GSP281

Opis
SQL (Structured Query Language) to standardowy język używany przy wykonywaniu operacji na danych, umożliwiający zadawanie pytań i uzyskiwanie informacji z ustrukturyzowanych zbiorów danych. Powszechnie wykorzystuje się go do zarządzania bazami danych oraz wykonywania zadań takich jak wpisywanie rejestru transakcji do relacyjnych baz danych czy analizowanie petabajtów danych.
Moduł składa się z 2 części. W pierwszej nauczysz się podstawowych słów kluczowych SQL. Wykorzystasz je w BigQuery, uruchamiając zapytania do publicznego zbioru danych zawierającego informacje o przejazdach rowerami miejskimi w Londynie.
Z drugiej części dowiesz się, jak eksportować podzbiory zbioru danych o wykorzystaniu rowerów miejskich w Londynie do plików CSV, które następnie prześlesz do Cloud SQL. Nauczysz się także, jak za pomocą Cloud SQL tworzyć bazy danych i tabele oraz nimi zarządzać. Na koniec przećwiczysz użycie dodatkowych słów kluczowych SQL umożliwiających wykonywanie operacji na danych i ich edytowanie.
Czego się nauczysz
W tym module nauczysz się, jak:
- wczytywać dane do BigQuery;
- wykonywać proste zapytania w BigQuery, aby przeglądać dane;
- wyeksportować podzbiór danych do pliku CSV i umieścić ten plik w nowym zasobniku Cloud Storage;
- utworzyć nową instancję Cloud SQL i przesłać wyeksportowany przez siebie plik CSV jako nową tabelę.
Wymagania wstępne
Bardzo ważne: przed rozpoczęciem tego modułu wyloguj się z osobistego i służbowego konta Gmail.
To jest moduł dla użytkowników początkujących. Zakładamy więc, że masz niewielkie doświadczenie z SQL lub nie masz go wcale. Znajomość Cloud Storage i Cloud Shell może być pomocna, ale nie jest konieczna. W tym module nauczysz się podstaw czytania i pisania zapytań w języku SQL, a także przećwiczysz zdobyte umiejętności przy użyciu BigQuery oraz Cloud SQL.
Zanim rozpoczniesz ten moduł, spróbuj ocenić swój stopień znajomości SQL. Poniżej znajdziesz trudniejsze moduły pozwalające na wykorzystanie wiedzy w bardziej złożonych przykładach.
Aby rozpocząć, przewiń stronę w dół i wykonaj opisane niżej kroki konfiguracji środowiska modułu.
Konfiguracja i wymagania
Zanim klikniesz przycisk Rozpocznij moduł
Zapoznaj się z tymi instrukcjami. Moduły mają limit czasowy i nie można ich zatrzymać. Gdy klikniesz Rozpocznij moduł, na liczniku wyświetli się informacja o tym, na jak długo udostępniamy Ci zasoby Google Cloud.
W tym praktycznym module możesz spróbować swoich sił w wykonywaniu opisywanych działań w prawdziwym środowisku chmury, a nie w jego symulacji lub wersji demonstracyjnej. Otrzymasz nowe, tymczasowe dane logowania, dzięki którym zalogujesz się i uzyskasz dostęp do Google Cloud na czas trwania modułu.
Do ukończenia modułu potrzebne będą:
- Dostęp do standardowej przeglądarki internetowej (zalecamy korzystanie z przeglądarki Chrome).
Uwaga: uruchom ten moduł w oknie incognito (zalecane) lub przeglądania prywatnego. Dzięki temu unikniesz konfliktu między swoim kontem osobistym a kontem do nauki, co mogłoby spowodować naliczanie dodatkowych opłat na koncie osobistym.
- Odpowiednia ilość czasu na ukończenie modułu – pamiętaj, że gdy rozpoczniesz, nie możesz go wstrzymać.
Uwaga: w tym module używaj tylko konta do nauki. Jeśli użyjesz innego konta Google Cloud, mogą na nim zostać naliczone opłaty.
Rozpoczynanie modułu i logowanie się w konsoli Google Cloud
-
Kliknij przycisk Rozpocznij moduł. Jeśli moduł jest odpłatny, otworzy się okno, w którym możesz wybrać formę płatności.
Po lewej stronie znajduje się panel Szczegóły modułu z następującymi elementami:
- przyciskiem Otwórz konsolę Google Cloud;
- czasem, który Ci pozostał;
- tymczasowymi danymi logowania, których musisz użyć w tym module;
- innymi informacjami potrzebnymi do ukończenia modułu.
-
Kliknij Otwórz konsolę Google Cloud (lub kliknij prawym przyciskiem myszy i wybierz Otwórz link w oknie incognito, jeśli korzystasz z przeglądarki Chrome).
Moduł uruchomi zasoby, po czym otworzy nową kartę ze stroną logowania.
Wskazówka: otwórz karty obok siebie w osobnych oknach.
Uwaga: jeśli pojawi się okno Wybierz konto, kliknij Użyj innego konta.
-
W razie potrzeby skopiuj nazwę użytkownika znajdującą się poniżej i wklej ją w oknie logowania.
{{{user_0.username | "Username"}}}
Nazwę użytkownika znajdziesz też w panelu Szczegóły modułu.
-
Kliknij Dalej.
-
Skopiuj podane niżej hasło i wklej je w oknie powitania.
{{{user_0.password | "Password"}}}
Hasło znajdziesz też w panelu Szczegóły modułu.
-
Kliknij Dalej.
Ważne: musisz użyć danych logowania podanych w module. Nie używaj danych logowania na swoje konto Google Cloud.
Uwaga: korzystanie z własnego konta Google Cloud w tym module może wiązać się z dodatkowymi opłatami.
-
Na kolejnych stronach wykonaj następujące czynności:
- Zaakceptuj Warunki korzystania z usługi.
- Nie dodawaj opcji odzyskiwania ani uwierzytelniania dwuskładnikowego (ponieważ konto ma charakter tymczasowy).
- Nie rejestruj się w bezpłatnych wersjach próbnych.
Poczekaj, aż na karcie otworzy się konsola Google Cloud.
Uwaga: aby uzyskać dostęp do produktów i usług Google Cloud, kliknij Menu nawigacyjne lub wpisz nazwę usługi albo produktu w polu Szukaj.

Zadanie 1. Podstawy SQL
Bazy danych i tabele
Jak już wspomnieliśmy, SQL umożliwia pozyskiwanie informacji z „ustrukturyzowanych zbiorów danych”. Ustrukturyzowany zbiór danych ma jasno określone reguły i formatowanie. Często uporządkowany jest w formie tabeli lub danych w wierszach i kolumnach.
Przykładem nieustrukturyzowanych danych są pliki graficzne. Nieustrukturyzowane dane nie działają w SQL i nie mogą być przechowywane w zbiorach danych ani tabelach BigQuery (przynajmniej nie natywnie). Aby móc wykonywać operacje na (między innymi) pliku graficznym, należałoby skorzystać z usługi takiej jak Cloud Vision – na przykład bezpośrednio poprzez jej interfejs API.
Poniżej znajdziesz przykład ustrukturyzowanego zbioru danych w formie prostej tabeli:
|
Użytkownik
|
Cena
|
Wysłano
|
|
Sean
|
35 USD
|
Tak
|
|
Rocky
|
50 USD
|
Nie
|
Jeśli masz już doświadczenie z Arkuszami Google, powinno to wyglądać znajomo. W tabeli znajdują się kolumny Użytkownik, Cena i Wysłano oraz 2 wiersze składające się z wartości wpisanych dla poszczególnych kolumn.
Ogólnie rzecz biorąc, baza danych to zestaw składający się z co najmniej 1 tabeli. Choć SQL jest narzędziem do zarządzania ustrukturyzowanymi bazami danych, często uruchamia się zapytania nie do całej bazy, a do jednej lub kilku połączonych ze sobą tabel (co będziemy robić również w tym module).
SELECT i FROM
Ponieważ język SQL jest z natury fonetyczny, przed uruchomieniem zapytania warto zastanowić się nad tym, jakie informacje chcemy uzyskać (chyba że badamy dane tylko dla zabawy).
SQL ma gotowe słowa kluczowe, których używa się do tworzenia zapytań opartych na pseudoangielskiej składni SQL, tak aby silnik bazy danych zwrócił oczekiwaną odpowiedź.
Najważniejsze słowa kluczowe to SELECT i FROM:
- Użyj słowa kluczowego
SELECT, aby określić, które pola ze zbioru danych chcesz pobrać.
- Użyj słowa kluczowego
FROM, aby określić, z których tabel chcesz pobrać dane.
Wesprzyjmy się przykładem. Załóżmy, że masz tabelę example_table, która zawiera kolumny USER (UŻYTKOWNIK), PRICE (CENA) i SHIPPED (WYSŁANO):
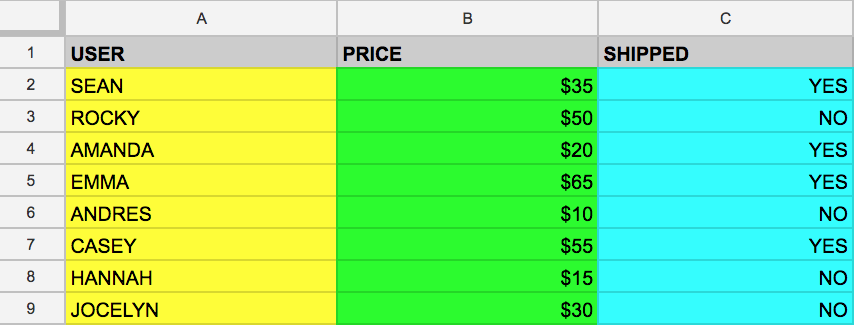
Przyjmijmy także, że chcesz pobrać tylko dane znajdujące się w kolumnie USER. Możesz to zrobić, uruchamiając zapytanie wykorzystujące słowa kluczowe SELECT i FROM:
SELECT USER FROM example_table
Jeśli wykonasz podane powyżej polecenie, wybrane zostaną wszystkie nazwy z kolumny USER znajdujące się w example_table.
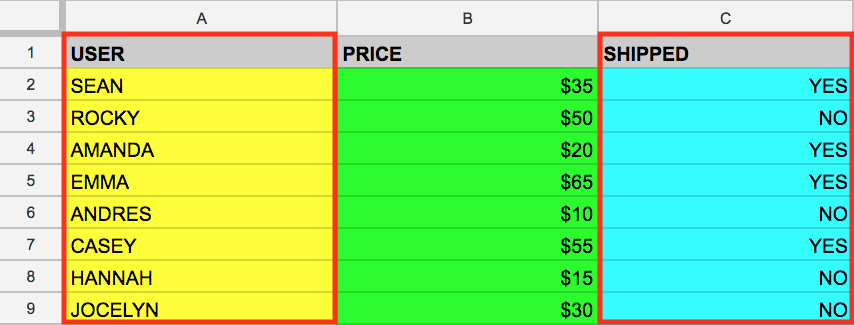
Przy użyciu słowa kluczowego SQL SELECT można wybrać też wiele kolumn. Załóżmy, że chcesz pobrać dane, które znajdują się w kolumnach USER i SHIPPED. Aby to zrobić, zmodyfikuj poprzednie zapytanie SELECT, dodając do niego kolejną wartość kolumny (pamiętaj, by oddzielić tę wartość przecinkiem):
SELECT USER, SHIPPED FROM example_table
Uruchomienie tego polecenia sprawi, że z pamięci pobrane zostaną dane USER i SHIPPED:
Tym prostym sposobem udało Ci się opanować 2 podstawowe słowa kluczowe SQL. Teraz zrobi się jeszcze ciekawiej.
WHERE
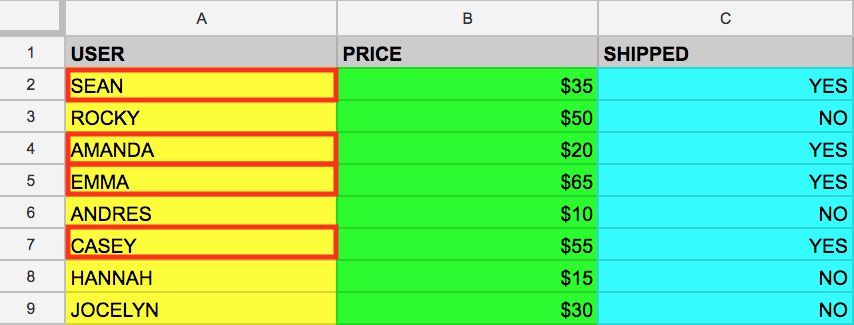
Słowo kluczowe WHERE to kolejne polecenie SQL, które filtruje tabele w poszukiwaniu określonych wartości kolumny. Przyjmijmy, że z tabeli example_table chcesz pobrać nazwy użytkowników, których paczki zostały wysłane. Możesz dodać do zapytania słowo WHERE, tak jak poniżej:
SELECT USER FROM example_table WHERE SHIPPED='YES'
To polecenie zwraca z pamięci nazwy wszystkich użytkowników z kolumny USER, których paczki zostały wysłane (SHIPPED):
Skoro poznaliśmy już podstawy dotyczące słów kluczowych SQL, spróbuj wykorzystać zdobyte informacje, uruchamiając omówione typy zapytań w konsoli BigQuery.
Sprawdź swoją wiedzę
Poniżej znajdziesz pytania jednokrotnego wyboru, które pomogą Ci utrwalić zdobytą dotychczas wiedzę. Odpowiedz na nie najlepiej, jak potrafisz.
Zadanie 2. Informacje o konsoli BigQuery
Wzorzec BigQuery
BigQuery to w pełni zarządzana hurtownia danych, która może obsługiwać petabajty danych i działa w Google Cloud. Analitycy i badacze danych mogą szybko filtrować duże zbiory danych, tworzyć do nich zapytania, zbierać wyniki oraz wykonywać złożone operacje, nie martwiąc się o konfigurację czy zarządzanie serwerami. BigQuery jest dostarczane w formie narzędzia wiersza poleceń (zainstalowanego w Cloud Shell) lub konsoli sieciowej – obie formy pozwalają na zarządzanie danymi przechowywanymi w projektach Google Cloud i tworzenie do nich zapytań.
W tym module do uruchamiania zapytań SQL użyjesz konsoli sieciowej.
Otwieranie konsoli BigQuery
- W konsoli Google Cloud Console kliknij menu nawigacyjne > BigQuery.
Otworzy się okno Witamy w usłudze BigQuery w Cloud Console. Zawiera ono link do krótkiego wprowadzenia oraz informacji o wersji.
- Kliknij Gotowe.
Otworzy się konsola BigQuery.
Poświęćmy chwilę na omówienie kilku ważnych funkcji interfejsu użytkownika. Po prawej stronie konsoli znajduje się Edytor zapytań. To w nim wpisuje się i uruchamia polecenia SQL takie jak te, które przedstawiliśmy wcześniej. Pod spodem znajduje się „Historia zapytań”, czyli lista zapytań uruchomionych w przeszłości.
Obszar po lewej stronie konsoli to Menu nawigacyjne. Oprócz niewymagających wyjaśnień opcji związanych z historią zapytań, zapisanymi zapytaniami i historią zadań znajduje się tam karta Eksplorator.
Najwyższy poziom zasobów na karcie Eksplorator to projekty Google Cloud – czyli takie, jak tymczasowe projekty Google Cloud, w których logujesz się i których używasz w każdym module Google Cloud Skills Boost. Jak widać w konsoli i na ostatnim zrzucie ekranu, na karcie Eksplorator znajduje się tylko Twój projekt. Jeśli klikniesz strzałkę obok nazwy projektu, nic się nie wyświetli.
To dlatego, że projekt nie zawiera żadnych zbiorów danych ani tabel – nie ma nic, do czego można by utworzyć zapytanie. Wcześniej dowiedzieliśmy się, że zbiór danych zawiera tabele. Dodając dane do projektu, zwróć uwagę na następującą prawidłowość: w BigQuery projekt zawiera zbiory danych, a zbiór danych – tabele. Skoro zrozumieliśmy już wzorzec projekt > zbiór danych > tabela i zgłębiliśmy tajniki konsoli, spróbujmy przesłać dane, do których można utworzyć zapytania.
Przesyłanie danych, do których można utworzyć zapytania
W tej sekcji pobierzesz do projektu dane publiczne, aby móc przećwiczyć uruchamianie poleceń SQL w BigQuery.
-
Kliknij + DODAJ.
-
Wybierz Oznacz projekt według nazwy gwiazdką.
-
Jako nazwę projektu wpisz bigquery-public-data.
-
Kliknij GWIAZDKĘ.
Pamiętaj, że w nowej karcie nadal pracujesz z poziomu projektu modułu. Wprawdzie pobraliśmy dostępny publicznie projekt zawierający zbiory danych i tabele, aby przeanalizować go w BigQuery, ale nie przełączyliśmy się na niego. Wszystkie zadania i usługi wciąż powiązane są z Twoim kontem Google Cloud Skills Boost. Możesz się o tym przekonać, sprawdzając pole projektu tuż przy samej górze konsoli:
- Masz teraz dostęp do tych danych:
- Projekt Google Cloud →
bigquery-public-data
- Zbiór danych →
london_bicycles
- Kliknij zbiór danych london bicycles, aby wyświetlić powiązane tabele.
- Tabela →
cycle_hire
- Tabela →
cycle_stations
W tym module użyjesz danych z tabeli cycle_hire. Otwórz tabelę cycle_hire, po czym kliknij kartę Podgląd. Wyświetlona strona powinna przypominać tę:
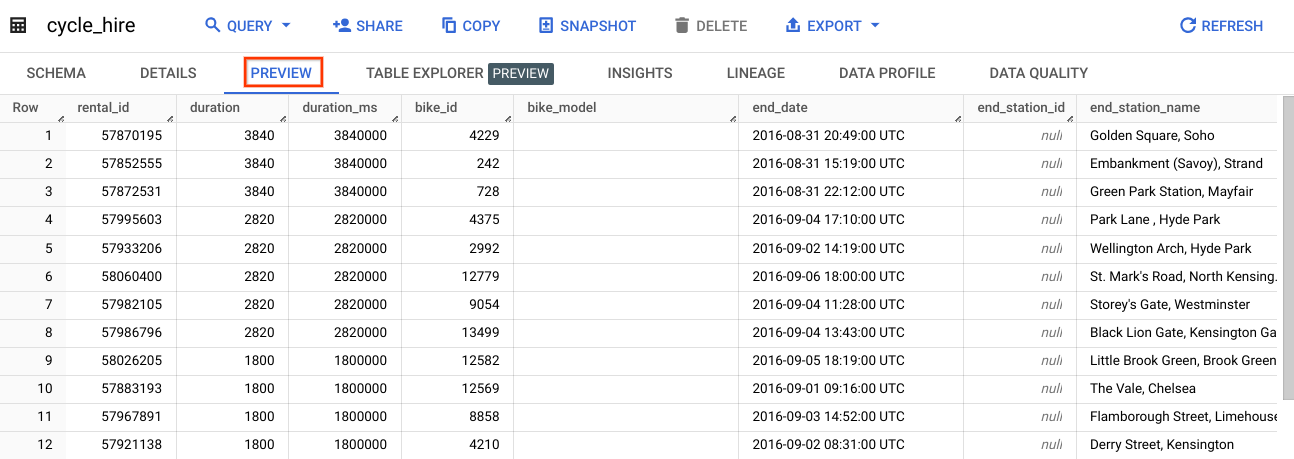
Przyjrzyj się kolumnom i wartościom podanym w wierszach. Teraz do tabeli cycle_hire możesz uruchomić zapytania SQL.
Uruchamianie poleceń SELECT, FROM i WHERE w BigQuery
Poznaliśmy już podstawowe słowa kluczowe stosowane w zapytaniach SQL oraz omówiliśmy wzorzec danych BigQuery; mamy także dane, z którymi można pracować. Teraz możemy uruchomić polecenia SQL przy użyciu tej usługi.
Jeśli spojrzysz w prawy dolny róg konsoli, zobaczysz, że jest 83 434 866 wierszy danych dotyczących pojedynczych przejazdów rowerami publicznymi na terenie Londynu w latach 2015–2017 – trzeba przyznać, że to niemało.
Przyjrzyj się kluczowi end_station_name w kolumnie siódmej, który wskazuje na miejsce docelowe przejazdu rowerem miejskim. Wcześniej jednak uruchom proste zapytanie, aby wyizolować kolumnę end_station_name.
- Skopiuj następujące polecenie i wklej je do Edytora zapytań:
SELECT end_station_name FROM `bigquery-public-data.london_bicycles.cycle_hire`;
- Następnie kliknij Uruchom.
Po około 20 sekundach powinno zostać zwróconych 83 434 866 wierszy zawierających dane z kolumny, której dotyczyło zapytanie: end_station_name.
A może sprawdzimy, ile przejazdów trwało co najmniej 20 minut?
- Wyczyść zapytanie z edytora, a następnie uruchom zapytanie ze słowem kluczowym
WHERE:
SELECT * FROM `bigquery-public-data.london_bicycles.cycle_hire` WHERE duration>=1200;
Przeprocesowanie tego zapytania może potrwać około minuty.
SELECT * zwraca wszystkie wartości kolumny z tabeli. Czas trwania (duration) mierzony jest w sekundach, dlatego użyliśmy wartości 1200 (60 × 20).
Jeśli spojrzysz w prawy dolny róg, zobaczysz, że zwróconych zostało 26 441 016 wierszy. Liczba ta stanowi ułamek całości (26 441 016 / 83 434 866), co oznacza, że około 30% przejazdów rowerem publicznym po Londynie trwało co najmniej 20 minut (dobre rozwiązanie na dłuższą metę).
Sprawdź swoją wiedzę
Poniżej znajdziesz pytania jednokrotnego wyboru, które pomogą Ci utrwalić zdobytą dotychczas wiedzę. Odpowiedz na nie najlepiej, jak potrafisz.
Zadanie 3. Więcej słów kluczowych SQL: GROUP BY, COUNT, AS i ORDER BY
GROUP BY
Słowo kluczowe GROUP BY zbiera wiersze wyników o wspólnych kryteriach (np. wartości kolumny) i zwraca wszystkie unikalne wpisy spełniające dane kryteria.
To użyteczne słowo kluczowe, które przydaje się do wyszukiwania informacji kategorialnych w tabelach.
- Aby przyjrzeć się jego działaniu, wyczyść zapytanie z edytora, po czym skopiuj i wklej następujące polecenie:
SELECT start_station_name FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name;
- Kliknij Uruchom.
Wynikiem jest lista unikalnych (niepowtarzalnych) wartości kolumny.
Gdybyśmy nie użyli słowa kluczowego GROUP BY, zapytanie zwróciłoby wszystkie 84 434 866 wierszy. Zastosowanie GROUP BY pozwala na wyświetlenie unikalnych wartości kolumny z tabeli. Możesz się o tym przekonać, spoglądając w prawy dolny róg. Zobaczysz 954 wiersze, co oznacza, że w Londynie są 954 unikalne miejsca, w których rozpoczęto przejazd rowerem publicznym.
COUNT
Funkcja COUNT() zwraca liczbę wierszy o takich samych kryteriach (np. wartości kolumny). W połączeniu z GROUP BY może być bardzo przydatna.
Dodaj funkcję COUNT do poprzedniego zapytania, aby dowiedzieć się, ile przejazdów rozpoczęło się w danym miejscu.
- Wyczyść zapytanie z edytora, skopiuj i wklej to polecenie, po czym kliknij Uruchom:
SELECT start_station_name, COUNT(*) FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name;
Wyniki pokazują, ile przejazdów rowerem miejskim rozpoczęło się w każdym z miejsc.
AS
Kolejnym słowem kluczowym używanym w SQL jest AS – umożliwia ono stworzenie aliasu tabeli lub kolumny. Alias to nowa nazwa nadawana zwróconej kolumnie lub tabeli (w zależności od tego, do czego słowo AS się odnosi).
- Dodaj słowo kluczowe
AS do zapytania, które zostało uruchomione przed chwilą, aby zobaczyć, jak to wygląda w praktyce. Wyczyść zapytanie z edytora, po czym skopiuj i wklej następujące polecenie:
SELECT start_station_name, COUNT(*) AS num_starts FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name;
- Kliknij Uruchom.
W wynikach nazwa prawej kolumny zmieniła się z COUNT(*) na num_starts.
Jak widzimy, nazwa aliasu dla kolumny COUNT(*) w zwróconej tabeli to num_starts. „AS” jest przydatnym słowem kluczowym, zwłaszcza jeśli ma się do czynienia z dużymi zbiorami danych – skomplikowana nazwa tabeli czy kolumny może łatwo wypaść z pamięci (i zdarza się to częściej, niż myślisz).
ORDER BY
Słowo kluczowe ORDER BY sortuje dane zwrócone z zapytania w kolejności rosnącej lub malejącej na podstawie określonych kryteriów bądź wartości kolumny. Dodaj to słowo do poprzedniego zapytania, aby:
- uzyskać tabelę zawierającą liczbę przejazdów rowerem miejskim, które rozpoczęły się w każdym z miejsc początkowych, uporządkowaną alfabetycznie według nazwy miejsca rozpoczęcia przejazdu;
- uzyskać tabelę zawierającą liczbę przejazdów rowerem miejskim, które rozpoczęły się w każdym z miejsc początkowych, uporządkowaną numerycznie od wartości najniższej do najwyższej;
- uzyskać tabelę zawierającą liczbę przejazdów rowerem miejskim, które rozpoczęły się w każdym z miejsc początkowych, uporządkowaną numerycznie od wartości najwyższej do najniższej.
Każde z poniższych poleceń jest osobnym zapytaniem. Dla każdego polecenia:
- Wyczyść Edytor zapytań.
- Skopiuj polecenie i wklej je do Edytora zapytań.
- Kliknij Uruchom. Przyjrzyj się wynikom.
SELECT start_station_name, COUNT(*) AS num FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name ORDER BY start_station_name;
SELECT start_station_name, COUNT(*) AS num FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name ORDER BY num;
SELECT start_station_name, COUNT(*) AS num FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name ORDER BY num DESC;
Wyniki ostatniego zapytania zawierają listę miejsc początkowych według liczby przejazdów, które się w nich rozpoczęły.
Jak widać, najwięcej przejazdów rozpoczęło się na stacji „Hyde Park Corner, Hyde Park”. Są one jednak tylko ułamkiem całości (234 458 / 83 434 866) i stanowią mniej niż 1% wszystkich przejazdów.
Sprawdź swoją wiedzę
Poniżej znajdziesz pytania jednokrotnego wyboru, które pomogą Ci utrwalić zdobytą dotychczas wiedzę. Odpowiedz na nie najlepiej, jak potrafisz.
Zadanie 4. Praca z Cloud SQL
Eksportowanie zapytań do plików CSV
Cloud SQL to w pełni zarządzana usługa bazy danych ułatwiająca konfigurację i obsługę relacyjnych baz danych PostgreSQL i MySQL w chmurze oraz zarządzanie i administrowanie nimi. Cloud SQL akceptuje 2 formaty danych: pliki zrzutu SQL (.sql) i pliki CSV (.csv). Za chwilę dowiesz się, jak wyeksportować podzbiory tabeli cycle_hire do plików CSV i przesłać je do Cloud Storage jako lokalizacji pośredniej.
Tak powinno wyglądać ostatnie uruchomione przez Ciebie polecenie w konsoli BigQuery:
SELECT start_station_name, COUNT(*) AS num FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name ORDER BY num DESC;
-
W sekcji Wyniki zapytania kliknij ZAPISZ WYNIKI > CSV (plik lokalny). Rozpocznie się pobieranie, w wyniku którego Twoje zapytanie zostanie zapisane jako plik CSV. Zapamiętaj lokalizację i nazwę pobranego pliku – wkrótce będzie Ci on potrzebny.
-
Wyczyść zapytanie z edytora, po czym skopiuj i uruchom następujące polecenie:
SELECT end_station_name, COUNT(*) AS num FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY end_station_name ORDER BY num DESC;
Zwraca ono tabelę zawierającą liczbę przejazdów rowerem miejskim, które zakończyły się w każdym z miejsc docelowych, uporządkowaną numerycznie od wartości najwyższej do najniższej.
- W sekcji Wyniki zapytania kliknij ZAPISZ WYNIKI > CSV (plik lokalny). Rozpocznie się pobieranie, w wyniku którego Twoje zapytanie zostanie zapisane jako plik CSV. Zapamiętaj nazwę i lokalizację pobranego pliku – będzie Ci on potrzebny w następnej sekcji.
Przesyłanie plików CSV do Cloud Storage
-
Przejdź do konsoli Google Cloud. Utworzysz tam zasobnik na dane, do którego prześlesz utworzone przed chwilą pliki.
-
Wybierz Menu nawigacyjne > Cloud Storage > Zasobniki, a następnie kliknij UTWÓRZ ZASOBNIK.
Uwaga: jeśli pojawi się pytanie o niezapisaną pracę, kliknij OPUŚĆ.
-
Wpisz unikalną nazwę zasobnika, pozostaw wszystkie pozostałe ustawienia z wartościami domyślnymi i kliknij Utwórz.
-
Jeśli pojawi się okno Dostęp publiczny zostanie zablokowany, kliknij Potwierdź.
Testowanie ukończonego zadania
Kliknij Sprawdź postępy poniżej, aby sprawdzić postęp pracy z modułem. Jeśli udało Ci się utworzyć zasobnik, wyświetli się odpowiedni wynik.
Utworzenie zasobnika w Cloud Storage
W konsoli Google Cloud powinien wyświetlać się teraz Twój nowo utworzony zasobnik Cloud Storage.
-
Kliknij PRZEŚLIJ > Prześlij pliki i wybierz plik CSV zawierający dane związane z miejscami początkowymi przejazdów (start_station_name).
-
Następnie kliknij Otwórz. Powtórz te czynności dla pliku zawierającego dane związane z miejscami docelowymi przejazdów (end_station_name).
-
Zmień nazwę pliku z danymi start_station_name, klikając najpierw 3 kropki znajdujące się w pewnej odległości od pliku, a następnie zmień nazwę. Jako nazwę pliku wpisz start_station_data.csv.
-
Zmień nazwę pliku z danymi end_station_name, klikając najpierw 3 kropki znajdujące się w pewnej odległości od pliku, a następnie zmień nazwę. Jako nazwę pliku wpisz end_station_data.csv.
Na liście Obiekty na stronie Szczegóły zasobnika powinny teraz występować obiekty start_station_data.csv i end_station_data.csv.
Testowanie ukończonego zadania
Kliknij Sprawdź postępy, żeby zobaczyć stan realizacji zadania. Jeśli udało Ci się przesłać obiekty CSV do zasobnika, wyświetli się odpowiedni wynik.
Przesłanie plików CSV do Cloud Storage
Zadanie 5. Tworzenie instancji Cloud SQL
W konsoli wybierz Menu nawigacyjne > SQL.
-
Kliknij UTWÓRZ INSTANCJĘ > Wybierz MySQL.
-
Wpisz my-demo jako identyfikator instancji.
-
W polu Hasło wpisz bezpieczne hasło (zapamiętaj je).
-
Jako wersję bazy danych wybierz MySQL 8.
-
W polu Wybierz wersję Cloud SQL kliknij Enterprise.
-
W polu Gotowe wybierz Programowanie (4 vCPU, 16 GB RAM, 100 GB miejsca na dane, jedna strefa).
Uwaga: jeśli wybierzesz gotową instancję większą niż Programowanie, Twój projekt zostanie oznaczony, a moduł zostanie zakończony.
-
W polu Region ustaw wartość .
-
W polu Wiele stref (wysoka dostępność) > Główna strefa ustaw .
-
Kliknij UTWÓRZ INSTANCJĘ.
Uwaga: tworzenie instancji może potrwać kilka minut. Gdy proces dobiegnie końca, na stronie instancji SQL obok nazwy instancji wyświetli się zielony znacznik wyboru.
- Kliknij instancję Cloud SQL. Otworzy się strona SQL – przegląd.
Testowanie ukończonego zadania
Kliknij Sprawdź postępy poniżej, aby sprawdzić postęp pracy z modułem. Jeśli udało Ci się skonfigurować instancję Cloud SQL, wyświetli się odpowiedni wynik.
Utworzenie instancji Cloud SQL
Zadanie 6. Nowe zapytania w Cloud SQL
Słowo kluczowe CREATE (tworzenie baz danych i tabel)
Instancja Cloud SQL została już skonfigurowana, możesz więc utworzyć w niej bazę danych przy użyciu wiersza poleceń Cloud Shell.
-
Otwórz Cloud Shell, klikając ikonę w prawym górnym rogu konsoli.
-
Uruchom to polecenie, aby ustawić identyfikator projektu jako zmienną środowiskową:
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
Tworzenie bazy danych w Cloud Shell
- Aby skonfigurować uwierzytelnianie bez otwierania przeglądarki, uruchom to polecenie w Cloud Shell:
gcloud auth login --no-launch-browser
Jeśli pojawi się pytanie [Y/n], naciśnij Y, a następnie Enter.
Wyświetli się link do otwarcia w przeglądarce. Otwórz ten link w tej samej przeglądarce, w której masz otwarte konto qwiklabs. Po zalogowaniu się otrzymasz kod weryfikacyjny do skopiowania. Wklej ten kod w Cloud Shell.
- Uruchom podane niżej polecenie, aby połączyć się z instancją SQL. Zastąp część
my-demo własną nazwą instancji (o ile to konieczne):
gcloud sql connect my-demo --user=root --quiet
Uwaga: łączenie się z instancją może potrwać około minuty. Jeśli pojawi się komunikat „Nie udało się wykonać operacji, ponieważ inna operacja była już w toku”, musisz poczekać na zakończenie tworzenia instancji SQL i spróbować się połączyć jeszcze raz.
- Gdy pojawi się prośba, wpisz hasło roota ustawione dla instancji. Uwaga: kursor się nie porusza.
Powinny pojawić się wyniki podobne do tych:
Welcome to the MySQL monitor. Commands end with ; or \g.
Wersja serwera: 8.0.31-google (Google)
Copyright (c) 2000, 2024, Oracle lub jej podmioty stowarzyszone.
Oracle jest zastrzeżonym znakiem towarowym firmy Oracle Corporation lub jej podmiotów stowarzyszonych. Pozostałe nazwy mogą być znakami towarowymi ich właścicieli.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
Choć instancja Cloud SQL zawiera już skonfigurowane bazy danych, utworzysz własną bazę do przechowywania danych dotyczących przejazdów rowerem miejskim na terenie Londynu.
- Uruchom podane niżej polecenie w wierszu poleceń serwera MySQL, aby utworzyć bazę danych o nazwie
bike:
CREATE DATABASE bike;
Powinny pojawić się te wyniki:
Query OK, 1 row affected (0.05 sec)
mysql>
Testowanie ukończonego zadania
Kliknij Sprawdź postępy, by zobaczyć stan realizacji zadania. Jeśli udało Ci się utworzyć bazę danych w instancji Cloud SQL, wyświetli się odpowiedni wynik.
Utworzenie bazy danych
Tworzenie tabeli w Cloud Shell
- Utwórz tabelę w bazie danych „bike”, uruchamiając następujące polecenie:
USE bike;
CREATE TABLE london1 (start_station_name VARCHAR(255), num INT);
Ta instrukcja używa słowa kluczowego CREATE, ale tym razem pojawia się w niej klauzula TABLE, która określa, że utworzona ma zostać tabela, a nie baza danych. Słowo kluczowe USE wskazuje bazę danych, z którą chcesz się połączyć. Masz już tabelę o nazwie „london1” zawierającą 2 kolumny: „start_station_name” i „num”. Część VARCHAR(255) wskazuje na kolumnę z ciągiem o zmiennej długości, mogącą pomieścić do 255 znaków, a INT to kolumna przechowująca wartości całkowite.
- Utwórz nową tabelę o nazwie „london2”, uruchamiając następujące polecenie:
USE bike;
CREATE TABLE london2 (end_station_name VARCHAR(255), num INT);
- Teraz upewnij się, że puste tabele zostały utworzone. Uruchom podane niżej polecenia w wierszu poleceń serwera MySQL:
SELECT * FROM london1;
SELECT * FROM london2;
Dla obu kolumn dane wyjściowe powinny wyglądać tak:
Empty set (0.04 sec)
W wyniku widzimy „Empty set”, ponieważ dane nie zostały jeszcze wczytane.
Przesyłanie plików CSV do tabel
Wróć do konsoli Cloud SQL. Teraz prześlesz pliki CSV z danymi start_station_name i end_station_name do nowo utworzonych tabel „london1” i „london2”.
- Na stronie instancji SQL kliknij IMPORTUJ.
- W polu pliku w Cloud Storage kliknij Przeglądaj, a następnie kliknij strzałkę obok nazwy Twojego zasobnika i wybierz
start_station_data.csv. Kliknij Wybierz.
- Jako format pliku wybierz CSV.
- Wybierz bazę danych
bike, a jako tabelę wpisz london1.
- Kliknij Importuj.
Wykonaj te same czynności dla drugiego pliku CSV.
- Na stronie instancji SQL kliknij IMPORTUJ.
- W polu pliku w Cloud Storage kliknij Przeglądaj, a następnie kliknij strzałkę obok nazwy Twojego zasobnika i wybierz
end_station_data.csv. Kliknij Wybierz.
- Jako format pliku wybierz CSV.
- Wybierz bazę danych
bike, a jako tabelę wpisz london2.
- Kliknij Importuj.
Oba pliki CSV powinny być już przesłane do tabel w bazie danych bike.
- Wróć do sesji Cloud Shell i w wierszu poleceń MySQL uruchom następujące polecenie, aby zbadać zawartość tabeli „london1”:
SELECT * FROM london1;
Powinno wyświetlić się 955 wierszy danych wyjściowych, po 1 na każdą unikalną nazwę miejsca.
- Uruchom następujące polecenie, by upewnić się, że tabela „london2” zawiera dane:
SELECT * FROM london2;
Powinno wyświetlić się 959 wierszy danych wyjściowych, 1 na każdą unikalną nazwę miejsca plus 1 dodatkowy.
Słowo kluczowe DELETE
Teraz przedstawimy kilka innych słów kluczowych SQL, które pomagają w zarządzaniu danymi. Zacznijmy od DELETE.
- Uruchom podane niżej polecenie w sesji MySQL, aby usunąć pierwszy wiersz z tabel „london1” i „london2”.
DELETE FROM london1 WHERE num=0;
DELETE FROM london2 WHERE num=0;
Po uruchomieniu obu poleceń dane wyjściowe powinny wyglądać tak:
Query OK, 1 row affected (0.04 sec)
Usunięte wiersze były nagłówkami kolumn z plików CSV. Słowo kluczowe DELETE nie powoduje usunięcia pierwszego wiersza jako takiego – usunie ono wszystkie wiersze tabeli, które w danej kolumnie (w tym przypadku: „num”) mają określoną wartość (w tym przypadku: 0). Jeśli uruchomisz zapytania SELECT * FROM london1; i SELECT * FROM london2;, a następnie przewiniesz tabelę do góry, zobaczysz, że te wiersze już nie istnieją.
Słowo kluczowe INSERT INTO
Słowo kluczowe INSERT INTO pozwala na wstawianie wartości do tabel.
- Uruchom podane niżej polecenie, aby wstawić do tabeli „london1” nowy wiersz z wartością „test destination” („testowy cel podróży”) w kolumnie
start_station_name i wartością 1 w kolumnie num:
INSERT INTO london1 (start_station_name, num) VALUES ("test destination", 1);
Słowo kluczowe INSERT INTO wymaga tabeli („london1”) – utworzy ono nowy wiersz z wartościami dla kolumn wskazanych w pierwszym nawiasie (w tym przypadku „start_station_name” i „num”). Wszystko, co zostanie wpisane po klauzuli VALUES, zostanie wstawione jako wartości w nowym wierszu.
Powinny pojawić się te wyniki:
Query OK, 1 row affected (0.05 sec)
Jeśli uruchomisz zapytanie SELECT * FROM london1;, zobaczysz dodatkowy wiersz dodany u dołu tabeli „london1”.
Słowo kluczowe UNION
Ostatnim słowem kluczowym, którego się dziś nauczysz, jest UNION. Łączy ono dane wyjściowe z co najmniej 2 zapytań SELECT w zestaw wyników. Użyjesz słowa kluczowego UNION do połączenia podzbiorów tabel „london1” i „london2”.
Przedstawione niżej połączone zapytanie pobierze określone dane z obu tabel i połączy je przy użyciu operatora UNION.
- Uruchom to polecenie w wierszu poleceń serwera MySQL:
SELECT start_station_name AS top_stations, num FROM london1 WHERE num>100000
UNION
SELECT end_station_name, num FROM london2 WHERE num>100000
ORDER BY top_stations DESC;
Pierwsze zapytanie SELECT wybiera 2 kolumny z tabeli „london1” i tworzy alias kolumny „start_station_name”, która zostaje ustawiona jako „top_stations”. Używa też słowa kluczowego WHERE do pobrania nazw wyłącznie tych miejsc, z których rozpoczęło się ponad 100 tys. przejazdów rowerami miejskimi.
Drugie zapytanie SELECT wybiera 2 kolumny z tabeli „london2” i używa słowa kluczowego WHERE do pobrania nazw wyłącznie tych miejsc, w których zakończyło się ponad 100 tys. przejazdów rowerami miejskimi.
Umieszczone pomiędzy zapytaniami słowo kluczowe UNION łączy wyniki tych zapytań poprzez zgrupowanie danych z tabel „london2” i „london1”. Ponieważ nastąpiło połączenie „london1” z „london2”, wyodrębnione kolumny to „top_stations” i „num”.
Słowo kluczowe ORDER BY uporządkuje ostateczną, połączoną tabelę alfabetycznie według wartości w kolumnie „top_stations” w kolejności malejącej.
Przykładowe dane wyjściowe (Twoje wyniki mogą się różnić) :
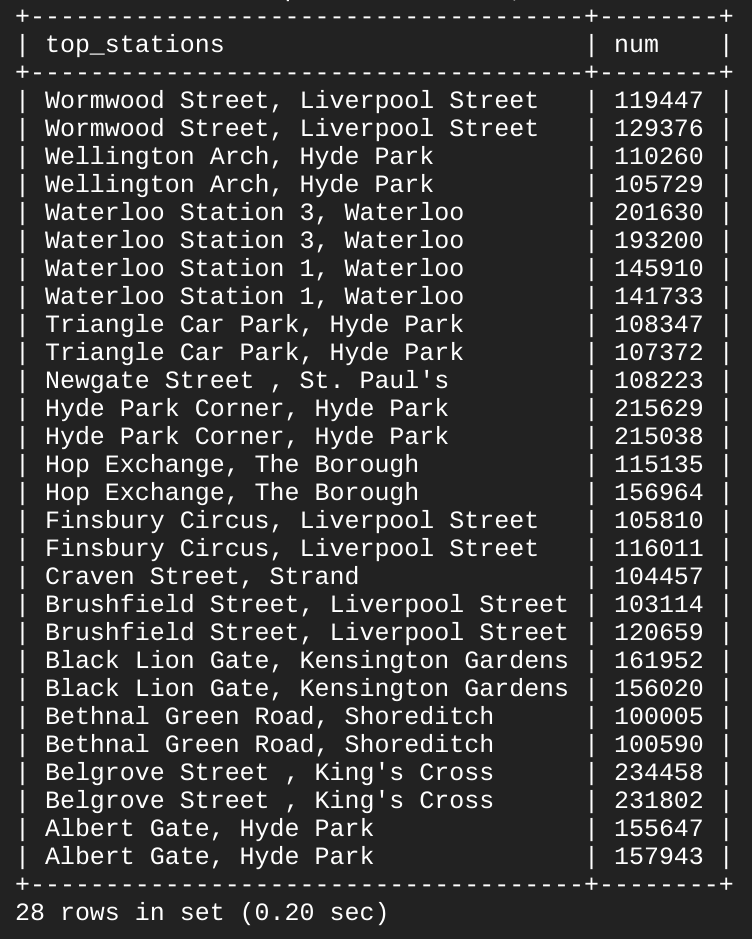
Jak widzisz, 13 z 14 stacji to najpopularniejsze miejsca zarówno pod względem rozpoczęcia, jak i zakończenia przejazdów. Dzięki kilku podstawowym słowom kluczowym SQL udało Ci się utworzyć zapytanie do sporego zbioru danych, które zwróciło punkty danych i odpowiedzi na określone pytania.
Gratulacje!
W tym module nauczyliśmy się podstaw SQL oraz tego, jak stosować słowa kluczowe i uruchamiać zapytania w BigQuery i CloudSQL. Poznaliśmy podstawowe zagadnienia dotyczące projektów, baz danych i tabel. Wykorzystaliśmy w praktyce słowa kluczowe, które umożliwiają edytowanie danych i wykonywanie na nich operacji. Wiesz już, jak wczytywać dane do BigQuery oraz jak uruchamiać zapytania do tabel w praktyce. Dowiedzieliśmy się, jak utworzyć instancje w Cloud SQL, i przenieśliśmy podzbiory danych do tabel znajdujących się w bazach danych. Połączyliśmy i uruchomiliśmy zapytania w Cloud SQL, aby dojść do interesujących wniosków dotyczących miejsc w Londynie, w których rozpoczęto i zakończono przejazdy rowerami miejskimi.
Kolejne kroki / Więcej informacji
Kontynuuj naukę i ćwiczenie korzystania z Cloud SQL i BigQuery w tych modułach Google Cloud Skill Boost:
Więcej informacji o badaniu danych znajdziesz w publikacji Data Science on the Google Cloud Platform, 2nd Edition: O'Reilly Media, Inc.
Szkolenia i certyfikaty Google Cloud
…pomogą Ci wykorzystać wszystkie możliwości technologii Google Cloud. Nasze zajęcia obejmują umiejętności techniczne oraz sprawdzone metody, które ułatwią Ci szybką naukę i umożliwią jej kontynuację. Oferujemy szkolenia na poziomach od podstawowego po zaawansowany prowadzone w trybach wirtualnym, na żądanie i na żywo, dzięki czemu możesz dopasować program szkoleń do swojego napiętego harmonogramu. Certyfikaty umożliwią udokumentowanie i potwierdzenie Twoich umiejętności oraz doświadczenia w zakresie technologii Google Cloud.
Ostatnia aktualizacja instrukcji: 11 października 2024 r.
Ostatni test modułu: 11 października 2024 r.
Copyright 2025 Google LLC. Wszelkie prawa zastrzeżone. Google i logo Google są znakami towarowymi Google LLC. Wszelkie inne nazwy firm i produktów mogą być znakami towarowymi odpowiednich podmiotów, z którymi są powiązane.





