GSP281

Descripción general
SQL (Structured Query Language) es un lenguaje estándar para operaciones de datos que permite hacer preguntas y obtener estadísticas a partir de conjuntos de datos estructurados. Es de uso general en la administración de bases de datos y te permite realizar tareas como escribir registros de transacciones en bases de datos relacionales y analizar datos a escala de petabytes.
Este lab está dividido en dos partes. En la primera, aprenderás palabras clave esenciales para formular consultas en SQL, las cuales ejecutarás en BigQuery con un conjunto de datos públicos que contiene información sobre los sistemas de bicicletas compartidas de Londres.
En la segunda parte, aprenderás a exportar subconjuntos del conjunto de datos de los sistemas de bicicletas compartidas de Londres a archivos CSV, que posteriormente subirás a Cloud SQL. Luego, aprenderás a usar Cloud SQL para crear y administrar tablas y bases de datos. Al final, adquirirás práctica con palabras clave de SQL adicionales que permiten manipular y editar datos.
Qué aprenderás
En este lab, aprenderás a hacer lo siguiente:
- Leer datos en BigQuery
- Ejecutar consultas sencillas en BigQuery para explorar datos
- Exportar un subconjunto de datos a un archivo CSV y almacenarlo en un bucket nuevo de Cloud Storage
- Crear una instancia de Cloud SQL nueva y cargar tu archivo CSV exportado como una tabla nueva
Requisitos previos
Muy importante: Antes de comenzar este lab, sal de tu cuenta de Gmail personal o corporativa.
Este es un lab de nivel introductorio. Parte de la suposición de que el alumno tiene escasa o nula experiencia en el uso de SQL. Se recomienda tener conocimientos de Cloud Storage y Cloud Shell, pero no es obligatorio. En este lab, aprenderás los conceptos básicos de leer y escribir consultas en SQL, y los aplicarás para usar BigQuery y Cloud SQL.
Antes de realizar este lab, considera tu nivel de competencia en SQL. Aquí tienes labs más desafiantes que te permitirán aplicar tus conocimientos a casos de uso más avanzados:
Cuando tengas todo listo, desplázate hacia abajo y sigue los pasos que se muestran a continuación para configurar el entorno de tu lab.
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs cuentan con un temporizador que no se puede pausar. El temporizador, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar. Se recomienda el navegador Chrome.
Nota: Usa una ventana del navegador privada o de incógnito (opción recomendada) para ejecutar el lab. Así evitarás conflictos entre tu cuenta personal y la cuenta de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
- Tiempo para completar el lab (recuerda que, una vez que comienzas un lab, no puedes pausarlo).
Nota: Usa solo la cuenta de estudiante para este lab. Si usas otra cuenta de Google Cloud, es posible que se apliquen cargos a esa cuenta.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá un diálogo para que selecciones la forma de pago.
A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón para abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debes usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordena las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta.
-
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}}
También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}}
También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud.
Nota: Usar tu propia cuenta de Google Cloud para este lab podría generar cargos adicionales.
-
Haz clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.
Nota: Para acceder a los productos y servicios de Google Cloud, haz clic en el menú de navegación o escribe el nombre del servicio o producto en el campo Buscar.

Tarea 1: Conceptos básicos de SQL
Tablas y bases de datos
Como se mencionó antes, SQL te permite obtener información de “conjuntos de datos estructurados”. Estos cuentan con reglas y formatos claros y, a menudo, están organizados en tablas: datos organizados en filas y columnas.
Un ejemplo de datos no estructurados sería un archivo de imagen. Los datos no estructurados no pueden operarse con SQL ni tampoco pueden almacenarse en los conjuntos de datos o tablas de BigQuery (al menos de forma nativa). Para trabajar con datos de imágenes, por ejemplo, deberías usar un servicio como Cloud Vision, quizá directamente a través de su API.
El siguiente es un ejemplo de un conjunto de datos estructurados, una tabla sencilla:
|
User
|
Price
|
Shipped
|
|
Sean
|
$35
|
Yes
|
|
Rocky
|
$50
|
No
|
Si tienes experiencia con Hojas de cálculo de Google, el ejemplo anterior debería verse bastante similar. La tabla tiene las columnas User, Price y Shipped, además de dos filas en las que se encuentran los valores de columna ingresados.
Una base de datos es básicamente una colección de una o más tablas. SQL es una herramienta de administración de bases de datos estructurados, pero con frecuencia (y en este lab) se usa para ejecutar consultas en una o varias tablas unidas, no en bases de datos completas.
SELECT y FROM
SQL es fonético por naturaleza, de modo que, antes de ejecutar una consulta, siempre es útil pensar primero qué pregunta queremos responder con los datos (a menos que solo estemos explorando por curiosidad).
SQL tiene palabras clave predefinidas que se usan para traducir una pregunta a la sintaxis en seudoinglés de SQL, de modo que puedas hacer que el motor de base de datos devuelva la respuesta que quieres.
Las palabras clave más importantes son SELECT y FROM:
- Usa
SELECT para especificar qué campos deseas extraer de tu conjunto de datos.
- Usa
FROM para especificar de qué tabla o tablas quieres extraer los datos.
Es más fácil entenderlo con un ejemplo. Imagina que tienes la siguiente tabla, llamada example_table, que tiene columnas identificadas como USER, PRICE y SHIPPED:
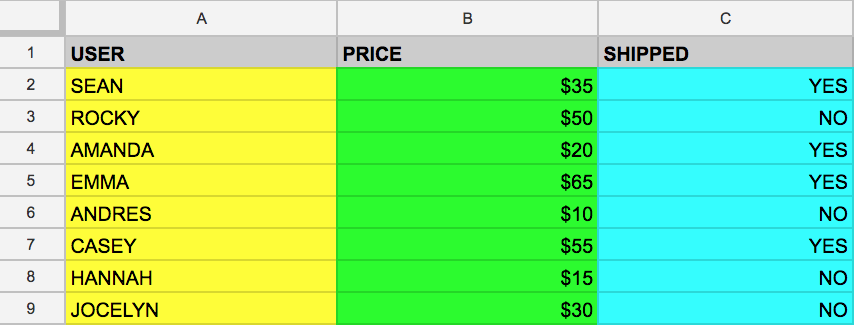
Digamos que solo quieres extraer los datos que se encuentran en la columna USER. Para hacerlo, puedes ejecutar la siguiente consulta que usa SELECT y FROM:
SELECT USER FROM example_table
Si ejecutaste el comando anterior, se seleccionaron todos los nombres de la columna USER que se encuentran en example_table.
También puedes seleccionar varias columnas con la palabra clave SELECT de SQL. Supongamos que quieres extraer los datos que se encuentran en las columnas USER y SHIPPED. Para ello, modifica la consulta anterior agregando otro valor de columna a nuestra consulta SELECT (asegúrate de que esté separado por una coma):
SELECT USER, SHIPPED FROM example_table
Si ejecutas lo anterior, recuperarás los datos de USER y SHIPPED de la memoria:
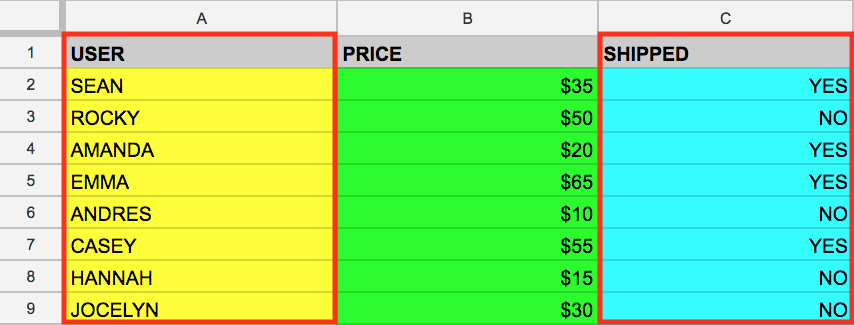
Con estos ejemplos, ya te familiarizaste con dos palabras clave importantes de SQL. Ahora, hagamos todo un poco más interesante.
WHERE
La palabra clave WHERE es otro comando de SQL que filtra tablas según valores de columna específicos. Supongamos que quieres extraer los nombres de example_table cuyos paquetes fueron enviados. Puedes complementar la consulta con WHERE, como en el siguiente ejemplo:
SELECT USER FROM example_table WHERE SHIPPED='YES'
Ejecutar esa consulta mostrará todos los usuarios (USER) cuyos paquetes les fueron enviados (SHIPPED) desde la memoria:
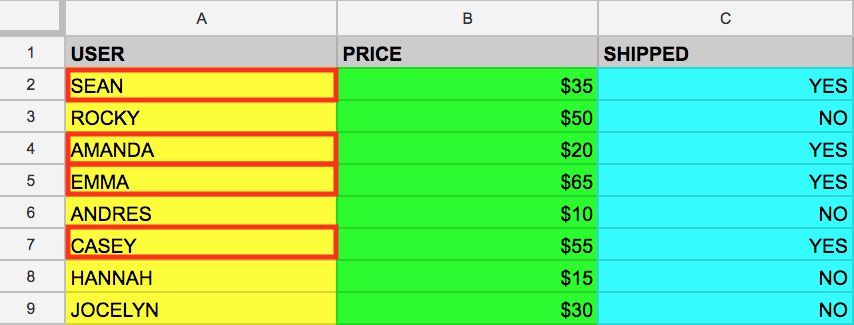
Ahora que cuentas con una comprensión básica de las palabras clave principales de SQL, aplica lo que aprendiste ejecutando estos tipos de consultas en la consola de BigQuery.
Pon a prueba tus conocimientos
Las siguientes son algunas preguntas de opción múltiple para reforzar tus conocimientos de los conceptos que vimos hasta ahora. Trata de responderlas lo mejor posible.
Tarea 2: Explora la consola de BigQuery
El paradigma de BigQuery
BigQuery es un almacén de datos a escala de petabytes completamente administrado que se ejecuta en Google Cloud. Los analistas y científicos de datos pueden consultar y filtrar rápidamente grandes conjuntos de datos, agregar resultados y realizar operaciones complejas sin tener que preocuparse por configurar y administrar servidores. Se presenta como una herramienta de línea de comandos (preinstalada en Cloud Shell) o una consola web; en ambos casos, viene lista para administrar y consultar datos alojados en proyectos de Google Cloud.
En este lab, usarás la consola web para ejecutar consultas en SQL.
Cómo abrir la consola de BigQuery
- En la consola de Google Cloud, seleccione elmenú de navegación > BigQuery.
Se abrirá el cuadro de mensaje Te damos la bienvenida a BigQuery en la consola de Cloud. Este cuadro de mensaje contiene un vínculo a la guía de inicio rápido y las notas de la versión.
- Haga clic en Listo.
Se abrirá la consola de BigQuery.
Dedica un momento a observar algunas características importantes de la IU. En el lado derecho de la consola, se encuentra el "Editor" de consultas. Aquí es donde se escriben y ejecutan comandos de SQL, como los de los ejemplos que se explicaron anteriormente. Debajo de este, se encuentra el “Historial de consultas”, una lista de consultas que ejecutaste previamente.
El panel de la izquierda de la consola es el menú de navegación. Además de las secciones denominadas Historial de consultas, Historial de trabajos y Consultas guardadas, cuyo significado es obvio, también hay una pestaña llamada Explorador.
El nivel más alto de recursos en la pestaña Explorador contiene proyectos de Google Cloud, que son como los proyectos temporales de Google Cloud a los que puedes acceder y usar en cada lab de Google Cloud Skills Boost. Como puedes ver en la consola y en la última captura de pantalla, solo tienes tu proyecto alojado en la pestaña Explorador. Si intentas hacer clic en la flecha junto al nombre del proyecto, no se mostrará nada.
Esto ocurre porque tu proyecto no contiene conjuntos de datos ni tablas, por lo que no hay nada que pueda consultarse. Anteriormente, aprendiste que los conjuntos de datos contienen tablas. Cuando agregues datos a tu proyecto, observa que, en BigQuery, los proyectos contienen conjuntos de datos, y los conjuntos de datos contienen tablas. Ahora que ya comprendes mejor el paradigma de proyecto > conjunto de datos > tabla y las particularidades de la consola, puedes cargar algunos datos que se pueden consultar.
Sube datos que puedan consultarse
En esta sección, incorporarás algunos datos públicos a tu proyecto para practicar la ejecución de comandos de SQL en BigQuery.
-
Haz clic en + AGREGAR.
-
Elige Destaca un proyecto por nombre.
-
Ingresa el nombre de proyecto como bigquery-public-data.
-
Haz clic en DESTACAR.
Es importante destacar que aún estás trabajando desde tu proyecto del lab en esta pestaña nueva. Lo único que hiciste fue incorporar a BigQuery un proyecto al que se puede acceder de manera pública y que contiene tablas y conjuntos de datos para su análisis; pero no cambiaste a ese proyecto. Todos tus trabajos y servicios siguen vinculados a la cuenta de Google Cloud Skills Boost. Para comprobarlo, revisa el campo de proyecto cerca de la parte superior de la consola:
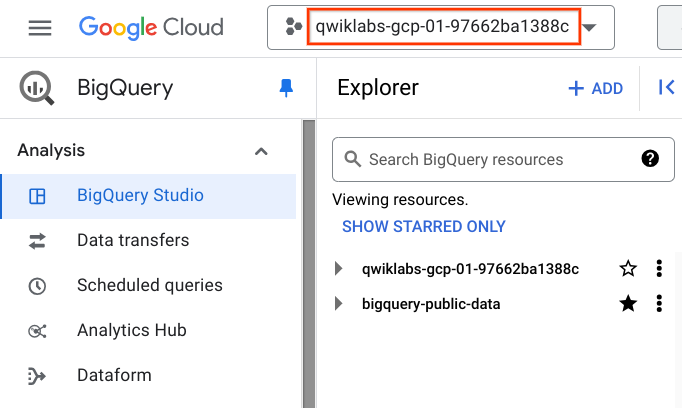
- Ahora, tienes acceso a los siguientes datos:
- Proyecto de Google Cloud →
bigquery-public-data
- Conjunto de datos →
london_bicycles
- Haz clic en el conjunto de datos london bicycles para revelar las tablas asociadas.
- Tabla →
cycle_hire
- Tabla →
cycle_stations
En este lab, usarás los datos de la tabla cycle_hire. Abre la tabla cycle_hire y, luego, haz clic en la pestaña Vista previa. Tu página debería verse de la siguiente manera:
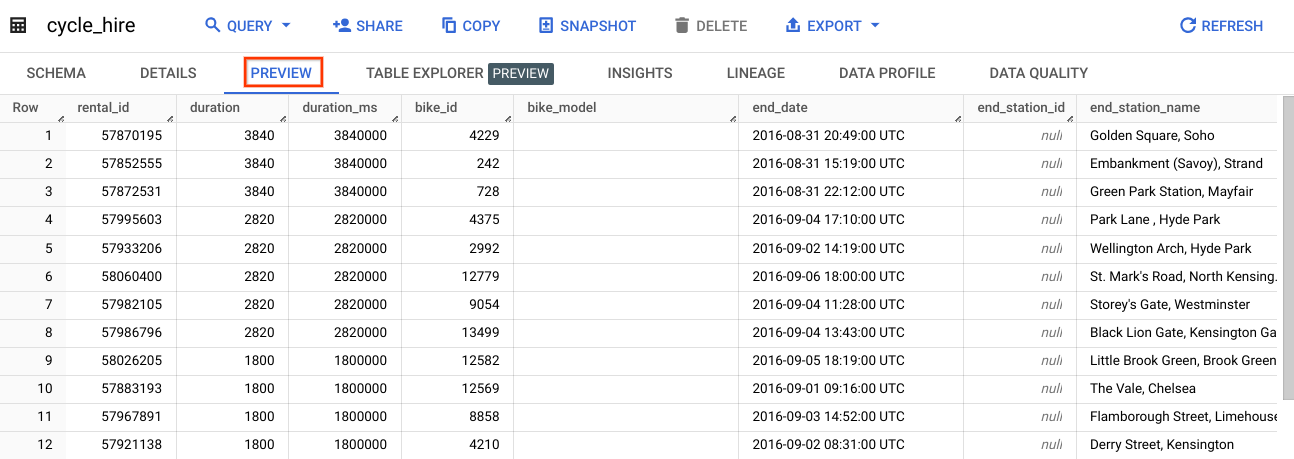
Revisa las columnas y los valores propagados en las filas. Ahora tienes todo listo para ejecutar algunas consultas en SQL en la tabla cycle_hire.
Ejecuta SELECT, FROM y WHERE en BigQuery
Ya cuentas con conocimientos básicos de las palabras clave de consulta en SQL y del paradigma de datos de BigQuery, así como con algunos datos para trabajar. Ejecuta algunos comandos de SQL con este servicio.
Si te fijas en la esquina inferior derecha de la consola, notarás que hay 83,434,866 filas de datos o viajes individuales en bicicletas compartidas realizados en Londres entre el 2015 y el 2017 (no es una cifra pequeña en absoluto).
Ahora, toma nota de la clave de la novena columna, end_station_name, que especifica el destino final de los viajes en bicicletas compartidas. Antes de profundizar más, ejecuta una consulta sencilla para aislar la columna end_station_name.
- Copia el siguiente comando y pégalo en el Editor de consultas:
SELECT end_station_name FROM `bigquery-public-data.london_bicycles.cycle_hire`;
- Luego, haz clic en Ejecutar.
Después de unos 20 segundos, deberían devolverse 83,434,866 filas que contienen la única columna que solicitaste en la consulta: end_station_name.
¿Por qué no averiguas cuántos viajes en bicicleta duraron 20 minutos o más?
- Borra la consulta del editor y ejecuta la siguiente consulta que usa la palabra clave
WHERE:
SELECT * FROM `bigquery-public-data.london_bicycles.cycle_hire` WHERE duration>=1200;
Esta consulta puede tardar aproximadamente un minuto en ejecutarse.
SELECT * muestra los valores de todas las columnas de la tabla. La duración se mide en segundos; es por ello que usaste el valor 1200 (60 × 20).
Si miras en la esquina inferior derecha, verás que se devolvieron 26,441,016 filas. Como fracción del total (26,441,016/83,434,866), esto significa que aproximadamente el 30% de los viajes en bicicletas compartidas en Londres duraron 20 minutos o más (a estos usuarios sí que les gusta pedalear).
Pon a prueba tus conocimientos
Las siguientes son algunas preguntas de opción múltiple para reforzar tus conocimientos sobre los conceptos que tratamos hasta ahora. Trata de responderlas lo mejor posible.
Tarea 3: Más palabras clave de SQL: GROUP BY, COUNT, AS y ORDER BY
GROUP BY
La palabra clave GROUP BY agrega filas de un conjunto de resultados que comparten criterios comunes (p. ej., el valor de la columna) y muestra todas las entradas únicas encontradas para esos criterios.
Es una palabra clave útil para averiguar información categórica en las tablas.
- Para comprender mejor cómo funciona esta palabra clave, borra la consulta del editor y, luego, copia y pega el siguiente comando:
SELECT start_station_name FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name;
- Haz clic en Ejecutar.
Los resultados serán una lista de valores de columna únicos (no duplicados).
Sin GROUP BY, la consulta hubiera devuelto las 83,434,866 filas. Con GROUP BY, el resultado son los valores de columna únicos que se encuentran en la tabla. Puedes verlo si te fijas en la esquina inferior derecha. Notarás que hay 954 filas, lo que significa que hay 954 puntos de partida diferentes para las bicicletas compartidas de Londres.
COUNT
La función COUNT() devolverá la cantidad de filas que comparten los mismos criterios (p. ej., el valor de columna). Esto puede resultar muy útil cuando lo utilizamos con GROUP BY.
Agrega la función COUNT a nuestra consulta anterior para averiguar cuántos viajes comienzan en cada punto de partida.
- Borra la consulta del editor, copia y pega el siguiente comando y, luego, haz clic en Ejecutar:
SELECT start_station_name, COUNT(*) FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name;
En el resultado se muestra cuántos viajes en bicicletas compartidas comenzaron en cada ubicación de partida.
AS
SQL también cuenta con una palabra clave AS, que crea un alias de una tabla o columna. Un alias es un nombre nuevo que se le da a la columna o tabla que se devuelve, según lo que se especifique en AS.
- Agrega una palabra clave
AS a la última consulta que ejecutaste para verla en acción. Borra la consulta del editor y, luego, copia y pega el siguiente comando:
SELECT start_station_name, COUNT(*) AS num_starts FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name;
- Haz clic en Ejecutar.
Para obtener resultados, el nombre de la columna derecha cambió de COUNT(*) a num_starts.
Como puedes ver, la columna COUNT(*) en la tabla que se muestra ahora tiene el nombre de alias num_starts. Esta es una palabra clave práctica, sobre todo si trabajas con grandes conjuntos de datos y olvidas que los nombres ambiguos en columnas o tablas suelen ser más comunes de lo que crees.
ORDER BY
La palabra clave ORDER BY ordena los datos devueltos de una consulta de manera ascendente o descendente según el criterio o valor de columna que se especifique. Agrega esta palabra clave a nuestra consulta anterior para hacer lo siguiente:
- Devolver una tabla que contenga la cantidad de viajes en bicicletas compartidas que comienzan en cada estación de partida, organizada alfabéticamente según la estación
- Mostrar una tabla que contenga la cantidad de viajes en bicicletas compartidas que comienzan en cada estación de partida, organizada numéricamente de menor a mayor
- Mostrar una tabla que contenga la cantidad de viajes en bicicletas compartidas que comienzan en cada estación de partida, organizada numéricamente de mayor a menor
Cada uno de los siguientes comandos es una consulta individual. Haz lo siguiente con cada comando:
- Borra los datos del Editor de consultas.
- Copia el comando y pégalo en el Editor de consultas.
- Haz clic en Ejecutar. Analiza los resultados.
SELECT start_station_name, COUNT(*) AS num FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name ORDER BY start_station_name;
SELECT start_station_name, COUNT(*) AS num FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name ORDER BY num;
SELECT start_station_name, COUNT(*) AS num FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name ORDER BY num DESC;
En los resultados de la última consulta se enumeran las ubicaciones de partida por la cantidad de partidas desde esa ubicación.
Verás que "Hyde Park Corner, Hyde Park" tiene la mayor cantidad de partidas. Sin embargo, como fracción del total (671688/83434866), notas que menos del 1% de los viajes comienzan en esa estación.
Pon a prueba tus conocimientos
Las siguientes son algunas preguntas de opción múltiple para reforzar tus conocimientos de los conceptos que vimos hasta ahora. Trata de responderlas lo mejor posible.
Tarea 4: Trabaja con Cloud SQL
Exporta consultas como archivos CSV
Cloud SQL es un servicio de bases de datos completamente administrado que facilita la configuración, el mantenimiento y la administración de bases de datos relacionales de PostgreSQL y MySQL en la nube. Cloud SQL acepta dos formatos de datos: archivos de volcado (.sql) o archivos CSV (.csv). Aprenderás a exportar subconjuntos de la tabla cycle_hire a archivos CSV y subirlos a Cloud Storage como ubicación intermedia.
Regresa a la consola de BigQuery; el siguiente debería ser el último comando que ejecutaste:
SELECT start_station_name, COUNT(*) AS num FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY start_station_name ORDER BY num DESC;
-
En la sección Resultados de la consulta, haz clic en GUARDAR RESULTADOS > CSV (archivo local). Esta acción inicia una descarga que guarda la consulta como un archivo CSV. Toma nota de la ubicación y el nombre de este archivo descargado; los necesitarás pronto.
-
Borra el contenido del Editor de consultas y, luego, copia y ejecuta el siguiente comando allí:
SELECT end_station_name, COUNT(*) AS num FROM `bigquery-public-data.london_bicycles.cycle_hire` GROUP BY end_station_name ORDER BY num DESC;
Esto muestra una tabla que contiene la cantidad de viajes en bicicletas compartidas que terminan en cada estación de llegada, y está organizada de forma numérica desde la cantidad de viajes más alta hasta la más baja.
- En la sección Resultados de la consulta, haz clic en GUARDAR RESULTADOS > CSV (archivo local). Esta acción inicia una descarga que guarda la consulta como un archivo CSV. Toma nota de la ubicación y el nombre de este archivo descargado; los necesitarás en la sección siguiente.
Sube archivos CSV a Cloud Storage
-
Ve a la consola de Cloud, en la que crearás un bucket de Storage donde podrás subir los archivos que acabas de crear.
-
Selecciona el menú de navegación > Cloud Storage > Buckets y, luego, haz clic en CREAR BUCKET.
Nota: Si se te solicita, haz clic en SALIR en el diálogo Trabajo sin guardar.
-
Ingresa un nombre único para el bucket, mantén el resto de la configuración predeterminada y haz clic en Crear:
-
Haz clic en Confirmar si te aparece el diálogo Se impedirá el acceso público.
Prueba la tarea completada
Haz clic en Revisar mi progreso a continuación para revisar tu progreso en el lab. Si creaste tu bucket correctamente, verás una puntuación de evaluación.
Crear un bucket de Cloud Storage
Ahora deberías estar en la consola de Cloud y ver el bucket de Cloud Storage que acabas de crear.
-
Haz clic en SUBIR > Subir archivos y selecciona el archivo CSV que contiene datos de start_station_name.
-
A continuación, haz clic en Abrir. Repite estos pasos para los datos de end_station_name.
-
Para cambiar el nombre de tu archivo start_station_name, haz clic en los tres puntos que aparecen en el extremo del archivo y selecciona Cambiar nombre. Cambia el nombre del archivo a start_station_data.csv.
-
Para cambiar el nombre de tu archivo end_station_name, haz clic en los tres puntos que aparecen en el extremo del archivo y selecciona Cambiar nombre. Cambia el nombre del archivo a end_station_data.csv.
Ahora, deberías ver start_station_data.csv y end_station_data.csv en la lista de Objetos en la página Detalles del bucket.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si subiste los objetos CSV a tu bucket de forma correcta, verás una puntuación de evaluación.
Subir archivos CSV a Cloud Storage
Tarea 5: Crea una instancia de Cloud SQL
En la consola, selecciona el menú de navegación > SQL.
-
Haz clic en CREAR INSTANCIA > elige MySQL.
-
En el ID de instancia, escribe my-demo.
-
En el campo Contraseña, ingresa una contraseña segura (es importante que la recuerdes).
-
Selecciona la versión de base de datos MySQL 8.
-
En Elige una edición de Cloud SQL, selecciona Enterprise.
-
En Ajuste predeterminado de edición, selecciona Desarrollo (4 CPU virtuales, 16 GB de RAM, 100 GB de almacenamiento, zona única).
Advertencia: Si eliges una configuración predeterminada con valores mayores que los de Desarrollo, tu proyecto se marcará y tu lab se dará por finalizado.
-
Establece el campo Región como .
-
Establece el campo de Multi zones (Con alta disponibilidad) > Zona principal en .
-
Haz clic en CREAR INSTANCIA.
Nota: Es posible que la instancia tarde algunos minutos en crearse. Cuando se cree, verás una marca de verificación verde al lado del nombre de la página de la instancia de SQL.
- Haz clic en la instancia de Cloud SQL. Se abrirá la página Descripción general de SQL.
Prueba la tarea completada
Para verificar tu progreso en el lab, haz clic en Revisar mi progreso a continuación. Si configuraste tu instancia de Cloud SQL de forma correcta, verás una puntuación de evaluación.
Crear una instancia de Cloud SQL
Tarea 6: Consultas nuevas en Cloud SQL
Palabra clave CREATE (tablas y bases de datos)
Ahora que ya cuentas con una instancia de Cloud SQL en funcionamiento, crea una base de datos en ella usando la línea de comandos de Cloud Shell.
-
Para abrir Cloud Shell, haz clic en el ícono de la esquina superior derecha de la consola.
-
Ejecuta el siguiente comando para configurar tu ID del proyecto como una variable de entorno:
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
Crea una base de datos en Cloud Shell
- Ejecuta el siguiente comando en Cloud Shell para configurar la autenticación sin abrir un navegador:
gcloud auth login --no-launch-browser
Si aparece la opción [Y/n], presiona Y y, luego, INTRO.
Aparecerá un vínculo para abrir en tu navegador. Ábrelo en el mismo navegador en el que accediste a la cuenta de Qwiklabs. Cuando accedas, obtendrás un código de verificación para copiar. Pega el código en Cloud Shell.
- Ejecuta el siguiente comando para conectarte a tu instancia de SQL, pero reemplaza
my-demo si usaste un nombre diferente para tu instancia:
gcloud sql connect my-demo --user=root --quiet
Nota: La conexión a tu instancia puede tardar unos minutos. Si aparece un mensaje que indica que se produjo un error en la operación porque ya había otra operación en curso, deberás esperar a que se termine de crear la instancia de SQL y, luego, volver a conectarte.
- Cuando se te solicite, ingresa la contraseña raíz que estableciste para la instancia. Nota: El cursor no se moverá.
Deberías ver un resultado similar al siguiente:
Welcome to the MySQL monitor. Commands end with ; or \g.
Server version: 8.0.31-google (Google)
Copyright (c) 2000, 2024, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
Una instancia de Cloud SQL incluye bases de datos preconfiguradas, pero tú crearás una propia para almacenar los datos del sistema de bicicletas compartidas de Londres.
- Ejecuta el siguiente comando en el símbolo del sistema del servidor de MySQL para crear una base de datos llamada
bike:
CREATE DATABASE bike;
Deberías recibir el siguiente resultado:
Query OK, 1 row affected (0.05 sec)
mysql>
Prueba la tarea completada
Haz clic en Revisar mi progreso y verifica la tarea realizada. Si creaste correctamente la base de datos en la instancia de Cloud SQL, verás una puntuación de evaluación.
Crear una base de datos
Crea una tabla en Cloud Shell
- Ejecuta el siguiente comando para crear una tabla dentro de la base de datos de bicicletas:
USE bike;
CREATE TABLE london1 (start_station_name VARCHAR(255), num INT);
Esta instrucción usa la palabra clave CREATE, pero esta vez usa la cláusula TABLE para especificar que se desea crear una tabla en lugar de una base de datos. La palabra clave USE especifica una base de datos a la que deseas conectarte. Ahora tienes una tabla llamada “london1” que contiene dos columnas: “start_station_name” y “num”. VARCHAR(255) especifica la columna de cadena de longitud variable que admite hasta 255 caracteres, y el valor INT es una columna de tipo número entero.
- Ejecuta el siguiente comando para crear otra tabla con el nombre "london2":
USE bike;
CREATE TABLE london2 (end_station_name VARCHAR(255), num INT);
- Ahora confirma que se crearon tus tablas vacías. Ejecuta los siguientes comandos en el símbolo del sistema del servidor MySQL:
SELECT * FROM london1;
SELECT * FROM london2;
Deberías recibir el siguiente resultado para ambos comandos:
Empty set (0.04 sec)
Aparece “empty set” porque aún no has cargado datos.
Sube archivos CSV a las tablas
Regresa a la consola de Cloud SQL. Ahora, subirás los archivos CSV start_station_name y end_station_name a tus tablas recién creadas, london1 y london2.
- En la página de tu instancia de Cloud SQL, haz clic en IMPORTAR.
- En el campo de archivos de Cloud Storage, haz clic en Explorar. Luego, haz clic en la flecha que se encuentra junto al nombre de tu bucket y en
start_station_data.csv. A continuación, haz clic en Seleccionar.
- Selecciona CSV como el formato de archivo.
- Selecciona la base de datos
bike y escribe london1 como tu tabla.
- Haz clic en Importar.
Haz lo mismo para el otro archivo CSV.
- En la página de tu instancia de Cloud SQL, haz clic en IMPORTAR.
- En el campo de archivos de Cloud Storage, haz clic en Explorar. Luego, haz clic en la flecha que se encuentra junto al nombre de tu bucket y en
end_station_data.csv. A continuación, haz clic en Seleccionar.
- Selecciona CSV como el formato de archivo.
- Selecciona la base de datos
bike y escribe london2 como tu tabla.
- Haz clic en Importar.
Los dos archivos CSV deberían haberse subido a las tablas de la base de datos bike.
- Regresa a tu sesión de Cloud Shell y ejecuta el siguiente comando en el prompt del servidor MySQL para revisar el contenido de london1:
SELECT * FROM london1;
Deberías recibir 955 líneas de resultados, una por cada nombre de estación único.
- Ejecuta el siguiente comando para asegurarte de que se hayan propagado datos a london2:
SELECT * FROM london2;
Deberías recibir 959 líneas de resultados, una por cada nombre de estación único.
Palabra clave DELETE
Estas son algunas palabras clave de SQL más que nos ayudarán con la administración de los datos. La primera es DELETE.
- Ejecuta los siguientes comandos en tu sesión de MySQL para borrar la primera fila de las tablas london1 y london2:
DELETE FROM london1 WHERE num=0;
DELETE FROM london2 WHERE num=0;
Deberías recibir el siguiente resultado después de ejecutar ambos comandos:
Query OK, 1 row affected (0.04 sec)
Las filas que se borraron eran los encabezados de columna de los archivos CSV. La palabra clave DELETE no quitará la primera fila del archivo, sino todas las filas de la tabla en las que el nombre de columna (en este caso, “num”) contenga un valor especificado (en este caso, “0”). Si ejecutas las consultas SELECT * FROM london1; y SELECT * FROM london2;, y te desplazas hacia la parte superior de la tabla, verás que esas filas ya no existen.
Palabra clave INSERT INTO
También puedes insertar valores en las tablas con la palabra clave INSERT INTO.
- Ejecuta el siguiente comando para agregar una fila nueva a london1, que configura
start_station_name como “test destination” y num como “1”:
INSERT INTO london1 (start_station_name, num) VALUES ("test destination", 1);
La palabra clave INSERT INTO requiere de una tabla (london1) y creará una fila nueva con columnas especificadas por los términos en el primer paréntesis (en este caso, “start_station_name” y “num”). El contenido que aparece después de la cláusula “VALUES” se inserta como valores en la fila nueva.
Deberías recibir el siguiente resultado:
Query OK, 1 row affected (0.05 sec)
Si ejecutas la consulta SELECT * FROM london1;, verás una fila adicional agregada al final de la tabla “london1”.
Palabra clave UNION
La última palabra clave de SQL que aprenderás es UNION. Esta combina el resultado de dos o más consultas SELECT en un conjunto de resultados. Usarás UNION para combinar los subconjuntos de las tablas "london1" y "london2".
La siguiente consulta en cadena extrae datos específicos de ambas tablas y los combina con el operador UNION.
- Ejecuta el siguiente comando en el símbolo del sistema del servidor MySQL:
SELECT start_station_name AS top_stations, num FROM london1 WHERE num>100000
UNION
SELECT end_station_name, num FROM london2 WHERE num>100000
ORDER BY top_stations DESC;
La primera consulta SELECT selecciona las dos columnas de la tabla "london1" y crea un alias para "start_station_name", que se establece como "top_stations". Usa la palabra clave WHERE para extraer solo los nombres de las estaciones de transporte compartido en las que comienzan su recorrido más de 100,000 bicicletas.
La segunda consulta SELECT selecciona las dos columnas de la tabla "london2" y usa la palabra clave WHERE para extraer solamente los nombres de las estaciones de transporte compartido en las que terminan su recorrido más de 100,000 bicicletas.
La palabra clave UNION en el medio combina el resultado de estas consultas integrando los datos de "london2" con "london1". Puesto que “london1” se está uniendo con “london2”, los valores de columna que tendrán precedencia son “top_stations” y “num”.
ORDER BY ordenará alfabéticamente la tabla unida final según el valor de columna “top_stations”, en orden descendente.
Resultado de ejemplo (tus resultados pueden variar):
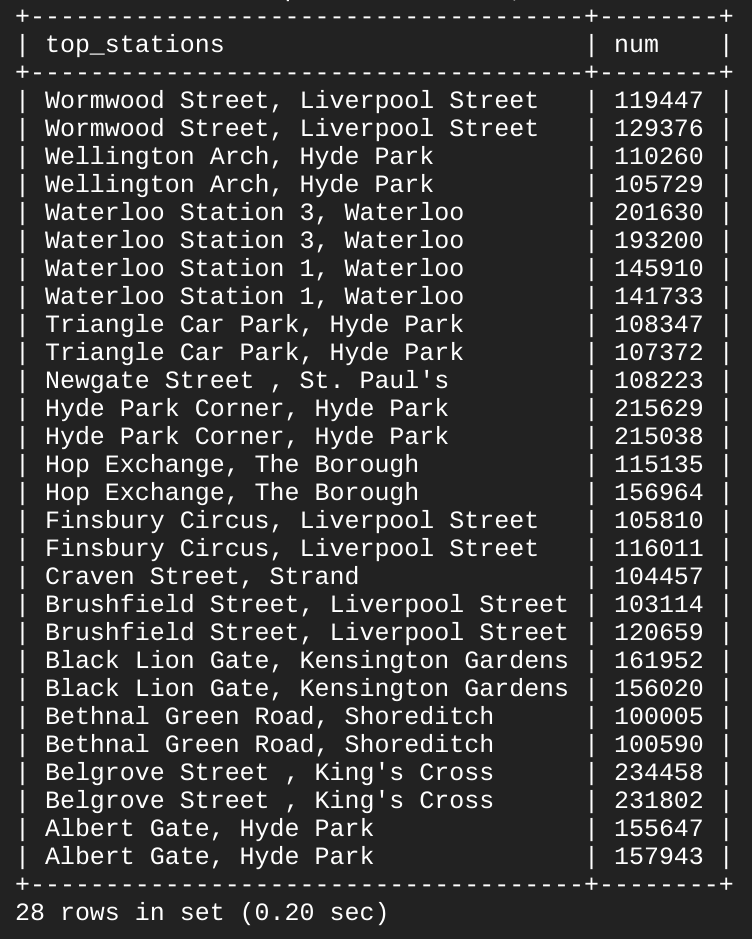
Como puedes ver, hay 13 o 14 estaciones que comparten los primeros puestos como punto de partida y llegada para el transporte compartido. Con algunas palabras clave básicas de SQL, pudiste realizar consultas a un conjunto de datos considerable, que devolvió como resultado datos y respuestas a preguntas específicas.
¡Felicitaciones!
En este lab, aprendiste los conceptos básicos de SQL y cómo puedes aplicar palabras clave y ejecutar consultas en BigQuery y Cloud SQL. Aprendiste los conceptos principales detrás de los proyectos, las bases de datos y las tablas. Practicaste el uso de palabras clave para manipular y editar datos. Aprendiste a leer datos en BigQuery y practicaste la ejecución de consultas en tablas. Además, aprendiste a crear instancias en Cloud SQL y practicaste la transferencia de subconjuntos de datos a tablas contenidas en bases de datos. Encadenaste y ejecutaste consultas en Cloud SQL para llegar a algunas conclusiones interesantes sobre las estaciones de partida y llegada del sistema de bicicletas compartidas de Londres.
Próximos pasos y más información
Continúa aprendiendo y practicando con Cloud SQL y BigQuery con estos labs de Google Cloud Skills Boost:
Obtén más información relacionada con la ciencia de datos en el libro Data Science on the Google Cloud Platform, 2nd Edition: O'Reilly Media, Inc.
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Actualización más reciente del manual: 16 de octubre de 2024
Prueba más reciente del lab: 16 de octubre de 2024
Copyright 2025 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.





