

시작하기 전에
- 실습에서는 정해진 기간 동안 Google Cloud 프로젝트와 리소스를 만듭니다.
- 실습에는 시간 제한이 있으며 일시중지 기능이 없습니다. 실습을 종료하면 처음부터 다시 시작해야 합니다.
- 화면 왼쪽 상단에서 실습 시작을 클릭하여 시작합니다.
Create a cloud storage bucket
/ 25
Upload CSV files to Cloud Storage
/ 25
Create a Cloud SQL instance
/ 25
Create a database
/ 25
SQL(구조적 쿼리 언어)은 질문을 통해 구조화된 데이터 세트로부터 유용한 정보를 얻을 수 있는 데이터 작업용 표준 언어입니다. SQL은 일반적으로 데이터베이스 관리에 사용되며 관계형 데이터베이스에 트랜잭션 레코드 작성, 페타바이트급의 데이터 분석과 같은 작업을 수행할 수 있습니다.
실습은 두 부분으로 나뉘어져 있습니다. 전반부에서는 기본 SQL 쿼리 키워드를 학습합니다. 이 키워드는 BigQuery에서 런던의 자전거 공유 관련 공개 데이터 세트에 대해 실행됩니다.
후반부에서는 런던 자전거 공유 데이터 세트의 하위 집합을 CSV 파일로 내보내 Cloud SQL에 업로드하는 방법을 알아봅니다. 여기에서 Cloud SQL을 사용하여 데이터베이스와 테이블을 만들고 관리하는 방법을 학습합니다. 마지막으로 데이터를 가공하고 편집하는 추가 SQL 키워드를 사용하는 실무형 실습을 진행합니다.
이 실습에서 학습할 작업 수행 방법은 다음과 같습니다.
매우 중요: 이 실습을 시작하려면 먼저 개인 또는 회사 Gmail 계정에서 로그아웃합니다.
이 실습은 입문용이며, SQL 사용 경험이 거의 없거나 전혀 없는 사람을 대상으로 합니다. Cloud Storage 및 Cloud Shell에 익숙하면 좋지만 필수사항은 아닙니다. 이 실습에서는 BigQuery 및 Cloud SQL을 사용하여 SQL로 쿼리를 읽고 쓰는 기초적인 내용을 학습합니다.
실습을 시작하기 전에 자신의 SQL 숙련도를 고려하세요. 다음은 고급 사용 사례에 지식을 적용할 수 있는 좀 더 난이도 높은 실습입니다.
준비가 됐으면 아래로 스크롤하여 아래 단계에 따라 실습 환경을 설정합니다.
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지를 표시합니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
실습 시작 버튼을 클릭합니다. 실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 대화상자가 열립니다. 왼쪽에는 다음과 같은 항목이 포함된 실습 세부정보 창이 있습니다.
Google Cloud 콘솔 열기를 클릭합니다(Chrome 브라우저를 실행 중인 경우 마우스 오른쪽 버튼으로 클릭하고 시크릿 창에서 링크 열기를 선택합니다).
실습에서 리소스가 가동되면 다른 탭이 열리고 로그인 페이지가 표시됩니다.
팁: 두 개의 탭을 각각 별도의 창으로 나란히 정렬하세요.
필요한 경우 아래의 사용자 이름을 복사하여 로그인 대화상자에 붙여넣습니다.
실습 세부정보 창에서도 사용자 이름을 확인할 수 있습니다.
다음을 클릭합니다.
아래의 비밀번호를 복사하여 시작하기 대화상자에 붙여넣습니다.
실습 세부정보 창에서도 비밀번호를 확인할 수 있습니다.
다음을 클릭합니다.
이후에 표시되는 페이지를 클릭하여 넘깁니다.
잠시 후 Google Cloud 콘솔이 이 탭에서 열립니다.

앞에서 언급했듯이 SQL을 사용하면 구조화된 '정형 데이터 세트'에서 정보를 얻을 수 있습니다. 정형 데이터 세트에는 명확한 규칙과 형식이 있으며 종종 테이블이나 행과 열로 이루어진 데이터로 구성됩니다.
비정형 데이터의 예로는 이미지 파일이 있습니다. 비정형 데이터는 SQL과 호환되지 않으므로 기본적으로 BigQuery 데이터 세트 또는 테이블에 저장할 수 없습니다. 예를 들어 이미지 데이터로 작업하려면 API를 통해 Cloud Vision과 같은 서비스를 직접 사용할 수 있습니다.
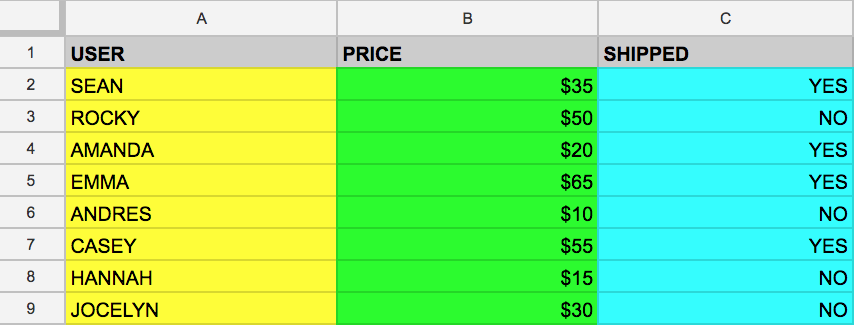
다음은 정형 데이터 세트인 간단한 테이블의 예입니다.
|
사용자(User) |
가격(Price) |
배송(Shipped) |
|
션 |
35달러 |
예 |
|
로키 |
50달러 |
아니요 |
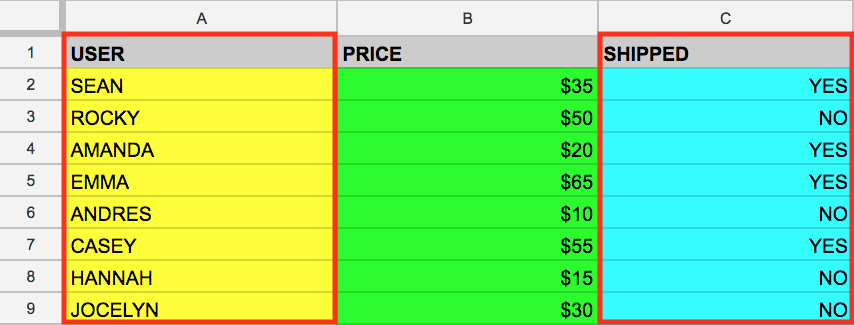
Google Sheets 사용 경험이 있다면 위의 형식이 익숙할 것입니다. 테이블에는 사용자(User), 가격(Price), 배송 여부(Shipped) 열과 열 값이 채워진 두 개의 행이 있습니다.
기본적으로 데이터베이스는 하나 이상의 테이블 모음입니다. SQL은 정형화된 데이터베이스 관리 도구이지만 전체 데이터베이스가 아닌 하나 또는 몇 개의 테이블을 함께 조인하여 쿼리를 실행하는 경우가 많습니다. 본 실습도 그렇게 진행됩니다.
SQL은 기본적으로 표음식이며 재미삼아 탐색하려는 게 아닌 이상 쿼리를 실행하기 전에 항상 데이터에서 알아내고자 하는 것이 무엇인지 정의하는 것이 좋습니다.
SQL에는 질문을 유사 영어 SQL 구문으로 변환하는 데 사용하는 키워드가 미리 정의되어 있어 데이터베이스 엔진에서 원하는 대답을 반환하도록 할 수 있습니다.
가장 핵심적인 키워드는 SELECT 및 FROM입니다.
SELECT를 사용하여 데이터 세트에서 가져오려는 필드를 지정합니다.FROM을 사용하여 데이터를 가져올 테이블을 지정합니다.이해를 돕기 위해 예를 들어 보겠습니다. 다음과 같이 사용자(User), 가격(Price), 배송 여부(Shipped) 열이 있는 example_table 테이블이 있다고 해 봅시다.
여기서 사용자(User) 열에 있는 데이터를 가져오려고 합니다. 이 작업은 SELECT 및 FROM을 사용하는 다음 쿼리를 실행하여 수행할 수 있습니다.
위의 명령어를 실행하면 example_table에 있는 USER 열의 모든 이름이 선택됩니다.
SQL SELECT 키워드를 사용하여 여러 열을 선택할 수도 있습니다. USER 및 SHIPPED 열에 있는 데이터를 가져오려고 합니다. 이 작업을 수행하려면 SELECT 쿼리에 열 값을 추가하여 이전 쿼리를 수정합니다(쉼표로 구분).
위 명령어를 실행하면 메모리에서 USER 및 SHIPPED 데이터가 검색됩니다.
지금까지 두 가지 기본 SQL 키워드를 알아보았습니다. 이제 한층 수준을 높여 보겠습니다.
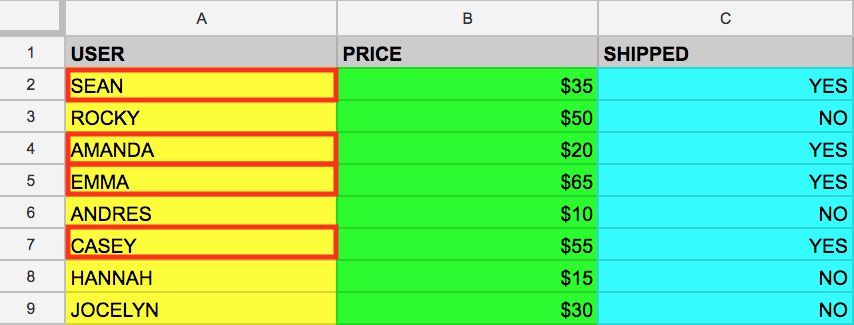
WHERE 키워드는 특정 열 값에 대해 테이블을 필터링하는 또 다른 SQL 명령어입니다. example_table에서 물건이 배송된 사용자의 이름을 가져올 필요가 있다고 가정해 보겠습니다. 다음과 같이 WHERE로 쿼리를 보완할 수 있습니다.
위의 명령어를 실행하면 물건이 배송된 모든 사용자 데이터가 메모리에서 반환됩니다.
이제 SQL 핵심 키워드에 대한 기본 지식을 익혔으므로, BigQuery 콘솔에서 이러한 유형의 쿼리를 실행하여 학습한 내용을 적용해 보세요.
다음은 지금까지 살펴본 개념에 대한 이해를 돕기 위한 객관식 질문입니다. 최선을 다해 풀어보세요.
BigQuery는 Google Cloud에서 실행되는 페타바이트 규모의 완전 관리형 데이터 웨어하우스입니다. 데이터 분석가와 데이터 과학자는 서버 설정 및 관리에 대해 걱정할 필요 없이 대규모 데이터 세트를 신속하게 쿼리 및 필터링하고, 결과를 집계하고, 복잡한 작업을 수행할 수 있습니다. BigQuery는 명령줄 도구(Cloud Shell에 사전 설치됨) 또는 웹 콘솔의 형태로 제공되며 이를 통해 Google Cloud 프로젝트에 저장된 데이터를 관리하고 쿼리할 수 있습니다.
이 실습에서는 웹 콘솔을 사용하여 SQL 쿼리를 실행합니다.
Cloud 콘솔의 BigQuery에 오신 것을 환영합니다라는 메시지 상자가 열립니다. 이 메시지 상자에서는 빠른 시작 가이드 및 출시 노트로 연결되는 링크가 제공됩니다.
BigQuery 콘솔이 열립니다.
UI의 몇 가지 중요한 기능을 먼저 살펴보겠습니다. 콘솔의 오른쪽에는 쿼리 '편집기'가 있습니다. 여기에서 앞의 예시처럼 SQL 명령어를 작성하고 실행할 수 있습니다. 아래에는 이전에 실행한 쿼리 목록인 '쿼리 기록'이 있습니다.
콘솔의 왼쪽 창은 탐색 메뉴입니다. 여기에는 직관적인 쿼리 기록, 저장된 쿼리 및 작업 기록 외에도 탐색기 탭이 있습니다.
탐색기 탭에 있는 가장 높은 수준의 리소스에는 Google Cloud 프로젝트가 포함되어 있으며, 이는 사용자가 각 Google Cloud Skills Boost 실습에 로그인하여 사용하는 임시 Google Cloud 프로젝트와 같습니다. 콘솔과 마지막 스크린샷에서 볼 수 있듯이, 프로젝트는 탐색기 탭에만 저장되어 있습니다. 프로젝트 이름 옆에 있는 화살표를 클릭하면 아무것도 나타나지 않습니다.
이는 프로젝트에 데이터 세트나 테이블이 없어서 쿼리할 수 있는 항목이 없기 때문입니다. 앞에서 데이터 세트에 테이블이 있다는 것을 배웠습니다. 프로젝트에 데이터를 추가할 때 BigQuery에서는 프로젝트에 데이터 세트가 포함되고 데이터 세트에는 테이블이 포함됩니다. 프로젝트 > 데이터 세트 > 테이블로 이어지는 패러다임과 콘솔과 관련해 자세한 정보를 알아봤으니 이제 쿼리 가능한 데이터를 로드해 봅시다.
이 섹션에서는 프로젝트에 일부 공개 데이터를 가져와 BigQuery에서 SQL 명령어를 실행하는 것을 연습합니다.
+ 추가를 클릭합니다.
이름으로 프로젝트에 별표표시를 선택합니다.
프로젝트 이름으로 bigquery-public-data를 입력합니다.
별표를 클릭합니다.
이 새 탭에서도 실습 프로젝트를 작업하고 있다는 점에 유의해야 합니다. 방금 수행한 작업은 분석을 위해 BigQuery에 데이터 세트 및 테이블이 포함된 공개 프로젝트를 가져온 것이지 해당 프로젝트로 전환한 것은 아닙니다. 모든 작업과 서비스는 여전히 Google Cloud Skills Boost 계정을 통해 수행 중입니다. 콘솔 상단 근처의 프로젝트 필드에서 이를 직접 확인할 수 있습니다.
bigquery-public-data
london_bicycles
cycle_hire
cycle_stations
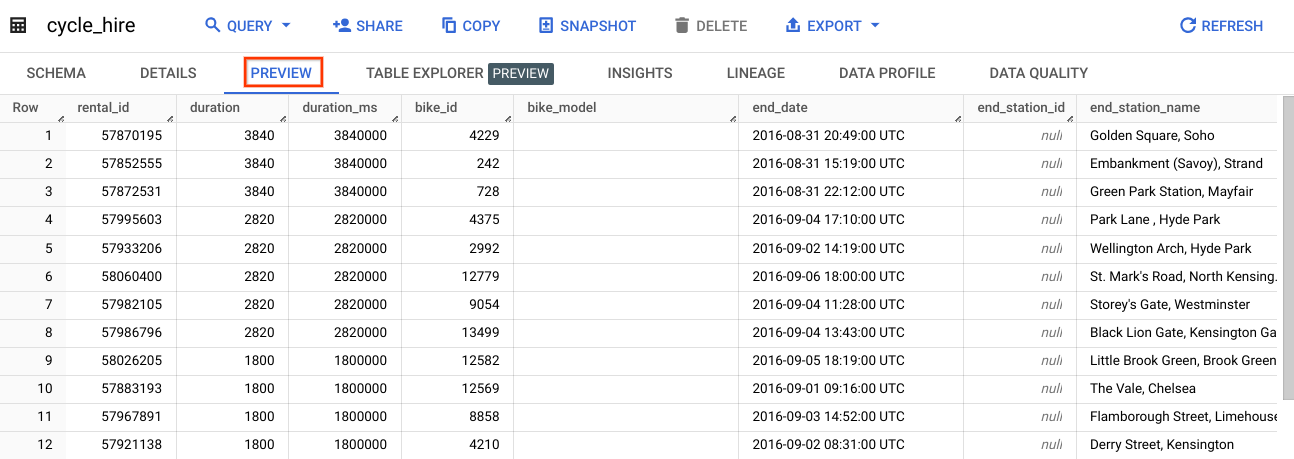
이 실습에서는 cycle_hire에서 가져온 데이터를 사용합니다. cycle_hire 테이블을 연 후 프리뷰 탭을 클릭합니다. 페이지가 다음과 비슷하게 표시됩니다.
행에 채워진 열과 값을 검사합니다. 이제 cycle_hire 테이블에서 SQL 쿼리를 실행할 준비가 되었습니다.
지금까지 SQL 쿼리 키워드와 BigQuery 데이터 패러다임 및 작업할 데이터에 대한 기본적인 사항을 알아보았습니다. 이 서비스를 사용하여 SQL 명령어를 몇 개 실행해 봅니다.
콘솔의 오른쪽 하단에서 무려 83,434,866개 행의 데이터, 즉 2015년에서 2017년 사이 런던에서 발생한 자전거 공유 주행 건수가 존재함을 확인할 수 있습니다.
아홉 번째 열 키인 end_station_name을 기록해 두세요. 이 키는 자전거 공유 주행의 최종 목적지를 명시합니다. 깊이 들어가기 전에 end_station_name 열을 격리하는 간단한 쿼리를 실행해 보겠습니다.
약 20초 후 쿼리로 요청한 단일 열 end_station_name이 있는 83,434,866개 행이 반환될 겁니다.
20분 이상 걸린 자전거 주행 건수를 알아볼까요?
WHERE 키워드를 사용하는 다음 쿼리를 실행합니다.이 쿼리는 실행하는 데 1분 정도 소요될 수 있습니다.
SELECT *는 테이블의 모든 열 값을 반환합니다. 지속 시간은 초 단위로 측정되므로 1200(60 * 20) 값을 사용했습니다.
오른쪽 하단에서 26,441,016개의 행이 반환된 것을 볼 수 있습니다. 전체 건수 83,434,866개와 비교했을 때 26,441,016개는 런던 자전거 공유 주행 건수 중 20분 이상 지속된 건수(장거리 주행 포함)가 약 30%라는 것을 의미합니다.
다음은 지금까지 살펴본 개념에 대한 이해를 돕기 위한 객관식 질문입니다. 최선을 다해 풀어보세요.
GROUP BY 키워드는 공통 기준(예: 열 값)을 공유하는 결과 집합 행을 집계하며 이러한 기준에 대해 찾은 모든 고유 항목을 반환합니다.
이 키워드는 테이블에서 카테고리 정보를 찾는 데 유용합니다.
고유한(중복되지 않는) 열 값의 목록이 결과로 반환됩니다.
GROUP BY가 없었으면 쿼리가 83,434,866개의 행 전체를 반환했을 것입니다. GROUP BY는 테이블에 있는 고유한 열 값을 출력합니다. 오른쪽 하단에서 이를 직접 확인할 수 있습니다. 954개의 행이 표시됩니다. 즉, 954개의 고유한 런던 자전거 공유 출발지가 있습니다.
COUNT() 함수는 동일한 기준(예: 열 값)을 공유하는 행 수를 반환합니다. 이 함수를 GROUP BY와 함께 사용할 경우 매우 유용할 수 있습니다.
이전 쿼리에 COUNT 함수를 추가하여 각 출발지에서 출발한 주행 건수를 파악합니다.
출력을 통해 각 출발지에서 출발한 자전거 공유 주행 건수를 알 수 있습니다.
SQL에는 테이블 또는 열의 별칭을 생성하는 AS 키워드도 있습니다. 별칭은 반환된 열이나 테이블에 AS가 지정하는 대로 부여되는 새 이름입니다.
AS 키워드를 추가하여 실제로 작동하는지 보겠습니다. 편집기에서 쿼리를 지운 후 다음 명령어를 복사하여 붙여넣습니다.결과에서 오른쪽 열 이름이 COUNT(*)에서 num_starts로 변경되었습니다.
이제 반환된 테이블의 COUNT(*) 열에 별칭 이름 num_starts가 설정된 것을 볼 수 있습니다. 이 키워드는 대규모 데이터 세트를 다루는 경우에 특히 유용합니다. 모호하게 지정된 테이블이나 열 이름이 무엇을 지칭하는지 알기는 쉽지 않습니다.
ORDER BY 키워드는 쿼리에서 반환된 데이터를 지정된 조건 또는 열 값에 따라 오름차순 또는 내림차순으로 정렬합니다. 이전 쿼리에 이 키워드를 추가하여 다음 작업을 수행해 보겠습니다.
아래의 각 명령어는 별도의 쿼리입니다. 각 명령어에서 다음과 같이 수행합니다.
마지막 쿼리의 결과는 발생한 출발 수를 기준으로 출발 위치를 나열합니다.
여기서 'Hyde Park Corner, Hyde Park' 정거장에서 출발한 수가 가장 많음을 알 수 있습니다. 그러나 전체 주행 건수 83,434,866개와 비교했을 때 671,688개는 이 정거장에서 출발하는 주행 건수의 1% 미만임을 알 수 있습니다.
다음은 지금까지 살펴본 개념에 대한 이해를 돕기 위한 객관식 질문입니다. 최선을 다해 풀어보세요.
Cloud SQL은 클라우드에서 관계형 PostgreSQL과 MySQL 데이터베이스를 손쉽게 설정, 유지 및 관리할 수 있는 완전 관리형 데이터베이스 서비스입니다. Cloud SQL에서 허용하는 데이터 형식에는 덤프 파일(.sql) 또는 CSV 파일(.csv) 두 가지가 있습니다. cycle_hire 테이블의 하위 집합을 CSV 파일로 내보낸 다음 중간 위치인 Cloud Storage에 업로드하는 방법을 알아봅니다.
BigQuery 콘솔로 돌아가면 마지막으로 실행한 명령어가 표시됩니다.
쿼리 결과 섹션에서 결과 저장 > CSV(로컬 파일)를 클릭합니다. 이렇게 하면 쿼리가 다운로드되어 CSV 파일로 저장됩니다. 다운로드한 파일의 위치와 이름은 나중에 필요하므로 적어둡니다.
쿼리 편집기에서 쿼리를 지운 후 다음을 복사하여 쿼리 편집기에서 실행합니다.
이 쿼리를 실행하면 각 도착 정거장에서 끝난 자전거 공유 주행 건수가 포함된 테이블(가장 많은 탑승 횟수부터 가장 적은 횟수로 내림차순)이 반환됩니다.
Cloud 콘솔로 이동하여 방금 만든 파일을 업로드할 수 있는 스토리지 버킷을 만듭니다.
탐색 메뉴 > Cloud Storage > 버킷을 선택한 후 버킷 만들기를 클릭합니다.
버킷의 고유한 이름을 입력하고 다른 모든 설정을 기본값으로 유지한 채 만들기를 클릭합니다.
메시지가 표시되고 공개 액세스가 차단됨 대화상자가 표시되면 확인을 클릭합니다.
아래 진행 상황 확인을 클릭하여 실습 진행 상황을 확인하세요. 버킷이 만들어지면 평가 점수가 표시됩니다.
이제 Cloud 콘솔에서 새로 만든 Cloud Storage 버킷이 표시됩니다.
업로드 > 파일 업로드를 클릭하고 start_station_name 데이터가 포함된 CSV를 선택합니다.
그런 다음 열기를 클릭합니다. end_station_name 데이터에 대해 이 작업을 반복합니다.
start_station_name 파일 맨 끝 옆에 있는 세 개의 점을 클릭하고 이름 바꾸기를 클릭하여 이름을 변경합니다. start_station_data.csv로 파일 이름을 바꿉니다.
end_station_name 파일 맨 끝 옆에 있는 세 개의 점을 클릭하고 이름 바꾸기를 클릭하여 이름을 변경합니다. end_station_data.csv로 파일 이름을 바꿉니다.
이제 버킷 세부정보 페이지의 객체 목록에 start_station_data.csv 및 end_station_data.csv가 표시됩니다.
진행 상황 확인을 클릭하여 실행한 작업을 확인합니다. 버킷에 CSV 객체가 업로드되면 평가 점수가 표시됩니다.
콘솔에서 탐색 메뉴 > SQL을 선택합니다.
인스턴스 만들기 > MySQL 선택을 클릭합니다.
인스턴스 ID로 my-demo를 입력합니다.
비밀번호 필드에 안전한 비밀번호를 입력합니다(비밀번호는 잊지 말고 기억해 두세요).
데이터베이스 버전으로 MySQL 8을 선택합니다.
Cloud SQL 버전 선택에서 Enterprise를 선택합니다.
버전 사전 설정에서 개발(vCPU 4개, RAM 16GB, 저장용량 100GB, 단일 영역)을 선택합니다.
리전 필드를
멀티 영역(고가용성) > 기본 영역 필드를
인스턴스 만들기를 클릭합니다.
실습 진행 상황을 확인하려면 아래에서 진행 상황 확인을 클릭합니다. Cloud SQL 인스턴스를 성공적으로 설정하면 평가 점수가 표시됩니다.
이제 Cloud SQL 인스턴스를 가동했으므로 Cloud Shell 명령줄을 사용하여 인스턴스 내에 데이터베이스를 만듭니다.
콘솔 오른쪽 상단에 있는 아이콘을 클릭하여 Cloud Shell을 엽니다.
다음 명령어를 실행하여 프로젝트 ID를 환경 변수로 설정합니다.
[Y/n]이 표시되면 Y를 누른 다음 Enter 키를 누릅니다.
그러면 브라우저에서 링크를 열 수 있습니다. Qwiklabs 계정에 로그인한 것과 동일한 브라우저에서 링크를 엽니다. 로그인하면 복사할 인증 코드를 받게 됩니다. Cloud Shell에 해당 코드를 붙여넣습니다.
my-demo 부분을 바꿔 사용합니다.다음과 비슷한 출력이 표시됩니다.
Cloud SQL 인스턴스에는 미리 구성된 데이터베이스가 제공되지만 런던 자전거 공유 데이터를 저장할 데이터베이스를 직접 만들어 봅니다.
bike라는 데이터베이스를 만듭니다.다음과 같은 출력이 표시됩니다.
진행 상황 확인을 클릭하여 진행 상황을 확인하고 수행한 작업을 확인합니다. Cloud SQL 인스턴스에 데이터베이스가 정상적으로 생성되면 평가 점수가 표시됩니다.
이 명령문은 CREATE 키워드를 사용하지만, 이번에는 TABLE 절을 사용하여 데이터베이스 대신 테이블을 만들도록 지정합니다. USE 키워드는 연결할 데이터베이스를 지정합니다. 이제 'start_station_name'과 'num'의 두 열을 포함하는 'london1'이라는 테이블이 만들어졌습니다. VARCHAR(255)는 255자까지 저장할 수 있는 가변 길이 문자열 열을 지정하며 INT는 정수 유형의 열입니다.
두 명령어 모두에 대해 다음과 같은 결과가 표시되어야 합니다.
아직 데이터를 로드하지 않았기 때문에 'empty set'이 표시됩니다.
Cloud SQL 콘솔로 돌아갑니다. 이제 새로 만든 london1 및 london2 테이블에 start_station_name 및 end_station_name CSV 파일을 업로드합니다.
start_station_data.csv를 클릭합니다. 선택을 클릭합니다.bike 데이터베이스를 선택하고 테이블로 london1을 입력합니다.다른 CSV 파일에 대해서도 동일한 작업을 수행합니다.
end_station_data.csv를 클릭합니다. 선택을 클릭합니다.bike 데이터베이스를 선택하고 테이블로 london2를 입력합니다.이제 두 개의 CSV 파일을 bike 데이터베이스의 테이블에 업로드해야 합니다.
고유한 정거장마다 1개씩 총 955줄의 출력이 표시됩니다.
고유한 정거장마다 1개씩 더해 총 959줄의 출력이 표시됩니다.
다음은 데이터 관리에 도움이 되는 몇 가지 SQL 키워드입니다. 첫 번째는 DELETE 키워드입니다.
두 명령어 모두 실행 후 다음과 같은 출력이 표시되어야 합니다.
삭제된 행은 CSV 파일의 열 헤더입니다. DELETE 키워드는 엄밀히 말하자면 파일의 첫 번째 행을 삭제하지 않고 열 이름(이 경우 'num')에 지정된 값(이 경우 '0')이 들어 있는 테이블의 모든 행을 삭제합니다. SELECT * FROM london1; 및 SELECT * FROM london2; 쿼리를 실행하고 테이블 맨 위로 스크롤하면 이러한 행이 더 이상 존재하지 않음을 알 수 있습니다.
INSERT INTO 키워드를 사용하여 테이블에 값을 삽입할 수도 있습니다.
start_station_name을 'test destination'으로, num을 '1'로 설정하는 새 행을 삽입합니다.INSERT INTO 키워드에는 테이블(london1)이 필요하며 첫 번째 괄호(이 경우 'start_station_name' 및 'num')의 용어로 지정된 열이 있는 새 행을 만듭니다. 'VALUES' 절 뒤에 오는 항목이 새로운 행의 값으로 삽입됩니다.
다음과 같은 출력이 표시됩니다.
쿼리 SELECT * FROM london1;을 실행하면 'london1' 테이블 하단에 행이 추가됩니다.
마지막으로 학습할 SQL 키워드는 UNION입니다. 이 키워드는 두 개 이상의 SELECT 쿼리의 출력을 결과 집합으로 결합합니다. UNION을 사용하여 'london1' 및 'london2' 테이블의 하위 집합을 결합해 보겠습니다.
다음 체인 쿼리는 두 테이블에서 특정 데이터를 가져와 UNION 연산자를 사용하여 결합합니다.
첫 번째 SELECT 쿼리는 'london1' 테이블에서 두 개의 열을 선택하고 'start_station_name'에 대한 별칭을 만듭니다. 이 별칭은 'top_stations'로 설정됩니다. WHERE 키워드를 사용하여 주행을 시작한 자전거 수가 100,000대가 넘는 자전거 공유 정거장 이름만 가져옵니다.
두 번째 SELECT 쿼리는 'london2' 테이블에서 두 개의 열을 선택하고 WHERE 키워드를 사용하여 주행을 끝낸 자전거 수가 100,000대가 넘는 자전거 공유 정거장 이름만 가져옵니다.
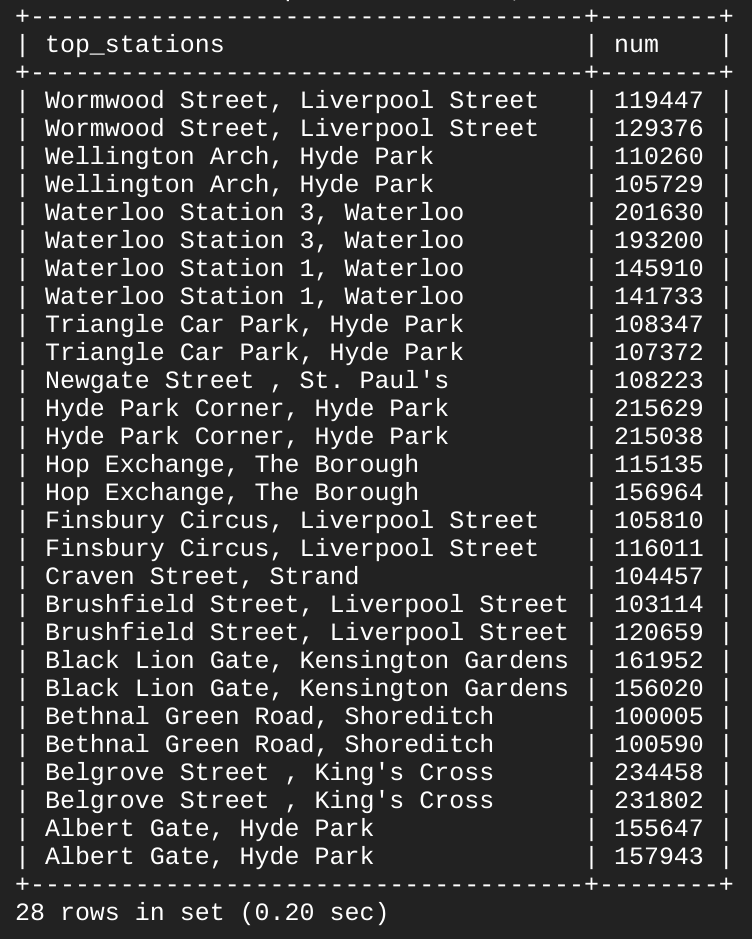
UNION 키워드를 사용하면 'london1' 데이터와 'london2' 데이터를 융합하여 이러한 쿼리의 출력을 결합합니다. 'london1'은 'london2'와 통합되므로 열 값 'top_stations' 및 'num'이 앞에 옵니다.
ORDER BY는 결합된 최종 테이블을 'top_stations' 열 값에 따라 알파벳 순서와 내림차순으로 정렬합니다.
출력 예시(결과에 차이가 있을 수 있음):
여기에서 13/14 정거장은 자전거 공유 출발지와 도착지 모두에서 최상위 지점임을 알 수 있습니다. 몇 가지 기본 SQL 키워드를 통해 상당한 규모의 데이터 세트를 쿼리하여 데이터 포인트를 반환하고 특정 정보를 알아낼 수 있었습니다.
이 실습에서는 SQL의 기초와 BigQuery 및 CloudSQL에서 키워드를 적용하고 쿼리를 실행하는 방법을 학습하고 프로젝트, 데이터베이스 및 테이블의 핵심 개념을 배웠습니다. 또한 키워드를 사용하여 데이터를 가공하고 편집하는 방법과 BigQuery로 데이터를 읽어오는 방법을 알아보고 테이블에서 쿼리를 실행하는 연습을 했습니다. Cloud SQL에서 인스턴스를 만들고 데이터베이스에 포함된 테이블로 데이터의 하위 집합을 전달하는 방법도 배웠습니다. Cloud SQL에서 쿼리를 체인화하고 실행하여 런던 자전거 공유 출발 및 도착 정거장에 대한 흥미로운 결과도 확인해 보았습니다.
다음 Google Cloud Skill Boost 실습을 통해 계속해서 Cloud SQL 및 BigQuery를 학습하고 연습하세요.
Data Science on the Google Cloud Platform(구글 클라우드 플랫폼상의 데이터 과학, 제2판: O'Reilly Media, Inc.)에서 데이터 과학에 대해 자세히 알아보세요.
Google Cloud 기술을 최대한 활용하는 데 도움이 됩니다. Google 강의에는 빠른 습득과 지속적인 학습을 지원하는 기술적인 지식과 권장사항이 포함되어 있습니다. 기초에서 고급까지 수준별 학습을 제공하며 바쁜 일정에 알맞은 주문형, 실시간, 가상 옵션이 포함되어 있습니다. 인증은 Google Cloud 기술에 대한 역량과 전문성을 검증하고 입증하는 데 도움이 됩니다.
설명서 최종 업데이트: 2024년 10월 16일
실습 최종 테스트: 2024년 10월 16일
Copyright 2025 Google LLC. All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.



현재 이 콘텐츠를 이용할 수 없습니다
이용할 수 있게 되면 이메일로 알려드리겠습니다.

감사합니다
이용할 수 있게 되면 이메일로 알려드리겠습니다.

한 번에 실습 1개만 가능
모든 기존 실습을 종료하고 이 실습을 시작할지 확인하세요.