Os fluxos de trabalho são um tema comum quando falamos em análise de dados. Eles envolvem ingestão, transformação e análise de dados para descobrir informações relevantes contidas nesses dados. A ferramenta do Google Cloud Platform (GCP) para hospedagem de fluxos de trabalho é o Cloud Composer. Ele é a versão hospedada da famosa ferramenta de fluxo de trabalho de código aberto Apache Airflow.
Neste laboratório, você usará o Console do GCP para configurar um ambiente do Cloud Composer. Depois, você usará o Cloud Composer para realizar um fluxo de trabalho simples que verifica a existência de um arquivo de dados, cria um cluster do Cloud Dataproc, executa um job de contagem de palavras no cluster do Cloud Dataproc e depois exclui esse cluster.
Atividades deste laboratório
Usar o Console do GCP para criar o ambiente do Cloud Composer
Ver e executar o gráfico acíclico dirigido (DAG) na interface da Web do Airflow
Ver os resultados do job de contagem de palavras no armazenamento
Configuração e requisitos
Configuração do laboratório
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual que contém ferramentas para desenvolvedores. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece aos seus recursos do Google Cloud acesso às linhas de comando. A gcloud é a ferramenta ideal para esse tipo de operação no Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
No painel de navegação do Console do Google Cloud, clique em Ativar o Cloud Shell ().
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando esses processos forem concluídos, você já vai ter uma autenticação, e o projeto estará definido com seu PROJECT_ID. Por exemplo:
Antes de começar a trabalhar no Google Cloud, confira se o projeto tem as permissões corretas no Identity and Access Management (IAM).
No Console do Google Cloud, acesse o menu de navegação () e clique em IAM e administrador > IAM.
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que pode ser encontrado em Menu de navegação > Visão geral do Cloud.
Se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
No Menu de navegação do console do Google Cloud, clique em Visão geral do Cloud.
No card Informações do projeto, copie o Número do projeto.
No Menu de navegação, clique em IAM e administrador > IAM.
Na parte superior da página IAM, clique em Adicionar.
Substitua {project-number} pelo número do seu projeto.
Em Selecionar um papel, selecione Básico (ou Projeto) > Editor.
Clique em Salvar.
Tarefa 1: verificar se a API Kubernetes Engine foi ativada
Para garantir o acesso às APIs necessárias, reinicie a conexão com a API Kubernetes Engine.
No console do Google Cloud, encontre e registre o Número do projeto na caixa Informações do projeto.
No console, insira API Kubernetes Engine na barra de pesquisa superior. Clique no resultado para API Kubernetes Engine.
Clique em Gerenciar.
Clique em Desativar API.
Se for necessário confirmar, clique em Desativar.
Se aparecer Do you want to disable Kubernetes Engine API and its dependent APIs?, clique em Desativar outra vez.
Selecione Ativar.
A opção para desativar a API aparece quando ela é ativada novamente.
Tarefa 2: verificar se a API Cloud Composer foi ativada
Reinicie a conexão com a API Cloud Composer. Na etapa anterior, o reinício da API Kubernetes Engine forçou a desativação da API Cloud Composer.
No Console do Google Cloud, insira API Cloud Composer na barra de pesquisa superior. Clique no resultado para API Cloud Composer.
Selecione Ativar.
A opção para desativar a API aparece quando ela é ativada novamente.
Tarefa 3: criar o ambiente do Cloud Composer
Nesta seção, você vai criar um ambiente do Cloud Composer.
Observação: antes de continuar, verifique se você executou as tarefas anteriores para ativar as APIs necessárias. Caso contrário, faça isso para evitar falha na criação do ambiente do Cloud Composer.
Na barra de título do console do Google Cloud, no campo Pesquisar, digite Cloud Composer e clique em Composer.
Clique em Criar ambiente e selecione Composer 3.
Defina o seguinte para seu ambiente:
Propriedade
Valor
Nome
highcpu
Local
Versão de imagem
composer-3-airflow-n.n.n-build.n (observação: selecione a imagem com o maior número disponível)
Não altere as outras configurações.
Em Recursos do ambiente, escolha Pequeno.
Clique em Criar.
O processo de criação do ambiente é concluído quando a marca de seleção verde aparece à esquerda do nome na página "Ambientes" no Console do GCP.
O processamento de configuração do ambiente pode levar de 10 a 20 minutos. Continue o laboratório enquanto o ambiente é gerado.
Clique em Verificar meu progresso para conferir o objetivo.
Crie o ambiente do Cloud Composer.
Crie um bucket do Cloud Storage
Crie um bucket do Cloud Storage no projeto. Ele será usado como saída no job do Hadoop no Dataproc.
Acesse Menu de navegação > Cloud Storage > Buckets e clique em + Criar.
Dê um nome exclusivo ao seu bucket e clique em Criar. Se a mensagem O acesso público será bloqueado aparecer, clique em Confirmar.
Lembre-se do nome do bucket do Cloud Storage. Ele será usado posteriormente neste laboratório como uma variável do Airflow.
Clique em Verificar meu progresso para conferir o objetivo.
Crie um bucket do Cloud Storage.
Tarefa 4: definição e conceitos principais do Airflow
Enquanto você aguarda a criação do ambiente do Composer, veja alguns termos usados com o Airflow.
O Airflow é uma plataforma para criar, programar e monitorar fluxos de trabalho de forma programática.
Use o Airflow para criar fluxos de trabalho como gráficos acíclicos dirigidos (DAGs, na sigla em inglês) de tarefas. O programador do Airflow executa suas tarefas em uma matriz de workers enquanto segue as dependências especificadas.
Principais conceitos
DAG: um gráfico acíclico dirigido é uma coleção das tarefas que você quer executar, organizadas para refletir as relações e dependências.
Operador: é a descrição de uma única tarefa. Em geral, os operadores são atômicos. Por exemplo, o operador BashOperator é usado para executar o comando "bash".
Tarefa: uma instância parametrizada de um operador. As tarefas são nós no DAG.
Instância de tarefa: a execução específica de uma tarefa. É composta de um DAG, uma tarefa e um ponto no tempo. Ela tem sempre um estado indicativo, por exemplo: running, success, failed, skipped etc.
Agora vamos falar sobre o fluxo de trabalho usado. No Cloud Composer, os fluxos de trabalho são compostos de gráficos acíclicos dirigidos (DAGs). Os DAGs são definidos em arquivos Python padrão, armazenados na pasta DAG_FOLDER do Airflow. O Airflow executará o código em cada arquivo para criar dinamicamente os objetos DAG. É possível ter quantos DAGs quiser e usar cada um deles para descrever algumas tarefas. Em geral, cada um deles deve corresponder a um único fluxo de trabalho lógico.
Veja abaixo o código do fluxo de trabalho hadoop_tutorial.py, também chamado de DAG:
"""Exemplo de um DAG do Airflow que cria um cluster do Cloud Dataproc, executa o exemplo de contagem de palavras do Hadoop
e exclui o cluster.
Este DAG depende de três variáveis do Airflow
https://airflow.apache.org/concepts.html#variables
* gcp_project - Projeto do Google Cloud que será usado pelo cluster do Cloud Dataproc.
* gce_zone - Zona do Google Compute Engine onde o cluster do Cloud Dataproc deve ser
criado.
* gcs_bucket - bucket do Google Cloud Storage utilizado como saída dos jobs do Hadoop.
Leia https://cloud.google.com/storage/docs/creating-buckets para aprender a criar um
bucket.
"""
import datetime
import os
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
# Arquivo produzido pelo job do Cloud Dataproc.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
# Caminho para o exemplo de contagem de palavras do Hadoop disponível em todos os clusters do Dataproc.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
# Argumentos que devem ser transmitidos ao job do Cloud Dataproc.
wordcount_args = ['wordcount', 'gs://pub/shakespeare/rose.txt', output_file]
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
# Definir a data de início como ontem inicia o DAG imediatamente quando ele for
# detectado no bucket do Cloud Storage.
'start_date': yesterday,
# Para enviar e-mail em caso de falha ou nova tentativa, defina o argumento 'email' para seu e-mail e ative
# essa opção aqui.
'email_on_failure': False,
'email_on_retry': False,
# Se uma tarefa falhar, faça uma nova tentativa depois de esperar pelo menos 5 minutos
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
with models.DAG(
'composer_sample_quickstart',
# Continue executando o DAG uma vez por dia
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
# Crie um cluster do Cloud Dataproc.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
# Dê um nome exclusivo ao cluster anexando a data agendada.
# Consulte https://airflow.apache.org/code.html#default-variables
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
region=models.Variable.get('gce_region'),
zone=models.Variable.get('gce_zone'),
image_version='2.0',
master_machine_type='n1-standard-2',
worker_machine_type='n1-standard-2')
# Execute o exemplo de contagem de palavras do Hadoop instalado no nó mestre do cluster do
# Cloud Dataproc.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
region=models.Variable.get('gce_region'),
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial- cluster-{{ ds_nodash }}',
arguments=wordcount_args)
# Exclua o cluster do Cloud Dataproc.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
region=models.Variable.get('gce_region'),
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
# Definir trigger_rule como ALL_DONE faz com que o cluster seja excluído
# mesmo que o job do Dataproc apresente falha.
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
# Defina as dependências de DAG.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
Para orquestrar as três tarefas do fluxo de trabalho, o DAG importa os seguintes operadores:
DataprocClusterCreateOperator: cria um cluster do Cloud Dataproc.
DataProcHadoopOperator: envia um job de contagem de palavras do Hadoop e grava os resultados em um bucket do Cloud Storage.
DataprocClusterDeleteOperator: exclui o cluster para evitar cobranças contínuas do Compute Engine.
As tarefas são executadas sequencialmente, como mostra esta seção do arquivo:
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
O DAG é executado uma vez por dia, e o nome dele é quickstart.
with models.DAG(
'composer_sample_quickstart',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
Como o código start_date transmitido para default_dag_args está definido como yesterday, o Cloud Composer programa o fluxo de trabalho para iniciar imediatamente após o DAG ser carregado.
Tarefa 6: consultar as informações do ambiente
Volte para o Composer e verifique o status do seu ambiente.
Depois que seu ambiente for criado, clique no nome dele (highcpu) para ver os detalhes.
Na guia Configuração do ambiente, você encontra informações como o URL da interface da Web do Airflow, o cluster do GKE e um link para a pasta de DAGs, que está armazenada no seu bucket.
Observação: o Cloud Composer só programa os fluxos de trabalho que estão na pasta /dags.
Tarefa 7: usar a interface do Airflow
Para acessar a interface da Web do Airflow com o Console do GCP:
Volte para a página Ambientes.
Na coluna Servidor da Web do Airflow do ambiente, clique em Airflow.
Clique nas suas credenciais do laboratório.
A interface da Web do Airflow será aberta em uma nova janela do navegador.
Tarefa 8: como definir variáveis do Airflow
As variáveis do Airflow são um conceito específico da plataforma e diferente das variáveis de ambiente.
Na interface do Airflow, selecione Admin > Variables na barra de menus.
Clique no ícone + para adicionar um novo registro.
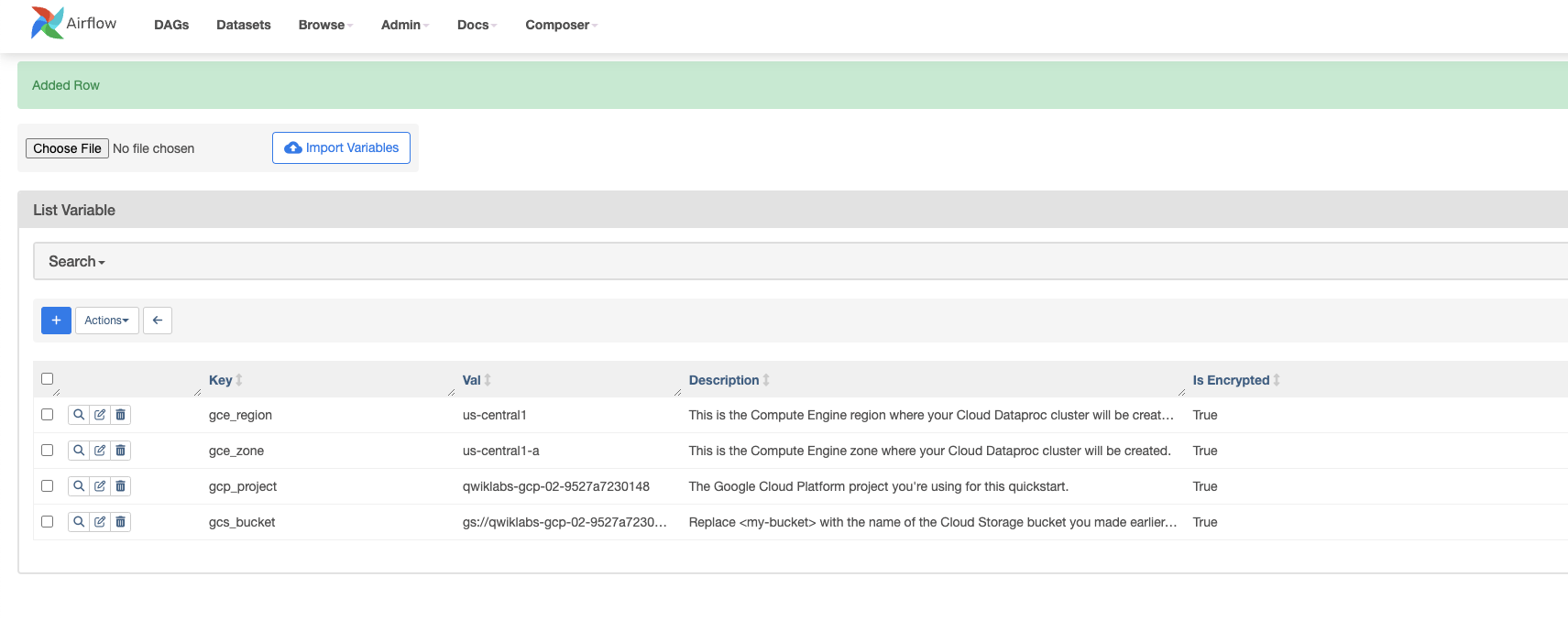
Crie as variáveis gcp_project, gcs_bucket e gce_zone do Airflow:
Key
Val
Details
gcp_project
É o projeto do Google Cloud Platform usado neste laboratório.
gcs_bucket
gs://<my-bucket>
Substitua <my-bucket> pelo nome do bucket do Cloud Storage que você criou. Esse bucket armazena a resposta dos jobs do Hadoop no Dataproc.
gce_zone
Essa é a zona do Compute Engine em que o cluster do Cloud Dataproc será criado.
gce_region
Essa é a região do Compute Engine em que o cluster do Cloud Dataproc será criado.
Clique em Save. Depois de adicionar a primeira variável, repita o mesmo processo para a segunda e a terceira. A tabela de variáveis será semelhante a esta no final:
Tarefa 9: fazer upload do DAG para o Cloud Storage
Siga estas etapas para fazer o upload do DAG:
No Cloud Shell, execute o comando abaixo para fazer upload de uma cópia do arquivo hadoop_tutorial.py no bucket do Cloud Storage que foi criado automaticamente quando você criou o ambiente.
No comando abaixo, substitua <DAGs_folder_path> pelo caminho para a pasta de DAGs:
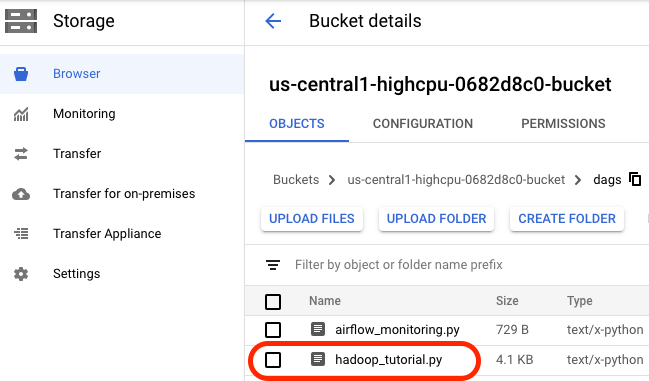
Após o upload para o diretório de DAGs, abra a pasta dags no bucket que mostra o arquivo na guia Objetos dos detalhes do bucket.
Quando um arquivo DAG é incluído na pasta relacionada, o Cloud Composer adiciona o DAG ao Airflow e o programa automaticamente. As alterações no DAG levam de 3 a 5 minutos.
Você pode ver o status da tarefa do DAG composer_hadoop_tutorial na interface da Web do Airflow.
Clique em Verificar meu progresso para conferir o objetivo.
Faça upload do DAG no Cloud Storage.
Como o DAG é executado
Quando estiver na pasta dags no Cloud Storage, o arquivo DAG será analisado pelo Cloud Composer. Se nenhum erro for encontrado, o nome do fluxo de trabalho será exibido na lista de DAGs e entrará na fila para ser executado imediatamente.
Verifique se você está na guia "DAGs" na interface da Web do Airflow. É preciso esperar alguns minutos até que esse processo seja concluído. Atualize o navegador para acessar as informações mais recentes.
Verifique se você está na guia "DAGs" na interface da Web do Airflow. É preciso esperar alguns minutos até que esse processo seja concluído. Atualize o navegador para acessar as informações mais recentes.
No Airflow, clique em composer_hadoop_tutorial para abrir a página de detalhes do DAG. Ela inclui várias representações das tarefas e dependências do fluxo de trabalho.
Na barra de ferramentas, clique em Graph. Passe o cursor sobre a representação gráfica de cada tarefa para conferir o status correspondente. A borda das tarefas também indica o status: verde = em execução, vermelha = falha etc.
Clique no link "Refresh" para ver as informações mais recentes. As bordas dos processos mudam de cor para indicar o estado.
Observação: quando o cluster do Dataproc já existe, é possível executar o fluxo de trabalho novamente para alcançar o estado "success". Para isso, clique no gráfico `create_dataproc_cluster` e em Clear, que redefine as três tarefas. Depois, clique em OK para confirmar.
Assim que o status de create_dataproc_cluster mudar para "running", acesse o Menu de navegação > Dataproc e clique em:
Clusters para monitorar a criação e a exclusão de clusters. O cluster criado pelo fluxo de trabalho é efêmero e será excluído como parte da última tarefa após a execução do fluxo;
Jobs para monitorar o job de contagem de palavras do Apache Hadoop. Clique no ID do job para ver a saída do registro dele.
Quando o Dataproc alcançar o estado "running", volte para o Airflow e clique em Refresh para conferir se o cluster está completo.
Ao final do processo run_dataproc_hadoop, acesse o Menu de navegação > Cloud Storage > Buckets e clique no nome do seu bucket para conferir os resultados da contagem de palavras na pasta wordcount.
Depois que todas as etapas forem concluídas no DAG, cada uma delas terá uma borda verde escura. Além disso, o cluster do Dataproc que foi criado é excluído.
Parabéns!
Você executou um fluxo de trabalho do Cloud Composer.
Após terminar seu laboratório, clique em End Lab. O Qwiklabs removerá os recursos usados e limpará a conta para você.
Você poderá avaliar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Submit.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Support.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Neste laboratório, você criará um ambiente do Cloud Composer usando o console do GCP. Depois, você usará a interface da Web do Airflow para executar um fluxo de trabalho que verifica um arquivo de dados, cria e executa um job de contagem de palavras do Apache Hadoop em um cluster do Dataproc e exclui o cluster.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 90 minutos
·
Tempo para conclusão: 90 minutos
 ).
).
 ) e clique em IAM e administrador > IAM.
) e clique em IAM e administrador > IAM.