O BigQuery é um banco de dados de análise NoOps, totalmente gerenciado e de baixo custo desenvolvido pelo Google. Com ele, você pode consultar muitos terabytes de dados sem ter que gerenciar uma infraestrutura ou precisar de um administrador de banco de dados. O BigQuery usa SQL e está disponível no modelo de pagamento por uso. Assim, você pode se concentrar na análise dos dados para encontrar insights relevantes.
O BigQuery Machine Learning (BigQuery ML) é um recurso do BigQuery usado por analistas de dados para criar, treinar, avaliar e fazer previsões usando modelos de machine learning com o mínimo de programação.
A filtragem colaborativa é uma forma de recomendar produtos a usuários ou segmentar usuários para promover produtos. O ponto de partida é uma tabela com três colunas: um ID do usuário, um ID do item e a classificação que o usuário deu ao produto. A tabela pode ter poucos dados. Os usuários não precisam classificar todos os produtos. Com base apenas nas classificações, a técnica encontra usuários e produtos semelhantes e identifica como um usuário classificaria um produto que ele ainda não viu. Você pode recomendar os produtos aos usuários ou segmentar usuários para produtos com base na maior classificação prevista.
Para demonstrar o funcionamento dos sistemas do recomendador, você vai usar o conjunto de dados MovieLens. Ele contém avaliações de filmes e foi lançado pelo GroupLens, um laboratório de pesquisa do Departamento de Ciência e Engenharia da Computação da Universidade de Minnesota com o financiamento da Fundação Nacional da Ciência dos EUA.
Objetivos
Neste laboratório, você vai aprender a fazer o seguinte:
Criar um conjunto de dados do BigQuery para armazenar e carregar dados do MovieLens
Analisar o conjunto de dados do MovieLens
Usar um modelo treinado para fazer recomendações no BigQuery
Fazer previsões de produtos para usuários individuais ou em lote
Configurar o ambiente
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Abrir o BigQuery no Console do Cloud
No Console do Google Cloud, selecione o menu de navegação > BigQuery:
Você vai ver a caixa de mensagem Olá! Este é o BigQuery no Console do Cloud. Ela tem um link para o guia de início rápido e lista as atualizações da IU.
Clique em Concluído.
Tarefa 1: reunir os dados do MovieLens
Nesta tarefa, você vai usar a linha de comando para criar um conjunto de dados do BigQuery e armazenar os dados do MovieLens. Em seguida, esses dados serão carregados de um bucket do Cloud Storage para o conjunto.
Inicie o editor do Cloud Shell
Use o Cloud Shell para criar um conjunto de dados do BigQuery e carregar os dados do MovieLens.
No console do Google Cloud, clique em Ativar o Cloud Shell ().
Se for solicitado, clique em Continuar.
Crie e carregue o conjunto de dados do BigQuery
Execute este comando para criar um conjunto de dados do BigQuery chamado movies:
bq --location=US mk --dataset movies
Execute os comandos a seguir separadamente no Cloud Shell:
Confirme se o conjunto de dados consiste em mais de 138 mil usuários, quase 27 mil filmes e pouco mais de 20 milhões de classificações.
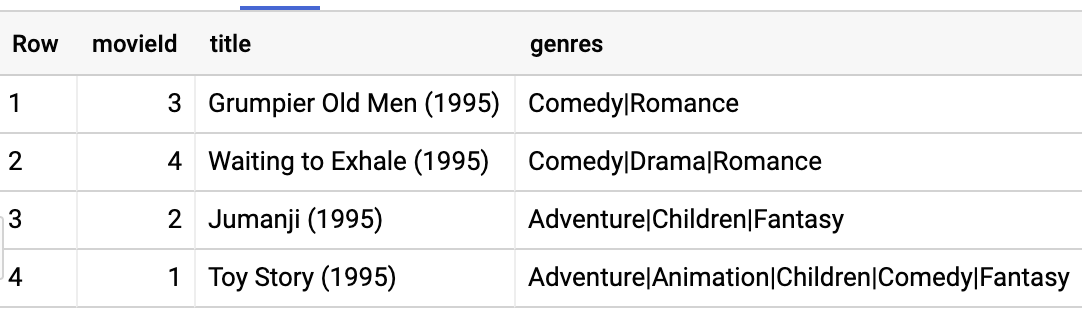
Examine os primeiros filmes com esta consulta:
SELECT
*
FROM
movies.movielens_movies_raw
WHERE
movieId < 5
Observe que a coluna de gêneros é uma string formatada. Divida os gêneros em uma matriz e reescreva os resultados em uma tabela chamada movielens_movies:
CREATE OR REPLACE TABLE
movies.movielens_movies AS
SELECT
* REPLACE(SPLIT(genres, "|") AS genres)
FROM
movies.movielens_movies_raw
Faça outras consultas para conhecer melhor o conjunto de dados.
Clique em Verificar meu progresso para conferir o objetivo.
Analise os dados
Tarefa 3: avaliar um modelo treinado que foi desenvolvido com a filtragem colaborativa
Nesta tarefa, você verá as métricas de um modelo treinado que foi desenvolvido com a fatoração de matriz.
Essa é uma técnica de filtragem colaborativa que usa dois vetores, denominados fatores de usuário e fatores de item. Os fatores de usuário são uma representação de baixa dimensão de user_id, enquanto os de item representam item_id.
Para fazer a fatoração de matriz dos dados, use a sintaxe típica do BigQuery ML, mas especifique model_type como matrix_factorization e identifique o papel de cada coluna na configuração da filtragem colaborativa.
Para aplicar a fatoração de matriz aos dados de classificação de filmes, é necessário executar a consulta do BigQuery ML para criar o modelo. No entanto, a criação desse tipo de modelo pode levar até 40 minutos e requer um projeto do Google Cloud com recursos orientados por reserva, que não é igual aos oferecidos pelo ambiente do Qwiklabs.
Um modelo foi criado no conjunto de dados cloud-training-demos do BigQuery no projeto de treinamento do Google Cloud. Esse modelo será usado no restante do laboratório.
Observação: a consulta abaixo serve apenas como referência. NÃO A EXECUTE no seu projeto:
CREATE OR REPLACE MODEL movies.movie_recommender
OPTIONS (model_type='matrix_factorization', user_col='userId', item_col='movieId', rating_col='rating', l2_reg=0.2, num_factors=16) AS
SELECT userId, movieId, rating
FROM movies.movielens_ratings
Observação: selecionamos as opções num_factors e l2_reg após vários experimentos para agilizar o treinamento do modelo.
Para ver as métricas do modelo treinado, execute a seguinte consulta:
SELECT * FROM ML.EVALUATE(MODEL `cloud-training-demos.movielens.recommender`)
Tarefa 4: fazer recomendações
Nesta tarefa, você vai usar o modelo treinado para fazer recomendações.
Vamos descobrir quais são as melhores comédias para recomendar ao usuário que tem o userId 903.
Digite esta consulta:
SELECT
*
FROM
ML.PREDICT(MODEL `cloud-training-demos.movielens.recommender`,
(
SELECT
movieId,
title,
903 AS userId
FROM
`movies.movielens_movies`,
UNNEST(genres) g
WHERE
g = 'Comedy' ))
ORDER BY
predicted_rating DESC
LIMIT
5
O resultado inclui alguns filmes que o usuário já viu e classificou.
Vamos remover essas obras:
SELECT
*
FROM
ML.PREDICT(MODEL `cloud-training-demos.movielens.recommender`,
(
WITH
seen AS (
SELECT
ARRAY_AGG(movieId) AS movies
FROM
movies.movielens_ratings
WHERE
userId = 903 )
SELECT
movieId,
title,
903 AS userId
FROM
movies.movielens_movies,
UNNEST(genres) g,
seen
WHERE
g = 'Comedy'
AND movieId NOT IN UNNEST(seen.movies) ))
ORDER BY
predicted_rating DESC
LIMIT
5
Clique em Verificar meu progresso para conferir o objetivo.
Faça recomendações
Tarefa 5: aplicar a segmentação de clientes
Nesta tarefa, você verá como identificar os filmes mais indicados para um usuário específico. Às vezes, você precisa encontrar os clientes que provavelmente vão gostar de determinado produto.
Você quer mais avaliações do filme movieId=96481, que só tem uma classificação, e quer mandar cupons para os 100 usuários que têm mais probabilidade de dar a classificação mais alta.
Identifique os usuários com esta consulta:
SELECT
*
FROM
ML.PREDICT(MODEL `cloud-training-demos.movielens.recommender`,
(
WITH
allUsers AS (
SELECT
DISTINCT userId
FROM
movies.movielens_ratings )
SELECT
96481 AS movieId,
(
SELECT
title
FROM
movies.movielens_movies
WHERE
movieId=96481) title,
userId
FROM
allUsers ))
ORDER BY
predicted_rating DESC
LIMIT
100
O resultado indica 100 usuários para a segmentação.
Clique em Verificar meu progresso para conferir o objetivo.
Segmentação de clientes
Tarefa 6: fazer previsões em lote para todos os usuários e filmes
Nesta tarefa, você vai fazer uma consulta para gerar previsões em lote para usuários e filmes.
Como fazer previsões para todas as combinações de usuários e filmes? Em vez de recuperar cada usuário e filme como na consulta anterior, você pode usar uma função que facilita as previsões em lote de todos os valores de movieId e userId abordados no treinamento.
Faça esta consulta para receber as previsões em lote:
SELECT
*
FROM
ML.RECOMMEND(MODEL `cloud-training-demos.movielens.recommender`)
LIMIT
100000
Sem o comando LIMIT, os resultados seriam grandes demais e não retornariam por conta das configurações padrão. Mas a resposta dá uma ideia dos tipos de previsão que podem ser feitos com o modelo.
Como vimos acima, é possível eliminar os filmes que o usuário já assistiu e classificou. Os filmes já vistos não são eliminados por padrão porque há situações em que esses resultados são úteis. Por exemplo, é útil recomendar ao cliente restaurantes que ele já conheceu e gostou.
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Neste laboratório, você vai usar o conjunto de dados MovieLens para criar um modelo de filtragem colaborativa que vai fazer previsões.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 60 minutos
·
Tempo para conclusão: 60 minutos
 ).
).