BigQuery est la base de données d'analyse NoOps, économique et entièrement gérée de Google. Avec BigQuery, vous pouvez interroger plusieurs téraoctets de données sans avoir à gérer d'infrastructure ni faire appel à un administrateur de base de données. Basé sur le langage SQL et le modèle de paiement à l'usage, BigQuery vous permet de vous concentrer sur l'analyse des données pour en dégager des insights pertinents.
BigQuery dispose d'une fonctionnalité appelée BigQuery Machine Learning (ou BigQuery ML), qui permet aux analystes de données de créer, d'entraîner et d'évaluer des modèles de machine learning en vue de prédire des résultats, et ce avec très peu de code.
Le filtrage collaboratif permet de faire des recommandations aux utilisateurs ou de cibler des utilisateurs en fonction des produits. Au minimum, il vous faut un tableau à trois colonnes : l'ID de l'utilisateur, l'ID de l'élément et la note que l'utilisateur a attribuée au produit. Le tableau peut être partiellement rempli. Les utilisateurs ne doivent pas nécessairement donner leur avis sur tous les produits. Ensuite, en se basant uniquement sur les notations, la technique consiste à trouver des utilisateurs et des produits qui présentent des similitudes, puis à déterminer la note qu'un utilisateur pourrait attribuer à un produit qu'il n'a pas encore vu. Vous pouvez alors recommander aux utilisateurs les produits susceptibles d'être les mieux notés ou proposer des produits aux utilisateurs à qui ils devraient plaire le plus.
Pour mieux comprendre le fonctionnement des systèmes de recommandation, vous allez utiliser l'ensemble de données MovieLens. Il s'agit d'un ensemble de données de critiques de films publiées par GroupLens, un laboratoire de recherche du département d'informatique et d'ingénierie de l'université du Minnesota, grâce au financement de la National Science Foundation (Fondation nationale pour la science) des États-Unis.
Objectifs
Dans cet atelier, vous allez apprendre à réaliser les opérations suivantes :
Créer un ensemble de données BigQuery pour stocker et charger les données MovieLens
Explorer l'ensemble de données MovieLens
Faire des recommandations dans BigQuery à l'aide d'un modèle entraîné
Faire des prédictions de produits pour des utilisateurs uniques et par lots
Configurer votre environnement
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Qwiklabs dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à Google Cloud Console.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ouvrir la console BigQuery
Dans Google Cloud Console, sélectionnez le menu de navigation > BigQuery :
Le message Welcome to BigQuery in the Cloud Console (Bienvenue sur BigQuery dans Cloud Console) s'affiche. Il contient un lien vers le guide de démarrage rapide et répertorie les mises à jour de l'interface utilisateur.
Cliquez sur Done (OK).
Tâche 1 : Obtenir des données MovieLens
Dans cette tâche, vous allez utiliser la ligne de commande pour créer un ensemble de données BigQuery dans lequel stocker les données MovieLens. Les données MovieLens seront ensuite chargées depuis un bucket Cloud Storage vers l'ensemble de données.
Ouvrir l'éditeur Cloud Shell
Pour créer un ensemble de données BigQuery et charger les données MovieLens, vous allez utiliser Cloud Shell.
Dans la console Google Cloud, cliquez sur Activer Cloud Shell ().
Cliquez sur Continuer si vous y êtes invité.
Créer et charger un ensemble de données BigQuery
Exécutez la commande suivante pour créer un ensemble de données BigQuery nommé movies :
bq --location=US mk --dataset movies
Exécutez les commandes suivantes séparément dans Cloud Shell :
Vérifiez que l'ensemble de données comprend bien plus de 138 000 utilisateurs, près de 27 000 films et un peu plus de 20 millions d'avis.
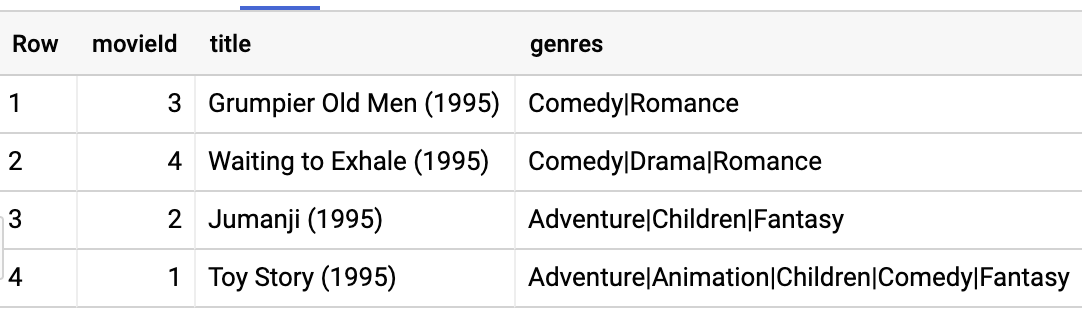
Examinez les premiers films à l'aide de la requête :
SELECT
*
FROM
movies.movielens_movies_raw
WHERE
movieId < 5
Vous constatez que la colonne des genres est une chaîne formatée. Analysez les genres dans un tableau et réécrivez les résultats dans un tableau nommé movielens_movies :
CREATE OR REPLACE TABLE
movies.movielens_movies AS
SELECT
* REPLACE(SPLIT(genres, "|") AS genres)
FROM
movies.movielens_movies_raw
N'hésitez pas à effectuer d'autres requêtes pour bien vous familiariser avec l'ensemble de données.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Explorer les données
Tâche 3 : Évaluer un modèle entraîné créé à l'aide du filtrage collaboratif
Dans cette tâche, vous allez afficher les métriques d'un modèle entraîné généré à l'aide de la factorisation matricielle.
La factorisation matricielle est une technique de filtrage collaboratif qui repose sur deux vecteurs : les facteurs utilisateur et les facteurs élément. Les facteurs utilisateur et élément sont respectivement une représentation de faible dimension de l'identifiant user_id de l'utilisateur et de l'identifiant item_id de l'élément.
La factorisation matricielle des données se fait à l'aide de la syntaxe classique de BigQuery ML, à la différence que le model_type (type de modèle) est matrix_factorization (factorisation matricielle), et que vous devez déterminer le rôle des colonnes dans la configuration du filtrage collaboratif.
Afin d'appliquer la factorisation matricielle aux données de notation des films, la requête BigQuery ML doit être exécutée pour créer le modèle. Toutefois, la création de ce type de modèle peut prendre jusqu'à 40 minutes et nécessite un projet Google Cloud avec des ressources axées sur la réservation, ce qui n'est pas le cas des ressources offertes par l'environnement Qwiklabs.
Un modèle a été créé dans l'ensemble de données BigQuery cloud-training-demos du projet d'entraînement Google Cloud pour pouvoir être utilisé dans le reste de l'atelier.
Remarque : La requête ci-dessous n'est fournie qu'à titre de référence. Veuillez NE PAS EXÉCUTER cette requête dans votre projet :
CREATE OR REPLACE MODEL movies.movie_recommender
OPTIONS (model_type='matrix_factorization', user_col='userId', item_col='movieId', rating_col='rating', l2_reg=0.2, num_factors=16) AS
SELECT userId, movieId, rating
FROM movies.movielens_ratings
Remarque : Les options num_factors et l2_reg ont été choisies après de nombreux tests pour accélérer l'entraînement du modèle.
Pour afficher les métriques du modèle entraîné, exécutez la requête suivante :
SELECT * FROM ML.EVALUATE(MODEL `cloud-training-demos.movielens.recommender`)
Tâche 4 : Faire des recommandations
Dans cette tâche, vous allez utiliser le modèle entraîné pour émettre des recommandations.
Découvrons quelles sont les meilleures comédies à recommander à l'utilisateur dont l'identifiant userId est 903.
Saisissez la requête ci-dessous :
SELECT
*
FROM
ML.PREDICT(MODEL `cloud-training-demos.movielens.recommender`,
(
SELECT
movieId,
title,
903 AS userId
FROM
`movies.movielens_movies`,
UNNEST(genres) g
WHERE
g = 'Comedy' ))
ORDER BY
predicted_rating DESC
LIMIT
5
Ce résultat inclut les films que l'utilisateur a déjà vus et notés.
Supprimons-les :
SELECT
*
FROM
ML.PREDICT(MODEL `cloud-training-demos.movielens.recommender`,
(
WITH
seen AS (
SELECT
ARRAY_AGG(movieId) AS movies
FROM
movies.movielens_ratings
WHERE
userId = 903 )
SELECT
movieId,
title,
903 AS userId
FROM
movies.movielens_movies,
UNNEST(genres) g,
seen
WHERE
g = 'Comedy'
AND movieId NOT IN UNNEST(seen.movies) ))
ORDER BY
predicted_rating DESC
LIMIT
5
Cliquez sur Vérifier ma progression pour valider l'objectif.
Faire des recommandations
Tâche 5 : Appliquer le ciblage des utilisateurs
Dans cette tâche, vous allez apprendre à identifier les films les mieux notés pour un utilisateur donné. Parfois, vous avez un produit et devez trouver les clients susceptibles de l'apprécier.
Vous souhaitez obtenir plus de critiques pour le film movieId=96481, qui n'a reçu qu'un avis, et envoyer des bons de réduction aux 100 utilisateurs susceptibles de lui donner la meilleure note.
Identifiez ces utilisateurs à l'aide de la requête suivante :
SELECT
*
FROM
ML.PREDICT(MODEL `cloud-training-demos.movielens.recommender`,
(
WITH
allUsers AS (
SELECT
DISTINCT userId
FROM
movies.movielens_ratings )
SELECT
96481 AS movieId,
(
SELECT
title
FROM
movies.movielens_movies
WHERE
movieId=96481) title,
userId
FROM
allUsers ))
ORDER BY
predicted_rating DESC
LIMIT
100
Le résultat nous donne 100 utilisateurs à cibler.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Cibler des utilisateurs
Tâche 6 : Faire des prédictions par lots pour tous les utilisateurs et tous les films
Dans cette tâche, vous allez exécuter une requête pour obtenir des prédictions par lots pour les utilisateurs et les films.
Supposons que vous souhaitiez faire des prédictions pour chaque combinaison d'utilisateur et de film. Au lieu de devoir extraire les données concernant des utilisateurs et des films précis, comme dans la requête précédente, une fonction pratique permet d'effectuer des prédictions par lots pour tous les identifiants movieId et userId utilisés pendant l'entraînement.
Saisissez la requête suivante pour obtenir des prédictions par lots :
SELECT
*
FROM
ML.RECOMMEND(MODEL `cloud-training-demos.movielens.recommender`)
LIMIT
100000
Sans la commande LIMIT, il y aurait trop de résultats pour qu'ils s'affichent, compte tenu des paramètres par défaut. Toutefois, le résultat donne une idée du type de prédictions pouvant être réalisées avec ce modèle.
Comme nous l'avons vu dans une section précédente, il est possible de filtrer les films que l'utilisateur a déjà vus et notés. Par défaut, les films déjà vus ne sont pas filtrés. En effet, dans certaines situations, comme pour les recommandations de restaurants, par exemple, il est logique de recommander des restaurants que l'utilisateur a déjà bien notés.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2020 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Ouvrez une fenêtre de navigateur en mode navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez utiliser l'ensemble de données MovieLens pour construire un modèle de filtrage collaboratif et faire des prédictions.
Durée :
0 min de configuration
·
Accessible pendant 60 min
·
Terminé après 60 min
 ).
).