明する方法を学習しました。また、あるロジスティック回帰モデルをすべての入力値に対してトレーニングした結果、このモデルでは空港の場所のような新しい特徴量を効果的に使用できないことがわかりました。
次のステップと詳細情報
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 10 月 30 日
ラボの最終テスト日: 2023 年 10 月 31 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。

