

Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Create a cloud storage bucket
/ 25
Upload CSV files to Cloud Storage
/ 25
Create a Cloud SQL instance
/ 25
Create a database
/ 25
SQL (Structured Query Language – мова структурованих запитів) – це стандартна мова для роботи з даними, за допомогою якої можна ставити запитання й отримувати статистику зі структурованих наборів даних. Вона широко використовується в керуванні базами даних і дає змогу виконувати такі завдання, як запис транзакцій у реляційні бази даних і аналіз величезних обсягів даних, які вимірюються петабайтами.
Це практичне заняття складається з двох частин. У першій частині ви вивчите основні ключові слова запитів SQL, які ви виконуватимете в BigQuery із загальнодоступним набором даних про прокат велосипедів у Лондоні.
У другій частині ви дізнаєтесь, як експортувати підмножини набору даних про прокат велосипедів у Лондоні у файли CSV, які ви потім завантажите в Cloud SQL. Ви також навчитеся використовувати Cloud SQL, щоб створювати бази даних і таблиці й керувати ними. Наприкінці ви отримаєте практичні навички роботи з додатковими ключовими словами SQL, за допомогою яких можна редагувати дані й виконувати з ними певні операції.
Під час цього практичного заняття ви навчитеся виконувати наведені нижче дії.
Важливо. Перед початком цього практичного заняття вийдіть зі свого особистого або корпоративного облікового запису Gmail.
Це практичне заняття початкового рівня. Вона передбачає, що попередній досвід роботи з SQL мінімальний або взагалі відсутній. Знання Cloud Storage і Cloud Shell бажане, але не є обов’язковим. У цьому практичному занятті ви опануєте основні навички роботи із запитами мовою SQL, які ви застосовуватимете під час використання BigQuery й Cloud SQL.
Перш ніж виконувати це практичне заняття, оцініть, наскільки добре ви знаєте мову SQL. Нижче наведено практичні роботи підвищеного рівня складності, де ви зможете застосувати свої знання в розширених прикладах використання.
Щойно ви будете готові, прокрутіть сторінку вниз і виконайте описані кроки, щоб налаштувати середовище для практичного заняття.
Ознайомтеся з наведеними нижче вказівками. На виконання практичного заняття відводиться обмежений час, і його не можна призупинити. Щойно ви натиснете Почати заняття, з’явиться таймер, який показуватиме, скільки часу для роботи з ресурсами Google Cloud у вас залишилося.
Ви зможете виконати практичне заняття в дійсному робочому хмарному середовищі (не в симуляції або демонстраційному середовищі). Для цього на час практичного заняття вам надаються тимчасові облікові дані для реєстрації і входу в Google Cloud.
Для цього практичного заняття потрібно мати:
Натисніть кнопку Start Lab (Почати практичне заняття). Якщо за практичне заняття необхідно заплатити, відкриється вікно, де ви зможете обрати спосіб оплати. Ліворуч розміщено панель "Відомості про практичне заняття" з такими компонентами:
Натисніть Відкрити консоль Google або натисніть правою кнопкою миші й виберіть Відкрити анонімне вікно, якщо ви використовуєте вебпереглядач Chrome.
Завантажаться необхідні ресурси. Потім відкриється нова вкладка зі сторінкою "Увійти".
Порада. Упорядковуйте вкладки в окремих вікнах, розміщуючи їх поруч.
За потреби скопіюйте значення в полі Username (Ім’я користувача) нижче й вставте його у вікні Вхід.
Поле "Ім’я користувача" також можна знайти на панелі "Відомості про практичне заняття".
Натисніть Далі.
Скопіюйте значення в полі Password (Пароль) нижче й вставте його у вікні Welcome (Привітання).
Поле "Пароль" також можна знайти на панелі "Відомості про практичне заняття".
Натисніть Далі.
Що від вас очікується
Через кілька секунд консоль Google Cloud відкриється в новій вкладці.

Як зазначалося вище, SQL дає змогу отримувати інформацію зі "структурованих наборів даних". Структуровані набори даних мають чіткі правила й форматування та часто організовані як таблиці, тобто впорядковані в рядки й стовпці.
Прикладом неструктурованих даних може бути файл зображення. Неструктуровані дані непридатні для роботи з SQL, а також не можуть зберігатися в наборах даних або таблицях BigQuery (принаймні безпосередньо). Для роботи з даними зображень можна скористатися сервісом на кшталт Cloud Vision (наприклад, напряму через інтерфейс API).
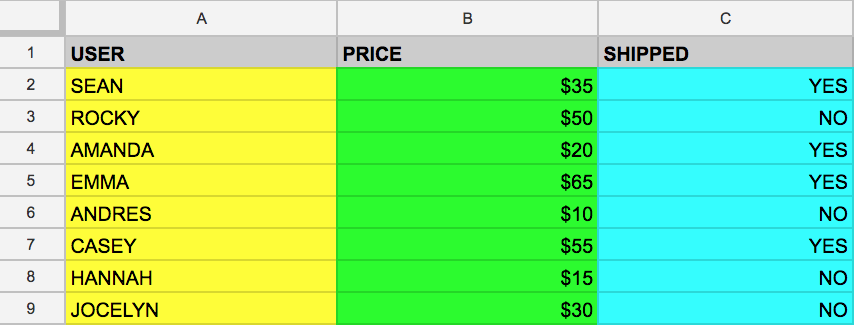
Нижче наведено приклад структурованого набору даних у вигляді простої таблиці.
|
User (Користувач) |
Price (Ціна) |
Shipped (Відправлено) |
|
Sean (Шон) |
$35 (35 дол. США) |
Yes (Так) |
|
Rocky (Роккі) |
$50 (50 дол. США) |
No (Ні) |
Наведений вище формат даних має бути вам знайомим, якщо ви вже працювали з Google Таблицями. Таблиця має стовпці User (Користувач), Price (Ціна) і Shipped (Відправлено) та два рядки, які складаються із заповнених значень стовпців.
База даних – це, по суті, набір з однієї або декількох таблиць. SQL – це інструмент керування структурованими базами даних, але досить часто (зокрема в цьому практичному занятті) ви виконуватимете запити в одній або кількох об’єднаних таблицях, а не в цілих базах даних.
Мова SQL має фонетичну природу, і перед виконанням запиту завжди потрібно визначити, на яке запитання має відповісти ваша вибірка даних (якщо ви серйозно займаєтеся цією справою).
SQL має попередньо визначені ключові слова, які використовуються для перетворення вашого запитання в псевдоанглійський синтаксис SQL, завдяки чому процесор бази даних повертає потрібну відповідь.
Найважливішими ключовими словами є SELECT і FROM.
SELECT використовується для того, щоб указати, які поля потрібно отримати з набору даних.FROM використовується для того, щоб указати, з якої таблиці або таблиць ви хочете отримати дані.Для наочності можна навести приклад. Припустімо, що у вас є наведена нижче таблиця example_table, яка містить стовпці USER (КОРИСТУВАЧ), PRICE (ЦІНА) і SHIPPED (ВІДПРАВЛЕНО).
Скажімо, ви хочете отримати дані зі стовпця USER (КОРИСТУВАЧ). Для цього ви можете виконати наведений нижче запит із використанням ключових слів SELECT і FROM.
Якщо виконати наведену вище команду, то буде вибрано всі імена зі стовпця USER (КОРИСТУВАЧ), які містяться в таблиці example_table.
Також за допомогою ключового слова SQL SELECT можна вибрати кілька стовпців. Скажімо, ви хочете отримати дані зі стовпців USER (КОРИСТУВАЧ) і SHIPPED (ВІДПРАВЛЕНО). Для цього змініть попередній запит SELECT, додавши значення ще одного стовпця (обов’язково відокремивши його комою):
У результаті виконання цього запиту буде отримано дані стовпців USER (КОРИСТУВАЧ) і SHIPPED (ВІДПРАВЛЕНО).
Таким чином, ви вивчили два основні ключові слова SQL. Тепер розгляньмо інший приклад.
Ключове слово WHERE – це ще одна команда SQL, яка фільтрує таблиці за певними значеннями стовпців. Скажімо, ви хочете отримати з таблиці example_table імена користувачів, чиї посилки було відправлено. Ви можете доповнити свій запит ключовим словом WHERE, як показано нижче.
У результаті виконання цього запиту буде отримано дані всіх стовпців USER (КОРИСТУВАЧ), для чиїх посилок указано статус SHIPPED (ВІДПРАВЛЕНО).
Ви ознайомилися з основними ключовими словами SQL. Тепер час застосувати отримані знання, виконуючи ці типи запитів у консолі BigQuery.
Дайте відповіді на запитання з кількома варіантами відповіді нижче, щоб закріпити розуміння понять, які зустрічаються в практичній роботі.
BigQuery – це повністю кероване сховище даних, яке працює в Google Cloud і може містити петабайти інформації. Аналітики й спеціалісти з обробки даних можуть швидко надсилати запити, фільтрувати великі набори даних, узагальнювати результати й виконувати складні операції, не витрачаючи час на налаштування серверів і керування ними. Доступ до сховища BigQuery можна отримати через інструмент командного рядка (попередньо встановлений у Cloud Shell) або вебконсоль. В обох випадках ви можете надсилати запити й керувати даними, розміщеними в проектах Google Cloud.
Під час цього практичного заняття ви використовуватимете для виконання запитів SQL вебконсоль.
Відкриється повідомлення Welcome to BigQuery in the Cloud Console (Вітаємо в BigQuery в Cloud Console). Це повідомлення містить посилання на короткий посібник і примітки до випуску.
Відкриється консоль BigQuery.
Зверніть увагу на деякі важливі елементи інтерфейсу. Праворуч на консолі можна знайти редактор запитів. Це місце, де ви пишете й виконуєте команди SQL, як було показано в прикладах вище. Нижче розташовується Query history (Історія запитів) – це список запитів, які ви виконували раніше.
На панелі ліворуч можна знайти меню навігації. Воно містить історію запитів, збережені запити, історію завдань, а також вкладку Explorer (Провідник).
На найвищому рівні ресурсів на вкладці Explorer (Провідник) відображаються проекти Google Cloud, а саме тимчасові проекти Google Cloud, у які ви входите і які використовуєте в кожній практичній роботі Google Cloud Skills Boost. Як ви бачите у своїй консолі й на останньому знімку екрана, на вкладці Explorer (Провідник) відображається лише ваш проект. Якщо ви натиснете стрілку поруч із назвою проекту, нічого не відкриється.
Це тому, що ваш проект не містить наборів даних або таблиць, тобто нічого, на що можна було б надіслати запит. Раніше ви дізналися, що набори даних містять таблиці. Коли ви додаєте дані в проект, пам’ятайте, що в BigQuery проекти містять набори даних, а набори даних – таблиці. Отже, ви познайомилися зі структурою "проект > набір даних > таблиця" й інтерфейсом консолі. Тепер можна завантажити деякі дані для подальшого надсилання запитів.
У цьому розділі ви додасте деякі загальнодоступні дані у свій проект, щоб потренуватися виконувати команди SQL у BigQuery.
Натисніть + ADD (ДОДАТИ).
Виберіть Star a project by name (Позначити проект зірочкою за назвою).
Введіть таку назву проекту: bigquery-public-data.
Натисніть STAR (ПОЗНАЧИТИ ЗІРОЧКОЮ).
Важливо зауважити, що на цій новій вкладці ви продовжуєте працювати над проектом свого практичного заняття. Ви отримали загальнодоступний проект із наборами даних і таблицями в BigQuery для аналізу, але ви не переключилися на цей проект. Усі ваші завдання й сервіси, як і раніше, прив’язано до вашого облікового запису Google Cloud Skills Boost. Ви можете переконатися в цьому, переглянувши поле Project (Проект) у верхній частині консолі.
bigquery-public-data
london_bicycles
cycle_hire
cycle_stations
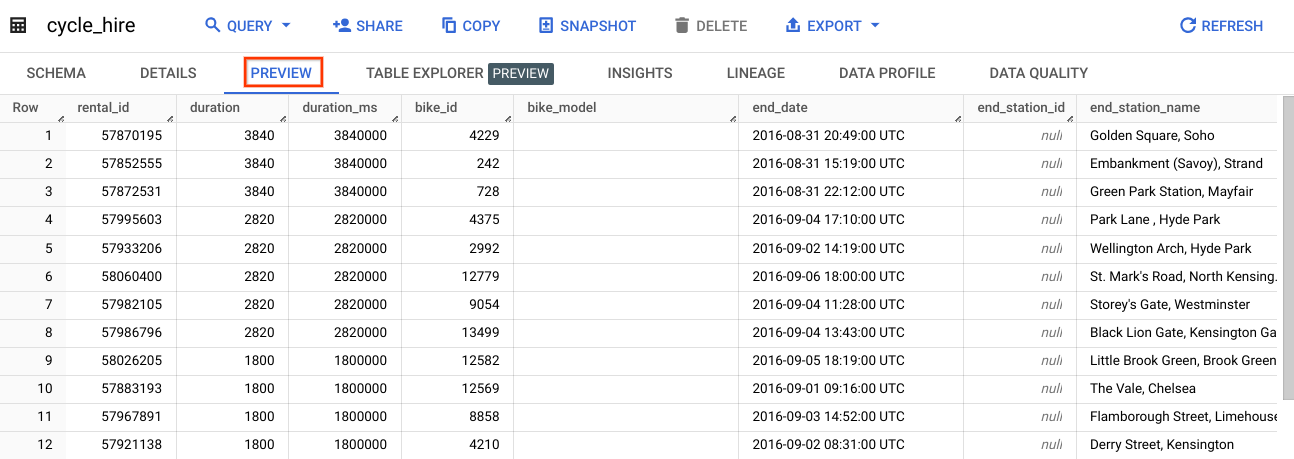
У цьому практичному занятті ви використовуватимете дані таблиці cycle_hire. Відкрийте таблицю cycle_hire, а потім – вкладку Preview (Попередній перегляд). Сторінка матиме приблизно такий вигляд:
Перегляньте стовпці й значення в рядках. Тепер можна виконувати запити SQL у таблиці cycle_hire.
Тепер у вас є базове розуміння ключових слів для запитів SQL і структури сховища даних BigQuery, а також деякі дані для роботи. Запустіть певні команди SQL за допомогою цього сервісу.
Якщо ви подивитеся в правий нижній кут консолі, то побачите, що таблиця містить 83 434 866 рядків даних – це кількість окремих поїздок на велосипеді, здійснених у Лондоні в період із 2015 по 2017 рік (і це доволі велике число!).
Тепер зверніть увагу на ключ у дев’ятому стовпці: end_station_name. Це кінцева станція поїздок на велосипеді. Перш ніж продовжувати, виконайте простий запит, щоб виокремити стовпець end_station_name.
Через приблизно 20 секунд ви маєте отримати 83 434 866 рядків тільки із запитаним стовпцем end_station_name.
Тепер можна дізнатися, скільки поїздок на велосипеді тривали 20 хвилин або довше.
WHERE.Виконання цього запиту може зайняти приблизно хвилину.
Ключове слово із зірочкою SELECT * повертає значення всіх стовпців із таблиці. Тривалість вимірюється в секундах, тому використовується значення 1200 (60 * 20).
Якщо ви подивитесь у правий нижній кут, то побачите, що запит повернув 26 441 016 рядків. Вирахувавши частку від загальної кількості (26 441 016/83 434 866), ми дізнаємося, що приблизно 30% поїздок на велосипеді в Лондоні тривали 20 хвилин та більше (і це досить довго!).
Дайте відповіді на запитання з кількома варіантами відповіді нижче, щоб закріпити розуміння понять, які зустрічаються в практичній роботі.
Ключове слово GROUP BY об’єднує рядки списку результатів, які мають спільні критерії (наприклад, значення стовпця), і повертає всі унікальні записи, знайдені за цими критеріями.
Це ключове слово допомагає знайти в таблицях інформацію категоріального характеру.
У результаті ви отримаєте список унікальних (неповторюваних) значень стовпців.
Запит без ключового слова GROUP BY повернув би весь список із 83 434 866 рядків. GROUP BY дає змогу отримати унікальні значення стовпців, знайдені в таблиці. Якщо ви подивитесь у правий нижній кут консолі, то побачите, що запит повернув 954 рядки. Це означає, що в Лондоні є 954 різні початкові станції прокату велосипедів.
Функція COUNT() повертає кількість рядків, які відповідають однаковим критеріям (наприклад, значенням стовпця). Вона може бути корисною в поєднанні з ключовим словом GROUP BY.
Додайте функцію COUNT у попередній запит, щоб дізнатися, скільки поїздок починається з кожної станції.
У результаті ви отримаєте кількість поїздок, які починаються з кожної станції.
У SQL також є ключове слово AS, яке створює псевдонім таблиці або стовпця. Псевдонім – це нова назва поверненого стовпця або таблиці, яку вказує ключове слово AS.
AS в останній запит, який ви виконували, щоб побачити це в дії. Видаліть запит із редактора, а потім скопіюйте й вставте наведену нижче команду.У результаті назву правого стовпця було змінено з COUNT(*) на num_starts.
Отже, стовпець COUNT(*) у повернутій таблиці тепер має псевдонім num_starts. Це корисне ключове слово, особливо якщо ви маєте справу з великими наборами даних, адже неоднозначні назви таблиць або стовпців зустрічаються частіше, ніж може здатися на перший погляд.
Ключове слово ORDER BY сортує дані, отримані під час виконання запиту, за зростанням або спаданням на основі заданого критерію або значення стовпця. Додайте це ключове слово в попередній запит, щоб:
Кожна з таких команд представляє окремий запит. Для їх запуску виконайте наведені нижче дії.
У результаті останнього запиту ви отримаєте список початкових станцій за кількістю стартів із цього місця.
Ви можете помітити, що станція "Hyde Park Corner, Hyde Park" ("Гайд-парк-корнер, Гайд-парк") має найбільшу кількість стартів. Однак якщо вирахувати частку від загальної кількості (671 688/83 434 866), то виявиться, що із цієї станції починається <1% поїздок.
Дайте відповіді на запитання з кількома варіантами відповіді нижче, щоб закріпити розуміння понять, які зустрічаються в практичній роботі.
Cloud SQL – це повністю керований сервіс баз даних, який дає змогу легко налаштовувати, підтримувати й адмініструвати реляційні бази даних PostgreSQL і MySQL та керувати ними в хмарі. У Cloud SQL підтримуються два формати даних: файли дампу (.sql) або CSV (.csv). Ви дізнаєтесь, як експортувати підмножини таблиці cycle_hire у файли CSV й завантажити їх у Cloud Storage як проміжне місце.
У консолі BigQuery Console ви мали виконати останньою таку команду:
У розділі Query Results (Результати запиту) натисніть SAVE RESULTS (ЗБЕРЕГТИ РЕЗУЛЬТАТИ) > CSV(local file). Таким чином буде ініційовано завантаження запиту у вигляді файлу CSV. Запам’ятайте розташування й назву завантаженого файлу, оскільки він вам скоро знадобиться.
Очистьте редактор запитів, а потім скопіюйте й запустіть наведену нижче команду.
У результаті ви отримаєте таблицю, яка містить кількість поїздок на велосипеді, що завершилися на кожній кінцевій станції, упорядковану за числом від найбільшого до найменшого.
Перейдіть у Cloud Console, де буде створено сховище, куди ви зможете завантажити щойно збережені файли.
Виберіть меню навігації > Cloud Storage > Buckets (Сегменти), а потім натисніть CREATE BUCKET (СТВОРИТИ СЕГМЕНТ).
Введіть унікальну назву для сегмента, залиште всі інші налаштування за умовчанням і натисніть Create (Створити).
Якщо з’явиться вікно Public access will be prevented (Загальний доступ буде заборонено), натисніть Confirm (Підтвердити).
Щоб підтвердити виконання завдання, натисніть Підтвердити виконання нижче. Якщо сегмент створено правильно, з’явиться оцінка.
Тепер ви маєте бути в Cloud Console, де відображається щойно створений сегмент Cloud Storage.
Натисніть UPLOAD > Upload files (ЗАВАНТАЖИТИ > Завантажити файли) і виберіть файл CSV, який містить дані start_station_name.
Натисніть Open (Відкрити). Повторіть ці дії з даними end_station_name.
Змініть назву файлу start_station_name, натиснувши три крапки збоку файлу, а потім – Rename (Перейменувати). Нова назва файлу має бути така: start_station_data.csv.
Змініть назву файлу end_station_name, натиснувши три крапки збоку файлу, а потім – Rename (Перейменувати). Нова назва файлу має бути така: end_station_data.csv.
Тепер файли start_station_data.csv й end_station_data.csv мають відображатися в списку Objects (Об’єкти) на сторінці Bucket details (Відомості про сегмент).
Щоб підтвердити виконання завдання, натисніть Підтвердити виконання. Якщо об’єкти файлів CSV завантажено правильно, з’явиться оцінка.
У консолі виберіть меню навігації > SQL.
Натисніть CREATE INSTANCE (СТВОРИТИ ЕКЗЕМПЛЯР) > Choose MySQL (Виберіть MySQL).
Укажіть такий ідентифікатор екземпляра: my-demo.
У полі Password (Пароль) введіть надійний пароль (запам’ятайте його!).
Виберіть таку версію бази даних: MySQL 8.
У полі Choose a Cloud SQL edition (Виберіть версію Cloud SQL) натисніть Enterprise.
Для параметра Edition preset (Набір налаштувань версії) виберіть Development (Розробка) (4 віртуальні центральні процесори, 16 ГБ оперативної пам’яті, сховище обсягом 100 ГБ, одна зона).
У полі Region (Регіон) укажіть:
У полі Multi zones (Highly available) (Кілька зон (Високий рівень доступності)) > Primary Zone (Основна зона) укажіть:
Натисніть CREATE INSTANCE (СТВОРИТИ ЕКЗЕМПЛЯР).
Щоб підтвердити виконання завдання, натисніть Підтвердити виконання нижче. Якщо екземпляр Cloud SQL налаштовано правильно, з’явиться оцінка.
Тепер у вас є активний екземпляр Cloud SQL, і ви можете створити базу даних усередині нього за допомогою командного рядка Cloud Shell.
Відкрийте Cloud Shell, натиснувши значок у верхньому правому куті консолі.
Виконайте наведену нижче команду, щоб установити ідентифікатор вашого проекту як змінну середовища.
Якщо з’явиться запит [Y/n], натисніть Y, а потім – ENTER.
Ви отримаєте посилання, яке потрібно відкрити у вебпереглядачі (у тому самому, де ви входили в обліковий запис Qwiklabs). Після входу ви отримаєте код підтвердження, який потрібно скопіювати й вставити в Cloud Shell.
my-demo іншою назвою, яку ви використовували для свого екземпляра.Вивід матиме приблизно такий вигляд:
Екземпляр Cloud SQL надається з попередньо налаштованими базами даних, але ви створите власну базу для зберігання даних про прокат велосипедів у Лондоні.
bike.Вивід має бути таким:
Щоб підтвердити виконання завдання, натисніть Підтвердити виконання. Якщо базу даних в екземплярі Cloud SQL створено правильно, з’явиться оцінка.
Ця інструкція містить ключове слово CREATE, але цього разу зі словом TABLE, щоб указати, що потрібно створити таблицю, а не базу даних. Ключове слово USE указує базу даних, до якої ви хочете підключитися. Тепер у вас є таблиця з назвою "london1", яка містить два стовпці: "start_station_name" і "num". VARCHAR(255) указує, що стовпець змінної довжини може містити до 255 символів, а INT – тип стовпця, у якому значення має бути цілим числом.
Для обох команд ви маєте отримати такий вивід:
У консолі відображається "empty set" ("порожній набір"), тому що ви ще не завантажили дані.
Поверніться в консоль Cloud SQL. Тепер потрібно завантажити файли CSV start_station_name і end_station_name у нові таблиці "london1" та "london2".
start_station_data.csv. Натисніть Select (Вибрати).bike і введіть london1 для таблиці.Виконайте ті самі дії для іншого файлу CSV.
end_station_data.csv. Натисніть Select (Вибрати).bike і введіть london2 для таблиці.Обидва файли CSV мають завантажитися в таблиці в базі даних bike.
Ви повинні отримати 955 рядків, по одному для кожної унікальної назви станції.
Ви повинні отримати 959 рядків, по одному для кожної унікальної назви станції.
Пропонуємо ознайомитися з іще кількома ключовими словами SQL, які допомагають у керуванні даними. Перше таке ключове слово – DELETE.
Після виконання обох команд ви маєте отримати такий вивід:
Видалені рядки були заголовками стовпців у файлах CSV. Ключове слово DELETE видаляє не перший рядок файлу сам по собі, а всі рядки таблиці, де назва стовпця (у цьому випадку "num") містить указане значення (у цьому випадку "0"). Якщо ви виконаєте запити SELECT * FROM london1; і SELECT * FROM london2; та прокрутите таблицю вгору, то побачите, що цих рядків більше немає.
Ви також можете вставляти значення в таблиці за допомогою ключового слова INSERT INTO.
start_station_name значення "test destination", а для num значення "1".Для ключового слова INSERT INTO потрібна таблиця ("london1"), тоді буде створено новий рядок зі стовпцями, визначеними умовами в перших дужках (у цьому випадку "start_station_name" і "num"). Усе, що стоїть після оператора "VALUES" ("ЗНАЧЕННЯ"), буде вставлено в новому рядку.
Вивід має бути таким:
Якщо ви виконаєте запит SELECT * FROM london1;, то побачите новий рядок, доданий у нижній частині таблиці "london1".
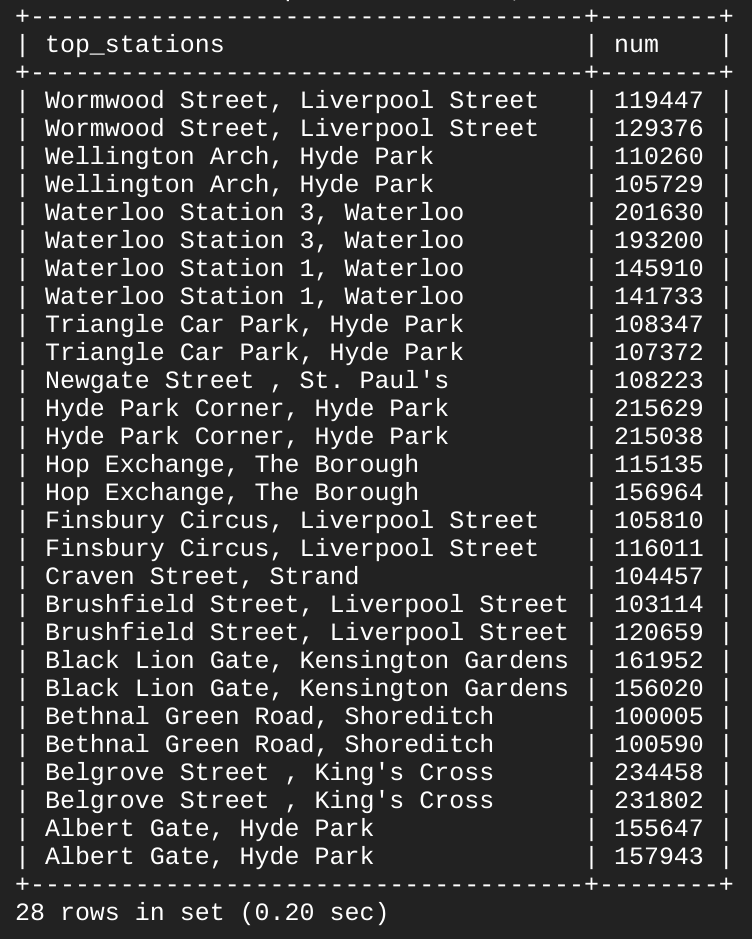
Останнє ключове слово SQL, яке ви вивчите, – це UNION. Воно об’єднує принаймні два запити SELECT і виводить для них список результатів. UNION використовується для об’єднання підмножин даних таблиць "london1" і "london2".
Такий ланцюговий запит витягує певні дані з обох таблиць і об’єднує їх за допомогою оператора UNION.
Перший запит SELECT вибирає два стовпці з таблиці "london1" і створює псевдонім для стовпця "start_station_name", якому присвоюється значення "top_stations". У ньому використовується ключове слово WHERE, щоб отримати лише назви станцій, з яких стартують понад 100 000 велосипедів.
Другий запит SELECT вибирає два стовпці з таблиці "london2" і використовує ключове слово WHERE, щоб отримати лише назви станцій, де закінчують поїздку понад 100 000 велосипедів.
Ключове слово UNION між ними поєднує результати цих запитів, комбінуючи дані таблиць "london2" й "london1". Оскільки "london1" об’єднується з "london2", значення стовпців, яким надається пріоритет, є "top_stations" і "num".
Ключове слово ORDER BY упорядкує кінцеву об’єднану таблицю за значенням стовпця "top_stations" в алфавітному порядку за спаданням.
Приклад виводу (ваш результат може відрізнятися) :
Отже, як ви можете бачити, 13 із 14 станцій посідають перші місця за кількістю як стартів, так і завершень поїздок. За допомогою базових ключових слів SQL ви зробили запит у великий набір даних, у результаті чого отримали точки даних і відповіді на конкретні запитання.
Під час цієї практичної роботи ви вивчили основи мови SQL, а також навчилися застосовувати ключові слова та виконувати запити в BigQuery й CloudSQL. Ви розглянули ключові поняття, як-от проекти, бази даних і таблиці. Ви потренувалися використовувати ключові слова, які дають змогу редагувати дані й керувати ними. Ви дізнались, як працювати з даними в BigQuery й спробували виконувати запити в таблицях. Ви навчилися створювати екземпляри в Cloud SQL і переносити підмножини даних у таблиці, які містяться в базах даних. Ви створили ланцюжок і виконали запити в Cloud SQL, щоб зробити висновки щодо початкових і кінцевих станцій прокату велосипедів у Лондоні.
Продовжуйте вивчати й застосовувати на практиці Cloud SQL і BigQuery за допомогою наведених нижче практичних робіт Google Cloud Skill Boost.
Якщо вас цікавить наука про дані, більше інформації ви знайдете в книзі Data Science on the Google Cloud Platform, 2nd Edition: O'Reilly Media, Inc. (Наука про дані з Google Cloud Platform, 2-й випуск, видавництво O’Reilly Media, Inc).
…допомагають ефективно використовувати технології Google Cloud. Наші курси передбачають опанування технічних навичок, а також ознайомлення з рекомендаціями, що допоможуть вам швидко зорієнтуватися й вивчити матеріал. Ми пропонуємо курси різних рівнів – від базового до високого. Ви можете вибрати формат навчання (за запитом, онлайн або офлайн) відповідно до власного розкладу. Пройшовши сертифікацію, ви перевірите й підтвердите свої навички та досвід роботи з технологіями Google Cloud.
Посібник востаннє оновлено 16 жовтня 2024 року
Практичне заняття востаннє протестовано 16 жовтня 2024 року
© Google LLC 2025. Усі права захищено. Назва та логотип Google є торговельними марками Google LLC. Усі інші назви компаній і продуктів можуть бути торговельними марками відповідних компаній, з якими вони пов’язані.



This content is not currently available
We will notify you via email when it becomes available

Great!
We will contact you via email if it becomes available

One lab at a time
Confirm to end all existing labs and start this one